Оператор позиционной модификации
Оператор описывается следующими синтаксическими правилами:
<update statement: positioned> ::= UPDATE <table name> SET <set clause:positioned> [{,<set clause:positioned>}...] WHERE CURRENT OF <cursor name> <set clause: positioned> ::= <object column:positioned> = { <value expression> NULL } <object column: positioned> ::= <column name>
Если указанный в операторе курсор открыт и установлен на некоторую строку, и курсор определяет изменяемую таблицу, то текущая строка курсора модифицируется в соответствии с разделом SET. Позиция курсора не изменяется. Таблица, указанная в разделе FROM оператора DELETE, должна быть таблицей, указанной в самом внешнем разделе FROM спецификации курсора.
<dynamic update statement: positioned> ::= UPDATE <table name> SET <set clause> [{<comma> <set clause>}...] WHERE CURRENT OF <dynamic cursor name>
По сути, оператор позиционной модификации по курсору, связанному с динамически подготовленным оператором SQL, отличается от статического случая только тем, что имя курсора может задаваться через переменную.
Оператор установки дескриптора
<set descriptor statement> ::= SET DESCRIPTOR <descriptor name> <set descriptor information> <set descriptor information> ::= <set count> VALUE <item number> <set item information> [{<comma> <set item information>}...] <set count> ::= COUNT <equals operator> <simple value specification 1> <set item information> ::= <descriptor item name> <equals operator> <simple value specification 2> <simple target specification 1> ::= <simple target specification> <simple target specification 2> ::=<simple target specification> <item number> ::= <simple value specification>
Оператор SET DESCRIPTOR служит для заполнения элементов дескриптора с целью его использования в разделе USING. За одно выполнение оператора можно поместить значение в поле COUNT (число заполненных элементов), либо частично или полностью сформировать один элемент дескриптора.
Оператор выборки
Оператор выборки - это отдельный оператор языка SQL/89, позволяющий получить результат запроса в прикладной программе без привлечения курсора. Поэтому оператор выборки имеет синтаксис, отличающийся от синтаксиса спецификации курсора, и при его выполнении возникают ограничения на результат табличного выражения. Фактически, и то, и другое диктуется спецификой оператора выборки как одиночного оператора SQL: при его выполнении результат должен быть помещен в переменные прикладной программы. Поэтому в операторе появляется раздел INTO, содержащий список переменных прикладной программы, и возникает то ограничение, что результирующая таблица должна содержать не более одной строки. Соответственно, результат базового табличного выражения должен содержать не более одной строки, если оператор выборки не содержит спецификации DISTINCT, и таблица, полученная применением списка выборки к результату табличного выражения, не должна содержать более одной несовпадающих строк, если спецификация DISTINCT задана.
Замечание: В диалекте SQL СУБД Oracle поддерживается расширенный вариант оператора выборки, результатом которого не обязательно является таблица из одной строки. Такое расширение не поддерживается ни в SQL/89, ни в SQL/92.
Для удобства мы повторяем синтаксис этого оператора еще раз:
<select statement> ::= SELECT [ALL DISTINCT] <select name> INTO <select target list> <table expression> <select target list>::= <target specification> [{,<target specification>}...]
Поскольку, как мы уже объясняли, результатом одиночного оператора выборки является таблица, состоящая не более, чем из одной строки, список целей специфицируется в самом операторе.
Оператор выделения памяти под дескриптор
<allocate descriptor statement> ::= ALLOCATE DESCRIPTOR <descriptor name> [WITH MAX <occurrences>] <occurrences> ::= <simple value specification> <descriptor name> ::= [(<scope option>] <simple value specification> <scope option> ::= GLOBAL LOCAL <simple value specification> ::= <parameter name> <embedded variable name> <literal>
Дескриптор, это динамически выделяемая часть памяти прикладной программы, служащая для принятия информации о результате или параметрах динамически подготовленного оператора SQL или задания параметров такого оператора. Смысл того, что для выделения памяти используется оператор SQL, а не просто стандартная функция alloc или какая-нибудь другая функция динамического запроса памяти, состоит в том, что прикладная программа не знает структуры дескриптора и даже его адреса. Это позволяет не привязывать SQL к особенностям какой-либо системы программирования или ОС. Все обмены информацией между собственно прикладной программой и дескрипторами производятся также с помощью специальных операторов SQL (GET и SET).
Второй вопрос: зачем вообще выделять память под дескрипторы динамически? Это нужно потому, что в общем случае прикладная программа, использующая динамический SQL, не знает в статике число одновременно действующих динамических операторов SQL, описание которых может потребоваться. С этим же связано то, что имя дескриптора может задаваться как литеральной строкой символов, так и через строковую переменную включающего языка, т.е. его можно генерировать во время выполнения программы.
В операторе ALLOCATE DESCRIPTOR, помимо прочего, может указываться число описательных элементов, на которое он рассчитан. Если, например, при выделении памяти под дескриптор в разделе WITH MAX указано целое положительное число N, а потом дескриптор используется для описания M (M>N) элементов (например, M столбцов результата запроса), то это приводит к возникновению исключительной ситуации.
Оператор выполнения подготовленного оператора
<execute statement> ::= EXECUTE <SQL statement name> [<result using clause>] [<parameter using clause>] <result using clause> ::= <using clause> <parameter using clause> ::= <using clause>
Оператор EXECUTE может быть применен к любому ранее подготовленному оператору SQL, кроме <dynamic select statement>. Если это оператор <dynamic single row select statement>, то оператор EXECUTE должен содержать раздел <result using class> с ключевым словом INTO. В любом случае число фактических параметров, задаваемых через разделы using, должно соответствовать числу формальных параметров, определенных в подготовленном операторе SQL.
Оператор закрытия курсора
Синтаксис этого оператора следующий:
<close statement> ::= CLOSE <cursor name>
Если к моменту выполнения этого оператора курсор находился в открытом состоянии, то оператор переводит курсор в закрытое состояние. После этого над курсором возможно выполнение только оператора OPEN.
