Аргументы в пользу динамической типизации
Несмотря на все это, динамическая типизация не теряет своих приверженцев, в частности, среди Smalltalk-программистов. Их аргументы основаны прежде всего на реализме, речь о котором шла выше. Они уверены, что статическая типизация чересчур ограничивает их, не давая им свободно выражать свои творческие идеи, называя иногда ее "поясом целомудрия".
С такой аргументацией можно согласиться, но лишь для статически типизированных языков, не поддерживающих ряд возможностей. Стоит отметить, что все концепции, связанные с понятием типа и введенные в предыдущих лекциях, необходимы - отказ от любой из них чреват серьезными ограничениями, а их введение, напротив, придает нашим действиям гибкость, а нам самим дает возможность в полной мере насладиться практичностью статической типизации.
Базисная конструкция
Простота типизации в ОО-подходе есть следствие простоты объектной вычислительной модели. Опуская детали, можно сказать, что при выполнении ОО-системы происходят события только одного рода - вызов компонента (feature call):
x.f (arg)
означающий выполнение операции f над объектом, присоединенным к x, с передачей аргумента arg (возможно несколько аргументов или ни одного вообще). Программисты Smalltalk говорят в этом случае о "передаче объекту x сообщения f с аргументом arg", но это - лишь отличие в терминологии, а потому оно несущественно.
То, что все основано на этой Базисной Конструкции (Basic Construct), объясняет частично ощущение красоты ОО-идей.
Из Базисной Конструкции следуют и те ненормальные ситуации, которые могут возникнуть в процессе выполнения:
Определение: нарушение типа
Нарушение типа в период выполнения или, для краткости, просто нарушение типа (type violation) возникает в момент вызова x.f (arg), где x присоединен к объекту OBJ, если либо:
не существует компонента, соответствующего f и применимого к OBJ,такой компонент имеется, однако, аргумент arg для него недопустим.
Проблема типизации - избегать таких ситуаций:
Проблема типизации ОО-систем
Когда мы обнаруживаем, что при выполнении ОО-системы может произойти нарушение типа?
Ключевым является слово когда. Рано или поздно вы поймете, что имеет место нарушение типа. Например, попытка выполнить компонент "Пуск торпеды" для объекта "Служащий" не будет работать и при выполнении произойдет отказ. Однако возможно вы предпочитаете находить ошибки как можно раньше, а не позже.
Библиографические замечания
Ряд материалов этой лекции представлен в докладах на форумах OOPSLA 95 и TOOLS PACIFIC 95, а также опубликован в [M 1996a]. Ряд обзорных материалов заимствован из статьи [M 1989e].
Понятие автоматического выведения типов введено в [Milner 1989], где описан алгоритм выведения типов функционального языка ML. Связь между полиморфизмом и проверкой типов была исследована в работе [Cardelli 1984a].
Приемы повышения эффективности кода динамически типизированных языков в контексте языка Self можно найти в [Ungar 1992].
Теоретическую статью, посвященную типам в языках программирования и оказавшую большое влияние на специалистов, написали Лука Карделли (Luca Cardelli) и Петер Вегнер (Peter Wegner) [Cardelli 1985]. Эта работа, построенная на базе лямбда-исчисления (см. [M 1990]), послужила основой многих дальнейших изысканий. Ей предшествовала другая фундаментальная статья Карделли [Cardelli 1984].
Руководство по ISE включает введение в проблемы совместного применения полиморфизма, ковариантности и скрытия потомком [M 1988a]. Отсутствие надлежащего анализа в первом издании этой книги послужило причиной ряда критических дискуссий (первыми из которых стали комментарии Филиппа Элинка (Philippe Elinck) в бакалаврской работе "De la Conception-Programmation par Objets", Memoire de licence, Universite Libre de Bruxelles (Belgium), 1988), высказанных в работах [Cook 1989] и [America 1989a]. В статье Кука приведены несколько примеров, связанных с проблемой ковариантности, и предпринята попытка ее решения. Решение на основе типовых параметров для ковариантных сущностей на TOOLS EUROPE 1992 предложил Франц Вебер [Weber 1992]. Точные определения понятий системной корректности, а также классовой корректности, даны в [M 1992], там же предложено решение с применением полного анализа системы. Решение Кэтколл впервые предложено в [M 1996a]; см. также [M-Web].
Решение Закрепления было представлено в моем докладе на семинаре TOOLS EUROPE 1994. Тогда я, однако, не усмотрел необходимости в anchor-объявлениях и связанных с этим ограничениях совместимости. Поль Дюбуа (Paul Dubois) и Амирам Йехудай (Amiram Yehudai) не преминули заметить, что в этих условиях проблема ковариантности остается. Они, а также Рейнхардт Будде (Reinhardt Budde), Карл-Хайнц Зилла (Karl-Heinz Sylla), Ким Вальден (Kim Walden) и Джеймс Мак-Ким (James McKim) высказали множество замечаний, имевших принципиальное значение в той работе, которая привела к написанию этой лекции.
Вопросам ковариантности посвящено большое количество литературы. В [Castagna 1995] и [Castagna 1996] вы найдете как обширную библиографию, так и обзор математических аспектов проблемы. Перечень ссылок на онлайновые материалы по теории типов в ООП и Web-страницы их авторов см. на странице Лорана Дами (Laurent Dami) [Dami-Web]. Понятия ковариантности и контравариантности заимствованы из теории категорий. Их появлением в контексте программной типизации мы обязаны Луке Карделли, который начал использовать их в своих выступлениях с начала 80-х гг., но до конца 80-х не прибегал к ним в печати.
Приемы на основе типовых переменных описаны в [Simons 1995], [Shang 1996], [Bruce 1997].
Контравариантность была реализована в языке Sather. Пояснения даны в [Szypersky 1993].

Глобальный анализ
Этот раздел посвящен описанию промежуточного подхода. Основные практические решения изложены в лекции 17.
Изучая вариант с закреплением, мы заметили, что его основной идеей было разделение ковариантного и полиморфного наборов сущностей. Так, если взять две инструкции вида
s := b ... s.share (g)
каждая из них служит примером правильного применения важных ОО-механизмов: первая - полиморфизма, вторая - переопределения типов. Проблемы начинаются при объединении их для одной и той же сущности s. Аналогично:
p := r ... p.add_vertex (...)
проблемы начинаются с объединения двух независимых и совершенно невинных операторов.
Ошибочные вызовы ведут к нарушению типов. В первом примере полиморфное присваивание присоединяет объект BOY к сущности s, что делает g недопустимым аргументом share, так как она связана с объектом GIRL. Во втором примере к сущности r присоединяется объект RECTANGLE, что исключает add_vertex из числа экспортируемых компонентов.
Вот и идея нового решения: заранее - статически, при проверке типов компилятором или иными инструментальными средствами - определим набор типов (typeset) каждой сущности, включающий типы объектов, с которыми сущность может быть связана в период выполнения. Затем, опять же статически, мы убедимся в том, что каждый вызов является правильным для каждого элемента из наборов типов цели и аргументов.
В наших примерах оператор s := b указывает на то, что класс BOY принадлежит набору типов для s (поскольку в результате выполнения инструкции создания create b он принадлежит набору типов для b). GIRL, ввиду наличия инструкции create g, принадлежит набору типов для g. Но тогда вызов share будет недопустим для цели s типа BOY и аргумента g типа GIRL. Аналогично RECTANGLE находится в наборе типов для p, что обусловлено полиморфным присваиванием, однако, вызов add_vertex для p типа RECTANGLE окажется недопустимым.
Эти наблюдения наводят нас на мысль о создании глобального подхода на основе нового правила типизации:
Правило системной корректности
Вызов x.f (arg) является системно-корректным, если и только если он классово-корректен для x, и arg, имеющих любые типы из своих соответствующих наборов типов.
В этом определении вызов считается классово-корректным, если он не нарушает правила Вызова Компонентов, которое гласит: если C есть базовый класс типа x, компонент f должен экспортироваться C, а тип arg должен быть совместим с типом формального параметра f. (Вспомните: для простоты мы полагаем, что каждый подпрограмма имеет только один параметр, однако, не составляет труда расширить действие правила на произвольное число аргументов.)
Системная корректность вызова сводится к классовой корректности за тем исключением, что она проверяется не для отдельных элементов, а для любых пар из наборов множеств. Вот основные правила создания набора типов для каждой сущности:
Для каждой сущности начальный набор типов пуст.Встретив очередную инструкцию вида create {SOME_TYPE} a, добавим SOME_TYPE в набор типов для a. (Для простоты будем полагать, что любая инструкция create a будет заменена инструкцией create {ATYPE} a, где ATYPE - тип сущности a.)Встретив очередное присваивание вида a := b, добавим в набор типов для a все элементы набора типов для b.Если a есть формальный параметр подпрограммы, то, встретив очередной вызов с фактическим параметром b, добавим в набор типов для a все элементы набора типов для b.Будем повторять шаги (3) и (4) до тех пор, пока наборы типов не перестанут изменяться.
Данная формулировка не учитывает механизма универсальности, однако расширить правило нужным образом можно без особых проблем. Шаг (5) необходим ввиду возможности цепочек присваивания и передач (от b к a, от c к b и т. д.). Нетрудно понять, что через конечное число шагов этот процесс прекратится.
| Число шагов ограничено длиной максимальной цепочки присоединений; другими словами максимум равен n, если система содержит присоединения от xi+1 к xi для i=1, 2, ... n-1. Повторение шагов (3) и (4) известно как метод "неподвижной точки". |
Как вы, возможно, заметили, правило не учитывает последовательности инструкций. В случае
create {TYPE1} t; s := t; create {TYPE2} t
в набор типов для s войдет как TYPE1, так и TYPE2, хотя s, учитывая последовательность инструкций, способен принимать значения только первого типа. Учет расположения инструкций потребует от компилятора глубокого анализа потока команд, что приведет к чрезмерному повышению уровня сложности алгоритма. Вместо этого применяются более пессимистичные правила: последовательность операций:
create b s := b s.share (g)
будет объявлена системно-некорректной, несмотря на то, что последовательность их выполнения не приводит к нарушению типа.
Глобальный анализ системы был (более детально) представлен в 22-й главе монографии [M 1992]. При этом была решена как проблема ковариантности, так и проблема ограничений экспорта при наследовании. Однако в этом подходе есть досадный практический недочет, а именно: предполагается проверка системы в целом, а не каждого класса в отдельности. Убийственным оказывается правило (4), которое при вызове библиотечной подпрограммы будет учитывать все ее возможные вызовы в других классах.
Хотя затем были предложены алгоритмы работы с отдельными классами в [M 1989b], их практическую ценность установить не удалось. Это означало, что в среде программирования, поддерживающей возрастающую компиляцию, необходимо будет организовать проверку всей системы. Желательно проверку вводить как элемент (быстрой) локальной обработки изменений, внесенных пользователем в некоторые классы. Хотя примеры применения глобального подхода известны, - так, программисты на языке C используют инструмент lint для поиска несоответствий в системе, не обнаруживаемых компилятором, - все это выглядит не слишком привлекательно.
В итоге, как мне известно, проверка системной корректности осталась никем не реализованной. (Другой причиной такого исхода, возможно, послужила сложность самих правил проверки.)
Классовая корректность предполагает проверку, ограниченную классом, и, следовательно, возможна при возрастающей компиляции.Системная корректность предполагает глобальную проверку всей системы, что входит в противоречие с возрастающей компиляцией.
Однако, несмотря на свое имя, фактически можно проверить системную корректность, используя только возрастающую проверку классов (в процессе работы обычного компилятора). Это и будет финальным вкладом в решение проблемы.
Использование родовых параметров
Универсальность лежит в основе интересной идеи, впервые высказанной Францем Вебером (Franz Weber). Объявим класс SKIER1, ограничив универсализацию родового параметра классом ROOM:
class SKIER1 [G -> ROOM] feature accommodation: G accommodate (r: G) is ... require ... do accommodation := r end end
Тогда класс GIRL1 будет наследником SKIER1 [GIRL_ROOM] и т. д. Тем же приемом, каким бы странным он не казался на первый взгляд, можно воспользоваться и при отсутствии параллельной иерархии: class SKIER [G -> SKIER].
Этот подход позволяет решить проблему ковариантности. При любом использовании класса необходимо задать фактический родовой параметр ROOM или GIRL_ROOM, так что неверная комбинация просто становится невозможной. Язык становится безвариантным, а система полностью отвечает потребностям ковариантности благодаря родовым параметрам.
К сожалению, эта техника неприемлема как общее решение, поскольку ведет к разрастанию списка родовых параметров, по одному на каждый тип возможного ковариантного аргумента. Хуже того, добавление ковариантной подпрограммы с аргументом, тип которого отсутствует в списке, потребует добавления родового параметра класса, а, следовательно, изменит интерфейс класса, повлечет изменения у всех клиентов класса, что недопустимо.
