Стоимость, $
| ERwin/ERX | 3,295 |
| Bpwin | 2,495 |
| ERwin/ERX for PowerBuilder, Visual Basic, Progress | 3,495 |
| ERwin/ERX for Delphi | 4,295 |
| ERwin/Desktop for PowerBuilder, Visual Basic | 495 |
| ERwin/ERX for SQLWindows / Designer/2000 / Solaris | 3,495 / 5,795 / 6,995 |
| ModelMart 5 / 10 user | 11,995 / 19,995 |
| Erwin/OPEN for ModelMart | 3,995 |
Страница базы данных World Wide Web
- это законченный информационный объект, который отображается пользователю при обращении к информационному ресурсу World Wide Web по универсальному идентификатору этого ресурса (URI, URL).
Страницей-формой
будем называть в данном контексте файл в формате HTML, который содержит в себе HTML-форму.
После обращения к странице-форме, как правило, следует вызов либо API-модуля, встроенного в сервер, либо CGI-программы. В свою очередь такое действие вызывает генерацию этим модулем или программой виртуальной страницы.
Структура базы данных сервера WWW
Итак первой основной задачей для любого сервера является ведение его базы данных. База данных сервера - это часть файловой системы, отведенная для размещения файлов HTML-документов. Большинство современных файловых систем - это иерархические деревья, следовательно, и база данных HTTP-сервера также является таким деревом. Для любой базы данных необходимо ввести понятие единицы хранения - минимальный объект, к которому можно обратиться извне или получить в качестве ответа на запрос. Стандартным объектом хранения в базе данных HTTP-сервера является HTML-документ, который является обычном текстовым файлом. Кроме такого стандартного объекта многие серверы поддерживают различные комбинированные объекты хранения, создаваемые в ряде случаев из нескольких файлов или генерируемые программами "на лету".
Если обратиться к терминологии, которая принята в системах World Wide Web, то можно выделить следующие основные объекты, с которыми оперирует сервер и программа-клиент:
Структура запросов
Для того, чтобы можно было более или менее точно рассказать про структуру запросов в стандарте SQL/89, необходимо начать со сводки синтаксических правил:
<cursor specification> ::= <query expression> [<order by clause>] <query expression> ::= <query term> <query expression> UNION [ALL] <query term> <query term> ::= <query specification> (<query expression>) <query specification> ::= (SELECT [ALL DISTINCT] <select list> <table expression>) <select statement> ::= SELECT [ALL DISTINCT] <select list> INTO <select target list> <table expression> <subquery> ::= (SELECT [ALL DISTINCT] <result specification> <table expression> <table expression> ::= <from clause> [<where clause>] [<group by clause>] [<having clause>]
Язык допускает три типа синтаксических конструкций, начинающихся с ключевого слова SELECT: спецификация курсора (cursor specification), оператор выборки (select statement) и подзапрос (subquery). Основой всех них является синтаксическая конструкция "табличное выражение (table expression)". Семантика табличного выражения состоит в том, что на основе последовательного применения разделов from, where, group by и having из заданных в разделе from таблиц строится некоторая новая результирующая таблица, порядок следования строк которой неопределен и среди строк которой могут находиться дубликаты (т.е. в общем случае таблица-результат табличного выражения является мультимножеством строк). На самом деле именно структура табличного выражения наибольшим образом характеризует структуру запросов языка SQL/89. Мы рассмотрим структуру и смысл разделов табличного выражения ниже, но до этого немного подробнее обсудим три упомянутые конструкции, включающие табличные выражения.
Сущность (Entity)
- реальный либо воображаемый объект, имеющий существенное значение для рассматриваемой предметной области, информация о котором подлежит хранению (рисунок 4.1).

Рис. 4.1. Графическое изображение сущности
Каждая сущность должна обладать уникальным идентификатором. Каждый экземпляр сущности должен однозначно идентифицироваться и отличаться от всех других экземпляров данного типа сущности. Каждая сущность должна обладать некоторыми свойствами:
каждая сущность должна иметь уникальное имя, и к одному и тому же имени должна всегда применяться одна и та же интерпретация. Одна и та же интерпретация не может применяться к различным именам, если только они не являются псевдонимами; сущность обладает одним или несколькими атрибутами, которые либо принадлежат сущности, либо наследуются через связь; сущность обладает одним или несколькими атрибутами, которые однозначно идентифицируют каждый экземпляр сущности; каждая сущность может обладать любым количеством связей с другими сущностями модели.
Обращаясь к приведенным выше выдержкам из интервью, видно, что сущности, которые могут быть идентифицированы с главным менеджером - это автомашины и продавцы. Продавцу важны автомашины и связанные с их продажей данные. Для администратора важны покупатели, автомашины, продавцы и контракты. Исходя из этого, выделяются 4 сущности (автомашина, продавец, покупатель, контракт), которые изображаются на диаграмме следующим образом (рисунок 4.2).
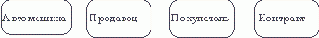
Рис. 4.2.
Следующим шагом моделирования является идентификация связей.
Связь (Relationship)
- поименованная ассоциация между двумя сущностями, значимая для рассматриваемой предметной области. Связь - это ассоциация между сущностями, при которой, как правило, каждый экземпляр одной сущности, называемой родительской сущностью, ассоциирован с произвольным (в том числе нулевым) количеством экземпляров второй сущности, называемой сущностью-потомком, а каждый экземпляр сущности-потомка ассоциирован в точности с одним экземпляром сущности-родителя. Таким образом, экземпляр сущности-потомка может существовать только при существовании сущности родителя.
Связи может даваться имя, выражаемое грамматическим оборотом глагола и помещаемое возле линии связи. Имя каждой связи между двумя данными сущностями должно быть уникальным, но имена связей в модели не обязаны быть уникальными. Имя связи всегда формируется с точки зрения родителя, так что предложение может быть образовано соединением имени сущности-родителя, имени связи, выражения степени и имени сущности-потомка.
Например, связь продавца с контрактом может быть выражена следующим образом:
продавец может получить вознаграждение за 1 или более контрактов; контракт должен быть инициирован ровно одним продавцом.
Степень связи и обязательность графически изображаются следующим образом (рисунок 4.3).
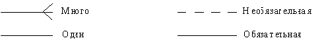
Рис. 4.3.
Таким образом, 2 предложения, описывающие связь продавца с контрактом, графически будут выражены следующим образом (рисунок 4.4).
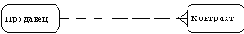
Рис. 4.4.
Описав также связи остальных сущностей, получим следующую схему (рисунок 4.5).
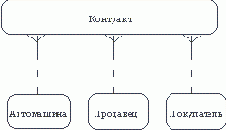
Рис.4.5.
Последним шагом моделирования является идентификация атрибутов.
по сравнению со стандартом
В стандарте SQL/ 92 по сравнению со стандартом SQL/89 язык был расширен главным образом количественно, хотя даже этих количественных расширений оказалось достаточно для того, чтобы стандарт SQL/92 не удалось полностью реализовать до сих пор. Поскольку SQL/92 не удовлетворял значительной части претензий, исторически предъявляемых к языку SQL, был сформирован новый комитет, который должен выработать стандарт языка с качественными расширениями. Язык SQL-3 пока не сформирован полностью, многие аспекты продолжают обсуждаться. Поэтому к приводимой здесь сводке возможностей нужно относиться как к сугубо предварительной.
Sybase
Стратегия компании в области складов данных основывается на разработанной ей архитектуре Warehouse WORKS. В основе подхода находится реляционная СУБД Sybase System 11, средство для подключения и доступа к базам данных OmniCONNECT и средство разработки приложений PowerBuilder. Компания продолжает совершенствовать свою СУБД для лучшего удовлетворения потребностей складов данных (например, введена побитная индексация).
Таблица - на подтип
| Преимущества | |
| Все хранится вместе
Легкий доступ к супертипу и подтипам Требуется меньше таблиц | Более ясны правила подтипов
Программы работают только с нужными таблицами |
| Недостатки | |
| Слишком общее решение
Требуется дополнительная логика работы с разными наборами столбцов и разными ограничениями Потенциальное узкое место (в связи с блокировками) Столбцы подтипов должны быть необязательными В некоторых СУБД для хранения неопределенных значений требуется дополнительная память | Слишком много таблиц
Смущающие столбцы в представлении UNION Потенциальная потеря производительности при работе через UNION Над супертипом невозможны модификации |
Таблица удовлетворяет проверочному
Замечание: В некоторых реализациях допускаются расширенные механизмы ограничений по ссылкам и проверочных ограничений. Следует быть внимательным, если не желать выходить за пределы возможностей стандарта.
Табличное выражение
Стандарт SQL/89 рекомендует рассматривать вычисление табличного выражения как последовательное применение разделов FROM, WHERE, GROUP BY и HAVING к таблицам, заданным в списке FROM. Раздел FROM имеет следующий синтаксис:
<from clause> ::= FROM <table reference> ({,<table reference>}...] <table reference> ::= <table name> [<correlation name>]
TCP
Теорема Фейджина
Отношение R (A, B, C) можно спроецировать без потерь в отношения R1 (A, B) и R2 (A, C) в том и только в том случае, когда существует MVD A -->> B C.
Под проецированием без потерь понимается такой способ декомпозиции отношения, при котором исходное отношение полностью и без избыточности восстанавливается путем естественного соединения полученных отношений.
TFTP
| Простой протокол пересылки файлов (Trivial File Transfer Protocol) |
В наиболее стандартной на сегодняшний день реализации UNIX System V Release 4 протокол TCP/IP реализован как набор специализированных потоковых модулей плюс дополнительный компонент TLI (Transport Level Interface - Интерфейс транспортного уровня). TLI является интерфейсом между прикладной программой и транспортным механизмом. Приложение, пользующееся интерфейсом TLI, получает возможность использовать TCP/IP.
