Библиографические замечания
В методе проектирования, известном как "структурное проектирование" [Yourdon 1979], особое значение придается важности использования модульных структур. Этот метод был основан на анализе "сцепления" и "связности" модулей. Но неявно выраженное представление модулей в структурном проектировании было основано на традиционном понятии подпрограммы, что ограничило рамки обсуждения. Принцип унифицированного доступа был первоначально предложен (под названием "унифицированная ссылка") в работе [Geschke 1975]. При обсуждении унифицированного доступа упоминался язык Algol W, преемник языка Algol 60 и предшественник языка Pascal (в котором были предложены некоторые интересные механизмы, не сохранившиеся в Pascal'е), разработанный Виртом и Хоаром, и описанный в работе [Hoare 1966].
Скрытие информации было предложено в двух основополагающих статьях Дэвида Парнаса [Parnas 1972] [Parnas 1972a].
Средства управления конфигурацией, которые будут перекомпилировать модули, затронутые изменениями в других модулях, исходя из подробного списка зависимостей между модулями, основаны на концепциях сервисной программы Make, первоначально разработанной для Unix [Feldman 1979]. Современные сервисные программы - а их имеется много на рынке программных средств - существенно дополнили функциональность основных идей.
В некоторых из приводимых ниже упражнений предлагается разработать метрики для количественной оценки различных неформальных критериев модульности, сформулированных в этой лекции. Некоторые результаты, относящиеся к ОО-метрикам, содержатся в работах Кристины Минджинс (Christine Mingins) [Mingins 1993] [Mingins 1995] и Брайана Хендерсон-Селлерса (Brian Henderson-Sellers) [Henderson-Sellers 1996a].
Декомпозиция
Метод проектирования удовлетворяет критерию Декомпозиции, если он помогает разложить задачу на несколько менее сложных подзадач, объединяемых простой структурой, и настолько независимых, что в дальнейшем можно отдельно продолжить работу над каждой из них.
Такой процесс часто будет циклическим, поскольку каждая подзадача может оказаться достаточно сложной и потребует дальнейшего разложения.

Рис. 3.1. Декомпозиция
Следствием требования декомпозиции является разделение труда (division of labor): как только система будет разложена на подсистемы, работу над ними следует распределить между разными разработчиками или группами разработчиков. Это трудная задача, так как необходимо ограничить возможные взаимозависимости между подсистемами:
Необходимо свести такие взаимозависимости к минимуму; в противном случае разработка каждой из подсистем будет ограничиваться темпами работы над другими подсистемами. Эти взаимозависимости должны быть известны: если не удастся составить перечень всех связей между подсистемами, то после завершения разработки проекта будет получен набор элементов программы, которые, возможно, будут работать каждая в отдельности, но не смогут быть собраны вместе в завершенную систему, удовлетворяющую общим требованиям к исходной задаче.
Наиболее очевидным примером обсуждаемого метода1), удовлетворяющим критерию декомпозиции, является метод нисходящего (сверху вниз) проектирования (top-down design). В соответствии с этим методом разработчик должен начать с наиболее абстрактного описания функции, выполняемой системой. Затем последовательными шагами детализировать это представление, разбивая на каждом шаге каждую подсистему на небольшое число более простых подсистем до тех пор, пока не будут получены элементы с настолько низким уровнем абстракции, что становится возможной их непосредственная реализация. Этот процесс можно представить в виде дерева.

Рис. 3.2. Иерархия нисходящего проектирования
Типичным контрпримером (counter-example) является любой метод, предусматривающий включение в разрабатываемую систему модуля глобальной инициализации.
Многие модули системы нуждаются в инициализации - открытии файлов или инициализации переменных.
Каждый модуль должен произвести эту инициализацию до начала выполнения непосредственно возложенных на него операций. Могло бы показаться, что все такие действия для всех модулей системы неплохо сосредоточить в одном модуле, который проинициализирует сразу все для всех. Подобный модуль будет обладать хорошей "согласованностью во времени" (temporal cohesion) в том смысле, что все его действия выполняются на одном этапе работы системы. Однако для получения такой "согласованности во времени", придется нарушать автономию других модулей. Придется модулю инициализации дать право доступа ко многим структурам данных, принадлежащим различным модулям системы и требующим специфических действий по их инициализации. Это означает, что автор модуля инициализации должен будет постоянно следить за структурами данных других модулей и взаимодействовать с их авторами. А это несовместимо с критерием декомпозиции.
Термин "согласованность во времени" пришел из метода, известного как структурное проектирование (см. комментарии к библиографии).
| В объектно-ориентированном методе каждый модуль должен самостоятельно инициализировать свои структуры данных. |
Единственный Выбор
Последний из пяти принципов модульности можно считать следствием как принципа Открыт-Закрыт, так и правила Скрытия Информации.
Прежде чем подробно ознакомиться с принципом Единственного Выбора, рассмотрим типичный пример. Предположим, что создается система для работы с библиотекой (в не-программистском смысле слова: с множеством книг и других изданий, а не модулей программы). Эта система будет обрабатывать структуры данных, представляющие различные публикации. Можно объявить соответствующий тип в синтаксисе языков Pascal-Ada:
type PUBLICATION = record author, title: STRING; publication_year: INTEGER case pubtype:(book, journal, conference_proceedings) of book:(publisher: STRING); journal:(volume, issue: STRING); proceedings:(editor, place: STRING) -- Conference proceedings end
Здесь использован "тип записи с вариантами" (record type with variants) для описания наборов структур данных с полями, одни из которых (в этом примере author, title, publication_year) являются общими во всех случаях, а другие - характерны для частных вариантов данных.
| Использование конкретной синтаксической конструкции здесь не является существенным. Языки программирования Algol 68 и C обеспечивают такую же возможность с помощью типа "объединение" (union). Тип union это тип T, определен как объединение ранее существовавших типов A, B,:: значение типа T это либо значение типа A, либо значение типа B,: . Достоинством типов записей с вариантами является то, что в них с каждым вариантом явно связан некоторый ярлык (tag), например book, journal, conference_proceedings. |
Пусть A - модуль, который содержит описанное выше объявление типа. Пока модуль A считается открытым, к нему можно добавлять поля или вводить в него новые варианты. Но когда модуль A передается клиентам, следует закрыть его, а это по умолчанию означает, что в нем уже перечислены все существенные поля и варианты. Итак, пусть B это типичный клиент модуля A. B будет манипулировать с публикациями через некоторую переменную, например:
p: PUBLICATION
Чтобы с помощью p осуществлять какие- либо полезные действия, необходимо явно выделить различные случаи:
case p of book:... Instructions which may access the field p.publisher... journal:... Instructions which may access fields p.volume, p.issue... proceedings:... Instructions which may access fields p.editor, p.place... end
Здесь оказалась удобной команда выбора case из языков Pascal и Ada; ее синтаксис воспроизводит определение типа записи с вариантами. В Fortran'е и C это может имитироваться многократным использованием команды безусловного перехода goto (switch в языке C). В этих и других языках такой же результат можно получить, используя вложенные команды условного перехода (if ... then ... elseif ... elseif ... else ... end).
Следует отметить, что, независимо от используемой синтаксической конструкции, для осуществления такого выбора каждый модуль-клиент должен знать полный список вариантов представления для публикации, поддерживаемых модулем A. Последствия этого нетрудно предвидеть. Наступит момент, когда потребуется новый вариант, например технические отчеты фирм и университетов. Тогда необходимо расширить определение типа PUBLICATION в модуле A, учитывающее новый случай. Это вполне логично и неизбежно: если было изменено определение понятия публикации, то следует обновить и соответствующее объявление типа. Однако значительно труднее найти оправдание другому следствию: любой клиент модуля A, такой как B, также будет требовать обновления, если в нем использовалась рассмотренная выше структура, основанная на полном списке случаев для p. А это, очевидно, будет иметь место для большинства клиентов.
Итак, наблюдаются очень опасные изменения в программе: простое и естественное дополнение может вызвать цепную реакцию изменений во многих модулях-клиентах.
Эта проблема возникнет всякий раз, когда некоторое понятие допускает множество вариантов. Здесь таким понятием было "публикация" ("publication"), а его начальными вариантами были: книга (book), журнальная статья (journal article), труды конференции (conference proceedings); другими типичными примерами могут быть:
В системе работы с графикой: понятие фигуры (figure), с такими вариантами как многоугольник (polygon), окружность (circle), эллипс (ellipse), отрезок (segment) и другие основные виды фигур. В текстовом редакторе: понятие команды пользователя (user command), с такими вариантами как вставка строки (line insertion), удаление строки (line deletion), удаление символа (character deletion), глобальная замена (global replacement) одного слова другим. В компиляторе для языка программирования: понятие языковой конструкции (language construct), с такими вариантами как команда (instruction), выражение (expression), процедура (procedure).
В любом таком случае необходимо допускать возможность того, что список вариантов, заданных и известных на некотором этапе разработки программы, может в последующем быть изменен путем добавления или удаления вариантов. Чтобы обеспечить реализацию такого подхода к процессу разработки программного обеспечения, нужно найти способ защитить структуру программы от воздействия подобных изменений. Отсюда следует принцип Единственного Выбора:
Принцип Единственного Выбора
Всякий раз, когда система программного обеспечения должна поддерживать множество альтернатив, их полный список должен быть известен только одному модулю системы.
Требование того, чтобы список выбора был известен лишь одному модулю, обеспечивает подготовку к последующим изменениям: при добавлении вариантов понадобится произвести обновление только того модуля, в котором содержится эта информация - такова сущность единственного выбора. А все остальные модули, в частности - его клиенты, смогут продолжать свою работу как обычно.
Таким образом, как показывает пример с библиотекой публикаций, традиционные методы не обеспечивают решения проблемы, в то время как объектные технологии позволят получить ее решение благодаря двум методическим приемам, связанным с наследованием: полиморфизмом (polymorphism) и динамическим связыванием (dynamic binding). Однако приведенного здесь предварительного обсуждения недостаточно; эти методические приемы можно будет понять лишь в контексте всего метода наследования. (См. "Динамическое связывание" лекция 4)
Принцип Единственного Выбора нуждается еще в нескольких комментариях:
В соответствии с этим принципом, список возможных выборов должен быть известен одному и только одному модулю. Из целей модульного программирования следует, что желательно иметь не более чем один модуль, располагающий этой информацией; но очевидно также, что ею должен обладать хотя бы один модуль. Невозможно составить программу текстового редактора, если, по крайней мере один из компонентов не будет иметь списка всех поддерживаемых этой программой команд, для графической программы - списка всех типов фигур, для компилятора - списка всех языковых конструкций. Подобно другим правилам и принципам, обсужденным в этой лекции, принцип Единственного Выбора касается распределения знаний (distribution of knowledge) в системе ПО. Этот вопрос является действительно решающим при поиске расширяемых, многократно используемых программных средств. Чтобы получить цельную, надежную архитектуру ПО, следует предпринять строго обдуманные шаги по ограничению объема информации, доступной каждому модулю. По аналогии с методами, используемыми некоторыми общественными организациями, можно назвать это принципом необходимого знания (need-to-know): запретить каждому модулю доступ к любой информации, которая не является безусловно необходимой для его надлежащего функционирования. Можно рассматривать принцип Единственного Выбора как прямое следствие принципа Открыт-Закрыт. Обсудим пример с библиотекой публикаций в свете рисунка, иллюстрирующего необходимость в открытых и закрытых модулях: A это модуль, содержащий первоначальное описание типа PUBLICATION; клиенты B, C это модули, зависящие от исходного списка вариантов; A' это усовершенствованная версия A, предлагающая дополнительный вариант - технические отчеты (technical reports). (См. второй рисунок в разделе "Открыт-Закрыт") Можно также понимать этот принцип как сильную форму принципа Скрытия Информации. Разработчик модулей-поставщиков, таких как A и A', стремится скрыть информацию (относительно точного списка вариантов для некоторого понятия) от модулей-клиентов.
Явные интерфейсы
Четвертое правило является еще одним шагом к укреплению тоталитарного режима в обществе модулей: требуется не только, чтобы любые переговоры ограничивались лишь несколькими участниками и были немногословными; необходимо, чтобы такие переговоры были публичными и гласными!
Всякое общение двух модулей A и B между собой должно быть очевидным и отражаться в тексте A и/или B.
За этим правилом стоят критерии:
Декомпозиции и композиции. Если нужно разложить модуль на несколько подмодулей или компоновать его с другими модулями, то любая внешняя связь должна быть ясно видна. Непрерывности. Должно быть очевидно, какие элементы могут быть затронуты возможным изменением. Понятности. Как можно истолковывать действие модуля A, если на его поведение может косвенным образом влиять модуль B?
Одной из проблем, возникающих при применении правила Явных Интерфейсов, является то, что межмодульная связь может осуществляться не только через вызов процедуры; источником косвенной связи может быть, например, совместное использование данных (data sharing):

Рис. 3.9. Совместное использование данных
Предположим, что модуль A изменяет данные, а модуль B использует тот же элемент данных x. Тогда A и B оказываются фактически связанными через x, хотя между ними может и не быть явной взаимосвязи, например, вызова процедуры.
Ключевые концепции
Выбор надлежащей структуры модуля является ключом к достижению целей его возможного повторного использования и расширяемости. Модули служат как для декомпозиции программного обеспечения (проектирование сверху вниз), так и для его композиции (снизу-вверх). Принципы модульности применимы как к спецификации и проектированию, так и к реализации ПО. Всеобъемлющее определение модульности должно объединять различные точки зрения; разные требования иногда оказываются взаимно противоречивыми, например декомпозиция (стимулирующая методы проектирования сверху-вниз) и композиция (способствующая использованию метода снизу-вверх). Управление количеством и формой связей между модулями является основой разработки хорошей модульной архитектуры. Для долгосрочной целостности структур модульной системы требуется скрытие информации, что приводит к необходимости строгого разделения интерфейса и реализации. Унифицированный доступ освобождает клиентов от знания выбора внутренних представлений, реализованных в модулях-поставщиках. Закрытым является такой модуль, который может использоваться, благодаря знанию его интерфейса, модулями-клиентами. Открытым является такой модуль, который еще можно расширять. Для эффективного руководства проектом следует поддерживать модули, являющиеся одновременно как открытыми, так и закрытыми. Но традиционные подходы к разработке и программированию не дают такой возможности. Принцип Единственного Выбора предписывает ограничивать распространение полной информации обо всех вариантах некоторого понятия.
Лингвистические Модульные Единицы
Принцип Лингвистических Модульных Единиц утверждает, что формализм описания ПО на различных уровнях (спецификации, проектирования, реализации) должен поддерживать модульность:
Принцип Лингвистических Модульных Единиц
Модули должны соответствовать синтаксическим единицам используемого языка.
Упомянутым выше языком может быть язык программирования, язык проектирования, язык оформления технических требований и т. д. В случае языка программирования модули должны независимо компилироваться.
Этот принцип на любом уровне (анализа, проектирования, реализации) не допускает объединения метода, исходящего из концепции модульности, и языка, не содержащего соответствующих модульных конструкций. В самом деле, нередко встречаются фирмы, которые на этапе проектирования применяют некие методологические подходы, например используя модули языка Ada, но затем реализуют свои замыслы в таком языке программирования, как Pascal или C, не поддерживающим эти подходы. Такой подход нарушает некоторые из критериев модульности:
Непрерывность: если границы модуля в окончательном тексте программы не соответствуют логической декомпозиции спецификации или проекта, то при сопровождении системы и ее эволюции будет затруднительно или даже невозможно поддерживать совместимость различных уровней. Изменение спецификации можно считать небольшим, если оно затрагивает спецификацию лишь небольшого числа модулей. Для обеспечения "непрерывности" должно иметь место прямое соответствие между спецификацией, проектом и модулями реализации.Прямое отображение: необходимо поддерживать явное соответствие между структурой модели и структурой решения. Для этого необходимо иметь явную синтаксическую идентификацию концептуальных единиц модели и решения, отражающее разбиение, предусмотренное методом разработки.Декомпозиция: для разбиения системы на отдельные задачи необходимо быть уверенным, что результатом решения каждой из задач явится четко ограниченная синтаксическая единица; на этапе реализации эти программные компоненты должны быть раздельно компилируемыми.Композиция: что же, кроме модулей с однозначно определенными синтаксическими границами, можно объединять между собой? Защищенность: лишь в случае, если модули синтаксически разграничены, можно надеяться на возможность контроля области действия ошибок.
Минимум интерфейсов
Правило Минимума Интерфейсов ограничивает общее число информационных каналов, связывающих модули системы:
Каждый модуль должен поддерживать связь с возможно меньшим числом других модулей.
Связь между модулями может осуществляться различными способами. Модули могут вызывать друг друга (если они являются процедурами), совместно использовать структуры данных и так далее. Правило Минимума Интерфейсов ограничивает число таких связей.

Рис. 3.7. Виды структур межмодульных связей
В системе, составленной из n модулей, число межмодульных связей должно быть намного ближе к минимальному значению n-1, как показано на рисунке (A), чем к максимальному n (n - 1)/2, как показано на рисунке (B).
Это правило следует, в частности, из критериев непрерывности и защищенности: если между модулями имеется слишком много взаимосвязей, то влияние изменения или ошибки может распространиться на большое число модулей. Оно также имеет отношение к критериям композиции (чтобы модуль мог использоваться в новой программной среде, он не должен зависеть от слишком большого числа других модулей), понятности и декомпозиции.
Вариант (A) на последнем рисунке показывает, как добиться минимального числа связей, n-1, с помощью весьма централизованной структуры: один основной модуль, а все остальные общаются только с ним. Но имеются намного более "демократические" структуры, такие как (C), содержащие почти такое же число связей. В этой схеме каждый модуль непосредственно общается с двумя ближайшими соседями, центральной власти здесь нет. Такой подход к конструированию программы кажется сначала немного неожиданным, поскольку он не согласуется с традиционной моделью нисходящего проектирования. Но он может приводить к надежным, расширяемым решениям. Это именно такой вид структуры, к созданию которой будет стремиться ОО-метод при его разумном применении.
Модульная Композиция
Метод удовлетворяет критерию Модульной Композиции, если он обеспечивает разработку элементов программного продукта, свободно объединяемых между собой для получения новых систем, быть может, в среде, отличающейся от той, для которой эти элементы первоначально разрабатывались.
Композиция определяет процесс, обратный декомпозиции: элементы программного продукта извлекаются из того контекста, для которого они были первоначально предназначены, для использования их вновь в ином контексте.