Ключевые концепции
Статическая типизация - залог надежности, читабельности и эффективности.Чтобы быть реалистичной, статической типизации требуется совместное применение механизмов: утверждений, множественного наследования, попытки присваивания, ограниченной и неограниченной универсальности, закрепленных объявлений. Система типов не должна допускать ловушек (приведений типа).Практические правила повторного объявления должны допускать ковариантное переопределение. Типы результатов и аргументов при переопределении должны быть совместимыми с исходными.Ковариантность, также как и возможность скрытия потомком компонента, экспортированного предком, в сочетании с полиморфизмом порождают редко встречающуюся, но весьма серьезную проблему нарушения типов.Этих нарушений можно избежать, используя: глобальный анализ, (что непрактично) ограничивая ковариантность закрепленными типами (что противоречит принципу "Открыт-Закрыт"), решение Кэтколл, препятствующее вызову полиморфной целью подпрограммы с ковариантностью или скрытием потомком.
Контравариантность и безвариантность
Контравариантность устраняет теоретические проблемы, связанные с нарушением системной корректности. Однако при этом теряется реалистичность системы типов, по этой причине рассматривать этот подход в дальнейшем нет никакой необходимости.
Оригинальность языка C++ в том, что он использует стратегию безвариантности (novariance), не позволяя менять тип аргументов в переопределяемых подпрограммах! Если бы язык C++ был строго типизированным языком, его системной типов было бы трудно пользоваться. Простейшее решение проблемы в этом языке, как и обход иных ограничений C++ (скажем, отсутствия ограниченной универсальности), состоит в использовании кастинга - приведения типа, что позволяет полностью игнорировать имеющийся механизм типизации. Это решение не кажется привлекательным. Заметим, однако, что ряд предложений, обсуждаемых ниже, будет опираться на безвариантность, смысл которой придаст введение новых механизмов работы с типами взамен ковариантного переопределения.
Корректность систем и классов
Для обсуждения проблем ковариантности и скрытия потомком нам понадобится несколько новых терминов. Будем называть классово-корректной (class-valid) систему, удовлетворяющую трем правилам описания типов, приведенным в начале лекции. Напомним их: каждая сущность имеет свой тип; тип фактического аргумента должен быть совместимым с типом формального, аналогичная ситуация с присваиванием; вызываемый компонент должен быть объявлен в своем классе и экспортирован классу, содержащему вызов.
Система называется системно-корректной (system-valid), если при ее выполнении не происходит нарушения типов.
В идеале оба понятия должны совпадать. Однако мы уже видели, что классово-корректная система в условиях наследования, ковариантности и скрытия потомком может не быть системно-корректной. Назовем такую ошибку нарушением системной корректности (system validity error).
Корректность систем: первое приближение
Давайте сконцентрируемся вначале на проблеме ковариантности, более важной из двух рассматриваемых. Этой теме посвящена обширная литература, предлагающая ряд разнообразных решений.
Ковариантность
Что происходит с аргументами компонента при переопределении его типа? Это важнейшая проблема, и мы уже видели ряд примеров ее проявления: устройства и принтеры, одно- и двухсвязные списки и т. д. (см. разделы 16.6, 16.7).
Вот еще один пример, помогающий уяснить природу проблемы. И пусть он далек от реальности и метафоричен, но его близость к программным схемам очевидна. К тому же, разбирая его, мы будем часто возвращаться к задачам из практики.
Представим себе готовящуюся к чемпионату лыжную команду университета. Класс GIRL включает лыжниц, выступающих в составе женской сборной, BOY - лыжников. Ряд участников обеих команд ранжированы, показав хорошие результаты на предыдущих соревнованиях. Это важно для них, поскольку теперь они побегут первыми, получив преимущество перед остальными. (Это правило, дающее привилегии уже привилегированным, возможно и делает слалом и лыжные гонки столь привлекательными в глазах многих людей, являясь хорошей метафорой самой жизни.) Итак, мы имеем два новых класса: RANKED_GIRL и RANKED_BOY.
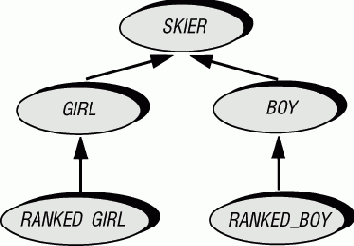
Рис. 17.4. Классификация лыжников
Для проживания спортсменов забронирован ряд номеров: только для мужчин, только для девушек, только для девушек-призеров. Для отображения этого используем параллельную иерархию классов: ROOM, GIRL_ROOM и RANKED_GIRL_ROOM.
Вот набросок класса SKIER:
class SKIER feature roommate: SKIER -- Сосед по номеру. share (other: SKIER) is -- Выбрать в качестве соседа other. require other /= Void do roommate := other end ... Другие возможные компоненты, опущенные в этом и последующих классах ... end
Нас интересуют два компонента: атрибут roommate и процедура share, "размещающая" данного лыжника в одном номере с текущим лыжником:
s1, s2: SKIER ... s1.share (s2)
При объявлении сущности other можно отказаться от типа SKIER в пользу закрепленного типа like roommate (или like Current для roommate и other одновременно). Но давайте забудем на время о закреплении типов (мы к ним еще вернемся) и посмотрим на проблему ковариантности в ее изначальном виде.
Как ввести переопределение типов? Правила требуют раздельного проживания юношей и девушек, призеров и остальных участников. Для решения этой задачи при переопределении изменим тип компонента roommate, как показано ниже (здесь и далее переопределенные элементы подчеркнуты).
class GIRL inherit SKIER redefine roommate end feature roommate: GIRL -- Сосед по номеру. end
Переопределим, соответственно, и аргумент процедуры share. Более полный вариант класса теперь выглядит так:
class GIRL inherit SKIER redefine roommate, share end feature roommate: GIRL -- Сосед по номеру. share (other: GIRL) is -- Выбрать в качестве соседа other. require other /= Void do roommate := other end end
Аналогично следует изменить все порожденные от SKIER классы (закрепление типов мы сейчас не используем). В итоге имеем иерархию:
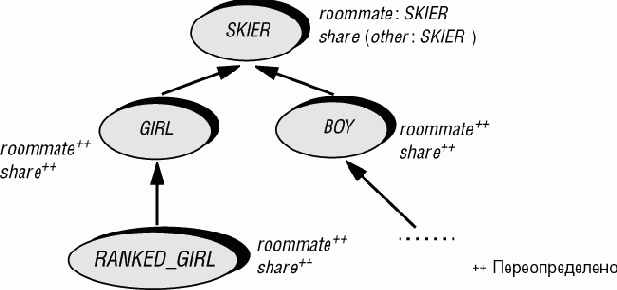
Рис. 17.5. Иерархия участников и повторные определения
Так как наследование является специализацией, то правила типов требуют, чтобы при переопределении результата компонента, в данном случае roommate, новый тип был потомком исходного. То же касается и переопределения типа аргумента other подпрограммы share. Эта стратегия, как мы знаем, именуется ковариантностью, где приставка "ко" указывает на совместное изменение типов параметра и результата. Противоположная стратегия называется контравариантностью.
Все наши примеры убедительно свидетельствуют о практической необходимости ковариантности.
Элемент односвязного списка LINKABLE должен быть связан с другим подобным себе элементом, а экземпляр BI_LINKABLE - с подобным себе. Ковариантно потребуется переопределяется и аргумент в put_right.Всякая подпрограмма в составе LINKED_LIST с аргументом типа LINKABLE при переходе к TWO_WAY_LIST потребует аргумента BI_LINKABLE.Процедура set_alternate принимает DEVICE-аргумент в классе DEVICE и PRINTER-аргумент - в классе PRINTER.
Ковариантное переопределение получило особое распространение потому, что скрытие информации ведет к созданию процедур вида
set_attrib (v: SOME_TYPE) is -- Установить attrib в v. ...
для работы с attrib типа SOME_TYPE. Подобные процедуры, естественно, ковариантны, поскольку любой класс, который меняет тип атрибута, должен соответственно переопределять и аргумент set_attrib. Хотя представленные примеры укладываются в одну схему, но ковариантность распространена значительно шире. Подумайте, например, о процедуре или функции, выполняющей конкатенацию односвязных списков (LINKED_LIST). Ее аргумент должен быть переопределен как двусвязный список (TWO_ WAY_LIST). Универсальная операция сложения infix "+" принимает NUMERIC-аргумент в классе NUMERIC, REAL - в классе REAL и INTEGER - в классе INTEGER. В параллельных иерархиях телефонной службы процедуре start в классе PHONE_SERVICE может требоваться аргумент ADDRESS, представляющий адрес абонента, (для выписки счета), в то время как этой же пр оцедуре в классе CORPORATE_SERVICE потребуется аргумент типа CORPORATE_ADDRESS.
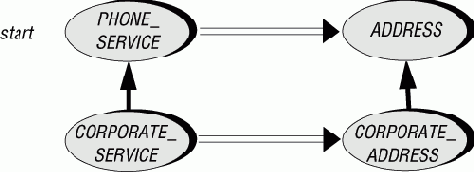
Рис. 17.6. Службы связи
Что можно сказать о контравариантном решении? В примере с лыжниками оно означало бы, что если, переходя к классу RANKED_GIRL, тип результата roommate переопределили как RANKED_GIRL, то в силу контравариантности тип аргумента share можно переопределить на тип GIRL или SKIER. Единственный тип, который не допустим при контравариантном решении, - это RANKED_GIRL! Достаточно, чтобы возбудить наихудшие подозрения у родителей девушек.
Ковариантность и скрытие потомком
Если бы мир был прост, то разговор о типизации можно было бы и закончить. Мы определили цели и преимущества статической типизации, изучили ограничения, которым должны соответствовать реалистичные системы типов, и убедились в том, что предложенные методы типизации отвечают нашим критериям.
Но мир не прост. Объединение статической типизации с некоторыми требованиями программной инженерии создает проблемы более сложные, чем это кажется с первого взгляда. Проблемы вызывают два механизма: ковариантность (covariance) - смена типов параметров при переопределении, скрытие потомком (descendant hiding) - способность класса потомка ограничивать статус экспорта наследуемых компонентов.
Назад, в Ялту
Суть решения Кэтколл (Catcall), - смысл этого понятия мы поясним позднее, - в возвращении к духу Ялтинских соглашений, разделяющих мир на полиморфный и ковариантный (и спутник ковариантности - скрытие потомков), но без необходимости обладания бесконечной мудростью.
Как и прежде, сузим вопрос о ковариантности до двух операций. В нашем главном примере это полиморфное присваивание: s := b, и вызов ковариантной подпрограммы: s.share (g). Анализируя, кто же является истинным виновником нарушений, исключим аргумент g из числа подозреваемых. Любой аргумент, имеющий тип SKIER или порожденный от него, нам не подходит ввиду полиморфизма s и ковариантности share. А потому если статически описать сущность other как SKIER и динамически присоединить к объекту SKIER, то вызов s.share (other) статически создаст впечатление идеального варианта, но приведет к нарушению типов, если полиморфно присвоить s значение b.
Фундаментальная проблема в том, что мы пытаемся использовать s двумя несовместимыми способами: как полиморфную сущность и как цель вызова ковариантной подпрограммы. (В другом нашем примере проблема состоит в использовании p как полиморфной сущности и как цели вызова подпрограммы потомка, скрывающего компонент add_vertex.)
Решение Кэтколл, как и Закрепление, носит радикальный характер: оно запрещает использовать сущность как полиморфную и ковариантную одновременно. Подобно глобальному анализу, оно статически определяет, какие сущности могут быть полиморфными, однако, не пытается быть слишком умным, отыскивая для сущностей наборы возможных типов. Вместо этого всякая полиморфная сущность воспринимается как достаточно подозрительная, и ей запрещается вступать в союз с кругом почтенных лиц, включающих ковариантность и скрытие потомком.
Оценка
Прежде чем мы сведем воедино все, что узнали о ковариантности и скрытии потомком, вспомним еще раз о том, что нарушения корректности систем возникают действительно редко. Наиболее важные свойства статической ОО-типизации были обобщены в начале лекции. Этот впечатляющий ряд механизмов работы с типами совместно с проверкой классовой корректности, открывает дорогу к безопасному и гибкому методу конструирования ПО.
Мы видели три решения проблемы ковариантности, два из которых затронули и вопросы ограничения экспорта. Какое же из них правильное?