Интерфейс TLI основан на использовании классической семиуровневой модели ISO/OSI, которая разделяет сетевые функции на семь областей, или уровней. Цель модели в обеспечении стандарта сетевой связи компьютеров независимо от производителя аппаратуры компьютеров и/или сети. Семь уровней модели можно кратко описать следующим образом:
Типы данных
Набор встроенных типов данных предполагается расширить типами BOOLEAN и ENUMERATED. Хотя по причине поддержки неопределенных значений языку SQL свойственно применение трехзначной логики, тип BOOLEAN содержит только два возможных значения true и false. Для представления значения unknown рекомендуется использовать NULL, что, конечно, не вполне естественно. Перечисляемый тип ENUMERATED обладает свойствами, подобными свойствам перечисляемых типов в языках программирования.
Расширены возможности работы с неопределенными значениями. Появился новый оператор CREATE NULL CLASS, позволяющий ввести именованный набор именованных неопределенных значений. При определении домена можно явно указать имя класса неопределенных значений, появление которых допустимо в столбцах, связанных с этим доменом. Смысл каждого неопределенного значения интерпретируется на уровне пользователей.
Предполагается включение в язык возможности использовать определенные пользователями типы данных. Видимо, будут иметься возможности определения абстрактных типов данных с произвольно сложной внутренней структурой на основе таких традиционных способов агрегирования и структуризации как LIST, ARRAY, SET, MULTISET и TUPLE, а также возможности определения объектных типов с соответствующими методами в стиле объектно-ориентированного подхода.
Появляется возможность использования принципов наследования свойств существующей таблицы (супертаблицы) при определении новой таблицы (подтаблицы). Подтаблица наследует от супертаблицы все определения столбцов и первичного ключа. Другая возможность - создать таблицу, "подобную" существующей в том смысле, что в новой таблице наследуются определения некоторых столбцов существующей таблицы.
Литеральные значения приблизительных чисел в общем случае представляются в виде <литеральное-значение-точного-числа>E<целое-со-знаком>.
Заметим, что хотя с использованием языка SQL можно определить схему БД, содержащую данные любого из перечисленных типов, возможность использования этих данных в прикладных системах зависит от применяемого языка программирования. Весь набор типов данных можно использовать, только если программировать на ПЛ/1. Поэтому в некоторых реализациях SQL типы данных с масштабом и точностью вообще не поддерживаются.
Хотя правила встраивания SQL в программы на языке Си не определены в SQL/89, в большинстве реализаций, поддерживающих такое встраивание, имеется следующее соответствие между типами данных SQL и типами данных Си: CHARACTER соответствует строкам Си; INTEGER соответствует long; SMALLINT соответствует short; REAL соответствует float; DOUBLE PRECISION соответствует double (именно такое соответствие утверждено в стандарте SQL/92).
Заметим еще, что в большинстве реализаций SQL поддерживаются некоторые дополнительные типы данных, например, DATE, TIME, INTERVAL, MONEY. Некоторые из этих типов специфицированы в стандарте SQL/92, но в текущих реализациях синтаксические и семантические свойства таких типов могут различаться.
Типы информационных ресурсов
Информация в FTP-архивах разделена на три категории:
Защищенная информация, режим доступа к которой определяется ее владельцами и разрешается по специальному соглашению с потребителем. К этому виду ресурсов относятся коммерческие архивы (например, коммерческие версии программ в архивах ftp.microsoft.com или ftp.bsdi.com), закрытые национальные и международные некоммерческие ресурсы (например, работы по международным проектам CES или IAEA), частная некоммерческая информация со специальными режимами доступа (частные благотворительные фонды, например). Информационные ресурсы ограниченного использования, к которым относятся, например, программы класса shareware (Trumpet Winsock, Atis Mail, Netscape, и т.п.). В данный класс могут входить ресурсы ограниченного времени использования (текущая версия Netscape перестанет работать в июне если только кто-то не сломает защиту) или ограниченного времени действия, т.е. пользователь может использовать текущую версию на свой страх и риск, но никто не будет оказывать ему поддержку. Свободно распространяемые информационные ресурсы или freeware, если речь идет о программном обеспечении. К этим ресурсам относится все, что можно свободно получить по сети без специальной регистрации. Это может быть документация, программы или что-либо еще. Наиболее известными свободно распространяемыми программами являются программы проекта GNU Free Software Foundation. Следует отметить, что свободно распространяемое программное обеспечение не имеет сертификата качества, но как правило, его разработчики открыты для обмена опытом.
Из выше перечисленных ресурсов наиболее интересными, по понятным причинам, являются две последних категории, которые, как правило, оформлены в виде FTP-архивов.
Технология FTP была разработана в рамках проекта ARPA и предназначена для обмена большими объемами информации между машинами с различной архитектурой. Главным в проекте было обеспечение надежной передачи и поэтому с современной точки зрения FTP кажется перегруженным излишними редко используемыми возможностями. Стержень технологии составляет FTP-протокол.
Традиционные средства и методологии разработки файл-серверных приложений
Пожалуй, стоит отметить, что хотя для разработки файл-серверных приложений имеется целый ряд инструментальных средств, отсутствуют общепринятые методологии. Вернее сказать, что когда методологии используются, то они те же, что в к клиент-серверных приложениях. Обычно же файл-серверные приложения проектируются и разрабатываются "по месту" без использования каких-либо стандартных методов.
Требования к техническим средствам, поддерживающим ИС
Естественно, что требования к техническим средствам определяются требованиями к информационной системе в целом. Какие бы информационные возможности не требовались сотрудникам корпорации, окончательное решение всегда принимается ее руководством, которое корректирует требования к информационной системе и формирует окончательное представление об аппаратной среде. На наш взгляд, имеются четыре возможных позиции руководства по поводу места информационной системы в корпорации: пессимистическая, пессимистически-оптимистическая, оптимистически-пессимистическая и оптимистическая.
Руководитетель-пессимист рассуждает следующим образом. Корпорации нужно продержаться хотя бы какое-то время. Без информационной системы это невозможно. Нужно выбрать самое дешевое решение, которое может быть реализовано максимально быстро. Руководитель не думает, что будет с корпорацией через два года (вернее, поскольку он пессимист, то думает, что, скорее всего, через два года корпорация просто не будет существовать или у нее сменится руководитель). При такой позиции наиболее подходящим является некоторое закрытое и законченное техническое решение. Например, это может быть полностью сбалансированная локальная сеть Novell с выделенным файл-сервером и фиксированным числом рабочих станций. Жесткость решения затем закрепляется соответствующим программным обеспечением информационной системы. Возможности расширения системы отсутствуют, реинжиниринг требует практически полной переделки системы.
Пессимистически-оптимистический руководитель не ожидает краха корпорации или своего собственного увольнения. Но он не надеется на изменение статуса компании, например, на появление зарубежных филиалов. Возможно, корпорация будет несколько развиваться, возможно, появятся новые виды бизнеса, возможно, увеличится число сотрудников. Но поскольку руководитель все-таки более пессимист, чем оптимист, то он не очень высоко оценивает шансы на развитие (дай-то Бог, чтобы за два года мы выросли на 20%). Такой позиции руководства больше всего подходит закрытое решение, обладающее ограниченными возможностями расширения.
Например, это может быть локальная сеть Novell, в которой пропускная способность превосходит потребности имеющихся рабочих станций, а файл-сервер может быть оснащен дополнительными магнитными дисками. Если пессимизм руководителя окажется неоправданным, то корпорация встретится с потребностью сложного реинжиниринга.
Руководитель с оптимистически-пессимистической позицией ставит своей целью развитие корпорации. Он учитывает, что при развитии корпорации потребуется соответствующее развитие информационной системы, для чего, вообще говоря, может понадобиться сменить сервер баз данных. Он учитывает, что при развитии корпорации могут образоваться территориально разнесенные офисы, в результате чего, возможно, потребуется перейти к использованию распределенной базы данных. Он учитывает, в конце концов, что корпорации могут потребоваться развитые средства телекоммуникации с удаленными филиалами и/или партнерами. Пессимизм руководителя состоит только в том, что он заранее делает ставку на одного производителя (эти-то продукты я знаю). Например, может быть сделана установка на использование только Intel-платформ в среде Microsoft или только Alpha-платформ с VAX/VMS. Вообще говоря, это здоровый пессимизм, поскольку однородность аппаратно-программной среды существенно облегчает ее администрирование. Но как обидно будет этому руководителю, если ему предложат дешево купить прекрасный аппаратный продукт другого производителя. Придется либо отказаться, либо снова производить изнурительный реинжиниринг.
Наконец, руководитель-оптимист разделяет позицию оптимистически-пессимистического руководителя по поводу перспектив развития корпорации, но при этом желает сохранить возможность использования различных аппаратных платформ. Он стимулирует построение открытой корпоративной информационной системы, которая может неограниченно наращиваться за счет подключения новых сегментов сети, включения новых серверов и рабочих станций. Оптимистический подход, естественно, требует применения международных стандартов, что облегчает комплексирование аппаратного комплекса и обеспечивает реальное масштабирование информационной системы.
Если начать построение корпоративной системы с сети Ethernet с использованием стека протоколов TCP/IP, то это начало оптимистического решения. В этом случае проблемы реинжиниринга практически отсутствуют (пока не сменятся стандарты).
Конечно, приведенная классификация является несколько утрированной. В жизни все гораздо сложнее. В частности, нельзя не учитывать влияние на руководителя технических специалистов. Чем грамотнее составляется обоснование на приобретение технических средств, тем обоснованнее оптимизм или пессимизм руководителя. Конечно, многое определяется возможными денежными затратами. Но стоит заметить, что оптимистический подход (по сути дела, это подход открытых систем) требует минимальных затрат на начальном этапе становления корпоративной системы (если, конечно, не учитывать необходимость приобретения хорошего программного сервера баз данных).
Главный вывод этого раздела состоит в том, что выбор технических средств для построения корпоративной информационной системы - это непростая задача, включающая технические, политические и эмоциональные аспекты. Ни в коем случае комплексирование аппаратуры нельзя пускать на самотек. Простой пример. Многие считают, что чем больше тактовая частота аппаратного сервера баз данных, то тем быстрее будет работать СУБД. Вообще говоря, это неправильно. Быстродействие любого сервера баз данных в основном определяется объемом основной памяти и/или числом процессоров. Другими словами, с одинаковой тщательностью нужно относиться и к выбору общей аппаратной архитектуры системы, и к выбору конфигурации каждого из ее компонентов.