Оператор закрытия курсора, связанного с динамически подготовленным оператором выборки
<dynamic close statement> ::= CLOSE <dynamic cursor name>
По сути, оператор закрытия курсора, связанного с динамически подготовленным оператором SQL, отличается от статического случая только тем, что имя курсора может задаваться через переменную.
Оператор запроса описания подготовленного оператора
<describe statement> ::= <describe input statement> <describe output statement> <describe input statement> ::= DESCRIBE INPUT <SQL statement name> <using descriptor> <describe output statement> ::= DESCRIBE [OUTPUT] <SQL statement name> <using descriptor> <using clause> ::= <using arguments> <using descriptor> <using arguments> ::= { USING INTO } <argument> [{<comma> <argument>}...] <argument> ::= <target specification> <using descriptor> ::= { USING INTO } SQL DESCRIPTOR <descriptor name> <target specification> ::= <parameter specification> <variable specification> <parameter specification> ::= <parameter name> [<indicator parameter>] <indicator parameter> ::= [INDICATOR] <parameter name> <variable specification> ::= <embedded variable name> [<indicator variable>] <indicator variable> ::= [INDICATOR] <embedded variable name>
При выполнении оператора DESCRIBE происходит заполнение указанного в операторе дескриптора информацией, описывающей либо результат ранее подготовленного оператора SQL (если это оператор выборки), либо количество и типы параметров подготовленного оператора. В <using descriptor> здесь полагается писать USING SQL DESCRIPTOR.
Операторы окончания транзакции
Текущая транзакция может быть завершена успешно (с фиксацией в базе данных произведенных изменений) путем выполнения оператора COMMIT WORK или аварийно (с удалением из базы данных изменений, произведенных текущей транзакцией) путем выполнения оператора ROLLBACK WORK. При выполнении любого из этих операторов производится принудительное закрытие всех курсоров, открытых к моменту выполнения оператора завершения транзакции.
Назад | Содержание | Вперед
Операторы, связанные с курсором
Операторы этой группы объединяет то, что все они работают с некоторым курсором, объявление которого должно содержаться в том же модуле или программе со встроенным SQL.
Определение
Отношение R находится во второй нормальной форме (2NF) в том и только в том случае, когда находится в 1NF и каждый неключевой атрибут полностью зависит от каждого ключа R.
Здесь и далее мы не будем приводить примеры для отношений с несколькими ключами. Они слишком громоздки и относятся к ситуациям, редко встречающимся на практике.
Отношение R находится в третьей нормальной форме (3NF) в том и только в том случае, если находится в 1NF, и каждый неключевой атрибут не является транзитивно зависимым от какого-либо ключа R.
На практике третья нормальная форма схем отношений достаточна в большинстве случаев, и приведением к третьей нормальной форме процесс проектирования реляционной базы данных обычно заканчивается. Однако иногда полезно продолжить процесс нормализации.
Определение : Четвертая нормальная форма
Отношение R находится в четвертой нормальной форме (4NF) в том и только в том случае, если в случае существования многозначной зависимости A -->> B все остальные атрибуты R функционально зависят от A.
В нашем примере можно произвести декомпозицию отношения ПРОЕКТЫ в два отношения ПРОЕКТЫ-СОТРУДНИКИ и ПРОЕКТЫ-ЗАДАНИЯ:
ПРОЕКТЫ-СОТРУДНИКИ (ПРО_НОМЕР, ПРО_СОТР) ПРОЕКТЫ-ЗАДАНИЯ (ПРО_НОМЕР, ПРО_ЗАДАН)
Оба эти отношения находятся в 4NF и свободны от отмеченных аномалий.
Определение Детерминант
Детерминант - любой атрибут, от которого полностью функционально зависит некоторый другой атрибут.
Определение Функциональная зависимость
В отношении R атрибут Y функционально зависит от атрибута X (X и Y могут быть составными) в том и только в том случае, если каждому значению X соответствует в точности одно значение Y: R.X --> R.Y.
Определение : Многозначные зависимости
В отношении R (A, B, C) существует многозначная зависимость R.A -->> R.B в том и только в том случае, если множество значений B, соответствующее паре значений A и C, зависит только от A и не зависит от С.
В отношении ПРОЕКТЫ существуют следующие две многозначные зависимости:
ПРО_НОМЕР -->> ПРО_СОТР ПРО_НОМЕР -->> ПРО_ЗАДАН
Легко показать, что в общем случае в отношении R (A, B, C) существует многозначная зависимость R.A -->> R.B в том и только в том случае, когда существует многозначная зависимость R.A -->> R.C.
Дальнейшая нормализация отношений, подобных отношению ПРОЕКТЫ, основывается на следующей теореме:
Определение Неключевой атрибут
Неключевым атрибутом называется любой атрибут отношения, не входящий в состав ключа (в частности, первичного).
Определение Нормальная форма Бойса-Кодда
Отношение R находится в нормальной форме Бойса-Кодда (BCNF) в том и только в том случае, если каждый детерминант является возможным ключом.
Очевидно, что это требование не выполнено для отношения СОТРУДНИКИ-ПРОЕКТЫ. Можно произвести его декомпозицию к отношениям СОТРУДНИКИ и СОТРУДНИКИ-ПРОЕКТЫ:
СОТРУДНИКИ (СОТР_НОМЕР, СОТР_ИМЯ)
Возможные ключи:
СОТР_НОМЕР СОТР_ИМЯ
Функциональные зависимости:
СОТР_НОМЕР --> CОТР_ИМЯ СОТР_ИМЯ --> СОТР_НОМЕР СОТРУДНИКИ-ПРОЕКТЫ (СОТР_НОМЕР, ПРО_НОМЕР, СОТР_ЗАДАН)
Возможный ключ:
СОТР_НОМЕР, ПРО_НОМЕР
Функциональные зависимости:
СОТР_НОМЕР, ПРО_НОМЕР --> CОТР_ЗАДАН
Возможна альтернативная декомпозиция, если выбрать за основу СОТР_ИМЯ. В обоих случаях получаемые отношения СОТРУДНИКИ и СОТРУДНИКИ-ПРОЕКТЫ находятся в BCNF, и им не свойственны отмеченные аномалии.