На этот вопрос нет окончательного ответа. Следствия коварного взаимодействия ОО-типизации и полиморфизма изучены не так хорошо, как вопросы, изложенные в предыдущих лекциях. В последние годы появились многочисленные публикации по этой теме, ссылки на которые приведены в библиографии в конце лекции. Кроме того, я надеюсь, что в настоящей лекции мне удалось представить элементы окончательного решения или хотя бы к нему приблизиться.
Глобальный анализ кажется непрактичным из-за полной проверки всей системы. Тем не менее, он помог нам лучше понять проблему.
Решение на основе Закрепления чрезвычайно привлекательно. Оно простое, интуитивно понятное, удобное в реализации. Тем сильнее мы должны сожалеть о невозможности поддержки в нем ряда ключевых требований ОО-метода, отраженных в принципе Открыт-Закрыт. Если бы мы и впрямь обладали прекрасной интуицией, то закрепление стало бы великолепным решением, но какой разработчик решится утверждать это, или, тем более, признать, что такой интуицией обладали авторы библиотечных классов, наследуемых в его проекте?
| Это предположение сужает сферу применения многих опубликованных методов, в том числе, основанных на типовых переменных. Если бы мы были уверены в том, что разработчик всегда заранее знает о будущих изменениях типов, задача бы упростилась в теоретическом плане, но из-за ошибочности гипотезы она не имеет практической ценности. |
Если от закрепления мы вынуждены отказаться, то наиболее подходящим кажется Кэтколл-решение, достаточно легко объяснимое и применимое на практике. Его пессимизм не должен исключать полезные комбинации операторов. В случае, когда полиморфный кэтколл порожден "легитимным" оператором, всегда можно безопасно допустить его, введением попытки присваивания. Тем самым ряд проверок можно перенести на время выполнения программы. Однако количество таких случаев должно быть предельно мало.
В качестве пояснения я должен заметить, что на момент написания книги решение Кэтколл не было реализовано. До тех пор, пока компилятор не будет адаптирован к проверке правила типов Кэтколл и не будет успешно применен к репрезентативным системам - большим и малым, - рано говорить, что в проблеме примирения статической типизации с полиморфизмом, сочетаемым с ковариантностью и скрытием потомком, сказано последнее слово.
Одно правило и несколько определений
Правило типов для решения Кэтколл имеет простую формулировку:
Правило типов для Кэтколл
Полиморфные кэтколлы некорректны.
В его основе - столь же простые определения. Прежде всего, полиморфная сущность:
Определение: полиморфная сущность
Сущность x ссылочного (не развернутого) типа полиморфна, если она обладает одним из следующих свойств:
Встречается в присваивании x := y, где сущность y имеет иной тип или по рекурсии полиморфна.Встречается в инструкциях создания create {OTHER_TYPE} x, где OTHER_TYPE не является типом, указанным в объявлении x.Является формальным аргументом подпрограммы.Является внешней функцией.
Цель этого определения - придать статус полиморфной ("потенциально полиморфной") любой сущности, которую при выполнении программы можно присоединить к объектам разных типов. Это определение применимо лишь к ссылочным типам, так как развернутые сущности по природе не могут быть полиморфными.
В наших примерах лыжник s и многоугольник p - полиморфны по правилу (1). Первому из них присваивается объект BOY b, второму - объект RECTANGLE r.
Если вы познакомились с формулировкой понятия набора типов, то заметили, насколько пессимистичнее выглядит определение полиморфной сущности, и насколько проще его проверить. Не пытаясь отыскать все всевозможные динамические типы сущности, мы довольствуемся общим вопросом: может данная сущность быть полиморфной или нет? Наиболее удивительным выглядит правило (3), по которому полиморфным считается каждый формальный параметр (если его тип не расширен, как в случае с целыми и т. д.). Мы даже не утруждаем себя анализом вызовов. Если у подпрограммы есть аргумент, то он находится в полном распоряжении клиента, а значит, и полагаться на указанный в объявлении тип нельзя. Это правило тесно связано с повторным использованием - целью объектной технологии, - где любой класс потенциально может быть включен в состав библиотеки, и будет многократно вызываться различными клиентами.
Характерным свойством этого правила является то, что оно не требует никаких глобальных проверок.
Для выявления полиморфности сущности достаточно просмотреть текст самого класса. Если для всех запросов (атрибутов или функций) сохранять информацию об их статусе полиморфности, то не приходится изучать даже тексты предков. В отличие от отыскания наборов типов, можно обнаружить полиморфные сущности, проверяя класс за классом в процессе возрастающей компиляции.
| Как было сказано при обсуждении наследования, подобный анализ может также представлять ценность при оптимизации кода. |
Определение: полиморфный вызов
Вызов является полиморфным, если его цель полиморфна.
Оба вызова в наших примерах полиморфны: s.share (g) ввиду полиморфизма s, p.add_ vertex (...) ввиду полиморфизма p. Согласно определению, только квалифицированные вызовы могут быть полиморфны. (Придав неквалифицированному вызову f (...) вид квалифицированного Current.f (...), мы не меняем суть дела, поскольку Current, присвоить которому ничего нельзя, не является полиморфным объектом.)
Далее нам потребуется понятие Кэтколла, основанное на понятии CAT. (CAT - это аббревиатура Changing Availability or Type - изменение доступности или типа). Подпрограмма является CAT подпрограммой, если некоторое ее переопределение потомком приводит к изменениям одного из двух видов, которые, как мы видели, являются потенциально опасными: изменяет тип аргумента (ковариантно) или скрывает ранее экспортировавшийся компонент.
Определение: CAT-подпрограммы
Подпрограмма называется CAT-подпрограммой, если некоторое ее переопределение изменяет статус экспорта или тип любого из ее аргументов.
Это свойство опять-таки допускает возрастающую проверку: любое переопределение типа аргумента или статуса экспорта делают процедуру или функцию CAT-подпрограммой. Отсюда следует понятие Кэтколла: вызова CAT-подпрограммы, который может оказаться ошибочным.
Определение: Кэтколл
Вызов называется Кэтколлом, если некоторое переопределение подпрограммы сделало бы его ошибочным из-за изменения статуса экспорта или типа аргумента.
Созданная нами классификация позволяет выделять специальные группы вызовов: полиморфные и кэтколлы. Полиморфные вызовы придают выразительную мощь объектному подходу, кэтколлы позволяют переопределять типы и ограничивать экспорт. Используя терминологию, введенную ранее в этой лекции, можно сказать, что полиморфные вызовы расширяют полезность (usefulness), кэтколлы - используемость(usability).
Вызовы share и add_vertex, рассмотренные в наших примерах, являются кэт-коллами. Первый осуществляет ковариантное переопределение своего аргумента. Второй экспортируется классом RECTANGLE, но скрыт классом POLYGON. Оба вызова также и полиморфны, а потому они служат прекрасным примером полиморфных кэтколлов. Они являются ошибочными согласно правилу типов Кэтколл.
Остерегайтесь полиморфных кэтколлов!
Правило Системной Корректности пессимистично: в целях упрощения оно отвергает и вполне безопасные комбинации инструкций. Как ни парадоксально, но последний вариант решения мы построим на основе еще более пессимистического правила. Естественно, это поднимет вопрос о том, насколько реалистичным будет наш результат.
Параллельные иерархии
Чтобы не оставить камня на камне, рассмотрим вариант примера SKIER с двумя параллельными иерархиями. Это позволит нам смоделировать ситуацию, уже встречавшуюся на практике: TWO_ WAY_LIST > LINKED_LIST и BI_LINKABLE > LINKABLE; или иерархию с телефонной службой PHONE_SERVICE.
Пусть есть иерархия с классом ROOM, потомком которого является GIRL_ROOM (класс BOY опущен):
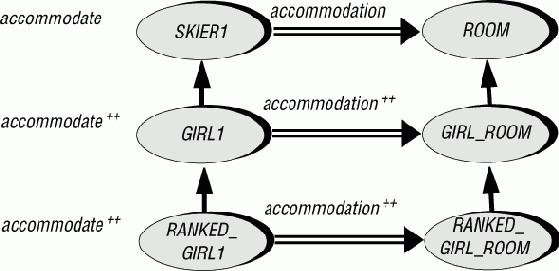
Рис. 17.7. Лыжники и комнаты
Наши классы лыжников в этой параллельной иерархии вместо roommate и share будут иметь аналогичные компоненты accommodation (размещение) и accommodate (разместить):
indexing description: "Новый вариант с параллельными иерархиями" class SKIER1 feature accommodation: ROOM accommodate (r: ROOM) is ... require ... do accommodation:= r end end
Здесь также необходимы ковариантные переопределения: в классе GIRL1 как accommodation, так и аргумент подпрограммы accommodate должны быть заменены типом GIRL_ROOM, в классе BOY1 - типом BOY_ROOM и т.д. (Не забудьте: мы по-прежнему работаем без закрепления типов.) Как и в предыдущем варианте примера, контравариантность здесь бесполезна.
Пессимизм
Статическая типизация приводит по своей природе к "пессимистической" политике. Попытка дать гарантию, что все вычисления не приводят к отказам, отвергает вычисления, которые могли бы закончиться без ошибок.
Рассмотрим обычный, необъектный, Pascal-подобный язык с различными типами REAL и INTEGER. При описании n: INTEGER; r: Real оператор n := r будет отклонен, как нарушающий правила. Так, компилятор отвергнет все нижеследующие операторы:
n := 0.0 [A] n := 1.0 [B] n := -3.67 [C] n := 3.67 - 3.67 [D]
Если мы разрешим их выполнение, то увидим, что [A] будет работать всегда, так как любая система счисления имеет точное представление вещественного числа 0,0, недвусмысленно переводимое в 0 целых. [B] почти наверняка также будет работать. Результат действия [C] не очевиден (хотим ли мы получить итог округлением или отбрасыванием дробной части?). [D] справится со своей задачей, как и оператор:
if n ^ 2 < 0 then n := 3.67 end [E]
куда входит недостижимое присваивание (n ^ 2 - это квадрат числа n). После замены n ^ 2 на n правильный результат даст только ряд запусков. Присваивание n большого вещественного значения, не представимого целым, приведет к отказу.
В типизированных языках все эти примеры (работающие, неработающие, иногда работающие) безжалостно трактуются как нарушения правил описания типов и отклоняются любым компилятором.
Вопрос не в том, будем ли мы пессимистами, а в том, насколько пессимистичными мы можем позволить себе быть. Вернемся к требованию реализма: если правила типов настолько пессимистичны, что препятствуют простоте записи вычислений, мы их отвергнем. Но если достижение безопасности типов достигается небольшой потерей выразительной силы, мы примем их. Например, в среде разработки, предоставляющей функции округления и выделения целой части - round и truncate, оператор n := r считается некорректным справедливо, поскольку заставляет вас явно записать преобразование вещественного числа в целое, вместо использования двусмысленных преобразований по умолчанию.
Полагаясь на закрепление типов
Почти готовое решение проблемы ковариантности мы найдем, присмотревшись к известному нам механизму закрепленных объявлений.
При описании классов SKIER и SKIER1 вас не могло не посетить желание, воспользовавшись закрепленными объявлениями, избавиться от многих переопределений. Закрепление - это типичный ковариантный механизм. Вот как будет выглядеть наш пример (все изменения подчеркнуты):
class SKIER feature roommate: like Current share (other: like Current) is ... require ... do roommate := other end ... end class SKIER1 feature accommodation: ROOM accommodate (r: like accommodation) is ... require ... do accommodation := r end end
Теперь потомки могут оставить класс SKIER без изменений, а в SKIER1 им понадобится переопределить только атрибут accommodation. Закрепленные сущности: атрибут roommate и аргументы подпрограмм share и accommodate - будут изменяться автоматически. Это значительно упрощает работу и подтверждает тот факт, что при отсутствии закрепления (или другого подобного механизма, например, типовых переменных) написать ОО-программный продукт с реалистичной типизацией невозможно.
Но удалось ли устранить нарушения корректности системы? Нет! Мы, как и раньше, можем перехитрить проверку типов, выполнив полиморфные присваивания, вызывающие нарушения системной корректности.
Правда, исходные варианты примеров будут отклонены. Пусть:
s: SKIER; b: BOY; g: GIRL ... create b;create g;-- Создание объектов BOY и GIRL. s := b; -- Полиморфное присваивание. sl share (g)
Аргумент g, передаваемый share, теперь неверен, так как здесь требуется объект типа like s, а класс GIRL не совместим с этим типом, поскольку по правилу закрепленных типов ни один тип не совместим с like s, кроме него самого.