Назад | Содержание | Вперед
Трехзвенные архитектуры (Web-ориентированные)
Ориентация на использование Web-технологии позволяет одновременно добиться двух эффектов. Во-первых, за счет использования CGI или API можно перенести на сторону сервера часть логики приложения. Во-вторых, используя технику шлюзования Web-сервера (опять же применяя CGI-шлюзы или API) можно работать через Web-сервер (в стандартном интерфейсе) с другими серверами. Клиента можно сделать очень "тонким", Web-сервер будет достаточно "толстым", а уж остальные такими, как велит судьба (рисунок 5.10).

Рис. 5.10. "Тонкий" клиент, "толстый" Web-сервер и сравнительно "стройный" дополнительный сервер
Третьем уровне
находятся клиентские рабочие места конечных пользователей, на которых устанавливаются средства оперативного анализа данных.
Третья нормальная форма
Рассмотрим еще раз отношение СОТРУДНИКИ-ОТДЕЛЫ, находящееся в 2NF. Заметим, что функциональная зависимость СОТР_НОМЕР --> СОТР_ЗАРП является транзитивной; она является следствием функциональных зависимостей СОТР_НОМЕР --> ОТД_НОМЕР и ОТД_НОМЕР --> СОТР_ЗАР. Другими словами, заработная плата сотрудника на самом деле является характеристикой не сотрудника, а отдела, в котором он работает (это не очень естественное предположение, но достаточное для примера).
В результате мы не сможем занести в базу данных информацию, характеризующую заработную плату отдела, до тех пор, пока в этом отделе не появится хотя бы один сотрудник (первичный ключ не может содержать неопределенное значение). При удалении кортежа, описывающего последнего сотрудника данного отдела, мы лишимся информации о заработной плате отдела. Чтобы согласованным образом изменить заработную плату отдела, мы будем вынуждены предварительно найти все кортежи, описывающие сотрудников этого отдела. Т.е. в отношении СОТРУДНИКИ-ОТДЕЛЫ по-прежнему существуют аномалии. Их можно устранить путем дальнейшей нормализации.
UDP
Укрупнение приложений (Upsigsing)
Пакет Microsoft Access Upsizing Tools позволяет автоматизировать процесс перехода от настольных баз данных к архитектуре клиент-сервер, в данном случае - от Microsoft Access к Microsoft SQL Server для Windows NT. Данный продукт добавляет к Access такие модули, как Upsizing Wizard и SQL Server Browser. Upsizing Wizard позволяет задать все параметры процесса переноса данных с помощью серии диалогов, а затем создает саму базу данных, журнал транзакций, таблицы, индексы, правила проверок значений данных, отношения между таблицами и поля типа timestamp (временная метка). Browser позволяет управлять объектами Access Server с помощью Access-подобного интерфейса. В комплект поставки также входит дискета с ODBC 2.0 и ODBC-драйвером для Microsoft SQL Server. База данных Access (файл с расширением .MDB) содержит таблицы данных и индексы, а также компоненты управления данными (запросы, макросы, модули, формы и отчеты).
Применение Microsoft Access Upsizing Tools основывается на концепции прозрачного для пользователя размещения данных: перенос информации в базу данных SQL Server при сохранении в исходном виде остальной части Access MDB. Access способен работать в качестве клиента в архитектуре клиент-сервер, поэтому разработчикам, переносящим приложения с помощью этого инструмента, не нужно отказываться от Access. Запросы, отчеты и прочие объекты остаются в неизменном виде, так как Upsizing Wizard перенаправляет их на экспортированные таблицы, переименовывая при этом локальные таблицы.
Upsizing Wizard учитывает при переносе ряд архитектурных различий между Microsoft Access и SQL Server для Windows NT. Он экспортирует таблицы и их свойства, такие как правила проверок, значения по умолчанию и индексы. Он выполняет такие операции, как добавление поля типа timestamp, преобразование отношений между таблицами Access в триггеры, поддерживающие ссылочную целостность, и даже создание INSERT-триггеров для аналогов автоинкрементируемых полей Access типа Counter. Upsizing Wizard не экспортирует из базы данных Access сведения о пользователях, группах и правах доступа, поэтому администратор базы данных должен устанавливать права доступа вручную. Upsizing Wizard создает подробный отчет, содержащий имена баз данных и размеры, параметры переноса, триггеры, таблицы (старые и новые), а также информацию об ошибках, возникших в процессе работы.
Модули Microsoft Wizard - это инструменты для автоматизации операций, направляющие действия пользователя в нужной последовательности. Access Upsizing Wizard не является примитивным продуктом, так как пользователю может понадобиться вручную конфигурировать систему для обеспечения нормальной работы, но, несмотря на это, покупка Microsoft Access Upsizing Tools будет оправдана для тех, кому необходимо перемещать данные из Access в SQL Server. Эта программа автоматизирует большинство рутинных моментов процесса, которые могут оказаться утомительными и нетривиальными, а документация включает специальный раздел по оптимизации использования Microsoft Access в качестве клиента в приложениях типа клиент-сервер.
Uniface
Uniface 6.1 - продукт фирмы Compuware (США) - представляет собой среду разработки крупномасштабных приложений в архитектуре "клиент-сервер" и имеет следующую компонентную архитектуру:
Application Objects Repository (репозиторий объектов приложений) со-держит метаданные, автоматически используемые всеми остальными компонен-тами на протяжении жизненного цикла информационной системы (прикладные модели, описания данных, бизнес-правил, экранных форм, глобальных объектов и шаблонов). Репозиторий может храниться в любой из баз данных, поддерживаемых Uniface; Application Model Manager поддерживает прикладные модели (E-R модели), каждая из которых представляет собой подмножество общей схемы БД с точки зрения данного приложения, и включает соответствующий графический редактор; Rapid Application Builder - средство быстрого создания экранных форм и отчетов на базе объектов прикладной модели. Оно включает графический ре-дактор форм, средства прототипирования, отладки, тестирования и документи-рования. Реализован интерфейс с разнообразными типами оконных элементов управления (Open Widget Interface) для существующих графических интерфейсов - MS Windows (включая VBX), Motif, OS/2. Универсальный интерфейс представления (Universal Presentation Interface) позволяет использовать одну и ту же версию приложения в среде различных графических интерфейсов без изменения программного кода; Developer Services (службы разработчика) - используются для поддержки крупных проектов и реализуют контроль версий (Uniface Version Control System), права доступа (разграничение полномочий), глобальные мо-дификации и т.д. Это обеспечивает разработчиков средствами параллельного проектирования, входного и выходного контроля, поиска, просмотра, поддержки и выдачи отчетов по данным системы контроля версий; Deployment Manager (управление распространением приложений) - средства, позволяющие подготовить созданное приложение для распространения, устанавливать и сопровождать его (при этом платформа пользователя может отличаться от платформы разработчика).
В их состав входят сетевые драйверы и драйверы СУБД, сервер приложений (полисервер), средства распространения приложений и управления базами данных. Uniface поддерживает интерфейс практически со всеми известными программно-аппаратными платформами, СУБД, CASE-средствами, сетевыми протоколами и менеджерами транзакций; Personal Series (персональные средства) - используются для создания сложных запросов и отчетов в графической форме (Personal Query и Personal Access - PQ/PA), а также для переноса данных в такие системы, как WinWord и Excel; Distributed Computing Manager - средство интеграции с менеджерами транзакций Tuxedo, Encina, CICS, OSF DCE.
Объявленная в конце 1996 г. версия Uniface 7 полностью поддерживает распределенную модель вычислений и трехзвенную архитектуру "клиент-сервер" (с возможностью изменения схемы декомпозиции приложений на этапе исполнения). Приложения, создаваемые с помощью Uniface 7, могут исполняться в гетерогенных операционных средах, использующих различные сетевые протоколы, одновременно на нескольких разнородных платформах (в том числе и в Internet).
В состав компонент Uniface 7 входят:
Uniface Application Server - сервер приложений для распределенных систем; WebEnabler - серверное программное обеспечение для эксплуатации приложений в Internet и Intrаnet; Name Server - серверное программное обеспечение, обеспечивающее использование распределенных прикладных ресурсов; PolyServer - средство доступа к данным и интеграции различных систем.
В список поддерживаемых СУБД входят DB2, VSAM и IMS; PolyServer обеспечивает также взаимодействие с ОС MVS.
Среда функционирования Uniface - все основные UNIX - платформы и MS Windows.
Уникальный идентификатор
- это атрибут или совокупность атрибутов и/или связей, предназначенная для уникальной идентификации каждого экземпляра данного типа сущности. В случае полной идентификации каждый экземпляр данного типа сущности полностью идентифицируется своими собственными ключевыми атрибутами, в противном случае в его идентификации участвуют также атрибуты другой сущности-родителя (рисунок 4.7).
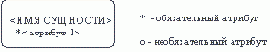
Рис. 4.6.

Рис. 4.7.
Каждый атрибут идентифицируется уникальным именем, выражаемым грамматическим оборотом существительного, описывающим представляемую атрибутом характеристику. Атрибуты изображаются в виде списка имен внутри блока ассоциированной сущности, причем каждый атрибут занимает отдельную строку. Атрибуты, определяющие первичный ключ, размещаются наверху списка и выделяются знаком "#".
Каждая сущность должна обладать хотя бы одним возможным ключом. Возможный ключ сущности - это один или несколько атрибутов, чьи значения однозначно определяют каждый экземпляр сущности. При существовании нескольких возможных ключей один из них обозначается в качестве первичного ключа, а остальные - как альтернативные ключи.
С учетом имеющейся информации дополним построенную ранее диаграмму (рисунок 4.8).
Помимо перечисленных основных конструкций модель данных может содержать ряд дополнительных.
