Хэш-секционирование
Хэш-секционирование (hash partitioning) означает равномерное распределение строк таблицы по назначенным табличным пространствам в зависимости от значения ключа секционирования, который в данном случае хэшируется. Этот вид секционирования удобно применять для строк, у которых распределение значений ключа секционирования неравномерно или плохо группируется. Если проектировщик базы данных принимает решение о создании хэш-секционированной таблицы, то он должен достаточно точно представлять размер этой таблицы, поскольку встроенные в СУБД Oracle алгоритмы хэширования используют этот размер для вычисления позиции строки на физической странице базы данных. Неверное определение размера таблицы может привести к большому числу коллизий, т.е. к попаданию строк с различными значениями ключа на одну и ту же страницу, что приводит к поддержке цепочек переполнения и дополнительному вводу/выводу.
Пример. Рассмотрим ту же таблицу Sales, что и в предыдущем примере, и ту же схему (рис. 11.2) табличных пространств. Однако используем в качестве ключа секционирования идентификацию клиента. Отметим, что распределение значений этой колонки может быть очень неравномерно. Фрагмент кода SQL для создания хэш-секционированной таблицы Sales можно написать так:
CREATE TABLE Sales ( s_customer_id number(6), s_amt number(9,2), s_date date) PARTITION BY HASH (s_customer_id) (PARTITION q01 TABLESPACE ts_01, PARTITION q02 TABLESPACE ts_02, PARTITION q03 TABLESPACE ts_03, PARTITION q04 TABLESPACE ts_04 );
Предложение PARTITION BY HASH (s_customer_id) указывает СУБД Oracle выполнить секционирование таблицы по ключу секционирования - s_customer_id. Предложения вида (PARTITION q01 TABLESPACE ts_01 определяют имя секции st_q01 и ее размещение в соответствующем табличном пространстве ts_01.
Индекс со структурой B-Tree
Индекс на основе сбалансированной иерархической структуры, или индекс B-Tree (Balanced Tree structured object), используется как индекс по умолчанию в СУБД Oracle. Эта структура напоминает дерево (если смотреть снизу вверх), в котором сначала считывается самый верхний блок - корневой узел (root), затем блок на следующем уровне - блок-ветвь (branch) и так до тех пор, пока не будет извлечен блок-лист (leaf) с идентификатором строки. Значения ключа сохраняются в индексе (рис. 11.1). Такая структура позволяет сократить до минимума число операций ввода/вывода. Для получения идентификатора строки обычно требуется одно посещение блок-листа, т.е. физической страницы базы данных, отведенной под индекс.
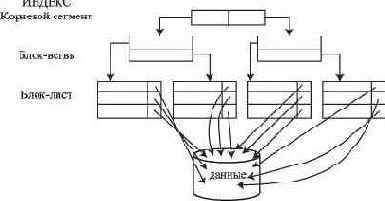
Рис. 11.1. Концептуальная организация B-Tree индекса
Замечание. Следует отметить два случая, когда после выборки идентификатора строки из индекса может понадобиться несколько посещений физической страницы индекса: 1) когда строка имеет длину более одной физической страницы, так называемая расщепленная строка; 2) когда строка за время своего существования в базе данных увеличилась и была перемещена из исходной страницы в другую, так называемая мигрировавшая строка.
Индекс B-Tree характеризуется количеством уровней в индексе (height). Чем меньше уровней, тем выше производительность.
Индекс B-Tree - это физический объект реляционной базы данных, организованный по принципу сбалансированной иерархической структуры и обладающий набором свойств. Сформулируем некоторые свойства индексов со структурой B-Tree.
Количество операций ввода/вывода, необходимых для получения идентификатора строки, зависит от числа уровней ветвления дерева. По мере увеличения индекса в результате добавление новых данных, СУБД добавляет в него новые уровни, чтобы обеспечить сбалансированность дерева. Однако в действительности таких уровней редко бывает более четырех.Корневой узел и узлы - ветви индекса сжимаются и поэтому содержат ровно столько начальных байтов значения ключа, сколько нужно для того, чтобы отличить его от других значений.
Узлы-листья содержат полное значение ключа.Значения в индексе упорядочиваются по ключевому значению, а физические страницы индекса организуются в двунаправленный список. Это обеспечивает последовательный доступ к индексу и позволяет использовать индекс для выполнения операции ORDER BY в запросе.Индекс можно использовать для поиска и точного соответствия, и для диапазона значений.Индексы могут быть построены для нескольких колонок таблицы (так называемый составной индекс). СУБД использует составные индексы для выполнения тех запросов, в которых задана лидирующая часть составного ключа. Например, составной индекс {Ename, Job} для обработки запроса SELECT * FROM EMPLOYEE WHERE Job='Инженер'; применяться не будет.СУБД обычно само принимает решение, использовать индекс или нет.Значения колонок NULL не индексируются. Если для таких колонок строится индекс, то СУБД будет отказываться примерять его в некоторых операциях, например ORDER BY.
Индексы создаются командой SQL CREATE INDEX. В предыдущих лекциях мы уже создавали индексы на основе B-Tree. При создании индекса опционально можно задать ряд параметров. Для получения полного списка параметров следует обратиться к документации по СУБД. Применение некоторых параметров будет показано в следующих разделах.
Пример. В нашей учебной базе создадим для таблицы EMPLOYEE составной индекс по колонкам Ename и Job. При этом проектировщик базы данных не уверен, что этот индекс будет использоваться эффективно, поэтому он задал опцию для сбора статистики для этого индекса.
CREATE INDEX emp_ndx2 ON EMPLOYEE (Ename, Job) COMPUTE STATISTICS;
В этом подразделе мы рассмотрели наиболее часто используемый тип индексов. В последующих подразделах и разделах мы рассмотрим другие типы индексов реляционных баз данных.
Индексирование
Индексирование (indexing) - это способ обеспечения быстрого доступа к значениям колонки или комбинации колонок. Физически новые строки добавляются в конец таблицы, результатом чего становится неупорядоченное размещение значений в колонках. Без использования каких-либо методов упорядочения данных единственным способом просмотра значения колонки со стороны СУБД является последовательный просмотр каждой строки от начала таблицы к ее концу, так называемое сканирование таблицы. Производительность такого сканирования пропорционально размеру таблицы, размеру физической страницы базы данных и длине строки. Одним из способов внесения отношения порядка в значения колонок без нарушения физического расположения строк таблицы является создание объекта реляционной СУБД - индекса (index). Индекс - это объект в реляционной базе данных, который предназначен для организации быстрого доступа к строкам таблицы по значениям одной или более колонок этих строк.