Впрочем, радоваться нам не долго. В другую сторону это правило говорит о том, что like s совместим с типом s. А значит, используя полиморфизм не только объекта s, но и параметра g, мы можем снова обойти систему проверки типов:
s: SKIER; b: BOY; g: like s; actual_g: GIRL; ...
create b; create actual_g -- Создание объектов BOY и GIRL. s := actual_g; g := s -- Через s присоединить g к GIRL. s := b -- Полиморфное присваивание. s.share (g)
В результате незаконный вызов проходит.
Выход из положения есть. Если мы всерьез готовы использовать закрепление объявлений как единственный механизм ковариантности, то избавиться от нарушений системной корректности можно, полностью запретив полиморфизм закрепленных сущностей. Это потребует изменения в языке: введем новое ключевое слово anchor (эта гипотетическая конструкция нужна нам исключительно для того, чтобы использовать ее в данном обсуждении):
anchor s: SKIER
Разрешим объявления вида like s лишь тогда, когда s описано как anchor. Изменим правила совместимости так, чтобы гарантировать: s и элементы типа like s могут присоединяться (в присваиваниях или передаче аргумента) только друг к другу.
| В исходном варианте правила существовало понятие опорно-эквивалентных элементов. При новом подходе опорно-эквивалентными должны быть как правая, так и левая часть любого присваивания, в котором участвует опорная или закрепленная сущность. |
r (u: Y) ...
тогда как у класса C - родителя D это выглядело
r (u: X) ...
где Y соответствовало X, то теперь переопределение компонента r будет выглядеть так:
r (u: like your_anchor) ...
Остается только в классе D переопределить тип your_anchor.
Это решение проблемы ковариантности - полиморфизма будем называть подходом Закрепления (Anchoring). Более аккуратно следовало бы говорить: "Ковариация только через Закрепление".
Свойства подхода привлекательны:
Закрепление основано на идее строгого разделения ковариантных и потенциально полиморфных (или, для краткости, полиморфных) элементов. Все сущности, объявленные как anchor или like some_anchor ковариантны; прочие-полиморфны. В каждой из двух категорий допустимы любые присоединения, но нет сущности или выражения, нарушающих границу. Нельзя, например, присвоить полиморфный источник ковариантной цели.Это простое и элегантное решение нетрудно объяснить даже начинающим.Оно полностью устраняет возможность нарушения системной корректности в ковариантно построенных системах.Оно сохраняет заложенную выше концептуальную основу, в том числе понятия ограниченной и неограниченной универсальности. (В итоге это решение, по-моему, предпочтительнее типовых переменных, подменяющих собой механизмы ковариантности и универсальности, предназначенных для решения разных практических задач.)Оно требует незначительного изменения языка, - добавляя одно ключевое слово, отраженное в правиле соответствия, - и не связано с ощутимыми трудностями в реализации.Оно реалистично (по крайней мере, теоретически): любую ранее возможную систему можно переписать, заменив ковариантные переопределения закрепленными повторными объявлениями. Правда, некоторые присоединения в результате станут неверными, но они соответствуют случаям, которые могут привести к нарушениям типов, а потому их следует заменить попытками присваивания и разобраться в ситуации во время выполнения.
Казалось бы, дискуссию можно на этом закончить. Так почему же подход Закрепления не полностью нас устраивает? Прежде всего, мы еще не касались проблемы скрытия потомком. Кроме этого, основной причиной продолжения дискуссии является проблема, уже высказанная при кратком упоминании типовых переменных. Раздел сфер влияния на полиморфную и ковариантную часть, чем-то похож на результат Ялтинской конференции. Он предполагает, что разработчик класса обладает незаурядной интуицией, что он в состоянии для каждой введенной им сущности, в частности для каждого аргумента раз и навсегда выбрать одну из двух возможностей:
Сущность является потенциально полиморфной: сейчас или позднее она (посредством передачи параметров или путем присваивания) может быть присоединена к объекту, чей тип отличается от объявленного. Исходный тип сущности не сможет изменить ни один потомок класса.Сущность является субъектом переопределения типов, то есть она либо закреплена, либо сама является опорным элементом.
Но как разработчик может все это предвидеть? Вся привлекательность ОО-метода во многом выраженная в принципе Открыт-Закрыт как раз и связана с возможностью изменений, которые мы вправе внести в ранее сделанную работу, а также с тем, что разработчик универсальных решений не должен обладать бесконечной мудростью, понимая, как его продукт смогут адаптировать к своим нуждам потомки.
При таком подходе переопределение типов и скрытие потомком - своего рода "предохранительный клапан", дающий возможность повторно использовать существующий класс, почти пригодный для достижения наших целей:
Прибегнув к переопределению типов, мы можем менять объявления в порожденном классе, не затрагивая оригинал. При этом чисто ковариантное решение потребует правки оригинала путем описанных преобразований.Скрытие потомком защита от многих неудач при создании класса. Можно критиковать проект, в котором RECTANGLE, используя тот факт, что он является потомком POLYGON, пытается добавить вершину. Взамен можно было бы предложить структуру наследования, в которой фигуры с фиксированным числом вершин отделены от всех прочих, и проблемы не возникало бы. Однако при разработке структур наследования предпочтительнее всегда те, в которых нет таксономических исключений. Но можно ли их полностью устранить? Обсуждая ограничение экспорта в одной из следующих лекций, мы увидим, что подобное невозможно по двум причинам. Во-первых, это наличие конкурирующих критериев классификации. Во-вторых, вероятность того, что разработчик не найдет идеального решения, даже если оно существует.
Желая сохранить гибкость адаптации порожденных классов для наших нужд, мы должны разрешить и ковариантное переопределение типов, и скрытие потомком.Далее мы узнаем, как этого добиться.
Полное соответствие
Завершая обсуждение ковариантности, полезно понять, как общий метод можно применить к решению достаточно общей проблемы. Метод появился как результат Кэтколл-теории, но может использоваться в рамках базисного варианта языка без введения новых правил.
Пусть существуют два согласованных списка, где первый задает лыжников, а второй - соседа по комнате для лыжника из первого списка. Мы хотим выполнять соответствующую процедуру размещения share, только если она разрешена правилами описания типов, которые разрешают поселять девушек с девушками, девушек-призеров с девушками-призерами и так далее. Проблемы такого вида встречаются часто.
Возможно простое решение, основанное на предыдущем обсуждении и попытке присваивания. Рассмотрим универсальную функцию fitted (согласовать):
fitted (other: GENERAL): like other is -- Текущий объект (Current), если его тип соответствует типу объекта, -- присоединенного к other, иначе void. do if other /= Void and then conforms_to (other) then Result ?= Current end end
Функция fitted возвращает текущий объект, но известный как сущность типа, присоединенного к аргументу. Если тип текущего объекта не соответствует типу объекта, присоединенного к аргументу, то возвращается Void. Обратите внимание на роль попытки присваивания. Функция использует компонент conforms_to из класса GENERAL, выясняющий совместимость типов пары объектов.
Замена conforms_to на другой компонент GENERAL с именем same_type дает нам функцию perfect_fitted (полное соответствие), которая возвращает Void, если типы обоих объектов не идентичны.
Функция fitted - дает нам простое решение проблемы соответствия лыжников без нарушения правил описания типов. Так, в код класса SKIER мы можем ввести новую процедуру и использовать ее вместо share, (последнюю можно сделать скрытой процедурой).
safe_share (other: SKIER) is -- Выбрать, если допустимо, other как соседа по номеру. -- gender_ascertained - установленный пол local gender_ascertained_other: like Current do gender_ascertained_other := other .fitted (Current) if gender_ascertained_other /= Void then share (gender_ascertained_other) else "Вывод: совместное размещение с other невозможно" end end
Для other произвольного типа SKIER (а не только like Current) определим версию gender_ascertained_other, имеющую тип, закрепленный за Current. Гарантировать идентичность типов нам поможет функция perfect_ fitted.
При наличии двух параллельных списков лыжников, представляющих планируемое размещение:
occupant1, occupant2: LIST [SKIER]
можно организовать цикл, выполняя на каждом шаге вызов:
occupant1.item.safe_share (occupant2.item)
сопоставляющий элементы списков, если и только если их типы полностью совместимы.
Практический аспект
Простота проблемы создает своеобразный парадокс: пытливый новичок построит контрпример за считанные минуты, в реальной практике изо дня в день возникают ошибки классовой корректности систем, но нарушения системной корректности даже в больших, многолетних проектах возникают исключительно редко.
Однако это не позволяет игнорировать их, а потому мы приступаем к изучению трех возможных путей решения данной проблемы.
Далее мы будем затрагивать весьма тонкие и не столь часто дающие о себе знать аспекты объектного подхода. Читая книгу впервые, вы можете пропустить оставшиеся разделы этой лекции. Если вы лишь недавно занялись вопросами ОО-технологии, то лучше усвоите этот материал после изучения лекций 1-11 курса "Основы объектно-ориентированного проектирования", посвященной методологии наследования, и в особенности лекции 6 курса "Основы объектно-ориентированного проектирования", посвященной методологии наследования.
Правила типизации
Наша ОО-нотация является статически типизированной. Ее правила типов были введены в предыдущих лекциях и сводятся к трем простым требованиям.
При объявлении каждой сущности или функции должен задаваться ее тип, например, acc: ACCOUNT. Каждая подпрограмма имеет 0 или более формальных аргументов, тип которых должен быть задан, например: put (x: G; i: INTEGER).В любом присваивании x := y и при любом вызове подпрограммы, в котором y - это фактический аргумент для формального аргумента x, тип источника y должен быть совместим с типом цели x. Определение совместимости основано на наследовании: B совместим с A, если является его потомком, - дополненное правилами для родовых параметров (лекцию 14).Вызов x.f (arg) требует, чтобы f был компонентом базового класса для типа цели x, и f должен быть экспортирован классу, в котором появляется вызов (см. 14.3).
Преимущества
Причины применения статической типизации в объектной технологии мы перечислили в начале лекции. Это надежность, простота понимания и эффективность.
Надежность обусловлена обнаружением ошибок, которые иначе могли проявить себя лишь во время работы, и только в некоторых случаях. Первое из правил, заставляющее объявлять сущности, как, впрочем, и функции, вносит в программный текст избыточность, что позволяет компилятору, используя два других правила, обнаруживать несоответствия между задуманным и реальным применением сущностей, компонентов и выражений.
Раннее выявление ошибок важно еще и потому, что чем дольше мы будем откладывать их поиск, тем сильнее вырастут издержки на исправление. Это свойство, интуитивно понятное всем программистам-профессионалам, количественно подтверждают широко известные работы Бема (Boehm). Зависимость издержек на исправление от времени отыскания ошибок приведена на графике, построенном по данным ряда больших промышленных проектов и проведенных экспериментов с небольшим управляемым проектом:
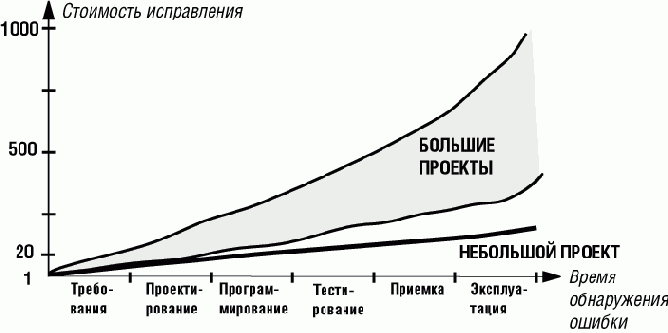
Рис. 17.1. Сравнительные издержки на исправление ошибок ([Boehm 1981], публикуется с разрешения)
Читабельность или Простота понимания (readability) имеет свои преимущества. Во всех примерах этой книги появление типа у сущности дает читателю информацию о ее назначении. Читабельность крайне важна на этапе сопровождения.
| Исключив читабельность из круга приоритетов, можно было бы получить другие преимущества, не вводя явных объявлений. В самом деле, возможна неявная форма типизации, когда компилятор, не требуя явного указания типа, пытается автоматически определить его из контекста применения сущности. Эта стратегия известна как выведение типов (type inference). Но в программной инженерии явные объявления типов это помощь, а не наказание, - тип должен быть ясен не только машине, но и читающему текст человеку. |
Наконец, эффективность может определять успех или отказ от объектной технологии на практике. В отсутствие статической типизации на выполнение x.f (arg) может уйти сколько угодно времени.
Причина этого в том, что на этапе выполнения, не найдя f в базовом классе цели x, поиск будет продолжен у ее потомков, а это верная дорога к неэффективности. Снять остроту проблемы можно, улучшив поиск компонента по иерархии. Авторы языка Self провели большую работу, стремясь генерировать лучший код для языка с динамической типизацией. Но именно статическая типизация позволила такому ОО-продукту приблизиться или сравняться по эффективности с традиционным ПО.
