Циклы зависимых таблиц
Использование ограничений ссылочной целостности может порождать так называемые ссылочные циклы. Для пояснения этого понятия обратимся к учебной базе данных. Таблица EMPLOYEE содержит колонку DEPNO (внешний ключ, содержащий ссылку на таблицу DEPARTAMENT). Если добавить в таблицу EMPLOYEE колонку MNGR, которая определяет руководителя каждого служащего, а в таблицу DEPARTAMENT - колонку с номером руководителя MRGNO, то мы получим пример ссылочного цикла (при определении ссылочной целостности по этим атрибутам).
Такой вид циклической связи порождает проблемы для операций манипулирования данными. Допустим, что на работу принят служащий, который должен руководить вновь созданным отделом 100. Последовательное выполнение операторов INSERT будет неуспешным (строка в дочерней таблице EMPLOYEE ссылается на отдел, которого еще нет, и такого менеджера еще не существует).
INSERT INTO EMPLOYEE (EMPNO,ENAME,LNAME,DEPNO, JOB,AGE,HIREDATE,SAL,COMM,FINE,MNGR) VALUES(4000,"Анисимов","Виктор",100,"Менеджер",,2500000,,,NULL);
INSERT INTO DEPARTAMENT (DEPNO, DNAME, LOC, MANAGER, MRGNO,PHONE) VALUES (100,'Маркетинг','Москва', 'Анисимов', 4000,1352519);
Операция добавления в базу данных записей, связанных с организацией нового отдела и прихода его руководителя, при поддержке ссылочной целостности в случае ссылочного цикла будет следующей:
INSERT INTO EMPLOYEE (EMPNO,ENAME,LNAME,DEPNO, JOB,AGE,HIREDATE,SAL,COMM,FINE,MNGR) VALUES(4000, "Анисимов","Виктор",NULL, "Менеджер",,2500000,,,NULL);
INSERT INTO DEPARTAMENT (DEPNO, DNAME, LOC, MANAGER, MRGNO,PHONE) VALUES (100,'Маркетинг','Москва', 'Анисимов', 4000,1352519);
UPDATE EMPLOYEE SET DEPNO=100 WHERE EMPNO=4000;
Аналогичным образом могут, при наличии ссылочных циклов, возникать проблемы с операцией удаления кортежей в родительской и дочерних таблицах. Следует избегать наличия ссылочных циклов в таблицах. Так, для учебной базы данных добавление новых полей и установка для них ограничений ссылочной целостности совсем не обязательна.
Более подробное описание работы с ограничениями ссылочной целостности приводятся в соответствующих руководствах фирм - изготовителей СУБД.
В этом разделе мы изучили ограничения, которые поддерживаются в реляционной базе данных средствами СУБД. Такие ограничения представляют встроенные в СУБД механизмы обеспечения целостности данных и поддержку ссылочной целостности. Исходными данными для наложения ограничений являются бизнес-правила предметной области базы данных. Решение о том, как будут использоваться эти бизнес-правила при проектировании физической модели базы данных в рамках предоставляемых СУБД механизмов добавления ограничений, находится полностью в компетенции проектировщиков баз данных. Проектировщик базы данных может принять решение о том, что ссылочная целостность будет контролироваться через триггеры, а целостность данных будет отдана на откуп разработчикам программ или опять же будут использованы триггеры. Или для выполнения такого контроля будет предусмотрено специальное приложение базы данных, или такой контроль будут осуществлять организационными мероприятиями.
Ниже приведен типичный синтаксис команды ALTER TABLE.
Типичный синтаксис команды ALTER TABLE (без учета ссылочной целостности):
ALTER TABLE имя_таблицы DROP [имя_колонки [,имя_колонки ѕ]] ADD имя_колонки тип_данных [(размер)] [NOT NULL | NOT NULL WITH DEFAULT] RENAME имя_колонки новое_имя | TABLE новое_имя MODIFY имя_колонки тип_данных [(размер)] [NULL | NOT NULL | NOT NULL WITH DEFAULT]
Добавление CHECK-ограничения в спецификацию колонки
Ограничение CHECK позволяет выполнять проверку содержимого колонки относительно некоторых условий и списка значений. Она налагается с помощью предложения CHECK. Для добавления этого ограничения нужно после объявления столбца в спецификации колонки определить синтаксическую конструкцию CHECK (предикат). Согласно требованиям стандарта с помощью ключевого слова VALUE в предикате вы ссылаетесь на значение колонки. Но практически во всех диалектах для этой цели используется имя колонки.
Пример. В учебной базе данных в таблице EMPLOYEE для сотрудников может указываться признак пола: 0 - мужской, 1 - женский. Бизнес-правило предметной области для значений этого поля может быть сформулировано так:
Лицо, принимаемое на работу, может иметь один из двух допустимых признаков пола.
Тогда спецификация колонки может выглядеть так:
SEX int NOT NULL CHECK (SEX=0 OR SEX=1),
Добавление колонок в таблицы
Следующим шагом проектировщика базы данных является определение колонок для базовых таблиц. Колонки таблицы должны представлять атрибуты отношений логической модели реляционной базы данных. Эти атрибуты необходимо преобразовать в спецификации колонок в команде CREATE TABLE. Спецификация колонки таблицы имеет следующий синтаксис: имя колонки, тип данных для значений, сохраняемых в колонке, список ограничений.
Сначала рассмотрим задачу добавления колонок. Колонка должна иметь имя. Имена атрибутов соответствующих отношений логической модели преобразуются в имена колонок в соответствии с правилами именования объектов, принятых в конкретной СУБД. Обычно, как указывалось выше, это ограничение на длину имени и использование в имени специальных символов. Например, в некоторых СУБД допускается использовать знак доллара в имени, однако этот знак обычно не распознается в командах выборки данных - SELECT.
Имеется еще одна проблема в именовании колонок: имена колонок должны интерпретироваться пользователем однозначно. Например, если проектировщик базы данных назначит для фамилии сотрудника короткое имя LN, то, наверное, потребуется комментарий, в котором необходимо указать, что это фамилия, а не линия (например, линия производства). Если невозможно по каким-то причинам применять длинные имена полей, то следует использовать словарь данных для интерпретации введенных аббревиатур.
При назначении имен колонок проектировщик базы данных продолжает формировать стандартный список имен колонок и их сокращений в словаре данных. Он также должен выполнить проверку списка имен в словаре данных, чтобы избежать конфликтов имен в базе данных в целом.
Пример. Продолжим работу с учебным примером. После именования колонок получим следующее:
CREATE TABLE DEPARTAMENT ( DEPNO, имя колонки DNAME, LOC, MANAGER, PHONE, );
CREATE TABLE EMPLOYEE ( EMPNO, ENAME, LNAME, DEPNO, SSECNO, PROJNO, JOB, AGE, HIREDATE, SAL, COMM, FINE, ); CREATE TABLE PROJECT ( PROJNO, PNAME, BUDGET, );
Добавление ограничения первичного ключа и внешнего ключа
Мы уже рассматривали вопрос о задании ограничений первичного ключа в предыдущем разделе. Там же был показан пример задания ограничений внешнего ключа при разрешении связей "многие-ко-многим". Более детально мы разберем работу с ограничением внешнего ключа при обсуждении поддержки ссылочной целостности ниже.
Добавление ограничения UNIQUE в спецификацию колонки
Ограничение UNIQUE гарантирует уникальность значения данных в колонке. Оно используется, если нужно следить за тем, чтобы значения колонки, не являющейся первичным ключом, были уникальны в таблице. При этом проверяется уникальность всех значений, отличных от NULL.
Пример. В учебной базе данных в таблице EMPLOYEE используется номер социальной страховки SSECNO, для которого бизнес-правило состоит в том, что для каждой персоны, если она имеет такой номер, он должен быть уникальным. Установить уникальность этих номеров можно следующей спецификацией колонки:
SSECNO char(10) UNIQUE,
Ограничение UNIQUE можно определить также в конце команды CREATE TABLE в следующей синтаксической форме: UNIQUE (SSECNO).
Добавление, удаление и блокирование ограничений
Ограничения задаются в спецификациях колонки или спецификациях ключей при создании таблицы в командах SQL CREATE TABLE или налагаются после создания таблицы в командах SQL ALTER TABLE. Как добавить ограничения в таблицу с помощью команды CREATE TABLE, мы уже знаем. Чтобы добавить ограничения с помощью команды ALTER TABLE, можно поступать следующим образом.