Определение ограничений целостности таблицы
Ограничения целостности таблицы обладают следующим синтаксисом:
<table constraint definition> ::= <unique constraint definition> <referential constraint definition> <check constraint definition> <unique constraint definition> ::= <unique specification> (<unique column list>) <unique specification> ::= UNIQUE PRIMARY KEY <unique column list> ::= <column name> [{,<column name>}...] <referential constraint definition> ::= FOREIGN KEY (<referencing columns>) <references specification> <references specification> ::= REFERENCES <referenced table and columns> <referencing columns> ::= <reference column list> <referenced table and columns> ::= <table name> [(<reference column list>)] <reference column list> ::= <column name> [{,<column name>}...] <check constraint definition> ::= CHECK (<search condition>)
Для одной таблицы может быть задано несколько ограничений целостности, в том числе те, которые неявно порождаются ограничениями целостности столбцов. Стандарт SQL/89 устанавливает, что ограничения таблицы фактически проверяются при выполнении каждого оператора SQL.
Замечание: Наличие правильно подобранного набора ограничений БД очень важно для надежного функционирования прикладной информационной системы. Вместе с тем, в некоторых СУБД ограничения целостности практически не поддерживаются. Поэтому при проектировании прикладной системы необходимо принять решение о том, что более существенно: рассчитывать на поддержку ограничений целостности, но ограничить набор возможных СУБД, или отказаться от их использования на уровне SQL, сохранив возможность использования не самых современных СУБД.
Далее T обозначает таблицу, для которой определяются ограничения целостности.
Определение : Пятая нормальная форма
Отношение R находится в пятой нормальной форме (нормальной форме проекции-соединения - PJ/NF) в том и только в том случае, когда любая зависимость соединения в R следует из существования некоторого возможного ключа в R.
Введем следующие имена составных атрибутов:
СО = {СОТР_НОМЕР, ОТД_НОМЕР} СП = {СОТР_НОМЕР, ПРО_НОМЕР} ОП = {ОТД_НОМЕР, ПРО_НОМЕР}
Предположим, что в отношении СОТРУДНИКИ-ОТДЕЛЫ-ПРОЕКТЫ существует зависимость соединения:
* (СО, СП, ОП)
На примерах легко показать, что при вставках и удалениях кортежей могут возникнуть проблемы. Их можно устранить путем декомпозиции исходного отношения в три новых отношения:
СОТРУДНИКИ-ОТДЕЛЫ (СОТР_НОМЕР, ОТД_НОМЕР) СОТРУДНИКИ-ПРОЕКТЫ (СОТР_НОМЕР, ПРО_НОМЕР) ОТДЕЛЫ-ПРОЕКТЫ (ОТД_НОМЕР, ПРО_НОМЕР)
Пятая нормальная форма - это последняя нормальная форма, которую можно получить путем декомпозиции. Ее условия достаточно нетривиальны, и на практике 5NF не используется. Заметим, что зависимость соединения является обобщением как многозначной зависимости, так и функциональной зависимости.
Назад | Содержание | Вперед
Определение Полная функциональная зависимость
Функциональная зависимость R.X --> R.Y называется полной, если атрибут Y не зависит функционально от любого точного подмножества X.
Определение представлений
Механизм представлений (view) является мощным средством языка SQL, позволяющим скрыть реальную структуру БД от некоторых пользователей за счет определения представления БД, которое реально является некоторым хранимым в БД запросом с именованными столбцами, а для пользователя ничем не отличается от базовой таблицы БД (с учетом технических ограничений). Любая реализация должна гарантировать, что состояние представляемой таблицы точно соответствует состоянию базовых таблиц, на которых определено представление. Обычно вычисление представляемой таблицы (материализация соответствующего запроса) производится каждый раз при использовании представления.
В стандарте SQL/89 оператор определения представления имеет следующий синтаксис:
<view definition> ::= CREATE VIEW <table name> [(<view column list>)] AS <query specification> [WITH CHECK OPTION] <view column list> ::= <column name> [{,<column name>}...]
Определяемая представляемая таблица V является изменяемой (т.е. по отношению к V можно использовать операторы DELETE и UPDATE) в том и только в том случае, если выполняются следующие условия для спецификации запроса: в списке выборки не указано ключевое слово DISTINCT; каждое арифметическое выражение в списке выборки представляет собой одну спецификацию столбца, и спецификация одного столбца не появляется более одного раза; в разделе FROM указана только одна таблица, являющаяся либо базовой таблицей, либо изменяемой представляемой таблицей; в условии выборки раздела WHERE не используются подзапросы; в табличном выражении отсутствуют разделы GROUP BY и HAVING.
Замечание: Эти ограничения являются очень сильными. В реализациях они могут быть ослаблены. Но если стремиться к мобильности, не следует пользоваться расширенными возможностями.
Если в списке выборки спецификации запроса имеется хотя бы одно арифметическое выражение, состоящее не из одной спецификации столбца, или если одно имя столбца участвует в списке выборки более одного раза, определение представления должно содержать список имен столбцов представляемой таблицы. Более просто, нужно явно именовать столбцы представляемой таблицы, если эти имена не наследуются от столбцов таблиц раздела FROM спецификации запроса.
Требование WITH CHECK OPTION в определении представления имеет смысл только в случае определения изменяемой представляемой таблицы, которая определяется спецификацией запроса, содержащей раздел WHERE. При наличии этого требования не допускаются изменения представляемой таблицы, которые приводят к появлению в базовых таблицах строк, не видимых в представляемой таблице (т.е. таких строк, которые не удовлетворяют условию поиска раздела WHERE спецификации запроса). Если WITH CHECK OPTION в определении представления отсутствует, такой контроль не производится.
Определение привилегий
В соответствии с идеологией языка SQL контроль прав доступа данного пользователя к таблицам БД производится на основе механизма привилегий. Фактически, этот механизм состоит в том, что для выполнения любого действия над таблицей пользователь должен обладать соответствующей привилегией (реально все возможные действия описываются фиксированным стандартным набором привилегий). Пользователь, создавший таблицу, автоматически становится владельцем всех возможных привилегий на выполнение операций над этой таблицей. В число этих привилегий входит привилегия на передачу всех или некоторых привилегий по отношению к данной таблице другому пользователю, включая привилегию на передачу привилегий. Иногда поддерживается и обратная операция изъятия привилегий от пользователя, ранее их получившего.