О создании индекса мы уже говорили при обсуждении ограничений первичного ключа и внешнего ключа. Тогда индексы предназначались для поддержки целостности первичного ключа и поддержки ограничения ссылочной целостности. В этом разделе пойдет речь об использовании индекса как инструмента повышения производительности обработки запросов.
Концептуально действие индекса состоит в следующем. В индексе содержится упорядоченный список значений колонки или комбинации колонок, а также сведения о местонахождении на жестком диске соответствующих этим значениям строк таблицы. Значения колонки в индексе упорядочены. Несмотря на то, что порядок строк в таблице случаен, индекс можно быстро просмотреть, чтобы найти конкретное значение. Упорядоченный индекс можно просмотреть во много раз быстрее, чем неупорядоченную таблицу. Чем выше степень различия значений ключа в колонке, тем быстрее будет выполняться доступ к строкам этой таблицы.
Так при вставке новой записи в таблицу проверка уникальности первичного ключа реализуется не реальным просмотром индекса, а тем, что требование уникальности предъявляется к значениям колонки первичного ключа в индексе.
Таким образом, индекс - это объект базы данных, который может существенно сократить время поиска нужных строк в таблице.
Замечание. После того как вы создали индекс, оптимизатор СУБД, о котором пойдет речь в последней лекции, будет использовать его всякий раз, когда это ускоряет считывание данных. Обратите внимание на то, что созданный вами индекс может ни разу не использоваться!
Индексы, несомненно, занимают место в базе данных. При вводе новых данных или удалении данных СУБД приходится обновлять и таблицы, и индексы. Это может замедлить выполнение операций модификации данных, особенно для таблиц с большим числом строк. Таким образом, может возникнуть проблема, суть которой состоит в возникновении конфликта между скоростью обновления данных в таблице и скоростью ее считываний. При разрешении этой проблемы следует придерживаться следующего эмпирического правила: создавайте индексы для колонок первичных ключей и других колонок, часто используемых в тех запросах, в которых для выборки данных применяются логические критерии. Если в результате скорость обновления данных ухудшается, то можно рассмотреть вопрос об удалении некоторых индексов.
Каждая таблица базы данных может иметь один или несколько индексов. Индексы могут создаваться по одной колонке или нескольким колонкам таблицы. Колонки, входящие в индекс, принято называть ключевыми полями (key fields) или ключами. Индексы могут быть уникальными и неуникальными. Неуникальный индекс может иметь несколько ключей с одинаковыми значениями.
В СУБД Oracle и SQLBase каждая строка таблицы обладает уникальным идентификатором ROWID - идентификатором строки, который представляет собой псевдоколонку с информацией о точном расположении строки в базе данных и содержит еще некоторую идентифицирующую информацию (идентификатор объекта базы данных, файла данных, блока и строки). Идентификатор строки хранится в индексе вместе со значениями ключевых полей.
Зачем создавать индекс для колонки или группы колонок? Это важный вопрос, и мы на него можем ответить следующим образом:
чтобы ускорить поиск в таблицах ( об этом мы только что говорили выше);чтобы обеспечить уникальное значение в колонках (это мы обсуждали в разделе об ограничениях);чтобы извлекать строки в заданном порядке на основании значений индексированных колонок (эта мысль оправдана только для очень больших таблиц, когда использование предложения ORDER дает ухудшение производительности).
На этапе физического проектирования реляционной базы данных проектировщику необходимо принять ряд важных решений о том, что и как индексировать. В данном случае важно четко сформулировать правила индексирования. Для чего нужны правила индексирования? Для каждого ИТ-проекта с базами данных проектировщику необходимо создать и оформить в письменном виде правила индексирования, как часть общих правил обеспечения производительности. Поддержка и сопровождение индексов в процессе эксплуатации базы данных является в основном задачей администратора базы данных. Решая задачи обеспечения производительности базы данных, администратор базы данных будет ставить вопрос о перепроектировании физической структуры базы данных (обратные задачи проектирования), в том числе и вопрос об удалении и создании новых индексов. Он может решать эти задачи самостоятельно. Тем более важно знать, по каким правилам и из каких соображений создавались индексы того или иного типа. Разработка таких правил значительно повысит качество эксплу атации базы данных с точки зрения обеспечения ее производительности.
Чтобы решать эти задачи, проектировщик базы данных должен знать, как работает индекс, какие типы индексов поддерживает СУБД, а также понимать смысл методов индексирования.
Сначала мы опишем типы индексов вместе с методами индексирования для каждого типа, затем разберем вопрос о том, как работает индекс, и в заключение дадим некоторые рекомендации по созданию и использованию индексов.
Исключительно индексные таблицы
Индексы могут создаваться на основе значений одной или нескольких колонок. Если требования к данным в запросе удовлетворяются на основе информации из связанного с этими данными индекса, то доступ к базовой таблице не осуществляется. Это обстоятельство привело к идее создания исключительно индексной таблицы (index-organized table). Исключительно индексная таблица является индексом типа B-Tree базы данных, который одновременно исполняет роль таблицы. Все данные такой таблицы хранятся в индексе. Преимуществом создания полностью индексированных таблиц состоит в экономии места хранения на диске и сокращения объема ввода/вывода, поскольку ключевые колонки нет необходимости сохранять еще раз в таблице. Результат выполнения запроса будет получен на основе данных, сохраненных в индексной таблице. Исключительно индексная таблица создается с помощью команды SQL CREATE TABLE, как показано в примере ниже.
