Сканирование для системы распознавания символов
Системы оптического распознавания символов (Optical Character Recognition, ли OCR-системы) предназначены для автоматического ввода документов в память компьютера. За ничтожный по историческим меркам отрезок времени эти системы вышли из стадии экспериментальных испытаний и превратились в один из самых спешных в коммерческом отношении класс программных продуктов. Сейчас OCR-системы успешно справляются с обработкой печатных документов. Задача распознавания рукописных символов решается только в нескольких частных случаях.
Распознавание символов - это сложная проблема, которая требует для своего решения привлечения новейших методов дискретной математики и искусственного интеллекта. Она не решается простыми переборными алгоритмами. Сложность реализации не стала непреодолимой преградой для разработчиков; на рынке программных продуктов предлагается несколько систем автоматического распознавания примерно равного класса, обладающих похожими функциональными возможностями. За рубежом получили наибольшее распространение программы OmniPage, Presto!, OCR Pro. Неплохой функциональностью обладают системы Textbridge и CuneiForm. В нашей стране самой популярной является программа FineReader, разработанная фирмой ABBYY.
FineReader - это программа-полиглот, разработчики ввели в ее состав средства распознавания текстов, написанных на самых распространенных языках мира. Она почти не знает шрифтовых ограничений, в среде программы могут быть успешно обработаны тексты, набранные самыми разнообразными шрифтовыми гарнитурами.
Процедура обработки документов в любой OCR-системе состоит из следующих этапов:
- Сканирование. На этом этапе сканер формирует изображение, которое является основой для последующего распознавания. Цифровая версия документа представляет собой изображение, которое не может быть отредактировано как текст ни одним программным средством.
Интенсивность проявления полиграфического муара зависит от рисунка. Он особенно заметен в областях с однородной заливкой. И наоборот, изобилие мелких деталей способно полностью маскировать этот дефект от глаз наблюдателя. Так, на рис. 1.18 муар почти незаметен на изображении гор и снега, которые содержат множество произвольно расположенных фрагментов маленького размера.
Большинство современных компьютерных мониторов использует в своей работе электронно-лучевые трубки и матрицы жидких кристаллов. Это регулярные структуры, которые при «благоприятных» обстоятельствах могут стать причиной появления муара на экране. Интенсивность экранного муара зависит от масштаба изображения. В зависимости от установленного коэффициента увеличения этот эффект может усиливаться или совершенно исчезать. Для изображения, которое предназначено для публикации в сети, муар - это совершенно недопустимое явление. Достоверное заключение о наличии этого артефакта и его силе можно сделать, только просмотрев картинку в ее истинном масштабе, т. е. при 100 %-ном увеличении.
Все упомянутые настройки процесса сканирования расположены в одном диалогом окне программы FineReader (см. рис. 1.15). Чтобы вывести его на экран, следует выполнить команду главного меню программы Сервис => Опции => Сканирование/ Открытие => Настройки сканера.
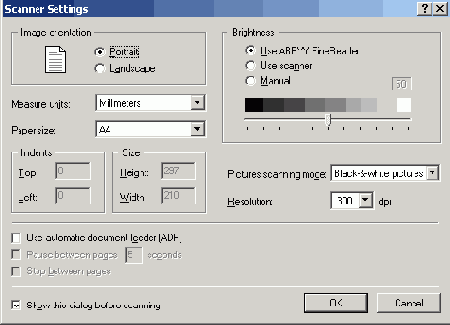
Рис. 1.15. Диалоговое окно с настройками сканера в программе FineReader
Это доступное интерфейсное средство, все его элементы носят русские названия и имеют очень простые правила обращения. При сканировании страниц в черно-белом режиме результаты распознавания очень сильно зависят от выбранного значения яркости. Ее настройка выполняется при помощи ползунка, расположенного под черно-белым градиентом, или посредством ввода числового значения яркости.
От выбранного значения яркости зависит процентное соотношение между черными и белыми точками, а следовательно, и плотность букв. Этот параметр является по сути дела порогом, от значения которого зависит тон точек. Чем выше значение яркости, тем большее число точек получает в результате сканирования белый цвет. И наоборот, снижение яркости вводит в состав документа больше черных точек, что делает символы темнее и плотнее.
Верхняя надпись, показанная на рис. 1.16, обработана с высокой яркостью. Можно заметить, что это привело к потере связности некоторых букв. Обработка такого образца может привести к появлению неправильно распознанных символов. Средний вариант оцифрован при низких значениях яркости, что привело к захвату множества паразитных фоновых точек. Распознавание такого образца также может повлечь за собой появление ошибок, поскольку увеличение толщины символов привело к появлению соединенных пар литер- лигатур. Нижний образец- это пример изображения, оцифрованного с нормальной яркостью. В результате удачного распределения черных и белых точек достигнута высокая плотность символов и сохранение мелких деталей. С другой стороны, все литеры хорошо отделимы от своих соседей и фона.

Рис. 1.16. Варианты изображения, оцифрованные с разной яркостью. От установленной яркости зависит плотность литер, которая решающим образом влияет на результативность распознавания
Следует отметить, что невозможно задать оптимальный уровень яркости умозрительно, для этого требуется провести серию пробных сеансов оцифровки. Программы распознавания символов не приспособлены для такой работы, поэтому они не предоставляют пользователю удобных средств подбора яркости. Эта ситуация дает еще один весомый аргумент в пользу тезиса, который автор не раз отстаивал в этой книге. Всю препроцессорную обработку изображений лучше выполнять средствами специализированного растрового редактора. Применительно к распознаванию это означает, что документ следует сканировать в режиме Grayscale, затем открыть его в Photoshop и в его среде провести всю необходимую подготовку для успешного распознавания.
Алгоритмы работы систем распознавания закрыты от пользователя, но все программы этого класса демонстрируют несколько общих особенностей поведения. Идеальным оригиналом для любой программы распознавания является белая плотная страничка, набранная рубленым шрифтом 12 кегля (например, Arial или Prag-matica), не имеющая графических вставок, цветного фона, загрязненных фрагментов, малоупотребительных слов, фрагментов на иностранных языках, пометок на полях, математических и химических формул, перегибов и разрывов и при этом набранная в одну колонку. Все отклонения от этого идеала в большей или меньшей степени усложняют работу системы распознавания.