Ключом к статической типизации является уже высказанная идея о том, что компилятор, генерирующий код для конструкции x.f (arg), знает тип x. Из-за полиморфизма нет возможности однозначно определить подходящую версию компонента f. Но объявление сужает множество возможных типов, позволяя компилятору построить таблицу, обеспечивающую доступ к правильному f с минимальными издержками, - с ограниченной константой сложностью доступа. Дополнительно выполняемые оптимизации статического связывания (static binding) и подстановки (inlining) - также облегчаются благодаря статической типизации, полностью устраняя издержки в тех случаях, когда они применимы.
Проблема типизации
О типизации при ОО-разработке можно сказать одно: эта задача проста в своей постановке, но решить ее подчас нелегко.
Реализм
Хотя определение статически типизированного языка дано совершенно точно, его недостаточно, - необходимы неформальные критерии при создании правил типизации. Рассмотрим два крайних случая.
Совершенно корректный язык, в котором каждая синтаксически правильная система корректна и в отношении типов. Правила описания типов не нужны. Такие языки существуют (представьте себе польскую запись выражения со сложением и вычитанием целых чисел). К сожалению, ни один реальный универсальный язык не отвечает этому критерию.Совершенно некорректный язык, который легко создать, взяв любой существующий язык и добавив правило типизации, делающее любую систему некорректной. По определению, этот язык типизирован: так как нет систем, соответствующих правилам, то ни одна система не вызовет нарушения типов.
Можно сказать, что языки первого типа пригодны, но бесполезны, вторые, возможно, полезны, но не пригодны.
На практике необходима система типов, пригодная и полезная одновременно: достаточно мощная для реализации потребностей вычислений и достаточно удобная, не заставляющая нас идти на усложнения для удовлетворения правил типизации.
Будем говорить, что язык реалистичен, если он пригоден к применению и полезен на практике. В отличие от определения статической типизации, дающего безапелляционный ответ на вопрос: "Типизирован ли язык X статически?", определение реализма отчасти субъективно.
В этой лекции мы убедимся, что предлагаемая нами нотация реалистична.
Скрытие потомком
Прежде чем искать решение проблемы ковариантности, рассмотрим еще один механизм, способный в условиях полиморфизма привести к нарушениям типа. Скрытие потомком (descendant hiding) - это способность класса не экспортировать компонент, полученный от родителей.

Рис. 17.8. Скрытие потомком
Типичным примером является компонент add_vertex (добавить вершину), экспортируемый классом POLYGON, но скрываемый его потомком RECTANGLE (ввиду возможного нарушения инварианта - класс хочет оставаться прямоугольником):
class RECTANGLE inherit POLYGON export {NONE} add_vertex end feature ... invariant vertex_count = 4 end
Не программистский пример: класс "Страус" скрывает метод "Летать", полученный от родителя "Птица".
Давайте на минуту примем эту схему такой, как она есть, и поставим вопрос, будет ли легитимным сочетание наследования и скрытия. Моделирующая роль скрытия, подобно ковариантности, нарушается из-за трюков, возможных из-за полиморфизма. И здесь не трудно построить вредоносный пример, позволяющий, несмотря на скрытие компонента, вызвать его и добавить прямоугольнику вершину:
p: POLYGON; r: RECTANGLE ... create r; -- Создание объекта RECTANGLE. p := r; -- Полиморфное присваивание. p.add_vertex (...)
Так как объект r скрывается под сущностью p класса POLYGON, а add_vertex экспортируемый компонент POLYGON, то его вызов сущностью p корректен. В результате выполнения в прямоугольнике появится еще одна вершина, а значит, будет создан недопустимый объект.
Статическая и динамическая типизация
Хотя возможны и промежуточные варианты, здесь представлены два главных подхода:
Динамическая типизация: ждать момента выполнения каждого вызова и тогда принимать решение.Статическая типизация: с учетом набора правил определить по исходному тексту, возможны ли нарушения типов при выполнении. Система выполняется, если правила гарантируют отсутствие ошибок.
Эти термины легко объяснимы: при динамической типизации проверка типов происходит во время работы системы (динамически), а при статической типизации проверка выполняется над текстом статически (до выполнения).
| Термины типизированный и нетипизированный (typed/untyped) нередко используют вместо статически типизированный и динамически типизированный (statically/dynamically typed). Во избежание любых недоразумений мы будем придерживаться полных именований. |
Статическая типизация предполагает автоматическую проверку, возлагаемую, как правило, на компилятор. В итоге имеем простое определение:
Определение: статически типизированный язык
ОО-язык статически типизирован, если он поставляется с набором согласованных правил, проверяемых компилятором, соблюдение которых гарантирует, что выполнение системы не приведет к нарушению типов.
В литературе встречается термин "сильная типизация" (strong). Он соответствует ультимативной природе определения, требующей полного отсутствия нарушения типов. Возможны и слабые (weak) формы статической типизации, при которых правила устраняют определенные нарушения, не ликвидируя их целиком. В этом смысле некоторые ОО-языки являются статически слабо типизированными. Мы будем бороться за наиболее сильную типизацию.
В динамически типизированных языках, известных как нетипизированные, отсутствуют объявления типов, а к сущностям в период выполнения могут присоединяться любые значения. Статическая проверка типов в них невозможна.
Статическая типизация: как и почему
Хотя преимущества статической типизации очевидны, неплохо поговорить о них еще раз.
Своенравие полиморфизма
Не довольно ли примеров, подтверждающих практичность ковариации? Почему же кто-то рассматривает контравариантность, которая вступает в противоречие с тем, что необходимо на практике (если не принимать во внимание поведения некоторых молодых людей)? Чтобы понять это, рассмотрим проблемы, возникающие при сочетании полиморфизма и стратегии ковариантности. Придумать вредительскую схему несложно, и, возможно, вы уже создали ее сами:
s: SKIER; b: BOY; g: GIRL ... create b; create g;-- Создание объектов BOY и GIRL. s := b; -- Полиморфное присваивание. s.share (g)
Результат последнего вызова, вполне возможно приятный для юношей, - это именно то, что мы пытались не допустить с помощью переопределения типов. Вызов share ведет к тому, что объект BOY, известный как b и благодаря полиморфизму получивший псевдоним s типа SKIER, становится соседом объекта GIRL, известного под именем g. Однако вызов, хотя и противоречит правилам общежития, является вполне корректным в программном тексте, поскольку share -экспортируемый компонент в составе SKIER, а GIRL, тип аргумента g, совместим со SKIER, типом формального параметра share.
Схема с параллельной иерархией столь же проста: заменим SKIER на SKIER1, вызов share - на вызов s.accommodate (gr), где gr - сущность типа GIRL_ROOM. Результат - тот же.
При контравариантном решении этих проблем не возникало бы: специализация цели вызова (в нашем примере s) требовала бы обобщения аргумента. Контравариантность в результате ведет к более простой математической модели механизма: наследование - переопределение - полиморфизм. Данный факт описан в ряде теоретических статей, предлагающих эту стратегию. Аргументация не слишком убедительна, поскольку, как показывают наши примеры и другие публикации, контравариантность не имеет практического использования.
| В литературе для программистов нередко встречается призыв к методам, основанных на простых математических моделях. Однако математическая красота - всего лишь один из критериев ценности результата, - есть и другие - полезность и реалистичность. |
Поэтому, не пытаясь натянуть контравариантную одежду на ковариантное тело, следует принять ковариантную действительность и искать пути устранения нежелательного эффекта.
Типизация и связывание
Хотя как читатель этой книги вы наверняка отличите статическую типизацию от статического связывания, есть люди, которым подобное не под силу. Отчасти это может быть связано с влиянием языка Smalltalk, отстаивающего динамический подход к обеим задачам и способного сформировать неверное представление, будто они имеют одинаковое решение. (Мы же в своей книге утверждаем, что для создания надежных и гибких программ желательно объединить статическую типизацию и динамическое связывание.)
Как типизация, так и связывание имеют дело с семантикой Базисной Конструкции x.f (arg), но отвечают на два разных вопроса:
Типизация и связывание
Вопрос о типизации: когда мы должны точно знать, что во время выполнения появится операция, соответствующая f, применимая к объекту, присоединенному к сущности x (с параметром arg)?Вопрос о связывании: когда мы должны знать, какую операцию инициирует данный вызов?
Типизация отвечает на вопрос о наличии как минимум одной операции, связывание отвечает за выбор нужной.
В рамках объектного подхода:
проблема, возникающая при типизации, связана с полиморфизмом: поскольку x во время выполнения может обозначать объекты нескольких различных типов, мы должны быть уверены, что операция, представляющая f, доступна в каждом из этих случаев;проблема связывания вызвана повторными объявлениями: так как класс может менять наследуемые компоненты, то могут найтись две или более операции, претендующие на то, чтобы представлять f в данном вызове.
Обе задачи могут быть решены как динамически, так и статически. В существующих языках представлены все четыре варианта решения.
Ряд необъектных языков, скажем, Pascal и Ada, реализуют как статическую типизацию, так и статическое связывание. Каждая сущность представляет объекты только одного типа, заданного статически. Тем самым обеспечивается надежность решения, платой за которую является его гибкость.Smalltalk и другие ОО-языки содержат средства динамического связывания и динамической типизации. При этом предпочтение отдается гибкости в ущерб надежности языка.Отдельные необъектные языки поддерживают динамическую типизацию и статическое связывание.
Среди них - языки ассемблера и ряд языков сценариев (scripting languages).Идеи статической типизации и динамического связывания воплощены в нотации, предложенной в этой книге.
Отметим своеобразие языка C++, поддерживающего статическую типизацию, хотя и не строгую ввиду наличия приведения типов, статическое связывание (по умолчанию), динамическое связывание при явном указании виртуальных (virtual) объявлений.
Причина выбора статической типизации и динамического связывания очевидна. Первый вопрос: "Когда мы будем знать о существовании компонентов?" - предполагает статический ответ: "Чем раньше, тем лучше", что означает: во время компиляции. Второй вопрос: "Какой из компонентов использовать?" предполагает динамический ответ: "тот, который нужен", - соответствующий динамическому типу объекта, определяемому во время выполнения. Это единственно приемлемое решение, если статическое и динамическое связывание дает различные результаты.
Следующий пример иерархии наследования поможет прояснить эти понятия:
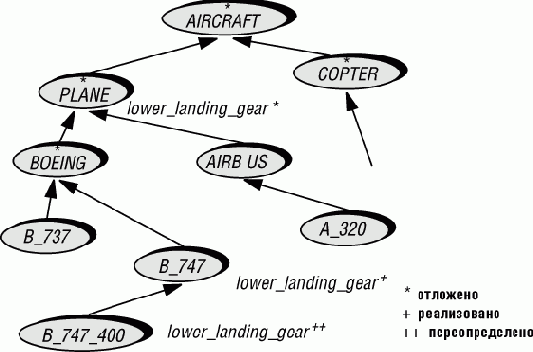
Рис. 17.3. Виды летательных аппаратов
Рассмотрим вызов:
my_aircraft.lower_landing_gear
Вопрос о типизации: когда убедиться, что здесь будет компонент lower_landing_gear ("выпустить шасси"), применимый к объекту (для COPTER его не будет вовсе) Вопрос о связывании: какую из нескольких возможных версий выбрать.
Статическое связывание означало бы, что мы игнорируем тип присоединяемого объекта и полагаемся на объявление сущности. В итоге, имея дело с Boeing 747-400, мы вызвали бы версию, разработанную для обычных лайнеров серии 747, а не для их модификации 747-400. Динамическое связывание применяет операцию, требуемую объектом, и это правильный подход.
При статической типизации компилятор не отклонит вызов, если можно гарантировать, что при выполнении программы к сущности my_aircraft будет присоединен объект, поставляемый с компонентом, соответствующим lower_landing_gear. Базисная техника получения гарантий проста: при обязательном объявлении my_aircraft требуется, чтобы базовый класс его типа включал такой компонент.Поэтому my_aircraft не может быть объявлен как AIRCRAFT, так как последний не имеет lower_landing_gear на этом уровне; вертолеты, по крайней мере в нашем примере, выпускать шасси не умеют. Если же мы объявим сущность как PLANE, - класс, содержащий требуемый компонент, - все будет в порядке.
Динамическая типизация в стиле Smalltalk требует дождаться вызова, и в момент его выполнения проверить наличие нужного компонента. Такое поведение возможно для прототипов и экспериментальных разработок, но недопустимо для промышленных систем - в момент полета поздно спрашивать, есть ли у вас шасси.
Типизация: слагаемые успеха
Каковы механизмы реалистичной статической типизации? Все они введены в предыдущих лекциях, а потому нам остается лишь кратко о них напомнить. Их совместное перечисление показывает согласованность и мощь их объединения.