Пример. Для нашей учебной базы данных мы могли бы не определять первичный ключ в таблице EMPLOYEE в команде CREATE TABLE и после нее выполнить команду
ALTER TABLE EMPLOYEE PRIMARY KEY (EMPNO);
Аналогично, мы могли бы установить ограничение внешнего ключа в таблице EMP_PRJ следующим образом:
CREATE TABLE EMP_PRJ ( EMPNO integer NOT NULL, PROJNO char(8) NOT NULL, WORKS number, PRIMARY KEY (EMPNO, PROJNO), ); ALTER TABLE EMP_PRJ FOREING KEY (EMPNO) REFERENCES EMPLOYEE ON DELETE RESTRICT, FOREING KEY (PROJNO) REFERENCES PROJECT ON DELETE RESTRICT;
Чтобы удалять ограничения первичного и внешнего ключей, можно использовать команду ALTER TABLE в синтаксической форме
ALTER TABLE EMPLOYEE DROP PRIMARY KEY (EMPNO);
В СУБД Oracle 9i для создания ограничений на уровне таблицы используется следующий синтаксис команды ALTER TABLE:
ALTER TABLE имя_таблицы ADD CONSTRAINTS ограничение TYPE(колонка);
а для удаления
ALTER TABLE имя_таблицы DROP CONSTRAINTS ограничение.
Кроме этого, в СУБД Oracle 8i можно блокировать и деблокировать действие ограничений с помощью опций DISABLE и ENABLE команды ALTER TABLE, как показано в примере ниже:
ALTER TABLE EMPLOYEE DISABLE PRIMARY KEY; ALTER TABLE EMPLOYEE ENABLE PRIMARY KEY;
После использования опции DISABLE ограничение становится неактивным, но его определение остается в словаре базы данных. Вы можете вернуть активность ограничению с помощью опции ENABLE. Использование опции DROP полностью удаляет ограничение из базы данных (и словаря базы данных также).
Использование опции DEFAULT
Опция DEFAULT заставляет СУБД размещать значение по умолчанию в колонке, когда кортеж вставляется в таблицу и никакого значения колонки не представлено. Чтобы указать значение по умолчанию, нужно в спецификацию колонки добавить ключевое слово "DEFAULT" и после него указать любое значение, являющееся достоверным экземпляром типа данных колонки.
Пример. Для нашей учебной базы данных мы могли бы определить значение по умолчанию для числовых колонок в таблице EMPLOYEE:
SAL dec(9,2) DEFAULT(0), COMM dec(9,2) DEFAULT(0), FINE dec(9,2) DEFAULT(0),
Назначение первичных ключей таблицам
После определения всех колонок и их типов следует перейти к идентификации первичных ключей таблицы. Согласно требованиям реляционной теории каждая строка таблицы (кортеж) должна иметь уникальный первичный ключ. Обычно хорошим кандидатом на первичный ключ таблицы является первичный ключ отношения логической модели. Поскольку предполагается, что в отношении логической модели задан первичный ключ, обладающий свойством минимальности, то его просто нужно определить в команде CREATE TABLE. Такое определение первичного ключа таблицы для многих таблиц не является окончательным. Переопределение первичного ключа может происходить на следующих этапах физического проектирования базы данных.
Задание колонки как первичного ключа в контексте многих СУБД, в том числе и Oracle, считается ограничением на значение колонки (см. следующий подраздел).
Стандартом SQL-92 предусмотрено специальное предложение PRIMARY KEY команды CREATE TABLE для спецификации первичного ключа таблицы. Атрибуты первичного ключа перечисляются через запятую и заключаются в круглые скобки. Если спецификация PRIMARY KEY не определяется, то считается, что таблица не имеет первичного ключа. При этом допускается дублирование строк в таблице.
Пример. Для нашего примера колонками первичного ключа могут быть назначены: колонка DEPNO в отношении DEPARTAMENT, колонка EMPNO в отношении EMPLOYEE, колонка PROJNO в отношении PROJECT.
CREATE TABLE DEPARTAMENT ( DEPNO integer, DNAME char(20), LOC char(20), MANAGER char(20), PHONE char(15), PRIMARY KEY (DEPNO) определение первичного ключа );
CREATE TABLE EMPLOYEE ( EMPNO integer, ENAME char(25), LNAME char(10), DEPNO int, SSECNO char(10), PROJNO char(8), J OB char(25), AGE date, HIREDATE date, SAL dec(9,2), COMM dec(9,2), FINE dec(9,2), PRIMARY KEY (EMPNO) );
CREATE TABLE PROJECT ( PROJNO char(8), PNAME char(25), BUDGET dec(9,2), PRIMARY KEY (PROJNO) );
В СУБД Oracle можно задавать ограничение первичного ключа, т.е. определять колонку как первичный ключ, как часть спецификации колонки, а не как часть спецификации таблицы (см.
пример выше). При использовании такой техники команда CREATE TABLE будет выглядеть так, как показано ниже для таблицы DEPARTAMENT:
CREATE TABLE DEPARTAMENT ( DEPNO integer primary key, определение первичного ключа DNAME char(20), LOC char(20), MANAGER char(20), PHONE char(15), );
Когда вы определяете PRIMARY KEY при создании таблицы, многие реляционные СУБД требуют обязательного создания уникального индекса первичного ключа. Индексы, так же как и таблицы, являются объектами реляционной базы данных (но не реляционной модели). Логически индексы представляют собой таблицу, в которой каждому значению индексируемой колонки ставится в соответствие некоторая информация, связанная с ее месторасположением на физическом носителе. Индексы предназначены для организации быстрого доступа к строкам таблицы и обеспечения контроля целостности данных (механизм индексов будет блокировать вашу базу данных от повторного ввода строк в таблицу с одинаковыми значениями индексируемых атрибутов). Индекс создается с помощью команды
CREATE UNIQUE INDEX NDXDEPT ON DEPARTAMENT (DEPNO);
Предложение CREATE INDEX определяет имя индекса, предложение ON определяет имя таблицы и колонок, для которой и по которым строится индекс, ключевое слово UNIQUE указывает, что индексируемые значения колонок должны быть уникальными для таблицы, т.е. исключается дублирование значений в индексируемой колонке. Таблица должна быть уже создана, и должна содержать определения индексируемых столбцов. Спецификация UNIQUE опциональна, и вы можете также создавать и неуникальные индексы.
Следует помнить, что для многих СУБД целостность первичного ключа поддерживается заданием уникального индекса на колонку ключа, иначе создание таблицы считается незавершенным.
Поэтому для завершения процедуры определения первичных ключей базовых таблиц проектировщик базы данных должен будет добавить в скрипт три команды CREATE UNIQUE INDEX, как показано ниже:
CREATE UNIQUE INDEX NDXDEPT ON DEPARTAMENT (DEPNO); CREATE UNIQUE INDEX NDXEMPLOYEE ON EMPLOYEE(EMPNO); CREATE UNIQUE INDEX NDXPROJECT ON PROJECT(PROJNO);
Для диалекта SQL СУБД Oracle этого делать не нужно, т.к. она автоматически поддерживает целостность первичного ключа.
После выполнения вышеперечисленных действий задачу определения первичных ключей базовых таблиц в первом приближении можно считать законченной и перейти к решению следующей очень важной задачи определения таблиц - определению ограничений на значения колонок.
Обавление NOT NULL ограничения в спецификацию колонки
NOT NULL ограничение гарантирует, что колонка всегда содержит значения. СУБД не будет разрешать вставлять или обновлять строку таблицы, если в ней существует колонка с ограничением NOT NULL, а данных для этой колонки в добавляемой строке не представлено. Как мы уже видели выше, для колонок первичного ключа это ограничение нужно устанавливать всегда.
Пример. Для нашей учебной базы данных действует правило, что сотрудник всегда должен иметь имя и фамилию. Чтобы удовлетворить этому правилу, нужно определить следующую спецификацию колонок ENAME и LNAME в таблице EMPLOYEE:
ENAME char(25) NOT NULL, LNAME char(10) NOT NULL,
Иногда ограничение NOT NULL используется вместе с опцией DEFAULT, как это было определено в спецификации колонки HIREDATE (дата приема на работу) в таблице EMPLOYEE:
HIREDATE date NOT NULL WITH DEFAULT,
Ограничения и их использование в реляционной базе данных
В предыдущих разделах мы уже сталкивались с несколькими типами ограничений в спецификациях колонок - NOT NULL, и ограничениях в таблицах - PRIMARY KEY, FOREING KEY. В данном разделе мы изучим практически все виды ограничений, которые поддерживаются в реляционных базах данных. Ограничения являются важным инструментом проектировщика базы данных, с помощью которого он поддерживает целостность (strong) базы данных. Их можно использовать для того, чтобы быть уверенным в том, что колонка первичного ключа таблицы является уникальной и всегда содержит значения. Ограничения используются также для поддержки ссылочной целостности. Последнее означает, что значения в колонке внешнего ключа должны существовать как некоторое значение в колонке первичного ключа другой таблицы.
