Адаптируемость с помощью библиотек
В течение ряда лет было предложено много механизмов параллельности, некоторые наиболее известные из них были рассмотрены в начале этой лекции. У каждого из них есть свои сторонники, и каждый может предложить наилучший подход к какой-либо проблемной области.
Поэтому важно, чтобы предлагаемый механизм смог бы поддержать хотя бы некоторые из известных механизмов. Более точно, предлагаемое решение должно позволять запрограммировать в его терминах другие параллельные конструкции.
И здесь ОО-метод проявляется с лучшей стороны. Один из наиболее важных аспектов этого метода состоит в том, что он поддерживает создание специальных библиотек для широко используемых схем. Имеющиеся для построения библиотек средства (классы, утверждения, ограниченная и неограниченная универсальность, множественное наследование, отложенные классы и др.) позволяют выразить многие параллельные механизмы в виде библиотечных компонентов. Некоторые примеры таких инкапсулированных механизмов уже были приведены в этой лекции (например, класс PROCESS и класс поведения для замков), в упражнениях будут предложены дополнительные примеры.
Вполне вероятно, что, используя и дополняя базисные средства, проектировщики построят множество библиотек, поддерживающих параллельные модели, удовлетворяющие специфическим требованиям и вкусам.
Мы также видели, как, используя такие библиотечные классы, как CONCURRENCY, можно уточнять базовую схему, задаваемую предложенным параллельным механизмом языка.
Активные объекты
Основываясь на приведенных выше аналогиях, в многочисленных предложениях параллельных ОО-механизмов было введено понятие "активного объекта". Активный объект - это объект, являющийся также процессом: у него есть собственная исполняемая программа. Вот как он определяется в одной книге по языку Java [Doug Lea 1996]:
Каждый объект является единой идентифицируемой процессоподобной сущностью (не отличающейся (?) от процесса в Unix) со своим состоянием и поведением.Однако это понятие приводит к тяжелым проблемам. Легко понять самую важную из них. У процесса имеется собственный план решения задачи: на примере с принтером видно, что он постоянно выполняет некоторую последовательность действий. А у классов и объектов дело обстоит не так. Объект не делает одно и то же, он является хранилищем услуг (компонентов порожденного класса) и просто ожидает, когда очередной клиент запросит одну из этих услуг - она выбирается клиентом, а не объектом. Если сделать объект активным, то он сам станет определять расписание выполнения своих операций. Это приведет к конфликту с клиентами, которые совершенно точно знают, каким должно быть это расписание: им нужно только, чтобы поставщик в любой момент, когда от него потребуется конкретная услуга, был готов немедленно ее предоставить!
Эта проблема возникает и в не ОО-подходах к параллельности и приводит к механизмам синхронизации процессов - иначе говоря, к определению того, когда и как каждый процесс готов общаться, ожидая, если требуется, готовности другого процесса. Например, в очень простой схеме производитель-потребитель (producer-consumer) может быть процесс producer, который последовательно повторяет следующие действия:
"Сообщает, что producer не готов" "Выполняет вычисление значения x" "Сообщает, что producer готов" "Ожидает готовности consumer" "Передает x consumer"и процесс consumer, который последовательно повторяет
"Сообщает, что consumer готов" "Ожидает готовности producer" "Получает x от producer" "Сообщает, что consumer не готов" "Выполняет вычисление, использующее значение x"Графически эту схему можно представить так

Рис. 12.1. Простая схема производитель-потребитель (producer-consumer)
Общение процессов происходит, когда оба они к этому готовы; это иногда называется handshake (рукопожатие) или rendez-vous (рандеву). Проектирование механизмов синхронизации - позволяющих точно выражать смысл команд "Известить о готовности процесса" или "Ждать готовности" - на протяжении нескольких десятилетий является плодотворной областью исследований.
Все это хорошо для процессов, являющихся параллельными эквивалентами традиционных последовательных программ, "делающих одну вещь". Параллельная система, построенная на процессах, похожа на последовательную систему с несколькими главными программами. Но при ОО-подходе мы уже отвергли понятие главной программы и вместо нее определили программные единицы, предоставляющие клиентам несколько компонентов.
Согласование этого подхода с понятием процесса требует тщательно проработанных конструкций синхронизации, когда каждый поставщик будет готов выполнить компонент, затребованный клиентом. Согласование должно быть особенно тщательным, когда клиент и поставщик являются активными объектами, придерживающихся своих порядков действий.
Изобретение механизмов, основанных на понятии активного объекта, вполне возможно, о чем свидетельствует обильная литература по этому предмету (в библиографических заметках к этой лекции приведено много соответствующих ссылок). Но это обилие свидетельствует о сложности предлагаемых решений, ни одно из которых не получило широкого признания, из чего можно заключить, что подход с использованием активных объектов сомнителен.
Библиотечные механизмы
При подходах типа ФУП программа приложения может быть никак не связана с конкретной физической параллельной архитектурой. Однако некоторым разработчикам ПО требуется более тонкий контроль, осуществляемый приложением (ценой возможного удорожания при динамической реконфигурации). Некоторые функции ФУП должны быть доступны непосредственно самому приложению, позволяя ему, например, выбрать для некоторого процессора определенный процесс или поток. Они будут доступны через библиотеки, как часть двухуровневой параллельной архитектуры; это не приведет ни к каким трудным проблемам. Позже в этой лекции мы еще столкнемся с необходимостью дополнительных библиотечных механизмов.
С другой стороны, некоторым приложениям может потребоваться неограниченное реконфигурирование во время исполнения. Тогда недостаточно иметь возможность прочесть ФУП или аналогичную информацию о конфигурации во время старта, а затем ее придерживаться. Но также плохо перечитывать информацию о конфигурации перед выполнением каждой операции, поскольку это убило бы эффективность. Снова разумное решение - использование библиотечного механизма: должна быть доступна процедура для динамического чтения информации о конфигурации, позволяющая приложению адаптироваться к новой конфигурации тогда (и только тогда), когда оно готово это сделать.
Компоненты класса CONCURRENCY позволяют в некоторых случаях считать, что условие выполнимости вызова S1 имеет место, даже если A_OBJ зарезервирован другим объектом ("обладателем") в случае, когда C_OBJ ("претендент") вызвал demand или insist; если в результате этого вызов становится выполнимым, то обладатель получает некоторое исключение. Это может произойти только, если обладатель находится в состоянии "готов уступить", в которое можно попасть, вызвав yield.
Для возврата в предопределенное состояние "неуступчивости" обладатель может выполнить retain; булевский запрос yielding позволяет узнать текущее состояние. Состояние претендента задается числовым запросом Challenging, который может иметь значения Normal, Demanding или Insisting.
Для возврата в предопределенное состояние Normal претендент может выполнить wait_turn. Различие между demand и insist заключается в том, что, если обладатель не находится в состоянии yielding, то при demand претендент получит исключение, а при insist он далее просто ожидает, как и при wait_turn.
Когда эти механизмы возбуждают исключение в обладателе или в претенденте, то булевский запрос is_concurrency_exception из класса EXCEPTIONS имеет значение "истина" (true).
Буфер - это сепаратная очередь
Нам нужен рабочий пример. Чтобы понять, что происходит с утверждениями, рассмотрим (понятие уже несколько раз неформально появляющееся в этой лекции) ограниченный буфер, позволяющий различным компонентам параллельной системы обмениваться данными. Производитель, порождающий объект, не должен ждать, пока потребитель будет готов его использовать, и наоборот. Взаимодействие происходит через разделяемую структуру - буфер. Ограниченный буфер может содержать не более maxcount элементов и поэтому может переполняться. При этом ожидание происходит только тогда, когда потребитель хочет получить элемент из пустого буфера или когда производителю нужно поместить элемент, а буфер полон. В хорошо отрегулированной системе с буфером такие события будут происходить гораздо реже, чем при взаимодействии без буфера, а их частота будет уменьшаться с ростом его размера. Правда, возникает еще один источник задержек из-за того, что доступ к буферу должен быть исключающим: в каждый момент лишь один клиент может выполнять операцию помещения в буфер (put) или извлечения из него (item, remove). Но это простые и быстрые операции, поэтому обычно общее время ожидания мало.