Наша система типов полностью основана на понятии класса. Классами являются даже такие базовые типы, как INTEGER, а стало быть, нам не нужны особые правила описания предопределенных типов. (В этом наша нотация отличается от "гибридных" языков наподобие Object Pascal, Java и C++, где система типов старых языков сочетается с объектной технологией, основанной на классах.)
Развернутые типы дают нам больше гибкости, допуская типы, чьи значения обозначают объекты, наряду с типами, чьи значения обозначают ссылки.
Решающее слово в создании гибкой системы типов принадлежит наследованию и связанному с ним понятию совместимости. Тем самым преодолевается главное ограничение классических типизированных языков, к примеру, Pascal и Ada, в которых оператор x := y требует, чтобы тип x и y был одинаковым. Это правило слишком строго: оно запрещает использовать сущности, которые могут обозначать объекты взаимосвязанных типов (SAVINGS_ACCOUNT и CHECKING_ACCOUNT). При наследовании мы требуем лишь совместимости типа y с типом x, например, x имеет тип ACCOUNT, y - SAVINGS_ACCOUNT, и второй класс - наследник первого.
На практике статически типизированный язык нуждается в поддержке множественного наследования. Известны принципиальные обвинения статической типизации в том, что она не дает возможность по-разному интерпретировать объекты. Так, объект DOCUMENT (документ) может передаваться по сети, а потому нуждается в наличия компонентов, связанных с типом MESSAGE (сообщение). Но эта критика верна только для языков, ограниченных единичным наследованием.

Рис. 17.2. Множественное наследование
Универсальность необходима, например, для описания гибких, но безопасных контейнерных структур данных (например class LIST [G] ...). Не будь этого механизма, статическая типизация потребовала бы объявления разных классов для списков, отличающихся типом элементов.
В ряде случаев универсальность требуется ограничить, что позволяет использовать операции, применимые лишь к сущностям родового типа. Если родовой класс SORTABLE_LIST поддерживает сортировку, он требует от сущностей типа G, где G - родовой параметр, наличия операции сравнения. Это достигается связыванием с G класса, задающего родовое ограничение, - COMPARABLE:
class SORTABLE_LIST [G -> COMPARABLE] ...
Любой фактический родовой параметр SORTABLE_LIST должен быть потомком класса COMPARABLE, имеющего необходимый компонент.
Еще один обязательный механизм - попытка присваивания - организует доступ к тем объектам, типом которых ПО не управляет. Если y - это объект базы данных или объект, полученный через сеть, то оператор x ?= y присвоит x значение y, если y имеет совместимый тип, или, если это не так, даст x значение Void.
Утверждения, связанные, как часть идеи Проектирования по Контракту, с классами и их компонентами в форме предусловий, постусловий и инвариантов класса, дают возможность описывать семантические ограничения, которые не охватываются спецификацией типа. В таких языках, как Pascal и Ada, есть типы-диапазоны, способные ограничить значения сущности, к примеру, интервалом от 10 до 20, однако, применяя их, вам не удастся добиться того, чтобы значение i являлось отрицательным, всегда вдвое превышая j. На помощь приходят инварианты классов, призванные точно отражать вводимые ограничения, какими бы сложными они не были.
Закрепленные объявления нужны для того, чтобы на практике избегать лавинного дублирования кода. Объявляя y: like x, вы получаете гарантию того, что y будет меняться вслед за любыми повторными объявлениями типа x у потомка. В отсутствие этого механизма разработчики беспрестанно занимались бы повторными объявлениями, стремясь сохранить соответствие различных типов.
Закрепленные объявления - это особый случай последнего требуемого нам языкового механизма - ковариантности, подробное обсуждение которого нам предстоит позже.
При разработке программных систем на деле необходимо еще одно свойство, присущее самой среде разработки - быстрая, возрастающая (fast incremental) перекомпиляция.Когда вы пишите или модифицируете систему, хотелось бы как можно скорее увидеть эффект изменений. При статической типизации вы должны дать компилятору время на перепроверку типов. Традиционные подпрограммы компиляции требуют повторной трансляции всей системы (и ее сборки), и этот процесс может быть мучительно долгим, особенно с переходом к системам большого масштаба. Это явление стало аргументом в пользу интерпретирующих систем, таких как ранние среды Lisp или Smalltalk, запускавшие систему практически без обработки, не выполняя проверку типов. Сейчас этот аргумент позабыт. Хороший современный компилятор определяет, как изменился код с момента последней компиляции, и обрабатывает лишь найденные изменения.
"Типизирована ли кроха"?
Наша цель - строгая статическая типизация. Именно поэтому мы и должны избегать любых лазеек в нашей "игре по правилам", по крайней мере, точно их идентифицировать, если они существуют.
Самой распространенной лазейкой в статически типизированных языках является наличие преобразований, меняющих тип сущности. В C и производных от него языках их называют "приведением типа" или кастингом (cast). Запись (OTHER_TYPE) x указывает на то, что значение x воспринимается компилятором, как имеющее тип OTHER_TYPE, при соблюдении некоторых ограничениях на возможные типы.
Подобные механизмы обходят ограничения проверки типов. Приведение широко распространено при программировании на языке C, включая диалект ANSI C. Даже в языке C++ приведение типов, хотя и не столь частое, остается привычным и, возможно, необходимым делом.
Придерживаться правил статической типизации не так просто, если в любой момент их можно обойти путем приведения.
Далее будем полагать, что система типов является строгой и не допускает приведения типа.
| Возможно, вы заметили, что попытка присваивания - неотъемлемый компонент реалистичной системы типов - напоминает приведение. Однако есть существенное отличие: попытка присваивания выполняет проверку, действительно ли текущий тип соответствует заданному типу, - это безопасно, а иногда и необходимо. |
Типовые переменные
Ряд авторов, среди которых Ким Брюс (Kim Bruce), Дэвид Шенг (David Shang) и Тони Саймонс (Tony Simons), предложили решение на основе типовых переменных (type variables), значениями которых являются типы. Их идея проста:
взамен ковариантных переопределений разрешить объявление типов, использующее типовые переменные;расширить правила совместимости типов для управления такими переменными;считать язык (в остальном) безвариантным;обеспечить возможность присваивания типовым переменным в качестве значений типы языка.
Подробное изложение этих идей читатели могут найти в ряде статей по данной тематике, а также в публикациях Карделли (Cardelli), Кастаньи (Castagna), Вебера (Weber) и др. Начать изучение вопроса можно с источников, указанных в библиографических заметках к этой лекции. Мы же не будем заниматься этой проблемой, и вот почему.
Надлежаще реализованный механизм типовых переменных относится к категории, позволяющей использовать тип без полной его спецификации. Эта же категория включает универсальность и закрепление объявлений. Этот механизм мог бы заменить другие механизмы этой категории. Вначале это можно истолковать в пользу типовых переменных, но результат может оказаться плачевным, так как не ясно, сможет ли этот всеобъемлющий механизм справиться со всеми задачами с той легкостью и простотой, которая присуща универсальности и закреплению типов.Предположим, что разработан механизм типовых переменных, способный преодолеть проблемы объединения ковариантности и полиморфизма (все еще игнорируя проблему скрытия потомком). Тогда от разработчика классов потребуется незаурядная интуиция для того, чтобы заранее решить, какие из компонентов будут доступны для переопределения типов в порожденных классах, а какие - нет. Ниже мы обсудим эту проблему, имеющую место в практике создания программ и, увы, ставящую под сомнение применимость многих теоретических схем.
Это заставляет нас вернуться к уже рассмотренным механизмам: ограниченной и неограниченной универсальности, закреплению типов и, конечно, наследованию.
Атрибуты-константы
Как и все сущности, символические константы должны быть определены внутри класса. Будем рассматривать константы как атрибуты с фиксированным значением, одинаковым для всех экземпляров класса.
Синтаксически вновь используем служебное слово is, применяемое при описании методов, только здесь за ним будет следовать не алгоритм, а значение нужного типа. Вот примеры определения констант базовых типов INTEGER, BOOLEAN, REAL и CHARACTER:
Zero: INTEGER is 0 Ok: BOOLEAN is True Pi: REAL is 3.1415926524 Backslash: CHARACTER is '\'
Как видно из этих примеров, имена атрибутов-констант рекомендуется начинать с заглавной буквы, за которой следуют только строчные символы.
Потомки не могут переопределять значения атрибутов-констант.
Как и другие атрибуты, класс может экспортировать константы или скрывать. Так, если C - класс, экспортирующий выше объявленные константы, а у клиента класса к сущности x присоединен объект типа C, то выражение x.Backslash обозначает символ '\'.
В отличие от атрибутов-переменных, константы не занимают в памяти места. Их введение не связано с издержками в период выполнения, а потому не страшно, если их в классе достаточно много.
Библиографические замечания
Проблемы перечислимых типов были изучены в работах [Welsh 1977] и [Moffat 1981]. Некоторые приемы, рассмотренные в этой лекции, впервые представлены в [M 1988b].
Инициализация: подходы языков программирования
Проблема, решаемая в этой лекции, - это общая проблема языков программирования: как работать с глобальными константами и разделяемыми объектами, в частности, как выполнять их инициализацию в библиотеках компонентов?
Для библиотек более общей задачей является включение в каждый компонент возможности определения того, что его вызов является первым запросом к службам библиотеки, что и позволяет определить, была ли сделана инициализация.
Последнюю задачу можно свести к более простой: как разделять переменные булевого типа и согласованно их инициализировать? Свяжем с глобальным объектом p или группой глобальных объектов, нуждающихся в одновременной инициализации, булеву переменную, скажем, ready, истинную, если и только если инициализация проведена. Тогда любому обращению к p нетрудно предпослать инструкцию
if not ready then "Создать или вычислить p" ready := True end
Теперь проблема инициализации касается только ready - еще одного глобального объекта, который необходимо инициализировать значением False.
Как же решается эта задача в языках программирования? С момента их появления в этом плане почти ничего не менялось. В блочно-структурированных языках, среди которых Algol и Pascal, типичным было описание ready как глобальной переменной на верхнем синтаксическом уровне; ее инициализация производилась в главной программе. Но такая техника непригодна для библиотек автономных модулей.
В языке Fortran, позволяющем независимую компиляцию подпрограмм (что придает им известную автономность), можно поместить все глобальные объекты в общий блок (common block), идентифицируемый по имени. Всякая подпрограмма, обращающаяся к общему блоку, должна содержать такую директиву:
COMMON /common_block_name/ data_item_names
При этом возникают две проблемы:
Две совокупности подпрограмм могут использовать одноименные общие блоки, что приведет к конфликту, если одной из программ понадобится как первый, так и второй блок. Смена имени блока вызовет трудности у других программ.Как инициализировать сущности общего блока, такие как ready? Из-за отсутствия инициализации по умолчанию, ее нужно выполнять в особом модуле, называемом блоком данных (block data unit).
В Fortran 77 допускаются именованные модули, что позволяет разработчикам объединять глобальные данные разных общих блоков. При этом есть немалый риск несогласованности инициализации и объявления глобальных объектов.
Принцип решения этой задачи в языке C по сути не отличается от решения Fortran 77. Признак ready нужно описать как "внешнюю" переменную, общую для нескольких "файлов" (единиц компиляции языка). Объявление переменной с указанием ее значения может содержать только один файл, остальные, используя директиву extern, подобную COMMON в Fortran 77, лишь заявляют о необходимости доступа к переменной. Обычно такие определения объединяют в "заголовочные" (header) .h-файлы, которые соответствуют блоку данных в Fortran. При этом наблюдаются те же проблемы, отчасти решаемые утилитами make, призванными отслеживать возникающие зависимости.
Решение может быть близко к тому, что предлагают модульные языки наподобие Ada или Modula 2, подпрограммы которых можно объединять в модули более высокого уровня. В Ada эти модули называют "пакетами" (package). Если все подпрограммы, использующие группу взаимосвязанных глобальных объектов, собраны в одном пакете, то соответствующие признаки ready можно описать в этом же пакете и здесь же выполнить их инициализацию. Однако этот подход (применимый также в C и Fortran 77) не решает проблему инициализации автономных библиотек. Еще более деликатный вопрос связан с тем, как поступать с глобальными объектами, разделяемых подпрограммами разных независимых модулей. Языки Ada и Modula не дают простого ответа на этот вопрос.
Механизм "однократных" методов, сохраняя независимость классов, допускает контекстно-зависимую инициализацию.