Замечание. Одна из главных концепций реляционной базы данных состоит в том, что всегда целесообразнее заставлять саму базу данных поддерживать свою непротиворечивость, чем заставлять решать эту задачу приложение базы данных. Вопрос о том, что лучше: передавать поддержку ограничений приложениям базы данных или оставлять самой базе данных, - остается все еще открытым.
Ограничения представляют собой способ применения бизнес-правил предметной области на уровне базы данных и гарантируют совместимость вводимых данных с теми, которые уже находятся в таблицах. В реляционной базе данных под ограничением понимается правило (условие), которому должен удовлетворять некоторый элемент в базе данных. Например, условия, которым должны дополнительно удовлетворять значения колонки таблицы в рамках определенного для нее типа данных (т.е. тип данных плюс правило), полностью воплощают концепцию домена в физической модели реляционной базы данных.
Как мы видели выше, ограничения могут применяться на уровне колонки (ограничения колонки) или на уровне таблицы (ограничения таблицы). Ограничения первичного ключа - это ограничения, действующие на уровне таблицы, а NOT NULL ограничения - это ограничения на уровне колонки. Существуют три основных типа ограничений, используемых в реляционной базе данных, - ограничения целостности данных, ограничения целостности ссылок и ограничения первичного ключа.
Ограничения целостности данных (data integrity constraints) относятся к значениям данных в некоторых колонках и определяются в спецификации колонки с помощью элементов SQL NOT NULL, UNIQUE, CHECK. Ограничения целостности ссылок (referential constraints) относятся к связям между таблицами на основе связи первичного и внешнего ключей. Ограничения первичного ключа относятся к значениям данных в колонках первичного ключа таблицы и должно налагаться на каждую базовую таблицу реляционной базы данных. В таблице ниже приведен список ограничений, применяемых в реляционных базах данных.
| Ограничение | Описание | |
Определение базовых таблиц
Как указывалось выше, первый шаг в построении внутренней схемы есть идентификация реляционной таблицы, которая будет сохраняться в базе данных. При решении этой задачи проектировщик базы данных имеет на входе отношения логической модели реляционной базы данных, представляющие сущности предметной области, а на выходе должен создать набор макетных команд CREATE TABLE, которые будут использоваться далее для добавления колонок и других деталей.
Базовые таблицы создаются для каждого отношения логической модели и являются главными объектами хранения данных в базе данных. Для каждой базовой таблицы определяется длинный идентификатор, который уникально идентифицирует таблицу в базе данных. Это имя должно соответствовать стандартам наименований сущностей предметной области базы данных, если такие стандарты были разработаны администратором данных на стадии анализа предметной области базы данных. Имена таблиц должны быть занесены проектировщиком базы данных в словарь данных базы данных.
Далее проектировщик базы данных формирует список всех пользователей каждой таблицы. При этом выделяются так называемые владельцы таблицы, т.е. пользователи, которые имеют все права доступа к таблице. Этот список используется на завершающем этапе проектирования физической структуры базы данных при авторизации пользователей и разграничении полномочий доступа.
Когда проектировщик заканчивает обработку всех отношений логической модели данных, он должен еще раз проверить, чтобы число базовых таблиц соответствовало числу отношений логической модели реляционной базы данных (т.е. было не меньше, чем число сущностей предметной области базы данных). Таким образом, при создании базовых таблиц проектировщик базы данных придерживается принципа "каждому отношению логической модели базы данных по базовой таблице".
Пример. Для нашего учебного примера результат решения задачи настоящего пункта может иметь следующий вид:
CREATE TABLE DEPARTAMENT имя таблицы ( ); CREATE TABLE EMPLOYEE имя таблицы ( ); CREATE TABLE PROJECT имя таблицы ( );
Определение типов данных для колонок
После идентификации колонок необходимо задать их тип в соответствии с допустимыми для данной СУБД типами данных. Эта задача упрощается, если в отношениях логической модели определены домены атрибутов. Некоторые из доменов могут быть определены уже в терминах СУБД. Для таких атрибутов практически ничего делать не нужно. Определение домена в терминах типа данных СУБД нужно просто перенести в спецификацию колонки. Возможно, проектировщику будет нужно уточнить второстепенные параметры типа. Например, если задан домен как DEC (9,2), а из контекста предметной области следует, что в этой колонке будет накапливаться итоговая сумма расходов за год, то может быть целесообразным определить тип как DEC (15,2), чтобы избежать возможного переполнения при работе приложений базы данных.
Если домен определен не в терминах СУБД, проектировщик базы данных должен преобразовать его в подходящий тип данных. При выполнении таких преобразования следует учитывать ряд факторов.
Следует уточнить, как СУБД физически хранит данные того или иного предопределенного типа, и затем уточнить интервалы изменения значений колонок. Например, если тип переменной - varchar (3), которая содержит код, чье значение изменяется в интервале от '10A' ' до '99Z', то целесообразно с точки зрения хранения изменить тип этой переменной на char(3). Это объясняется тем, что тип varchar при физическом хранении занимает на байт-два больше, чем тип char при одной и той же объявленной длине.Для числовых значений фиксированной длины предпочтительнее использовать тип DEC. Он обрабатывается процессором быстрее, чем тип FLOAT. Исключение составляют данные для научных расчетов, где представление чисел в экспоненциальной форме бывает необходимо.Используйте INT и SMALLINT исключительно для счетчиков.Старайтесь избегать использования LONG VARCHAR без лишней надобности. Обычно колонки такого типа хранятся на отдельном экстенте жесткого диска, причем не в той области диска, где хранятся остальные данные таблицы. Избегайте использовать тип CHAR для представления числовых данных.
Во-первых, может потребоваться дополнительная проверка, а во-вторых, могут возникнуть проблемы при сортировке таких колонок, поскольку число, заданное строкой '11', будет находиться выше, чем число, заданное строкой '9', при упорядочивании по возрастанию.Используйте типы DATE и TIME только для хранения хронологических данных.Используйте тип DATETIME исключительно для целей управления данными.
Пример. Продолжим изучение нашего примера. После определения типов колонок наши команды для создания таблиц будут выглядеть следующим образом:
CREATE TABLE DEPARTAMENT ( DEPNO integer, имя колонки, тип, длина DNAME char(20), LOC char(20), MANAGER char(20), PHONE char(15), );
CREATE TABLE EMPLOYEE ( EMPNO integer, ENAME char(25), LNAME char(10), DEPNO int, SSECNO char(10), PROJNO char(8), JOB char(25), AGE date, HIREDATE date, SAL dec(9,2), COMM dec(9,2), FINE dec(9,2), );
CREATE TABLE PROJECT ( PROJNO char(8), PNAME char(25), BUDGET dec(9,2), );
Особенности манипулирования данными при ограничениях ссылочной целостности
Естественно, что ограничения ссылочной целостности (фиксируя в базе данных связи между таблицами и отслеживая их) оказывают действие на команды манипулирования данными. Такие действия регламентируют правила использования данных команд, в случае, когда таблица имеет внешний ключ.
Для команды INSERT предусмотрены следующие правила:
каждое NOT NULL значение атрибута внешнего ключа должно соответствовать значению атрибута первичного ключа в таблице-родителе;если один из атрибутов внешнего ключа имеет нуль-значение, то принимается нуль-значение для всего ключа, при этом никаких проверок ограничений ссылочной целостности не выполняется;невозможно вставить строки в таблицу-родитель или таблицу-потомок, если таблица-родитель находится в незавершенном состоянии;можно вставить строки в таблицу-родитель, не делая одновременно аналогичных действий в таблице-потомке.
Для команды UPDATE предусмотрены следующие правила:
при обновлении таблицы-потомка каждое ненулевое значение внешнего ключа должно соответствовать значению первичного ключа в родительской таблице;если таблица-потомок имеет нескольких родителей, то значение внешнего ключа должны соответствовать значениям первичного ключа всех таблиц-родителей.
Попытка обновить первичный ключ родительской таблицы возможна лишь тогда, когда ему не соответствует ни одного значения внешнего ключа в таблицах-потомках, причем сделать это можно только для одной строки таблицы в команде UPDATE.
Правила для команды DELETE сообщают СУБД, что ей делать, когда пользователь пытается удалить строку в таблице-родителе. Отметим также, что в командах удаления нельзя использовать подзапрос, ссылающийся на заданную в команде таблицу.
Применение команды DROP в условиях ограничений ссылочной целостности также имеет свои особенности. Так, когда вы удаляете таблицу-родитель или первичный ключ, ограничения ссылочной целостности разрушаются. Если вы удаляете первичный индекс, то вы не разрушаете ограничений ссылочной целостности, но таблица становится незавершенной. Удаление первичного или внешнего ключа физически не удаляет соответствующие колонки.
