Алгоритмы параллельной сборки мусора
Для получения полного решения проблемы работы в стартстопном режиме крайне привлекательно выделить сборщику мусора отдельный поток выполнения, конечно, при условии поддержки многозадачности операционной системой. Этот прием известен, как сборка мусора "на лету" (on-the fly) или параллельная.
Во время сборки мусора на лету выполнение ОО-системы использует два отдельных потока (часто соответствующих двум отдельным процессам операционной системы): приложение и сборщик. Только приложение выделяет память объектам с помощью инструкций создания; только сборщик освобождает память с помощью reclaim операций.
Сборщик будет работать непрерывно, повторяя фазу пометки и следом фазу чистки для обнаружения и удаления недостижимых объектов.
Отдельные потоки не обязательно должны быть отдельными процессами. Они могут быть, во избежание дополнительных расходов на переключение между процессами или даже потоками, плоскими сопрограммами. (Подробнее сопрограммы будут рассмотрены в лекции 12 курса "Основы объектно-ориентированного проектирования", рассматривающей "параллелизм")
Даже при этих условиях сборка мусора на лету на практике имеет неудовлетворительную полную производительность. Это печально, поскольку сам метод достаточно хорош, особенно при условии использования алгоритма Дейкстры (см. библиографическую ссылку).
По моему мнению (мой комментарий отражает надежду, а не научно установленный результат) параллельная сборка мусора - решение будущего, требующее кооперации с аппаратными средствами. Вместо того, чтобы воровать время у процессора, выполняющего приложение, сборка мусора должна управляться отдельным процессором, предназначенным только для решения этой задачи и сконструированным так, чтобы как можно меньше влиять на процессор(ы), работающие с приложением.
Эта идея требует изменения доминирующей аппаратной архитектуры и, вероятно, вряд ли найдет скорое применение. Я надеюсь, что ответом на иногда задаваемый вопрос -
"Какой тип аппаратного обеспечения наиболее пригоден для объектной технологии?" -
первым пунктом в списке пожеланий будет наличие отдельного процессора для сборки мусора.
Автоматическое управление памятью
Ни один из рассмотренных подходов не является полностью удовлетворительным. Общее решение проблемы управления памятью предполагает серьезную работу на уровне реализации языка.
Байт здесь, байт там, и реальные покойники
Пора послушать печальную и поучительную историю Лондонской службы скорой помощи.
Лондонская служба скорой помощи, как говорят, самая большая в мире, обслуживает территорию около 1500 кв. км, c постоянным населением почти в семь миллионов человек и с еще большим количеством населения в дневное время. Каждый день эта служба обслуживает пять тысяч пациентов и получает от двух до трех тысяч звонков.
Как можно догадаться по мрачному заголовку, в этой работе используются компьютеры (точнее ПО). Вначале было несколько неудачных разработок, даже не введенных в действие, как несоответствующих требованиям, несмотря на то что на разработку этих систем затрачивались значительные финансовые средства. Наконец, в 1992 была введена в эксплуатацию новая система, разработанная за миллион фунтов. Скоро о ней снова заговорили. 28 и 29 октября на телевидении и в прессе сообщалось, что из-за неадекватной работы системы были потеряны двадцать жизней. Говорили, что в одном конкретном случае врачи скорой помощи по рации сообщили на базу, что прибыли на место назначения и спросили, почему владелец похоронного бюро прибыл раньше. Исполнительный директор службы ушел в отставку, была назначена следственная комиссия.
Служба скорой помощи после трагедии не сразу отказалась от компьютерной системы, а переключилась на гибридную модель - частично ручную, частично полагающуюся на систему. Согласно официальным отчетам:
Эта гибридная система действовала с переменным успехом с 27 октября 1992 г. до раннего утра 4 ноября. Однако после двух часов 4 ноября работа системы значительно замедлилась, вскоре после этого система вышла из строя совсем. Перезагрузка не смогла решить проблему. Управление и персонал вернулись к бумаге и телефонным звонкам.
Что привело систему к краху, так что ее не могли сохранить даже как дополнение к ручным операциям? Отчет определил несколько причин. Вот основная:
Следственная команда пришла к выводу, что крах системы был вызван незначительной ошибкой программного обеспечения.
Программист XX ("XX" здесь и далее заменяет название компании, разрабатывающей программное обеспечение данной системы) тремя неделями раньше оставил в системе кусок программного кода, который, используя небольшой файл на сервере, записывал и не стирал информацию о выезде машины на вызов. Через три недели память переполнилась. Эта ошибка была вызвана беспечностью и отсутствием проверки качества программного кода. Такого рода неисправности вряд ли могут быть обнаружены обычным тестированием программистом или пользователем.
Читатель должен сам решить, какую программную ошибку стоит называть незначительной, особенно принимая во внимание последний комментарий о трудностях тестирования, который еще будет подробно обсуждаться ниже.
Для тех, кто все еще думает, что можно пользоваться несерьезным подходом, и для тех, кто относится к управлению памятью только как к проблеме реализации, двадцать жертв лондонской службы скорой помощи должны служить грустным напоминанием о серьезности рассматриваемой проблемы.
Библиографические заметки
Различные модели создания объектов, обсуждаемые в начале этой лекции, поддерживаются "контурной моделью" выполнения языка программирования, которая может быть найдена в [Johnston 1971].
Информация о фиаско Лондонской службы скорой помощи получена из множества сообщений, присланных на форум Risks.
Алгоритм параллельной сборки мусора представлен в [Dijkstra 1978]. Проблемы производительности подобных алгоритмов рассматривал [Cohen 1984]. Сборка мусора поколений представлена в [Ungar 1984].
Механизм сборки мусора ISE's среды, описанный в конце этой лекции, был создан Рафаэлем Манфреди (Raphael Manfredi) и усовершенствован Ксавьером Ле Вурч (Xavier Le Vourch) и Фабрис Францески (Fabrice Franceschi) (чей технический отчет служил основой данного здесь описания).
Что происходит с объектами
ОО-программа создает объекты. Предыдущая лекция показала, как полезно полагаться на динамическое создание для получения гибких объектных структур, подстраивающихся автоматически к нуждам системы.
Что в точности понимается под восстановлением?
Прежде чем рассмотреть подсчет ссылок и сборку мусора, займемся одной технической деталью. В любой форме автоматического управления памятью возникает вопрос, - каков механизм утилизации объекта, определенного как недостижимый? Возможны две интерпретации:
Механизм может добавить память, занимаемую объектом, к постоянно поддерживаемому "списку свободных ячеек", в духе техники, использованной при рассмотрении подхода на уровне компонентов. Последующая инструкция создания ( create x... ) вначале обратится к этому списку для выделения памяти новому объекту. Только если этот список пуст или нет подходящих ячеек, инструкция запросит память у операционной системы. Этот подход может быть назван внутренний список свободной памяти.Альтернативой является возвращение занимаемой объектом памяти операционной системе. На практике это решение включает в себя некоторые аспекты первого: для избежания переизбытка системных вызовов, утилизированные объекты могут временно храниться в списке, возвращаемого операционной системе при достижении определенного предела. Этот подход может быть назван реальным восстановлением.
Хотя возможны оба решения, долго работающие системы требуют реального восстановления. Причина очевидна. Рассмотрим приложение, которое никогда не останавливается. Оно создает объекты, большинство из которых становятся недостижимыми. Существует верхняя граница количества одновременно достижимых объектов, в то время как общее количество созданных с начала работы объектов не ограниченно. Тогда при подходе внутренних списков свободной памяти возможна ситуация, когда приложение постоянно запрашивает большую, чем нужно, память. В упражнении У9.1 этой лекции требуется создать образец программы, демонстрирующий такое поведение.
Было бы большим разочарованием иметь автоматическое управление памятью и оказаться в ситуации лондонской службы скорой помощи, - посягая без причин байт за байтом на доступную память, пока выполнение не выйдет за рамки памяти и не закончится катастрофой.
Дискуссия
Этот пример показывает, как подход на уровне компонентов может облегчить проблему восстановления памяти. Подразумевается, что реализации языка не предоставляет автоматического механизма сборки мусора, описанного в следующих разделах. Не обременяя приложение проблемами управления памятью, решение передается повторно используемым библиотечным классам, созданных производителями компонентов.
Недостатки и польза - понятны. Проблемы ручного управления памятью (угроза ненадежности, монотонность) не исчезают магически. Защищенная от неправильного использования схема управления памятью, например, для связного списка, - трудна. Но вместо того, чтобы бороться с проблемой каждому разработчику приложений, работа возлагается на производителя компонентов. Чрезмерные усилия, затрачиваемые производителями компонент, окупаются тем, что созданные компоненты многократно используются различными приложениями.
Достижимые объекты в классическом подходе
Поскольку проблема недостижимости рассматривается в таких классических подходах, как Pascal, C и Ada, разумно начать с этих случаев. (Читатели, незнакомые ни с одним из этих подходов, могут пропустить этот раздел и перейти к следующему, рассматривающему ОО-программирование.)
Все подходы используют стековое размещение объектов и размещение в динамической памяти. Языки C и Ada поддерживают также статическую модель, но для упрощения ее можно проигнорировать, рассматривая статику как специальный случай размещения в стеке. Можно полагать, что статические объекты размещаются в начале выполнения и находятся в конце стека. В языке Pascal они объявляются в самом внешнем блоке.