Использование констант
Вот пример, показывающий, как клиент может применять константы, определенные в классе:
class FILE feature error_code: INTEGER; -- Атрибут-переменная Ok: INTEGER is 0 Open_error: INTEGER is 1 ... open (file_name: STRING) is -- Открыть файл с именем file_name -- и связать его с текущим файловым объектом do error_code := Ok ... if "Что-то не так" then error_code := Open_error end end ... Прочие компоненты ... end
Клиент можем вызвать метод open и проверить успешность операции:
f: FILE; ... f.open if f.error_code = f.Open_error then "Принять меры" else ... end
Нередко нужны и наборы констант, не связанных с конкретным объектом. Их, как и раньше, можно объединить в класс, выступающий в роли родителя всех классов, которым необходимы константы. В этом случае можно не создавать экземпляр класса:
class EDITOR_CONSTANTS feature Insert: CHARACTER is 'i' Delete: CHARACTER is 'd'; -- и т.д. ... end class SOME_CLASS_FOR_THE_EDITOR inherit EDITOR_CONSTANTS ...Другие возможные родители ... feature ... ... подпрограммы класса имеют доступ к константам, описанным в EDITOR_CONSTANTS ... end
Класс, подобный EDITOR_CONSTANTS, служит лишь для размещения в нем группы констант, и его роль как "реализации АТД" (а это - наше рабочее определение класса) не столь очевидна, как в предыдущих примерах. Теоретическое обоснование введения таких классов мы обсудим позднее. Представленная схема работоспособна только при множественном наследовании, поскольку классу SOME_CLASS_FOR_THE_EDITOR могут потребоваться и другие родители.
Ключевые концепции
При любом подходе к конструированию ПО возникает проблема работы с глобальными объектами, совместно используемыми компонентами разных модулей, и инициализируемыми в период выполнения, когда какой-либо из компонентов первым к ним обратился.Константы могут быть манифестными и символическими. Первые задаются значениями, синтаксис которых определен так, что значение одновременно описывает и тип константы, а потому является манифестом. Символические константы представлены именами, а их значение указывается в определении константы.Манифестные константы базовых типов можно объявлять как константные атрибуты, не требующие памяти в объектах.За исключением строк, типы, определенные пользователем, не имеют манифестных констант, нарушающих принципы Скрытия информации и расширяемости.Однократная подпрограмма синтаксически отличается от обычной лишь ключевым словом once, заменяющим do. Она полностью выполняется лишь один раз (при первом вызове). При последующих вызовах однократной функции возвращается результат, вычисленный при первом вызове, последующие вызовы процедуры не имеют эффекта и могут быть проигнорированы.Разделяемые объекты могут быть реализованы как однократные функции. Можно использовать инвариант для указания их константности.Однократные процедуры используются там, где операции должны быть выполнены только однажды во время выполнения системы, чаще всего, это связано с инициализацией глобальных параметров системы.Тип однократной функции не может быть закрепленным или родовым типом.Константы строковых типов внутренне интерпретируются как однократные функции, однако, внешне они выглядят как манифестные константы, значения которых заключается в двойные кавычки.Перечислимые типы в стиле языка Pascal не соответствуют объектной методологии. Для представления объектов с несколькими возможными вариантами значений используются символические unique константы. Инициализация значений таких констант выполняется компилятором.
Константы базовых типов
Начнем с формы записи констант.
Правило стиля - принцип символических констант - гласит, что обращение к конкретному значению (числу, символу или строке) почти всегда должно быть косвенным. Должно существовать определение константы, задающее имя, играющее роль символической константы (symbolic constant), и связанное с ним значение - константа, называемаю манифестной (manifest constant). Далее в алгоритме следует использовать символическую константу. Тому есть два объяснения.
Читабельность: читающему текст легче понять смысл US_states_count, чем числа 50;Расширяемость: символическую константу легко обновить, исправив лишь ее определение.
Принцип допускает применение манифестных или, как часто говорят, неименованных констант в качестве "начальных" элементов разнообразных операций, как в случае с циклом from i = 1 until i > n (Но n, конечно, должно быть символической константой).
Итак, нам нужен простой и ясный способ определения символических констант.
Константы пользовательских классов
Символические константы полезны не только при работе с предопределенными типами, такими как INTEGER. Они нужны и тогда, когда их значениями являются объекты классов, созданных разработчиком. В этом случае решение не столь очевидно.
Константы с манифестом для этого непригодны
Первым примером служит класс, описывающий комплексное число:
class COMPLEX creation make_cartesian, make_polar feature x, y: REAL -- Действительная и мнимая часть make_cartesian (a, b: REAL) is -- Установить действительную часть a, мнимую - b. do x := a; y := b end ... Прочие методы (помимо x и y, других атрибутов нет) ... end
Пусть мы хотим определить константу - комплексное число i, действительная часть которого равна 0, а мнимая 1. Первое, что приходит в голову, - это буквальная константа вида
i: COMPLEX is "Выражение, определяющее комплексное число (0, 1)"
Как записать выражение после is? Для пользовательских типов данных никакой формы записи неименованных констант не существует.
Можно представить себе вариант нотации на основе атрибутов класса:
i: COMPLEX is COMPLEX (0, 1)
Но этот подход, хотя и реализован в некоторых ОО-языках, противоречит принципу модульности - основе объектной методологии. Приняв этот подход, мы согласились бы с тем, что клиенты COMPLEX должны описывать константы в терминах реализации класса, а это нарушает принцип Скрытия информации.
Кроме того, как гарантировать соответствие неименованной константы инварианту класса, если таковой имеется?
Последнее замечание позволяет найти правильное решение. Мы уже говорили о том, что в момент рождения объекта ответственность за соблюдение инварианта возлагается на процедуру создания. Создание объекта иным путем (помимо безопасного клонирования clone) ведет к ситуациям ошибки. Поэтому мы должны найти путь, основанный на обычном методе создания объектов класса.
Константы строковых типов
В начале этой лекции были введены символьные константы, значением которых является символ. Например:
Backslash: CHARACTER is '\'
Однако нередко классам требуются строковые константы, использующие, как обычно, для записи константы двойные кавычки:
[S1]
Message: STRING is "Syntax error" -- "Синтаксическая ошибка"
Вспомните, что STRING - не простой тип. Это - библиотечный класс, поэтому значение, связанное с сущностью Message во время работы программы, является объектом, то есть экземпляром STRING. Как вы могли догадаться, такое описание является сокращенной формой объявления однократной функции вида:
[S2]
Message: STRING is -- Строка из 12 символов once create Result.make (12) Result.put ('S', 1) Result.put ('y', 2) ... Result.put ('r', 12) end
Строковые значения являются не константами, а ссылками на разделяемые объекты. Любой класс, имеющий доступ к Message, может изменить значение одного или нескольких символов строки. Строковые константы можно использовать и как выражения при передаче параметров или присваивании:
Message_window.display ("НАЖМИТЕ ЛЕВУЮ КНОПКУ ДЛЯ ВЫХОДА") greeting := "Привет!"
Однократные функции
Пусть константный объект - это функция. Например, i можно (в иллюстративных целях) описать внутри самого класса COMPLEX как
i: COMPLEX is -- Комплексное число, re= 0, а im= 1 do create Result.make_cartesian (0, 1) end
Это почти решает нашу задачу, поскольку функция всегда возвратит ссылку на объект нужного вида. Коль скоро мы полагаемся на обычную процедуру создания объекта, условие инварианта будет соблюдено, - как следствие, получим корректный объект.
Однако результат не соответствует потребностям: каждое обращение клиента к i порождает новый объект, идентичный всем остальным, а это - трата времени и пространства. Поэтому необходим особый вид функции, выполняемой только при первом вызове. Назовем такую функцию однократной (once function). В целом она синтаксически аналогична обычной функции и отличается лишь служебным словом once, начинающего вместо do ее тело:
i: COMPLEX is -- Комплексное число, re= 0, im= 1 once create Result.make_cartesian (0, 1) end
При первом вызове однократной функции она создает объект, который представляет желаемое комплексное число, и возвращает на него ссылку. Каждый последующий вызов приведет к немедленному завершению функции и возврату результата, вычисленного в первый раз. Что касается эффективности, то обращение к i во второй, третий и т.д. раз должно отнимать времени ненамного больше, чем операция доступа к атрибуту.
Результат, найденный при первом вызове однократной функции, может использоваться во всех экземплярах класса, включая экземпляры потомков, где эта функция не переопределена. Переопределение однократных функций как обычных (и обычных как однократных) допускается без всяких ограничений. Так, если COMPLEX1, порожденный от класса COMPLEX, заново определяет i, то обращение к i в экземпляре COMPLEX1 означает вызов переопределенного варианта, а обращение к i в экземпляре самого COMPLEX или его потомка, отличного от COMPLEX1, означает вызов однократной функции, то есть значения, найденного ею при первом вызове.
Однократные функции с результатами базовых типов
Еще одним применением однократных функций является моделирование глобальных значений - "системных параметров", которые обычно нужны сразу нескольким классам, но не меняются в ходе программной сессии. Их начальная установка требует информации от пользователя или операционной среды. Например:
компонентам низкоуровневой системы может понадобиться объем доступной им памяти, выделенный средой при инициализации;система эмуляции терминала может начать работу с отправки среде запроса о числе терминальных портов. Затем эти данные будут использоваться в ряде модулей приложения.
Такие глобальные данные аналогичны совместно используемым объектам, хотя обычно они являются значениями базовых типов. Схема их реализации однократными функциями такова:
Const_value: T is -- Однократно вычисляемый системный параметр local envir_param: T ' -- Любой тип (T и не только) once "Получить envir_param из операционной среды" Result := "Значение, рассчитанное на основе envir_param" end
Такие однократные функции описывают динамически вычисляемые константы.
Предположим, данное объявление находится в классе ENVIR. Класс, которому надо воспользоваться константой Const_value, получит ее значение, указав ENVIR в списке своих родителей. В отличие от классического подхода к расчету константы, здесь не нужна процедура инициализации системы, вычисляющая все глобальные параметры системы, как это делается в классическом подходе. Как отмечалось в начальных лекциях, такая процедура должна была бы иметь доступ к внутренним деталям многих модулей, что нарушало бы ряд критериев и принципов модульности: декомпозиции, скрытия информации и других. Наоборот, классы, подобные ENVIR, могут разрабатываться как согласованные модули, каждый задающий множество логически связанных глобальных значений. Процесс вычисления такого параметра, к примеру, Const_value, инициирует первый из компонентов, который запросит этот параметр при выполнении системы. Хотя Const_value является функцией, использующие
его компоненты могут полагать, что имеют дело с константным атрибутом.
Как уже говорилось, ни один модуль не имеет больше прав на разделяемые данные, чем остальные. Это особенно справедливо для только что рассмотренных случаев. Если расчет значения способен инициировать любой модуль, нет смысла и говорить о том, будто один из них выступает в роли владельца. Такое положение дел и отражает модульная структура системы.
Однократные функции, закрепление и универсальность
В этом разделе мы обсудим конкретную техническую проблему, поэтому при первом чтении книги его можно пропустить.
Однократные функции, тип которых не является встроенным, вносят потенциальную несовместимость с механизмом закрепления типов и универсальностью.
Начнем с универсальности. Пусть в родовом классе EXAMPLE [G] есть однократная функция, чей тип родовой параметр:
f: G is once ... end
Рассмотрим пример ее использования:
character_example: EXAMPLE [CHARACTER] ... print (character_example.f)
Пока все в порядке. Но если попытаться получить константу с другим родовым параметром:
integer_example: EXAMPLE [INTEGER] ... print (integer_example.f + 1)
В последней инструкции мы складываем два числа. Первое значение, результат вызова f, к сожалению, уже найдено, поскольку f - однократная функция, причем символьного, а не числового типа. Сложение окажется недопустимым.
Проблема заключается в попытке разделения значения разными формами родового порождения, ожидающими значения, тип которого определяется родовым параметром. Аналогичная ситуация возникает и с закреплением типов. Представим себе класс B, добавляющий еще один атрибут к компонентам своего родителя A:
class B inherit A feature attribute_of_B: INTEGER end
Пусть A имеет однократную функцию f, возвращающую результат закрепленного типа:
f: like Current is once create Resultl make end
и пусть первый вызов функции f имеет вид:
a2 := a1.f
где a1 и a2 имеют тип. Вычисление f создаст экземпляр A и присоединит его к сущности a2. Все прекрасно. Но предположим, далее следует:
b2 := b1.f
где b1 и b2 имеют тип B. Не будь f однократной функцией, никакой проблемы бы не возникло. Вызов f породил бы экземпляр класса B и вернул его в качестве результата. Но функция является однократной, а ее результат был уже найден при первом вызове. И это - экземпляр A, но не B. Поэтому инструкция вида:
print (b2.attribute_of_B)
попытается обратиться к несуществующему полю объекта A.
Проблема в том, что закрепление вызывает неявное переопределение типов.