Пример. Предположим, что в нашей учебной базе требуется в отдельной таблице сохранять и отслеживать проблемы, возникающие по выполнении всех проектов, и частоту возникновения проблемы. Создадим исключительно индексную таблицу для этой таблицы, как показано ниже:
CREATE TABLE Proj_Index ( projno char(8) NOT NULL, t_person char(32) NOT NULL, t_frequency integer, t_problem varchar2(512), CONSTRAINT pk_ndx PRIMARY KEY( projno, t_person) ) ORGANIZATION INDEX TABLESPACE ts_ndx1 PCTTHRESHOLD 20 INCLUDING t_frequency OVERFLOW TABLESPACE ts__of_ndx1;
Команда CREATE TABLE не отличается ничем от других команд создания таблиц до тех пор, пока не встретится предложение ORGANIZATION INDEX, которое указывает СУБД на создание исключительно индексной таблицы. Для размещения индекса на диске указывается табличное пространство. Параметр PCTTHRESHOLD указывает, что оставшуюся часть строки нужно сохранять в заданном табличном пространстве - сегменте переполнения, если данная строка превышает размер физической страницы базы данных на указанное число процентов. Параметр INCLUDING определяет имя колонки, с которой строка индексной таблицы делится на две части: индексную и переполнения. Эта колонка может быть частью первичного ключа таблицы или неключевой колонкой. Все неключевые колонки, которые следуют за указанной колонкой, размещаются в сегменте переполнения, который определяется ключевым словом OVERFLOW.
О некоторых параметрах проектирования индексов
Когда проектировщик базы данных приступает к проектированию индексов, то он должен иметь некоторый способ оценки качества создаваемого индекса. Введем несколько понятий, с помощью которых проектировщик может грубо оценить качество потенциального индекса.
Кардинальностью колонки (cardinality) таблицы называется число дискретных различных значений колонки, которые встречаются в строках таблицы. Например, если в таблице EMPLOYEE мы заводим колонку для указания пола - SEX, то кардинальность этой колонки есть 2, так как в природе у людей существует только два пола - мужской и женский. Для колонки первичного ключа кардинальность будет равна числу строк в таблице.
Причиной, по которой кардинальность колонки важна для проектирования индексов, состоит в том, что кардинальность индексируемой колонки определяет число уникальных входов, которые должны сохраняться в индексе, т.е. число записей в индексе. Так, для индексируемой колонки SEX будет существовать два уникальных входа, которые будут повторяться много раз в индексе. При предположении равновероятного распределения пола сотрудников на 100000 строк в таблице EMPLOYEE каждый вход индекса будет повторяться 50000 раз. СУБД вряд ли будут принимать решение об использовании такого индекса при построении плана запроса.
Определить кардинальность потенциальной колонки индексирования в существующей базе данных достаточно просто:
SELECT COUNT (DISTINCT колонка) FROM таблица
При проектировании новой базы данных проектировщик должен оценить кардинальность всех потенциальных индексируемых колонок во всех таблицах базы данных, исходя из имеющейся документации.
Способ, с помощью которого СУБД оценивает действие кардинальности, состоит в использовании фактора селективности выборки (selectivity factor). Фактора селективности выборки индекса определяется как величина, обратная кардинальности индексной колонки:

Фактор селективности оценивает потенциальный объем операций ввода/вывода. Чем меньше фактор селективности, тем меньше требуется операций ввода/вывода для получения результирующего множества строк таблицы.
СУБД оценивает эту величину, чтобы решить, использовать индекс для доступа к строкам таблицы или нет. Какие формулы используются для оценки фактора селективности в СУБД, мы рассмотрим в последней лекции этого курса.
В заключение раздела мы приведем список правил для определения колонок, которые являются хорошими и плохими кандидатами для индексирования. Эти правила могут быть использованы проектировщиком базы данных при принятии решения о построении индексов реляционной базы данных.
Хорошими кандидатами для индексирования обычно являются:
колонки первичного ключа. По определению, колонки первичного ключа должны иметь уникальный индекс;колонки внешнего ключа. Они дают хороший индекс по двум причинам. Во-первых, они часто применяются для выполнения соединений с родительскими таблицами. Во-вторых, они могут быть использованы СУБД при поддержке ссылочной целостности в операциях удаления строк родительской и дочерних таблиц;любые колонки, которые содержат уникальные значения;колонки, запросы или соединения по которым захватывают от 5 до 10% строк таблицы;колонки, которые часто входят как аргументы в функции агрегирования;колонки, которые часто используются для проверки правильности ввода данных в программах ввода/редактирования.
Факторы, влияющие на низкую эффективность индексов:
Таблицы маленького размера. Одним из общих эмпирических правил является правило "не создавать индексы для таблиц размером менее пяти физических страниц". Для таких страниц стоимость поддержки индекса больше, чем стоимость сканирования всей таблицы. Конечно, уникальный индекс требуется для первичного ключа и поддержки ссылочной целостности.Интенсивные обновления таблиц в пакетном режиме. Такие таблицы обычно имеют проблемы с переполнением индекса при интенсивной модификации таблицы. Если индекс необходим для такой таблицы, то целесообразнее его удалять перед обновлением и создавать после него.Асимметрия значений ключей (Skewness of keys). Если распределение значений ключа имеет значительную асимметрию, то кардинальность индекса может оказаться достаточно высокой и СУБД из-за низкого фактора селективности будет часто использовать этот индекс.
СУБД оценивает эту величину, чтобы решить, использовать индекс для доступа к строкам таблицы или нет. Какие формулы используются для оценки фактора селективности в СУБД, мы рассмотрим в последней лекции этого курса.
В заключение раздела мы приведем список правил для определения колонок, которые являются хорошими и плохими кандидатами для индексирования. Эти правила могут быть использованы проектировщиком базы данных при принятии решения о построении индексов реляционной базы данных.
Хорошими кандидатами для индексирования обычно являются:
колонки первичного ключа. По определению, колонки первичного ключа должны иметь уникальный индекс;колонки внешнего ключа. Они дают хороший индекс по двум причинам. Во-первых, они часто применяются для выполнения соединений с родительскими таблицами. Во-вторых, они могут быть использованы СУБД при поддержке ссылочной целостности в операциях удаления строк родительской и дочерних таблиц;любые колонки, которые содержат уникальные значения;колонки, запросы или соединения по которым захватывают от 5 до 10% строк таблицы;колонки, которые часто входят как аргументы в функции агрегирования;колонки, которые часто используются для проверки правильности ввода данных в программах ввода/редактирования.
Факторы, влияющие на низкую эффективность индексов:
Таблицы маленького размера. Одним из общих эмпирических правил является правило "не создавать индексы для таблиц размером менее пяти физических страниц". Для таких страниц стоимость поддержки индекса больше, чем стоимость сканирования всей таблицы. Конечно, уникальный индекс требуется для первичного ключа и поддержки ссылочной целостности.Интенсивные обновления таблиц в пакетном режиме. Такие таблицы обычно имеют проблемы с переполнением индекса при интенсивной модификации таблицы. Если индекс необходим для такой таблицы, то целесообразнее его удалять перед обновлением и создавать после него.Асимметрия значений ключей (Skewness of keys). Если распределение значений ключа имеет значительную асимметрию, то кардинальность индекса может оказаться достаточно высокой и СУБД из-за низкого фактора селективности будет часто использовать этот индекс.