В SQL/89 определяется упрощенная схема механизма привилегий. Во-первых, "раздача" привилегий возможна только при определении таблицы. Во-вторых, пользователь, получивший некоторые привилегии от других пользователей, может передать их дальше только при определении схемы.
Определение привилегий производится в следующем синтаксисе:
<privilege definition> ::= GRANT <privileges> ON <table name> TO <grantee> [{,<grantee>}...] [WITH GRANT OPTION] <privileges> ::= ALL PRIVILEGES <action> [{,<action>}...] <action> ::= SELECT INSERT DELETE UPDATE [(<grant column list>)] REFERENCES [(<grant column list>] <grant column list> ::= <column name> [{,<column name>}...] <grantee> ::= PUBLIC <authorization identifier>
Смысл механизма определения привилегий в SQL/89 достаточно понятен из этого синтаксиса. Заметим лишь, что привилегией REFERENCES по отношению к указанным столбцам таблицы T1 необходимо обладать, чтобы иметь возможность при определении таблицы T определить ограничение по ссылкам между этой таблицей и существующей к этому моменту таблицей T1.
Еще раз заметим, что хотя в общем смысле во всех SQL-ориентированных СУБД поддерживается механизм защиты доступа на основе привилегий, реализации могут различаться в деталях. Это опять то место, которое нужно локализовывать, если стремиться к созданию мобильной прикладной системы.
Определение процедуры
Процедуры в модуле SQL определяются в следующем синтаксисе:
<procedure> ::= PROCEDURE <procedure name> <parameter declaration>...; <SQL statement>; <parameter declaration>::= <parameter name> <data type> <SQLCODE parameter> <SQLCODE parameter> ::= SQLCODE <SQL statement> ::= <close statement> <commit statement> <delete statement positioned> <delete statement searched> <fetch statement> <insert statement> <open statement> <rollback statement> <select statement> <update statement positioned> <update statement searched>
Имена всех процедур в одном модуле должны быть различны. Любое имя параметра, содержащегося в операторе SQL процедуры, должно быть специфицировано в разделе объявления параметров. Число фактических параметров при вызове процедуры должно совпадать с числом формальных параметров, указанных при ее объявлении. Список формальных параметров каждой процедуры должен содержать ровно один параметр SQLCODE (код ответа процедуры; возможные значения кодов ответа стандартизованы, но некоторые из них определяются в реализации).
Определение столбца
Оператор определения столбца описывается следующими синтаксическими правилами:
<column definition> ::= <column name> <data type> [<default clause>] [<column constraint>...] <default clause> ::= DEFAULT { <literal> | USER | NULL } <column constraint> ::= NOT | NULL [<unique specification>] | <references specification> | CHECK (<search condition>)
Как видно, кроме обязательной части, в которой определяется имя столбца и его тип данных, определение столбца может содержать два необязательных раздела: раздел значения столбца по умолчанию и раздел ограничений целостности столбца.
В разделе значения по умолчанию указывается значение, которое должно быть помещено в строку, заносимую в данную таблицу, если значение данного столбца явно не указано. Значение по умолчанию может быть указано в виде литеральной константы с типом, соответствующим типу столбца; путем задания ключевого слова USER, которому при выполнении оператора занесения строки соответствует символьная строка, содержащая имя текущего пользователя (в этом случае столбец должен иметь тип символьных строк); или путем задания ключевого слова NULL, означающего, что значением по умолчанию является неопределенное значение. Если значение столбца по умолчанию не специфицировано, и в разделе ограничений целостности столбца указано NOT NULL, то попытка занести в таблицу строку с неспецифицированным значением данного столбца приведет к ошибке.
Указание в разделе ограничений целостности NOT NULL приводит к неявному порождению проверочного ограничения целостности для всей таблицы (см. следующий подраздел) "CHECK (C IS NOT NULL)" (где C - имя данного столбца). Если ограничение NOT NULL не указано, и раздел умолчаний отсутствует, то неявно порождается раздел умолчаний DEFAULT NULL. Если указана спецификация уникальности, то порождается соответствующая спецификация уникальности для таблицы.
Если в разделе ограничений целостности указано ограничение по ссылкам данного столбца (<reference specification>), то порождается соответствующее определение ограничения по ссылкам для таблицы:
FOREIGN KEY(C) <reference specification>.
Наконец, если указано проверочное ограничение столбца, то условие поиска этого ограничения должно ссылаться только на данный столбец, и неявно порождается соответствующее проверочное ограничение для всей таблицы.
Определение таблицы
Оператор определения таблицы имеет следующий синтаксис:
<table definition> ::= CREATE TABLE <table name> (<table element> [{,<table element>}...]) <table element> ::= <column definition> <table constraint definition>
Кроме имени таблицы, в операторе специфицируется список элементов таблицы, каждый из которых служит либо для определения столбца, либо для определения ограничения целостности определяемой таблицы. Требуется наличие хотя бы одного определения столбца. Оператор CREATE TABLE определяет так называемую базовую таблицу, т.е. реальное хранилище данных.
Для определения столбцов таблицы и ограничений целостности используются специальные операторы, которые должны быть вложены в оператор определения таблицы.
Определение Транзитивная функциональная зависимость
Функциональная зависимость R.X --> R.Y называется транзитивной, если существует такой атрибут Z, что имеются функциональные зависимости R.X --> R.Z и R.Z --> R.Y и отсутствует функциональная зависимость R.Z --> R.X. (При отсутствии последнего требования мы имели бы "неинтересные" транзитивные зависимости в любом отношении, обладающем несколькими ключами.)
Определение Третья нормальная форма
(Снова определение дается в предположении существования единственного ключа.)
Отношение R находится в третьей нормальной форме (3NF) в том и только в том случае, если находится в 1NF и каждый неключевой атрибут не является транзитивно зависимым от первичного ключа.