Как правило, порядок, в котором производятся объекты, важен для потребителей, поэтому буфер должен поддерживать дисциплину очереди "первым-в, первым-из (FIFO)".
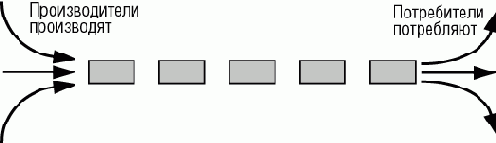
Рис. 12.8. Ограниченный буфер
Типичная реализация - несущественная для нашего рассмотрения, но дающая более конкретное представление о буфере - может использовать кольцевой массив representation размера capacity = maxcount + 1; число oldest будет номером самого старого элемента, а next - это индекс позиции, в которую нужно вставлять следующий элемент. Можно изобразить этот массив в виде кольца, в котором позиции 1 и capacity являются соседними (см. рис. 12.9).
Процедура put, используемая производителем для добавления элемента x, будет реализована как:
Representation.put (x, next); next := (next\\ maxcount) + 1где \\ - это операция получения остатка при целочисленном делении; запрос item, используемый потребителями для получения самого старого элемента, просто возвращает representation @ oldest (элемент массива в позиции oldest), а процедура remove просто выполняет oldest:= (oldest\\ maxcount) + 1.
Ячейка массива с индексом capacity ( на рисунке она серая) остается свободной; это позволяет отличить проверку условия пустоты empty, выражаемую как next = oldest, от проверки на полное заполнение full, выражаемой как (next\\ maxcount) + 1 = oldest.
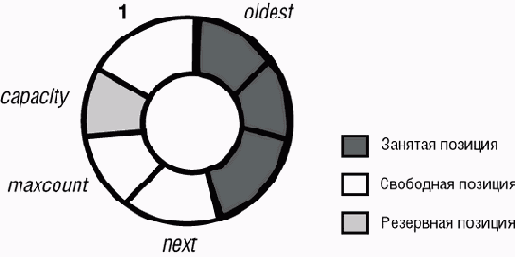
Рис. 12.9. Ограниченный буфер, реализованный массивом
Такая структура с политикой FIFO и представлением буфера в виде кольцевого массива, конечно, не является специфически параллельной: это просто ограниченная очередь, похожая на многие структуры, изученные в предыдущих лекциях. Нетрудно написать соответствующий класс, используя в качестве образца схему, использованную в лекции 3 для команды возврата Undo. Ниже представлена краткая форма этого класса в упрощенном виде (только основные компоненты и главные утверждения без комментариев заголовков):
class interface BOUNDED_QUEUE [G] feature empty, full: BOOLEAN put (x: G) require not full ensure not empty remove require not empty ensure not full item: G require not empty endПолучить из этого описания класс, задающий ограниченные буферы, проще, чем об этом можно было бы мечтать:
separate class BOUNDED_BUFFER [G] inherit BOUNDED_QUEUE [G] end
| Спецификатор separate относится только к тому классу, в котором он появляется, но не к его наследникам. Поэтому сепаратный класс может быть, как в данном случае, наследником несепаратного класса и наоборот. Соглашение такое же, как и для двух других спецификаторов, применимых к классам: expanded и deferred. Как уже отмечалось, эти три спецификатора являются взаимно исключающими, так что не более одного из них может появиться перед ключевым словом class. |
Допускается ли одновременный доступ?
Заключительное замечание относится к одному из важных свойств предложенного подхода - требованию, чтобы в каждый момент времени не более чем один клиент мог иметь доступ к каждому объекту-поставщику. Для VIP-клиентов предоставляется механизм дуэлей.
Причина запрета понятна: если бы некоторый клиент мог бы прервать в любой момент выполнение программы, запущенной его претендентом, то была бы потеряна возможность рассуждать о классах (используя свойства вида {INV and pre} body {INV and post}), поскольку прерванный претендент мог бы оставить объект в произвольном состоянии.
Такой недостаток исчез бы, если бы мы разрешили претендентам выполнять только программы весьма специального вида: аппликативные программы (в определенном в предыдущих лекциях для функций смысле), которые либо вовсе не изменяют объект, либо, изменяя его, устраняют все свои изменения перед тем, как его покинуть. Для этого нужен языковой механизм, позволяющий утверждать, что некоторая программа аппликативна, и компиляторы, обеспечивающие это свойство.
Доступ к сепаратным объектам
Сейчас у нас уже достаточно сведений, чтобы предложить подходящие механизмы синхронизации параллельных ОО-систем.
Но, как мы уже отмечали, это не всегда работает - по крайней мере, до тех пор, пока не обеспечен безопасный исключающий доступ к buffer. Иначе между моментом, когда проверяется условие для count и моментом, когда выполняется первое удаление remove, любой другой клиент может придти и удалить элемент, так что эта программа аварийно завершится, пытаясь применить remove к пустой структуре.
В следующем примере предполагается, что компонент item, не имеющий побочного эффекта, возвращает элемент, удаляемый компонентом remove:
if not buffer.empty then value := buffer.item; buffer.remove endБез защиты буфера buffer другой клиент может добавить или удалить элемент в промежутке между вызовами item и remove. В один прекрасный день автор этого фрагмента получит доступ к одному элементу, а удалит другой, так что можно, например, (при повторении указанной схемы) получить доступ к одному и тому же элементу дважды! Все это очень плохо.
Сделав buffer аргументом вызывающей подпрограммы, мы устраняем эти проблемы: гарантируется, что buffer будет зарезервирован на все время выполнения вызова подпрограммы.
Конечно, вина за ошибки в рассмотренных примерах лежит на невнимательных разработчиках. Но без правила сепаратного вызова такие ошибки совершаются легко. По-настоящему плохо то, что поведение во время выполнения становится недетерминированным, поскольку оно зависит от относительной скорости клиентов. Из-за этого ошибка будет блуждающей, сейчас в одном месте программы, при следующем запуске - в другом. Еще хуже то, что она, вероятно, будет проявляться редко: во всяком случае (в первом примере) конкурирующий клиент должен оказаться очень удачливым, чтобы протиснуться между проверкой count и первым вызовом remove. Поэтому такую ошибку очень трудно повторить и изолировать.
Такие коварные ошибки ответственны за кошмарную репутацию отладки параллельных систем. Всякое правило, существенно уменьшающее вероятность их появления, оказывает большую помощь разработчикам.
Учитывая правило сепаратного вызова, наши примеры следует записать в виде следующих процедур, использующих сепаратный тип BOUNDED_BUFFER:
remove_two (buffer: BOUNDED_BUFFER) is -- Удаляет два самых старых элемента do if buffer.count >= 2 then buffer.remove; buffer.remove end end get_and_remove (buffer: BOUNDED_BUFFER) is -- Присваивает самый старый элемент value и удаляет его do if not buffer.empty then value := buffer.item; buffer.remove end endЭти процедуры могут быть частью некоторого класса приложения; в частности, они могут быть описаны в классе BUFFER_ACCESS (ДОСТУП_К_БУФЕРУ), инкапсулирующем операции работы с буфером и служащем родительским классом для различных видов буферов.