Параметры индексирования
СУБД Oracle предусмотрено еще несколько параметров индексирования, которые позволяют улучшить традиционные для всех СУБД индексы со структурой B-Tree. К таким модификациям, помимо исключительно индексных таблиц, относятся битовые индексы, индексы с обращением ключа, индексы на основе значения функций.
Каждый бит так называемого битового (bitmap) индекса относится к идентификатору строки ROWID в табличном объекте. Если некоторая строка содержит данное ключевое значение, то в индексе для этого значения сохраняется единица. Такая организация индекса может в некоторых случаях значительно повысить производительность выборки данных, т.к. для извлечения строк с определенным значением индекса СУБД нужно лишь найти все единицы, отвечающие ключу. Физически такой индекс организован на основе структуры B-Tree, но задача сводится к поиску данной строки за счет одной операции чтения битовой индексной структуры. Этот тип индекса очень эффективен для индексирования колонок с небольшим кардинальным числом - пол, цвет и т.д. Если значений у колонки буде много, то объем ввода/вывода будет возрастать.
Пример. Для нашей учебной базы данных можно построить битовый индекс для таблицы EMPLOYEE по колонке DEPNO, как показано ниже:
CREATE BITMAP INDEX emp_ndx ON EMPLOYEE (DEPNO);
В индексе с обращением ключа (reverse-key index) применяется обращение байтов индексируемой колонки числового типа. Этот прием позволяет получать равномерное распределение значений колонок среди блок-листов индекса со структурой B-Tree. Этот индекс хорошо подходит для индексирования колонок с последовательной нумерацией или нумерацией с заданным шагом. Заметим, что такие индексы применяются только для возвращения отдельных строк, и с их помощью нельзя выполнить поиск значений в некотором диапазоне. Вы не можете применить опцию REVERSE к битовым индексам и исключительно индексным таблицам.
Пример. В нашей учебной базе данных числовые ключи, содержащие последовательные числа, есть, в частности, в таблице PLOYEE - EMPNO.
Мы можем определить для этой таблиц дополнительный индекс с обращением ключа для извлечения записи о сотруднике. Заметим, что для этой колонки уже есть индекс первичного ключа.
CREATE INDEX dep_ndx ON EMPLOYEE (EMPNO) REVERSE;
В процессе эксплуатации администратор базы данных может перестроить этот индекс с помощью команды ALTER INDEX, как показано ниже
ALTER INDEX EMPLOYEE REBUILD NOREVERSE;
Если в предложении WHERE используется функция по индексированной колонке, то обычно СУБД не применяют этот индекс при организации доступа к строкам таблицы. Но при создании индекса на основе значения функции (function-based index), которая является той же функцией, что и в предложении WHERE, то СУБД использует такой индекс для считывания строк, удовлетворяющих критерию отбора. Индексы на основе значений функции могут быть битовыми индексами.
Пример. Обратимся к нашей учебной базе. Предположим, что при поиске сотрудников по фамилии таковая вводится на верхнем регистре, как в примере ниже:
SELECT * FROM EMPLOYEE WHERE UPPER(:ENAME) ORDER BY UPPER(:ENAME);
Тогда, даже при наличии индекса по колонке ENAME, СУБД будет сканировать таблицу, не обращаясь к этому индексу. Проектировщик базы данных, учитывая, что частота таких транзакций будет очень высокой, может предусмотреть создание индекса на основе значений функции от колонки EMANE, как показано ниже:
CREATE INDEX emp_ndx_e ON EMPLOYEE UPPER(:ENAME);
При наличии в базе данных такого индекса СУБД Oracle будет его использовать при обработке вышеприведенного запроса.
Повышение производительности запросов: Кластеры
Самой медленной операцией, выполняемой СУБД, является операция чтения данных с диска или запись данных на диск. Если существует возможность уменьшить в несколько раз число таких операций, то общая производительность базы данных может заметно увеличиться.
Следует помнить, что СУБД считывает с диска или записывает на диск за один раз одну физическую страницу данных, размер которой колеблется в зависимости от аппаратной платформы от 512 байт до 4 Кб. Таким образом, если можно физически хранить данные, к которым часто происходит совместное обращение, на одной и той же странице диска или на страницах, физически близко расположенных друг к другу, то скорость доступа к этим данным повышается.
Кластеризация (Clustering) - это способ физического размещения рядом, на одной физической странице данных, строк, доступ к которым осуществляется при помощи одинакового значения колонки (ключа) с целью увеличения производительности. Такой ключ называется кластерным ключом. Значением кластерного ключа являются значения одинаковых по смыслу колонок строк кластеризуемых таблиц. Ключ может быть либо хэш-ключом, либо индексным ключом. Если ключ является хэш-ключом, то физическое размещение определяется функцией преобразования ключа (хэширования) и мы имеем дело с уже известной нам из предыдущих разделов таблицей хэширования или хэш-кластером. Если это индексный ключ, то для идентификации страницы данных в кластере используется индекс со структурой B-Tree, в котором сроки, имеющие одинаковые значения ключа, размещаются либо в одной странице, либо в смежных стран ицах индекса. Такой кластер называется индексным кластером. Строки, которые хранятся в индексном кластере, не обязательно должны принадлежать одной таблице. Таким образом, кластеры являются одним из методов хранения таблиц данных, поддерживаемых СУБД. Кластер - это группа таблиц, которая разделяет общие физические страницы данных при совместном использовании в запросах общих колонок этих таблиц.
На практике индексный кластер создается для совместного хранения строк, связанных ограничением внешнего и первичного ключей.
Совместное хранение строк родительской и дочерней таблиц может значительно ускорить выполнение соединения этих таблиц.
Пример. Рассмотрим таблицы DEPARTAMENT и EMPLOYEE нашей учебной базы данных. Они некластеризованы и хранятся каждая на своих физических страницах. Предположим, что анализ запросов показывает, что в 80% запросов эти таблицы используются совместно, при этом соединение выполняется по колонке DEPNO. Проектировщик базы данных может решить построить кластер для этих двух таблиц. На рисунке ниже показана концептуальная сторона такого решения.