Если бы f была переопределена явно, с применением в классе B объявления
f: B is once create Resultl make end
при условии, что исходный вариант f в классе A возвращает результат типа A (а не like Current), все было бы замечательно: экземпляры A обращались бы к версии f для A, экземпляры B - к версии f для B. Однако закрепление типов было введено как раз для того, чтобы избавить нас от таких явных переопределений.
Эти примеры - свидетельства несовместимости семантики однократных функций (с процедурами все прекрасно) с результатами применения закрепленных типов и формальных родовых параметров. Одно из решений проблемы в том, чтобы трактовать такие случаи как явные переопределения, приняв за правило то, что результат однократной функции совместно используется лишь в пределах одной формы родовой порождения, а при закреплении результата - лишь среди экземпляров своего класса. Недостатком такого подхода, впрочем, является, что он не отвечает интуитивной семантике однократных функций, которые, с позиции клиента, должны быть эквивалентны разделяемым атрибутам. Во избежание недоразумений и возможных ошибок можно пойти на более суровые меры, наложив полный запрет на сценарии подобного рода:
Правило для однократной функции
Тип результата однократной функции не может быть закреплен и не может включать любой родовой параметр.
Однократные процедуры
Функция close должна вызываться только один раз. Контроль над количеством ее вызовов рекомендуется возложить на глобальную переменную приложения.
Из руководства к коммерческой библиотеке функций языка C
Механизм однократных функций интересен и при работе с процедурами. Однократные процедуры могут применяться для инициализации общесистемного свойства, когда заранее неизвестно, какому компоненту это свойство понадобится первому.
Примером может стать графическая библиотека, в которой любая функция, вызываемая первой, должна предварительно провести настройку, учитывающую параметры дисплея. Автор библиотеки мог, конечно, потребовать, чтобы каждый клиент начинал работу с библиотекой с вызова функции настройки. Этот нюанс, в сущности, не решает проблему - чтобы справиться с ошибками, любая функция должна обнаруживать, не запущена ли она без настройки. Но если функции такие "умные", то зачем что-то требовать от клиента, когда можно нужную функцию настройки вызывать самостоятельно.
Однократные процедуры решают эту проблему лучше:
check_setup is -- Настроить терминал, если это еще не сделано. once terminal_setup -- Фактические действия по настройке. end
Теперь каждая экранная функция должна начинаться с обращения к check_setup, первый вызов которой приведет к настройке параметров, а остальные не сделают ничего. Заметьте, что check_setup не должна экспортироваться клиентам.
Однократная процедура - это важный прием, упрощающий применение библиотек и других программных пакетов.
и функции могут иметь параметры,
Однократные процедуры и функции могут иметь параметры, необходимые, по определению, лишь при первом вызове.
Применение однократных подпрограмм
Понятие однократных подпрограмм расширяет круг задач, позволяя включить разделяемые объекты, глобальные системные параметры, инициализацию общих свойств.
Разделяемые объекты
Для ссылочных типов, таких как COMPLEX, наш механизм фактически предлагает константные ссылки, а не обязательно константные объекты. Он гарантирует, что тело функции выполняется при первом обращении, возвращая результат, который будет также возвращаться при последующих вызовах, уже не требуя никаких действий.
Если функция возвращает значение ссылочного типа, то в ее теле, как правило, есть инструкция создания объекта, и любой вызов приведет к получению ссылки на этот объект. Хотя создание объекта не повторяется, ничто не мешает изменить сам объект, воспользовавшись полученной ссылкой. В итоге мы имеем разделяемый объект, не являющийся константным.
Пример такого объекта - окно вывода информации об ошибках. Пусть все компоненты интерактивной системы могут направлять в это окно свои сообщения:
Message_window.put_text ("Соответствующее сообщение об ошибке")
где Message_window имеет тип WINDOW, чей класс описан следующим образом:
class WINDOW creation make feature make (...) is -- Создать окно; аргументы задают размер и положение. do ... end text: STRING -- Отображаемый в окне текст put_text (s: STRING) is -- Сделать s отобржаемым в окне текстом. do text := s end ... Прочие компоненты ... end -- класс WINDOW
Ясно, что объект Message_window должен быть одним для всех компонентов системы. Это достигается описанием соответствующего компонента как однократной функции:
Message_window: WINDOW is -- Окно для вывода сообщений об ошибках once create Result.make ("... Аргументы размера и положения ...") end
В данном случае окно сообщений должно находиться в совместном пользовании всех сторон, но не являться константным объектом. Каждый вызов put_text будет изменять объект, помещая в него новую строку текста. Лучшим местом описания Message_window станет класс, от которого порождены все компоненты системы, нуждающиеся в окне выдачи сообщений.
| Создав разделяемый объект, играющий роль константы, (например, i), вы можете запретить вызовы i.some_procedure, способные его изменять. Для этого, например, в классе COMPLEX достаточно ввести в инвариант класса предложения i.x = 0 и i.y = 1. |
Строковые константы
Строковые константы (а точнее, разделяемые строковые объекты) объявляются в языках программирования в манифестной форме с использованием двойных кавычек. Это находит отражение в правилах языка, и как следствие любой компилятор предполагает присутствие в библиотеке класса STRING. Это - своего рода компромисс между "полярными" решениями.
STRING рассматривается как встроенный тип, каким он является во многих языках программирования. Это означает введение в язык операций над строками: конкатенации, сравнения, выделения подстроки и других, что усложняет язык. Преимуществом введения такого класса является возможность снабдить его операции точными спецификациями, благодаря утверждениям, и способность порождать от него другие классы.STRING рассматривается как обычный класс, создаваемый разработчиком. Тогда задавать его константы в манифестной форме [S1] уже нельзя, от разработчиков потребуется соблюдение формата [S2]. Кроме того, данный подход препятствует оптимизации компилятором таких операций, как прямой доступ к символам строки.
Поэтому строки STRING, как и массивы ARRAY, ведут "двойную жизнь", принимая вид предопределенного типа при задании констант и оптимизации кода, и становясь классом, когда речь заходит о гибкости и универсальности.
У18.1 Эмуляция перечислимых типов однократными функциями
Покажите, что при отсутствии unique-типов перечислимый тип языка Pascal
type ERROR = (Normal, Open_error, Read_error)
может быть представлен классом с однократной функцией для каждого значения типа.
У18.2 Однократные функции для эмуляции unique-значений
Покажите, что в языке без поддержки unique-объявлений результат, аналогичный
value: INTEGER is unique
можно получить, воспользовавшись объявлением вида
value: INTEGER is once...end
где вам необходимо написать тело однократной функции и все, что может еще понадобиться.
У18.3 Однократные функции в родовых классах
Приведите пример однократной функции, чей результат включает родовой параметр, и, если он не корректен, порождает ошибку времени выполнения.
У18.4 Однократные атрибуты?
Исследуйте полезность понятия "однократного атрибута", полученного по образцу однократной функции? Будет ли такой атрибут общим для всех экземпляров класса? Как инициализировать однократные атрибуты? Являются ли они избыточными при наличии однократных функций без аргументов? Если нет, объясните, когда использовать тот или иной механизм. Предложите хороший синтаксис объявления однократных атрибутов.
Unique-значения
Иногда при разработке программ возникает потребность в сущности, принимающей лишь несколько значений, характеризующих возможные ситуации. Так, операция чтения может вернуть код результата, значениями которого будут признаки успешной операции, ошибки при открытии и ошибки при считывании. Простым решением проблемы было бы применение целочисленного атрибута:
code: INTEGER
и набора символьных констант
[U1] Successful: INTEGER is 1 Open_error: INTEGER is 2 Read_error: INTEGER is 3
которые позволяют записывать условные инструкции вида
[U2] if code = Successful then ...
или инструкции выбора
[U3] inspect code when Successful then ... when ... end
Но такой перебор значений констант утомляет. Следующий вариант записи действует так же, как [U1]:
[U4] Successful, Open_error, Read_error: INTEGER is unique
Спецификатор unique, записанный вместо буквального значения в объявлении атрибута-константы целого типа, указывает на то, что это значение выбирает компилятор, а не сам разработчик. При этом условная инструкция [U2] и оператор выбора [U3] по-прежнему остаются в силе.
Каждое unique-значение в теле класса положительно и отличается от других. Если, как в случае [U4], константы будут описаны вместе, то их значения образуют последовательность. Чтобы ограничить значение code этими тремя константами, в инвариант класса можно включить условие
code >= Successful; code <= Read_error
Располагая подобным инвариантом, производные классы, обладающие правом специализации инварианта, но не его расширением, могут сузить, но не расширить перечень возможных значений code, сведя его, скажем, всего к двум константам.
Значения, заданные как unique, следует использовать только для представления фиксированного набора возможных значений. Если допустить его пополнение, то это приведет к необходимости внесения изменений в тексты инструкций, подобных [U3]. В общем случае для классификации не рекомендуется использовать unique-значения, так как ОО-методология располагает лучшими приемами решения этой задачи.
Данный выше пример является образцом правильного обращения с описанным механизмом. Правильными можно считать и объявления цветов семафора: green, yellow, red: INTEGER is unique; нот: do, re, mi, ...: INTEGER is unique. Объявление savings, checking, money_market: INTEGER is unique возможно будет неверным, поскольку различные финансовые инструменты, список которых здесь приведен, имеют различные свойства или допускают различную реализацию. Более удачным решением в этом случае, пожалуй, станут механизмы наследования и переопределения.
Объединим сказанное в форме правила:
Принцип дискриминации
Используйте unique для описания фиксированного набора возможных альтернатив. Используйте наследование для классификации абстракций с изменяющимися свойствами.
Хотя объявление unique-значений напоминает определение перечислимых типов (enumerated type) языков Pascal и Ada, оно не вводит новые типы, а только целочисленные значения. Дальнейшее обсуждение позволит объяснить разницу подходов.
Unique-значения и перечислимые типы
Pascal и производные от него языки допускают описание переменной вида
code: ERROR
где ERROR - это "перечислимый тип":
type ERROR = (Normal, Open_error, Read_error)
Переменная code может принимать только значения типа ERROR. Мы уже видели, как добиться того же самого в ОО-нотации: при выполнении кода результат будет почти идентичен, поскольку Pascal-компиляторы традиционно реализуют значения перечислимого типа как целые числа. Введение объявления unique не порождает нового типа. Понятие перечислимых типов, кажется, трудно совместить с объектным подходом. Все наши типы основаны на классах, характеризующих реально осуществимые операции и их свойства. Перечислимые типы не обладают такими характеристиками, а представляют обычные множества чисел. Проблемы с этими типами данных возникают и в необъектных языках.
Статус символических имен не вполне ясен. Могут ли два перечислимых типа иметь общие символические имена (скажем, Orange в составе типов FRUIT и COLOR)? Можно ли их экспортировать как переменные и распространять на них те же правила видимости?Значения перечислимых типов трудно получать и передавать программам, написанным на других языках, к примеру, C и Fortran, не поддерживающих такое понятие. В тоже время значения, описанные как unique, - это обычные числа, работа с которыми не вызывает никаких проблем.Перечислимые типы данных могут требовать специальных операторов. Так, можно представить себе оператор next, возвращающий следующее значение и неопределенный для последнего элемента перечисления. Помимо него потребуется оператор, сопоставляющий элементу целое значение (индекс). В итоге синтаксическое и семантическое усложнение языка кажется непропорциональным вкладу этого механизма.
Объявления перечислимых типов в Pascal и Ada обычно принимают вид:
type FIGURE_SORT = (Circle, Rectangle, Square, ...)
и используются совместно с вариантными полями записей:
FIGURE = record perimeter: INTEGER; ... Другие атрибуты, общие для фигур всех типов ... case fs: FIGURE_SORT of Circle: (radius: REAL; center: POINT); Rectangle:...
Специальные атрибуты прямоугольника ...; ... end end
Этот механизм позволяет организовать разбор случаев в операторе выбора case:
procedure rotate (f: FIGURE) begin case f of Circle:... Специальные операции поворота окружности ...; Rectangle:...; ...
Мы уже познакомились с лучшим способом решения этой проблемы, сохраняющим расширяемость при появлении новых вариантов, - достаточно определить различные версии процедур, подобных rotate для каждого нового варианта, представленного классом.
Когда это наиболее важное применение перечислимых типов исчезло, все, что осталось необходимым в некоторых случаях, - это выбор целочисленных кодов для фиксированного множества возможных значений. Определив их как обычные целые, мы избежим многих семантических неопределенностей, связанных с перечислимыми типами, например, нет ничего необычного в выражении Circle +1, если известно, что Circle типа integer. Введение unique-значения позволяет обойти единственное неудобство, связанное с необходимостью инициализации значений, позволяя выполнять ее автоматически.