Общим свойством этих подходов является и то, что сущности могут задаваться указателями. В ОО-подходе вместо указателей используются ссылки - более абстрактное понятие (эта тема обсуждалась в предыдущей лекции). Позвольте сделать вид, что указатели есть в действительности ссылки, игнорируя слабо типизируемую природу указателей в С.
При этих допущениях и упрощениях на следующем рисунке показаны оригиналы, размещенные в стеке или присоединенные к ссылке, размещенной в стеке, достижимые и недостижимые объекты.

Рис. 9.6. Живые и мертвые объекты в комбинированной модели - стек и динамическая память (живые объекты окрашены в серый цвет)
Проблема недостижимости возникает только для объектов, размещенных в динамической памяти. Такие объекты всегда подсоединяются к сущностям ссылочного типа. Поэтому удобно игнорировать проблему повторного использования памяти для объектов, непосредственно размещенных в стеке. Она может быть решена просто при помощи освобождения стека при окончании блока. Начнем рассмотрение со ссылок, размещенных в стеке. Мы можем назвать их ссылками оригиналами (reference origins). Они изображены толстыми стрелками на рисунке и представляют:
(O1) Значение локальных сущностей или аргументов функции ссылочного типа (как две верхних начальных ссылки на рисунке).(O2) Поля ссылочного типа объектов, расположенных в стеке (ниже лежащая ссылка на рисунке).
Рассмотрим пример объявления типа и процедуры, написанный на смеси Pascal и нотации, используемой в этой книге ( reference G - ссылка, которая может быть подсоединена к объекту типа G):
type COMPOSITE = record m:INTEGER r:reference COMPOSITE end ... procedure p is local n: INTEGER c: COMPOSITE s: reference COMPOSITE do ... end
При каждом вызове процедуры p три значения вталкиваются в стек:

Рис. 9.7. Размещение сущностей для процедуры
Тремя новыми значениями являются: целое n, не влияющее на проблему управления объектами (оно исчезнет при завершении процедуры и не ссылается на другие объекты); ссылка s, являющаяся примером категории О1; и объект с типа COMPOSITE. Сам объект содержится в стеке и занятая объектом память может быть использована по завершении работы процедуры. Но он содержит ссылочное поле r, являющееся примером категории О2.
Итак, для определения достижимости объекта в классическом подходе, комбинирующем стековую и динамическую память, следует начать со ссылок в стеке (переменные ссылочного типа и ссылочные поля комбинированных объектов), и последовательно просмотреть все ссылочные поля присоединенных объектов, если они существуют.
Достижимые объекты в ОО-модели
ОО-структура данных, представленная в предыдущих лекциях, имеет некоторые отличия от рассмотренной выше структуры.

Рис. 9.8. Достижимость в ОО-модели
Работа любой системы начинается с создания объекта, называемого корневым объектом системы, или просто корнем (когда нет путаницы с корневым классом, задаваемым статически). Корень в этом случае является одним из оригиналов.
Другое множество оригиналов возникает из-за возможного присутствия локальных переменных в подпрограмме. Рассмотрим подпрограмму вида
some_routine is local rb1, rb2: BOOK3 eb: expanded BOOK3 do . . . create rb1 . . .Операции, возможно использующие rb1, rb2 и eb . . . end
При любом вызове и выполнении подпрограммы some_routine, инструкции в теле подпрограммы могут ссылаться на rb1, rb2, eb и на присоединенные к ним объекты, если они есть. Это значит, что такие объекты должны быть частью множества достижимых объектов, но не обязательно зависимы от корня. Заметим, для eb всегда есть присоединенный объект, а rb1 и rb2 могут при некоторых запусках иметь значение void.
Локальные сущности ссылочного типа, такие как rb1 и rb2, подобны переменным подпрограммы, которые в предыдущей модели были размещены в стеке. Локальные сущности развернутого типа, как eb, подобны объектам, расположенным в стеке.
Когда завершается очередной вызов some_routine, исчезают сущности rb1, rb2 и eb текущей версии. В результате все присоединенные объекты перестают быть частью множества оригиналов. Это не значит, что они становятся недостижимыми, - они могут тем временем стать зависимыми от корня или других оригиналов.
Допустим, например, что а - это атрибут рассматриваемого класса и что полный текст подпрограммы имеет вид:
some_routine is local rb1, rb2: BOOK3 eb: expanded BOOK3 do create rb1;create rb2 a := rb1 end
На следующем рисунке показаны объекты, создаваемые вызовом some_routine, и ссылки с присоединенными объектами.

Рис. 9.9. Объекты, присоединенные к локальным сущностям
Когда вызов some_routine завершается, объект О, представляющий цель вызова, все еще доступен (иначе не было бы этого вызова). Поле а этого объекта О в результате вызова присоединено к объекту B1 класса BOOK3, созданного первой инструкцией создания нашей подпрограммы. Поэтому объект B1 остается достижимым по завершении вызова. Напротив, объекты B2 и EB, которые были присоединены к rb2 и eb во время вызова, теперь становятся недостижимыми: в соответствии с текстом процедуры невозможно, чтобы какой-либо другой объект "запомнил" В2 или ЕВ.
Использование динамического режима
Динамический режим, очевидно, наиболее общий, и он необходим для ОО-программирования. Его используют многие не ОО-языки. В частности:
Pascal использует статический режим для массивов, режим, основанный на стеке, для переменных, не являющихся массивами и указателями, динамический режим для указателей. В последнем случае создание объекта выполняется с помощью вызова специальной процедуры создания new. Язык C похож на Pascal, но дополнительно вводит динамические массивы и статические переменные, не являющиеся массивами, Язык С динамически размещает переменные типа указатель и массивы, используя библиотечную функцию malloc. PL/I поддерживает все модели. Lisp системы традиционно были высоко динамичны и полагались большей частью на динамический режим распределения памяти. Одна из наиболее важных операций Lisp, используемая многократно для представления списков, - CONS, создает структуру из двух полей. В первом поле хранится значение элемента, а во втором - указатель на следующий элемент. Здесь CONS, скорее источник новых объектов, чем инструкция их создания.
Класс MEMORY
Наиболее удобный подход - представить эти свойства в виде класса, который назовем MEMORY. Класс приложения, нуждающийся в свойствах, будет наследником MEMORY.
| Аналогичный подход будет использован для механизма обработки исключений (класс EXCEPTIONS, лекция 12) и для управления параллелизмом (класс CONCURRENCY, лекция 12 курса "Основы объектно-ориентированного проектирования") |
Среди компонентов класса MEMORY будут представлены рассмотренные ранее процедуры: collection_off, collection_on, collect_now.
Ключевые концепции
Существует три основных режима создания объектов: статический, основанный на стеке, динамический. Последний характерен для ОО-языков, но встречается везде, например, в Lisp, Pascal (указатели и new), C (malloc), Ada (типы доступа).В программах, создающих много объектов, объекты могут становиться недостижимыми. Их память теряется, приводя, в худших случаях, к сбою из-за нехватки памяти, при том что часть памяти остается неиспользованной.Эту проблему можно игнорировать в тех случаях, когда программа почти не создает недостижимых объектов или создает всего лишь несколько объектов, общий размер которых сравним с доступной памятью.Во всех других случаях (динамические структуры данных, ограниченные ресурсы памяти) любое решение проблемы включает два компонента: обнаружение мертвых объектов и восстановление занятой ими памяти.Каждая из задач может быть решена на одном из трех уровней: реализации языка, разработки компонентов, приложения.Вменять в обязанность приложения обнаружение мертвых объектов и восстановление памяти - опасно и обременительно. Эта проблема должна решаться на уровне языка.В некоторых специальных случаях можно управлять памятью на уровне компонентов. Обнаружение выполняется компонентами, восстановление памяти - компонентами, либо средствами, реализованными на уровне языка.Подсчет ссылок не работает для циклических структур.Общеприменимой техникой решения проблемы является сборка мусора. Ее накладные издержки приемлемо малы в нормальных ситуациях и, благодаря алгоритмам, работающим в стартстопном режиме, невидимы в нормальных интерактивных приложениях.Сборка мусора поколений увеличивает эффективность алгоритма, используя тот факт, что недостижимыми становятся, в первую очередь, новые объекты.Хороший механизм управления памятью должен возвращать неиспользуемую память не только текущему приложению, но и операционной системе.Описанная схема реальной системы управления памятью предлагает комбинацию алгоритмов и способов, позволяющих разработчикам приложений производить настройку механизмов системы, в том числе позволяя включать и отключать сборку мусора в критических разделах приложения.
Механизм освобождения
Другой важной процедурой класса MEMORY является dispose (не путайте с тезкой Pascal, которая освобождает память). Она связана с важной практической проблемой, иногда называемой финалом или окончательным завершением (finalization). Если сборщик мусора утилизирует объект, связанный с внешними ресурсами, вы можете пожелать включить в его спецификацию некоторое дополнительное действие, такое как освобождение ресурсов, выполняемое параллельно с утилизацией. Типичный пример - класс FILE, экземпляр которого представляет файлы операционной системы. Желательно иметь возможность в случае утилизации недостижимого экземпляра класса FILE вызвать некоторую процедуру, закрывающую соответствующий физический файл.
Обобщая сказанное, рассмотрим процедуру dispose, выполняющую во время утилизации необходимые объекту операции. Это могут быть не только операции по освобождению ресурсов, но и любые операции, определяемые спецификацией класса.
При ручном управлении памятью проблем не возникает: достаточно включить вызов dispose до вызова reclaim. Деструктор класса в С++ включает в себя две операции dispose и reclaim. Однако при наличии сборщика мусора приложение напрямую не контролирует момент утилизации объекта, поэтому невозможно вставить dispose в нужное место.