Обе эти процедуры взывают о предусловии. Вскоре мы позаботимся о нем.
Дуальная семантика вызовов
При наличии нескольких процессоров мы сталкиваемся с необходимостью пересмотра обычной семантики основной операции ОО-вычисления - вызова компонента, имеющего один из видов:
x.f (a) -- если f - команда y := x.f (a) -- если f - запросПусть, как и раньше, O2 - объект, присоединенный в момент вызова к x, а O1 - объект, от имени которого выполняется вызов. (Иными словами, команда любого указанного вида является частью подпрограммы, имеющей цель O1).
Мы привыкли понимать действие вызова как выполнение тела f, примененного к O2 с использованием a в качестве аргумента и возвратом некоторого результата в случае запроса. Если такой вызов является частью последовательности инструкций:
... previous_instruction; x.f (a); next_instruction; ...(или ее эквивалента в случае запроса), то выполнение next_instruction не начнется до того, как завершится вызов f.
В случае нескольких процессоров дело обстоит иначе. Главная цель параллельной архитектуры состоит в том, чтобы позволить вычислению клиента продолжаться, не ожидая, когда поставщик завершит свою работу, если эта работа выполняется другим процессором. В приведенном в начале лекции примере с принтером приложение клиента захочет послать запрос на печать ("задание") и далее продолжить работу в соответствии со своим планом.
Поэтому вместо одной семантики вызова у нас появляются две:
Если у O1 и O2 один и тот же обработчик, то всякая следующая операция O1 (next_instruction) должна ждать завершения вызова. Такие вызовы называются синхронными.Если O1 и O2 обрабатываются разными процессорами, то операции O1 могут продолжаться сразу после того, как он инициирует вызов O2. Такие вызовы называются асинхронными.Асинхронный случай особенно интересен для выполнения команды, так как результаты вызова O2 могут вовсе не понадобиться или понадобиться оставшейся ее части гораздо позже. О1 может просто отвечать за запуск одного или нескольких параллельных вычислений и за их завершение. В случае запроса результат, конечно, нужен, например, выше его значение присваивается y, но ниже будет объяснено, как можно продолжать параллельную работу и в этом случае.
Дуэли и их семантика
Почти неизбежная метафора предполагает, что вместо терминологии "экспресс-сообщение" можно говорить о дуэли (в предшествующей эре к дуэли приводили попытки увести чью-либо законную супругу).
Пусть объект выполнил инструкцию:
r (b)для сепаратного b. После возможного ожидания освобождения b и выполнения сепаратного предусловия объект захватывает b, становясь его текущим владельцем. От имени владельца начинается выполнение r на b, но в некий момент времени, когда действие еще не завершилось, другой сепаратный объект, претендент, выполняет вызов:
s (c)Пусть сущность c сепаратная и присоединена к тому же объекту, что и b. В обычном случае претендент будет ждать завершения вызова r. Но что случится, если претендент нетерпелив?
С помощью процедур класса CONCURRENCY можно обеспечить необходимую гибкость. Владелец мог уступить, вызвав процедуру yield, означающую: "Я готов отдать свое владение более достойному". Конечно, большинство владельцев не будут столь любезны: если вызов yield явно не выполнен, то владелец будет удерживать то, чем владеет. Сделав уступку, владелец позже может от нее отказаться, вернувшись к установленному по умолчанию поведению, для чего использует вызов процедуры retain.
У претендента, желающего захватить занятый ресурс, есть два разных способа сделать это. Он может выполнить:
Demand означает "сейчас или никогда!". Непреклонный владелец (не вызвавший yield), ресурс не отдаст, и у претендента, не сумевшего захватить предмет своей мечты, возникнет исключение (так что demand - это своего рода попытка самоубийства). Уступчивый владелец ресурса отдаст его претенденту, исключение возникнет у него.Insist более мягкая процедура: вы пытаетесь прервать программу владельца, но, если это невозможно, то вас ждет общий жребий - ждать, пока не освободится объект.Для возврата к обычному поведению с ожиданием владельца претендент может использовать вызов процедуры wait_turn.
Вызов одной из этих процедур класса CONCURRENCY будет сохранять свое действие до тех пор, пока другая процедура его не отменит.
Отметим, что эти два набора не исключают друг друга. Например, претендент может одновременно использовать insist, требуя специальной обработки, и yield, допуская прерывание своей работы другими. Можно также добавить схему с приоритетами, в которой претенденты ранжированы в соответствии с приоритетами, но здесь мы не будем ее уточнять.
В следующей таблице показаны все возможные результаты дуэлей - конфликтов между владельцем и претендентом. По умолчанию считается, что процедуры из класса CONCURRENCY не вызываются (эти случаи в таблице подчеркнуты).
| retain | Претендент ждет | Исключение у претендента | Владелец ждет |
| yield | Претендент ждет | Исключение в программе владельца | Исключение в программе владельца |
Как вы помните, каждый вид исключений имеет свой код, доступный через класс EXCEPTIONS. Для выделения исключений, вызванных ситуациями из приведенной таблицы, класс предоставляет запрос is_concurrency_interrupt.
Импорт структур объекта
Одно из следствий правил корректности сепаратности состоит в том, что для получения объекта, обрабатываемого другим процессором, нельзя использовать функцию clone (из универсального класса ANY). Эта функция была объявлена как:
clone (other: GENERAL): like other is -- Новый объект с полями, идентичными полям other ...Поэтому попытка использовать y := clone (x) для сепаратного x нарушила бы часть 1-го правила: x, которая является сепаратной, не соответствует несепаратной other. Это то, чего мы и добивались. Сепаратный объект, обрабатываемый на машине во Владивостоке, может содержать (несепаратные) ссылки на объекты, находящиеся во Владивостоке. Если же его клонировать в Канзас Сити, то в результирующем объекте окажутся предатели - ссылки на сепаратные объекты, хотя в породившем их классе соответствующие атрибуты сепаратными не объявлялись.
Следующая функция из класса GENERAL позволяет клонировать структуру сепаратного объекта без создания предателей:
deep_import (other: separate GENERAL): GENERAL is -- Новый объект с полями, идентичными полям other ...Результатом будет структура несепаратного объекта, рекурсивно скопированная с сепаратной структуры, начиная с объекта other. По только что объясненной причине операция поверхностного импорта может приводить к предателям, поэтому нам нужен эквивалент функции deep_clone (см. лекцию 8 курса "Основы объектно-ориентированного программирования"), применяемый к сепаратному объекту. Таковым является функция deep_import. Она будет создавать копию внутренней структуры, делая все встречающиеся при этом копии объектов несепаратными. (Конечно, она может содержать сепаратные ссылки, если в исходной структуре были ссылки на объекты, обрабатываемые другими процессорами).
Для разработчиков распределенных систем функция deep_import является удобным и мощным механизмом, с помощью которого можно передавать по сети сколь угодно большие структуры объектов без необходимости писать какие-либо специальные программы, гарантирующие точное дублирование.
Экспресс сообщения
В параллельном языке ABCL/1 ([Yonezawa 1987a]) введено понятие "экспресс-сообщение" для тех случаев, когда объекту-поставщику нужно позволить обслужить "вне очереди" некоторого VIP-клиента, даже если он в данный момент занят обслуживанием другого клиента.