До кластеризации строки из таблиц сохраняются отдельно в своих физических областях на диске.
| DEPARTMENT | |||
| DEPNO | DNAME | LOC | … |
| 10 | Торговля | Москва | |
| 20 | Консалтинг | Черноголовка | |
| EMPLOYEE | |||
| EMPNO | ENAME | LNAME | DEPNO |
| 996 | Козырев | Сергей | 10 |
| 997 | Сапегин | Алексей | 20 |
| CLUSTER | ||||
| DEPNO | ||||
| 10 | DNAME | LOC | … | |
| Торговля | Москва | … | ||
| … | … | … | ||
| EMPNO | ENAME | LNAME | … | |
| 996 | Козырев | Сергей | … | |
| … | … | … | ||
| 20 | DNAME | LOC | … | |
| Консалтинг | Черноголовка | … | ||
| EMPNO | ENAME | LNAME | … | |
| 997 | Сапегин | Алексей | … | |
| … | … | … | … | |
Кластеризация может существенно ускорить работу с соединениями. Однако, планируя использование кластеров, проектировщик базы данных должен учитывать следующие факторы:
кластеризация затрагивает физическое размещение данных в файлах базы данных. Поэтому рекомендуется выполнить кластеризацию таблицы только по одной колонке или комбинации колонок;кластеризация замедляет выполнение операций, в которых нужно просканировать всю таблицу, так как она может вызвать разброс строк одной таблицы по множеству физических страниц;кластеризация может замедлить ввод данных;кластеризация может замедлить модификацию данных в тех колонках, которые помещены в кластер.
В силу вышеперечисленных обстоятельств кластеры не рекомендуется создавать для таблиц с интенсивным обновлением данных. Для того чтобы таблица была хорошим кандидатом для ее кластеризации, должны выполняться по крайней мере следующие условия:
Значения колонок кластерных ключей распределены равномерно и плотно, а их размер почти всегда меньше размера физической страницы (иначе будут образовываться кластерные цепочки).В случае индексного кластера на каждый кластерный ключ приходится больше одной выбираемой строки, а для хэш-кластера - одна строка. Альтернативное решение - индексация таблицы.Все данные для заданного кластерного ключа выбираются при каждом доступе по кластерному ключу. Альтернативное решение - индексация таблицы.Интенсивность обращений операций вставки, обновления и удаления не очень велика, иначе общая производительность базы данных может уменьшиться. Обратный отрицательный эффект.
В силу вышеперечисленных обстоятельств кластеры не рекомендуется создавать для таблиц с интенсивным обновлением данных. Для того чтобы таблица была хорошим кандидатом для ее кластеризации, должны выполняться по крайней мере следующие условия:
Значения колонок кластерных ключей распределены равномерно и плотно, а их размер почти всегда меньше размера физической страницы (иначе будут образовываться кластерные цепочки).В случае индексного кластера на каждый кластерный ключ приходится больше одной выбираемой строки, а для хэш-кластера - одна строка. Альтернативное решение - индексация таблицы.Все данные для заданного кластерного ключа выбираются при каждом доступе по кластерному ключу. Альтернативное решение - индексация таблицы.Интенсивность обращений операций вставки, обновления и удаления не очень велика, иначе общая производительность базы данных может уменьшиться. Обратный отрицательный эффект.
Из этого следует, что существуют две основные причины использования кластеров: это необходимость а) обеспечить прямой доступ к строке за одну операцию чтения; и б) сократить число операций ввода/вывода при доступе к часто совместно используемым данным путем размещения их в близко расположенных физических страницах базы данных.
С физической точки зрения кластер находится отдельно от таблиц. Он создается с указанием параметров хранения, а затем в нем последовательно создаются кластеризованные таблицы. При описании кластера нужно указать колонки или колонку, для которых СУБД сформирует кластер, и таблицы, которые будут включены в его состав. При обработке данных СУБД будет размещать строки, содержащие одинаковые значения в колонках кластера, физически максимально близко. В результате строки таблицы могут быть распределены среди нескольких дисковых страниц, но первичные и внешние ключи обычно располагаются на одной странице.
Пример. Вернемся к нашей учебной базе данных и напишем фрагмент скрипта для создания кластера для таблиц DEPARTAMENT и EMPLOYEE. Для создания кластеров используется команда SQL CREATE CLUSTER, которая в нашем случае будет иметь вид
Хэш- кластер является альтернативной техникой создания таблиц данных по отношению к индексному кластеру или некластеризованной таблице.
Пример. Рассмотрим нашу учебную базу данных с целью создания хэш-кластера для таблицы EMPLOYEE. На рис. 11.3 ниже показано, как будет выполняться доступ к записям таблицы до и после кластеризации.
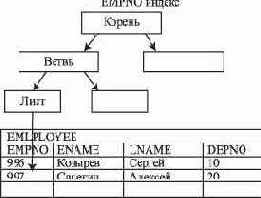
Рис. 11.3. Доступк строке таблицы EMPLOYEE через индекс по колонке EPMNO
SELECT * FROM EMPLOYEE WHERE EMPNO= 997;
До кластеризации по колонке EPMNO доступ будет выполняться через индекс, и согласно рисунку 11.3 потребуется 4 операции ввода/вывода, чтобы получить результирующую строку.
После кластеризации по колонке EPMNO строки таблицы EMPLOYEE будут сохраняться в структуре, которая условно приведена на рисунке ниже. После хэширования ключа потребуется одна операция ввода/вывода, чтобы получить результирующую строку, если нет цепочек переполнения.
| CLUSTER | ||||
| Хэш-ключ | Кластерный ключ | |||
| 110 | EMPNO | ENAME | LNAME | … |
| 996 | Козырев | Сергей | … | |
| … | … | … | ||
| 120 | EMPNO | ENAME | LNAME | … |
| 997 | Сапегин | Алексей | … | |
Пример. Создадим хэш-кластер для таблицы EMPLOYEE нашей учебной базы данных. Фрагмент скрипта приведен ниже.
CREATE CLUSTER PERSONNEL (EMPNO integer) SIZE 512 HASHKEYS 500 -- STORAGE (INITIAL 100K NEXT 50K PCTINCREASE 10) ;
Число уникальных значений хэш-ключа задается параметром HASHKEYS, после достижения этого значения в таблицы будут возникать коллизии - ситуации, когда разные хэшированные ключи должны будут размещаться в одном блоке. Это приводит к созданию при вставке строк так называемых цепочек переполнения, из-за которых увеличивается число доступов при выборке результирующей строки.