Решение проблемы использует мощь объектной технологии и, в частности, наследование и переопределение. (Эта техника изучается в последующих лекциях, но ее применение здесь достаточно просто и понятно без детального ознакомления.) Класс MEMORY включает процедуру dispose, в теле которой никакие действия не выполняются:
dispose is - Действия, которые следует выполнить в случае утилизации; - по умолчанию действия отсутствуют. - Вызывается автоматически сборщиком мусора. do end
Тогда любой класс, требующий специальных действий всякий раз, когда сборщик утилизирует один из его экземпляров, должен переопределить процедуру dispose так, чтобы она выполняла эти действия. Например, представим, что класс FILE имеет логический атрибут opened и процедуру close. Он может переопределить dispose следующим образом:
dispose is - Действия, которые следует выполнить в случае утилизации: - закрыть связанный файл, если он открыт. - Вызывается автоматически сборщиком мусора. do if opened then close end end
Комментарии описывают используемое правило: при утилизации объекта вызывается dispose - либо изначально пустую процедуру (что далеко не самый общий случай), либо версию, переопределенную в классе, представляющего потомка MEMORY.
Механизм сборки мусора
Сборщик мусора (garbage collector) - это функция исполнительной системы (runtime system) языка программирования. Сборщик мусора выполняет обнаружение и утилизацию недостижимых объектов, не нуждаясь в управлении приложением, хотя приложение может иметь в своем распоряжении различные средства контроля работы сборщика.
Детальное рассмотрение всех проблем сборки мусора требует отдельной книги. (В конце лекции приведена библиография по этой проблеме.) Рассмотрим общие принципы и возникающие проблемы, концентрируя внимание на свойствах, важных для разработчиков программ.
Требования к сборщику мусора
Сборщик мусора, несомненно, должен быть корректным, удовлетворяя двум требованиям:
Свойства сборщика мусора
Качественность: каждый собираемый объект должен быть недостижимым.
Полнота: каждый недостижимый объект должен быть собран.
Качественность - абсолютное требование: лучше не собирать мусор, чем выбрасывать нужный объект. Нужна полная уверенность в том, что управлению памятью можно слепо доверять. Фактически надо забыть о нем почти навсегда, будучи уверенным, что кто-то как-то убирает беспорядок в вашей программе, также как кто-то как-то убирает мусор в вашем офисе, когда вас нет, но не убирает при этом ваши книги, компьютер и семейные фотографии со стола.
Полнота желательна - без нее все равно можно столкнуться с проблемой, которую сборщик мусора должен решить: память тратится на бесполезные объекты. Но здесь можно не требовать безупречности: сборщик может быть полезным, если он собирает основную часть мусора, иногда пропуская один или два объекта.
Это замечание требует детализации. На практике любой сборщик промышленного масштаба должен обладать полнотой. Полнота на практике также необходима, как качественность, но менее жестка, если перефразировать ее определение: "каждый недостижимый объект должен быть, в конце концов, собран". Предположим, что мы можем сделать процесс сборки более эффективным, благодаря алгоритму, который собирает каждый недостижимый объект, но может запоздать с обращением к некоторым из них: такая схема будет приемлемой для большинства приложений.
В этом идея обсуждаемого далее алгоритма "сборки мусора поколений", который в целях эффективности чаще сканирует области памяти, содержащие с большей вероятностью недостижимые объекты, и реже обращает внимание на другие участки памяти.
| При таком компромиссном подходе для сборщика мусора необходимо будет ввести не только бинарные критерии полноты и качественности, но и критерий, называемый своевременность (timeliness). Его значением является интервал времени от момента, когда объект становится недостижимым, до момента его утилизации, причем важно как среднее значение времени, так и верхняя его граница. |
Действительная проблема лежит в структуре языка, а не в технологии компиляции или культурных традициях. Язык С++, следуя С, слабо типизирован; он предоставляет возможность преобразования типа, благодаря которой на объект одного типа можно ссылаться как на сущность другого типа. Конструкция:
(OTHER_TYPE) x
означает, что теперь x рассматривается как сущность типа OTHER_TYPE, связанного или несвязанного с истинным типом x. Хорошие книги по С++ предостерегают приложения от применения подобных конструкций. Но разработчикам компилятора деваться некуда, - они обязаны реализовать язык в соответствии с его определением. Теперь представьте следующий сценарий. Ссылка на объект какого-либо полезного типа, скажем NUCLEAR_SUBMARINE, временно приведена к типу integer.Сборщик мусора, работающий в этот момент, не видит ссылки, а видит только целое типа integer. Не находя других ссылок на объект, сборщик утилизирует подлодку. Когда, через некоторое время программа выполнит обратное преобразование целого в ссылку типа NUCLEAR_SUBMARINE, будет уже поздно, - подлодка уничтожена.
Для решения этой проблемы предлагались разные методы. Широкого применения они не получили из-за накладываемых ограничений. Язык Java может рассматриваться как язык семейства C++, в котором введены существенные ограничения на систему типов, вплоть до удаления множественного наследования и универсализации, чтобы сделать, наконец, возможной сборку мусора в мире программ, основанных на С.
При тщательно спроектированной системе типов, конечно, можно сочетать мощь множественного наследования и универсализации с безопасностью типов и поддержкой эффективной сборки мусора.
Может ли быть оправдан несерьезный подход?
Несерьезный подход не создает проблем в системах, создающих небольшое число объектов, например, при проведении простых тестов и экспериментов.
Более интересен случай, когда система может создавать много объектов, гарантируя, что ни один или немногие из них станут недостижимыми. Этот случай аналогичен статической схеме размещения, в которой ни один объект не удаляется. Разница только в том, что создание происходит динамически во время выполнения программы. Несерьезный подход в этом случае оправдан, поскольку практически не возникает необходимость утилизации объектов.
Некоторые программы реального времени следуют этой схеме: по причине эффективности, создавая все необходимые объекты статично или во время инициализации, избегая непредсказуемых моделей динамического создания.
Этот метод применяется в "жестких" системах реального времени ("hard-real- time"), требующих гарантированное микросекундное время отклика на внешние события (например, системы обнаружения ракет). В таких системах время выполнения каждой операции должно быть полностью предсказуемо. Но тогда приходится отказываться не только от управления памятью, но и от динамического создания объектов, рекурсии, вызова процедур с локальными сущностями и так далее. Работа с такими системами подразумевают специализированную машину с одним исполняемым процессом, фактически без операционной системы в обычном понимании этого термина. В таких средах люди предпочитают писать на языках ассемблера, из-за страха дополнительных неожиданностей от сгенерированного компилятором кода. Все это сводит обсуждение к малой, хотя и стратегически важной области мира программ.
Надо ли заботиться о памяти?
Другой аргумент, который можно услышать в оправдание несерьезному подходу, - это постоянный рост объема доступной памяти компьютера и уменьшение цены памяти.
Используемая память может быть как виртуальной, так и реальной. В системах виртуальной памяти первичная и вторичная память делится на блоки, называемые страницами. Вновь требуемые страницы первичной памяти вытесняют во вторичную память редко используемые страницы первичной памяти. Если такая система используется для работы с ОО-системами, страницы, содержащие недостижимые объекты, будут вытесняться и освободят основную память для часто используемых объектов.
Если бы действительно в нашем распоряжении было почти безграничное количество почти свободной памяти, можно было бы удовлетвориться несерьезным подходом.
К несчастью, это не так.
Первая причина в том, что на практике виртуальная память не эквивалентна реальной. Если хранить большое количество объектов в виртуальной памяти, в которой меньшинство достижимых объектов рассыпано среди большинства недостижимых, то процесс выполнения будет постоянно вызывать перемещение страниц памяти, феномен, известный как пробуксовка (trashing), приводящий к драматическому увеличению времени выполнения. Действительно, системы виртуальной памяти усложняют эффективное разделение двух основных аспектов - пространства и времени. (См. "Эффективность", лекцию 1.)
Но есть более важное ограничение применения несерьезного подхода. Даже большая память имеет границы. Удивительно, как быстро программисты к ним подходят. Как только мы выходим за пределы систем с небольшим числом недостижимых объектов, лицом к лицу сталкиваемся с проблемой восстановления памяти.
Недостижимые объекты
Значит ли отсоединение объектов, например O1 или O2 (рис.9.4 ), что они становятся бесполезными и, следовательно, механизмы периода исполнения могут освободить занимаемое ими место в памяти? Это было бы слишком просто! Сущность, для которой объект был первоначально создан, могла уже потерять интерес к объекту, но из-за динамических псевдонимов другие ссылки могут быть все еще подсоединены к нему. Например, рис.9.4 возможно отражает лишь частное видение связей между объектами. Рассматривая более широкий контекст, (рис.9.5 ) можно обнаружить, что O1 и O2 все еще достижимы для других объектов.
Но и эта картина все еще не дает полного видения структуры всех связей между объектами. Расширяя контекст, можно, например, выяснить, что O4 и O5 сами не нужны, так что в отсутствии других ссылок, O1 и O2 не нужны тоже.
Таким образом, ответ на вопрос: "Какие объекты можно удалить?" должен следовать из глобального анализа множества всех созданных объектов. Выделим три типа объектов:
(C1) Объекты, напрямую присоединенные к сущностям, известны (из правил языка программирования) как необходимые.(C2) Зависимые от объектов категории C1. (Напомним, наряду с непосредственно зависимыми объектами, имеющими ссылки на объекты C1, зависимые объекты могут рекурсивно иметь ссылки на непосредственно зависимые объекты.) Здесь рассматривается прямая и косвенная зависимость.