При некоторых подходах экспресс-сообщение прерывает нормальное сообщение, получает услугу, возобновляя затем нормальное сообщение. Для нас это неприемлемо. Ранее мы уже поняли, что в каждый момент на любом объекте может быть активизировано лишь одно вычисление. Экспресс-сообщение, как и всякий экспортируемый компонент, нуждается в выполнении инварианта в начальном состоянии, но кто знает, в каком состоянии окажется прерываемая программа, когда ее заставят уступить место экспресс-сообщению? И кто знает, какое состояние в этом случае будет создано в результате? Все это открывает дорогу к созданию противоречивого объекта. При обсуждении статического связывания в лекции 14 курса "Основы объектно-ориентированного программирования" это было названо "одним их худших событий, возникающих во время выполнения программной системы". Как мы тогда отметили, "если возникает такая ситуация, то нельзя надеяться на предсказание результата вычисления".
Тем не менее, это не означает полного отказа от экспресс-сообщения. Нам на самом деле может потребоваться прервать клиента либо потому, что появилось нечто более важное, что нужно сделать с зарезервированным им объектом, либо потому, что он слишком затянул владение объектом. Но такое прерывание - это не вежливая просьба отступить ненадолго. Это убийство или по меньшей мере попытка убийства. Устраняя конкурента, в него стреляют, так что он погибнет, если не сможет излечиться в больнице. В программных терминах прерывание, заданное клиентом, должно вызывать исключение, приводящее в итоге либо к смерти (fail), либо к излечению и повторной попытке (retry) выполнить свою работу.
При таком поведении подразумевается превосходство претендента над конкурентом. В противном случае, у него самого возникнут неприятности - исключение.
Конфликт активных объектов и наследования
Еще большие сомнения в правильности подхода, использующего активные объекты, появляются при его объединении с другими ОО-механизмами, особенно, с наследованием.
Если класс B является наследником класса A и оба они активны (т. е. описывают экземпляры, которые должны быть активными объектами), то что произойдет в B с описанием процесса A? Во многих случаях потребуется добавлять некоторые новые инструкции, но без специальных встроенных в язык механизмов это повлечет необходимость почти всегда переопределять и переписывать всю часть, относящуюся к процессу, - не очень привлекательное предложение.
Приведем пример одного специального языкового механизма. Хотя язык Simula 67 не поддерживает параллельность, в нем есть понятие активного объекта: класс Simula помимо компонентов содержит инструкции, называемые телом класса (см. лекцию 17). В теле класса A может содержаться специальная инструкция inner, не влияющая на сам класс, означающая подстановку собственного тела в потомке B. Так что, если тело A имеет вид:
some_initialization; inner; some_termination_actionsа тело B имеет вид:
specific_B_actionsто выполнение тела в B на самом деле означает:
some_initialization; specific_B_actions; some_termination_actionsХотя необходимость механизмов такого рода для языков, поддерживающих понятие активного объекта, не вызывает сомнений, на ум сразу приходят возражения. Во-первых, эта нотация вводит в заблуждение, поскольку, зная только тело B, можно получить неверное представление его выполнения. Во-вторых, это заставляет родителя предугадывать действия наследников, что в корне противоречит основополагающим принципам ОО-проектирования (в частности принципу Открыт-Закрыт) и годится только для языка с единичным наследованием.
Основная проблема останется и при другой нотации: как соединить спецификацию процесса в классе со спецификациями процессов в его потомках, как примирить спецификации процессов нескольких родителей в случае множественного наследования?
|
Позже в этой лекции мы увидим и другие проблемы, известные как "аномалия наследования", возникающие при использовании наследования с ограничениями синхронизации. |
Встретившись с этими трудностями, некоторые из ранних предложений по ОО-параллельности предпочли вообще отказаться от наследования. Хотя это оправдано, как временная мера, призванная помочь пониманию предмета путем разделения интересов, такое исключение наследования не может оставаться при окончательном выборе подхода к построению параллельного ОО-ПО; это было бы похоже на желание отрезать руку из-за того, что чешутся пальцы. (Для оправдания в некоторых источниках добавляют, что все равно наследование - это сложное и темное понятие, это - как сказать пациенту после операции, что иметь руку с самого начала было плохой идеей.)
Вывод, к которому мы можем придти, проще. Проблема не в ОО-технологии как таковой, и в частности, не в наследовании; она не в параллельности и даже не в комбинации этих идей. Источником неприятностей является понятие активного объекта.
Механизмы, основанные на синхронизации
Наиболее известный и элементарный механизм, основанный на синхронизации, - это семафор, средство блокировки для управления распределенными ресурсами. Семафор - это объект с двумя операциями: reserve (занять) и free (освободить), традиционно обозначаемыми P и V, но мы предпочитаем использовать содержательные имена. В каждый момент времени семафор либо занят некоторым клиентом, либо свободен. Если он свободен и клиент выполняет reserve, то семафор занимается этим клиентом. Если клиент, занявший семафор, выполняет free, то семафор становится свободным. Если семафор занят некоторым клиентом, а новый клиент выполняет reserve, то он будет ждать, пока семафор освободится. Эта спецификация отражена в следующей таблице:
| reserve | Занимается мной | Я жду | |
| free | Становится свободным |
|
Предполагается, что события, соответствующие пустым клеткам таблицы, не происходят, они могут рассматриваться как ошибки или как не вызывающие изменений. |
Правила захвата семафора после его освобождения, когда этого события ожидают несколько клиентов, могут быть частью спецификации семафора или вовсе не задаваться. (Обычно для клиентов выполняется свойство равнодоступности (fairness), гарантирующее, что никто не будет ожидать бесконечно, если получающий доступ к семафору обязательно его освобождает).
Это описание относится к бинарным семафорам. Целочисленный вариант допускает наличие одновременного обслуживания до n клиентов для некоторого целого n>0.
Хотя семафоры используются во многих практических приложениях, они сейчас считаются средствами низкого уровня для построения больших надежных систем. Но они дают хорошую отправную точку для обсуждения усовершенствованных методов.
Критические интервалы (critical regions) представляют более абстрактный подход. Критический интервал - это последовательность инструкций, которая может выполняться в каждый момент не более чем одним клиентом. Для обеспечения исключительного доступа к объекту a можно написать нечто вроде:
hold a then ... Операции с полями a ...end. Здесь критический интервал выделен ключевыми словами then... end. Только один клиент может выполнять критический интервал в каждый момент, другие клиенты, выполняющие hold, будут ждать.
Большей части приложений требуется общий вариант - условный критический интервал (conditional critical region), в котором выполнение критического интервала подчинено некоторому логическому условию. Рассмотрим некоторый буфер, разделяемый производителем, который может только писать в буфер, если тот не полон, и потребителем, который может только читать из буфера, если тот не пуст. Они могут использовать две соответствующие схемы:
hold buffer when not buffer.full then "Записать в буфер, сделав его непустым" end hold buffer when not buffer.empty then "Прочесть из буфера, сделав его неполным" endТакое взаимодействие между входным и выходным условиями требует введения утверждений и придания им важной роли в синхронизации. Эта идея будет развита далее в этой лекции.
Другим хорошо известным механизмом синхронизации, объединяющим понятие критического интервала с модульной структурой некоторых современных языков программирования, являются мониторы (monitor). Монитор - это программный модуль, похожий на модули Modula или Ada. Основной механизм синхронизации прост: взаимное исключение достигается на уровне процедур. В каждый момент времени только один клиент может выполнять процедуру монитора.
Интересно также понятие "путевого выражения" (path expression). Путевое выражение задает возможный порядок выполнения процессов. Например, выражение:
init ; (reader* | writer)+ ; finishописывает следующее поведение: вначале активизируется процесс init, затем активным может стать один процесс writer или произвольное число процессов reader; это состояние может повторяться конечное число раз, затем приходит черед заключительного процесса finish. В записи выражения звездочка (*) означает произвольное число параллельных экземпляров, точка с запятой (;) - последовательное применение, символ черты (|) - "или-или", (+) - любое число последовательных повторений.