Отношение "родитель-потомок" между таблицами
Первичный и соответствующий ему внешний ключ позволяют реализовать отношение "родитель-потомок" (parent/child relationship) между таблицами. Они отражают взаимосвязь между объектами предметной области (представленными кортежами таблиц) через значения некоторых их атрибутов по принципу иерархического подчинения, когда объект-родитель определяет существование объектов-потомков. Сами объекты-потомки могут также выступать в качестве родителей для других объектов (descendents).
Таблица реляционной базы данных, содержащая первичный ключ, называется таблицей-родителем (parent table) или родительской таблицей, а таблица, содержащая соответствующий первичному ключу внешний ключ, - таблицей-потомком (child table) или дочерней таблицей. Таблица DEPARTAMENT учебной базы данных является таблицей-родителем для таблицы EMPLOYEE.
Таблица базы данных может не иметь ни родителей, ни потомков. Такие таблицы называются независимыми таблицами (independent tables). Они не удовлетворяют никаким ограничениям ссылочной целостности и СУБД не контролирует и не проверяет правильность ссылок к таким таблицам.
Отношение "родитель-потомок" между таблицами реализуется через атрибуты-ключи соответствующих строк. Строка, принадлежащая таблице-родителю, называется родительской строкой, а строка в таблице-потомке, на которую ссылается родительская строка, называется строкой-потомком или дочерней строкой. Строка-потомок должна иметь по крайней мере один ненулевой атрибут внешнего ключа.
Совсем необязательно, чтобы каждая строка таблицы-родителя была родительской строкой. Аналогично, если строка в таблице-потомке имеет нуль-значение внешнего ключа, то она не будет строкой-потомком.
Отношение "родитель-потомок" между двумя таблицами отражает взаимосвязь по включению на доменах соответствующих атрибутов. Однако, таблица может реализовать отношение иерархического подчинения в самой себе. Примером такой таблицы может стать виртуальная таблица из этой лекции, реализующая отношение Руководитель-подчиненный, если ее сделать таблицей базы данных.
Первичные и внешние ключи
Понятие первичного ключа как уникального идентификатора кортежа отношения уже обсуждалось выше. Здесь нас интересует другой аспект данного понятия. А именно - то, что первичный ключ может гарантировать целостность данных. Если первичный ключ корректно используется, все кортежи отношения остаются различными и отсутствуют кортежи, у которых все атрибуты имеют нуль-значения. Напомним основные свойства первичного ключа:
отношение (таблица) может иметь только один первичный ключ;первичный ключ должен быть уникальным;первичный ключ должен быть минимальным, т.е. включать минимальное число атрибутов, необходимых для однозначной идентификации кортежа;первичный ключ не может содержать нулевых значений;значение первичного ключа не должно меняться при смене состояний базы данных.
Поддержка ссылочной целостности посредством первичного ключа осуществляется через его индекс. Уникальный индекс для первичного ключа отношения называется первичным индексом. Как правило, первичный индекс должен быть единственным для отношения. Если первичный индекс не создан, таблица реляционной базы данных находится в незавершенном состоянии. В такой таблице вы не можете искать, вставлять, удалять или модифицировать строки. Также невозможно создать внешний ключ для ссылки на первичный ключ таблицы.
Замечание. В СУБД Oracle 9i первичный индекс создается автоматически.
В конкретных реализациях СУБД существуют дополнительные ограничения на определение первичного ключа. Так, в SQLBase первичный ключ не может включать более 16 колонок, общая длина первичного ключа не может превышать 255 байт, нельзя использовать колонки типа LONG/LONG VARCHAR, в самоссылающихся строках значение первичного ключа невозможно модифицировать.
Внешний ключ представляет собой ссылку на первичный ключ в данной или другой таблице, т.е. один или несколько атрибутов отношения, которые содержат первичный ключ другого отношения. Примером внешнего ключа является номер отдела DEPNO в таблице EMPLOYEE нашей учебной базы данных.
Из определения следует, что внешний ключ может быть создан только после создания соответствующего первичного ключа (и первичного индекса).
Внешнему ключу обычно назначается специальное имя. Внешние ключи имеют следующие свойства:
Внешний ключ должен содержать такое же число колонок, такого же типа и в том же порядке следования, что и соответствующий первичный ключ.Имена колонок внешнего ключа и их значения по умолчанию могут отличаться от используемых в соответствующем первичном ключе (в том числе иметь нуль-значения).Таблица может иметь любое число внешних ключей.Упорядочение значений колонок внешнего ключа в его индексе может отличаться от соответствующего первичного ключа. Внешний ключ не может ссылаться на виртуальную таблицу.
Поддержка ссылочной целостности посредством внешних ключей не требует соответствующего индекса для внешнего ключа. Однако наличие такого индекса иногда может улучшить производительность базы данных.
В SQLBase существуют ограничения на определение внешнего ключа:
Внешний ключ не может содержать более 16 колонок.Внешний ключ может ссылаться только на первичный ключ родительской таблицы, которая должна находиться в той же базе данных.Внешний ключ не может ссылаться на таблицу системного каталога.
В других СУБД ограничения на определение внешнего ключа носят аналогичный характер.
Понятие внешней схемы
При обсуждении представлений мы уже касались понятия внешней схемы. В этом подразделе мы остановимся на этом понятии более подробно. Создание внешней схемы является желательным, но совсем не обязательным действием проектировщика данных.
В архитектуре трех схем ANSI/SPARC внешняя схема используется для изоляции требований к данным пользователей и приложений от физического размещения данных. Такая изоляция по определению делает пользователей независимыми от аспектов физической модели реляционной базы данных, включающих возможности СУБД и программно-аппаратной платформы. Эта изоляция делает пользователей также независимыми и от информационной модели предметной области, и от логической структуры базы данных или от стратегической политики обработки данных в масштабе организации, которая может быть неестественной для представления данных конкретного пользователя. Таким образом, под внешней схемой принято понимать такую организацию представления данных в базе данных, которое наиболее естественным и простым способом отражало бы взгляд пользователей на эти данные, когда они их обрабатывают. Цель разработки внешней схемы состоит в том, чтобы скрыть от пользователя особенности реализации физической модели базы данных.
В настоящее время стандарт SQL, так же как и большинство промышленных СУБД, не говоря уже об экспериментальных СУБД, обеспечивают поддержку внешней схемы ограниченно. Основным способом изоляции требований пользователей к данным от особенностей их физического хранения является механизм реляционных представлений, который мы обсуждали выше.
Приведем примеры, когда изменения на уровне физической организации базы данных могут быть скрыты от пользователей с помощью представлений.
Изменения владельцев объектов. Исключением может быть изменение владельцев представлений.Изменение имен колонок. Определение представления может отображать старые имена колонок в новые имена, делая, таким образом, эти изменения невидимыми пользователям.Изменения имен таблиц. Добавление колонок в таблицы, так как эти новые колонки не используются существующими представлениями.Физическое переупорядочивание колонок таблицы. В представлениях можно явно задавать нужный порядок.Создание, модификация и удаление индексов. Исключением может быть удаление индекса первичного ключа, когда базовая таблица, участвующая в соединении, становится незавершенной и, следовательно, не будет обрабатываться в запросе (для некоторых СУБД).Комбинация двух или более таблиц в одной. Обычно это предполагает, что первичные ключи этих таблиц одни и те же.Разделение одной таблицы на несколько таблиц.
Создание внешней схемы является в большей степени задачей администратора базы данных, чем задачей проектировщика. Более того, стоимость сопровождения представлений внешней схемы будет определяться стоимостью работ администратора базы данных по созданию и сопровождению представлений, а также по обеспечению безопасности, так как потребуется дополнительная авторизация доступа к представлениям.
Представления и множества
Представления (виртуальные таблицы) позволяют вам явным образом именовать результирующие отношения, получающиеся в промежуточных реляционных операциях, и использовать их как самостоятельные отношения. Так вы можете результату вложенного подзапроса (непоименованное отношение) присвоить имя и применять это отношение вместо вложенного подзапроса как самостоятельное.
Концепция представления особенно важна, когда требуется извлекать информацию из нескольких отношений. Во-первых, она является средством формирования пользователем своей виртуальной (внешней) схемы базы данных. Во-вторых, это средство формирования производных или выводимых атрибутов отношений базы данных, то есть таких атрибутов, которые непосредственно не хранятся в базе данных. Представление можно трактовать как макроопределение: любой запрос по отношению к нему подвергается макрорасширению и преобразуется SQL для ссылки на исходные базовые отношения. Чтобы представление (как производное отношение) стало доступно, вам необходимо дать ему уникальное имя и определить атрибуты.