Рис. 9.5. Отсоединение - не всегда смерть объекта
C3 Объекты, не относящиеся к предыдущим двум категориям.
Объекты первой категории могут называться оригиналами (origins). Вместе с объектами категории С2 они составляют множество достижимых (reachable) объектов. Объекты категории С3 недостижимы (unreachable). Они ранее неформально назывались ненужными или бесполезными. В другой более мрачной терминологии используются термины "мертвые объекты" для категории С3 и "живые" для первых двух. (У программистов принята более прозаическая терминология, и процесс удаления мертвых объектов, изучаемый ниже, называется просто сборкой мусора.)
| Для объектов наряду с термином "оригинал" используется термин "корень". Первый термин предпочтительнее, поскольку сама ОО-система имеет "корневой объект" и "корневой класс". Однако результат возможной двусмысленности не сильно вредит делу, потому что корневой объект, как будет видно далее, является одним из оригиналов. |
Первый шаг к решению проблемы управления памятью при использовании динамического режима - выделение достижимых и недостижимых объектов. Для идентификации достижимых объектов нужно начать с оригиналов и пройти по всем многократно возникающим ссылкам. Так что первый вопрос, - как найти оригиналы? Ответ зависит от структуры периода выполнения, определяемой лежащим в ее основе языком программирования.
Необходимость автоматических методов
Хорошая ОО-среда должна предлагать механизм автоматического управления памятью, который обнаруживал бы и утилизировал недостижимые объекты, позволяя разработчикам приложений концентрироваться на своей работе - разработке приложений.
Предыдущее обсуждение достаточно ясно показало, как важно иметь возможность управлять памятью. По словам Михаила Швейцера (Michael Schweitzer) и Ламберта Стретра (Lambert Strether): "ОО-программа без автоматического управления памятью то же самое, что скороварка без клапана безопасности: рано или поздно она взорвется!" (Из [Schweitzer 1991])
Многие среды разработки, разрекламированные как ОО, не поддерживают такие механизмы. Они могут иметь свойства, делающие их привлекательными на первый взгляд. Они даже могут безупречно работать в малых системах. Но в серьезном проекте вы рискуете разочароваться в среде, когда приложение достигнет реального размера. В заключение конкретный совет:
При выборе ОО-среды - или просто компилятора ОО-языка - для разработки программного продукта ограничьте ваше внимание только теми решениями, которые предлагают автоматическое управление памятью.
Два главных подхода применимы при автоматическом управлении памятью: подсчет ссылок и сборка мусора. Они оба достойны внимания, хотя второй намного мощнее и обще применим.
Несерьезный подход (тривиальный)
Первый подход заключается в игнорировании проблемы: предоставлять мертвые объекты их судьбе. Создаются объекты как обычно, но никто не волнуется о том, что может потом случиться с объектами.
Операции сборщика мусора
Сборщик мусора включается одной из двух требующих память операций: инструкцией создания ( create x ) или клонирования. Сборщик запускается не только, когда программе не хватает памяти: механизм может активизироваться, когда он определяет некоторые условия, за которыми последует нехватка памяти.
Если первичная память заполнена, сборщик начнет сборку мусора поколений. В большинстве случаев освободится достаточно памяти для текущих нужд. Если этого не произошло, следующий шаг - полный цикл пометки-чистки с последующим сжатием памяти. Если и в этом случае памяти не достаточно, сборщик запросит память у операционной системы.
Основные алгоритмы являются стартстопными; их время выполнения обычно составляет несколько процентов от времени выполнения приложения. Внутренняя статистика ведет учет занятой памяти и помогает определить подходящий для вызова алгоритм.
Можно настроить работу сборщика, задавая различные параметры, в частности, включение параметра speed заставит алгоритм не собирать всю доступную память с помощью механизма сжатия, а сразу использовать возможности операционной системы. Устанавливая другие параметры, можно включать механизмы: collection_off, collect_now и dispose из класса MEMORY.
Механизм управления памятью, построенный на основе всех этих методов, сделал возможным разработку и выполнение больших приложений, создающих много объектов, создающих их быстро, не заботясь об используемой памяти, поручая кому-то другому заботу о последствиях.
Основа сборки мусора
Рассмотрим работу сборщика мусора.
Основной алгоритм включает две фазы: пометка и чистка. Фаза пометки, начиная с оригиналов, рекурсивно следует ссылкам, проходит активную часть структуры и помечает как достижимые все встреченные объекты. Фаза чистки обходит всю структуру объектов, утилизируя все не помеченные объекты и удаляя все пометки. (Об оригиналах см. раздел "Достижимые объекты в ОО-модели этой лекции.")
Как и в случае с подсчетом ссылок, объекты включают дополнительное поле, используемое здесь для пометки. Но требуемая для этого поля память незначительна, - достаточно одного бита для каждого объекта. Как будет видно при изучении динамического связывания, реализация ОО-возможностей требует, чтобы объект имел дополнительную внутреннюю информацию (например, тип). Эта информация обычно занимает одно или два слова в каждом объекте. Бит пометки может быть частью служебного слова, и не будет занимать дополнительную память.
Основы
Управление памятью - автоматическое. Среда включает сборку мусора, существующую по умолчанию. Вполне естественен вопрос пользователя "как включить сборщик мусора?". Ответ - он уже включен! В обычном использовании, в том числе и в интерактивных приложениях, он незаметен. Его можно отключить с помощью collection_off.
В отличие от сборщиков в других средах, сборщик мусора не просто освобождает память для повторного использования объектами того же приложения, а возвращает память операционной системе для ее использования другими приложениями (по крайней мере, операционными системами, поддерживающими механизм освобождения памяти навсегда). Ранее показано, как важно это свойство, особенно для систем, работающих долгое время или постоянно.
Дополнительные инженерные цели, возложенные на сборщика мусора при его проектировании: эффективная сборка памяти, небольшие накладные расходы, стартстопный режим работы, позволяющий предотвратить блокировку приложения в критические моменты его работы.
Отсоединение
В динамическом режиме объекты могут стать ненужными в непредсказуемые моменты периода выполнения; раз так, то некоторый механизм (определяемый позже в этом обсуждении) может освобождать занятую ими память.
Причина - присутствие в этом режиме выполнения операции отсоединения (detachment), обратной к операции присоединения. В предыдущей лекции изучалось, как сущности присоединяются к объектам, но не рассматривались детали отсоединения. Пора это исправить.
| Отсоединение распространяется только на объекты x ссылочного типа. Если x развернутого типа - значением x является объект O, то нет способа отсоединить x от O. Заметьте, однако, если x развернутый атрибут некоторого класса, O представляет подобъект некоторого большого объекта BO. Тогда BO, а вместе с ним и O, может стать недостижимым по одной из причин, изучаемых ниже. Посему в оставшейся части этой лекции можно ограничиться рассмотрением сущностей ссылочного типа. |

Рис. 9.4. Отсоединение
Основные причины отсоединения следующие. Предположим, x и y сущности ссылочного типа вначале присоединены к объектам O1 и O2. Рисунок иллюстрирует случаи D1 и D2.
(D1) Присваивание вида x := Void, или x := v где v типа void, отсоединяет x от O1.(D2) Присваивание вида y := z, где z не присоединен к объекту O2, отсоединяет y от O2.(D3) Завершение подпрограммы отсоединяет формальные аргументы от присоединенных к ним объектов.(D4) Инструкция создания create x , присоединяет x к вновь созданному объекту и, следовательно, отсоединяет x, если он ранее был присоединен к объекту O1.
Случай D3 соответствует ранее данному правилу: инициализация формального аргумента a подпрограммы r во время вызова t.r(..., b, ...), где позиция b в вызове соответствует позиции a в объявлении r, в точности соответствует семантике присваивания a := b.
Перемещение объектов
Необходимость возвращать память операционной системе порождает одну из самых утонченных частей механизма: сборщик мусора может при необходимости перемещать объекты.
Это свойство вызывает головную боль при реализации сборщика, но оно делает этот механизм устойчивым и практичным. Без него невозможно было бы использовать сборку мусора для долго работающих, критически важных систем.
Внутри ОО-мира нет необходимости задумываться о перемещении объектов, если гарантируется, что система не имеет тенденции постоянного расширения (подразумевается, что общий размер достижимых объектов ограничен). При использовании внешних программ и передачи им объектов эту проблему необходимо рассматривать. Внешняя программа может сохранять ссылки на объекты из ОО-мира в виде простых адресов (указателей в языке С). При попытке использовать эти объекты, находящиеся без защиты, например, в течение 10 минут, возникнут трудности: за это время объект может быть перемещен и по его адресу лежит нечто другое или вообще ничего. Простой библиотечный механизм решает эту проблему: С-функции должны получать сам объект и доступ к нему через специальный макрос, который находит объект, где бы он ни находился.
Подход на уровне компонентов
(Этот раздел описывает решение, полезное только для специального случая; его можно пропустить при первом чтении книги.)
Перед тем как перейти к амбициозным схемам, таким как автоматическая сборка мусора, стоит посмотреть на решение, которое может быть альтернативой предыдущему, исправляя некоторые его недостатки.
Это решение применимо только для ОО-программирования "снизу-вверх", где структуры данных создаются не для нужд конкретной программы, а строятся как повторно используемые классы.