Часто цитируемый аргумент в пользу путевого выражения заключается в том, что они задают процессы и синхронизацию раздельно, устраняя помехи, возникающие между описанием отдельных алгоритмических задач и составлением расписания их выполнения.
| Еще одна категория методов для описания синхронизации основана на анализе множества состояний, через которое может проходить система или ее компонент, и переходов между этими состояниями. В частности, сети Петри основаны на графическом описании таких переходов. Хотя такие методы достаточно понятны для простых устройств, они быстро приводят к комбинаторному взрыву числа состояний и переходов, и трудны для иерархического проектирования (независимой спецификации подсистем, а затем рекурсивного вложения их спецификаций в большие системы). Поэтому они вряд ли применимы к большим эволюционирующим программным системам. |
Механизмы, основанные на взаимодействии
Начиная с книги Хоара "Взаимодействующие последовательные процессы" (ВПП), появившейся в конце 70-х, большинство работ по не ОО-параллельности сосредоточено на подходах, основанных на взаимодействии.
Причину этого легко понять. Если решена проблема синхронизации, то все равно нужно искать способы взаимодействия параллельных компонентов. Но если разработан хороший механизм взаимодействия, то, скорее всего, решены и вопросы синхронизации: так как два компонента не могут взаимодействовать, если отправитель не готов послать, а получатель не готов принять информацию. Взаимодействие влечет синхронизацию. Чистая синхронизация может выглядеть как крайний случай взаимодействия с пустым сообщением. Общий механизм взаимодействия обеспечит необходимую синхронизацию.
Подход ВПП основан на взгляде: "Я взаимодействую, следовательно, я синхронизирую". Исходным пунктом является обобщение фундаментального понятия "вход-выход": процесс получает информацию v по некоторому "каналу" с помощью конструкции c ? v; он посылает информацию в канал с помощью конструкции c ! v. Передача информации по каналу и получение информации из него являются двумя примерами возможных событий.
Для большей гибкости ВПП использует понятие недетерминированного ожидания, представляемого символом |, позволяющее процессу ожидать нескольких возможных событий и выполнять действие, связанное с первым из случившихся. Рассмотрим систему, позволяющую клиентам банка получать сведения о состоянии их счетов и производить переводы средств на них, а менеджеру банка проверять, что происходит:
(balance_enquiry ? customer R (ask_password.customer ? password R (password_valid R (balance_out.customer ! balance) | (password_invalid R (denial.customer ! denial_message))) | transfer_request ? customer R ... | control_operation ? manager R ...)Система находится в ожидании одного из трех возможных входных событий: запроса о балансе (balance_enquiry), требования о переводе (transfer_request), контроля операции (control_operation).
Событие, произошедшее первым, запустит на выполнение поведение, описываемое с использованием тех же механизмов (справа от соответствующей стрелки).
В примере часть справа от стрелки заполнена только для первого события: после получения запроса о балансе от некоторого клиента, ему посылается сообщение запрос пароля (ask_password), в результате которого ожидаем получить пароль (password). Затем проверяется правильность пароля и клиенту посылается одно из двух сообщений: balance_out с балансом счета (balance) в качестве аргумента или отказ (denial).
После завершения обработки события система возвращается в состояние ожидания следующего входного события.
Первоначальная версия ВПП в значительной степени повлияла на механизм параллельности в языке Ada, чьи "задачи" являются процессами, способными ожидать несколько возможных "входов" посредством команды "принять" (см. лекцию 15). Язык Occam, непосредственно реализующий ВПП, является основополагающим программным средством для транспьютеров (transputer) семейства микропроцессоров, разработанных фирмой Inmos (сейчас SGS-Thomson) для создания высокопараллельных архитектур.
Минимальность механизма
ОО-конструирование ПО - это богатая и мощная парадигма, которая, как отмечалось в начале этой лекции, интуитивно выглядит готовой для поддержания параллельности.
Это существенно для достижения цели наименьшего возможного расширения. Минимализм здесь - это не просто вопрос проектирования красивого языка. Если параллельное расширение не минимально, то некоторые параллельные конструкции оказываются излишними для ОО-конструкций или будут с ними конфликтовать, делая задачу проектировщика более трудной или невыполнимой. Чтобы избежать такой ситуации, нам нужно найти наименьший синтаксический и семантический эпсилон, который предоставит нашим ОО-программам возможность параллельного исполнения.
Представленное в предыдущих параграфах расширение действительно является синтаксически минимальным, поскольку нельзя добавить меньше чем одно ключевое слово.
Многозадачность
Другой главной формой параллельности является многозадачность, когда один компьютер выполняет одновременно несколько заданий.
Если рассмотреть системы общего назначения (исключая процессоры, встроенные в оборудование от стиральных машин до самолетов и однообразно повторяющие фиксированный набор операций), то компьютеры почти всегда являются многозадачными, выполняя задачи операционной системы параллельно с задачами приложений. Строго говоря, параллелизм при многозадачности скорее мнимый, чем настоящий: в каждый момент времени процессор на самом деле выполняет одно задание, но время переключения с одного задания на другое столь коротко, что внешний наблюдатель может поверить в то, что они выполняются одновременно. Кроме того, сам процессор может делать некоторые вещи параллельно (как, например, в современных схемах выборки команд во многих компьютерах, когда за один такт одновременно с выполнением текущей команды загружается следующая) или может на самом деле быть комбинацией нескольких вычисляющих компонентов, так что многозадачность переплетается с мультипроцессорностью.
Обычным применением многозадачности является разделение времени компьютера (time-sharing), позволяющее одной машине обслуживать одновременно нескольких пользователей. Но, за исключением случая самых мощных компьютеров - "мэйнфреймов", эта идея сегодня представляется гораздо менее привлекательной, чем в те времена, когда компьютеры были большой редкостью. Сегодня наше время является более ценным ресурсом, поэтому хотим, чтобы система выполняла для нас несколько дел одновременно. В частности, многооконный интерфейс пользователя позволяет одновременно выполнять несколько приложений: в одном окне мы осуществляем поиск в Интернете, в другом - редактируем документ, а еще в одном компилируем и отлаживаем некоторую программу. Все это требует мощных механизмов параллельности.
Ответственность за предоставление каждому пользователю многооконного многозадачного интерфейса лежит на операционной системе.
Но все больше пользователей разрабатываемых нами программ хотят иметь параллельность внутри одного приложения. Причина все та же: они знают, что вычислительные мощности доступны в изобилии, и не хотят сидеть в пассивном ожидании. Так что, если получение пришедших по электронной почте сообщений требует много времени, то хотелось бы иметь возможность в это же время посылать исходящие сообщения. В хорошем Интернет-браузере можно получать доступ к новому сайту во время загрузки страниц из другого сайта. В системе биржевой торговли можно одновременно получать информацию с нескольких бирж, покупая в одном месте, продавая в другом и управляя портфелем клиента в третьем.
Именно эта необходимость распараллеливания внутри одного приложения неожиданно выдвинула область параллельных вычислений на передний край разработки ПО и вызвала интерес к ней, в кругах далеко выходящих за рамки первоначальных спонсоров. Между тем традиционные приложения параллельности не потеряли своего значения в новых разработках, относящихся к операционным системам, Интернету, локальным сетям и научным вычислениям - всюду, где непрерывный поиск скорости требует еще более высокого уровня многозадачности.
Мультипроцессорная обработка
Чем больше хочется использовать огромную вычислительную мощь, тем меньше хотелось бы ждать ответа компьютера (хотя мы вполне миримся с тем, что компьютер ждет нас). Поэтому, если один вычислитель не выдает требуемый результат достаточно быстро, то приходится использовать несколько вычислителей, работающих параллельно. Эта форма параллельности называется мультипроцессорной обработкой.