Рис. 3.3. Композиция
Метод модульного проектирования облегчает этот процесс, создавая автономные элементы программного продукта достаточно независимыми от первоначально поставленной задачи, что делает такое извлечение возможным.
Композиция непосредственно связана с повторным использованием. Этот критерий отражает старую мечту - превратить процесс конструирования программного продукта в работу по складыванию кубиков так, чтобы строить программы из фабрично изготовленных элементов.
Пример 1: Библиотеки подпрограмм. Библиотеки подпрограмм создаются как наборы компонуемых элементов. Одной из областей, где они успешно используются, являются численные вычисления, основанные на тщательно подготовленных библиотеках подпрограмм для решения задач линейной алгебры, метода конечных элементов, дифференциальных уравнений и др. Пример 2: Соглашения, принятые в командном языке Shell операционной системы UNIX. Основные команды системы UNIX оперируют с входным потоком последовательных символов и выдают результат, имеющий такую же стандартную структуру. Потенциальная возможность композиции поддерживается оператором | командного языка "Shell". Запись A | B означает композицию программ. Вначале запускается программа A, ее результаты поступают на вход программы B, начинающей свою работу по завершении работы программы А. Такое системное соглашение благоприятствует композиции программных средств. Контрпример: Препроцессоры. Общепринятым способом расширения языка программирования, а иногда и преодоления его недостатков, является использование "препроцессора", принимающего входные данные в расширенном синтаксисе и отображающего их в стандартной для этого языка форме.
Типичные препроцессоры для Fortran'а и C поддерживают графические примитивы, расширенные управляющие структуры или операции над базами данных. Однако обычно такие расширения не являются взаимно совместимыми; что не позволяет сочетать два таких препроцессора, и приходится выбирать между, например, графикой или базой данных.
Композиция не зависит от декомпозиции. Фактически эти критерии часто противоречат друг другу. Например, метод нисходящего проектирования, удовлетворяющий, как уже было показано, критерию декомпозиции, обычно приводит к созданию таких модулей, которые нелегко сочетать с модулями, полученными из других источников. При такой декомпозиции модули обычно тесно связаны с теми специфическими требованиями, которые привели к их разработке, и не могут быть приспособлены к использованию в других условиях. Метод нисходящего проектирования не дает рекомендаций по разработке модулей, удовлетворяющих общим требованиям. В нем нет средств такой разработки, он не позволяет ни избежать, ни хотя бы обнаружить программную избыточность модулей, получаемых в различных частях иерархии.
Как композиция, так и декомпозиция являются частью требований к модульному методу проектирования. Неизбежна смесь двух подходов к проектированию: сверху-вниз и снизу-вверх. На этот принцип дополнительности обратил внимание Рене Декарт почти четыре столетия тому назад, как видно из сопоставления двух правил его Рассуждений, приведенных в эпиграфе этой лекции.
Модульная Непрерывность
Метод удовлетворяет критерию Модульной Непрерывности, если незначительное изменение спецификаций разработанной системы приведет к изменению одного или небольшого числа модулей.
Этот критерий непосредственно связан с критерием расширяемости. Как подчеркивалось в предыдущей лекции, внесение изменений является неотъемлемой частью процесса разработки программного продукта. Соответствующие требования к программе будут неминуемо изменяться в ходе разработки. Непрерывность означает, что небольшие изменения будут воздействовать только на отдельные модули в структуре системы, а не на всю систему.
Термин "непрерывность" предлагается по аналогии с понятием непрерывной функции в математическом анализе. Математическая функция является непрерывной, если (неформально) малое изменение аргумента приводит к пропорционально малому изменению результата. В нашем случае роль функции играет метод конструирования программного продукта, который может рассматриваться как механизм, получающий на входе спецификации и возвращающий в качестве результата систему, удовлетворяющую заданным требованиям:
Метод_конструирования_ПО: Спецификации -> Система

Рис. 3.5. Непрерывность
Этот математический термин введен здесь лишь по аналогии, поскольку не существует формального понятия размера спецификации и программы. Можно было бы ввести приемлемую меру для определения "небольших" или "больших" изменений программы, но дать подобное определение для спецификаций к программе это уже настоящая проблема. Однако если не претендовать на строгость, то такое интуитивно понятное определение будет соответствовать необходимому требованию к любому модульному методу.
Пример 1:именованные константы2). Разумный стиль не допускает в программе констант, заданных литералами. Вместо этого следует пользоваться именованными константами, значения которых даются в их определениях (constant в языках Pascal или Ada, макрокоманды препроцессоров в языке C, PARAMETER в языке Fortran 77, атрибуты констант в обозначениях этого курса).
Если значение изменяется, то следует лишь внести единственное изменение в определение константы. Это простое, но важное правило является разумной мерой обеспечения непрерывности, потому что значения констант, несмотря на их название, довольно часто могут изменяться. Пример 2: принцип Унифицированного Доступа. Еще одно правило требует единой нотации при вызове свойств объекта независимо от того, представляют они обычные или вычислимые поля данных. Контрпример 1: использование физического представления информации. Метод, в котором разрабатываемые программы согласуются с физической реализацией данных, будет приводить к конструкциям, весьма чувствительным к незначительным изменениям окружения. Контрпример 2: статические массивы. Такие языки, как Fortran или стандартный Pascal, в которых не допускаются динамические массивы, границы которых становятся известными лишь во время выполнения программы, существенно усложняют развитие системы.
Модульная Понятность
Метод удовлетворяет критерию Модульной Понятности, если он помогает получить такую программу, читая которую можно понять содержание каждого модуля, не зная текста остальных, или, в худшем случае, ознакомившись лишь с некоторыми из них.
Важность этого критерия следует из его влияния на процесс сопровождения программного продукта. Почти все действия по сопровождению программы, как неизбежные, так и не столь неизбежные, связаны с глубоким пониманием ее элементов. Метод едва ли может называться модульным, если тот, кто читает программный текст, не в состоянии понять его смысл.

Рис. 3.4. Понятность
Этот критерий, подобно четырем остальным, применим к модулям при описании системы на любом уровне: анализа, проектирования, реализации.
Контрпример: последовательные зависимости. Предположим, что некоторые модули спроектированы таким образом, что они будут правильно функционировать лишь при их запуске в определенном заранее предписанном порядке. Например, B может работать надлежащим образом лишь при запуске его после A и перед C, возможно потому, что эти модули предназначены для использования в "конвейере" Unix, упоминавшемся ранее: A | B | C. В таком случае, по-видимому, трудно понять как работает B, не понимая работу A и C.
В последующих лекциях критерий модульной понятности поможет при рассмотрении двух важных вопросов: как документировать многократно используемые компоненты и как их индексировать, чтобы разработчики программного продукта могли без труда обращаться к ним путем соответствующего запроса. В соответствии с этим критерием информация о компоненте, полезная для документирования или поиска, должна, насколько это возможно, содержаться в тексте самого компонента, тогда средства документирования, индексации или поиска смогут обработать этот компонент и получить требуемую информацию.
Наличие нужной информации в каждом компоненте предпочтительнее хранения ее где-либо в другом месте, например в базе данных для хранения информации о компонентах.
Модульная Защищенность
Метод удовлетворяет критерию Модульной Защищенности, если он приводит к архитектуре системы, в которой аварийная ситуация, возникшая во время выполнения модуля, ограничится только этим модулем, или, в худшем случае, распространится лишь на несколько соседних модулей.
Вопрос об отказах и ошибках является основным в программной инженерии. Сейчас речь идет об ошибках периода исполнения программы, связанных с аппаратными прерываниями, ошибочными входными данными или исчерпанием необходимых ресурсов (например, из-за недостаточного объема памяти). Критерий защищенности направлен не на предотвращение или исправление ошибок, а на проблему, непосредственно связанную с модульностью - распространением ошибок в модульной системе.

Рис. 3.6. Нарушение защищенности
Пример: проверка достоверности входных данных в источнике. Метод, требующий от каждого модуля, вводящего данные, проверку их достоверности, пригоден для реализации модульной защищенности.3)
Контрпример: недисциплинированные (undisciplined) исключения. (Об обработке исключений см. лекцию 12) Такие языки как PL/I, CLU, Ada, C++ и Java поддерживают понятие исключения (exception). Исключение это ситуация, при которой программа не может нормально выполняться. Исключение "возбуждается" ("raised") некоторой командой модуля, и в результате операционной системе посылается специальный сигнал. Обработчик исключения (exception handler) может находиться в одном или нескольких модулях, расположенных в, возможно, удаленной части системы. Детали этого механизма отличаются в разных языках программирования; Ada или CLU являются более строгими в этом отношении, чем PL/I. Такие средства контроля ошибок позволяют отделить алгоритмы для обычных случаев от алгоритмов обработки ошибок. Но ими следует пользоваться осторожно, чтобы не нарушить модульную защищенность. В лекции 12, посвященной исключениям, рассматривается проектирование дисциплинированного (disciplined) механизма исключений, удовлетворяющего критерию защищенности.
Открыт-Закрыт
Любой метод модульной декомпозиции должен удовлетворять принципу семафора: Открыт-Закрыт:
Принцип Открыт-Закрыт
Модули должны иметь возможность быть как открытыми, так и закрытыми.
Противоречие является лишь кажущимся, поскольку термины соответствуют разным целевым установкам:
Модуль называют открытым, если он еще доступен для расширения. Например, имеется возможность расширить множество операций в нем или добавить поля к его структурам данных. Модуль называют закрытым, если он доступен для использования другими модулями. Это означает, что модуль (его интерфейс - с точки зрения скрытия информации) уже имеет строго определенное окончательное описание. На уровне реализации закрытое состояние модуля означает, что модуль можно компилировать, сохранять в библиотеке и делать его доступным для использования другими модулями (его клиентами). На этапе проектирования или спецификации закрытие модуля означает, что он одобрен руководством, внесен в официальный репозиторий утвержденных программных элементов проекта - базу проекта (project baseline), и его интерфейс опубликован в интересах авторов других модулей.
Необходимость закрывать модули и необходимость оставлять их открытыми вызываются разными причинами. Для разработчиков ПО естественным состоянием модуля является его открытость, поскольку почти невозможно заранее предусмотреть все элементы - данные, операции - которые могут потребоваться в процессе создания модуля. Поэтому разработчики стараются сохранять гибкость ПО, допускающую последующие изменения и дополнения. Но необходимо, особенно с точки зрения руководителя проекта, закрывать модули. В системе, состоящей из многих модулей, большинство модулей зависимы. Например, модуль интерфейса пользователя может зависеть от модуля синтаксического разбора (parsing module) - синтаксического анализатора и от модуля графики. Синтаксический анализатор может зависеть от модуля лексического анализа, и так далее. Если не закрывать модуль до тех пор, пока не будет уверенности, что он уже содержит все необходимые компоненты, то невозможно будет завершить разработку многомодульной программы: каждый из разработчиков будет вынужден ожидать, когда же завершат свою работу все остальные.
При использовании традиционной методики, две рассмотренные целевые установки оказываются несовместимыми. Либо модуль остается открытым, что не позволяет пользоваться им всем остальным, либо он закрывается, и тогда любое изменение или дополнение может дать начало неприятной цепной реакции трудоемких изменений во многих других модулях, непосредственно или косвенно зависящих от этого исходного модуля.
Два рисунка, приведенные ниже, иллюстрируют ситуацию, в которой трудно согласовать потребности в открытых и закрытых состояниях модуля. На первом рисунке модуль A используется модулями-клиентами B, С, D, которые сами могут иметь своих клиентов - E, F и так далее.
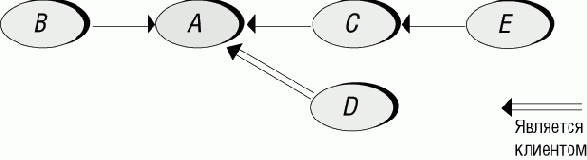
Рис. 3.12. Модуль А и его клиенты
В процессе течения времени ситуация изменяется и появляются новые клиенты - F и другие, которым требуется расширенная или приспособленная к новым условиям версия модуля A, которую можно назвать A':
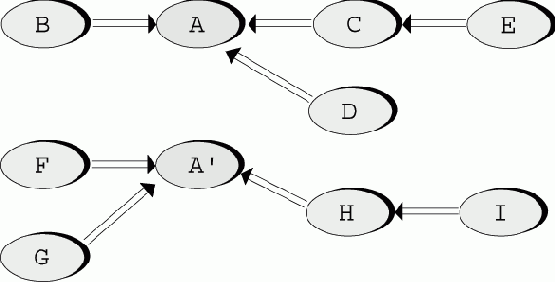
Рис. 3.13. Старые и новые клиенты
При использовании не ОО-методов, возможны лишь два решения этой проблемы, в равной степени неудовлетворительные:
N1 Можно переделать модуль A так, чтобы он обеспечивал расширенную или видоизмененную функциональность, требуемую новым клиентам. N2 Можно сохранить A в прежнем виде, сделать его копию, изменить имя копии модуля на A', и выполнить все необходимые переделки в новом модуле. При таком подходе новый модуль A' никак не будет связан со старым модулем A.
Возможные катастрофические последствия решения N1 очевидны. Модуль A мог использоваться длительное время и иметь многих клиентов, таких как B, С и D. Переделки, необходимые для удовлетворения потребностей новых клиентов, могут нарушить предположения, на основе которых старые клиенты использовали модуль A; в этом случае изменения в A могут "запустить" катастрофическую цепочку изменений у клиентов, у клиентов этих клиентов, и так далее. Для руководителя проекта это будет настоящим кошмаром: внезапно целые части ПО, считавшегося давным-давно завершенным и сданным в эксплуатацию, окажутся заново открытыми, что "запустит" новый цикл разработки, тестирования, отладки и документирования.
Многие ли из руководителей проектов ПО захотят видеть себя в роли Сизифа - быть приговоренными вечно катить камень на вершину горы лишь для того, чтобы видеть, как он всякий раз вновь скатывается вниз - и все из-за проблем, вызванных необходимостью заново открывать ранее закрытые модули.
На первый взгляд решение N2 кажется лучшим: оно позволяет избежать синдрома Сизифа, поскольку не требует модификации уже существующих программных средств (показанных в верхней части последнего рисунка). Но в действительности, это решение может иметь еще худшие последствия, поскольку оно лишь отодвигает час расплаты. Экстраполируем воздействие этого решения на множество модулей, - потребуется множество модификаций, занимающих длительное время. В конечном счете, последствия оказываются ужасными: бурный рост числа вариантов исходных модулей, многие из которых очень похожи, хотя и не вполне идентичны.
Для многих организаций по разработке ПО такое изобилие модулей, не согласующееся с количеством выполняемых функций (многие из вариантов, кажущихся различными, оказываются, по существу, клонами), создает серьезную проблему управления конфигурацией ПО. И эту проблему обычно пытаются преодолеть путем использования сложных инструментальных средств. Полезные сами по себе, эти инструментальные средства пытаются "лечить" программу в ситуациях, когда предпочтительней было бы первое из рассмотренных решений. Ведь лучше избежать избыточности, чем создавать ее.
| Несомненно, управление конфигурацией окажется полезным, но лишь в случае, если удастся найти модули, нуждающиеся в повторном открытии после возникших изменений, и в то же время избежать повторной компиляции модулей, не нуждающихся в этом. (В упражнении У3.6 предлагается выяснить, какова будет необходимость управления конфигурацией в объектно-ориентированной среде программирования.) |
Механизм наследования подробно рассматривается в последующих лекциях, а здесь дается лишь общее представление об этом. Для разрешения дилеммы, - изменять или повторно выполнять - наследование позволяет определить новый модуль A' на основе существующего модуля A, констатируя лишь различия между ними. Опишем A' как
class A' inherit A redefine f, g, ... end feature f is ... g is ... ... u is ... ... end
где предложение feature содержит как определение новых компонент, характерных для A', например u, так и переопределение тех компонент (таких как f, g,:), представление которых в A' отличается от того, которое они имели в A.
Для графической иллюстрации наследования используется стрелка от "наследника" (heir) (нового класса A') к "родителю" (parent) (классу A):