Можно произвести декомпозицию отношения СОТРУДНИКИ-ОТДЕЛЫ в два отношения СОТРУДНИКИ и ОТДЕЛЫ:
СОТРУДНИКИ (СОТР_НОМЕР, ОТД_НОМЕР)
Первичный ключ:
СОТР_НОМЕР
Функциональные зависимости:
СОТР_НОМЕР --> ОТД_НОМЕР ОТДЕЛЫ (ОТД_НОМЕР, СОТР_ЗАРП)
Первичный ключ:
ОТД_НОМЕР
Функциональные зависимости:
ОТД_НОМЕР --> СОТР_ЗАРП
Каждое из этих двух отношений находится в 3NF и свободно от отмеченных аномалий.
Если отказаться от того ограничения, что отношение обладает единственным ключом, то определение 3NF примет следующую форму:
Определение Вторая нормальная форма
(В этом определении предполагается, что единственным ключом отношения является первичный ключ.)
Отношение R находится во второй нормальной форме (2NF) в том и только в том случае, когда находится в 1NF, и каждый неключевой атрибут полностью зависит от первичного ключа.
Можно произвести следующую декомпозицию отношения СОТРУДНИКИ-ОТДЕЛЫ-ПРОЕКТЫ в два отношения СОТРУДНИКИ-ОТДЕЛЫ и СОТРУДНИКИ-ПРОЕКТЫ:
СОТРУДНИКИ-ОТДЕЛЫ (СОТР_НОМЕР, СОТР_ЗАРП, ОТД_НОМЕР)
Первичный ключ:
СОТР_НОМЕР
Функциональные зависимости:
СОТР_НОМЕР --> СОТР_ЗАРП СОТР_НОМЕР --> ОТД_НОМЕР ОТД_НОМЕР --> СОТР_ЗАРП СОТРУДНИКИ-ПРОЕКТЫ (СОТР_НОМЕР, ПРО_НОМЕР, СОТР_ЗАДАН)
Первичный ключ:
СОТР_НОМЕР, ПРО_НОМЕР
Функциональные зависимости:
СОТР_НОМЕР, ПРО_НОМЕР --> CОТР_ЗАДАН
Каждое из этих двух отношений находится в 2NF, и в них устранены отмеченные выше аномалии (легко проверить, что все указанные операции выполняются без проблем).
Если допустить наличие нескольких ключей, то определение 6 примет следующий вид:
Определение Взаимно независимые атрибуты
Два или более атрибута взаимно независимы, если ни один из этих атрибутов не является функционально зависимым от других.
Дальнейшие понятия и определения (в том числе определение многозначной зависимости и зависимости соединения) будут вводиться по ходу изложения в следующем подразделе.
Определение : Зависимость соединения
Отношение R (X, Y, ..., Z) удовлетворяет зависимости соединения * (X, Y, ..., Z) в том и только в том случае, когда R восстанавливается без потерь путем соединения своих проекций на X, Y, ..., Z.
Oracle
Решение компании Oracle в области складов данных основывается на двух факторах: широкий ассортимент продуктов самой компании и деятельность партнеров в рамках программы Warehouse Technology Initiative. Возможности Oracle в области складов данных базируются на следующих составляющих:
наличие реляционной СУБД Oracle 7, которая постоянно совершенствуется для лучшего удовлетворения потребностей складов данных; существование набора готовых приложений, обеспечивающих возможности разработки склада данных; высокий технологический потенциал компании в области анализа данных; доступность ряда продуктов, производимых другими компаниями.
Основные понятия Intranet
Поскольку для разработки Intranet-систем используются методы и средства Internet, и главным образом, технология WWW, то и понятия и термины Internet и Intranet совпадают. Приведем некоторые из них:
Основные понятия модели Entity-Relationship (Сущность-Связи)
Сущность - это реальный или представляемый объект, информация о котором должна сохраняться и быть доступна. В диаграммах ER-модели сущность представляется в виде прямоугольника, содержащего имя сущности. При этом имя сущности - это имя типа, а не некоторого конкретного экземпляра этого типа. Для большей выразительности и лучшего понимания имя сущности может сопровождаться примерами конкретных объектов этого типа.
Ниже изображена сущность АЭРОПОРТ с примерными объектами Шереметьево и Хитроу:
| АЭРОПОРТ например, Шереметьево, Хитроу |
Каждый экземпляр сущности должен быть отличим от любого другого экземпляра той же сущности (это требование в некотором роде аналогично требованию отсутствия кортежей-дубликатов в реляционных таблицах).
Связь - это графически изображаемая ассоциация, устанавливаемая между двумя сущностями. Эта ассоциация всегда является бинарной и может существовать между двумя разными сущностями или между сущностью и ей же самой (рекурсивная связь). В любой связи выделяются два конца (в соответствии с существующей парой связываемых сущностей), на каждом из которых указывается имя конца связи, степень конца связи (сколько экземпляров данной сущности связывается), обязательность связи (т.е. любой ли экземпляр данной сущности должен участвовать в данной связи).
Связь представляется в виде линии, связывающей две сущности или ведущей от сущности к ней же самой. При это в месте "стыковки" связи с сущностью используются трехточечный вход в прямоугольник сущности, если для этой сущности в связи могут использоваться много (many) экземпляров сущности, и одноточечный вход, если в связи может участвовать только один экземпляр сущности. Обязательный конец связи изображается сплошной линией, а необязательный - прерывистой линией.
Как и сущность, связь - это типовое понятие, все экземпляры обеих пар связываемых сущностей подчиняются правилам связывания.
В изображенном ниже примере связь между сущностями БИЛЕТ и ПАССАЖИР связывает билеты и пассажиров.
При том конец сущности с именем "для" позволяет связывать с одним пассажиром более одного билета, причем каждый билет должен быть связан с каким-либо пассажиром. Конец сущности с именем "имеет" означает, что каждый билет может принадлежать только одному пассажиру, причем пассажир не обязан иметь хотя бы один билет.

Лаконичной устной трактовкой изображенной диаграммы является следующая:
Каждый БИЛЕТ предназначен для одного и только одного ПАССАЖИРА; Каждый ПАССАЖИР может иметь один или более БИЛЕТОВ.