Что предлагает ОО-подход по отношению к управлению памятью? Одна из новинок скорее организационная, чем техническая: в этом подходе большое внимание уделяется повторному использованию библиотек. Между разработчиками приложения и создателями системных средств - компилятора и среды разработки - стоит третья группа людей, отвечающих за написание повторно используемых компонентов, реализующих основные структуры данных. Членов третьей группы, которые, конечно могут иногда выступать и в двух других ипостасях, принято называть производителями компонентов (component manufacturers).
Производители компонентов имеют полный контроль над любым использованием данного класса и потому находятся в лучшем положении при поиске приемлемого решения проблемы управления памятью для всех экземпляров этого класса.
Если модель размещения и удаления объектов класса достаточно проста, разработчики компонентов могут найти эффективное решение, возможно, даже не требующее специальной подпрограммы reclaim. Они могут выразить все в терминах понятий высокого уровня. Это и называется подходом на уровне компонентов.
Подсчет ссылок
Простая идея лежит в основе первого метода управления памятью - подсчета ссылок. Каждый объект хранит текущее число сделанных на него ссылок. Когда оно становится равным нулю, объект можно утилизировать.
Это решение не сложно для реализации на уровне языка. Нужно обновлять число ссылок любого объекта в ответ на операции, создающие новый объект, присоединения и отсоединения объекта.
Любая операция, создающая объект, инициализирует число ссылок, делая его равным единице. В частности, так должно происходить с инструкцией создания create a , создающей объект и присоединяющей его к а. (Ситуация с инструкцией clone вкратце будет обсуждена позже.)
Любая операция, присоединяющая новую ссылку к объекту О, должна увеличивать число ссылок О на единицу. Имеется два вида операций присоединения, в которых значение a представляет ссылку, присоединенную к О:
A1 L b := a (присваивание). A2 L x.r(..., a, ...) , где r - некоторая подпрограмма (передача аргумента).
Любая операция, отсоединяющая ссылку от объекта О, должна уменьшать число ссылок О на единицу. Имеется два вида операций отсоединения:
(D1) Любое присваивание a := b. Заметим, что это также присоединяющая операция (А1) для объекта, присоединенного к b. (Поэтому если b также присоединен к О, необходимо как увеличить, так и уменьшить счетчик О, т.е. оставить его без изменения - приятный результат.)(D2) Завершение вызова подпрограммы вида x.r(..., a, ...). (Если a встречается более одного раза в списке фактических аргументов, необходимо считать отсоединением каждое вхождение a.)
После таких операций, реализация должна также проверять, не является ли значение счетчика, равным нулю, если да, то можно утилизировать объект.
В заключение рассмотрим ситуацию с clone, требующую особого внимания. Операция a := clone (b) создает копию объекта ОВ, присоединенного к b, если ОВ существует. Вновь созданный объект ОA присоединяется к a. Счетчик ссылок ОA инициализируется единицей, естественно, не копируя счетчик ОВ. Если ОВ имеет непустые ссылочные поля, то при его копировании следует увеличить на единицу счетчик ссылок каждого объекта, присоединенного к каждому ссылочному полю, не исключено, что некоторые поля могут быть присоединены к одному и тому же объекту.
Очевидным недостатком подсчета ссылок являются издержки выполнения как временные, так и по объему памяти. Для всех операций со ссылками реализация языка должна выполнять арифметическую операцию, а в случае отсоединения, - условный оператор. К тому же, к каждому объекту добавляется поле счетчика ссылок.
Но есть более серьезная проблема, делающая подсчет ссылок, к сожалению, мало используемым. ("К сожалению", поскольку эта техника легко реализуема.) Проблема связана с циклическими структурами. Рассмотрим в очередной раз наш основной пример структуры с взаимосвязанными объектами:

Рис. 9.14. Неудаляемая при подсчете ссылок циклическая структура
Объекты О1, О2 и О3 содержат циклические ссылки друг на друга. Допустим, что нет объектов вне структуры кроме О, содержащих ссылки на какой-либо из объектов структуры. Соответствующий счетчик ссылок показан под каждым объектом.
Теперь допустим, что ссылка от О к О1 отрезана, например потому что подпрограмма вызываемая с целью О выполняет инструкцию:
а:=void
Тогда объекты О1, О2, О3 станут недостижимыми, но механизм подсчета ссылок не определит эту ситуацию: вышеуказанная инструкция уменьшит счетчик ссылок О1 до трех и только. Счетчики всех трех объектов останутся положительными, что не позволит определить необходимость их утилизации.
Из-за этой проблемы, подсчет ссылок применим только к структурам, гарантированно не использующим циклы. Это делает его неподходящим в качестве универсального механизма на уровне реализации языка. Невозможно гарантировать, что произвольная система не создает циклических структур. Поэтому метод может быть применен только при создании библиотек компонентов. К сожалению, если методы уровня компонентов, рассмотренные в предыдущем разделе, не применимы, то это происходит потому, что используемые структуры слишком сложны и, чаще всего, по причине наличия циклов.
Повторное использование памяти в трех режимах
Для объектов, созданных как в основанном на стеке режиме, так и в динамическом режиме, возникает вопрос, что делать с неиспользуемыми объектами? Возможно ли память, занятую таким объектом, повторно использовать в более поздних инструкциях создания новых объектов?
В статической модели проблемы не существует: для каждого объекта есть одна навсегда присоединенная сущность. Выполнение требует поддерживать связь с объектом все время, пока сущность активна. Поэтому повторное использование памяти невозможно в настоящей трактовке этого понятия. Однако при острой нехватке памяти похожая технология иногда используется. Если вы уверены, что объекты, присоединенные к двум сущностям, никогда не нужны одновременно, и эти сущности не должны сохранять свои значения между последовательными использованиями, то можно на одной и той же памяти размещать две или более сущности, будучи совершенно уверены в безопасности того, что вы делаете. Эта техника, известная как перекрытие (overlay), достаточно ужасная, все еще практикуется при работе вручную.
| Если все-таки использовать перекрытие, то, конечно, его следует выполнять автоматически, используя специальные инструменты, - слишком велика вероятность ошибки. Главной проблемой остается возможность изменений: решение о перекрытии двух переменных может быть корректным на определенном этапе жизни программы. Неожиданное изменение может сделать его неправильным. Мы столкнемся с похожей проблемой ниже, в технологии сборки мусора. |
В режиме, основанном на стеке, объекты, присоединенные к сущностям, могут быть размещены в стеке. В языках с блочной структурой ситуация упрощается: размещение объектов происходит одновременно для всех сущностей данного блока, допуская использование одного стека для всей программы. Схема действительно элегантна, потому что использует два множества сопутствующих событий:
| Размещение объекта | Начало блока | Вталкивание объектов (один для каждой локальной сущности блока) в стек |
| Удаление объекта | Конец блока | Выталкивание объектов из стека |
Простота и эффективность этой техники реализации является одной из причин успешности языков с блочной структурой. В динамическом режиме все не так просто. Проблема связана с мощью самого механизма: в период компиляции ничего нельзя сказать о создании объекта, невозможно предсказать, когда данный объект может стать ненужным.
Повышенное чувство голода и потеря аппетита (Bulimia and anorexia)
Алгоритм сжатия предохраняет от частых, дорогих по времени вызовов операционной системы - выделить или возвратить память. Вместо возвращения всех освобожденных блоков он сохраняет некоторые из них для построения небольшого резерва памяти, доступной приложению без обращения к операционной системе.
Эта техника крайне полезна для часто встречающегося класса приложений с повышенным чувством голода и потерей аппетита, у которых период кутежа с массовым созданием объектов сменяется постом, в течение которого происходит избавление от ненужных объектов; затем все повторяется.
Практические проблемы сборки мусора
Среда исполнения, обеспечивающая управление памятью, должна не только использовать хороший алгоритм сборки мусора, но и поддерживать несколько свойств, которые, хотя и не главные в теории управления памятью, являются существенными для практического использования среды.
Проблема надежности
Допустим, разработчик управляет утилизацией объектов с помощью механизма reclaim. Возможность ошибочного вызова reclaim всегда существует; особенно при наличии сложных структур данных. В жизненном цикле ПО reclaim, бывшее когда-то правильным, может стать некорректным.
Такие ошибки приводят к проблеме висячих ссылок, - когда в одном из полей существующего объекта хранится ссылка на удаленный объект. Если система, после того как область памяти, занимаемая этим объектом, была утилизирована и использована для хранения другой информации, попытается использовать ссылку, то результатом будет крах программы или (еще хуже) ее ошибочное или неуправляемое поведение.
Этот тип ошибки известен, как источник появления самых частых и неприятных жучков в практике языка С и производных языков. Программисты боятся таких жучков из-за трудности обнаружения их источника. Если программист не заметил, что определенная ссылка еще присоединена к объекту и как результат - ошибочно выполняет reclaim, то это часто происходит из-за того, что ссылка находится в другой части программы. Если так, то должна быть большая физическая и концептуальная дистанция между ошибкой - вызовом reclaim и ее проявлением - крах или другое ненормальное поведение из-за попытки применения некорректной ссылки. Проявиться ошибка может значительно позже и, по-видимому, совсем в другой части программы. К тому же, ошибка может быть плохо воспроизводимой, поскольку распределение памяти операционной системой не всегда происходит одинаково и может зависеть от внешних по отношению к программе факторов.