Рис. 3.14. Адаптация модуля к новым клиентам
Благодаря механизму наследования ОО, разработчики могут осуществлять гораздо более последовательный подход к разработке ПО, чем это было возможно при использовании прежних методов. Один из способов описания принципа Открыт-Закрыт и следующих из него ОО-методов состоит в рассмотрении их как организованного хакерства. Под "хакерством" здесь понимается небрежный (slipshod) подход к компоновке и модификации программы (а вовсе не несанкционированное и, конечно, недопустимое проникновение в компьютерные сети). Хакера можно считать плохим человеком, но часто намерения его чисты. Он может разглядеть полезный фрагмент программы, который почти пригоден для реализации текущих потребностей, намного превосходящих потребности, предусмотренные при первоначальной разработке программы. Вдохновленный похвальным желанием не создавать повторно то, что можно повторно использовать, наш хакер начинает модифицировать исходный текст программы, дополняя его средствами для выполнения новых задач. Конечно, такой порыв неплох, но результатом часто оказывается "засорение" программы многочисленными выражениями вида: if(этот_частный_случай) then.
После нескольких повторений, возможно, осуществляемыми разными хакерами, программа начинает походить на ломоть швейцарского сыра, оставленного слишком долго на августовской жаре (безвкусность этой метафоры оправдывается тем, что она хорошо воспроизводит появление в такой программе как "дырок", так и "наростов").
Организованная форма хакерства дает возможность приспосабливаться к изменяющейся структуре решаемых задач, не нарушая непротиворечивости исходной версии.
Небольшое предупреждение: здесь не предлагается неорганизованное хакерство. В частности:
Если имеется возможность переписать исходную программу так, чтобы она, без излишнего усложнения, смогла удовлетворять потребности нескольких разновидностей клиентов, то следует это сделать. Как принцип Открыт-Закрыт, так и переопределение в механизме наследования не позволяют справиться с дефектами разработки, не говоря уже об ошибках в программе. Если в модуле что-то не в порядке, то следует это сразу исправить в исходной программе, не пытаясь разбираться с возникающей проблемой в производном модуле. Возможным исключением из этого правила является случай некорректной программы, которую не разрешено модифицировать. Принцип Открыт-Закрыт и связанные с ним методы программирования, предназначены для адаптации "здоровых" модулей, то есть модулей, которые хотя и не могут решать некоторые новые задачи, однако отвечают строго определенным требованиям в интересах своих клиентов.
Пять критериев
Метод проектирования, который можно называть "модульным", должен удовлетворять пяти основным требованиям:
Декомпозиции (decomposability). Композиции (composability). Понятности (understandability). Непрерывности (continuity). Защищенности (protection).
Пять правил
Из рассмотренных критериев следуют пять правил, которые должны соблюдаться, чтобы обеспечить модульность:
Прямое отображение (Direct Mapping). Минимум интерфейсов (Few Interfaces). Слабая связность интерфейсов (Small interfaces - weak coupling). Явные интерфейсы (Explicit Interfaces). Скрытие информации (инкапсуляция) (Information Hiding).
Первое правило касается отношения между внешней системой и ПО. Следующие четыре правила касаются общей проблемы - как модули общаются между собой. Для получения хорошей модульной архитектуры необходим управляемый и строгий метод обеспечения межмодульных связей.
Пять принципов
Из предыдущих правил и, косвенным образом, из критериев следуют пять принципов конструирования ПО:
Принцип Лингвистических Модульных Единиц (Linguistic Modular Units).Принцип Самодокументирования (Self-Documentation).Принцип Унифицированного Доступа (Uniform Access).Принцип Открыт-Закрыт (Open-Closed).Принцип Единственного выбора (Single Choice).
Прямое отображение
Любая прикладная система стремится удовлетворить потребности некоторой проблемной области. Если имеется хорошая модель для описания этой проблемной области, то желательно обеспечить четкое отображение структуры проблемы, описываемой моделью, на структуру системы. Из этого следует первое правило:
Модульная структура, создаваемая в процессе конструирования ПО, должна оставаться совместимой с модульной структурой, создаваемой в процессе моделирования проблемной области.
Эта рекомендация следует, в частности, из двух критериев модульности:
Непрерывность: отслеживание модульной структуры проблемы в структуре решения облегчит оценку и ограничит последствия изменений. Декомпозиция: если уже была проделана некоторая работа по анализу модульной структуры проблемной области, то это может явиться хорошей отправной точкой для разбиения программы на модули.
Самодокументирование
Подобно правилу Скрытия Информации, принцип Самодокументирования определяет, как следует документировать модули:
Принцип Самодокументирования
Разработчик модуля должен стремиться к тому, чтобы вся информация о модуле содержалась в самом модуле.
Обычно реализации этого принципа мешает общепринятое положение, согласно которому информацию о модуле помещают в отдельные проектные документы.
| Документация, рассматриваемая здесь, является внутренней документацией о компонентах ПО. Пользовательская документация о выпущенном программном продукте может быть отдельным документом, реализованном в виде печатного текста, либо размещенном на CD-ROM или страницах в Интернете. Как отмечалось при обсуждении вопроса о качестве программного обеспечения, следствием общего принципа самодокументирования является наблюдаемая сейчас тенденция к большему использованию средств диалоговой оперативной подсказки. (См."О документировании" лекция 1) |
Наиболее очевидным обоснованием необходимости принципа Самодокументирования является критерий модульной понятности. По-видимому, однако, более важным является то, что этот принцип помогает реализации критерия непрерывности. Если программное обеспечение и документацию к нему рассматривать как отдельные объекты, то трудно гарантировать, что они будут оставаться совместимыми - будут синхронно изменяться при всех изменениях системы. Однако если хранить все в одном месте, то это, хотя и не дает полную гарантию, но все же поможет поддерживать совместимость.
Этот принцип, безобидный на первый взгляд, противоречит многому из того, что обычно рекомендуется к практическому применению в литературе по разработке ПО. Преобладает мнение, что разработчик ПО - инженер-программист - должен делать то, чем, по-видимому, обязаны заниматься остальные инженеры: производить килограмм бумаги на каждый грамм фактически создаваемой продукции. Предложение вести запись процесса разработки ПО является неплохим советом, но из этого вовсе не следует, что программа и документация к ней являются разными продуктами.
Такой подход игнорирует характерное свойство ПО, которое здесь неоднократно обсуждается: возможность его изменения. Если рассматривать программу и документацию к ней как два разных продукта, то вскоре можно оказаться в ситуации, когда в документации утверждается одно, а программа делает нечто иное. А ведь наличие неправильной документации намного хуже, чем ее отсутствие.
| Главным достижением последних нескольких лет явилось появление стандартов качества ПО. Разработаны сертификаты ISO, стандарт "2167" и его преемники, Модель Полноты Потенциала (Capability Maturity Model), предложенная Институтом программной инженерии (Software Engineering Institute). Но поскольку они брали начало из моделей, используемых в других отраслях знания, они наделены обширным "хвостом" бумажной документации. Некоторые из этих стандартов могли бы оказать значительно большее влияние на качество ПО, (помимо того, что они дают администраторам программного продукта средство для оправданий в случае последующих эксплуатационных неполадок) если бы они включали принцип Самодокументирования. |
При таком подходе ПО превращается в единственный программный продукт, обеспечивающий его различные представления или облики (views). Один облик, пригодный для компиляции и выполнения, - полный исходный текст модуля. Другой - документация, задающая абстрактный интерфейс модуля, позволяющий разработчикам программного обеспечения создавать модули-клиенты, не знакомясь с содержанием исходного модуля, что соответствует правилу Скрытия Информации.Возможны и другие представления.
Скрытие информации
Правило Скрытия Информации можно сформулировать следующим образом:
Разработчик каждого модуля должен выбрать некоторое подмножество свойств модуля в качестве официальной информации о модуле, доступной авторам клиентских модулей.
Применение этого правила означает, что каждый модуль известен всем остальным (то есть разработчикам других модулей) через некоторое официальное описание, или так называемые общедоступные (public) свойства.
Конечно, таким описанием может быть весь текст модуля (текст программы, текст проекта): он и обеспечивает правильное представление о модуле, поскольку это и есть модуль! Но правило Скрытия Информации устанавливает, что в общем случае это не обязательно: описание должно включать лишь некоторые из свойств модуля. Остальные свойства должны оставаться не общедоступными, или закрытыми (секретные) (secret). Вместо терминов - общедоступные и закрытые свойства - используются также термины: экспортируемые и частные (скрытые) (private) свойства. Общедоступные свойства модуля известны также как интерфейс (interface) модуля (не следует путать с пользовательским интерфейсом системы программирования).
В основе правила Скрытия Информации лежит критерий непрерывности. Предположим, что в некотором модуле происходят изменения, касающиеся лишь его скрытых элементов и не затрагивающие общедоступных свойств; тогда на другие обращающиеся к нему модули, называемые его клиентами, эти изменения не подействуют. Чем меньше общедоступная часть, тем больше шансов на то, что изменения в модуле будут содержаться в его скрытой части.
Можно изобразить модуль, поддерживающий правило Скрытия Информации, в виде айсберга; лишь его верхушка - интерфейс - видна клиентам.

Рис. 3.10. Модуль в условиях скрытия информации
В качестве характерного примера рассмотрим процедуру поиска по ключу атрибутов, хранящихся в таблице, такой как картотека личного состава или таблица идентификаторов компилятора. Эта процедура существенно зависит от способа представления таблицы - последовательный массив или файл, хэш-таблица, двоичное или индексное (B-Tree) дерево и т.д.
Скрытие информации означает, что выбранный способ реализации таблицы не влияет на использование такой процедуры. Модули-клиенты не должны страдать от каких-либо изменений в реализации программы.
Правило скрытия информации придает особое значение отделению описания функции от ее реализации, - что делает функция и как она это делает - разные вещи. Помимо критерия непрерывности, это правило связано также с критериями декомпозиции, композиции и понятности. Нельзя независимо разрабатывать модули системы, комбинировать существующие модули или понимать действие отдельных модулей, если неизвестно в точности, что каждый из них может (или не может) ожидать от других модулей.
Какие же из свойств модуля должны быть общедоступными, а какие - скрытыми? Как правило, в общедоступную часть следует включать функциональность, заданную спецификацией модуля, а все, что связано с реализацией этих функциональных возможностей, должно быть скрыто, предохраняя другие модули от последующих изменений реализации программы.
Однако эта рекомендация является нечеткой, так как не дано определение спецификации (specification) и реализации (implementation). Действительно, можно поддаться искушению, изменив определение на прямо противоположное, и утверждать, что спецификация состоит из общедоступных свойств модуля, а реализация - из его скрытых свойств! ОО-подход обеспечит намного более точные рекомендации на основе теории абстрактных типов данных.(См. лекцию 6, в частности "Абстрактные типы данных и скрытие информации".)
Для понимания смысла скрытия информации и применения этого правила должным образом, важно избежать широко распространенного неверного толкования. Несмотря на свое название, скрытие информации не означает защиты информации в смысле обеспечения секретности - запрещения авторам модулей-клиентов доступа к тексту модуля-поставщика (supplier module). На самом деле авторы модулей-клиентов имеют доступ ко всем интересующим их подробностям. В некоторых случаях было бы разумно запретить им это, но такое решение, которое, конечно, может принять руководство проекта, не следует из правила скрытия информации.
Скрытие информации, как техническое требование, означает лишь, что модули-клиенты (независимо от того, разрешен ли их авторам доступ к скрытым свойствам модулей-источников) должны рассчитывать только на общедоступные свойства модуля-поставщика. Точнее говоря, должно быть невозможным создание клиентских модулей, правильное функционирование которых зависело бы от скрытой информации.
| При формальном подходе к разработке программного обеспечения это определение можно было бы сформулировать следующим образом. Для доказательства корректности модуля необходимо сделать некоторые допущения о свойствах его модулей-поставщиков. Скрытие информации означает, что доказательство может основываться лишь на общедоступных свойствах поставщиков и никоим образом - на их скрытых свойствах. |
Скрытие информации означает нечто другое: даже если автор программы электронных таблиц знает о том, что поиск основан на дереве двоичного поиска, ему не следует составлять такой модуль-клиент, который правильно функционирует лишь при этой реализации поиска - и перестанет работать при замене алгоритма поиска на какой-либо другой, например, на поиск с хешированием.
Одной из причин вышеупомянутого недопонимания является сам термин "скрытие информации" ("information hiding"), который наводит на мысль о защите физического характера.В этом смысле предпочтительным, по-видимому, мог бы явиться термин "инкапсуляция" ("encapsulation"), иногда используемый в качестве синонима скрытию информации, однако в нашем обсуждении будет по-прежнему использоваться общий термин "скрытие информации".
Из этого обсуждения следует, что ключом к скрытию информации являются не решения по организации доступа к исходному тексту модуля в рамках управления проектом или маркетинговой политики, а строгие языковые правила, определяющие, какие права на доступ к модулю следуют из свойств его источника. В следующей лекции показано, что первые шаги в этом направлении реализованы в таких "языках с инкапсуляцией" как Ada и Modula-2. Объектно-ориентированная технология программирования приведет к более полному решению проблемы.5)
Слабая связность интерфейсов
Правило Слабой связности интерфейсов относится к размеру передаваемой информации, а не к числу связей:
Если два модуля общаются между собой, то они должны обмениваться как можно меньшим объемом информации.
Инженер-электрик сказал бы, что каналы связи между модулями должны иметь ограниченную полосу пропускания:

Рис. 3.8. Канал связи между модулями
Требование Слабой связности интерфейсов следует, в частности, из критериев непрерывности и защищенности.
Особо примечательным контрпримером является конструкция из языка Fortran, знакомая некоторым читателям как "общий блок для мусора" ("garbage common block"). Общим блоком в Fortran'е является директива вида:
COMMON /общее_имя/ переменная1 : переменнаяn.
Переменные, перечисленные в блоке, доступны во всех модулях, содержащих директиву COMMON с тем же общим_именем. Нередко встречаются программы на Fortran'е, в которых каждый модуль содержит одну и ту же огромную директиву COMMON с перечислением всех существенных переменных и массивов, так что каждый модуль может непосредственно обращаться к любым данным программы.
Возникающие здесь затруднения состоят в том, что любой из модулей может неправильно использовать общие данные, а модули тесно связаны между собой; поэтому проблемы реализации непрерывности (распространение изменений) и защищенности (распространение ошибок) являются чрезвычайно трудно разрешимыми. Тем не менее, эта освященная годами техника все еще остается любимой многими программистами, хотя и ведет к длительным ночным отладочным бдениям.
Разработчики, пользующиеся языками с вложенными структурами, испытывают такие же затруднения. При наличии блочной структуры, введенной в языке Algol и поддерживаемой, в более ограниченной форме, в языке Pascal, можно "вкладывать" блоки, содержащиеся внутри пар begin ... end, внутрь других блоков. К тому же каждый блок может вводить свои собственные переменные, которые имеют смысл лишь в синтаксическом контексте (syntactic scope) этого блока.
Например:
local -- Начало блока B1 x, y: INTEGER do ... Команды блока B1 ... local -- Начало блока B2 z: BOOLEAN do ... Команды блока B2 ... end -- Конец блока B2 local -- Начало блока B3 y, z: INTEGER do ... Команды блока B3 ... end -- Конец блока B3 ... Команды блока B1 (продолжение) ... end -- Конец блока B1
Переменная x доступна для всех команд в этом фрагменте программы, в то время как области действия двух переменных с именем z (одна типа BOOLEAN, другая типа INTEGER) ограничены блоками B2 и B3 соответственно. Подобно x, переменная y объявлена на уровне блока B1, но ее область действия не включает блока B3, где другая переменная с тем же именем и тем же типом локально имеет приоритет над самой ближней внешней переменной y. В Pascal'е этот вид блочной структуры существует лишь для блоков, связанных с подпрограммами (процедурами и функциями).4)
При наличии блочной структуры, эквивалентом "мусорного" общего блока Fortran'а является объявление всех переменных на самом верхнем (глобальном) уровне. В языках на основе языка С таким эквивалентом является объявление всех переменных внешними (external). (О кластерах см. лекции 10 курса "Основы объектно-ориентированного проектирования". Альтернатива вложенности рассматривается в разделе "Архитектурная роль выборочного экспорта (selective exports)".)
Использование блочной структуры является оригинальной идеей, но это может приводить к нарушению правила Слабой связности Интерфейсов. По этой причине мы будем воздерживаться от применения ее в объектно-ориентированной нотации, развиваемой далее в этом курсе. Язык Simula - объектно-ориентированная производная от Algol'а - поддерживает блочную структуру классов. Опыт работы с ним показал, что способность создавать вложенные классы является излишней при наличии некоторых возможностей, обеспечиваемых механизмом наследования. Структура объектно-ориентированного программного обеспечения содержит три уровня: система является набором кластеров; кластер является набором классов; класс является набором компонент (атрибутов (attributes) и методов (routines)).Кластеры скорее организационное средство, чем лингвистическая конструкция, могут быть вложенными, что позволяет руководителю проекта структурировать большую систему на любое необходимое число уровней; но классы, как и компоненты, имеют одноуровневую плоскую (flat) структуру, поскольку вложенность на любом из этих уровней приведет к излишнему усложнению.
У3.1 Модульность в языках программирования
Рассмотрите модульные структуры в любом хорошо знакомом вам языке программирования и оцените, насколько они удовлетворяют критериям и принципам, изложенным в этой лекции.
У3.2 Принцип Открыт-Закрыт (для программистов Lisp)
Многие реализации Lisp'а связывают конкретные функции с их именами не статически, а во время выполнения программы. Означает ли это, что язык Lisp лучше поддерживает принцип Открыт-Закрыт, чем статические языки?
У3.3 Ограничения на скрытие информации
Представляете ли вы себе обстоятельства, при которых скрытие информации не должно применяться к связям между модулями?
У3.4 Метрики для модульности (отчетная исследовательская работа)
Критерии, правила и принципы модульности были описаны в этой лекции с помощью качественных определений. Однако некоторые из них поддаются количественному анализу. Это могут быть:
Модульная непрерывность. Минимум интерфейсов. Слабая связность интерфейсов. Явные интерфейсы. Скрытие информации. Единственный выбор.
Выясните возможность разработки метрик модульности, чтобы оценить, насколько модульной является архитектура системы программного обеспечения в соответствии с некоторыми из этих понятий. Метрики должны быть размерно-независимыми: увеличение размера системы без изменения ее модульной структуры не должно приводить к изменению мер ее сложности (см. также следующее упражнение).
У3.5 Модульность существующих систем
Примените критерии, правила и принципы модульности из этой лекции для оценки системы, к которой у вас есть доступ. Если вы решили предыдущее упражнение, примените любую из предложенных вами метрик модульности.
Можете ли вы установить какие-нибудь взаимозависимости между результатами этого анализа (качественными, количественными, или теми и другими) и оценками структурной сложности исследуемой системы, основанными либо на ее неформальном анализе, либо, если это возможно, на реальных замерах затрат на ее отладку и сопровождение?
У3.6 Управление конфигурацией и наследование
Это упражнение предполагает знание механизма наследования, описанного далее в этом курсе. Его не стоит пока что выполнять, если вы дошли до этой лекции, изучая курс последовательно.
Обсуждение принципа Открыт-Закрыт показало, что отсутствие наследования в не ОО-методах вызывает чрезмерные расходы на разработку средств управления конфигурацией, поскольку желание избежать повторного открытия закрытых модулей может приводить к созданию слишком большого числа модульных вариантов. Выясните, какая роль остается за средствами управления конфигурацией в ОО-среде, где имеется механизм наследования, и вообще - как использование объектной технологии влияет на управление конфигурацией.
Если вы знакомы с конкретными средствами управления конфигурацией, выясните, как они взаимодействуют с механизмом наследования и другими принципами ОО-разработки ПО.
 |
|
|
1)
Дальнейшее обсуждение метода нисходящего проектирования показывает, что этот метод не вполне согласуется с другими критериями модульности.
2)
Это будет одним из принципов нашего стиля программирования: Принцип именованной константы (Symbolic Constant Principle.)
3)
Более подробно этот вопрос рассмотрен в разделе "Формальные утверждения (assertions) не являются механизмом контроля входа данных"
4)
Тело блока это последовательность команд. Примененный здесь синтаксис совместим с нотацией, используемой в последующих лекциях и несколько отличается от синтаксиса языка Algol. "--" означает начало комментария.
5)
По умолчанию, "Ada" всегда означает не более новую версию Ada 95, а наиболее распространенную форму этого языка (версия 1983 года.). Обе версии рассмотрены в лекции 15 курса "Основы объектно-ориентированного проектирования".
6)
Он известен также как принцип Унифицированных Ссылок
Унифицированный Доступ
Хотя вначале может показаться, что принцип Унифицированного Доступа направлен лишь на решение проблем, связанных с принятой нотацией, в действительности он задает правило проектирования, влияющее на многие аспекты ОО-разработки ПО. Принцип следует из критерия Непрерывности; его можно рассматривать и как частный случай правила Скрытия Информации.6)
Пусть x - имя, используемое для доступа к некоторому элементу данных, который в последующем будем называть объектом. Пусть f - имя компонента (feature), применимого к x. Под компонентом понимается некоторая операция; далее этот термин будет определен подробнее. Например, x может быть переменной, представляющей счет в банке, а f - компонент, задающий текущий баланс этого счета (account's current balance). Унифицированный Доступ направлен на решение вопроса о том, какой должна быть нотация, задающая применение f к x, не содержащая каких-либо преждевременных обязательств по способу реализации f.
Во многих языках проектирования и программирования выражение, описывающее применение f к x, зависит от реализации f, выбранной разработчиком. Это может быть свойство, хранимое вместе с x, или метод, вызываемый всякий раз, когда это требуется. В примере с банковскими счетами и остатками на счетах возможно использование обоих подходов:
A1 Можно представить баланс банковского счета в виде одного из полей записи, описывающей каждый счет. При использовании такого подхода каждая банковская операция, изменяющая баланс, должна предусматривать корректировку соответствующего поля. A2 Можно определить функцию, вычисляющую баланс на основании других полей этой записи, например полей, представляющих списки денежных сумм, снятых со счета и внесенных на счет. При использовании такого подхода значение баланса не сохраняется, а вычисляется по запросу.
В общепринятой нотации таких языков, как Pascal, Ada, C, C++ и Java используется обозначение x.f для случая A1 и f(x) для случая A2.