Управление буферами оперативной памяти
Серверы баз данных обычно работают с БД значительного размера; по крайней мере этот размер обычно существенно больше доступного объема оперативной памяти. Понятно, что если при обращении к любому элементу данных будет производиться обмен с внешней памятью, то вся система будет работать со скоростью устройства внешней памяти. Практически единственным способом реального увеличения этой скорости является буферизация данных в оперативной памяти. При этом, даже если операционная система производит общесистемную буферизацию (как в случае ОС UNIX), этого недостаточно для целей СУБД, которая располагает гораздо большей информацией о полезности буферизации той или иной части БД. Поэтому в развитых СУБД поддерживается собственный набор буферов оперативной памяти с собственной дисциплиной замены буферов.
Заметим, что существует отдельное направление СУБД, которое ориентировано на постоянное присутствие в оперативной памяти всей БД. Это направление основывается на предположении, что в будущем объем оперативной памяти компьютеров сможет быть настолько велик, что позволит не беспокоиться о буферизации. Пока эти работы находятся в стадии исследований.
Управление транзакциями
Транзакция - это последовательность операций над БД, рассматриваемых СУБД как единое целое. Либо транзакция успешно выполняется, и СУБД фиксирует (COMMIT) изменения БД, произведенные этой транзакцией, во внешней памяти, либо ни одно из этих изменений никак не отражается в состоянии БД. Понятие транзакции необходимо для поддержания логической целостности БД. Если воспользоваться примером информационной системы с файлами СОТРУДНИКИ и ОТДЕЛЫ, то единственным способом не нарушить целостность БД при выполнении операции приема на работу нового сотрудника является объединение элементарных операций над файлами СОТРУДНИКИ и ОТДЕЛЫ в одну транзакцию. Таким образом, поддержание механизма транзакций является обязательным условием даже однопользовательских СУБД (если, конечно, такая система заслуживает названия СУБД). Но понятие транзакции гораздо более важно в многопользовательских СУБД.
То свойство, что каждая транзакция начинается при целостном состоянии БД и оставляет это состояние целостным после своего завершения, делает очень удобным использование понятия транзакции как единицы активности пользователя по отношению к БД. При соответствующем управлении параллельно выполняющимися транзакциями со стороны СУБД каждый из пользователей может в принципе ощущать себя единственным пользователем СУБД (на самом деле, это несколько идеализированное представление, поскольку в некоторых случаях пользователи многопользовательских СУБД могут ощутить присутствие своих коллег).
С управлением транзакциями в многопользовательской СУБД связаны важные понятия сериализации транзакций и сериального плана выполнения смеси транзакций. Под сериализаций параллельно выполняющихся транзакций понимается такой порядок планирования их работы, при котором суммарный эффект смеси транзакций эквивалентен эффекту их некоторого последовательного выполнения. Сериальный план выполнения смеси транзакций - это такой план, который приводит к сериализации транзакций. Понятно, что если удается добиться действительно сериального выполнения смеси транзакций, то для каждого пользователя, по инициативе которого образована транзакция, присутствие других транзакций будет незаметно (если не считать некоторого замедления работы по сравнению с однопользовательским режимом).
Существует несколько базовых алгоритмов сериализации транзакций. В централизованных СУБД наиболее распространены алгоритмы, основанные на синхронизационных захватах объектов БД. При использовании любого алгоритма сериализации возможны ситуации конфликтов между двумя или более транзакциями по доступу к объектам БД. В этом случае для поддержания сериализации необходимо выполнить откат (ликвидировать все изменения, произведенные в БД) одной или более транзакций. Это один из случаев, когда пользователь многопользовательской СУБД может реально (и достаточно неприятно) ощутить присутствие в системе транзакций других пользователей.
URL
(Universal Resource Locator) - универсальный локатор ресурсов. Используется в качестве универсальной схемы адресации ресурсов в сети.
Уровень Физический уровень (Physical Level)
- среда передачи (например, Ethernet). Уровень отвечает за передачу неструктурированных данных по сети.
Уровень Канальный уровень (Data Link Layer)
- уровень драйвера устройства, называемый также уровнем ARP/RARP в TCP/IP. Этот уровень, в частности, отвечает за преобразование данных при исправлении ошибок, происходящих на физическом уровне.
Уровень Сетевой уровень (Network Level)
- отвечает за выполнение промежуточных сетевых функций, таких как поиск коммуникационного маршрута при отсутствии возможности прямой связи между узлом-отправителем и узлом-получателем. В TCP/IP этот уровень соответствует протоколам IP и ICMP.
Уровень Транспортный уровень (Transport Level)
- уровень протоколов TCP/IP или UDP/IP семейства протоколов TCP/IP. Уровень отвечает за разборку сообщения на фрагменты (пакеты) при передаче и за сборку полного сообщения из пакетов при приеме таким образом, что на более старших уровнях модели эти процедуры вообще незаметны. Кроме того, на этом уровне выполняется посылка и обработка подтверждений и, при необходимости, повторная передача.
Уровень Уровень представлений (Presentation Layer)
- отвечает за управление представлением информации. В NFS на этом уровне реализуется механизм внешнего представления данных (XDR - External Data Representation), машинно-независимого представления, понятного для всех компьютеров, входящих в сеть.
Уровень Уровень приложений
- интерфейс с такими сетевыми приложениями как telnet, rlogin, mail и т.д.
Интерфейс TLI соответствует трем старшим уровням этой модели (с пятого по седьмой) и позволяет прикладному процессу пользоваться сервисами сети без необходимости знать о деталях транспортного и более низких уровней. В System V Release 4 TLI реализован на основе механизма потоков. Для доступа используются не специальные системные вызовы, а функции библиотеки /usr/lib/libnsl_s.a.
Уровень Уровень сессий (Session Layer)
- отвечает за управление переговорами взаимодействующих транспортных уровней. В NFS этот уровень используется для реализации механизма вызовов удаленных процедур.
Userclient
- это программа просмотра конкретного информационного ресурса. В настоящее время наиболее популярны мультипротокольные программы типа Netscape Navigator. Такая программа обеспечивает просмотр документов World Wide Web, Gopher, Wais, FTP-архивов, почтовых списков рассылки и групп новостей Usenet. В свою очередь все эти информационные ресурсы являются объектом поиска информационно-поисковой системы.
Userinterface
- интерфейс пользователя - это не просто программа просмотра. В случае информационно-поисковой системы под этим словосочетанием понимают и способ общения пользователя с поисковым аппаратом системы, т.е. с системой формирования запросов и просмотров результатов поиска. Просмотр результатов поиска и информационных ресурсов сети - это совершенно разные вещи, на которых остановимся чуть позже.
Vantage Team Builder for Uniface
| Сущность-связь | ERD | + | + | + |
| Потоков данных | DFD | + | + | + |
| Структур данных | DSD | + | + | + |
| Архитектуры системы | SAD | + | + | + |
| Потоков управления | CSD | + | + | + |
| Типов данных | DTD | + | + | + |
| Структуры меню | MSD | + | ||
| Последовательности блоков | BSD | + | ||
| Последовательности форм | FSD | + | + | |
| Содержимого форм | FCD | + | + | |
| Переходов состояний | STD | + | + | + |
| Структурных схем | SCD | + | + | + |
При построении всех типов диаграмм обеспечивается контроль соответствия моделей синтаксису используемых методов, а также контроль соответствия одноименных элементов и их типов для различных типов диаграмм.
При построении DFD обеспечивается контроль соответствия диаграмм различных уровней декомпозиции. Контроль за правильностью верхнего уровня DFD осуществляется с помощью матрицы списков событий (ELM). Для контроля за декомпозицией составных потоков данных используется несколько вариантов их описания: в виде диаграмм структур данных (DSD) или в нотации БНФ (форма Бэкуса-Наура).
Для построения SAD используется расширенная нотация DFD, дающая возможность вводить понятия процессоров, задач и периферийных устройств, что обеспечивает наглядность проектных решений.
При построении модели данных в виде ER-диаграмм выполняется ее нормализация и вводится определение физических имен элементов данных и таблиц, которые будут использоваться в процессе генерации физической схемы данных конкретной СУБД. Обеспечивается возможность определения альтернативных ключей сущностей и полей, составляющих дополнительные точки входа в таблицу (поля индексов), и мощности отношений между сущностями.
Наличие универсальной системы генерации кода, основанной на специфицированных средствах доступа к репозиторию проекта, позволяет поддерживать высокий уровень исполнения проектной дисциплины разработчиками: жесткий порядок формирования моделей; жесткая структура и содержимое документации; автоматическая генерация исходных кодов программ и т.д. - все это обеспечивает повышение качества и надежности разрабатываемых информационных систем.
Для подготовки проектной документации могут использоваться издательские системы FrameMaker, Interleaf или Word Perfect.
Структура и состав проектной документации могут быть настроены в соответствии с заданными стандартами. Настройка выполняется без изменения проектных решений.
При разработке достаточно крупной информационной системы вся система в целом соответствует одному проекту как категории Vantage Team Builder. Проект может быть декомпозирован на ряд систем, каждая из которых соответствует некоторой относительно автономной подсистеме информационных систем и разрабатывается независимо от других. В дальнейшем системы проекта могут быть интегрированы.
Процесс проектирования информационных систем с использованием Vantage Team Builder реализуется в виде 4-х последовательных фаз (стадий) - анализа, архитектуры, проектирования и реализации, при этом законченные результаты каждой стадии полностью или частично переносятся (импортируются) в следующую фазу. Все диаграммы, кроме ER-диаграмм, преобразуются в другой тип или изменяют вид в соответствии с особенностями текущей фазы. Так, DFD преобразуются в фазе архитектуры в SAD, DSD - в DTD. После завершения импорта логическая связь с предыдущей фазой разрывается, т.е. в диаграммы могут вноситься все необходимые изменения.