На следующем примере изображена рекурсивная связь, связывающая сущность ЧЕЛОВЕК с ней же самой. Конец связи с именем "сын" определяет тот факт, что у одного отца может быть более чем один сын. Конец связи с именем "отец" означает, что не у каждого человека могут быть сыновья.

Лаконичной устной трактовкой изображенной диаграммы является следующая:
Каждый ЧЕЛОВЕК является сыном одного и только одного ЧЕЛОВЕКА; Каждый ЧЕЛОВЕК может являться отцом для одного или более ЛЮДЕЙ ("ЧЕЛОВЕКОВ").
Атрибутом сущности является любая деталь, которая служит для уточнения, идентификации, классификации, числовой характеристики или выражения состояния сущности. Имена атрибутов заносятся в прямоугольник, изображающий сущность, под именем сущности и изображаются малыми буквами, возможно, с примерами.
Пример:
| ЧЕЛОВЕК |
| имя |
Основные производители серверов баз данных и характеристика их продуктовЕстественно, мы не можем в этом разделе (третьего уровня!) достаточно детально представить производителей серверных продуктов баз данных и собственно эти продукты. Это связано и с допустимым объемом раздела, и с тем, что по поводу каждой компании можно сказать очень много, и с тем, что серверные продукты управления базами данных являются, по всей видимости наиболее сложными программными продуктами, присутствующими на рынке, и с тем, что компании-производители серверных продуктов очень не любят открывать технические детали реализации (это считается частью "know-how" компании). Мы постараемся охарактеризовать деятельность и продукты ведущей пятерки производителей (компаний Oracle, Informix, Sybase, Computer Associates и IBM), касаясь только особенностей серверов баз данных и не затрагивая возможности громадного числа сопутствующих программных продуктов. Кроме того, мы не будем обсуждать продукты компаний "второго эшелона", хотя зачастую они обладают специфическими возможностями. Ответ сервераОтвет сервера может быть, как и запрос, упрощенным или полным. При упрощенном ответе сервер возвращает только тело ресурса (например, текст HTML-документа). При полном ответе клиенту возвращается строка состояния (Status-Line), общий заголовок, заголовок ответа, заголовок ресурса и тело ресурса. В форме Бекуса-Наура полный ответ представляется следующим образом: <Полный ответ> := <Строка состояния> (<Общий заголовок> <Заголовок ответа> <Заголовок ресурса>) <символ новой строки>[<тело ресурса>] Строка состояния состоит из версии протокола, кода возврата и краткого описания этого кода. Например, она может выглядеть так: "HTTP/1.0 200 Success". Заголовок ответа сервера может состоять из адреса URI запрашиваемого ресурса, и/или наименования программы сервера, и/или кода идентификации для работы в защищенном режиме. Состав полей заголовка ресурса является общим и для запроса клиента и для ответа сервера, и состоит из разрешения на метод доступа, типа кодировки тела ресурса (содержания ресурса), длины тела ресурса, типа ресурса, время действия данной копии ресурса, времени последнего изменения ресурса и расширения заголовка. Рассмотрим более подробно поля заголовка, обращая внимание на реальное применение каждого из них и возможность проявления ошибок при обработке этих полей разными программами (серверами и клиентами). Если в заголовке ответа сервера указано предложение Location, то это значит, что требуемый ресурс находится по другому адресу и его надо запросить заново. Такая процедура называется перенаправлением. Перенаправление в заголовке будет выглядеть как: Location: http://apollo.polyn.kiae.su/risk/riskform.html Имя и версия сервера указываются в поле Server. При использовании сервера CERN данное поле будет выглядеть как: Server: CERN/3.0 libwww/2.17 В заголовке может встречаться и поле контроля доступа WWW-Authenticate, которое определяет способ доступа к закрытым ресурсам. Например, это поле может выглядеть как: WWW-Authenticate: Basic realm="WallyWorld" Кроме рассмотренных выше полей, в заголовке могут встретиться и другие поля, которые определяют содержание тела передаваемого ресурса. Эти поля относятся к заголовку ресурса, но в ответе сервера они встречаются вперемешку с общими полями. Поле Allow определяет разрешенные методы доступа к ресурсу: Allow: GET,HEAD Поле Сontent-Encoding определяет тип кодирования передаваемого ресурса: Content-Encoding: x-gzip В данном случае указывается, что ресурс является заархивированным файлом в формате zip. Обычно ресурсы хранятся в виде, указанном в данном поле, и при их получении клиент должен обеспечить их преобразование в приемлемый для отображения вид. Это своего рода предобработка данных, которая базируется обычно на MIME типах. В машинах, где недостаточно памяти на видео-адаптерах, используют предобработку для преобразования изображений в приемлемый для отображения вид. Так, например, для персональных компьютеров с 512 КБ памяти на видеоадаптере используют предобработку для преобразования 256-цветных картинок в 16-цветные. Если этого не делать, то можно наблюдать интересный эффект: в Unix-системах при работе с программами Chimera и Mosaic 256-цветные картинки удваиваются, т.е. вместо одной на экране отображаются последовательно две картинки. Это связано с тем, что для 256 цветов нужно ровно в два раза больше памяти, чем для 16. Для того, чтобы избежать двойного отображения встроенных в текст картинок, их следует преобразовать. Другим полем, которое проявляет себя при работе в сети, порождая ошибки отображения ранними версиями программ просмотра или ранним версиями программ серверов, является поле Пакет MS AccessMicrosoft Access - первая СУБД для персональных компьютеров, созданная для работы в среде Windows и несущая в себе многие черты новых инструментальных средств для разработки файл-серверных приложений. Эта система ориентирована как на конечных пользователей, так и на профессиональных программистов, облегчая и тем, и другим разработку и доступ к БД, быстрое создание информационных приложений с графическим интерфейсом. Система может работать в следующих версиях операционных систем: Windows 3.1, Windows 95 и Windows NT. Пакет Microsoft Access 2.0 полностью поддерживает кириллицу, в частности, сортировку данных в соответствии с русским алфавитом. Microsoft Access является составной частью семейства программ Microsoft Office. Все семейство основано на IntelliSense - интеллектуальной технологии, которая "чувствует", что нужно пользователю, и дает требуемый результат, автоматически выполняя рутинные операции и упрощая сложные задачи. Например, наличие десятков мастеров (Wizards), помогает автоматизировать массу операций от создания форм до написания программ. От пользователя требуется ответить лишь на несколько простых вопросов. Ниже приводится перечень некоторых необходимых мастеров: мастер Table Wizards; мастер Command Button Wizards; мастер Form Wizards; мастер Report Wizards; мастер Mail Merge Wizards. Мастер Table Wizards создает структуры базы данных и таблиц таким образом, что пользователи могут сразу же получать результаты. Мастер Command Button Wizards создает функциональные кнопки, что избавляет пользователя от потребностей в программировании. Мастера Form Wizards и Report Wizards используются при создании сложных форм и отчетов. Для создания более простых форм и отчетов можно использовать такие функции как Автоформа (AutoForm) и Автоотчет (AutoReport). Мастер Mail Merge Wizard работает совместно с Microsoft Word, облегчая подготовку почтовых рассылок - необходимо только выделить данные для слияния или документ, который необходимо отослать. MS Word можно также использовать для непосредственной работы с данными в Microsoft Access.