Рис. 3.11. Два представления банковского счета
Выбор между представлениями A1 и A2 это компромисс между "памятью и временем": первое экономит на вычислениях, а второе - на памяти.
Решение о выборе одного из вариантов является типичным примером решения, изменяемого разработчиком, по крайней мере один раз за время существования проекта. Поэтому с целью поддержания непрерывности желательно иметь нотацию для доступа к компоненту, не зависящую от выбора одного из двух представлений. Если способ реализации x'ов на некотором этапе разработки проекта будет изменен, то это не потребует изменений в модулях, использующих вызов f.
Мы рассмотрели пример принципа Унифицированного Доступа. В общем виде принцип можно сформулировать так:
Принцип Унифицированного Доступа
Все службы, предоставляемые модулем, должны быть доступны в унифицированной нотации, которая не подведет вне зависимости от реализации, использующей память или вычисления.
Этому принципу удовлетворяют немногие языки. Старейшим из них был Algol W, в котором как вызов функции, так и доступ к полю записывались в виде a(x). Первым из ОО-языков, удовлетворяющих Принципу Унифицированного Доступа, был язык Simula 67, использовавший обозначение x.f в обоих случаях. Нотация, предлагаемая в лекциях 7-18 этого курса, будет поддерживать такое соглашение.
Библиографические замечания
Первая публикация, обсуждающая проблемы повторного использования, упомянутая в начале этой лекции, принадлежит, по-видимому, Мак-Илрою (McIlroy's 1968 Mass-Produced Software Components). Его статья [McIlroy 1976] была представлена в 1968 г. на первой конференции по разработке ПО, созванной Комитетом НАТО по науке (NATO Science Affairs Committee). 1976 г. это дата издания трудов конференции, [Buxton 1976], публикация которых была задержана на несколько лет. Мак-Илрой пропагандировал развитие промышленного производства компонентов ПО.
Вот фрагмент его статьи:
| "Производство ПО в наши дни оказывается по уровню индустриализации ниже наиболее отсталых отраслей строительной промышленности. Я думаю, что его надлежащее место значительно выше, и хотел бы выяснить перспективы реализации методов массового производства ПО ...
Когда мы беремся за написание компилятора, то начинаем с вопроса: "Какой механизм работы с таблицами будем создавать?". А следует задавать вопрос: "Какой механизм будем использовать?" ... Я выдвигаю тезис о том, что у индустрии программ слабая основа отчасти в связи с отсутствием подотрасли производства программных компонентов... Такое производство компонентов могло бы быть весьма успешным." |
Одним из важных вопросов, рассмотренных в статье, был вопрос о необходимости иметь семейства модулей, обсуждавшийся выше как одно из требований к любому комплексному решению проблем повторного использования.
Наиболее важной характеристикой индустрии компонентов ПО является то, что она должна предлагать семейства [модулей] для выполнения заданной работы.
| В тексте Мак-Илроя использовалось слово "подпрограмма" (routine), а не "модуль"; в свете обсуждения, проведенного в этой лекции, этот термин является - с ретроспективным учетом тридцати лет последующей эволюции методов разработки ПО - слишком ограничительным. |
Специальный выпуск Transactions on Software Engineering, изданный Биггерстафом и Перлисом (Biggerstaff and Perlis) [Biggerstaff 1984], сыграл важную роль в привлечении внимания сообщества разработчиков ПО к вопросам повторного использования; смотрите в частности, в этом выпуске, статьи [Jones 1984], [Horowitz 1984], [Curry 1984], [Standish 1984] и [Goguen 1984].
Те же издатели включили все эти статьи (кроме первой из вышеупомянутых) в расширенный двухтомный сборник [Biggerstaff 1989]. Еще одним сборником статей по повторному использованию является [Tracz 1988]. Позже Трач (Tracz) собрал ряд своих материалов из IEEE Computer в полезную книгу [Tracz 1995], в которой особое значение придается организационным вопросам.
Один из подходов к повторному использованию, основанный на идеях искусственного интеллекта, воплощен в проекте Массачусетского технологического института по подготовке программистов (MIT Programmer's Apprentice project); смотрите статьи [Waters 1984] and [Rich 1989], воспроизведенные в первом и втором сборниках Биггерстафа-Перлиса, соответственно. Эта система использует не реальные повторно используемые модули, а шаблоны (называемые cliches and plans), представляющие общие стратегии разработки программы.
При обсуждении вопроса о пакетах упоминались три "языка с инкапсуляцией": Ada, Modula-2 и CLU. Язык Ada обсуждается в одной из последующих лекций, библиографический раздел которой содержит ссылки на языки Modula-2, CLU, а также Mesa and Alphard, причем два последних языка с инкапсуляцией принадлежат "модульному поколению" семидесятых и начала восьмидесятых годов прошлого века. Эквивалент пакета в языке Alphard был назван формой (form).
Важный проект STARS Министерства обороны США восьмидесятых годов прошлого века был акцентирован на проблеме повторного использования, особенно на организационных аспектах этой проблемы, причем в качестве языка для компонентов ПО использовался язык Ada. Ряд статей по этим вопросам можно найти в трудах конференции STARS DoD-Industry 1985 г. [NSIA 1985].
Двумя наиболее известными книгами по "образцам (шаблонам) проектов" являются [Gamma 1995] и [Pree 1994].
Работа [Weiser 1987] является призывом к распространению ПО в виде исходных текстов. Однако в этой статье недооценивается необходимость абстракции; как было показано в этой лекции, при необходимости можно сохранить возможность доступа к исходному тексту, но применить его высокоуровневую форму в качестве документации по умолчанию для пользователей модуля.
Из других соображений Ричард Сталлман (Richard Stallman), создатель Лиги Сторонников Свободы Программирования (League for Programming Freedom), утверждал, что представление в виде исходного текста всегда должно быть доступно; смотрите [Stallman 1992].
В работе [Cox 1992] описывается идея суперпоставки (superdistribution) Некоторая разновидность перегрузки имелась в языке Algol 68 [van Wijngaarden 1975]; в языках Ada (в котором это распространено на подпрограммы), C++ и Java, которые будут рассмотрены в последующих лекциях, этот механизм широко используется.
Универсальность или полиморфизм (genericity) появляется в языках Ada и CLU, и в ранней версии языка спецификаций Z [Abrial 1980]; в этой версии синтаксис Z близок к используемому для представления универсальности в этой книге. Язык LPG [Bert 1983], был явно предназначен для исследования универсальности. (Название этого языка является аббревиатурой из начальных букв "Language for Programming Generically".)
Работа, цитированная в начале этой лекции в качестве основной ссылки на табличный поиск, это [Knuth 1973]. Среди многих пособий по алгоритмам и структурам данных, которые освещают этот вопрос, стоит обратить внимание на [Aho 1974], [Aho 1983] или [M 1978].
Две книги автора данной книги содержат дальнейший анализ вопроса повторного использования. Книга Reusable Software [M 1994a], полностью посвященная этой теме, представляет принципы разработки и реализации для создания высококачественных библиотек, и полную спецификацию множества базисных библиотек. В книге Object Success [M 1995] обсуждаются организационные аспекты проблемы повторного использования, особенно те сферы деятельность, в которых должна прилагать усилия фирма, заинтересованная в повторном использовании, и области, в которых такие усилия будут, по-видимому, бесполезными (например, рекомендации повторного использования разработчикам приложений, или поощрение осуществления ими повторного использования). Смотрите также короткую статью на эту тему, [M 1996].
|
|
|
[Gamma 1995]; см также [Pree 1994].
2)
Компиляторы ISE формируют как код C, так и байт-код.
3)
В этой таблице индекс сокращенно обозначен как i, а курсор - как c.
4)
Этот подход будет рассмотрен подробно в лекции 15 курса "Основы объектно-ориентированного проектирования", с использованием понятия пакета из языка Ada. Напомним, что под "Ada" имеется в виду язык Ada 83. (В версии Ada 95 сохранены пакеты , но с некоторыми дополнениями.)
5)
Эта нотация, совместимая с нотацией, используемой в остальных лекциях этого курса, является скорее Ada-подобной, чем точно соответствующей языку Ada. Тип REAL в языке Ada называется FLOAT; точки с запятой здесь были удалены.
Цели повторного использования
Прежде всего, следует понять, почему так важно улучшать возможности повторного использования ПО. Здесь незачем обращаться к доводам типа "любовь к матери и яблочному пирогу". Как мы увидим, наша борьба за повторное использование преследует надлежащие цели, позволит избежать миражей, и принесет хороший доход от соответствующих инвестиций.
Что следует повторно использовать?
Убедив себя в том, что Повторное использование - Это Хорошо, осталось выяснить, как же этого добиться?
Первый возникающий вопрос - на каком уровне следует осуществлять повторное использование: персонала, спецификаций, проектов, их образцов, исходного кода, компонентов или абстрактных модулей.
Факторизация Общего Поведения
Если требование Независимости Представлений отражает позицию клиента - игнорирование внутренних деталей и вариантов реализации - то последнее требование отражает позицию разработчиков повторно используемых классов. Их цель в получении преимуществ от любой общности (commonality), которая может существовать в семействе или подсемействе реализаций.
Многообразие реализаций, имеющее место в некоторых проблемных областях, требует, как уже отмечалось, решения, основанного на семействе модулей. Часто это семейство настолько велико, что естественно поискать соответствующие подсемейства. В случае табличного поиска первая попытка классификации может привести к трем обширным подсемействам:
Таблицы, организуемые по некоторой схеме хеширования. Таблицы, организуемые как некоторая разновидность деревьев. Таблицы, организуемые последовательно.
Каждая из этих категорий охватывает много вариантов, но в большинстве случаев можно найти существенную общность между этими вариантами. Рассмотрим, например, семейство последовательных реализаций - таких, в которых элементы сохраняются и отыскиваются в порядке их первоначального включения в таблицу.

Рис. 4.1. Некоторые возможные реализации таблицы
Возможными представлениями последовательной таблицы являются массив, связный список и файл. Но независимо от варианта такой реализации, клиенты должны иметь возможность для любой последовательно организованной таблицы рассматривать ее элементы один за другим, перемещая (воображаемый) курсор, указывающий позицию элемента, рассматриваемого в настоящий момент. При таком подходе можно переписать подпрограмму поиска для последовательных таблиц в виде:
has (t: SEQUENTIAL_TABLE; x: ELEMENT): BOOLEAN is -- Содержится ли x в последовательной таблице t? do from start until after or else found (x) loop forth end Result := not after end
Это представление основано на использовании четырех подпрограмм, которые должны иметься в любой последовательной реализации таблицы(Подробно методика работы с курсором будет рассмотрена в лекции 5 курса "Основы объектно-ориентированного проектирования""Активные структуры данных" ("Active data structures"). ):
start (начать) , переместить курсор к первому элементу, если он имеется. forth (следующий) , переместить курсор к следующей позиции. after (после) , булев запрос, переместился ли курсор за последний элемент. found (x) , булев запрос, возвращающий true, когда курсор указывает на элемент, имеющий значение x.

Рис. 4.2. Последовательная структура с курсором
Несмотря на сходство с шаблоном подпрограммы, использованным в начале этого обсуждения, новый текст - это уже не шаблон, это настоящая подпрограмма, написанная в непосредственно исполняемой нотации (такая нотация используется в лекциях 7-18 этого курса). Если задать реализации для четырех операций start, forth, after и found, то можно откомпилировать и выполнить последнюю версию has.
Каждое представление последовательной таблицы требует соответствующего представления курсора. Три примера таких представлений основаны на работе с массивом, связным списком и файлом.
В первом из них используется массив из capacity элементов, и таблица занимает позиции от 1 до count + 1. (Последнее значение необходимо в случае, когда курсор переместился на позицию после ("after") последнего элемента.)

Рис. 4.3. Представление последовательной таблицы с курсором на основе массива
Во втором представлении используется связный список, в котором доступ к первому элементу обеспечивается по ссылке first_cell и каждый элемент связан со следующим по ссылке right. При этом курсор можно представить ссылкой cursor.

Рис. 4.4. Представление последовательной таблицы с курсором на основе связного списка
В третьем представлении используется последовательный файл, в котором курсор представляет просто текущую позицию чтения.