Параметр SIZE определяет максимальное число хэш-ключей, размещаемое на физической странице базы данных. Он равен оценке общего пространства в байтах, требуемого для сохранения среднего числа строк, связанного с каждым значением хэш-ключа. Если доступного пространства на странице - 1600 байт, а значение параметра - 512 байт, то три значения хэш-ключа будут распределяться на физической странице.
С помощью предложения HASH IS вы можете переопределить хэш-функцию, которую СУБД Oracle использует по умолчанию.
Пример. Если у нас есть хэш-кластер для таблицы EMPLOYEE и кластерный ключ определен как код домашнего адреса сотрудника, то вероятно, что будет случаться много коллизий в хэш-кластере, если городок, где живут сотрудники, невелик. Для того чтобы избежать такой коллизии, можно переопределить встроенную хэш-функцию Oracle в команде CREATE CLUSTER, добавив предложение HASH IS, как показано ниже.
CREATE CLUSTER personnel (home_area_code number, home_prefix number ) HASHKEYS 20 HASH IS MOD(home_area_code + home_suffix_tel, 101);
В примере добавлено некоторое число к коду домашнего адреса, чтобы изменить распределение значений хэш-ключа с целью избежать коллизий. В качестве такого числа взяты две последние цифры домашнего телефона.
В заключение отметим следующее. Несмотря на то, что СУБД Oracle, так же как и СУБД SQLBase, интенсивно использует кластеры для доступа к системным таблицам базы данных, автор настоящего курса рекомендует проектировщикам базы данных проявлять осторожность при принятии решения о кластеризации таблиц при создании новой базы данных. Выигрыш в производительности может быть не слишком высок по сравнению с другими проектными решениями. Проектирование кластеров - штучная работа. Очень полезно знать статистику использования аналогичного кластера при эксплуатации аналогичной базы данных, чтобы построить высокопроизводительный кластер. Придерживайтесь следующих эмпирических правил:
До 1000 записей СУБД не имеет больших преимуществ перед последовательным файлом.От 1000 до 10000 записей это преимущество незначительно.От 10000 до 100000 записей между настольными и промышленными СУБД не ощущается разницы в производительности.От 100000 до 1000000 записей промышленные СУБД обеспечивают приемлемую производительность без специальных способов ее повышения.От 1000000 записей надо начинать думать о повышении производительности.
Литература: [7], [14], [20], [23], [45].

Секционирование
Во многих базах данных в таблицах хранится огромное количество данных. Чем больше размер таблицы, тем больше времени потребуется как для некоторых операций по выборке строк таблицы, так и для выполнения некоторых функций администратора базы данных. Например, для резервного копирования и восстановления. Большие по размеру индексированные таблицы имеют также большие индексы, которые требуют много времени СУБД для работы с ними.
Секционирование (partitioning) - это способ физического распределения таблиц и индексов среди двух или более табличных пространств в зависимости от значений ключевых колонок таблиц с целью повышения производительности операций ввода/вывода. Фрагмент таблицы, расположенный в отдельном табличном пространстве, будем называть секцией таблицы. Секционирование также повышает эффективность резервного копирования и восстановления за счет выполнения этих задач с участием меньшего объема данных. Обсуждению создания табличных пространств далее будет посвящен отдельный раздел следующей лекции. Для понимания данного материала нам достаточно знать, что это предопределенный поименованный фрагмент памяти на одном или нескольких дисках, к которому можно обращаться в предложениях SQL по имени.
В осуществлении секционирования одним из важных понятий является колонка таблицы, относительно значений которой СУБД будет делать физическое разнесение таблицы по различным табличным пространствам на жестких дисках. Эти колонка называется ключом секционирования (partition key).
В СУБД Oracle поддерживается несколько видов секционирования: секционирование по диапазону, хэш-секционирование, составное секционирование, а также различные виды секционирования индексов.
Секционирование индексов
В СУБД Oracle предусмотрено секционирование индексов (index partitioning), которое означает преднамеренное распределение индексов таблиц по назначенным табличным пространствам в соответствии с ключом секционирования. Секционирование индексов может быть глобальным и локальным. Локально секционированный индекс имеет такой же ключ секционирования, количество табличных пространств и правила секционирования, что и отвечающая ему базовая таблица. Глобально секционированный индекс содержит предложение PARTITION BY RANGE, в котором задаются параметры секционирования, отличные от параметров секционирования соответствующей базовой таблицы. Секционированные индексы могут быть префиксными или непрефиксными. В случае префиксного секционированного индекса секционирование производится по ключу секционирования, который содержит основную часть индексного ключа. В случае непрефиксных секционированных индексов ключа секционирования секционирование вып олняется по значениям, отличным от значений колонки индексирования.
Индексы могут быть секционированы и в случае, когда индексируемая таблица не секционируется. В этом случае по умолчанию предполагается, что индекс является глобальным секционированием индексов. В Oracle не предусмотрена поддержка глобальных непрефиксных секционированных индексов.
В локально секционированном индексе ключевые значения одной секции индекса соответствуют строкам таблицы из одной ее секции.
Пример. Создадим локальный секционированный индекс для таблицы Sales (рис. 11.2). Ключом секционирования этой таблицы является колонка s_date. Фрагмент кода создания индекса приведен ниже.
CREATE INDEX sales_ndx ON Sales (s_date) LOCAL (PARTITION st_i_q01 TABLESPACE ts_01, PARTITION st_i_q02 TABLESPACE ts_02, PARTITION st_i_q03 TABLESPACE ts_03, PARTITION st_i_q04 TABLESPACE ts_04 );
Локально секционированный индекс называется равносекционированным (equi-partitioned), если он имеет то же число секций и те же правила секционирования, что и его базовая таблица. Обратите внимание, что в примере при создании индекса не использовалось предложение PARTITION BY RANGE.
Oracle автоматически берет структуру секционирования для индекса из структуры секционирования базовой таблицы Sales. Также можно опустить и предложения типа PARTITION st_i_q02 TABLESPACE ts_02. Если опущено PARTITION, то Oracle автоматически создаст имена секций. Если пущено TABLESPACE, то Oracle автоматически разместит секции в тех же табличных пространствах, в которых находятся соответствующие секции базовой таблицы.