Впечатляющие приложения мультипроцессорности привлекли исследователей, надеющихся на работу сотен компьютеров, разбросанных по сети Интернет, в то время, когда их (по-видимому, согласные с этим) владельцы в них не нуждаются, к решению задач, требующих интенсивных вычислений, таких, например, как взлом криптографических алгоритмов. Такие усилия прилагаются не только в компьютерных исследованиях. Ненасытное требование Голливудом реалистичной компьютерной графики подбрасывает топливо в топку прогресса этой области: в создании фильма Toy Story, одного из первых, в котором играли только искусственные персонажи (люди их лишь озвучивали), участвовала сеть из сотни мощных рабочих станций - это оказалось более экономичным, чем привлечение сотни профессиональных мультипликаторов.
Мультипроцессорность повсеместно используется в высокоскоростных научных вычислениях при решении физических задач большой размерности, в инженерных расчетах, метеорологии, статистике, инвестиционных банковских расчетах.
Во многих вычислительных системах часто применяется некоторый вид балансирования нагрузки (load balancing):автоматическое распределение вычислений по разным компьютерам, доступным в данный момент в локальной сети некоторой организации.
Другой формой мультипроцессорности является вычислительная архитектура, называемая клиент-сервер (client-server computing), присваивающая разные роли компьютерам в сети: несколько самых крупных и дорогих машин являются "серверами", выполняющими большие объемы вычислений, работающими с общими базами данных и содержащими другие централизованные ресурсы. Более дешевые машины сети, расположенные у конечных пользователей, выполняют децентрализованные задания, обеспечивая интерфейс и проведение простых вычислений, передавая серверам все задачи, не входящие в их компетенцию, получая от них результаты решений.
|
Нынешняя популярность подхода клиент-сервер представляется колебанием маятника в направлении, противоположном тенденциям предыдущего десятилетия. В 60-х и 70-х архитектуры были централизованными, заставляя пользователей бороться за ресурсы. Революция, вызванная появлением персональных компьютеров и рабочих станций в 80-х, наделила пользователей ресурсами, ранее приберегаемыми Центром (на промышленном жаргоне "стеклянным домом"). Но вскоре стало очевидным, что персональный компьютер может далеко не все и некоторые ресурсы должны быть общими (разделяться). Это объясняет появление архитектуры клиент-сервер в 90-х. Постоянный циничный комментарий - мы возвратились к архитектуре нашей юности: одна центральная машина - много терминалов, только с более дорогими терминалами, называемыми сейчас рабочими станциями, - на самом деле, не вполне оправдан: промышленность просто ищет путем проб и ошибок подходящее соотношение между децентрализацией и разделением ресурсов. |
Мультипускатель
Приведем типичный пример, показывающий преимущества ожидания по необходимости. Предположим, что некоторый объект должен создать множество других объектов, каждый из которых далее живет сам по себе:
launch (a: ARRAY [separate X]) is -- Запустить для каждого элемента a require -- Все элементы a непусты local i: INTEGER do from i := a.lower until i > a.upper loop launch_one (a @ i); i := i + 1 end end launch_one (p: separate X) is -- Запустить для p require p /= Void do p.live endЕсли процедура live класса X описывает бесконечный процесс, то корректность этой схемы основана на том, что каждая итерация цикла будет выполняться сразу же после запуска launch_one, не ожидая, когда завершится этот вызов: иначе бы цикл никогда бы не ушел дальше его первой итерации. Эта схема будет далее использована в одном из примеров.
|
Читатели, знакомые с моделированием дискретных событий, основанным на сопрограммах, изучаемым в одной из следующих лекций, легко распознают схему, близкую к используемой, когда оператор языка Simula detach возвращает управление после запуска процесса моделирования. |
О правилах доказательств
Этот параграф предназначен для читателей, склонных к математике, остальные могут сразу перейти к обсуждению в следующем разделе. Хотя основные идеи можно понять и без формального освоения теории языков программирования, полное понимание требует знакомства хотя бы с основами этой теории, изложенными, например, в книге [М 1990], обозначения которой здесь будут использоваться.
Основное математическое свойство последовательного ОО-вычисления было полуформально приведено при обсуждении Проектирования по Контракту:
{INV and pre} body {INV and post}где pre, post и body - это предусловие, постусловие и тело программы, а INV - это инвариант класса. При подходящей аксиоматизации исходных инструкций оно может послужить основой полной формальной аксиоматической семантики ОО-ПО.
Выразим это свойство более строго в виде правила доказательства вызовов. Такое правило послужит фундаментом математического изучения ОО-ПО, поскольку стержнем всякого ОО-вычисления - последовательного, как раньше, или параллельного, рассматриваемого сейчас, - являются операции вида:
t.f (..., a, ...)вызывающие компонент f, возможно, с аргументами такими, как a, для цели t, присоединенной к объекту. Правило доказательства для последовательного случая можно содержательно сформулировать так:
|
Основной последовательный метод доказательства Если можно доказать, что тело f, запущенное в состоянии, удовлетворяющем предусловию f, завершит работу в состоянии, удовлетворяющем постусловию, то для указанного выше вызова можно вывести то же свойство, в котором формальные аргументы заменены фактическими. Каждый неквалифицированный вызов в утверждениях вида some_boolean_property заменяется соответствующим свойством t вида t.some_boolean_property. |
Например, если мы можем доказать, что конкретная реализация put в классе BOUNDED_QUEUE, запускаемая при выполнении условия not full, выдает состояние, удовлетворяющее not empty, то для любой очереди q и любого элемента a приведенное правило позволяет вывести:
{not q.full} q.put (a) {not q.empty}Более формально основное правило доказательства можно выразить, приспособив к ОО-вычислениям известное правило Хоара (Hoare) для доказательства вызовов процедур:

Здесь INV - инвариант класса, Pre (f) - множество предложений предусловия f, а Post (f) - множество предложений постусловия. Напомним, что утверждение является конъюнкцией набора предложений вида:
clause1; ...; clausenЗнаки больших "и" означают конъюнкцию всех предложений. Фактические аргументы f явно не указаны, но выражения со штрихами, такие как t.q' , означают подстановку фактических аргументов вызова вместо формальных аргументов f.
| Из соображений краткости правило приведено в форме, не поддерживающей доказательства вызовов рекурсивных процедур. Однако добавление такой поддержки никак не повлияет на наше обсуждение. Детали, связанные с рекурсией, можно найти в [M 1990]. |
Что изменится в параллельном случае? В предложении предусловия может появиться ожидание только для предусловий в виде t.cond, где t - это сепаратная сущность, являющаяся формальным аргументом подпрограммы, содержащей рассматриваемый вызов. В подпрограмме вида:
f (..., a: T, ...) is require clause1; clause2; ... do ... endлюбое из предложений предусловия, не содержащее сепаратный вызов на сепаратном формальном аргументе, является условием корректности: любой клиент должен обеспечить выполнение этого условия перед каждым вызовом, иначе вызов будет ошибочным. Всякое предложение предусловия, включающее вызов вида a.some_condition, в котором a является сепаратным формальным аргументом, является условием ожидания, которое будет блокировать вызов до своего выполнения.
Эти наблюдения можно выразить в виде правила доказательства, которое заменяет для сепаратного вычисления предыдущее последовательное правило:

где Nonsep_Pre (f) - множество предложений предусловия f, не содержащих сепаратных вызовов, а Nonsep_Post (f) - аналогичное множество для постусловия.