Рис. 4.5. Представление последовательной таблицы с курсором на основе последовательного файла
Реализация операций start, forth, after и found будет разной для каждого из вариантов.
В следующей таблице3)
показана реализация для каждого случая. Здесь t @ i означает i-й элемент массива t, который записывается как t [i] в языках Pascal или C; Void означает "пустую" ссылку; обозначение f- языка Pascal, для файла f, означает элемент в текущей позиции чтения из файла.
| Массив | i :=1 | i :=i + 1 | i >count | t @ i =x |
| Связный список | c := first_cell | c :=c. right | c =Void | c. item =x |
| Файл | rewind | read | end_of_file | f -=x |
Все варианты последовательной таблицы совместно используют функцию has, и отличаются только реализацией операций. Хорошее решение проблемы повторного использования требует, чтобы в такой ситуации текст has находился бы лишь в одном месте, связанном с общим понятием последовательной таблицы. Для описания каждого нового варианта не нужно больше беспокоиться о подпрограмме has; требуется лишь подготовить подходящие версии start, forth, after и found.
Фирмы по разработке ПО и их стратегии
У фирмы по разработке ПО всегда существует искушение создавать решения, преднамеренно не удовлетворяющие критериям повторного использования, из опасения не получить следующий заказ, - поскольку если возможности уже приобретенного решения окажутся излишне широкими, то покупателю следующий заказ не потребуется!
Мне довелось слышать в высшей степени откровенное высказывание по этому вопросу после моей лекции о повторном использовании и ОО-технологии.
Высокопоставленный администратор из крупной фирмы по поставкам ПО сказал мне, что хотя он сознает высокую ценность этих идей, но никогда не будет внедрять их в своей фирме, поскольку не хочет резать курицу, несущую золотые яйца. Более 90% доходов его фирма получает от "сдачи напрокат" личного состава, предоставляя заказчикам услуги своих аналитиков и программистов, и руководство фирмы стремится довести эту цифру до 100%. При таком отношении к разработке ПО навряд ли будет встречена с энтузиазмом перспектива появления общедоступных библиотек повторно используемых компонентов.
Это высказывание было примечательно своей откровенностью, но оно вызвало очевидное возражение: если вообще возможно создать повторно используемые компоненты, которые заменят некоторые дорогостоящие услуги консультантов из фирмы, поставляющей ПО, то рано или поздно кто-либо их создаст. А тогда фирма, отказывавшаяся пойти таким путем, и у которой не осталось ничего, кроме торговли услугами своих консультантов, может пожалеть о том, что, подобно испуганному страусу, зарыла голову в песок.
Технологическая составляющая (engineering part) в разработке ПО не идентична такой же составляющей в индустрии массового производства; человеческий фактор будет, вероятно, по-прежнему играть ключевую роль в процессе конструирования ПО.
Цель повторного использования состоит не в том, чтобы заменить людей инструментальными средствами (а это часто, несмотря на всяческие утверждения, происходит с другими отраслями производства), а в изменении соотношения между тем, что следует поручить людям, а что - инструментальным средствам.
Так что для фирмы, приобретшей известность за счет своих консультантов, эти нововведения не так уж плохи. В частности:
Во многих случаях разработчики, применяющие повторно используемые компоненты, могут по-прежнему успешно пользоваться помощью специалистов, которые посоветуют, как наилучшим образом применять эти компоненты. Тем самым сохраняется существенная роль фирм по поставкам ПО и их консультантов. Как будет показано ниже, возможность повторного использования неотделима от расширяемости: хорошие повторно используемые компоненты будут оставаться открытыми для адаптации к конкретным обстоятельствам. Консультанты фирмы, разработавшей соответствующую библиотеку программ, имеют идеальную возможность выполнять настройку компонентов для отдельных заказчиков. Так что продажа компонентов и продажа услуг не обязательно являются взаимно исключающими видами деятельности; торговля компонентами может служить основой для торговли услугами. Хорошая повторно используемая библиотека может играть стратегическую роль в политике преуспевающей фирмы по производству ПО, даже если фирма продает решения, а не библиотеку, используя ее лишь для внутренних целей. Такая библиотека может дать фирме конкурентное преимущество в более быстрой и дешевой разработке нестандартных решений, удовлетворяющих требованиям заказчиков, чем могли бы сделать конкуренты, не опирающиеся на такую заранее заготовленную основу.
Форматы для распространения повторно используемых компонентов
Еще одной задачей, охватывающей как технические, так и организационные проблемы, является выбор представления для распространения: исходный текст или двоичный формат? Это спорный вопрос, и мы ограничимся рассмотрением только нескольких доводов с обеих сторон.
Разработчики коммерческого ПО часто распространяют лишь описание интерфейса (соответствующая краткая форма (short form) рассматривается в одной из последующих лекций) и исполняемый код. Тем самым разработчики защищают секреты производства и свои инвестиции. ("Использование утверждений (assertions) для документирования: сокращенная форма класса", лекция 11)
Двоичный код и в самом деле является предпочтительной формой распространения коммерческих прикладных программ, операционных систем и других инструментальных средств, в том числе компиляторов, интерпретаторов и сред разработки для ОО-языков. Несмотря на непрекращающиеся нападки на такую концепцию, исходящие, в частности, от группы, называющейся Лигой Сторонников Свободного Программирования (League for Programming Freedom), маловероятно, что от такого способа распространения коммерческого ПО откажутся в ближайшем будущем. Но наше обсуждение относится не к обычным инструментальным средствам или прикладным программам: здесь рассматриваются библиотеки повторно используемых компонентов. В этом случае также могут быть найдены некоторые доводы в пользу распространения исходных текстов.
Для изготовителя программного компонента польза от распространения исходного текста состоит в том, что это облегчает перенос программ (porting efforts). Можно избежать утомительной и малорентабельной деятельности по адаптации ПО к множеству несовместимых платформ, существующих в современном компьютерном мире, рассчитывая на то, что разработчики ОО-компиляторов и программных сред выполнят эту работу за вас. (Для потребителя это, конечно, контраргумент, поскольку инсталляция исходного текста более трудоемка и может привести к непредвиденным ошибкам.)
|
Некоторые компиляторы создают вначале промежуточный код, который уже затем транслируется или интерпретируется на конкретной платформе. Это позволяет обеспечить мобильность ПО без полного доступа к исходному тексту. Если, как это часто бывает сейчас, в компиляторе формируется промежуточный код с использованием языка C, то вместо двоичного кода обычно можно поставлять переносимый код на языке C.2) Этот прием использовался на разных этапах истории создания ПО, начиная с языка UNCOL (UNiversal COmputing Language - универсальный язык программирования), предложенного в конце пятидесятых годов 20-го века. Для него был определен формат команд, интерпретируемых на любой платформе, и представляющих промежуточный код, создаваемый компилятором. В связи с этой проблематикой в 1988 г. был сформирован консорциум компаний по компьютерным техническим средствам и программному обеспечению (Advanced computer environment (ACE) consortium). Вместе с языком Java появилась понятие байт-кода Java-компилятора, для которого были разработаны интерпретаторы на многих платформах. Но для производителей компонентов вначале это привело к дополнительным трудозатратам. Необходима двойная гарантия того, что новый формат пригоден на любой платформе, представляющей практический интерес, и что не происходит потери эффективности выполнения промежуточного кода в сравнении с платформо-специфическим решением. Без этих гарантий нельзя будет отказаться от старой технологии и придется просто добавить новый формат кода к тем форматам, которые поддерживались ранее. Таким образом, решение, которое рекламируется как завершающее все проблемы переносимости, фактически на некоторое время порождает дополнительные проблемы переносимости. |
/p> Возможно, более важным доводом в пользу распространения текста исходного кода является то, что попытки защитить свои изобретения и секреты производства путем удаления исходного текста из реализации программного продукта могут не приносить никакой существенной пользы. Самая трудоемкая работа при составлении хорошей повторно используемой библиотеки связана с проектированием интерфейсов компонентов, а не с реализацией; и именно это вы вынуждены опубликовать. Это особенно очевидно в мире структур данных и алгоритмов, для которых почти все необходимые методы описаны в литературе по компьютерным наукам. Чтобы успешно создать библиотеку, требуется встроить эти методы в модули, интерфейс которых сделает их полезными для разработчиков многих других приложений. Такое проектирование интерфейса является частью того, что вы должны выпустить в свет.
Важно отметить, что в случае ОО-модулей имеются две формы повторного использования компонентов: клиентами класса и наследниками класса. Вторая из этих форм объединяет повторное использование с расширяемостью. Описание интерфейсов (краткая форма) достаточно для клиентов, но не всегда достаточно для повторного использования на основе наследования.
Наконец, о педагогической стороне проблемы. Распространение исходных текстов библиотечных модулей является средством представления лучших образцов разработки ПО, способствующее разработке потребителями ПО в соответствующем стиле. Возникающая при этом стандартизация является одним из достоинств повторного использования. В определенной степени это будет иметь место даже в случае, когда доступны лишь интерфейсы, но лучше всего иметь полный текст.(Этот вопрос обсуждается в лекции, посвященной обучению ОО-технологии, в лекции 11 курса "Основы объектно-ориентированного проектирования".)
| Заметьте, что даже если доступен исходный код, то он не должен служить в качестве основного средства документации: для этого по-прежнему будет использоваться интерфейс модуля. |
Как же справедливо вознаградить разработчиков за их достижения и обеспечить приемлемую степень защиты их изобретений, не нарушая законных интересов пользователей? Существуют две противоположные точки зрения:
С одной стороны, это принципы Лиги Сторонников Свободного Программирования (League for Programming Freedom): все ПО должно быть бесплатным и доступным в форме исходных текстов.(См. библиографические замечания.) С другой стороны, имеется идея суперпоставки (superdistribution), предложенная Брэдом Коксом (Brad Cox) в нескольких статьях и книге. Суперпоставка должна дать возможность пользователям свободно копировать программы, оплачивая не их приобретение, а каждое использование. Представьте себе небольшой счетчик, присоединенный к каждому программному компоненту, который "выбивает" сумму в несколько пенсов всякий раз, когда вы пользуетесь этим компонентом, и в конце каждого месяца предъявляет вам соответствующий счет. Это, по-видимому, исключает возможность распространения исходных текстов, так как тогда было бы очень просто удалить из программы команды счетчика. Японская ассоциация по развитию электронной промышленности JEIDA (Japanese Electronic Industry Development Association) работает над механизмами создания технических и программных компьютерных средств поддержки такой концепции. Сам Кокс недавно подчеркнул особую роль не столько технологических методов, а механизмов принуждения, основанных на соответствующих правовых нормах (наподобие авторского права). Пока идея суперпоставки вызывает множество технических, экономических и психологических вопросов.
Группирование Подпрограмм (Routine Grouping)
Шаблон подпрограммы has, даже если его полностью детализировать и ввести параметризацию типа, все еще не будет пригоден в качестве повторно используемого компонента. Поиск в таблице зависит от того, как таблица создавалась, как в нее включаются элементы, как они удаляются. Отдельно взятая программа поиска - это еще не модуль повторного использования. Самодостаточный, повторно используемый модуль должен включать множество подпрограмм, обеспечивающих каждую из упомянутых операций - создание, включение, удаление, поиск.
Эта идея лежит в основе формирования модуля как "пакета", что имеет место в языках с инкапсуляцией таких как: Ada, Modula-2 и родственных им языках. Более подробно об этом будет сказано ниже.
Изменчивость Реализаций (Implementation Variation)
Шаблон has является весьма общим; и, как мы уже убедились, на практике имеется широкий выбор соответствующих структур данных и алгоритмов. Нельзя ожидать, что один модуль сможет обеспечить работу в столь разнообразных условиях, - он оказался бы просто огромным. Для охвата всех возможных реализаций требуется семейство модулей.
Общая методика создания и применения повторно используемых модулей должна поддерживать идею семейства модулей.
Изменчивость Типов (Type Variation)
Шаблон подпрограммы has предполагает, что таблица содержит объекты типа ELEMENT. При уточнении этой подпрограммы в применении к частному случаю можно использовать конкретный тип, например INTEGER или BANK_ACCOUNT, для таблицы целых чисел или банковских счетов.
Но это не совсем то, что требуется. Повторно используемый модуль поиска должен быть применим ко многим различным типам элементов без того чтобы пользователи вынуждены были производить "вручную" изменения в тексте программы. Другими словами, необходимо средство для описания модулей, в которых типы выступают в роли параметров (type-parameterized), или короче - родовых (полиморфных) модулей. Универсальность или полиморфность (genericity) (способность модулей быть родовыми) окажется важной частью ОО-метода; обзор этой концепции дается далее в этой лекции. (См. "Универсальность" ("Genericity"), лекция 4)
Изменения и постоянство
Разработка ПО, как уже упоминалось, во многом связана с повторяемостью. Для понимания технической трудности повторного использования, следует понять природу повторяемости.
Несмотря на то, что программисты обычно время от времени повторяют одни и те же действия, но эти действия являются не совсем одинаковыми. Ведь если бы они были одинаковыми, то решение оказалось бы простым, по крайней мере, на бумаге. Однако на практике может измениться настолько много деталей задачи, что любая бесхитростная попытка обеспечить ее унификацию потерпит неудачу.
| Наглядной иллюстрацией являются работы норвежского художника Эдварда Мунка, многие из которых можно видеть в посвященном ему музее в Осло, на родине языка программирования Simula. Творчеством Мунка владели несколько жизненно-важных, глубоких тем: любовь, страдание, ревность, танец, смерть. Он без конца воспроизводил их в своих рисунках и живописи, пользуясь всякий раз одними и теми же образцами, но меняя технические приемы, цвета, резкость контуров, размер, освещение, настроение. |
В таком же положении находится и разработчик ПО, создавая новые варианты, развивающие одни и те же основные темы.
Возьмем пример, упоминавшийся в начале этой лекции: табличный поиск. Несомненно, алгоритм табличного поиска в общем виде всегда выглядит одинаково: начать с некоторой позиции в таблице t, затем приступить к последовательному просмотру таблицы, всякий раз проверяя, является ли искомым элемент в текущей позиции и, если это не так, то переходить к следующей позиции. Процесс завершается, если найден нужный элемент, либо проверка всех элементов оказалась безуспешной. Такая общая схема применима к многим возможным случаям представления данных и алгоритмам для табличного поиска, в том числе в массивах (отсортированных или не отсортированных), связных списках (отсортированных или не отсортированных), последовательных файлах, двоичных деревьях, Б-деревьях и различных хеш-таблицах.
Нетрудно превратить это неформальное описание в частично детализированную подпрограмму:
has (t: TABLE, x: ELEMENT): BOOLEAN is -- Присутствует ли x в t? local pos: POSITION do from pos := INITIAL_POSITION (x, t) until EXHAUSTED (pos, t) or else FOUND (pos, x, t) loop pos := NEXT (pos, x, t) end Result := not EXHAUSTED (pos, t) end
Некоторые пояснения к принятой здесь нотации: from ... until ... loop ... end описывает цикл, с начальным условием в предложении from, ни разу или повторно выполняющий действия предложения loop, и завершающийся при выполнении условия предложения until. Переменная Result содержит значение, возвращаемое функцией has. Если вы незнакомы с оператором or else (Оператор or else объясняется в лекции 13), то считайте, что здесь содержится просто логическое or.
Хотя приведенный выше текст описывает общую схему работы алгоритма, он не является непосредственно выполняемым, поскольку содержит некоторые не вполне определенные фрагменты (написанные заглавными буквами). Они соответствуют аспектам задачи табличного поиска, зависящим от выбранной реализации: тип элементов таблицы (ELEMENT), с какой позиции начинать поиск (INITIAL_POSITION), как переходить от текущей позиции к следующей (NEXT), как проверить наличие искомого элемента на некоторой позиции (FOUND), как определить, что все интересующие нас позиции уже проверены (EXHAUSTED).
Поэтому вышеприведенный текст является не столько подпрограммой, а шаблоном подпрограммы, который можно превратить в действующую подпрограмму, лишь после уточнения фрагментов, написанных заглавными буквами.
Ключевые концепции
Для разработки ПО характерна повторяющаяся деятельность, включающая частое использование общих образцов (common patterns). Но имеются существенные вариации того, как используются и комбинируются эти образцы, так примитивные попытки работать с компонентами, имеющимися в наличии, терпят неудачу. При практическом внедрении повторного использования возникают экономические, психологические и организационные проблемы. Последние связаны, в частности, с необходимостью создания механизмов индексации, хранения и поиска большого числа повторно используемых компонентов. Более важными являются технические проблемы: общепринятые представления о модулях недостаточны для серьезной поддержки повторного использования. Основным затруднением при осуществлении повторного использования является необходимость сочетать повторное использование с расширяемостью. Дилемма - "повторно использовать или переделать" неприемлема. Хорошее решение должно обеспечить возможность сохранить одни свойства повторно используемого модуля и адаптировать другие. Простые подходы к решению проблемы: повторное использование персонала, повторное использование проектов, повторное использование исходного кода, библиотеки подпрограмм привели к некоторому успеху, но не позволили полностью реализовать потенциальные достоинства повторного использования. Компонентом программы, пригодным для повторного использования, является абстрактный модуль, обеспечивающий инкапсуляцию функциональных возможностей с помощью хорошо определенного интерфейса. Пакеты обеспечивают лучшую реализацию метода инкапсуляции, чем подпрограммы, поскольку в них объединяются структура данных и связанные с ней операции. Два метода позволяют повысить гибкость пакетов: перегрузка подпрограмм и универсальность. Перегрузка подпрограмм является синтаксическим средством, которое не решает важных проблем повторного использования, но затрудняет читабельность текстов программ. Универсальность способствует повторному использованию, но решает лишь проблему изменчивости типов. Что же нам требуется: техника, помогающая поставщику учесть общность в группах взаимосвязанных реализаций структур данных; и техника, избавляющая клиентов от необходимости знать о том, какой вариант реализации выбран поставщиком.
Несколько слов об индексировании компонентов
На стыке технических и организационных проблем возникает вопрос: как следует связывать индексирующую информацию, например ключевые слова с программными компонентами?