Глобально секционированный индекс имеет структуру секций, отличную от структуры секций базовой таблицы данного индекса. В качестве примера создадим глобально секционированный индекс для таблицы Sales из наших предыдущих примеров.
Пример. В качестве ключа секционирования для индекса используем колонку s_customer_id. Во фрагменте кода ниже для секций индекса используются другие индексные пространства ts_i_01, ts_i_02, ts_i_03. Число секций индекса не совпадает с числом секций базовой таблицы для этого индекса:
CREATE INDEX sales_ndx ON Sales (s_customer_id) GLOBAL PARTITION BY RANGE (s_customer_id) (PARTITION st_i_q1 VALUES LESS THAN (10000) TABLESPACE ts_i_01, PARTITION st_i_q2 VALUES LESS THAN (20000) TABLESPACE ts_i_02, PARTITION st_i_q3 VALUES LESS THAN (MAXVALUE) TABLESPACE ts_i_03, );
Локально секционированный индекс может быть создан по колонке, отличной от ключа секционирования базовой таблицы индекса. В примере ниже создается такой непрефиксный индекс для таблицы Sales.
Пример. В качестве колонки секционирования для индекса выбрана колонка s_customer_id, а для секций индекса выбраны другие табличные пространства ts_i_01, ts_i_02, ts_i_03, ts_i_04, чем для секций базовой таблицы индекса.
CREATE INDEX sales_ndx_1 ON Sales (s_customer_id) LOCAL (PARTITION st_i_q01 TABLESPACE ts_i_01, PARTITION st_i_q02 TABLESPACE ts_i_02, PARTITION st_i_q03 TABLESPACE ts_i_03, PARTITION st_i_q04 TABLESPACE ts_i_04 );
При принятии решения о секционировании индексов проектировщик базы данных должен иметь в виду следующее:
Локальное префиксное секционирование индекса является наиболее эффективным методом секционирования индекса.Поскольку строки одной секции базовой таблицы будут индексироваться в одной секции индекса, СУБД не придется сканировать все секции при выборке данных по запросу.Локальное непрефиксное секционирование индекса требует от СУБД выполнения большего объема работы, так как для поиска данных требуется сканировать все секции индекса. Этот тип следует принимать во внимание при параллельной обработке данных.Глобальное префиксное секционирование индекса является наиболее эффективным методом секционирования индекса при обработке данных, когда необходимо сканирование диапазона. Этот тип секционирования группирует строки в одной секции, и СУБД знает, в какой секции искать значения из заданного диапазона.
Секционирование по диапазону
Секционирование по диапазону (range partitioning) означает распределение строк таблицы на различные предопределенные табличные пространства в зависимости от значения ключа секционирования. Доступ к такой таблице, как и к любой другой, осуществляется по ее имени, причем доступ к секциям, расположенным в каждом табличном пространстве, можно получить отдельно. Например, таблицу, содержащую финансовые квартальные отчеты организации, можно секционировать по дате таким образом, что отчеты по каждому кварталу будут храниться в отдельном табличном пространстве. При такой организации секций данные только по одному кварталу будут выбираться из одного табличного пространства, что повысит эффективность работы базы данных в целом.
Секционирование по диапазону базируется на упорядочении строк таблицы в секциях (табличных пространствах) на основе значения колонок ключа секционирования. Концептуально таблица, секционированная по диапазону, устроена как на рис. 11.2 в примере ниже. Для создания секционированных таблиц используется команда SQL CREATE TABLE с предложением PARTITION. В СУБД Oracle ключ секционирования не может иметь тип LONG.

Рис. 11.2. Пример секционирования подиапазону
Пример. Рассмотрим систему обработки заказов. Предположим, что в ней есть таблица Sales, в которой сохраняются данных о количестве, времени и цене продаж для каждого клиента. Проектировщик базы данных может использовать секционирование по диапазону, а именно - по кварталу, для представления этой таблицы в базе данных. Предположим, что мы имеем четыре определенные ранее табличных пространства c именами ts_01, ts_02, ts_03, ts_04, распределенные по четырем дискам, как показано на рисунке ниже.
Фрагмент скрипта ниже определяет таблицу Sales с физическим размещением секций, как на рисунке выше:
CREATE TABLE Sales ( s_customer_id number(6), s_amt number(9,2), s_date date) PARTITION BY RANGE (s_date) (PARTITION st_q01 VALUES LESS THAN ('01-apr-2002') TABLESPACE ts_01, PARTITION st_q02 VALUES LESS THAN ('01-jul-2002') TABLESPACE ts_02, PARTITION st_q03 VALUES LESS THAN ('01-oct-2002') TABLESPACE ts_03, PARTITION st_q04 VALUES LESS THAN (MAXVALUE) TABLESPACE ts_04 );
Предложение PARTITION BY RANGE (s_date) указывает СУБД Oracle выполнить секционирование таблицы по ключу секционирования - s_date. Предложения вида (PARTITION st_q01 VALUES LESS THAN ('01-apr-2002') TABLESPACE ts_01 определяют имя секции st_q01 и ее размещение в соответствующем табличном пространстве ts_01.
Чтобы получить доступ к строкам таблицы, расположенным в определенной секции, узнать о продажах в третьем квартале, можно использовать команду SELECT, как показано ниже:
SELECT s_customer_id, s_amt FROM Sales PARTITION (st_q03);
Как мы можем увидеть, для этого нужно указать опцию PARTITION (имя секции) после имени таблицы в предложении FROM.
Администратор базы данных может легко удалять, добавлять, перемещать, расщеплять, усекать и изменять секции с помощью команды ALTER TABLE. Удалить отдельную секцию можно также, удалив соответствующее ей табличное пространство.
Секционирование представлений
В Oracle есть возможность секционировать представления. Основная идея секционирования представлений проста. Пусть физическая таблица разбита на несколько таблиц (необязательно с помощью методов секционирования таблиц) в соответствии с критерием разбиения, который делает обработку запроса более производительной. Критерий разбиения будем называть предикатом секционирования. Тогда мы можем создать и настроить представления таким образом, чтобы с их помощью обращение к данным этих таблиц было проще для пользователя. Секция представления определяется в соответствии с диапазоном значений ключа секционирования. Запросы, которые используют диапазон значений для выборки данных из секций представления, будут получать доступ только к тем секциям, которые соответствуют диапазонам значений ключа секционирования.