Перенос файл-серверных приложений в среду клиент-серверУсложнение информационных приложений, их интеграция в корпоративные сети, создание распределенных БД коллективного пользования требуют новых инструментальных средств и "истинно реляционных" СУБД. Традиционно используемые "персональные" СУБД типа Clipper и FoxPro не могут обеспечить требуемый уровень надежности и достоверности информации, особенно при работе в сетях. Подобные СУБД не поддерживают целостность баз данных и не имеют механизмов управления транзакциями, что существенно затрудняет обеспечение логической непротиворечивости информации при сбоях оборудования и программ. Возросшим требованиям удовлетворяет архитектура клиент-сервер, основанная на выделении одного узла сети под сервер БД с реляционной СУБД, поддерживающей максимальный уровень надежности хранения, ее актуальность и достоверность. До недавнего времени создание приложений для таких СУБД было делом непростым и требовало высокой квалификации, методика программирования на непроцедурном языке SQL не согласуется с опытом разработки приложений для СУБД на персональных компьютерах. С другой стороны, накоплен большой опыт работы на системах семейства xBase, в частности, Clipper. Создано большое число прикладных программ, которые внедрены в эксплуатацию. При интеграции отдельных автоматизированных рабочих мест в корпоративные сети было бы желательно сохранить не только постановку задачи и применяемые алгоритмы, но и собственно программное обеспечение. Существует несколько подходов к интеграции и адаптации файл-серверных приложений к архитектуре клиент-сервер: использование библиотек доступа к серверам БД; связь с сервером БД через открытый протокол ODBC; укрупнение файл-серверных приложений. Чтобы оценить возможности этих способов, рассмотрим их несколько подробнее. Первом уровнереализуется корпоративный склад данных на основе одной из развитых современных реляционных СУБД. Это хранилище интегрированных в основном детализированных данных. Реляционные СУБД обеспечивают эффективное хранение и управление данными очень большого объема, но не слишком хорошо соответствуют потребностям OLAP-систем, в частности, в связи с требованием многомерного представления данных. На Первый способсостоит в том, что все операторы SQL, с которыми может работать данная прикладная программа, собраны в один модуль и оформлены как процедуры этого модуля. Для этого SQL/89 содержит специальный подъязык - язык модулей. При использовании такого способа взаимодействия с БД прикладная программа содержит вызовы процедур модуля SQL с передачей им фактических параметров и получением ответных параметров. Пятая нормальная формаВо всех рассмотренных до этого момента нормализациях производилась декомпозиция одного отношения в два. Иногда это сделать не удается, но возможна декомпозиция в большее число отношений, каждое из которых обладает лучшими свойствами. Рассмотрим, например, отношение СОТРУДНИКИ-ОТДЕЛЫ-ПРОЕКТЫ (СОТР_НОМЕР, ОТД_НОМЕР, ПРО_НОМЕР) Предположим, что один и тот же сотрудник может работать в нескольких отделах и работать в каждом отделе над несколькими проектами. Первичным ключом этого отношения является полная совокупность его атрибутов, отсутствуют функциональные и многозначные зависимости. Поэтому отношение находится в 4NF. Однако в нем могут существовать аномалии, которые можно устранить путем декомпозиции в три отношения. Подготавливаемый оператор позиционного удаления<preparable dynamic delete statement: positioned> ::= DELETE [FROM <table name>] WHERE CURRENT OF <cursor name> Основной резон появления этого и следующего операторов состоит в том, что сочетание курсора, определенного на динамически подготовленном операторе выборки, и статически задаваемых операторов удаления и модификации по этому курсору, выглядит довольно нелепо. Поэтому в стандарте появились динамически подготавливаемые позиционные операторы удаления и вставки. Естественно, что выполняться они должны с помощью оператора EXECUTE. Подготавливаемый оператор позиционной модификации<preparable dynamic update statement: positioned> ::= UPDATE [<table name>] SET <set clause> [{<comma> <set clause>}...] WHERE CURRENT OF <cursor name> Пояснения аналогичны приведенным в предыдущем пункте. Подход, используемый в CASE-средстве Vantage Team BuilderВ CASE-средстве Vantage Team Builder (Westmount I-CASE) используется один из вариантов нотации П. Чена. На ER-диаграммах сущность обозначается прямоугольником, содержащим имя сущности (рисунок 4.19), а связь - ромбом, связанным линией с каждой из взаимодействующих сущностей. Числа над линиями означают степень связи.