Обратимся к примеру с футболом. Пусть имеется некоторая база данных, которая содержит всю информацию о чемпионате мира по футболу. Допустим, что вас интересует информация о стадионах и об играх, закончившихся с определенной разностью забитых и пропущенных мячей. Тогда вы можете первоначально определить представление как
CREATE VIEW СТАДРАЗН (стад, разн_мячей ) AS SELECT стадион, голыА - голыВ FROM ИГРЫ, РАЗМ_СТАДИОНОВ WHERE ИГРЫ.год = РАЗМ_СТАДИОНОВ.год AND ИГРЫ.группа = 2 АND РАЗМ_СТАДИОНОВ.группа=2 АND ИГРЫ.игра=РАЗМ_СТАДИОНОВ.игра
В этом примере также демонстрируется, как определять производные колонки в представлении.
Теперь вы можете выполнить запрос к виртуальной таблице, такой, чтобы получить ответ на вопрос: выдать все стадионы, на которых игры закончились с разностью мячей больше 4. Команда языка SQL в этом случае тривиальна:
SELECT стад FROM СТАДРАЗН WHERE разн_мячей > 4;
Таким образом, представление в алгебре отношений является операцией наименования промежуточных результатов.
Представления и независимость данных
Как вы могли видеть, виртуальные таблицы освобождают пользователя от необходимости знать, как хранятся данные. Пользователь имеет внешнюю схему (виртуальные таблицы), база данных определяется внутренней схемой (таблицы данных). Независимость данных определяется наличием двух уровней абстракции в представлении данных. Поддержка независимости данных для пользователя во многом упрощает работу с данными.
Рассмотрим пример из предыдущего раздела. Примененная схема базы данных учебного примера не позволяет использовать одного служащего в нескольких проектах (реализовано отношение "много (служащих) к одному (проекту)"). На практике обычно каждый служащий работает над несколькими проектами (отношение "многие-ко-многим"). Чтобы реализовать такое отношение, необходимо модернизировать структуру базы данных. При этом все ранее разработанные приложения и виртуальные таблицы должны работать соответствующим образом. Также следует использовать новые возможности. Определим отношение "многие-ко-многим" через создание новой таблицы PREM:
CREATE TABLE PREM ( EMPNO integer, PROJNO char(8), WORKS number);
которая будет служить для распределения служащих по проектам. В этой таблице каждому служащему отвечает столько строк, сколько проектов он выполняет. Колонка PROJNO таблицы EMPLOYEE при этом потеряла свой семантический смысл. Удалим эти данные:
UPDATE EMPLOYEE SET PROJNO=NULL;
При этом мы уже не можем пользоваться виртуальной таблицей PERSPROJ, которая использует эту колонку для соединения таблиц EMPLOYEE и PROJECT. Чтобы для пользователя ничего не изменилось, следует переопределить виртуальную таблицу PERSPROJ. Для этого удалим ее с помощью команды SQL DROP. Команда DROP является в SQL универсальной командой для удаления объектов реляционной базы данных: вы только должны определить, что вы хотите удалить: TABLE, VIEW или иной объект.
Удалим определение неподходящей виртуальной таблицы:
DROP VIEW PERSPROJ;
Создадим новую виртуальную таблицу с тем же именем, но учитывающую изменения в схеме базы данных:
CREATE VIEW PERSPROJ AS SELECT ENAME, JOB, PNAME FROM EMPLOYEE, PROJECT, PREM WHERE EMPLOYEE.EMPNO=PREM.EMPNO AND PREM.PROJNO=PROJECT.PROJNO;
Колонку PROJNO в таблице EMPLOYEE следует удалить за ненадобностью:
ALTER TABLE EMPLOYEE DROP PROJNO;
Вы видите, как легко изменить структуру базы данных, не внося слишком больших изменений в ваши приложения и используемые запросы (на виртуальных таблицах). Это объясняется тем, что SQL является непроцедурным языком, т.е. ваши программы и запросы не привязываются к структуре базы данных. За счет модификации виртуальных таблиц вы можете скрыть фактические изменения структуры базы данных от пользователя. Рассмотренный выше пример иллюстрирует основные моменты реализации концепции независимости данных в реляционных базах данных.
Синонимы
Синоним есть другое имя для таблицы или представления. Синонимы используются для того, чтобы сделать базу данных более дружественной для пользователя. Это означает, что объектам базы данных, которые попадают в сферу внимания пользователей, назначаются альтернативные, длинные имена в терминах предметной области базы данных. Такие имена более понятны неподготовленным пользователям базы данных и не будут создавать дополнительных психологических препятствий в работе с базой данных. С другой стороны, если объекты базы данных носят длинные имена, то их неудобно использовать в часто выполняемых запросах, т.к. каждый раз приходится набирать длинную последовательность символов. Синоним позволяет ввести сокращенное имя.
Задача назначения синонимов объектам базы данных является задачей администратора данных организации или администратора базы данных. Проектировщик может определить синонимы объектам базы данных, но он должен согласовать свои действия с администратором данных. Если синонимы определяются проектировщиком, то должен быть составлен список синонимов для передачи его администратору данных. Синонимы хранятся в словаре базы данных.
Синоним по определению может быть общим для всех пользователей базы данных (PUBLIC) или принадлежать пользователю (USER), который его создал. Опция PUBLIC позволяет обращаться к таблице с помощью синонима без уточнения имени таблицы именем владельца. Чтобы создать или удалить синоним PUBLIC, необходимо либо быть владельцем таблицы, либо иметь привилегии пользователей SYS или SYSTEM (Oracle). (Для СУБД SQLBase DBA или SYSADM соответственно.)
Пример. Для нашей учебной базы данных вы можете создать синоним EMP для таблицы EPMPLOYEE с помощью следующей команды:
CREATE PUBLIC SYNONYN EMP FOR EPMPLOYEE;
Или для пользователя SYS:
CREATE SYNONYN SYS.EMPL FOR EPMPLOYEE;
Чтобы удалить синоним EMP таблицы EPMPLOYEE, необходимо использовать команду
DROP PUBLIC SYNONYN EMP;
Создание начальной внутренней схемы реляционной базы данных
В настоящем разделе будет рассмотрена первая профессиональная задача проектировщика базы данных по созданию физической модели реляционной базы данных - создание объектов для хранения данных. Эта задача сводится к созданию таблиц и объектов в базе данных, в которых будет храниться информация о сущностях предметной области. Решая эту задачу, проектировщик базы данных отображает отношения логической модели реляционной базы данных (сущности предметной области, представленные в нормализованной форме на ER-диаграммах) в таблицы и индексы реляционной базы данных. Для выполнения этой задачи используется подмножество команд SQL - язык определения данных DDL (Data Definition Language) (например, для СУБД Oracle эти действия могут быть выполнены в программе SQL*PLUS).
В рамках концепции трехуровневой архитектуры баз данных ANSI/SPARC эту задачу проектировщика базы данных называют еще созданием внутренней схемы. Результатом решения этой задачи является скрипт для создания таблиц и индексов, что составляет первоначальный прототип физической модели базы данных.
Таким образом, физическая модель реляционной базы данных есть такое представление отношений базы данных и связей между ними, которое воплощено в последовательность команд SQL. Выполнение этой последовательности команд создает конкретную базу данных и ее объекты.
Одной из основных задач проектировщика данных при создании физической модели реляционной базы данных является превращение логических отношений базы данных в таблицы базы данных.
Элементарной подзадачей является создание таблицы базы данных. Таблицы в реляционных СУБД1 состоят из одной или более колонок или полей. Колонки представляют собой поименованные ячейки в записи, которые содержат значения. Колонки определяются посредством спецификации, которая определяет формат колонки и ее характеристики, задаваемые с помощью ограничений. Определение таблицы задается командой CREATE TABLE.
Создание первоначальной внешней схемы
Однако, если руководителем ИТ-проекта принято решение о разработке внешней схемы, проектировщик должен создать первоначальный вариант внешней схемы.
Для того чтобы создать внешнюю схему для новой базы данных, проектировщику базы данных необходимо начать с создания так называемых зеркальных представлений. Такое представление разрабатывается для каждой базовой таблицы внутренней схемы и включает все колонки этой таблицы, т.е. является полным зеркальным отображением базовой таблицы. Типичным требованием к таким представлениям является требование явного именования колонок представления, в противном случае приложениям может потребоваться модификация, если имена колонок будут изменены. Далее эти представления используются разработчиками и пользователями для доступа к базовой таблице.
Дополнительные представления могут быть созданы для приложений, которые выполняют так называемые типовые запросы к базам данных. Под типовым запросом здесь понимается запрос, который выполняется с высокой частотой использования либо одним пользователем, либо группой пользователей. Такое представление проектировщик базы данных может разработать, если требования к обработке данных задокументированы в спецификациях к базе данных.
Представления для эпизодических пользователей базы данных также могут быть созданы, если их требования к данным подробно описаны.