Принцип Самодокументирования говорит о том, что вся информация о модуле, включая индексирующую информацию и другие виды документации, - должна содержаться в самом модуле. Это важное требование учтено при разработке нотации классов, развиваемой в лекциях 7-18 этого курса. Механизм предусматривает возможность подключения данных индексирования к каждому компоненту.
"Самодокументирование", лекция 3.
Описание соответствующей синтаксической структуры не вызывает затруднений. В начале текста модуля предлагается написать предложение индексирования (indexing clause) в виде
Indexing index_word1: value, value, value ... index_word2: value, value, value ... ... ... Стандартное описание модуля (см. лекции 7-18) ...
Здесь каждое index_word (то есть - индексное слово) это идентификатор; каждое value (то есть - значение) это константа (целая, вещественная и т. д.), идентификатор, или какой либо другой стандартный лексический элемент. (Более подробно см. "Операторы индексирования", лекция 8 курса "Основы объектно-ориентированного проектирования")
Конкретные ограничения на выбор индексных слов и соответствующих значений отсутствуют, но какая либо отрасль промышленности, ассоциация по вопросам стандартизации (standards group), организация или проектная группа может, при необходимости, определить свои правила. Средства индексирования и поиска могут затем извлекать эту информацию, чтобы помочь разработчикам ПО в отыскании компонентов, удовлетворяющих определенным критериям.
Как показало обсуждение проблемы Самодокументирования, сохранение такой информации в самом модуле - а не во внешнем документе или базе данных - уменьшает вероятность ввода ложной информации и, в частности, не позволит забыть об обновлении информации при корректировке модуля (или наоборот). Операторы индексирования, довольно простые на первый взгляд, существенно помогают разработчикам приводить в порядок свои программные средства и регистрировать их свойства с тем, чтобы и другие разработчики могли о них узнать.
Нетехнические препятствия
Почему же повторное использование еще не является общепринятым?
Наиболее серьезные препятствия к этому являются техническими; пути их преодоления будут обсуждаться в последующих разделах этой лекции (да и в остальных лекциях курса). Но, конечно, имеются также некоторые организационные, экономические и политические препятствия.
Независимость Представлений
Общая структура повторно используемого модуля должна позволять модулям-клиентам определять свои действия при отсутствии сведений о реализации модуля. Это требование называется Независимостью Представлений.
Предположим, что модулю-клиенту C некоторой прикладной системы (управления ресурсами банка, компилятора, системы географической информации) необходимо определить, содержится ли некоторый элемент x в некоторой таблице t (вкладов, слов языка, городов). Независимость Представлений для C означает возможность получить такую информацию с помощью обращения к подпрограмме
present := has (t, x)
не зная, какой вид имеет таблица t во время этого обращения. Автору модуля C нужно лишь знать, что t это таблица из элементов определенного типа, и что x означает объект того же типа. Ему безразлично, является ли t деревом двоичного поиска, хеш-таблицей или связным списком. Он должен иметь возможность сосредоточиться на своей задаче управления активами, компиляции или географии.
Выбор подходящего алгоритма поиска, основанного на реализации таблицы t, является делом лишь того модуля, который организует эту таблицу.
Модуль-клиент C, содержащий упомянутое обращение к подпрограмме, мог бы получить t от одного из своих собственных клиентов (в виде аргумента вызова подпрограммы). Тогда для C имя t является лишь абстрактным идентификатором структуры данных, к детальному описанию которой он и не может иметь доступа.
Можно рассматривать Независимость Представлений как расширение правила Скрытия Информации (инкапсуляции), существенное для беспрепятственной разработки больших систем: решения по реализации могут часто изменяться, и клиенты должны быть защищены от этого (См. "Скрытие информации", лекция 3). Но требование Независимости Представлений идет еще дальше. Если обратиться к его полномасштабным последствиям, то оно означает защиту клиентов модуля от изменений не только во время жизненного цикла проекта, но и во время выполнения - а это намного меньший временной интервал! В рассматриваемом примере, желательно, чтобы подпрограмма has адаптировалась автоматически к виду таблицы t во время выполнения программы, даже если этот вид изменился со времени последнего обращения к подпрограмме.
Выполнение требования Независимости Представлений поможет также реализовать связанный с ним принцип Единственного Выбора, сформулированный при обсуждении модульности, который предписывает избегать ситуаций, связанных с разбором вариантов, например
if "t это массив, управляемый хешированием" then "Применить поиск с хешированием" elseif "t это дерево двоичного поиска" then "Применить обход дерева двоичного поиска" elseif (и т.д.) end
Было бы в равной степени неудобно иметь такую структуру в самом модуле (нельзя же ожидать, что модуль, организующий таблицу, знает обо всех текущих и будущих вариантах), так и воспроизводить ее в каждом модуле-клиенте. (См. "Единственный выбор", лекция 3) Решение состоит в том, чтобы обеспечить автоматический выбор, осуществляемый системой исполнения. Такова будет роль динамического связывания (dynamic binding), ключевой составляющей ОО-подхода, которая подробно будет рассматриваться при обсуждении наследования. (См. "Динамическое связывание" ("Dynamic binding"), лекция 14)
Образцы проектов (design patterns)
В середине девяностых годов специалистов привлекла идея образцов (или шаблонов) проектов. Образец - это архитектурный принцип, применимый во многих прикладных областях; следуя образцу можно построить решение некоторой проблемы.(Образец проекта с историей команд рассмотрен в лекции 3 курса "Основы объектно-ориентированного проектирования".)
Вот типичный пример, подробно обсуждаемый в одной из последующих лекций. Проблема: как снабдить интерактивную систему механизмом, позволяющим ее пользователям отменить ранее выполненную команду, если они решат, что она была нецелесообразной, и повторить выполнение отмененной команды, если они передумают. Образец: использовать класс COMMAND определенной структуры (которую мы в последующем рассмотрим) и связанный с ней "список истории". Будут рассмотрены и многие другие образцы проектов.
Одной из причин успешного внедрения идеи образца проекта явилось то, что это была не просто идея: книга1), в которой впервые было предложено это понятие, и последовавшие за ней издания содержали каталог непосредственно применимых образцов, которые читатели могли изучать и использовать.
Образцы проектов уже внесли существенный вклад в развитие ОО-технологии, и по мере публикации все новых образцов они помогут разработчикам пользоваться опытом своих предшественников и современников. Как же этот общий принцип приложить к проблеме повторного использования? Образцы проектов не должны внушать надежду на возвращение к уже упоминавшейся ранее мысли о том, что "все что нужно - это только повторно использовать проекты". Образец, который по-существу представляет собой лишь сценарий образца (book pattern), пусть даже самый лучший и универсальный, является только "учебным пособием", а не инструментальным средством повторного использования. Как-никак, а в течении трех последних десятилетий учебники по компьютерным наукам рассказывают об оптимизации реляционных баз данных, AVL-деревьях (сбалансированных деревьях Адельсона-Вельского и Ландиса), алгоритме быстрой сортировки (Quicksort) Хоара, алгоритме Дейкстры для поиска кратчайшего пути в графе, без какого-либо упоминания о том, что эти мет оды совершили прорыв в решении проблемы повторного использования.
В определенном смысле, образцы, разработанные за последние несколько лет, являются лишь очередными дополнениями к набору стандартных приемов, используемых специалистами по разработке ПО. При таком понимании новым вкладом в ОО-технологию следует считать не идею образца, а сами предлагаемые образцы.
Обстоятельное рассмотрение проблемы образцов показывает, что эта точка зрения оказывается излишне ограниченной (См. "Программы с дырами", лекция 14). По-видимому, само понятие образца является действительно новым вкладом, даже если это еще не вполне осознанно. Но требуется дополнительная работа над образцами, чтобы выйти за пределы их чисто педагогической ценности. Удачный образец не может быть представлен лишь некоторым текстовым описанием - это должен быть компонент ПО или набор таких компонентов. На первый взгляд такая цель может представляться довольно отдаленной, поскольку многие из образцов являются настолько универсальными и абстрактными, что кажется невозможным реализовать их в виде программных модулей.
Но использование ОО-технологии обеспечивает радикальный вклад - она позволяет создавать повторно используемые модули, обладающие способностью изменяться. Они не будут "замороженными" элементами, а служат общими схемами, образцами, - здесь действительно уместен термин образец в полном смысле этого слова, они могут быть адаптированы к различным конкретным ситуациям. Это новое понятие мы называем классом, определяющим поведение (behavior class) (более образным является термин программы с дырами (programs with holes)). Это понятие, основанное на понятии отложенного (абстрактного) класса (deferred class), будет рассмотрено в последующих лекциях. Объединяя его с идей о группе компонентов, предназначенных для совместного функционирования - часто называемых каркасами (frameworks) или просто библиотеками - получаем замечательное средство, сочетающее повторное использование и способность к адаптации.
Оценка
При любом всестороннем подходе к проблемам повторного использования следует наряду с техническими аспектами рассмотреть организационные и экономические вопросы: как сделать повторное использование частью культуры разработки ПО, как найти правильную структуру стоимости и правильную форму распространения компонентов, создать соответствующие средства для индексирования и поиска компонентов. Неудивительно, что эти вопросы легли в основу основных инициатив по повторному использованию, исходивших от правительств и больших корпораций, таких как программа STARS (Software Technology for Adaptable, Reliable Systems - Технология создания ПО для адаптивных, надежных систем) Министерства обороны США и "фабрики ПО" ("software factories"), введенные в действие некоторыми большими японскими фирмами.
Являясь важными в долгосрочной перспективе, эти вопросы не должны отвлекать внимания от главных проблем, являющихся все еще техническими. Для успешной реализации возможностей повторного использования требуется создание правильных модульных структур и высококачественных библиотек, содержащих десятки тысяч компонентов, необходимых индустрии.
Оставшаяся часть данной лекции посвящена первому из этих вопросов. В ней выясняется, почему общепринятые понятия модуля непригодны для широкомасштабного повторного использования, и определяются требования, которым должно удовлетворять лучшее решение, предлагаемое в последующих лекциях.
Организация доступа к компонентам
Вот что говорят скептики: прогресс в производстве повторно используемых ПО приведет к тому, что разработчики окажутся "заваленными" настолько большим количеством компонентов и это так усложнит их жизнь, что лучше бы этих компонентов не было.
Это высказывание следует рассматривать как предупреждение разработчикам повторно используемых ПО о том, что лучшие в мире повторно используемые компоненты бесполезны, если никто не знает об их существовании, или если для их получения придется затратить слишком много времени и усилий. Для практического успеха методов повторного использования требуется создание соответствующих баз данных, содержащих компоненты, запрос к которым позволял бы быстро выяснить, удовлетворяет ли нужным потребностям какой-либо из существующих компонентов.
Должны быть доступны и сетевые услуги, позволяющие осуществить заказ и немедленную доставку по сети выбранных компонентов.
Достижение этих целей требует решения технических и организационных проблем. Индексирование, поиск и доставка повторно используемых компонентов - это технические проблемы, решаемые известными средствами, в частности методами, основанными на использовании баз данных. Очевидно, справляться с программными компонентами ничуть не сложнее, чем с данными о заказчиках, информацией об авиарейсах или с библиотечными книгами.
С созданием Всемирной паутины WWW появились мощные средства поиска, позволяющие намного проще размещать и отыскивать полезную информацию либо в Интернете, либо в корпоративной сети (Intranet). Несомненно, появятся и более совершенные решения (полученные, возможно, с помощью ОО-технологии). Из всего этого становится очевидным, что основной трудностью реализации повторного использования является не организация использования повторно используемых компонентов, а в первую очередь - создание этих чертовых штуковин.
Основные методы модульности: оценка
Мы получили два основных результата. Одним из них является идея создания единого синтаксического "жилища", такого как пакетная конструкция (package construct), для множества подпрограмм, все из которых работают с однородными объектами. Вторым результатом является универсальность, приводящая к более гибкой форме модуля.
Все это, однако, охватывает лишь две проблемы повторного использования, Группирование Подпрограмм и Изменчивость Типов, и оказывает некоторое содействие в решении оставшихся трех проблем - Изменчивости Реализаций, Независимости Представлений и Факторизации Общего Поведения. Универсальность, в частности, недостаточна для решения проблемы Факторизации, поскольку определяет лишь два уровня. У нас появляется универсальный модуль, параметризованный и, следовательно, открытый для изменений, но непосредственно не применимый. На другом уровне у нас есть отдельные родовые порождения, пригодные для непосредственного применения, но закрытые для дальнейших изменений. Это не позволяет уловить тонкие различия, которые могут существовать между конкурирующими представлениями заданной общей идеи.
Что касается Независимости Представлений, то здесь мы почти не продвинулись. Ни один из рассмотренных методов - не считая беглого знакомства с семантической перегрузкой - не позволяет клиенту пользоваться различными реализациями некоторого общего понятия, не имея сведений о том, какая реализация будет выбрана в каждом случае.
Для решения этих проблем нам понадобится вся мощь ОО-концепций.
Ожидаемые преимущества
Повторное использование может обеспечить прогресс на следующих направлениях:
Своевременность (timeliness) (в том смысле, который определен при обсуждении показателей качества: быстрота доведения проектов до завершения и продукции до рынка). При использовании уже существующих компонентов нужно меньше разрабатывать, а, следовательно, ПО создается быстрее. Сокращение объема работ по сопровождению ПО (decreased maintenance effort). Если кто-то разработал ПО, то он же отвечает и за его последующее развитие. Известен парадокс компетентного разработчика ПО: "чем больше вы работаете, тем больше работы вы себе создаете". Довольные пользователи вашей продукции начнут просить добавления новых функциональных возможностей, переноса на новые платформы. Если не надеяться "на дядю", то единственное решение парадокса - стать некомпетентным разработчиком, - чтобы никто больше не был заинтересован в вашей продукции. В этой книге подобное решение не поощряется. Надежность. Получая компоненты от поставщика с хорошей репутацией, вы имеете определенную гарантию, что разработчики предприняли все нужные меры, включая всестороннее тестирование и другие методы контроля качества. В большинстве случаев можно ожидать, что кто-то уже испытал эти компоненты до вас и обнаружил все возможно остававшиеся ошибки. Заметьте, вовсе не предполагается, что разработчики компонентов умнее вас. Для них создаваемые компоненты - будь то графические модули, интерфейсы баз данных, алгоритмы сортировки - это служебная обязанность, цель работы. Для вас это лишь второстепенная, рутинная работа, поскольку вашей целью является создание некоторой прикладной системы в вашей собственной области деятельности. Эффективность. Факторы, способствующие возможности повторного использования ПО, побуждают разработчиков компонентов пользоваться наилучшими алгоритмами и структурами данных, известными в их конкретной сфере деятельности. Однако в команде, разрабатывающей большой прикладной проект, трудно ожидать наличия специалистов по каждой проблеме, затрагиваемой в этом проекте.
При разработке большого проекта невозможно оптимизировать все его детали. Следует стремиться к достижению наилучших решений в своей области знаний, а в остальном использовать профессиональные разработки. Совместимость. Если использовать хорошую современную ОО-библиотеку, то ее стиль повлияет, за счет естественного "процесса диффузии", на стиль разработки всего ПО. Это существенно помогает повысить качество программного продукта. Инвестирование. Создание повторно используемого ПО позволяет сберечь плоды знаний и открытий лучших разработчиков, превращая временные ресурсы в постоянные.
Многие из тех, кто признает повторное использование желательным, имеют в виду лишь первый из факторов в этом списке, - повышение производительности. Но это не всегда самый важный вклад повторного использования в процесс разработки ПО. Повышение надежности, например, является не менее существенным фактором. Тоже можно сказать и об эффективности.
В этом отношении повторное использование можно рассматривать как особый показатель, отличающийся от других факторов, обсуждавшихся в лекции 1. Его улучшение дает возможность улучшить почти все остальные факторы качества ПО. А причина чисто экономическая: если элемент ПО служит не для одного, а для многих проектов, то экономически разумно использовать лучшие методы создания высококачественного ПО - формальную верификацию, всестороннюю оптимизацию. В обычных разработках от таких приемов зачастую отказываются как от ненужного излишества. Однако для повторно используемых компонентов аргументация существенно изменяется - улучшение всего лишь одного элемента может оказаться выгодным для тысяч разработок.
Конечно, эти рассуждения не являются совсем новыми - они отчасти представляют собой перенос на производство ПО тех идей, которые уже существенно затронули другие отрасли деятельности, когда они перешли от индивидуально изготовляемых изделий к индустрии массового производства. Изготовление чипа СБИС обходится значительно дороже, чем серийное изготовление простой специализированной схемы, но если он хорошо выполнен, то он проявит себя в бесчисленных компьютерных системах и повысит их качество благодаря всей вложенной в него раз и навсегда работе его конструкторов.
Пакеты
В семидесятые годы двадцатого века, в связи с развитием идей скрытия информации и абстракции данных, возникла необходимость в форме модуля, более совершенном, чем подпрограмма. Появилось несколько языков проектирования и программирования, наиболее известные из них: CLU, Modula-2 и Ada. В них предлагается сходная форма модуля, называемого в языке Ada пакетом, CLU - кластером, Modula - модулем. В нашем обсуждении будет использоваться термин пакет.4)
Пакеты - это единицы программной декомпозиции, обладающие следующими свойствами:
P1 В соответствии с принципом Лингвистических Модульных Единиц, "пакет" это конструкция языка, так что каждый пакет имеет имя и синтаксически четко определенную область. P2 Описание каждого пакета содержит ряд объявлений связанных с ним элементов, таких как подпрограммы и переменные, которые в дальнейшем будут называться компонентами (features) пакета.P3 Каждый пакет может точно определять права доступа, ограничивающие использование его компонентов другими пакетами. Другими словами, механизм пакетов поддерживает скрытие информации. P4 В компилируемом языке (таком, который может быть использован для реализации, а не только для спецификации и проектирования) поддерживается независимая компиляция пакетов.