Сказать, что причиной этих ошибок является "плохой стиль программирования", как в письме, упомянутом выше, это не сказать ничего. Человеку свойственно ошибаться; ошибки при программировании неизбежны. Даже в приложениях средней сложности, нет разработчиков, которым можно доверять, нельзя доверять самому себе в способности проследить за всеми объектами периода выполнения. Это работа не для человека, с ней может справиться только компьютер.
Многие из С или С++ программистов ночи проводят, пытаясь понять, что произошло с одной из их игрушек. Нередко, что проект задерживается из-за загадочных ошибок при работе с памятью.
Проблема простоты разработки
Даже если можно было бы избежать ошибочных вызовов reclaim, остается вопрос - сколь реально просить разработчиков управлять удалением объектов? Загвоздка в том, что даже при обнаружении объекта, подлежащего утилизации, обычно просто удалить его недостаточно, он может сам содержать ссылки на другие объекты и нужно решить, что с ними делать.
Рассмотрим структуру, показанную на рис.9.10, ту же, что использовалась в предыдущей лекции для описания динамической природы объектных структур. Допустим, выяснилось, что можно утилизировать самый верхний объект. Тогда в отсутствии каких-либо других ссылок можно удалить и другие два объекта, на один из которых он ссылается прямо, а на другой - косвенно. Не только можно, но и нужно: разве хорошо удалять только часть структуры? В терминологии Pascal это иногда называется рекурсивной проблемой удаления: если операции утилизации имеют смысл, они должны быть рекурсивно применены ко всей структуре данных, а не только к одному индивидуальному объекту. Но конечно, необходимо быть уверенным, что на объекты удаляемой структуры нет ссылок из внешних объектов. Это трудная и чреватая ошибками задача.

Рис. 9.10. Прямые и косвенные взаимные ссылки
На этом рисунке все объекты одного типа PERSON1. Предположим, что сущность x присоединена к объекту О типа MY_TYPE , объявленным как класс:
class MY_TYPE feature attr1: TYPE_1 attr2: TYPE_2 end
Каждый объект типа MY_TYPE, такой как О, содержит две ссылки, которые (кроме void) присоединены к объектам типа TYPE_1 и TYPE_2. Утилизация О может предполагать, что эти два объекта тоже должны быть утилизированы, также как и зависимые от них объекты. Выполнение рекурсивной утилизации, в этом случае, предполагает написание множества процедур утилизации, - по одной для каждого типа объектов, которые, в свою очередь, могут содержать ссылки на другие объекты. Результатом будет множество взаимно рекурсивных процедур большой сложности.
Все это ведет к катастрофе. Нередко, в языках, не поддерживающих автоматическую сборку мусора, в приложения включаются специально разработанные системы управления памятью. Такая ситуация неприемлема. Разработчик приложения должен иметь возможность сконцентрироваться на своей работе, а не стать счетоводом или сборщиком мусора.
Возрастающая сложность программы из-за ручного управления памятью приводит к падению качества. В частности, она затрудняет читаемость и такие свойства как простота обнаружения ошибок и легкость модификации. В результате, к сложности конструкции добавляется проблема надежности. Чем сложнее система, тем больше вероятность содержания ошибок. Дамоклов меч ошибочного вызова reclaim всегда висит над головой и, скорее всего, упадет в наихудшее время: когда система пройдет тестирование и начнет использоваться, создавая большие и замысловатые структуры объектов.
Вывод очевиден. Кроме жестко контролируемых ситуаций (рассмотренных в следующем разделе), ручное управление памятью не подходит для разработки серьезных систем, как минимум, по соображениям качества.
Проблема управления памятью в ОО-модели
Подводя итог предшествующего анализа, определим оригиналы и соответственно достижимые объекты:
Определение: начальные, достижимые и недостижимые объекты
В каждый момент времени выполнения системы множество оригиналов включает:
Корневой объект системы.Любой объект, присоединенный к локальной сущности, или формальному аргументу, выполняемой в данный момент подпрограммы (для функции включается локальная сущность Result).
Любые объекты, прямо или косвенно зависящие от оригиналов, достижимы. Любые другие объекты недостижимы. Память, занятую недостижимыми объектами можно восстановить, (например, выделить ее другим объектам) сохраняя корректность семантики выполнения программы.
Проблема управления памятью возникает из-за непредсказуемости операций, влияющих на множество достижимых объектов: создание и отсоединение.
Такое предсказание возможно в некоторых случаях для строго управляемых структур данных. Примером является библиотечный класс, задающий список, - LINKED_LIST, рассматриваемый позже, и связанный с ним класс LINKABLE, описывающий элементы этого списка. Экземпляр LINKABLE создается только с помощью специальных процедур класса LINKED_LIST и может становиться недостижимым только в результате выполнения процедуры remove, удаляющей элементы списка. Для подобных классов можно представить себе особенную процедуру управления памятью. (Такой подход будет изучен позднее в этой лекции.)
Приведенный пример, хотя и важен, но только для специальных случаев. В общем случае приходится отвечать на сложный вопрос - что делать с недостижимыми объектами?
Продвинутый (Advanced) подход к сборке мусора
Хороший сборщик должен обеспечивать хорошую производительность, работая как постоянно, так и в стартстопном режиме, становясь приемлемым для интерактивных приложений и даже для систем реального времени.
Отсюда первое требование - необходимо дать возможность разработчикам управлять запуском и выключением циклов работы сборщика. В частности, библиотеки должны предоставлять процедуры:
collection_off collection_on collect_now
Вызов первой прекращает циклическую работу по сборке мусора до особого распоряжения; второй - включает сборщик, восстанавливая нормальное состояние работы; третьей - заставляет сборщик немедленно выполнить полный цикл работы. Пусть некоторая система содержит критический по времени выполнения раздел, в котором не должно быть никаких непредсказуемых временных задержек. В этом случае разработчик может вызвать collection_off в начале этого раздела и collection_on в его конце; в любой другой точке, где приложение работает вхолостую (например, во время ввода или вывода), можно запустить collect_now.
Более продвинутая техника, используемая в большинстве современных сборщиков мусора, известна как сборка мусора поколений (generation scavenging). Она исходит из следующего наблюдения: чем больше циклов сборки мусора объект пережил, тем больше вероятность, что он доживет до следующего цикла или всегда будет достижимым. Отсюда принцип работы сборщика мусора: "старые объекты оставляй нетронутыми". Сборщику полезна любая информации, позволяющая сканировать определенные категории объектов реже, чем остальные. Сборка мусора поколений обнаруживает объекты, существующие более чем определенное количество циклов. Такие объекты получают статус постоянной должности (tenuring) по аналогии с механизмом, защищающим экземпляры класса реальной жизни PROFESSOR, прошедших несколько циклов переизбрания и получивших, наконец, постоянную позицию. Объекты-долгожители будут рассматриваться отдельным сборщиком, работающим реже, чем сборщик "молодых" объектов.
Практическая реализация сборки мусора поколений имеет много вариаций. В частности, обычно делят объекты не только на молодые и старые, но на большее число поколений с разными стратегиями сборки мусора различных поколений.
Работа с утилизированными объектами
Для реализации fresh и recycle, можно среди других возможных вариантов представить available как стек: fresh будет удалять элемент из стека, а recycle будет помещать элемент в стек. Создадим класс STACK_OF_LINKABLES для этого случая и добавим следующие закрытые компоненты в класс LINKED_LIST (В упражнении У23.1. требуется определить, будет ли корректным появление у функции fresh побочных эффектов.):
available: STACK_OF_LINKABLES fresh (v: ELEMENT_TYPE): LINKABLE is - Новый элемент со значением v, для повторного - использования во вставке do if available.empty then - Создание нового элемента create Result.make (v) else - Повторное использование linkable Result := available.item; Result.put (v); available.remove end end recycle (dead: LINKABLE) is -Возвращает dead в список достижимых элементов. require dead /= Void do available.put (dead) end
Мы можем объявить класс STACK_OF_LINKABLES следующим образом:
class STACK_OF_LINKABLES feature {LINKED_LIST} item: LINKABLE - Элемент в вершине стека empty: BOOLEAN is - нет элементов в стеке? do Result := (item = Void) end put (element: LINKABLE) is - Добавить элемент в вершину стека. require element /= Void do element.put_right (item); item := element end remove is - Удалить последний добавленный элемент. require not empty do item := item.right end end

Рис. 9.13. STACK_OF_LINKABLES
Представление стека использует все преимущества поля right, присутствующего в каждом элементе LINKABLE, связывая все утилизированные элементы и предоставляя, тем самым, дополнительную память для размещения новых элементов списка LINKED_LIST. Класс LINKABLE должен экспортировать свои компоненты right и put_right в класс STACK_OF_LINKABLES.
Компонент available является атрибутом класса. Это означает, что каждый связный список будет иметь свой собственный стек. Конечно, память можно было бы использовать эффективнее в системе, содержащей несколько списков и единственный стек для всех удаленных элементов. Такая техника однократных функций (once functions), будет представлена позже; применение ее для available означает, что только один экземпляр класса STACK_OF_LINKABLES будет существовать до конца выполнения системы, что означает достижение поставленной цели. ( Упражнение У9.3. и У9.4. Об однократных функциях см. лекцию 18)
Сборка мусора
Наиболее общей и полностью удовлетворительной техникой является лишь автоматическая сборка мусора или просто сборка мусора.