Создавать внешнюю схему наиболее удобно параллельно с внутренней, по мере того как создаются базовые таблицы. Решение о том, как проектировщик базы данных будет создавать первоначальную внешнюю схему, является его прерогативой.
Пример. Для нашей учебной базы данных первоначальная внешняя схема может выглядеть следующим образом:
CREATE VIEW DEPARTAMENT_V AS SELECT DEPNO, DNAME, LOC, MANAGER, PHONE FROM DEPARTAMENT;
CREATE VIEW EMPLOYEE_V AS SELECT EMPNO, ENAME, LNAME, DEPNO, SSECNO, JOB, AGE, HIREDATE, SAL, COMM, FINE FROM EMPLOYEE;
CREATE VIEW PROJECT_V AS SELECT PROJNO, PNAME, BUDGET FROM PROJECT;
CREATE VIEW PERSPROJ AS SELECT ENAME, JOB, PNAME FROM EMPLOYEE, PROJECT, EMPL_PROJ WHERE EMPLOYEE.EMPNO= EMPL_PROJ.EMPNO AND EMPL_PROJ.PROJNO=PROJECT.PROJNO;
Проектировщик базы данных в данном случае решил создать зеркальные представления для базовых таблиц, представляющих сущности предметной области. При этом он использовал суффикс _V в именах представлений, для того чтобы указать, что эти представления зеркально отображают поля базовой таблицы с именем без суффикса.
Кроме этого, он добавил представление, позволяющее получать информацию о служащих и выполняемых ими проектах, которая включает связывающую таблицу для этого отношения со степенью связи "многие-ко-многим".
В этом разделе мы рассмотрели механизм представлений реляционной базы данных. Представления как объекты базы данных занимают немного физического пространства в словаре базы данных, но обеспечивают функциональность базы данных на уровне таблиц. Помимо прочего они позволяют скрывать от пользователей информацию о физической структуре таблиц базы данных, что повышает безопасность эксплуатации базы данных в целом. Представления являются в реляционных базах данных основным механизмом для построения внешней схемы базы данных.
Ниже приведены рекомендации проектировщикам баз данных по созданию представлений в типичной реляционной базе данных.
Создавайте по одному представлению для каждой базовой таблицы, в точности совпадающему с таблицей, но имеющему другое имя.Создавайте по одному представлению для каждого взаимоотношения "первичный ключ-внешний ключ", через которое часто устанавливается соединение.Создавайте по одному представлению для часто используемого сложного запроса.Создавайте представления, ограничивающие доступ пользователей к конкретным колонкам и строкам таблицы.
Литература: [14], [15], [20], [45].
Создание представлений
СУБД предоставляет вам возможность создавать представления или так называемые виртуальные таблицы. Виртуальная таблица, или представление, является таблицей, которой физически нет в базе данных, но которая существует в представлении пользователя о логической структуре данных. Виртуальная таблица не содержит фактических данных, а реализуется как запрос к существующим таблицам базы данных. Определение представления хранится в словаре базы данных. Виртуальную таблицу можно рассматривать как поименованный запрос, который порождает таблицу для использования другими запросами. Таким образом, представление, или виртуальная таблица, - это поименованный запрос на выборку данных из одной или нескольких базовых таблиц, определение которого сохраняется в словаре базы данных.
Примечание. Далее в тексте термины "представление" и "виртуальная таблица" будут употребляться на равных правах.
Виртуальные таблицы используются в основном для реализации внешних схем данных (точек зрения пользователя). Они упрощают доступ к данным за счет замены сложных запросов более простыми запросами, обеспечивают независимость и защиту данных. Виртуальная таблица является объектом реляционной базы данных.
Для создания виртуальных таблиц в SQL предназначена команда CREATE VIEW. Пусть вам требуется регулярно просматривать списки служащих по отделам. Тогда вы можете использовать виртуальную таблицу
CREATE VIEW EMPLIST AS SELECT DEPNO, EMPNO, ENAME, JOB FROM EMPLOYEE GROOP BY DEPNO, EMPNO, ENAME, JOB;
Как видите, виртуальная таблица является средством именования часто используемых команд SELECT. Как известно, результат выполнения команды SELECT является таблицей. Виртуальная таблица, при создании которой используется предложение GROUP BY, иногда называется групповым представлением (grouped view)
Как только промежуточная таблица получает имя, к ней можно делать запрос. Например, выполнить команду
SELECT * FROM EMPLIST WHERE DEPNO=10;
которая дает список сотрудников 10-го подразделения.
Виртуальные таблицы можно определять с помощью других виртуальных таблиц.
Однако во многих реализациях SQL представления имеют сильные ограничения на выполнение операций обновления данных над ними. Некоторые СУБД не разрешают в определении представления использовать предложение ORDER BY. В некоторых диалектах SQL недопустимо выполнение обновлений на виртуальных таблицах, определенных на нескольких базовых таблицах, а также содержащих предложения GROUP BY, HAVING, опцию DISTINCT и функции агрегирования. Такие представления используются только для чтения. Например, в СУБД SQLBase представление используется только для чтения (read-only view), если в определяющей команде SELECT:
предложение FROM задействует имена более одной таблицы или представления;применяется: опция DISTINCT;предложение GROUP BY;предложение HAVING;функция агрегирования.
Иногда запрещается использовать и подзапросы.
В противном случае представление считается обновляемым представлением (updatable view). Для обновляемых представлений предусмотрена опция WITH CHECK OPTION. Когда она указана, любая вставка и обновление через данное представление будет выполняться только, если представление отвечает своему определению (данные в таблице могут быть изменены непосредственно). В противном случае такой проверки не делается. Если представление предназначено только для чтения или применяет подзапрос, то данная опция не должна использоваться.
Команда ALTER TABLE с такими же ограничениями также выполнима на виртуальных таблицах.
Создание связывающих таблиц для
Отношения "многие-ко-многим", как уже упоминалось в предыдущих лекциях, не могут быть в подавляющем большинстве случаев непосредственно реализованы в реляционных базах данных без создания промежуточных таблиц, иначе называемых связывающими таблицами (junction tables). Связывающая таблица является базовой таблицей (дочерней) базы данных, которая представляет отношение связи между двумя таблицами (родительскими), находящимися в отношении "многие-ко-многим". Процедура представления отношения "многие-ко-многим" с помощью связывающей таблицы на языке проектировщика базы данных носит название разрешение взаимосвязи (или связи) "многие-ко-многим". Эта задача может быть частично решена на стадии логического проектирования реляционной базы данных. На этой стадии требуется аккуратное воплощение решения этой задачи в операторах SQL.
Алгоритм задачи разрешения взаимосвязи следующий:
Создать связывающую таблицу (новую таблицу базы данных). Обычно проектировщики баз данных имеют такую таблицу конкатенацией имен двух связываемых таблиц.Добавить колонки в связывающую таблицу, как описано в предыдущем разделе. Обязательно добавляются колонки первичных ключей связываемых таблиц, которые образуют первичный составной ключ связывающей таблицы. Убедитесь, что все части составного ключа связываемой таблицы добавлены в связывающую таблицу!Определить первичный ключ связывающей таблицы и внешние ключи для связываемых таблиц. Внешним ключом будет часть первичного ключа родительской таблицы, которая ссылается назад к родительской таблице.
Этот алгоритм решает задачу разрешения отношения "многие-ко-многим". Однако можно подумать об атрибутах (колонках), которые могут существовать у связи (ее представляет связывающая таблица). Такие колонки могут быть помещены в связывающую таблицу. Это могут быть колонки, общие для связываемых таблиц.
Рассмотрим пример. Используемая схема базы данных учебного примера не позволяет использовать одного служащего в нескольких проектах (реализовано отношение "много (служащих) к одному (проекту)").
На практике обычно каждый служащий работает над несколькими проектами (отношение "многие-ко-многим"). Чтобы реализовать такое отношение, необходимо модернизировать структуру физической базы данных. Определим отношение "многие-ко-многим" через создание новой таблицы EMP_PRJ
CREATE TABLE EMP_PRJ ( EMPNO integer NOT NULL, PROJNO char(8) NOT NULL, WORKS number, PRIMARY KEY (EMPNO, PROJNO), FOREIGN KEY (EMPNO) REFERENCES EMPLOYEE, FOREIGN KEY (PROJNO) REFERENCES PROJECT, );
которая будет служить для распределения служащих по проектам. В этой таблице каждому служащему отвечает столько строк, сколько проектов он выполняет. Схема базы данных примет теперь вид как на рис. 9.1. Колонка PROJNO таблицы EMPLOYEE при этом потеряла свой семантический смысл. Ee следует удалить из таблицы EMPLOYEE за ненадобностью.