Взаимодействие с другими средствами
Конфигурация Vantage Team Builder for Uniface обеспечивает совместное исполь-зование двух систем в рамках единой технологической среды проектирования, при этом схемы БД (SQL-модели) переносятся в репозиторий Uniface, и, наоборот, прикладные модели, сформированные средствами Uniface, могут быть перенесены в репозиторий Vantage Team Builder. Возможные рассогласования между репозиториями двух систем устраняются с помощью специальной утилиты. Разработка экранных форм в среде Uniface выполняется на базе диаграмм последовательностей форм (FSD) после импорта SQL-модели. Технология разработки информационной системы на базе данной конфигурации показана на рисунке 4.25.
Структура репозитория (хранящегося непосредственно в целевой СУБД) и интерфейсы Vantage Team Builder являются открытыми, что в принципе позволяет интеграцию с любыми другими средствами.
Vantage Team Builder (Westmount I-CASE)
Vantage Team Builder представляет собой интегрированный программный продукт, ориентированный на реализацию каскадной модели жизненного цикла программного обеспечения и поддержку полного жизненного цикла программного обеспечения.
Структура и функции
Vantage Team Builder обеспечивает выполнение следующих функций:
проектирование диаграмм потоков данных, "сущность-связь", структур данных, структурных схем программ и последовательностей экранных форм; проектирование диаграмм архитектуры системы - SAD (проектирование состава и связи вычислительных средств, распределения задач системы между вычислительными средствами, моделирование отношений типа "клиент-сервер", анализ использования менеджеров транзакций и особенностей функционирования систем в реальном времени); генерация кода программ на языке 4GL целевой СУБД с полным обеспечением программной среды и генерация SQL-кода для создания таблиц БД, индексов, ограничений целостности и хранимых процедур; программирование на языке Си со встроенным SQL; управление версиями и конфигурацией проекта; многопользовательский доступ к репозиторию проекта; генерация проектной документации по стандартным и индивидуальным шаблонам; экспорт и импорт данных проекта в формате CDIF (CASE Data Interchange Format).
Vantage Team Builder поставляется в различных конфигурациях в зависимости от используемых СУБД (ORACLE, Informix, Sybase или Ingres) или средств разработки приложений (Uniface). Конфигурация Vantage Team Builder for Uniface отличается от остальных некоторой степенью ориентации на спиральную модель жизненного цикла программного обеспечения за счет возможностей быстрого прототипирования, предоставляемых Uniface. Для описания проекта информационной системы используется достаточно большой набор диаграмм, конкретные варианты которого для наиболее распространенных конфигураций приведены ниже в таблице.
Вероятное будущее SQLМы не будем даже поверхностно описывать новые возможности языка SQL в стандарте SQL/92. Этот язык очень сложен и до сих пор не реализован ни в одной системе в полном объеме. Однако кажется полезным включить в наш курс сводку операторов динамического SQL с небольшими комментариями, поскольку в SQL/92 предпринята первая попытка стандартизовать эту часть языка SQL, и это описание можно использовать хотя бы в качестве эталона при сравнении различных реализаций. В конце раздела приводится краткая сводка новых возможностей, ожидаемых в новом стандарте SQL-3, работа над которым все еще продолжается. Виды нотацийКонечно, способ представления ER-диаграмм, используемый компанией Oracle, не является единственным. В этом подразделе мы представляем несколько других нотаций. Виртуальной страницейWebsite будем называть страницу, которая в виде файла в файловой системе сервера не существует. Данная страница появляется только в момент обращения клиента к серверу. Один из способов генерации виртуальной страницы - это генерация при помощи API-модуля или CGI-программы. При этом весь текст страницы может порождаться программой, либо для генерации могут использоваться файлы-заготовки. Генерируют не только текстовые файлы, но и графику. Одним из наиболее популярных способов генерации документов является обращение к стекам гипертекстовых ссылок и системам управления универсальными базами данных (СУБД). Второй способ генерации виртуальной страницы - это генерация такой страницы сервером. В данном случае в тело документа и файлы описания иерархии документов сервера включаются команды преобразования документов. Сервер может, в общем случае, производить условную генерацию документов на основе информации, полученной от программы-клиента. Другим типом объекта, который хранится в Website, являются страницы в формате Virtual Reality Modeling Language(VRML).VRML-страница - это такой же объект, как и обычные страницы Website, только написанная на другом языке. К VRML-страницам можно применять те же механизмы генерации, что и к страницам HTML. Java-applet - это мобильный код, сгенерированный компилятором applet'ов. Applet'ы составляют в базе данных Website отдельную директорию в файловой системе сервера. В страницы HTML встраиваются специальные контейнеры applet'ов, которые позволяют программе-клиенту распознавать наличие applet'а и подгружать его в качестве части страницы. 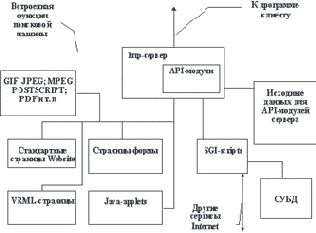 Рис. 5.6. Структура базы данных и программного обеспечения Website Как видно из рисунка 5.6, кроме перечисленных выше компонентов, базу данных Website составляют еще и другие файлы. Главным образом, это файлы графических и мультимедийных форматов. Для просмотра этих файлов программа-клиент должна уметь запускать либо внешнюю программу, либо plug-ins, т.е. программу, которая отображает файл графического или мультимедийного формата внутрь рабочей области программы-клиента. Совершенно очевидно, что для создания всего этого многообразия файлов и компонентов Website необходимо программное обеспечение, которое не входит в стандартный набор, представленный на рисунке 5.6. Самый минимальный набор инструментов, который необходим для поддержания страниц базы данных можно определить следующим образом: Редактор файлов формата HTML. Графический редактор, сохраняющий файлы в форматах GIF, в том числе и версии GIF89A, и JPEG. Редактор файлов формата MPEG. Редактор файлов VRML. Редактор аудиофайлов. Компилятор байткода Java. и др. Кроме прочего, для того, чтобы тестировать страницы, необходимо иметь версии клиентского программного обеспечения различных производителей и различных версий. Определить какие именно программы и их версии необходимы, можно по файлу статистики сервера. Возможные архитектуры Intranet-приложенийТехнологии Internet обеспечивают широкий диапазон возможных архитектур Intranet-систем. Мы очень коротко рассмотрим некоторые варианты. VRML(Virtual Reality Modeling Language) - язык описания трехмерных сцен и взаимодействия трехмерных объектов. Встроенный SQLПоскольку в стандарте SQL/89 не специфицированы (даже в приложениях) правила встраивания SQL в язык Си, мы приведем только общие синтаксические правила встраивания, используемые для любого языка. Это поможет оценить "степень стандартности" конкретной реализации. <embedded SQL statement> ::= <SQL prefix> { <declare cursor> <embedded exception declaration> <SQL statement>} [<SQL terminator>] <SQL prefix> ::= EXEC SQL <SQL terminator> ::= END EXEC ; <embedded SQL declare section> ::= <embedded SQL begin declare> (<host variable definition>...] <embedded SQL end declare> <embedded SQL begin declare> ::= <SQL prefix> BEGIN DECLARE SECTION [<SQL terminator>] <embedded SQL end declare> ::= <SQL prefix> END DECLARE SECTION [<SQL terminator>] <embedded variable name> ::= :<host identifier> <embedded exception declaration> ::= WHENEVER <condition> <exception action> <condition> ::= SQLERROR NOT FOUND <exception action> ::= CONTINUE <go to> <go to> ::= { GOTO GO TO } <target> <target> ::= :<host identifier> <unsigned integer> Встраиваемые операторы SQL, включая объявления курсора, а также разделы объявления исключительных ситуаций и переменных основной программы, должны быть окружены скобками EXEC SQL и END EXEC. Объявление курсора должно встречаться текстуально раньше любого оператора, ссылающегося на этот курсор. Все переменные основной программы, используемые во встроенных операторах SQL, должны быть объявлены в текстуально предшествующем этому оператору разделе объявления переменных основной программы. При этом синтаксис объявления переменной соответствует синтаксису основного языка программирования, но имени переменной предшествует двоеточие. Механизм обработки исключительных ситуаций в SQL/89 исключительно прост (можно сказать, примитивен). Можно задавать реакцию на возникновение двух видов условий: SQLERROR - это условие появления в переменной SQLCODE после выполнения встроенного оператора отрицательного значения; NOT FOUND - условие появления в SQLCODE значения +100 (этот код означает исчерпание курсора). Реакция может состоять в выполнении безусловного перехода на метку основной программы (действие GO TO), или отсутствовать (действие CONTINUE). Срабатывает тот оператор определения реакции на исключительную ситуацию, который текстуально ближе от начала программы к данному оператору SQL. Заметим, что во многих реализациях поддерживается два вида кодов ответа при выполнении операторов SQL (встроенных или взятых из модуля): через переменную SQLCODE с кодами ответа, представляемыми целыми числами и через переменную SQLSTATE с кодами ответа, кодируемыми десятичными числами, представленными в текстовой форме. Имеется тенденция к переходу на использование только механизма SQLSTATE, но в стандартных реализациях должен поддерживаться механизм SQLCODE. Вторая нормальная формаРассмотрим следующий пример схемы отношения: СОТРУДНИКИ-ОТДЕЛЫ-ПРОЕКТЫ (СОТР_НОМЕР, СОТР_ЗАРП, ОТД_НОМЕР, ПРО_НОМЕР, СОТР_ЗАДАН) Это отношение связывает уникальный номер сотрудника с размером его заработной платы, номером отдела, в котором работает сотрудник, номером проекта, в котором участвует сотрудник, и номером задания, выполняемого сотрудником в рамках этого проекта. Первичный ключ: СОТР_НОМЕР, ПРО_НОМЕР Функциональные зависимости: СОТР_НОМЕР --> СОТР_ЗАРП СОТР_НОМЕР --> ОТД_НОМЕР ОТД_НОМЕР --> СОТР_ЗАРП СОТР_НОМЕР, ПРО_НОМЕР --> СОТР_ЗАДАН Как видно, хотя первичным ключом является составной атрибут СОТР_НОМЕР, ПРО_НОМЕР, атрибуты СОТР_ЗАРП и ОТД_НОМЕР функционально зависят от части первичного ключа, атрибута СОТР_НОМЕР. В результате мы не сможем вставить в отношение СОТРУДНИКИ-ОТДЕЛЫ-ПРОЕКТЫ кортеж, описывающий сотрудника, который еще не выполняет никакого проекта (первичный ключ не может содержать неопределенное значение). При удалении кортежа мы не только разрушаем связь данного сотрудника с данным проектом, но утрачиваем информацию о том, что он работает в некотором отделе. При переводе сотрудника в другой отдел мы будем вынуждены модифицировать все кортежи, описывающие этого сотрудника, или получим несогласованный результат. Такие неприятные явления называются аномалиями схемы отношения. Они устраняются путем нормализации. Второй способсостоит в использовании так называемого встроенного SQL, когда с использованием специального синтаксиса в программу на традиционном языке программирования встраиваются операторы SQL. В этом случае с точки зрения прикладной программы оператор SQL выполняется "по месту". Явная параметризация операторов SQL отсутствует, но во встроенных операторах SQL могут использоваться имена переменных основной программы, и за счет этого обеспечивается связь между прикладной программой и СУБД. Концептуально эти два способа эквивалентны. Более того, в стандарте устанавливаются правила порождения неявного модуля SQL по программе со встроенным SQL. Однако в большинстве реализаций операторы SQL, содержащиеся в модуле SQL, и встроенные операторы SQL обрабатываются существенно по-разному. Модуль SQL обычно компилируется отдельно от прикладной программы, в результате чего порождается набор так называемых хранимых процедур (в стандарте этот термин не используется, но распространен в коммерческих реализациях). Т.е. в случае использования модуля SQL компиляция операторов SQL производится один раз, и затем соответствующие процедуры сколько угодно раз могут вызываться из прикладной программы. В отличие от этого, для операторов SQL, встроенных в прикладную программу, компиляция этих операторов обычно производится каждый раз при их использовании (правильнее сказать, при каждом первом использовании оператора при данном запуске прикладной программы). Конечно, пользователи не обязаны знать об этом техническом различии в обработке двух видов взаимодействия с СУБД. Существуют и такие системы, которые производят одноразовую компиляцию встроенных операторов SQL и сохраняют откомпилированный код. Но все-таки лучше иметь это в виду. Приведем некоторые соображения за и против каждого из этих двух способов. При использовании языка модулей текст прикладной программы имеет меньший размер, взаимодействия с СУБД более локализованы за счет наличия явных параметров вызова процедур. С другой стороны, для понимания смысла поведения прикладной программы потребуется одновременное чтение двух текстов. Кроме того, как кажется, синтаксис модуля SQL может существенно различаться в разных реализациях. Встроенный SQL предоставляет возможность производства более "самосодержащихся" прикладных программ. Имеется больше оснований рассчитывать на простоту переноса такой программы в среду другой СУБД, поскольку стандарт встраивания более или менее соблюдается. Основным недостатком является некоторый PL-подобный вид таких программ, независимо от выбранного основного языка. И конечно, нужно учитывать замечания, содержащиеся в предыдущих абзацах. Далее мы коротко опишем язык модулей и правила встраивания в соответствии со стандартом SQL/89 (еще раз заметим, что формально правила встраивания не являются частью стандарта). Втором уровнеподдерживаются рынки данных на основе многомерной системы управления базами данных (примером такой системы является Oracle Express Server). В этом курсе мы не рассматриваем особенности организации многомерных СУБД (это отдельная большая тема), но заметим, что такие СУБД почти идеально подходят для целей разработки OLAP-систем, но пока не позволяют хранить сверхбольшие объемы данных (предельный размер многомерной базы данных составляет 10-20 гигабайт). В данном случае это и не требуется, поскольку речь идет о рынках данных. Заметим, что рынок данных не обязательно должен быть полностью сформирован. Он может содержать ссылки на склад данных и добирать оттуда информацию по мере поступления запросов. Конечно, это несколько увеличивает время отклика, но зато снимает проблему ограниченного объема многомерной базы данных. Наконец, на Предлагаемый материал содержит доступную авторуПредлагаемый материал содержит доступную автору (возможно, не исчерпывающую) информацию по поводу проектирования, разработки, сопровождения и реинжиниринга информационных систем. Информация - это самое ценное достижение человечества. Она ценнее, чем алмазы и золото. Информация помогает нам жить. Информационные системы дают нам шанс на то, чтобы выжить. Грубо говоря, "data and knowlegment mining", т.е. добыча данных и знаний является нашей основной задачей. Задачей не русских, не японцев, не американцев, не какой-то конкретной страны, но всего человечества. Мы все непрерывно накапливаем данные и знания, но проблема состоит в том, чтобы все это переварить и полезно использовать. Для этого и предназначены компьютеризованные информационные системы. Они служат нам, чтобы более быстро, более надежно обработать информацию, чтобы люди не тратили рутинное время, чтобы избежать свойственных человеку случайных ошибок, чтобы сэкономить расходы, чтобы сделать жизнь людей более комфортной. Мы просто не можем справиться с поступающей информацией без компьютерной поддержки. Но для этого нужно уметь использовать существующие, а также проектировать, разрабатывать и сопровождать новые информационные системы. Собственно, этому и посвящен настоящий курс, который состоит из восьми частей. Выполнение
Идея же процедур SQL, определяемых на языке модулей, повлекла внедрение во многие реализации механизма хранимых процедур. Хранимая процедура - это именованная, параметризованная конструкция, определяемая на языке SQL или некотором его расширении, встраиваемая в прикладную программу, компилируемая на стороне сервера во время обработки текста процедуры прекомпилятором. Выполняемый или интерпретируемый код хранимой процедуры сохраняется в базе данных, а сама она может быть вызвана из любой прикладной программы авторизованного пользователя (того, кто получил привилегию на выполнение этой процедуры) с указанием фактических параметров (рисунок 1.5). Пожалуй, механизмы хранимых процедур возникли прежде всего для того, чтобы обеспечить некоторое подобие статической компиляции встроенных операторов SQL в СУБД, которые поддерживают динамическую схему. Компания Oracle пошла дальше, разработав процедурное расширение SQL - язык PL/SQL. С использованием этого языка можно отсылать на сервер компоненты логики приложения. (Похоже, что в следующем стандарте языка SQL - SQL-3 - появится нечто похожее на PL/SQL.) Как мы отмечали выше, фактически это можно трактовать как первое приближение к трехзвенной организации информационной системы. Как правило, развитые СУБД поддерживают язык модулей SQL, но язык хранимых процедур обычно шире и не стандартизован. Поэтому с хранимыми процедурами нужно обращаться осторожно, если вы не хотите попасть в полную зависимость от конкретного производителя. Кроме того, в случае использования распределенной базы данных следует внимательно отслеживать возможности ссылок на таблицы, размещающиеся в разных разделах.
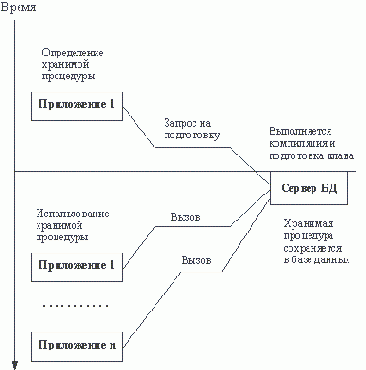 Рис. 1.5. Подготовка и использование хранимой процедуры Наконец-то мы закончили с логическим проектированием базы данных информационной системы и можем приступать к следующим стадиям.