Это правило частично отражает суть параллельного вычисления. Для доказательства правильности программы все еще требуется доказать те же условия (в числителе), что и в последовательном правиле. Но следствия этого для свойств вызова различны: клиенту нужно обеспечивать меньше свойств перед вызовом, поскольку, как это подробно обсуждено выше, по меньшей мере бесполезно пытаться обеспечить выполнение сепаратной части предусловия; но и на выходе мы получаем меньше гарантированных утверждений. Первое отличие является хорошей новостью для клиента, а последнее - плохой.
Таким образом, сепаратные предложения предусловий и постусловий объединяются с инвариантом как свойства, которые должны быть включены во внутреннее доказательство правильности тела подпрограммы, но они не используются явно как свойства ее вызова.
Это правило также восстанавливает симметрию между предусловиями и постусловиями, дополняя обсуждение, в котором выделялась роль предусловий.
О том, что будет дальше в этой лекции
Представив механизм дуэлей, мы завершили определение набора инструментов, необходимых для реализации параллельности. В оставшейся части этой лекции приведен большой набор примеров для различных приложений, использующий эти инструменты. После примеров вы найдете:
набросок правил доказательства для читателей, склонных к математике;сводку средств предложенного механизма параллельности с его синтаксисом, правилами корректности и семантикой;обсуждение целей этого механизма и дальнейшей необходимой работы;подробную библиографию других работ в этой области.Обедающие философы

Рис. 12.11. Блюдо спагетти обедающих философов
Знаменитые "обедающие философы" Дейкстры - искусственный пример, призванный проиллюстрировать поведение процессов операционной системы, конкурирующих за разделяемые ресурсы, является обязательной частью всякого обсуждения параллелизма. Пять философов, сидящих за столом, проводят время в размышлениях, затем едят, затем снова размышляют и т. д. Чтобы есть спагетти, каждому из них нужны две вилки, лежащие непосредственно слева и справа от философов, что создает предпосылку для возникновения блокировок.
Следующий класс описывает поведение философов. Благодаря механизму резервирования объектов с помощью сепаратных аргументов в нем, по существу, отсутствует явный код синхронизации (в отличие от обычно предлагаемых в литературе решений):
separate class PHILOSOPHER creation make inherit GENERAL_PHILOSOPHER PROCESS rename setup as getup undefine getup end feature {BUTLER} step is -- Выполнение задач философа do think eat (left, right) end feature {NONE} eat (l, r: separate FORK) is -- Обедать, захватив вилки l и r do ... end endВсе, что связано с синхронизацией, вложено в вызов eat, который использует аргументы left и right, представляющие обе необходимые вилки, резервируя тем самым эти объекты.
Простота этого решения объясняется способностью резервировать несколько сепаратных аргументов в одном вызове, здесь это left и right. Если бы мы ограничили число сепаратных аргументов в вызове одним, то в решении пришлось бы использовать один из многих опубликованных алгоритмов для захвата двух вилок без блокировки.
Главная процедура класса PHILOSOPHER не приведена выше, поскольку она приходит из класса поведения PROCESS: это процедура live, которая по определению в PROCESS просто выполняет from setup until over loop step end, поэтому все, что требуется переопределить, это step. Надеюсь, вам понравилось переименование обозначения начальной операции философа setup в getup.
Благодаря использованию резервирования нескольких объектов с помощью аргументов описанное выше решение не создает блокировок, но нет гарантии, что оно обеспечивает равнодоступность.
Некоторые из философов могут организовать заговор, уморив голодом коллег. Во избежание такого исхода предложены разные решения, которые можно интегрировать в описанную выше схему.
Чтобы избежать смешения жанров, независящие от параллельности компоненты собраны в классе GENERAL_PHILOSOPHER:
class GENERAL_PHILOSOPHER creation make feature -- Initialization make (l, r: separate FORK) is -- Задать l как левую, а r как правую вилки do left := l; right := r end feature {NONE} -- Implementation left, right: separate FORK -- Две требуемые вилки getup is -- Выполнить необходимую инициализацию do ... end think is -- Любое подходящие действие или его отсутствие do ... end endОстальная часть системы относится к инициализации и включает описания вспомогательных абстракций. У вилок никаких специальных свойств нет:
class FORK end Класс BUTLER ("дворецкий") используется для настройки и начала сессии: class BUTLER creation make feature count: INTEGER -- Число философов и вилок launch is -- Начало полной сессии local i: INTEGER do from i := 1 until i > count loop launch_one (participants @ i); i := i + 1 end end feature {NONE} launch_one (p: PHILOSOPHER) is -- Позволяет начать актуальную жизнь одному философу do p.live end participants: ARRAY [PHILOSOPHER] cutlery: ARRAY [FORK] feature {NONE} -- Initialization make (n: INTEGER) is -- Инициализация сессии с n философами require n >= 0 do count := n create participants.make (1, count); create cutlery.make (1, count) make_philosophers ensure count = n end make_philosophers is -- Настройка философов local i: INTEGER; p: PHILOSOPHER; left, right: FORK do from i := 1 until i > count loop p := philosophers @ i left := cutlery @ i right := cutlery @ ((i \\ count) + 1 create p.make (left, right) i := i + 1 end end invariant count >= 0; participants.count = count; cutlery.count = count endОбратите внимание, launch и launch_one, используя образец, обсужденный при введении ожидания по необходимости, основаны на том, что вызов p.live не приведет к ожиданию, допуская обработку следующего философа в цикле.
Объекты здесь и там
Некоторые люди, впервые познакомившись с понятием сепаратной сущности, выражают недовольство тем, что оно чересчур детализировано: "Я не хочу знать, где расположен объект! Я хотел бы лишь запрашивать операцию x.f (...), а остальное пусть делает машинерия - выполняет f на x , где бы x не находился".
Будучи вполне законным, такое желание не устраняет необходимость в сепаратных декларациях. Действительно, точное положение объекта часто остается деталью реализации, не влияющей на ПО. Но одно "да-нет" свойство местоположения объекта остается существенным: обрабатывается ли один объект тем же процессором, что и другой. Оно задает важное семантическое различие, поскольку определяет, будут ли вызовы объекта синхронными или асинхронными - будет ли клиент ждать их завершения или нет. Пренебрежение этим свойством в ПО было бы не удобством, а ошибкой.
Если известно, что объект сепаратный, то в большинстве случаев на функционирование использующей его программы (но не на ее эффективности) не должно сказываться, с каким процессором он связан. Он может быть связан с другим потоком того же процесса, другим процессом на том же компьютере или на другом компьютере в той же комнате, в другой комнате того же здания, другим сайтом в частной сети фирмы или узлом Интернета на другом конце мира. Но то, что он сепаратный, существенно.
Обработка исключений: алгоритм "Секретарь-регистратор"
Приведем пример, использующий дуэли. Предположим, что некоторый управляющий объект-контроллер запустил несколько объектов-партнеров, а затем занялся своей собственной работой, для которой требуется некоторый ресурс shared. Но другим объектам также может потребоваться доступ к этому разделяемому ресурсу, поэтому контроллер готов в таком случае прервать выполнение своего текущего задания и дать возможность поработать с ресурсом каждому из них, а когда партнер отработает, контроллер возобновит выполнение прерванного задания.
Приведенное общее описание среди прочего охватывает и ядро операционной системы (контроллер), запускающее процессоры ввода-вывода (партнеры), но не ждущее завершения их операций, поскольку операции ввода-вывода выполняются на несколько порядков медленнее основного вычисления. По завершении операции ввода-вывода ее процессор требует внимания к себе и посылает запрос на прерывание ядра. Это традиционная схема управления вводом-выводом с помощью прерываний - проблема, давшая много лет назад первоначальный импульс изучению параллелизма.