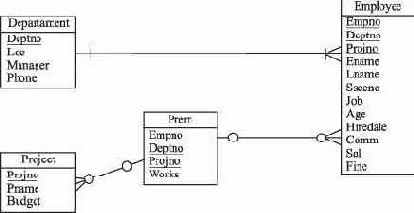
Рис. 9.1. Логическая структура учебной базы данных после разрешения отношения "многие-ко-многим"
Как работать с ограничением внешнего ключа, будет показано далее в соответствующем подразделе.
CREATE TABLE DEPARTAMENT ( DEPNO integer NOT NULL, DNAME char(20), LOC char(20), MANAGER char(20), PHONE char(15), PRIMARY KEY (DEPNO) определение первичного ключа );
CREATE TABLE EMPLOYEE ( EMPNO integer NOT NULL, ENAME char(25), LNAME char(10), DEPNO int, SSECNO char(10), JOB char(25), AGE date, HIREDATE date NOT NULL WITH DEFAULT, SAL dec(9,2), COMM dec(9,2), FINE dec(9,2), PRIMARY KEY (EMPNO) ); CREATE TABLE PROJECT ( PROJNO char(8) NOT NULL, PNAME char(25), BUDGET dec(9,2), PRIMARY KEY (PROJNO) );
CREATE TABLE EMP_PRJ ( EMPNO integer NOT NULL, PROJNO char(8) NOT NULL, WORKS number, PRIMARY KEY (EMPNO, PROJNO), FOREIGN KEY (EMPNO) REFERENCES EMPLOYEE, FOREIGN KEY (PROJNO) REFERENCES PROJECT );
Таким образом, в результате описанных выше действий был получен скрипт для создания базовых таблиц учебного примера. Этот скрипт можно выполнить, чтобы создать базовые таблицы. Но обычно проектировщики баз данных не спешат, а продолжают далее совершенствовать полученный скрипт.
Будем считать разработанный скрипт первой итерацией в создании внутренней схемы базы данных - создании базовых таблиц.
Дальнейшими задачами проектировщика базы данных будут задачи усовершенствования и доработки разработанного скрипта в следующих направлениях:
добавления ограничений в спецификации колонок (требования непротиворечивости и целостности данных); добавление ссылочной целостности (требования целостности данных);добавление представлений, синонимов и ряда других опциональных объектов базы данных (требования по разграничению доступа пользователей, частичное обеспечение требований безопасности);обеспечение требований производительности базы данных методами, предоставляемыми выбранной СУБД;определение пользователей, их авторизация и разграничение полномочий (требования безопасности базы данных).
Первые три направления деятельности носят опциональный характер и определяются особенностями конкретного ИТ-проекта и вкусами руководителя данного проекта, а также требованиями к базе данных и бизнес-правилами предметной области, если они представлены в исходной документации. Часто, особенно при использовании объектно-ориентированной парадигмы в разработке приложений базы данных, эти три направления деятельности проектировщика базы данных могут быть переданы разработчикам приложений базы данных. Поэтому мы подчеркиваем здесь их необязательный характер. Как может решать такие задачи проектировщик базы данных, будет рассмотрено в других разделах этой лекции. Четвертое направление деятельности очень желательно. Его следует выполнять, если априорно имеются данные о возможном поведении данных в системе во времени. Обычно борьба за производительность относится к задачам обратного влияния, когда становятся известными параметры эксплуатации системы. Это направление деятельности будет рассматриваться в двух последу ющих лекциях.
Последнее направление деятельности носит обязательный характер для обеспечения функционирования базы данных, эта задача в большей степени является задачей администратора базы данных - лица, ответственного за эксплуатацию базы данных в организации.
Как решаются такие задачи, будет рассмотрено в следующей лекции.
Ниже приведен типичный синтаксис некоторых команд SQL.
Синтаксис оператора CREATE TABLE:
CREATE TABLE имя_таблицы (имя_колонки тип_данных [NOT NULL | NOT NULL WITH DEFAULT] [, имя колонки ѕ] [PRIMARY KEY (имя_колонки [,имя_колонки ѕ]] [FOREIGN KEY [имя_ключа] (имя_колонки [, имя_колонки ѕ ]) REFERENCES имя_таблицы_родителя [ON DELETE [RESTRICT | CASCADE | SET NULL]]] ) [IN [имя_базы_данных] имя_области_табличного_пространства | IN DATABASE имя_базы_данных] [PCTFREE целочисленная_константа]
Примечание. Здесь и ниже опции операторов SQL, которые не объясняются в настоящем разделе книги, поясняются далее, там, где логика изложения требует их детального обсуждения. Подчеркивание ключевого слова обозначает значение, принятое по умолчанию.
Синтаксис оператора CREATE INDEX:
CREATE [UNIQUE] [CLUSTERED HASHED] INDEX имя_индекса ON имя_таблицы (имя_колонки [ASC | DESC] [, имя_колонки ѕ]) [PCTFREE целочисленная_константа] [SIZE целочисленное_значение [ROWS | BUCKETS]]
Создание таблиц
С точки зрения стандарта SQL-92, таблицы подразделяются на три категории.
Постоянные базовые таблицы (Base Table) - таблицы, содержимое которых хранится в базе данных и которые остаются в базе данных постоянно, если не удаляются явным образом.Глобальные временные таблицы - таблицы, которые применяются в качестве рабочей области хранения данных и которые уничтожаются в конце сеанса работы с базой данных. Описание этих таблиц хранится в словаре данных, но их данные не сохраняются. С глобальными таблицами может работать только текущий пользователь, но они доступны в течение всего сеанса работы с базой данных.Локальные временные таблицы - таблицы, которые аналогичны глобальным временным таблицам, но доступны только тому программному модулю, в котором созданы.
Физическая модель реляционной базы данных содержит базовые таблицы. Для определения и создания таблиц в SQL-92 предусмотрена команда CREATE TABLE, которая определяет имя таблицы, имена и физический порядок колонок для нее, тип каждой колонки, а также некоторые указания для СУБД, такие как определение первичного или внешнего ключа, требования на запрет неопределенных значений в колонке таблицы и т.п. Полный формат команды CREATE TABLE для каждой СУБД приводится в соответствующем документе с названием типа "Справочное руководство по SQL для СУБДѕ".
Создание таблиц с ограничениями ссылочной целостности
Для создания таблиц с поддержкой ограничений ссылочной целостности в SQL предназначены команды CREATE TABLE и команда ALTER TABLE. Таким образом, вы имеете два основных способа для поддержки ссылочной целостности в реляционной базе данных:
использование предложений PRIMARY KEY и FOREIGN KEY команды CREATE TABLE;использование предложений ADD/DROP PRIMARY KEY и ADD/DROP FOREIGN KEY команды ALTER TABLE.
В предыдущих разделах уже было показано использование предложения PRIMARY KEY команды CREATE TABLE. Пример использования предложения FOREIGN KEY команды CREATE TABLE продемонстрируем на примере создания таблицы для иерархии "руководитель-подчиненный":
CREATE TABLE MANAGEMENT ( MANAGNO INT NOT NULL, EMPNO INT, JOB INT, PRIMARY KEY (MANAGNO), FOREIGN KEY fnkey (EMPNO) REFERENCES EMPLOYEE ON DELETE CASCADE);
CREATE UNIQUE INDEX ndxmng ON MANAGEMENT(MANAGNO);
fnkey - имя внешнего ключа, предложение REFERENCES, связанное с предложением FOREIGN KEY, определяет имя таблицы-родителя, предложение ON DELETE определяет правило удаления записей в связанных таблицах. Каждое правило удаления соответствует определенной взаимосвязи между объектами реляционной базы данных (т. е. предметной области).
Правила удаления используются только в определении внешнего ключа. Обычно СУБД в соответствии со стандартом SQL поддерживает три правила:
CASCADE - сначала удаляется заданная строка в родительской таблице, а затем удаляются зависимые от нее строки;RESTRICT - строка может быть удалена, если никакие другие строки не зависят от нее, в противном случае удаления не происходит;SET NULL - для любого удаляемого первичного ключа соответствующее ему значение внешнего ключа дочерней строки принимает нуль-значение.
Для самоссылающихся таблиц используется только правило CASCADE. Правило RESTRICT препятствует удалению строки в таблице-родителе, если ей соответствуют какая-либо строка в таблице-потомке. Правило CASCADE определяет, что, когда строка в таблице-родителе удаляется, то все связанные с ней строки в таблице-потомке автоматически должны быть удалены. Правило SET NULL определяет, что, когда строка в родительской таблице удаляется, значения внешнего ключа во всех строках таблицы-потомка должны автоматически устанавливаться в нуль-значение.
Применение команды ALTER TABLE продемонстрируем на примере создания отношения "родитель-потомок" для таблиц DEPARTAMENT и EMPLOYEE учебной базы данных. Первичные ключи и индексы для этих таблиц уже созданы. Создадим внешние ключи (в таблицу DEPARTAMENT должна быть добавлена колонка EMPNO).