Выражение запросовВыражение запросов - это выражение, строящееся по указанным синтаксическим правилам на основе спецификаций запросов. Единственной операцией, которую разрешается использовать в выражениях запросов, является операция UNION (объединение таблиц) с возможной разновидностью UNION ALL. К таблицам-операндам выражения запросов предъявляется то требование, что все они должны содержать одно и то же число столбцов, и соответствующие столбцы всех операндов должны быть одного и того же типа. Выражение запросов вычисляется слева направо с учетом скобок. При выполнении операции UNION производится обычное теоретико-множественное объединение операндов, т.е. из результирующей таблицы удаляются дубликаты. При выполнении операции UNION ALL образуется результирующая таблица, в которой могут содержаться строки-дубликаты. Вывод всех предупреждений и ошибок(вывод всех предупреждений и ошибок). Существует режим, позволяющий предупреждать возникновение ошибок во время выполнения, при котором можно заказать отслеживание ситуаций переполнения, выхода за пределы указанного диапазона адресов (например, контроль доступа к элементам массива вне указанной размерности) и проверку корректности принадлежности объекта к тому или иному классу. В VisualObjects реализован целый список переключателей компилятора, используемых для обеспечения совместимости с CA-Clipper. Так, можно "разрешить" применение переменных в стиле Clipper, объявить правила использования операторов присваивания "=" или "(=", а также обеспечить применение функции ProcName() и ProcLinep(). Кроме того, компилятор VisualObjects позволяет проводить оптимизацию кода по размеру и скорости выполнения, а также имеется возможность смешанной проверки, что очень полезно в процессе конвертирования Clipper-программы в VisualObjects. С VisualObjects пользователь получает большой выбор библиотек, интегрируемых в IDE. Каждая используемая библиотека должна быть связана с приложением. Наиболее интересна библиотека GUI Classes - совокупность почти 100 классов. Здесь описаны классы для формирования окон, списков, кнопок, линеек прокрутки и прочих атрибутов GUI. DBF-библиотека поддерживает стандартные для xBase-архитектуры команды и функции обработки данных. Средства ООП позволяет реализовывать библиотека DBF Classes. Доступ через протокол ODBC к таблицам обслуживает библиотека SQL Classes, объектно-ориентированный интерфейс для генератора отчетов Report Classes, ввод/вывод в традиции xBase-Terminal, а функции прикладного программирования для Windows - Windows API. Центральное место занимает библиотека System Library, содержащая все системные средства. При работе с VisualObjects существует два варианта программирования в графическом интерфейсе - использование программы эмуляции терминала или применение библиотеки CommonView. В первом случае существует возможность использовать созданные раннее Clipper-приложения как программы Windows, хотя, конечно, это будет все то же DOS-приложение, просто работающее в окне Windows. Переход к GUI создает для разработчика массу новых проблем, что, правда, окупается на порядок более качественным и гибким приложением, получаемым в итоге. Поскольку программисту приходится учитывать событийный характер поведения тех или иных узлов приложения, инструментарий визуальной разработки оказывается ключевым. СА-VisualObjects дает возможность применять мощный набор средств визуального программирования. Так, доступны редакторы меню, окон, отчетов, исходных текстов программ и пиктограмм. Все это позволяет создавать качественные приложения. Сложность освоения VisualObjects состоит в традиционной ломке представлений и привычек, происходящей на пути от процедурного программирования к ООП. В скором времени появится большое количество программных систем, созданных на базе VisualObjects и реализующих все достоинства информационных систем в архитектуре клиент-сервер. Вызовы удаленных процедурОбщим решением проблемы мобильности систем, основанных на архитектуре "клиент-сервер" является опора на программные пакеты, реализующие протоколы удаленного вызова процедур (RPC - Remote Procedure Call). При использовании таких средств обращение к сервису в удаленном узле выглядит как обычный вызов процедуры. Средства RPC, в которых, естественно, содержится вся информация о специфике аппаратуры локальной сети и сетевых протоколов, переводит вызов в последовательность сетевых взаимодействий. Тем самым, специфика сетевой среды и протоколов скрыта от прикладного программиста. При вызове удаленной процедуры программы RPC производят преобразование форматов данных клиента в промежуточные машинно-независимые форматы и затем преобразование в форматы данных сервера. При передаче ответных параметров производятся аналогичные преобразования. Основными идеями механизма вызова удаленных процедур (RPC - Remote Procedure Call), который представляет собой технологическую основу архитектуры "клиент-сервер", являются следующие: (а) Во многих случаях взаимодействие процессов носит ярко выраженный асимметричный характер. Один из процессов ("клиент") запрашивает у другого процесса ("сервера") некоторую услугу (сервис) и не продолжает свое выполнение до тех пор, пока эта услуга не будет выполнена (и пока процесс-клиент не получит соответствующие результаты). Очевидно, что семантически такой режим взаимодействия эквивалентен вызову процедуры, и естественно желание оформить его должным образом синтаксически. (б) Операционная система UNIX по своей идеологии с самого начала была по-настоящему сетевой операционной системой. Свойства переносимости позволяют, в частности, предельно просто создавать "операционно однородные" сети, включающие разнородные компьютеры. Однако остается проблема разного представления данных в компьютерах разной архитектуры (часто по-разному представляются числа с плавающей точкой, используется разный порядок размещения байтов в машинном слове и т.д.). Плохо, когда решение проблемы разных представлений данных возлагается на пользователей. Поэтому второй идеей RPC (многие считают, что это основная идея) является автоматическое обеспечение преобразования форматов данных при взаимодействии процессов, выполняющихся на разнородных компьютерах. Взаимно исключающие связи:каждый экземпляр сущности участвует только в одной связи из группы взаимно исключающих связей (рисунок 4.10).
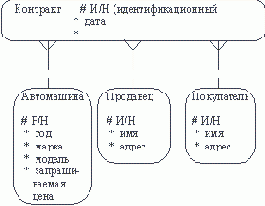 Рис. 4.8.
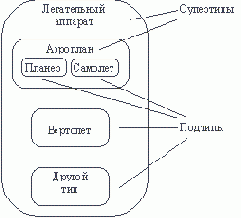 Рис. 4.9. Подтипы и супертипы
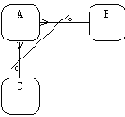 Рис. 4.10. Взаимно исключающие связи WRM - Workgroup Repository Manager) применяется как словарь данных для хранения общей для всех моделей информации, а также обеспечивает интеграцию модулей Silverrun в единую среду проектирования. Платой за высокую гибкость и разнообразие изобразительных средств построения моделей является такой недостаток Silverrun, как отсутствие жесткого взаимного контроля между компонентами различных моделей (например, возможности автоматического распространения изменений между DFD (диаграммами потоков данных) различных уровней декомпозиции). Следует, однако, отметить, что этот недостаток может иметь существенное значение только в случае использования каскадной модели жизненного цикла программного обеспечения. Взаимодействие с другими средствами Для автоматической генерации схем баз данных у Silverrun существуют мосты к наиболее распространенным СУБД: Oracle, Informix, DB2, Ingres, Progress, SQL Server, SQLBase, Sybase. Для передачи данных в средства разработки приложений имеются мосты к языкам 4GL: JAM, PowerBuilder, SQL Windows, Uniface, NewEra, Delphi. Все мосты позволяют загрузить в Silverrun RDM информацию из каталогов соответствующих СУБД или языков 4GL. Это позволяет документировать, перепроектировать или переносить на новые платформы уже находящиеся в эксплуатации базы данных и прикладные системы. При использовании моста Silverrun расширяет свой внутренний репозиторий специфичными для целевой системы атрибутами. После определения значений этих атрибутов генератор приложений переносит их во внутренний каталог среды разработки или использует при генерации кода на языке SQL. Таким образом можно полностью определить ядро базы данных с использованием всех возможностей конкретной СУБД: триггеров, хранимых процедур, ограничений ссылочной целостности. При создании приложения на языке 4GL данные, перенесенные из репозитория Silverrun, используются либо для автоматической генерации интерфейсных объектов, либо для быстрого их создания вручную. Для обмена данными с другими средствами автоматизации проектирования, создания специализированных процедур анализа и проверки проектных спецификаций, составления специализированных отчетов в соответствии с различными стандартами в системе Silverrun имеется три способа выдачи проектной информации во внешние файлы: Система отчетов. Можно, определив содержимое отчета по репозиторию, выдать отчет в текстовый файл. Этот файл можно затем загрузить в текстовый редактор или включить в другой отчет; Система экспорта/импорта. Для более полного контроля над структурой файлов в системе экспорта/импорта имеется возможность определять не только содержимое экспортного файла, но и разделители записей, полей в записях, маркеры начала и конца текстовых полей. Файлы с указанной структурой можно не только формировать, но и загружать в репозиторий. Это дает возможность обмениваться данными с различными системами: другими CASE-средствами, СУБД, текстовыми редакторами и электронными таблицами; Хранение репозитория во внешних файлах через ODBC-драйверы. Для доступа к данным репозитория из наиболее распространенных систем управления базами данных обеспечена возможность хранить всю проектную информацию непосредственно в формате этих СУБД. Групповая работа Групповая работа поддерживается в системе Silverrun двумя способами: В стандартной однопользовательской версии имеется механизм контролируемого разделения и слияния моделей. Разделив модель на части, можно раздать их нескольким разработчикам. После детальной доработки модели объединяются в единые спецификации; Сетевая версия Silverrun позволяет осуществлять одновременную групповую работу с моделями, хранящимися в сетевом репозитории на базе СУБД Oracle, Sybase или Informix. При этом несколько разработчиков могут работать с одной и той же моделью, так как блокировка объектов происходит на уровне отдельных элементов модели. Среда функционирования Имеются реализацииSilverrunдля трех платформ - MS Windows, Macintosh и OS/2 Presentation Manager - с возможностью обмена проектными данными между ними. Для функционирования в среде Windows необходимо иметь компьютер с процессором модели не ниже i486 и оперативную память объемом не менее 8 Мб (рекомендуется 16 Мб). На диске полная инсталляция Silverrun занимает 20 Мб. WWW-серверыКак уже было сказано выше, сервер World Wide Web - это программа, обслуживающая запросы клиентов по протоколу HTTP. Иногда серверами WWW называют и другие программы, например, поисковые машины Wide Area Information Server. Но это слишком вольное толкование понятия WWW-сервера. Главной задачей сервера "паутины" является обеспечение доступа пользователей к базе данных HTML-документов. Однако, в настоящее время функциональные возможности серверов значительно расширились и вышли за пределы простой отсылки документов на запросы клиентов. Наиболее типичными для современных серверов являются следующие функции: ведение иерархической базы данных документов, контроль за доступом к информации со стороны программ-клиентов, предварительная обработка данных перед ответом на запрос, взаимодействие с внешними программами через Common Gateway Interface, реализация взаимодействия с клиентами и другими серверами в режиме посредника, реализация встроенных или взаимодействие с внешними поисковыми машинами. Кроме того, такие серверы как NetSite (Netscape Communication) и Apachie реализуют шифрованные протоколы HTTP для обмена информацией с клиентами. Рассмотрение перечисленных свойств и функций WWW-серверов полезно провести на примерах, основанных на практике эксплуатации серверов NCSA httpd, CERN httpd, Winhttpd и WN, Apachie. Wwwsites- это весь Internet. А если говорить более точно, то это те информационные ресурсы, просмотр которых обеспечивается программами просмотра. Рассмотрим теперь назначение и принцип построения каждой из этих компонент более подробно и определим, в чем отличие данной системы от традиционной информационно-поисковой системы локального типа. Задачи информационных системКонкретные задачи, которые должны решаться информационной системой, зависят от той прикладной области, для которой предназначена система. Области применения информационных приложений разнообразны: банковское дело, страхование, медицина, транспорт, образование и т.д. Трудно найти область деловой активности, в которой сегодня можно было обойтись без использования информационных систем. С другой стороны, очевидно, что, например, конкретные задачи, решаемые банковскими информационными системами, отличаются от задач, решение которых требуется от медицинских информационных систем. Но можно выделить некоторое количество задач, не зависящих от специфики прикладной области. Естественно, такие задачи связаны с общими чертами информационных систем, рассмотренных в предыдущем разделе. Прежде всего, кажется бесспорным мнение о том, что наиболее существенной составляющей является информация, которая долго накапливается и утрата которой невосполнима. В качестве примера рассмотрим ситуацию, существующую в Зеленчукской астрофизической лаборатории. В этой лаборатории в горах в районе Нижнего Архыза установлен один из крупнейших в мире зеркальных телескопов (диаметр зеркала - 6 метров). Уникальные природные условия этого района Северного Кавказа позволяют максимально эффективно использовать возможности обсерватории. В самом Зеленчуке имеется крупнейший в России радиотелескоп. Комбинированное использование этих ресурсов в течение многих лет (более 10) позволило астрофизикам накопить уникальную информацию относительно разного рода космических объектов. К сожалению, компьютерные возможности лаборатории в первые годы ее существования были весьма ограничены, и поэтому накапливаемые данные хранились в основном на магнитных лентах. Известно, что любой магнитный носитель стареет, а магнитные ленты еще и пересыхают. В результате основной проблемой группы поддержки информационных ресурсов уже несколько лет является копирование старых магнитных лент на новые носители. Старые ленты часто не читаются, и приходится тратить громадные усилия и средства для их реанимирования.