Секции представления могут быть определены предикатами секционирования, заданными либо при помощи ограничения CHECK, либо с использованием предложения WHERE. Покажем, как могут быть применены оба приема на примере несколько модифицированной таблицы Sales, которую мы рассматривали в предыдущем разделе. Допустим, что данные о продажах для календарного года размещаются в четырех отдельных таблицах, каждая из которых соответствует кварталу года - Q1_Sales, Q2_Sales, Q3_Sales и Q4_Sales.
Пример. Секционирование представлений с помощью ограничения CHECK. С помощью команды ALTER TABLE мы можем добавить ограничения на колонку s_date каждой таблицы, чтобы ее строки соответствовали одному из кварталов года. Созданное затем представление sales дает возможность обращаться к этим таблицам - как к одной, так и по отдельности:
ALTER TABLE Q1_Sales ADD CONSTRAINT C0 CHECK (s_date BETWEEN 'jan-1-2002' AND 'mar-31-2002'); ALTER TABLE Q2_Sales ADD CONSTRAINT C1 CHECK (s_date BETWEEN 'apr 1-2002' AND 'jun-30-2002'); ALTER TABLE Q3_Sales ADD CONSTRAINT C2 check (s_date BETWEEN 'jul-1-2002' AND 'sep-30-2002'); ALTER TABLE Q4_Sales ADD CONSTRAINT C3 check (s_date BETWEEN 'oct-1-2002' AND 'dec-31-2002');
CREATE VIEW sales_v AS SELECT * FROM Q1_Sales UNION ALL SELECT * FROM Q2_Sales UNION ALL SELECT * FROM Q3_Sales UNION ALL SELECT * FROM Q4_Sales;
Преимуществом такого секционирования представлений является то, что предикат ограничения CHECK не оценивается для каждой строки запроса. Такие предикаты исключают вставку в таблицы строк, не соответствующих критерию предиката. Строки, соответствующие предикату секционирования, извлекаются из базы данных быстрее.
Пример. Секционирование представлений с помощью предложения WHERE. Создадим представление для тех же таблиц, что и в примере выше:
CREATE VIEW sales_v AS SELECT * FROM Q1_Sales WHERE s_date BETWEEN 'jan-1-2002' AND 'mar-31-2002' UNION ALL SELECT * FROM Q2_Sales WHERE s_date BETWEEN 'apr-1-2002' AND 'jun-30-2002' UNION ALL SELECT * FROM Q3_Sales WHERE s_date BETWEEN 'jul-1-2002' AND 'sep-30-2002' UNION ALL SELECT * FROM Q4_Sales WHERE s_date BETWEEN 'oct-1-2002' AND 'dec-31-2002';
Второй метод имеет некоторые недостатки. Во-первых, критерий секционирования проверяется во время выполнения для всех строк во всех секциях, которые охватываются запросом. Во-вторых, пользователи могут ошибочно вставить строку не в ту секцию, т.е. вставить запись, относящуюся к первому кварталу, в третий квартал, что приведет к неправильной выборке данных для этих кварталов.
У этого приема есть и достоинство по сравнению с использованием ограничения CHECK. Вы можете разместить секцию, соответствующую предикату WHERE, на удаленной базе данных. Фрагмент определения преставления приведен ниже:
SELECT * FROM east_sales@icp.ac.ru WHERE LOC = 'EAST' UNION ALL SELECT * FROM west_sales@ioc.ac.ru WHERE LOC = 'WEST';
Проектировщик базы данных при принятии решения о создании секционированных представлений должен принимать во внимание следующие факторы:
Секционирование представлений позволяет операциям DML, таким, как загрузка данных, создание индексов и удаление данных, работать на уровне секции, а не целой базовой таблицы.Доступ к одной из секций не оказывает никакого действия на данные в других секцияхСУБД Oracle облагает необходимыми встроенными возможностями для распознавания секционированных представлений.Секционирование представлений очень полезно при работе с таблицами, содержащими большое количество исторических данных.
В этом разделе мы рассмотрели некоторые приемы увеличения производительности обработки транзакций, основанные на секционировании объектов реляционной базы данных - базовых таблиц, индексов базовых таблиц и представлений. Основная задача секционирования: с помощью встроенных команд СУБД разбить таблицы большого объема на ряд физических фрагментов в соответствии с некоторым критерием секционирования, чтобы сократить объем ввода/вывода при обработке фрагментов. Секционирование очень часто используется при работе с таблицами большого объема. Проектировщику базы данных, если он определил наличие в проектируемой базе данных сохраняемых объектов большого объема (более 1 Гб), обязательно следует рассмотреть возможность использования техники секционирования.
Составное секционирование
Составное секционирование (composite partitioning) является комбинацией секционирования по диапазону и хэш-секционирования. Это означает, что таблица сначала распределяется среди табличных пространств на основе диапазона значений ключа секционирования, далее каждая из полученных секций диапазонов делится на подчиненные секции или подсекции, и затем строки равномерно распределяются среди подчиненных секций по значению хэш-ключа.
Пример. Рассмотрим ту же, что и в предыдущем примере таблицу Sales и ту же схему (рис. 11.2) табличных пространств. В качестве ключа секционирования по диапазону используем дату продажи. В качестве ключа хэш-секционирования -идентификацию клиента. Однако теперь каждая секция по диапазону будет разделена на предопределенное число подсекций. Фрагмент кода SQL для создания таблицы Sales с составным секционированием можно написать так:
CREATE TABLE Sales ( s_customer_id number(6), s_amt number(9,2), s_date date) PARTITION BY RANGE (s_date) SUB PARTITION BY HASH (s_customer_id) SUB PARTITION 4 STORE IN (ts_01, ts_02, ts_03, ts_04) (PARTITION q01 VALUES LESS THAN ('01-apr-2002'), PARTITION q02 VALUES LESS THAN ('01-jul-2002'), PARTITION q03 VALUES LESS THAN ('01-oct-2002'), PARTITION q04 VALUES LESS THAN (MAXVALUE) );
Секции q01, q02, q03, q04 будут содержать строки с диапазоном дат, которые определены в предложениях типа PARTITION q02 VALUES LESS THAN ('01-jul-2002') и будут распределены в табличных пространствах ts_01, ts_02, ts_03, ts_04. Предложение SUB PARTITION 4 предписывает СУБД Oracle разбиение каждой секции на четыре логические единицы, а предложение SUB PARTITION BY HASH (s_customer_id) распределяет строки заданного диапазона среди этих четырех подчиненных секций.