Благодаря свойству P3, пакеты можно рассматривать как абстрактные модули. Их главным вкладом в программирование является свойство P2, удовлетворяющее требованию Группирования Подпрограмм. Пакет может содержать любое количество связанных с ним операций, таких как создание таблицы, включение, поиск и удаление элементов. И нетрудно увидеть, как решение, основанное на использовании пакета, будет работать в рассматриваемом здесь примере табличного поиска. Ниже - в системе обозначений, заимствованной из нотации, используемой в последующих лекциях этого курса для ОО-ПО - приводится набросок пакета INTEGER_TABLE_HANDLING, описывающий частную реализацию таблиц целых чисел, основанную на использовании двоичных деревьев:
package INTEGER_TABLE_HANDLING feature type INTBINTREE is record -- Описание представления двоичного дерева, например: info: INTEGER left, right: INTBINTREE end new: INTBINTREE is -- Возвращение нового инициализированного INTBINTREE.
do ... end has (t: INTBINTREE; x: INTEGER): BOOLEAN is -- Содержится ли x в t? do ... Реализация операции поиска ... end put (t: INTBINTREE; x: INTEGER) is -- Включить x в t. do ... end remove (t: INTBINTREE; x: INTEGER) is -- Удалить x из t. do ... end end -- пакета INTEGER_TABLE_HANDLING
Этот пакет содержит объявление типа (INTBINTREE), и ряда подпрограмм, представляющих операции над объектами этого типа. В данном примере не потребовалось описания переменных пакета (хотя в подпрограммах могут иметься локальные переменные).
Пакеты-клиенты теперь могут работать с таблицами, используя различные методы из INTEGER_TABLE_HANDLING. Введем синтаксическое соглашение, позволяющее клиенту пользоваться методом f из пакета, для чего позаимствуем нотацию из языка CLU: P$f. В нашем примере типичные фрагменты программного текста клиента могут иметь вид:
-- Вспомогательные описания: x: INTEGER; b: BOOLEAN -- Описание t типа, определенного в INTEGER_TABLE_HANDLING: t: INTEGER_TABLE_HANDLING$INTBINTREE -- Инициализация t новой таблицей, создаваемой функцией new пакета: t := INTEGER_TABLE_HANDLING$new -- Включение x в таблицу, используя процедуру put пакета: INTEGER_TABLE_HANDLING$put (t, x) -- Присваивание True или False переменной b, -- для поиска используется функция has пакета: b := INTEGER_TABLE_HANDLING$has (t, x)
Отметим необходимость введения двух связанных между собой имен: одного для модуля, здесь это INTEGER_TABLE_HANDLING, и одного для его основного типа данных, здесь это INTBINTREE. Одним из ключевых шагов к ОО-программированию явится объединение этих двух понятий. Но не будем опережать события.
| Менее важной проблемой является утомительная необходимость неоднократно писать имя пакета (здесь это INTEGER_TABLE_HANDLING). В языках, поддерживающих работу с пакетами, эта проблема решается с помощью различных сокращенных синтаксических конструкций (shortcuts), таких как, например, в языке Ada: |
end
Другим очевидным недостатком пакетов рассмотренного вида является их неспособность удовлетворять требованию Изменчивости Типов: приведенный выше модуль пригоден лишь для таблиц целых чисел. Однако, вскоре мы увидим, как устранить этот недостаток, делая пакеты универсальными (generic).
Механизм пакетов обеспечивает скрытие информации, ограничивая права клиентов на доступ к компонентам. Показанный выше клиент был в состоянии объявить одну из своих собственных переменных, используя тип INTBINTREE, взятый от своего поставщика, и вызывать подпрограммы, описанные этим поставщиком. Но он не имеет доступа ни к внутреннему описанию этого типа (к структуре record, определяющей реализацию таблиц), ни к телу подпрограмм (здесь это операторы do). Кроме того, можно скрыть от клиентов некоторые компоненты пакета (переменные, типы, подпрограммы), делая их используемыми только в тексте пакета.
| Языки, поддерживающие работу с пакетами, несколько различаются своими механизмами скрытия информации. Например, в языке Ada, внутренние свойства типа, такого как INTBINTREE, будут доступны клиентам, если не объявить тип как private (закрытый). |
Пакеты: оценка
По сравнению с подпрограммами, механизм пакетов приводит к существенному совершенствованию разбиения системы ПО на абстрактные модули. Собрать нужные компоненты "под одной крышей" крайне полезно как для поставщиков, так и для клиентов:
Автор модуля-поставщика может хранить в одном месте и совместно компилировать все элементы, относящиеся к некоторому заданному понятию. Это облегчает отладку и изменения. В отличие от этого, при использовании отдельных самостоятельных подпрограмм всегда есть опасность забыть произвести обновление некоторых подпрограмм при изменениях проекта или реализации; например, можно обновить new, put и has, но забыть обновить remove. Для авторов модулей-клиентов несомненно легче найти и использовать множество взаимосвязанных компонентов, если все они собраны в одном месте.
Преимущество пакетов по сравнению с подпрограммами особенно очевидно в таких случаях, как рассмотренный здесь пример с таблицей, где в пакете собраны все операции, применимые к конкретной структуре данных.
Однако пакеты все же не обеспечивают полного решения проблем повторного использования. Как уже отмечалось, они отвечают требованию Группирования Подпрограмм, но не удовлетворяют всем остальным требованиям. В частности, они не обеспечивают возможности факторизации общего поведения - "вынесения за скобки" общих компонентов. Заметим, что INTEGER_TABLE_HANDLING в нашем наброске текста пакета основывается на одном частном выборе реализации, - двоичных деревьев поиска. Конечно, благодаря скрытию информации, клиентам незачем интересоваться этим выбором. Но библиотека повторно используемых компонентов должна будет содержать модули для многих различных реализаций. Возникающую при этом ситуацию нетрудно предвидеть: типичная библиотека пакетов будет предлагать массу похожих, но вовсе не идентичных, модулей для заданной прикладной области, например, для работы с таблицами, но без какого-либо учета их общности. Обеспечивая возможность повторного использования для клиентов, такая методика приносит в жертву
возможность повторного использования со стороны поставщиков.
Но даже со стороны клиентов ситуация остается не вполне приемлемой. Каждое использование таблицы клиентом требует упомянутого выше объявления вида:
t: INTEGER_TABLE_HANDLING$INTBINTREE
Клиент вынужден выбирать конкретную реализацию. Этим нарушается требование Независимости Представлений: авторы модулей-клиентов должны будут знать больше о реализациях представлений модуля-поставщика, чем это принципиально необходимо.
Перегрузка и универсальность
Два технических приема - перегрузка (overloading) и универсальность (genericity) предлагают свои решения, направленные на достижение большей гибкости описанных выше механизмов. Рассмотрим, что же они могут дать.
Пять требований к модульным структурам
Как же найти такие модульные структуры, которые позволят создать компоненты, непосредственно готовые к повторному использованию, и, в то же время, допускающие возможность их адаптации?
Задача табличного поиска и шаблон подпрограммы has иллюстрируют жесткие требования, предъявляемые к любому решению. Можно воспользоваться этим примером для выяснения, что же следует предпринять для перехода от обнаружения относительно нечеткой общности вариантов к реальному набору повторно используемых модулей. Такой анализ выявляет пять важных проблем:
Изменчивость Типов (Type Variation). Группирование Подпрограмм (Routine Grouping). Изменчивость Реализаций (Implementation Variation). Независимость Представлений (Representation Independence). Факторизация Общего Поведения (Factoring Out Common Behaviors).
Подпрограммы
Классический подход к повторному использованию состоит в том, чтобы создавать библиотеки подпрограмм. Здесь термин подпрограмма (routine) означает программный элемент, который может быть вызван другими элементами для выполнения некоторого алгоритма, используя некоторые входные данные, создавая некоторые выходные данные, и, возможно, модифицируя другие данные. Вызывающий элемент передает свои входные данные (а иногда - выходные данные и модифицируемые данные) в виде фактических аргументов (actual arguments) . Подпрограмма может также возвращать выходные данные в виде результата; в этом случае она называется функцией.
Библиотеки подпрограмм успешно использовались в различных прикладных областях, в частности, для численных расчетов, где применение отличных библиотек привело к первым сообщениям об успехах повторного использования. Декомпозицию систем на подпрограммы, функциональную декомпозицию, обеспечивает также метод нисходящего (сверху вниз) программирования. Подход, основанный на использовании библиотек подпрограмм, хорошо работает в случаях, когда можно определить множество (возможно - большое) отдельных задач, при наличии следующих ограничений:
R1 Каждая задача допускает простую спецификацию. Точнее, возможно охарактеризовать каждую отдельную задачу небольшим набором входных и выходных параметров. R2 Задачи четко отличаются одна от другой, поскольку подход, основанный на подпрограммах, не позволяет воспользоваться возможной сколько-нибудь существенной их общностью - за исключением повторного использования некоторых конструкций. R3 Отсутствуют сложные структуры данных, которые пришлось бы распределять между использующими их подпрограммами.
Поиск в таблице является хорошим примером ограниченных возможностей подпрограмм. Мы уже убедились, что подпрограмма поиска сама по себе не содержит достаточного контекста, чтобы служить в качестве функционально-завершенного модуля повторного использования. Даже если не обращать внимания на этот недостаток, мы столкнемся с двумя в равной степени неприятными решениями:
Подпрограмма поиска существует в одном варианте. Но тогда, чтобы охватить все возможные ситуации, ей потребуется длинный список аргументов и она окажется очень сложной. Подпрограмм поиска много, каждая из которых относится к конкретному случаю и отличается от других лишь немногими деталями. Нарушается требование Факторизации Общего Поведения; возможные пользователи легко могут заблудиться в неразберихе подпрограмм.
В целом, подпрограммы являются недостаточно гибкими, чтобы удовлетворять потребностям повторного использования. Мы уже видели тесную связь между возможностью повторного использования и расширяемостью. Повторно используемый модуль должен быть открыт для расширения, но в случае подпрограммы единственным средством адаптации является передача аргументов. Это делает нас заложником дилеммы - Повторно использовать или Переделать: либо пользоваться этой подпрограммой в ее исходном виде, либо написать собственную подпрограмму.
Потребители и производители повторно используемых программ
В приведенном выше списке преимуществ можно выделить две ситуации - использование профессиональных или собственных компонентов. Первые четыре элемента списка описывают ситуацию использования существующих, профессионально разработанных компонентов. Последний элемент списка характеризует повторное использование собственного программного продукта. Элемент списка - совместимость - относится к обоим случаям.
Такое разграничение достоинств отражает два аспекта повторного использования: точку зрения потребителя, пользующегося продукцией разработчиков компонент, и точку зрения производителя, обеспечивающего возможность повторного использования своих разработок.
Для разработчиков ПО, еще не имеющих большого опыта, следует быть потребителями компонентов. Принципиально невозможно сразу приступать к производству повторно используемых программ. Единственно возможный путь стать производителем - состоит в изучении и копировании уже существующих хороших образцов. Такой подход сразу принесет свои полезные плоды, поскольку в своих разработках вы воспользуетесь достоинствами этих компонентов.
Дорога к Повторному использованию
Станьте потребителем повторного использования, прежде чем пытаться стать его производителем.
Повторяемость при разработке ПО
В поиске идеала абстрактного модуля следует рассмотреть суть процесса конструирования ПО. Наблюдая за разработкой, нельзя не обратить внимания на периодически повторяющиеся действия в этом процессе. Вновь и вновь программисты "сплетают" программу из множества стандартных элементов: сортировка, поиск, считывание, запись, сравнение, обход по дереву, - все повторяется. Опытным разработчикам знакомо это ощущение de_ja vu (дежавю - ощущение, что настоящее уже встречалось в прошлом), столь характерное для их профессии.
Чтобы оценить эту ситуацию (для тех, кто разрабатывает ПО или руководит такой разработкой), полезно ответить на следующий вопрос:
Сколько раз за последние шесть месяцев вы, или те, кто работает на вас, разрабатывали некоторый вариант табличного поиска?
| Табличный поиск понимается здесь как выяснение того, содержится ли заданный элемент x в таблице t. Эта задача имеет много вариантов в зависимости от типа элементов, структуры данных, представляющей t, а также выбранного алгоритма поиска. |
Вполне возможно, что вы или ваши коллеги многократно искали и находили собственное решение этой задачи. Наблюдатель со стороны посчитает табличный поиск легкодоступным и очевидным объектом применения повторно используемых компонентов. Ведь это одна из наиболее широко исследованных областей в компьютерных науках, которой посвящены сотни статей и многие книги, начиная с тома 3 знаменитого трактата Кнута. Базовый университетский курс по информатике на всех соответствующих факультетах включает в себя наиболее важные алгоритмы и структуры данных. Несомненно, в этой тематике нет ничего непостижимого. Кроме того:
Как уже отмечалось, вряд ли возможно создать полезную систему ПО, в которой не будут содержаться некоторые виды табличного поиска. Как будет подробнее показано ниже, большинство алгоритмов поиска следуют общему образцу, что, по-видимому, обеспечивает идеальную основу для повторно используемого решения.(См. библиографические ссылки в конце этой лекции.)
Повторное использование абстрактных модулей
Все предыдущие подходы, несмотря на их ограниченную применимость, осветили важные аспекты проблемы повторного использования:
Повторное использование персонала необходимо, но недостаточно. Наилучшие повторно используемые компоненты бесполезны при отсутствии хорошо подготовленных разработчиков, которые обладают достаточным опытом, чтобы распознать ситуацию, в которой может помочь использование уже существующих компонентов. Для повторного использования проектов необходимы не только готовые решения конкретных задач, но и достаточно высокий концептуальный уровень и универсальность повторно используемых компонентов. Классы, с которыми мы встретимся при обсуждении ОО-технологии, могут рассматриваться и как модули-проекты, так и как модули-реализации. Возможность повторного использования исходного кода служит напоминанием о том, что ПО в конечном счете определяется текстами программ. Разумная политика в области повторного использования должна приводить к созданию повторно используемых программных элементов.
Обсуждение позволило сузить область поиска подходящих единиц повторного использования. Такой единицей должен быть программный элемент (коллекция элементов). Он должен быть модулем приемлемого размера, удовлетворяющим требованиям модульности из предыдущей лекции. В частности, его связи должны быть строго ограничены, чтобы облегчить возможность независимого повторного использования. Информация, характеризующая возможности модуля, и составляющая первичную документацию для программистов, повторно его использующих (reusers), должна быть абстрактной: в соответствии с принципом Скрытия Информации она должна освещать лишь свойства, существенные для клиентов, а не описывать все детали модуля (как это делается в исходном коде).
Термин абстрактный модуль будет применяться к таким повторно используемым единицам (units of reuse), входящим в состав непосредственно применяемых ПО, доступ из внешнего мира к которым может осуществляться через описание, содержащее лишь подмножество свойств каждой единицы.
Далее в лекциях 3-6 этого курса предлагается строгое определение таких абстрактных модулей; а затем в лекциях 7-18 будут рассмотрены их свойства.
| Акцент на понятии абстрактности и отказ от использования исходного кода в качестве средства для повторного использования, вовсе не препятствует распространению модулей в виде исходных текстов (source form). Противоречие здесь только кажущееся: в данном обсуждении речь идет не о том, как будут поставляться модули программистам, повторно их использующим, а о том, что они будут использовать в качестве первоисточника информации о модулях. Может оказаться приемлемым, чтобы модуль распространялся в виде исходного текста, но повторно использовался на основе абстрактного описания его интерфейса. |
Повторное использование исходного текста
Несмотря на полезность повторного использования персонала, проектов и спецификаций, здесь не реализуется ключевая цель повторного использования. Если мы хотели бы найти программистский эквивалент повторно используемых деталей из других технических дисциплин, то это означало бы необходимость повторно использовать тот "хлам", из которого фактически состоит наша программная продукция: исполняемые программы.
Если так, то в какой же форме следует их использовать? Естественный ответ - в первоначальной форме: в виде исходного текста. В некоторых случаях такой подход оказался весьма эффективным. Например, совершенствование операционной системы Unix, первоначально распространявшейся по университетам и исследовательским лабораториям, стало возможным в основном благодаря наличию исходного кода, получаемого в режиме онлайн. Это позволило пользователям изучать, копировать и расширять сферу использования системы. То же справедливо и для круга пользователей Lisp.
Существуют экономические и психологические препятствия на пути к распространению исходных кодов. Более серьезными ограничениям являются:
Отождествление повторно используемого ПО с повторно используемым исходным текстом (source) исключает возможность скрытия информации. Следует иметь в виду, что повторное использование действительно больших проектов невозможно, если не предпринять систематических усилий по защите повторных пользователей от необходимости знания бесчисленных деталей. В сложных системах многие ее части могут не очевидным образом зависеть от других. Это часто затрудняет повторное использование отдельных элементов, приводя к необходимости повторно использовать и все остальное.
Удовлетворяющая требованиям модульности форма повторного использования должна устранить эти ограничения, поддерживая абстракцию и обеспечивая "мелкоструктурную" реализацию повторного использования.
Повторное использование персонала
Наиболее просто повторно использовать разработчиков, что широко практикуется в промышленности. Переводя разработчиков ПО с одного проекта на другой, фирмы избегают потери накопленного ими ранее опыта и обеспечивают его достойное применение в новых разработках.
Ввиду высокой текучести программистских кадров возможности такого подхода ограничены.
Повторное использование проектов и спецификаций
Этот подход является, по существу, более организованной версией предыдущего - повторного использования знаний, умений и опыта. Как показало обсуждение вопроса о документации, само представление проекта как независимого программного продукта, имеющего собственный жизненный цикл, независимый от соответствующей реализации, кажется сомнительным, поскольку трудно гарантировать, что проект и его реализация будут оставаться совместимыми в процессе изменения системы ПО.
Таким образом, если повторно использовать только проект, то возникает риск повторного использования неправильно работающих или уже вышедших из употребления элементов.
Эти замечания можно отнести и к другому смежному виду повторного использования: повторному использованию спецификаций.