Сборка мусора и внешние вызовы
Хорошо спроектированная ОО-среда со сборкой мусора должна решать еще одну практическую проблему. Во многих случаях ОО-программы взаимодействуют с программами, написанными на не ОО-языках. В следующих лекциях будет рассмотрено, как лучше обеспечить такое взаимодействие. (См. "Взаимодействие с не ОО-программой", лекцию 13)
Если ПО включает вызовы подпрограмм, написанных на других языках (называемых далее внешними программами), возможно, этим подпрограммам необходимо будет передавать ссылки на объекты. Это потенциально опасно для управления памятью. Предположим, что внешняя подпрограмма имеет следующий вид (преобразованная в соответствии с синтаксисом языка внешней программы):
r (x: SOME_TYPE) is do ... a := x ... end
где a сущность, сохраняющая значение между последовательными вызовами r. Например, а может быть глобальной или статической переменной в традиционных языках, или атрибутом класса в нашей ОО-нотации. Рассмотрим вызов r(y), где y связан с некоторым объектом О1. Возможно, что через некоторое время после вызова, О1 становится недостижимым в объектной части нашей программы, но ссылка на него (от сущности a) остается во внешней программе. Сборщик мусора может - и в конце концов должен - утилизировать О1, но в данном случае это неправильно.
Для таких ситуаций необходимы процедуры, вызываемые из внешней программы, которые защитят нужный объект от сборщика. Эти процедуры могут быть названы:
adopt (a) - усыновлять wean (a) - отнимать от груди, отлучать
и должны быть частью интерфейса любой библиотеки, обеспечивающей взаимодействие ОО-программ и внешних программ. В следующем разделе описан подобный механизм для языка С. "Усыновление" объекта забирает его из области действия механизма утилизации; "отлучение" - возвращает возможность утилизации.
Передача объектов в не ОО-языки и удерживание ссылки на них внешней программой - дело рискованное. Но избежать этого возможно не всегда. Например, ОО-проект нуждается в специальном интерфейсе между ОО-языком и имеющейся системой управления БД. В этом случае, можно разрешить внешней программе сохранять информацию об объектах. Такие низкоуровневые манипуляции никогда не должны появляться в нормальном программном продукте. Они должны содержаться в обслуживающем классе, написанном с единственной целью - скрыть детали от остальной части программы и защитить ее от возможных неприятностей.
Сборка по принципу "все-или-ничего"
Когда нужно приводить в действие сборщик мусора?
Классические сборщики мусора активизируются по требованию и работают до завершения. Другими словами, сборщик мусора не работает, пока остается память для работы приложения. Как только ее не хватает, приложение запускает полный цикл сборки мусора - фаза пометки и следом фаза чистки.
Эта техника может быть названа "все-или-ничего". Преимущество ее в том, что она не вызывает перегрузки пока достаточно памяти. Когда программа выходит за пределы достижимых ресурсов, в наказание вызывается сборщик мусора.
Но сборка мусора по принципу "все-или-ничего" имеет серьезный недостаток: полный цикл пометки-чистки может занять много времени - особенно в среде виртуальной памяти, большое пространство виртуальных адресов которого сборщик мусора должен обойти полностью, прерывая на это время выполнение приложения.
Для пакетных приложений такая схема еще может быть приемлема. Но и здесь при высоком коэффициенте отношения виртуальной памяти к реальной перегрузка может стать причиной серьезной потери производительности, если система создает большое число объектов, лишь малая часть из которых является в каждый момент достижимыми.
Сборка мусора по принципу "все-или-ничего" не будет работать для интерактивных систем или систем реального времени. Представим систему обнаружения ракетного нападения, которая имеет 50-миллисекундный интервал для реагирования на запуск ракеты. Допустим, программа прекрасно работала, пока система не вышла за пределы памяти, но, к несчастью это событие произошло в момент запуска ракеты, когда вместо системы начал свою работу неспешный сборщик мусора.
Даже в менее жизненно важных приложениях, таких как интерактивные системы, неприятно использовать инструмент, например, редактор текста, который иногда непредсказуемо зависает на 10 минут, потому что у него начался цикл сборки мусора.
В таких случаях проблема заключается не в глобальном эффекте временных потерь, связанных со сборкой мусора: определенная потеря производительности может быть вполне допустимой для разработчиков и пользователей, как плата за надежность и удобство, предоставляемое автоматической сборкой мусора.
Но временные потери должны быть равномерно распределены. Неприемлемы непредсказуемые всплески активности сборщика мусора. Лучше черепаха, чем заяц, время от времени без предупреждения засыпающий на полчаса. Подсчет ссылок, если бы не его фатальный порок, удовлетворял бы лозунгу: "лучше ехать медленно, но с постоянной скоростью, чем быстро, но с неожиданными и непредсказуемыми остановками".
Конечно, временные потери должны быть не только постоянными, но и небольшими. Если приложение без сборщика мусора - заяц, никто не согласится заменить его черепахой. Хороший сборщик мусора должен обеспечивать задержку, не превышающую 5-15%. Хотя некоторые скажут, что и это неприемлемо, я знаю совсем немного приложений, которым нужны меньшие издержки. Необходимо учитывать также, что в отсутствии сборщика мусора потребуется ручная утилизация, также не обходящаяся без издержек. Несмотря на все издержки, сборка мусора необходима.
В ходе обсуждения выявлены две дополнительные проблемы эффективности работы сборщика мусора: производительность глобальная (overall performance) и в стартстопном режиме (incrementality).
Сложные проблемы
Сборщик мусора сталкивается со следующими проблемами, вызванными практическими ограничениями на размещение объектов в современной ОО-среде:
ОО-подпрограммы могут вызывать внешние программы, в частности, С-функции, которые могут, в свою очередь, размещать нечто в памяти. Поэтому нужно рассматривать два различных вида памяти: память для объектов и внешнюю память. Объекты создаются по-разному. Массивы и строки имеют переменный размер; экземпляры других классов имеют фиксированный размер. Наконец, как отмечалось, недостаточно освобождать память для повторного использования в самом ОО-приложении, - нужно возвращать ее навсегда операционной системе.
По этим причинам размещение объектов в памяти не может полагаться на стандартный системный вызов malloc, который, наряду с другими ограничениями, не возвращает память операционной системе. Вместо этого среда запрашивает у ядра операционной системы участки памяти и распределяет объекты в этих участках с помощью собственных механизмов.
Создание объектов
Мы рассмотрели базовые операции размещения новых объектов. Простейший способ размещения записывается как
create x
и его эффект был определен триадой: создать новый объект; связать его со ссылкой x; и инициализировать его поля.
Вариант этой инструкции вызывает процедуру инициализации; можно также создать новый объект с помощью подпрограмм clone и deep_clone. Так как все эти формы размещения основаны на одной и той же базисной инструкции создания, можно без потери общности ограничиться рассмотрением create x .
Рассмотрим эффект, создаваемый инструкциями управления памятью.
Три режима управления объектами
Во-первых, будет полезным расширить рамки дискуссии. Форма управления объектами, используемая для ОО-вычислений, может поддерживаться одним из трех обычно встречаемых режимов: статическим, стековым и динамически распределяемым. Выбор режима определяет, как сущности присоединяются к объектам.
| Напомним, что сущность - это имя в тексте программы, представляющее некоторое значение или совокупность значений в период выполнения. Такие значения являются либо объектами, либо (возможно неопределенными) ссылками на объект. Сущностями являются атрибуты, формальные аргументы подпрограмм, локальные переменные подпрограмм и Result. Термин присоединение описывает связь между сущностью и объектом: на определенном этапе выполнения программы сущность x присоединяется к объекту О, если значение x есть либо О (для x развернутого типа), либо ссылка на О (для x ссылочного типа). Если x присоединен к О, часто говорят также, что О присоединен к x. Ссылка может быть присоединена не более чем к одному объекту, объект может быть присоединен к двум и более ссылкам. Проблема динамических псевдонимов обсуждалась в предыдущей лекции. |
В статическом режиме сущность может быть присоединена максимум к одному объекту в процессе выполнения программы. Эта схема, поддерживаемая в таких языках как Fortran, резервирует место для всех объектов и присоединяет объект к имени раз и навсегда при загрузке программы или в начале ее выполнения.

Рис. 9.1. Статический режим
Статический режим прост и эффективно реализуем архитектурой обычного компьютера. Но он имеет серьезные ограничения:
Препятствует рекурсии. Рекурсивной программе необходимо иметь несколько одновременно активных копий, каждой со своими экземплярами сущностей. Препятствует созданию динамических структур данных. Компилятор должен уметь определять точный размер каждой структуры данных из текста программы. Каждый массив, например, должен в этом случае объявляться статично со своим строгим размером. Это серьезно ограничивает мощность языка: становится невозможным оперировать структурами, растущими в ответ на события выполнения. Приходится резервировать максимально возможную память для каждой из структур - это не только неэффективно, но и довольно опасно. Если размер одной из структур данных недооценен, это, скорее всего, вызовет ошибку выполнения системы.
Второй режим размещения объектов - режим стека. Здесь сущность может быть в реальном времени последовательно присоединяться к нескольким объектам. Механизм выполнения размещает и удаляет эти объекты в порядке "последним пришел, первым ушел". Когда объект удаляется, относящаяся к нему сущность присоединяется вновь к объекту, с которым она была связана до появления нового элемента, если, конечно, такой объект существует.