 Рис. 4.19. Обозначение сущностей и связей Связи являются многонаправленными и могут иметь атрибуты (за исключением ключевых). Выделяют два вида связей: необязательная связь (optional); слабая связь (weak). В Подходы и имеющиеся решенияВ этом разделе мы коротко охарактеризуем продукты ведущих поставщиков, имеющие связь с технологией складов данных. Подтипы и супертипы:одна сущность является обобщающим понятием для группы подобных сущностей (рисунок 4.9). ПодзапросНаконец, последняя конструкция SQL/89, которая может содержать табличные выражения, - это подзапрос, т.е. запрос, который может входить в предикат условия выборки оператора SQL. В SQL/89 к подзапросам применяется то ограничение, что результирующая таблица должна содержать в точности один столбец. Поэтому в синтаксических правилах, определяющих подзапрос, вместо списка выборки указано "выражение, вычисляющее значение", т.е. арифметическое выражение. Заметим еще, что поскольку подзапрос всегда вложен в некоторый другой оператор SQL, то в качестве констант в арифметическом выражении выборки и логических выражениях разделов WHERE и HAVING можно использовать значения столбцов текущих строк таблиц, участвующих в (под)запросах более внешнего уровня. Более подробно об этом см. ниже, при описании семантики табличных выражений. Поисковые серверыТакие имена информационных служб как Lycos, AltaVista, Yahoo, OpenText, InfoSeek и ряд других, хорошо известны пользователям Internet. Без пользования услугами этих систем практически нельзя найти что-либо полезное в море информационных ресурсов Сети. Но что они из себя представляют, как устроены, почему результат поиска в терабайтах информации выдается так быстро, как устроено ранжирование документов при выдаче, что из себя представляют информационные массивы этих систем - этим вопросам посвящен этот раздел. Полной (total)связи участвуют все экземпляры хотя бы одной из сущностей. Это означает, что экземпляры такой связи существуют только при условии существования экземпляров другой сущ-ности. Полная связь может иметь один из 4-х видов: обязательная связь, слабая связь, связь "супертип-подтип" и ассоциативная связь. Понятие сервера баз данныхДоступ к базе данных от прикладной программы или пользователя производится путем обращения к клиентской части системы. В качестве основного интерфейса между клиентской и серверной частями выступает язык баз данных SQL. Этот язык по сути дела представляет собой текущий стандарт интерфейса СУБД в открытых системах. Собирательное название SQL-сервер относится ко всем серверам баз данных, основанных на SQL. Соблюдая предосторожности при программировании, можно создавать прикладные информационные системы, мобильные в классе SQL-серверов. Серверы баз данных, интерфейс которых основан исключительно на языке SQL, обладают своими преимуществами и своими недостатками. Очевидное преимущество - стандартность интерфейса. В пределе, который вряд ли полностью достижим, клиентские части любой SQL-ориентированной СУБД могли бы работать с любым SQL-сервером вне зависимости от того, кто его произвел. Недостаток тоже довольно очевиден. При таком высоком уровне интерфейса между клиентской и серверной частями системы на стороне клиента работает слишком мало программ СУБД. Это нормально, если на стороне клиента используется маломощная рабочая станция. Но если клиентский компьютер обладает достаточной мощностью, то часто возникает желание возложить на него больше функций управления базами данных, разгрузив сервер, который является узким местом всей системы. Одним из перспективных направлений СУБД является гибкое конфигурирование системы, при котором распределение функций между клиентской и пользовательской частями СУБД определяется при установке системы. POST- этот метод разработан для передачи большого объема информации на сервер. Им пользуются для аннотирования существующих ресурсов, посылки почтовых сообщений, работы с формами интерфейсов к внешним базам данных и внешним исполняемым программам. В отличии от GET и HEAD, в POST передается тело ресурса, которое и является информацией из поля форм или других источников ввода. В первых версиях протокола были определены и другие методы доступа (DELETE, например), но они не нашли должного применения. Многие функции, которые возлагали на эти методы, можно успешно выполнять через POST. Изменение числа методов доступа отражает практику использования HTTP. Однако, с исторической и методической точек зрения, первые версии протокола представляют несомненный интерес, особенно раздел, описывающий методы доступа. В версии 1993 года насчитывалось 13 различных методов доступа. Среди этих методов были такие, например, как: CHECKOUT - защита от несанкционированного доступа; PUT - замена содержания информационного ресурса; DELETE - удаление ресурса; LINK - создание гипертекстовой ссылки; UNLINK - удаление гипертекстовой ссылки; SPACEJUMP - переход по координатам; SEARCH - поиск. Из этого списка видно, что протокол был действительно максимально ориентирован на работу с гипертекстовыми распределенными системами, причем не только с точки зрения потребителя, но и с точки зрения разработчика подобных систем. Однако, во-первых, как показывал опыт, практически не использовались методы доступа, связанные с изменением информации. Это объясняется прежде всего соображениями безопасности. Ни один администратор не позволит неизвестно кому менять информацию на его сервере. Во-вторых, методы SPACEJUMP и SEARCH были с успехом заменены на функционально аналогичные CGI-скрипты. Из этого не следует, что их возрождение невозможно, например, в язык гипертекстовой разметки вернулись ссылки, общие для всего документа, но пока их реализация в протоколе отложена. В-третьих, не нашли практической реализации методы установления/удаления ссылок LINK и UNLINK.
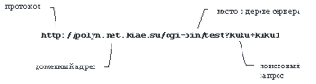 Рис. 5.1. Полный адрес ресурса Однако такой адрес реально нужен для работы через промежуточный сервер, так как тот может пересылать запросы. При обращении к первичному серверу клиент может опускать протокол и адрес, устанавливая взаимодействие с сервером по адресу, указанному в URL (в исходном документе), и порту 80, передавая только путь от корня сервера. Здесь пока оставим обсуждение элементов запроса и обратимся к структуре ответа сервера. Дело в том, что элементы заголовков запроса и ответа одинаковые, и поэтому их имеет смысл обсудить после определения структуры ответа сервера. Предикат betweenПредикат between имеет следующий синтаксис: <between predicate> ::= <value expression> [NOT] BETWEEN <value expression> AND <value expression> Результат "x BETWEEN y AND z" тот же самый, что результат "x >= y AND x <= z". Результат "x NOT BETWEEN y AND z" тот же самый, что результат "NOT (x BETWEEN y AND z)". Предикат existsПредикат exists имеет следующий синтаксис: lt;exists predicate> ::= EXISTS <subquery> Значением этого предиката всегда является true или false, и это значение равно true тогда и только тогда, когда результат вычисления подзапроса не пуст. |