ALTER TABLE DEPARTAMENT FOREIGN KEY EMP_DEP (EMPNO) REFERENCES EMPLOYEE ON DELETE RESTRICT;
Для того, чтобы удалить первичный или внешний ключ таблицы, необходимо использовать предложение DROP команды ALTER TABLE.
Ссылочная целостность
В реляционной теории концепция ссылочной целостности была предложена в 1976 году П. Ченом. В рамках этой концепции все отношения реляционной базы данных разделяют на два класса: объектные отношения и связные отношения. Объектное отношение предназначено для описания состояния объекта через значения его атрибутов. Ему в физической модели базы данных отвечает базовая таблица. Связное отношение предназначено для фиксации связей между объектами через значения ключевых атрибутов объектов. Ему в физической модели базы данных также может отвечать базовая таблица. Обычно связные отношения поддерживаются в физической модели базы данных через ограничения первичного и внешнего ключей.
Ссылочная целостность означает, что все связи между отношениями замкнуты, т.е. все ссылки между отношениями допустимы и нет ссылок на несуществующие объекты (отношения, кортежи). Это предохраняет приложения пользователей от ситуаций, когда изменения в одном отношении не отражаются в других, связанных с ним.
Допустимость ссылки еще не означает ее корректность. Так, в учебной базе данных вы можете приписать служащему в таблице EMPLOYEE несуществующий номер отдела. Однако значение номера отдела в этой таблице должно быть согласовано с соответствующим значением в таблице DEPARTAMENT. Поддержка ссылочной целостности будет гарантировать лишь то, что такой отдел существует в таблице DEPARTAMENT. При этом вставка служащего с неправильным номером отдела будет заблокирована. Однако правильность списка сотрудников отдела не контролируется. Допустимая ссылка еще не означает ее правильность.
Иными словами, ссылочная целостность задает ограничения на связи между отношениями реляционной базы данных за счет управления значениями некоторых атрибутов взаимосвязанных отношений. Ограничения ссылочной целостности называются еще правилами ссылочной целостности.
Такие ограничения (в виде бизнес-правил) определяются при анализе предметной области базы данных системным аналитиком и, следовательно, субъективны. Например, для нашей учебной базы данных можно сформулировать следующие правила ссылочной целостности:
каждый служащий работает в определенном отделе;каждый отдел имеет только одного менеджера;каждый служащий работает под управлением менеджера;каждый проект имеет уникальный шифр.
В настоящее время большинство промышленных реляционных СУБД имеют встроенный механизм поддержки ссылочной целостности. Таким образом, вам не нужно писать код для поддержки ссылочной целостности в своем приложении, СУБД делает эту работу сама.
Механизм поддержки ссылочной целостности основывается на использовании следующих понятий:
первичные и внешние ключи;отношение "родитель-потомок" между таблицами;отношение "родитель-потомок" между строками;самоссылающиеся отношения на множестве своих кортежей.
Виртуальные таблицы с соединениями
Если вам необходимо работать с несколькими таблицами как с одной, вы можете создать виртуальную таблицу, объединяющую информацию из нескольких таблиц. Пусть вам нужна информация о служащих и выполняемых проектах, тогда можно создать следующую виртуальную таблицу:
CREATE VIEW PERSPROJ AS SELECT ENAME, JOB, PNAME FROM EMPLOYEE, PROJECT WHERE EMPLOYEE.PROJNO=PROJECT.PROJNO;
Выполняя команду
SELECT * FROM PERSPROJ;
вы получите необходимую вам информацию. При этом вам не нужно помнить, что данные хранятся в двух таблицах. Даже если будет изменена структура базы данных, не затрагивающая колонки из виртуальной таблицы, вы этого не заметите.
Можно выполнять и более сложные запросы на виртуальных таблицах. Допустим, что вам нужен список руководителей по проектам, тогда вы можете выполнить
SELECT ENAME, PNAME FROM PERSPROJ WHERE JOB='руководитель';
С виртуальными таблицами используется предложение WITH CHECK OPTION. При этом каждая вставка или обновление будет проверяться на соответствие определению виртуальной таблицы и будет отвергаться, если такого соответствия не будет. В противном случае такой проверки не делается.
Пусть вам нужно иметь информацию о текущих проектах. Тогда можно определить виртуальную таблицу (предварительно определив поле START_DATE в таблице PROJECT и установив его значения) как
CREATE VIEW CURPROJ AS SELECT * FROM PROJECT WHERE START_DATE < SYSDATE WITH CHECK OPTION;
Колонка START_DATE при обновлении будет проверяться на соответствие текущей дате. Это предложение справедливо только для обновления данных в колонках базовых таблиц, для которых создана такая виртуальная таблица. Если виртуальная таблица только для чтения или при его создании используется подзапрос, то WITH CHECK OPTION не должно указываться.
Задание ограничений NOT NULL на значения колонок
При определении спецификаций колонок таблиц проектировщик базы данных должен рассмотреть ограничения, которые могут быть наложены на значения колонок. В реляционных СУБД этих ограничений предусмотрено достаточно много. Здесь мы остановимся на одном из главных ограничений такого рода - это обязательность присутствия значения в колонке. Такое ограничение на значение колонки называется NOT NULL ограничением.
Предопределенное значение колонки, равное NULL, означает, что в данный конкретный момент для данной конкретной строки (экземпляра сущности предметной области) значение не определено, или не известно, или отсутствует. Проектировщику базы данных необходимо идентифицировать возможность колонки принимать NULL-значения, т.к. пользователи могут иметь проблемы при использовании таких колонок. Примером этой проблемы может служить ситуация, в которой пользователю требуется выполнить соединение двух таблиц по колонкам, имеющим NULL-значения. При выполнении таких соединений любые строки, которые содержат NULL-значения в колонках соединения в любой из таблиц, не будут показаны в результирующей выборке для запроса. Подобная потеря данных может привести к тому, что пользователь получит неправильную выборку на запрос, особенно если ему необходимо видеть все строки хотя бы одной из таблиц.
Примечание. Одним из способов решения определенной выше проблемы является использование внешних соединений.
При назначении NULL-значений колонкам проектировщику базы данных необходимо принимать во внимание следующие факторы.
Колонки, являющиеся частью составного первичного ключа, всегда должны иметь ограничение NOT NULL, т.к. согласно реляционной теории значения колонок первичного ключа должны быть определены и уникальны для каждого кортежа.Внешние ключи должны также определяться как NOT NULL, поскольку дочерняя таблица зависит от родительской и внешний ключ родительской не может иметь NULL-значения. Это следует из того, что существование строки дочерней таблицы без соответствующей строки родительской таблицы нарушает правило зависимости связи. (О внешних ключах, родительских и дочерних таблицах см.
далее.) Только внешние ключи для таблицы с опциональной связью могут рассматриваться как кандидаты на наличие NULL-значений, чтобы показать, что для данной комбинации родительской и дочерних строк в этих таблицах связи нет.Внешние ключи с правилом удаления SET NULL должны определяться со спецификацией NULL.Используйте спецификацию NOT NULL WITH DEFAULT для колонок с типами данных DATE или TIME, чтобы сохранять текущие даты и текущее время автоматически.Разрешайте использовать NULL-значения только для тех колонок, которые действительно могут иметь неопределенные значения.Используйте NOT NULL WITH DEFAULT для всех колонок, которые не подпадают под перечисленные выше правила.Пример. Как можно увидеть ниже, проектировщик базы данных определил, что: дата поступления служащего в организацию HIREDATE определена со спецификацией NOT NULL WITH DEFAULT, которая означает, что если на вводе значение колонки не определено, то по умолчанию подставляется текущая дата;номер подразделения DEPNO, номер служащего EMPNO и номер проекта PROJNO имеют спецификацию NOT NULL как первичные ключи таблиц; для остальных полей базовых таблиц проектировщик базы данных принял решение разрешить наличие в них NULL-значений.
CREATE TABLE DEPARTAMENT ( DEPNO integer NOT NULL, DNAME char(20), LOC char(20), MANAGER char(20), PHONE char(15), PRIMARY KEY (DEPNO) определение первичного ключа );
CREATE TABLE EMPLOYEE ( EMPNO integer NOT NULL, ENAME char(25), LNAME char(10), DEPNO int, SSECNO char(10), PROJNO char(8), JOB char(25), AGE date, HIREDATE date NOT NULL WITH DEFAULT, SAL dec(9,2), COMM dec(9,2), FINE dec(9,2), PRIMARY KEY (EMPNO) );
CREATE TABLE PROJECT ( PROJNO char(8) NOT NULL, PNAME char(25), BUDGET dec(9,2), PRIMARY KEY (PROJNO) );