Рис. 9.2. Режим, основанный на стеке
Основанное на стеке управление объектами сделало популярным Algol 60 и с тех пор поддерживается (часто вместе с другими двумя режимами) в большинстве языков. Такой способ поддерживает рекурсию и динамические массивы, границы которых выясняются в процессе выполнения. В Pascal и C этот механизм не применяется к массивам, как это делается в Algol. Однако разработчикам хотелось бы чаще всего именно массивы распределять таким способом. Тем не менее, даже если этот механизм и может быть применен к массивам, размещение в стеке большинства сложных структур данных невозможно.1)
Для сложных структур данных нам нужен третий и последний режим: динамическая память, называемая также "кучей", из-за способа ее использования.Это память, в которой объекты создаются динамически по запросу. Сущности могут динамически присоединяться к разным объектам. Во время компиляции обычно нельзя предсказать, какие объекты будут созданы и присоединены к сущности. Кроме того, объекты могут содержать ссылки на другие объекты.

Рис. 9.3. Динамический режим
Динамическая память позволяет создавать сложные динамические структуры данных, необходимые когда, как обсуждалось в предыдущей лекции, ПО требуется вся мощь методов моделирования.
Среда с управлением памятью
В заключение рассмотрим, не вдаваясь в детали, как одна специфическая среда, представленная более широко в последней лекции этой книги, управляет памятью. Это даст пример практического, реально достижимого подхода к проблеме.
Три ответа
С недостижимыми объектами можно поступать тремя способами:
Проигнорировать проблему и надеяться, что хватит памяти для размещения всех объектов: достижимых и недостижимых. Это можно назвать несерьезным (casual) подходом.Предложить разработчикам включать в каждое приложение алгоритм, ищущий недостижимые объекты, и дать им механизм освобождения соответствующей памяти. Такой подход называется восстановлением вручную(manual reclamation) .Включить в среду разработки (как часть исполняемой системы (runtime system)) механизм, автоматически определяющий и утилизирующий недостижимые объекты. Этот подход принято называть автоматической сборкой мусора (automatic garbage collection).
Остаток лекции посвящен этим подходам.
У9.1 Модели создания объектов
При обсуждении автоматического управления памятью рассмотрен подход, основанный на создании внутренних списков свободной памяти. В этом случае память, занимаемая утилизированными объектами, не возвращается операционной системе, а остается в создаваемом списке. Разработайте модель системы, демонстрирующую постоянный рост занимаемой памяти, хотя фактически требуемая приложению память ограничена.
Вы можете описать эту модель как последовательность о1, о2, о3,..., где оi либо 1, (что показывает выделение памяти одному объекту), либо (-n), показывающее восстановление n единиц памяти.
У9.2 Какой уровень утилизации?
Подход на уровне компонентов, если программировать на языке типа Pascal или C, где операционная система предоставляет dispose или free, может напрямую использовать эти операции вместо создания своего списка свободной памяти для каждого типа структур данных. Рассмотрите плюсы и минусы двух подходов.
У9.3 Совместное использование стека достижимых элементов
(Это упражнение подразумевает знакомство с результатами лекции 18) Перепишите компонент available, задающий стек достижимых элементов при подходе на уровне компонентов. Единственный стек должен совместно использоваться всеми связными списками одного и того же типа. (Указание: используйте функцию once.)
У9.4 Совместное использование
(Это упражнение подразумевает, что вы выполнили предыдущее и прочитали все лекции, включая лекцию 18) Можно ли сделать available стек разделяемым всеми связными списками произвольных типов?
 |
|
|
1)
Динамические массивы могут создаваться в языке С, используя функцию mallok - механизм, подобный денамическому распределению, описываемому ниже; некоторые расширения Pascal поддерживают динамические массивы.
Удаление объектов, управляемое программистом
Одно популярное решение - обнаружение мертвых элементов возложить на разработчика программы, а восстановление памяти решать на уровне реализации языка.
Это простейшее решение для реализаторов языка: все, что от них требуется, - это ввести в язык примитив, скажем, reclaim, такой что a.reclaim сообщает системе, что объект, присоединенный к a, не нужен, и соответствующие ячейки памяти можно освободить для новых объектов.
Это решение реализовано в не ОО-языках, таких как Pascal (dispose процедура), C (free), PL/I (FREE), Modula-2 и Ada. Оно есть в большинстве 'гибридных ОО" языков, в частности в C++.
Такое решение особенно приветствуется в мире С-программистов, любящих полностью контролировать происходящее. Обычная реакция таких программистов на тезис о том, что Objective-C может давать преимущества, благодаря автоматическому восстановлению памяти, следующая:
Я говорю, НЕТ! Оставлять недостижимые объекты - ПЛОХОЙ СТИЛЬ ПРОГРАММИРОВАНИЯ. Если вы создаете объект, вы должны отвечать за его уничтожение, если вы им не пользуетесь. Разве мама не учила вас убирать свои игрушки после игры? (Послано Яном Стефенсоном (Ian Stephenson), 11 мая1993.)
Для серьезной разработки программ эта позиция не позволительна. Хорошие разработчики должны разрешать кому-либо другому играть со своими "игрушками" по двум причинам: надежности и простоты разработки.
Управление памятью связного списка
Приведем пример подхода на уровне компонентов. Рассмотрим класс LINKED_LIST, описывающий список, состоящий из заголовка (header) и набора связанных ячеек, являющихся экземплярами класса LINKABLE. Модель размещения и удаления для связного списка проста. Объектами рассмотрения являются связанные ячейки. В этом примере производители компонентов (люди, отвечающие за классы LINKED_LIST и LINKABLE) знают точно, как создаются и как становятся "мертвыми" экземпляры класса LINKABLE - процедурами вставки и удаления. Поэтому они могут управлять соответствующей памятью особенным способом.
Допустим, класс LINKED_LIST имеет только две процедуры вставки: put_right и put_left, вставляющие новый элемент справа или слева от текущей позиции курсора. Каждой процедуре вставки необходимо создать ровно один новый LINKABLE объект. Типичная реализация приведена ниже:
put_right (v: ELEMENT_TYPE) is - Вставка элемента со значением v правее позиции курсора. require ... local new: LINKABLE do create new.make (v) active.put_linkable_right (new) ... Инструкции по изменению других связей... end

Рис. 9.11. Связный список
Инструкция создания create new.make (v) дает указание уровню реализации языка разместить в памяти новый объект.
Точно так же, как мы управляем тем, где создавать объекты, мы точно знаем, где они становятся недостижимыми, - в процедурах удаления. Пусть в нашем классе три такие процедуры: remove, remove_right, remove_left. Могут быть также и другие процедуры, такие как remove_all_occurrences (которая удаляет все экземпляры с определенным значением) и wipe_out (удаляет все элементы списка). Допустим, что если они присутствуют, то используют первые три процедуры удаления. Процедура remove, например, может иметь следующую форму:
remove is - удаляет элемент текущей позиции курсора. do ... previous.put_linkable_right (next) ... Инструкции по изменению других связей... active := next end
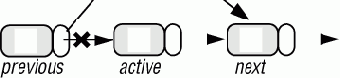
Рис. 9.12. Удаление объекта
Эти процедуры удаления представляют точный контекст обнаружения недостижимых объектов и, при желании, предоставят эти объекты для последующего использования.
В отсутствие какой- либо автоматической схемы освобождения памяти разработчик компонентов может безопасно резервировать освобождающуюся память. Если предыдущее удаление создало недостижимые LINKABLE объекты и разместило их где-то для последующего использования, то можно их использовать, когда вставка требует создания новых элементов.
Предположим, экземпляры LINKABLE хранятся в структуре данных, называемой available. Она будет представлена ниже. Тогда можно заменить инструкции создания типа create new.make (v) в put_right и put_left на
new := fresh (v)
где fresh закрытая функция класса LINKED_LIST, возвращающая готовый к использованию экземпляр linkable. Функция fresh пытается получить память из available списка, и выполнит создание нового элемента только, когда этот список пуст.
Элементы будут попадать в available в процедурах удаления. Например, тело процедуры remove теперь должно быть:
do recycle (active) - остальное без изменений: ... Инструкции по обновлению связей: previous, next, first_element, active...
где recycle новая процедура LINKED_LIST играет роль, противоположную fresh, добавляя свой аргумент в available. Эта процедура будет закрытой, она нужна только для внутреннего использования.
Восстановление памяти: проблемы
Если уйти от несерьезного подхода и его упрощающих допущений, то предстоит решить, как и когда восстанавливать память. Возникают две проблемы:
Обнаружение (detection). Как найти мертвые элементы?Восстановление (reclamation). Как восстановить для повторного использования память, присоединенную к этим элементам?
Для каждой из этих задач можно искать решение на одном из двух возможных уровнях:
Реализации языка - компилятор и среда исполнения обеспечивают общую поддержку любому ПО, создаваемому на этом языке и в данной среде.Приложения - приложение само решает возникающие проблемы.
В первом случае управление выделенной памятью происходит автоматически с помощью программно-аппаратных средств. Во втором случае каждый разработчик приложения должен позаботиться об этом сам.
Фактически, существует еще третий возможный уровень, нечто среднее между этими двумя, - фабрика компонентов. Функции управления памятью возлагаются на общецелевые повторно используемые классы библиотеки ОО-среды. Подобно уровню приложения, можно использовать только разрешенные конструкции языка программирования, не имея прямого доступа к аппаратуре и функциям операционной системы. Подобно уровню реализации языка, проблемы управления памятью решаются один раз и для всех приложений.
Даны две проблемы и три способа решения каждой, в итоге - девять возможных вариантов. Только четыре из них имеют практический смысл. Рассмотрим их.