 Рис. 1.1. Традиционная двухзвенная архитектура "клиент-сервер"  Рис. 1.2. Трехзвенная архитектура "клиент-сервер" с выделенным сервером приложений Заметим, что некоторые черты трехзвенности могут присутствовать и в двухзвенной архитектуре. Если, например, используемый сервер баз данных поддерживает развитый механизм хранимых процедур (например, такой, как в Oracle V.7), то можно перебросить некоторую часть логики приложения на сторону баз данных. Заметим, что механизм хранимых процедур недостаточно полно специфицирован в стандарте языка SQL. Как только вы решаетесь использовать действительно развитые средства, то немедленно привязываете свою информационную систему к конкретному производителю серверов баз данных. Развязаться будет очень трудно. И наконец, еще один класс задач относится к обеспечению удобного и соответствующего целям информационной системы пользовательского интерфейса. Более или менее просто выяснить функциональные компоненты интерфейса, например, какого вида должны предлагаться формы и какого вида должны выдаваться отчеты. Но построение действительно удобного и неутомительного для пользователя интерфейса - это задача дизайнера интерфейса. Простой аналог: при наличии полного набора качественной мебели хороший дизайнер сможет красиво оформить удобную для жизни квартиру (все на месте и под рукой). Плохой же дизайнер, скорее всего, добьется лишь того, что сможет запихнуть в квартиру всю мебель, а потом хозяину квартиры все время будет казаться, что у него слишком много ненужной мебели и ничего невозможно найти. Нужно отдавать себе отчет в том, что задача эргономичности интерфейса не формализуется. При ее решении не помогут никакие средства автоматизации разработки интерфейса. Такие средства облегчают только построение компонентов интерфейса. Построение же полного интерфейса - это творческая задача, при решении которой нужно учитывать требования эстетичности и удобства, а также принимать во внимание особенности конкретной области применения информационной системы. На первый взгляд упомянутая задача кажется не очень существенной. Можно полагать, что если информационная система обеспечивает полный набор функций и ее интерфейс обеспечивает доступ к любой из этих функций, то конечные пользователи должны быть удовлетворены. На самом деле, это не так. Пользователи часто судят о качестве системы в целом исходя из качества ее интерфейса. Более того, эффективность использования системы зависит от качества интерфейса.Поскольку, как отмечалось выше, задача построения эргономичного интерфейса не формализуется, мы больше не будем затрагивать ее в этом курсе, а ограничимся рассмотрением вопросов построения компонентов интерфейса. Защита сервера от несанкционированного доступаОтдельное место при обсуждении протокола занимают вопросы, связанные с обеспечением защиты ресурсов сервера от несанкционированного доступа. Как было отмечено в предыдущих разделах, первоначально разработка защищенных способов обмена данными в системе World Wide Web не предполагалась. Однако быстрое развитие популярности системы привело к тому, что многие коммерческие организации стали устанавливать серверы HTTP на свои машины. Кроме этого, конфиденциальной информации много и в научно-исследовательских государственных организациях. Таким образом, возникла необходимость в разработке механизмов защиты информации для системы WWW. Проблема защиты информации на Internet - это отдельная большая тема. В данном разделе мы рассмотрим только обеспечение безопасности при использовании серверов HTTP. Первая связана с чтением защищенных текстовых файлов. Для решения этой задачи имеется достаточно много традиционных механизмов, встроенных в операционные системы. Проблема возникает, если администратор системы решит использовать для размещения WWW-файлов и FTP-архива одно и тоже дисковое пространство. В этом случае защищенные WWW-файлы окажутся доступными для "анонимного" FTP-доступа. Многие серверы разрешают создавать в дереве поддерживаемых ими документов "домашние" страницы пользователей с помощью методов POST и GET. Это значит, что пользователи могут изменять информацию на компьютере сервера. Данные, вводимые пользователем, передаются как тело ресурса при методе POST через стандартный ввод, а методе GET через переменные окружения. Естественно, что разрешение создания файлов на сервере протокола HTTP создает потенциальную опасность доступа к защищенной информации лиц, не имеющих права доступа к ней. Решается эта проблема путем создания специальных файлов прав пользователей сервера WWW.
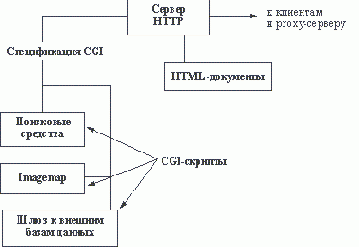 Рис. 5.2. Схема управления ресурсов сервером HTTP Вторая возможность проникновения в компьютерную систему через сервер WWW связана с CGI-скриптами. CGI-скрипт - это программа, которую сервер HTTP может запускать для реализации механизмов, не предусмотренных в протоколе.
ЖурнализацияОдним из основных требований к СУБД является надежное хранение данных во внешней памяти. Под надежностью хранения понимается то, что СУБД должна быть в состоянии восстановить последнее согласованное состояние БД после любого аппаратного или программного сбоя. Обычно рассматриваются два возможных вида аппаратных сбоев: так называемые мягкие сбои, которые можно трактовать как внезапную остановку работы компьютера (например, аварийное выключение питания), и жесткие сбои, характеризуемые потерей информации на носителях внешней памяти. Примерами программных сбоев могут быть: аварийное завершение работы СУБД (по причине ошибки в программе или в результате некоторого аппаратного сбоя) или аварийное завершение пользовательской программы, в результате чего некоторая транзакция остается незавершенной. Первую ситуацию можно рассматривать как особый вид мягкого аппаратного сбоя; при возникновении последней требуется ликвидировать последствия только одной транзакции. Понятно, что в любом случае для восстановления БД нужно располагать некоторой дополнительной информацией. Другими словами, поддержание надежного хранения данных в БД требует избыточности хранения данных, причем та часть данных, которая используется для восстановления должна храниться особо надежно. Наиболее распространенным методом поддержания такой избыточной информации является ведение журнала изменений БД. Журнал - это особая часть БД, недоступная пользователям СУБД и поддерживаемая с особой тщательностью (иногда поддерживаются две копии журнала, располагаемые на разных физических дисках), в которую поступают записи обо всех изменениях основной части БД. В разных СУБД изменения БД журнализуются на разных уровнях: иногда запись в журнале соответствует некоторой логической операции изменения БД (например, операции удаления строки из таблицы реляционной БД), иногда запись в журнале соответствует минимальной внутренней операции модификации страницы внешней памяти; в некоторых системах одновременно используются оба подхода. Во всех случаях придерживаются стратегии "упреждающей" записи в журнал (так называемого протокола Write Ahead Log - WAL). Грубо говоря, эта стратегия заключается в том, что запись об изменении любого объекта БД должна попасть во внешнюю память журнала раньше, чем измененный объект попадет во внешнюю память основной части БД. Известно, что если в СУБД корректно соблюдается протокол WAL, то с помощью журнала можно решить все проблемы восстановления БД после любого сбоя. Самая простая ситуация восстановления - индивидуальный откат транзакции. Строго говоря, для этого не требуется общесистемный журнал изменений БД. Достаточно для каждой транзакции поддерживать локальный журнал операций модификации БД, выполненных в этой транзакции, и производить откат транзакции путем выполнения обратных операций, следуя от конца локального журнала. В некоторых СУБД так и делают, но в большинстве систем локальные журналы не поддерживают, а индивидуальный откат транзакции выполняют по общесистемному журналу, для чего все записи от одной транзакции связывают обратным списком (от конца к началу). При мягком сбое во внешней памяти основной части БД могут находиться объекты, модифицированные транзакциями, не закончившимися к моменту сбоя, и могут отсутствовать объекты, модифицированные транзакциями, которые к моменту сбоя успешно завершились (по причине использования буферов оперативной памяти, содержимое которых при мягком сбое пропадает). При соблюдении протокола WAL во внешней памяти журнала должны гарантированно находиться записи, относящиеся к операциям модификации обоих видов объектов. Целью процесса восстановления после мягкого сбоя является состояние внешней памяти основной части БД, которое возникло бы при фиксации во внешней памяти изменений всех завершившихся транзакций и которое не содержало бы никаких следов незаконченных транзакций. Для того, чтобы этого добиться, сначала производят откат незавершенных транзакций (undo), а потом повторно воспроизводят (redo) те операции завершенных транзакций, результаты которых не отображены во внешней памяти.Этот процесс содержит много тонкостей, связанных с общей организацией управления буферами и журналом. Для восстановления БД после жесткого сбоя используют журнал и архивную копию БД. Грубо говоря, архивная копия - это полная копия БД к моменту начала заполнения журнала (имеется много вариантов более гибкой трактовки смысла архивной копии). Конечно, для нормального восстановления БД после жесткого сбоя необходимо, чтобы журнал не пропал. Как уже отмечалось, к сохранности журнала во внешней памяти в СУБД предъявляются особо повышенные требования. Тогда восстановление БД состоит в том, что исходя из архивной копии по журналу воспроизводится работа всех транзакций, которые закончились к моменту сбоя. В принципе, можно даже воспроизвести работу незавершенных транзакций и продолжить их работу после конца восстановления. Однако в реальных системах это обычно не делается, поскольку процесс восстановления после жесткого сбоя является достаточно длительным. |