Среди разработчиков ПО долгое время бытовала идея о том, что единственно заслуживающим внимания является повторное использование лишь проектов и спецификаций. Эта идея весьма существенно препятствовала продвижению вперед, поскольку означала, что создание компонентов направленно на удовлетворение лишь несущественных потребностей и не решает истинно трудных проблем. Прежде эта точка зрения была преобладающей; преодолеть ее удалось благодаря объединенному воздействию теоретических доводов (соображений ОО-технологии) и практических достижений (успешной реализации повторно используемых компонентов).
Термин "преодолеть" здесь является, пожалуй, слишком сильным, поскольку, как это часто бывает в подобных спорах, свою долю в достижение полезного результата внесли обе стороны. Идея повторного использования проектов становится намного более интересной при использовании подхода (такого, как точка зрения на ОО-технологию, развиваемая в этой книге), который существенно устраняет разрыв между проектом и его реализацией. Тогда разница между модулем и проектом модуля (design for a module) является не принципиальной, а лишь количественной: проект модуля это просто модуль, отдельные фрагменты которого еще не полностью реализованы; а полностью реализованный модуль можно использовать, благодаря средствам абстрактного представления, в качестве проекта модуля. При таком подходе различие между повторным использованием модулей (рассматриваемым ниже) и повторным использованием проектов постепенно исчезает.
Повторно использовать или переделать? (The reuse-redo dilemma)
Наличие всех этих вариантов выдвигает на первый план проблемы, возникающие при любой попытке размышлять над созданием модулей общего назначения в заданной прикладной области: как же воспользоваться наличием единого шаблона для согласования с таким большим числом различных вариантов? Это не только проблема реализации: почти так же трудно специфицировать модуль таким образом, чтобы модули-клиенты могли рассчитывать на взаимодействие с ним, не располагая его реализацией.
По этим соображениям обречены на неуспех простые решения проблемы повторного использования. Ввиду многосторонности и изменчивости ПО - не зря оно называется "soft - модули, не обладающие "гибкостью", не могут претендовать на возможность повторного использования.
"Замороженность" модуля приводит к дилемме - повторно использовать или переделать: повторно использовать модуль таким, какой он есть, или заново все переделать. Оба подхода слишком ограничительные. Типичная ситуация, когда существует модуль, обеспечивающий лишь частичное решение текущей задачи, и требуется адаптация модуля к конкретным потребностям. В этом случае желательно и повторно использовать и переделать: кое что повторно использовать, а кое что переделать - или, лучше всего, многое повторно использовать, а совсем немного переделать. Без способности объединения возможностей повторного использования и адаптации, методы повторного использования не могут удовлетворять практическим потребностям разработки ПО.
Поэтому не случайно почти любое обсуждение проблем повторного использования в этой книге затрагивает и проблему расширяемости (что приводит к охватывающему оба эти понятия термину "модульность", являющегося предметом обсуждения в предыдущей лекции). Всякий раз, когда вы начнете искать ответы на одно из этих требований, вы тут же столкнетесь и с другим требованием.
Такая взаимозависимость между повторным использованием и расширяемостью отмечалась ранее при обсуждении принципа Открыт-Закрыт. (См. "Принцип Открыт-Закрыт", лекция 3)
Поиску подходящего представления модуля посвящена оставшаяся часть этой лекции и несколько следующих лекций. Нам предстоит согласовать между собой возможность повторного использования и расширяемость, закрытость и открытость, постоянство и изменчивость. Нам следует удовлетворить сегодняшние потребности и попытаться отгадать, что же понадобится завтра.
Семантическая перегрузка (предварительное представление)
Описанную форму перегрузки подпрограмм можно назвать синтаксической перегрузкой. В ОО-подходе будет предложена намного более интересная методика, динамическое связывание, отвечающая целям Независимости Представлений. Динамическое связывание можно назвать семантической перегрузкой. При использовании этой методики и соответствующим образом подобранном синтаксисе можно записать некоторый эквивалент has (t, x) как запрос на выполнение.
Смысл такого запроса примерно таков:
|
Дорогой Компьютер (Hardware-Software Machine): Разберитесь, пожалуйста, что такое t; я знаю, что это должна быть таблица, но не знаю, какую реализацию этой таблицы выбрал ее создатель - и, откровенно говоря, лучше, если я останусь в неведении об этом. Как-никак, я занимаюсь не организацией ведения таблиц, а банковскими инвестициями [или компиляцией, или автоматизированным проектированием и т.д.]. Начальник над таблицами здесь кто-то другой. Так что разберитесь в этом сами и, когда получите ответ, поищите подходящий алгоритм для 'has', соответствующий этому конкретному виду таблицы. Затем используйте найденный алгоритм, чтобы установить, содержится ли 'x' в 't', и сообщите мне результат. Я с нетерпением ожидаю вашего ответа. С сожалением сообщаю вам что, кроме информации о том, что 't' это некоторого рода таблица, а 'x' это ее возможный элемент, вы не получите от меня больше никакой помощи. Примите мои дружеские пожелания, Искренне Ваш разработчик приложений. |
В отличие от синтаксической перегрузки, такая семантическая перегрузка является прямым ответом на требование Независимости Представлений. Все еще остается подозрение о нарушении принципа честности (non-deception), и ответом будет использование утверждений (assertions), задающих общую семантику подпрограммы, имеющей много различных вариантов (например, общие свойства, характеризующие has при всевозможных реализациях таблицы).
Поскольку для надлежащей работы механизма семантической перегрузки требуется использование всего ОО-аппарата, в частности - наследования, то понятно, что синтаксическая перегрузка является лишь полумерой. В ОО-языке, наличие синтаксической перегрузки наряду с динамическим связыванием может лишь приводить к путанице, как это происходит в языках C++ и Java, которые позволяют классу использовать несколько процедур с одним и тем же именем, возлагая разрешение неоднозначности вызовов на компилятор и человека, читающего текст программы.
Синдром NIH
Психологическим препятствием повторного использования является известный синдром: "Придумано Не Нами" (Not Invented Here или "NIH"). Говорят, что разработчики ПО являются индивидуалистами, предпочитающими все выполнять сами, не полагаясь на чужую работу.
Но на практике это не подтверждается. Разработчики ПО склонны к бесполезной работе не более других специалистов. Если имеется хорошее, широко известное и легкодоступное повторно используемое решение, то оно будет использовано.
Рассмотрим типичный случай лексического и синтаксического анализа. Намного проще создать программу грамматического анализа для командного языка или простого языка программирования, используя программные генераторы грамматического разбора (parser generators), например комбинацию известных программ Lex-Yacc, а не создавая все с нуля. Вывод очевиден: там, где инструментальные средства имеются, квалифицированные разработчики ПО повсеместно их используют.
В некоторых случаях имеет смысл создание собственного нестандартного анализатора, поскольку у упомянутых инструментальных средств имеются свои ограничения. Но обычно разработчики предпочитают обращаться к одному из этих средств. Это может привести к новому синдрому, противоположному синдрому NIH, который можно назвать синдромом "Привычки Препятствовать Нововведениям" (Habit Inhibiting Novelty или "HIN"). Повторно используемое решение, пусть даже полезное, но имеющее такие ограничения, которые сужают возможности разработчиков и подавляют внедрение новых идей, становится бесполезным. Попробуйте убедить кого-нибудь из разработчиков Unix'а использовать генератор грамматического разбора, отличающийся от Yacc, и вы можете на собственном опыте столкнуться с синдромом HIN.
Конечно, существует кое-что, напоминающее NIH, но часто это просто вполне понятная реакция осмотрительных разработчиков на новые и неизвестные компоненты. Они могут опасаться, что с ошибками или другими проблемами в новой для них программе труднее будет справиться, чем с решением, над которым они имеют полный контроль.
Часто такие опасения оправдываются неудачными прежними попытками повторного использования компонентов. Но если новые компоненты являются высококачественными и обеспечивают нормальное функционирование программы, то опасения быстро исчезают.
Таким образом, обеспечить высокое качество при создании повторно используемых компонентов существенно важнее, чем для других видов ПО.
Обозначим через N стоимость уникального решения, R - решения, основанного на повторно используемых компонентах. Значение R никогда не будет равно нулю: сюда войдут затраты на обучение, затраты на включение компонентов систему, понадобиться создать интерфейс вызова. Так что даже если экономия на повторном использовании и другие выгоды
r=(N - R)/ N
от повторного использования потенциально невелики, то придется все же убедить возможных "повторных пользователей" в том, что ради высокого качества повторно используемого решения стоит отказаться от желания полного контроля над всеми элементами системы.
| Этим объясняется, почему ошибочной целью является политика фирмы, направленная на работу с потенциальными повторными пользователями (потребителями, как их называют разработчики). Вместо этого следует ужесточить требования к производителям внешних компонентов, требуя гарантий качества и пригодности предлагаемой ими продукции. Разработчики прикладных систем будут использовать ваши компоненты не в связи с вашими рекомендациями, а потому, что вы хорошо потрудились над тем, чтобы повторно используемые компоненты было выгодно применять в прикладных программах. |
Синтаксическая перегрузка
Перегрузка - это связывание с одним именем более одного содержания. Наиболее часто перегружаются имена переменных: почти во всех языках программирования различные по смыслу переменные могут иметь одно и то же имя, если они принадлежат различным модулям (различным блокам - в языке Algol и подобных ему).
Для этого обсуждения более существенной является перегрузка подпрограмм, частным случаем которой является перегрузка операторов, которая позволяет использовать одинаковые имена для нескольких подпрограмм. Такая возможность почти всегда имеет место для арифметических операторов: одна и та же запись, a +b, означает различные виды сложения, в зависимости от типов a и b (целые, вещественные с обычной точностью, вещественные с удвоенной точностью). Начиная с языка Algol 68, в котором допускалась перегрузка основных операторов, некоторые языки программирования распространили возможность перегрузки на операции, определяемые пользователем, и на обычные подпрограммы.
Например, в языке Ada пакет может содержать несколько подпрограмм с одним и тем же именем, но с разной сигнатурой, определяемой здесь числом и типами аргументов. В общем случае сигнатура функций содержит также тип результата, но язык Ada разрешает перегрузку, учитывающую только аргументы. Например, пакет может содержать несколько функций square:5)
square (x: INTEGER): INTEGER is do ... end square (x: REAL): REAL is do ... end square (x: DOUBLE): DOUBLE is do ... end square (x: COMPLEX): COMPLEX is do ... end
Тогда при вызове square (y) тип аргумента y определит, какой вариант подпрограммы имелся в виду.
Подобным же образом, пакет может описывать набор функций поиска одинакового вида:
has (t: "SOME_TABLE_TYPE"; x: ELEMENT) is do ... end
Каждая из них задает свою реализацию и отличается фактическим типом, используемым вместо "SOME_TABLE_TYPE". Тип первого фактического аргумента, в любом клиентском вызове has, позволяет определить, какая из подпрограмм имелась в виду.
Из этих соображений следует общая характеризация перегрузки, которая будет полезной, когда несколько позже это свойство будет сопоставляться с универсальностью:
Роль перегрузки
Перегрузка подпрограмм является средством, предназначенным для клиентов. Она позволяет писать один и тот же текст, используя разные реализации некоторого понятия.
Так что же дает перегрузка подпрограмм решению проблемы повторного использования? Не много. Это - синтаксическое средство, освобождающее разработчиков от необходимости придумывать различные имена для разных реализаций некоторой операции и, по существу, перекладывает эту ношу на компьютер. Но это не решает ни одной из ключевых задач повторного использования. В частности, перегрузка не дает ничего для выполнения требования Независимости Представлений. Когда записывается вызов
has (t, x)
то необходимо будет объявить t, а следовательно (даже если скрытие информации освобождает вас от заботы о деталях каждого варианта алгоритма поиска) нужно точно знать, каков вид таблицы t! Единственной достоинством перегрузки является то, что во всех случаях можно пользоваться одним и тем же именем. Без перегрузки в каждой реализации потребуется другое имя, например
has_binary_tree (t, x) has_hash (t, x) has_linked (t, x)
Но является ли таки достоинством возможность избежать использования различных имен? Наверное нет. Основным правилом создания ПО, объектно оно или нет, является принцип честности (non-deception): различия в семантике должны отражаться в различиях текстов программ. Это позволяет существенно улучшить понятность ПО и минимизировать опасность возникновения ошибок. Если подпрограммы has являются различными, то использование для них одинакового имени может вводить в заблуждение - при чтении текста программы возникает предположение, что это одинаковые подпрограммы. Лучше предложить клиенту немного более многословный текст (как в случае введенных выше индивидуальных имен) и устранить какую-либо опасность путаницы.
Чем больше анализируешь перегрузку, тем более ограниченной она выглядит.
Критерий, используемый для устранения неоднозначности вызовов - сигнатуры списков аргументов - не обладает никакими конкретными достоинствами.
Он работает в приведенных выше примерах, где все различные перегружаемые процедуры square и has имеют разные сигнатуры, но нетрудно представить себе множество случаев, когда у разных вариантов сигнатуры совпадают. Одним из простейших примеров перегрузки, по-видимому, является множество функций системы компьютерной графики, используемых для создания новых точек, например в виде:
p1 := new_point (u, v)
Точку можно задать: декартовыми координатами x и y; или полярными координатами r и q (расстоянием от начала координат и углом, отсчитываемым от горизонтальной оси). Но если перегрузить функцию new_point, то возникнет затруднение, связанное с тем, что оба варианта имеют одинаковую сигнатуру:
new_point (p, q: REAL): POINT
Этот пример, да и многие подобные ему, показывает, что сигнатура типов может не устранять неоднозначность перегружаемых вариантов. Но ничего лучшего не было предложено.
| К сожалению, в относительно недавно появившемся языке Java используется описанная выше форма синтаксической перегрузки, в частности, для обеспечения альтернативных способов создания объектов. |
Техническая проблема
Как же должен выглядеть повторно используемый модуль?
Традиционные модульные структуры
Наряду с требованиями к модульности, изложенными в предыдущей лекции, пять требований Изменчивости Типов, Группирования Подпрограмм, Изменчивости Реализаций, Независимости Представлений и Факторизации Общего Поведения определяют, чего следует ожидать от наших повторно используемых компонентов - абстрактных модулей.
Рассмотрим решения, предшествовавшие ОО-подходу, чтобы понять, что нас не устраивает, и что следует взять с собой в ОО-мир.
Универсальность (genericity)
Универсальность - это механизм определения параметризованных шаблонов модулей (module patterns), параметры которых представляют собой типы. Это средство является прямым ответом на требование Изменчивости Типов. Оно устраняет необходимость использования многих модулей, таких как:
INTEGER_TABLE_HANDLING ELECTRON_TABLE_HANDLING ACCOUNT_TABLE_HANDLING
Вместо этого разрешается написать единственный шаблон модуля в виде:
TABLE_HANDLING [G]
Имя G, представляющее произвольный тип, и называется формальным родовым параметром (formal generic parameter). (Позже мы можем встретиться с необходимостью иметь два или более родовых параметров, но сейчас ограничимся одним.)
Такой параметризованный шаблон называется универсальным модулем (generic module), хотя это еще не настоящий модуль, а лишь общая схема - шаблон многих возможных модулей. Для получения фактического модуля из шаблона, следует задать некоторый тип, называемый фактическим родовым параметром. Модули, получаемые из шаблона заменой формального параметра G на фактический, записываются, например, в виде:
TABLE_HANDLING [INTEGER] TABLE_HANDLING [ELECTRON] TABLE_HANDLING [ACCOUNT]
Типы INTEGER, ELECTRON и ACCOUNT использованы, соответственно, в качестве фактических родовых параметров. Такой процесс получения фактического модуля из универсального модуля (шаблона модуля) называется родовым порождением (generic derivation), а сам модуль будет называться "универсально порожденным" (generically derived.).
| Два небольших замечания относительно терминологии. Во-первых, родовое порождение иногда называют родовой конкретизацией (generic instantiation), а порожденный модуль называют тогда родовым экземпляром (generic instance) Эта терминология может привести к недоразумениям в ОО-контексте, поскольку термин "экземпляр" применяется к объектам, созданные во время выполнения из соответствующих типов (или классов). Так что мы будем придерживаться термина "порождение".
Другим возможным источником недоразумений является слово "параметр". Подпрограмма может иметь формальные аргументы, представляющие значения, которые клиенты подпрограммы будут задавать при каждом обращении к ней. В литературе обычно используется термин "параметр" (формальный, фактический) как синоним аргумента (формального, фактического). Применение любого из этих терминов не является ошибкой, но мы, как правило, будем использовать термин "аргумент" для подпрограмм, а "параметр" для универсальных модулей. |
/p> Внутренне, описание унифицированного модуля TABLE_HANDLING будет напоминать приведенное выше описание INTEGER_TABLE_HANDLING, за исключением того, что для ссылки на тип элементов таблицы используется G вместо INTEGER. Например:
package TABLE_HANDLING [G] feature type BINARY_TREE is record info: G left, right: BINARY_TREE end has (t: BINARY_TREE; x: G): BOOLEAN -- Содержится ли x в t? do ... end put (t: BINARY_TREE; x: G) is -- Включить x в t. do ... end (и т.д.) end -- пакета TABLE_HANDLING
В этом подходе некоторое замешательство вызывает то обстоятельство, что тип, объявленный BINARY_TREE, хотелось бы сделать универсальным и объявить его как BINARY_TREE [G]. Нет очевидного способа достижения этой возможности при "пакетном" подходе. Однако объектная технология объединит понятия модуля и типа, так что проблема будет решена автоматически. Мы убедимся в этом, когда узнаем, как интегрировать универсальность (genericity) в ОО-мир.
Интересно сопоставить определение универсальности с приведенным ранее определением перегрузки:
Роль универсальности
Универсальность является средством, предназначенным для поставщиков. Она позволяет писать один и тот же текст, используя одну и ту же реализацию некоторого понятия, применяемую к различным видам объектов.
Как же универсальность способствует реализации целей этой лекции? В отличие от синтаксической перегрузки, универсальность дает реальный вклад в решение наших проблем, поскольку, как было отмечено выше, она обеспечивает выполнение одного из основных требований, Изменчивости Типов. И при изложении объектной технологии в лекциях 7-18 этого курса значительное внимание будет уделено универсальности.