Эту общую схему можно назвать алгоритмом "Секретарь-регистратор" по аналогии с тем, что наблюдается во многих организациях: регистратор сидит в приемной, приветствует, регистрирует и направляет посетителей, но кроме этого, он выполняет и обычную секретарскую работу. Когда появляется посетитель, регистратор прерывает свою работу, занимается с посетителем, а затем возвращается к прерванному заданию.
Возврат к выполнению некоторого задания после того, как оно было начато и прервано, может потребовать некоторых действий, поэтому приведенная ниже процедура работы секретаря передает в вызываемую ей процедуру operate значение interrupted, позволяющее проверить, запускалось ли уже текущее задание. Первый аргумент operate, здесь это next, идентифицирует выполняемое задание. Предполагается, что эта процедура является частью класса, наследника CONCURRENCY (yield и retain), и EXCEPTIONS (is_concurrency_interrupt). Выполнение процедуры operate может занять много времени, поэтому она является прерываемой частью.
execute_interruptibly is -- Выполнение собственного набора действий с прерываниями -- (алгоритм Секретарь-регистратор) local done, next: INTEGER; interrupted: BOOLEAN do from done := 0 until termination_criterion loop if interrupted then process_interruption (shared); interrupted := False else next := done + 1; yield operate (next, shared, interrupted) -- Это прерываемая часть retain; done := next end end rescue if is_concurrency_interrupt then interrupted := True; retry end endНекоторые из выполняемых контроллером шагов могут быть на самом деле затребованы одним из прерывающих партнеров. Например, при прерывании ввода-вывода его процессор будет сигнализировать об окончании операции и (в случае ввода) о доступности прочитанных данных. Прерывающий партнер может использовать объект shared для размещения этой информации, а для прерывания контроллера он будет выполнять:
insist; interrupt (shared); wait_turn -- Требует внимания контроллера, если нужно, прерывает его. -- Размещает всю необходимую информацию в объекте shared.По этой причине process_interruption, как и operate, использует в качестве аргумента shared: объект shared можно проанализировать, выявив информацию, переданную прерывающим партнером. Это позволит ему при необходимости подготовить одно из последующих заданий для выполнения от имени этого партнера. Подчеркнем, что в отличие от operate сама процедура process_interruption не является прерываемой; любому партнеру придется ждать (в противном случае некоторые заявки партнеров могли бы потеряться). Поэтому process_interruption должна выполнять простые операции - регистрировать информацию, требуемую для последующей обработки. Если это невозможно, то можно использовать несколько иную схему, в которой process_interruption надеется на сепаратный объект, отличный от shared.
Следует принять меры предосторожности. Хотя заявки партнеров могут обрабатываться позднее (с помощью вызовов operate на последующих шагах), важно то, что ни одна из них не будет потеряна. В приведенной схеме после выполнения некоторым партнером interrupt другой может сделать то же самое, стерев информацию до того, как у контроллера появится время для ее регистрации.
Такое нельзя допустить. Для устранения этой опасности можно добавить в класс, порождающий shared, логический атрибут deposited с соответствующими процедурами его установки и сброса. Тогда у interrupt появится предусловие not shared.deposited, и придется ждать, пока предыдущий партнер не зарегистрируется и не выполнит перед выходом вызов shared.set_deposited, а process_interruption перед входом будет выполнять shared.set_not_deposited.
Партнеры инициализируются вызовами по схеме "визитной карточки" вида create partner.make (shared, ...), в которых им передается ссылка на объект shared, сохраняемая для дальнейших нужд.
| Процедура execute_interruptibly должна быть расписана полностью с включением специфических для приложения элементов, представляемых вызовами подпрограмм operate, process_interruption, termination_criterion, которые в стиле класса поведения предполагаются отложенными. Это подготавливает возможное включение этих процедур в библиотеку параллелизма. |
Ограничение проверки правильности
Для устранения тупиков требуется наложить ограничение на предложения предусловий и постусловий. Предположим, что разрешены подпрограммы вида:
f (x: SOME_TYPE) is require some_property (separate_attribute) do ... endгде separate_attribute - сепаратный атрибут объемлющего класса. В этом примере, кроме separate_attribute, ничто не должно быть сепаратным. Вычисление предусловия f (как части мониторинга утверждений корректности либо как условия синхронизации, если фактический аргумент, соответствующий x, является сепаратным) может вызвать блокировку, когда присоединенный объект недоступен.
Эта ситуация запрещается следующим правилом:
|
Правило аргументов утверждения Если утверждение содержит вызов функции, то любой фактический аргумент этого вызова, если он сепаратный, должен быть формальным аргументом объемлющей подпрограммы. |
Отметим, что из этого правила следует, что такое утверждение не может появиться в инварианте класса, который не является частью подпрограммы.
Ограничения
Правило корректной сепаратности состоит из четырех частей и управляет правильностью сепаратных вызовов:
если источник присоединения (в инструкции присваивания или при передаче аргументов) является сепаратным, то его целевая сущность также должна быть сепаратной;если фактический аргумент сепаратного вызова имеет тип ссылки, то соответствующий формальный аргумент должен быть объявлен как сепаратный;если источник присоединения является результатом сепаратного вызова функции, возвращающей тип ссылки, то цель должна быть объявлена как сепаратная;если фактический аргумент или результат сепаратного вызова имеет развернутый тип, то его базовый класс не может содержать непосредственно или опосредованно никакой несепаратный атрибут ссылочного типа.Ранее не приведенное, простое правило корректности для типов утверждает: в описании separate TYPE базовый класс для TYPE не должен быть ни отложенным, ни развернутым.
Для правильности сепаратного вызова его целью должен быть формальный аргумент подпрограммы, включающей этот вызов.
Если утверждение содержит вызов функции, то любой фактический аргумент этого вызова, если он сепаратный, должен быть формальным аргументом объемлющего класса (правило аргументов утверждения).
Операции с объектом
Каждый компонент должен быть обработан (выполнен) некоторым процессором. Вообще, каждый объект O2 обрабатывается некоторым процессором - его обработчиком, обработчик ответственен за выполнение всех вызовов компонентов O2 (т. е. всех вызовов вида x.f (a), где x присоединен к O2).
Можно пойти дальше и решить, что обработчик связывается с объектом во время его создания и остается неизменным во время всей жизни объекта. Это предположение поможет получить простой механизм. На первый взгляд оно может показаться слишком жестким, так как некоторые распределенные системы должны поддерживать миграцию объектов по сети. Но с этой трудностью можно справиться двумя способами:
позволив переназначать процессору выполняющее его ЦПУ (при таком подходе все объекты, обрабатываемые некоторым процессором, будут мигрировать вместе);трактуя миграцию объекта как создание нового объекта.Организация доступа к буферам
Завершим рассмотрение примером ограниченного буфера, уже встречавшегося при описании механизма параллельности. Этот класс можно объявить как separate class BOUNDED_BUFFER [G] inherit BOUNDED_QUEUE [G] end в предположении, что имеется соответствующий последовательный класс BOUNDED_QUEUE .
Чтобы для сущности q типа BOUNDED_BUFFER [T] выполнить вызов вида q.remove, его нужно включить в подпрограмму, использующую q как формальный аргумент. Для этой цели полезно было бы разработать класс BUFFER_ACCESS (ДОСТУП_К_БУФЕРУ), инкапсулирующий понятие ограниченного буфера, а классы приложений могли бы стать его наследниками. В написании такого класса поведения нет ничего трудного. Он дает хороший пример того, как можно инкапсулировать сепаратные классы (непосредственно выведенные из последовательных, таких как BOUNDED_ QUEUE) для облегчения их непосредственного использования в параллельных приложениях.
indexing description: "Инкапсуляция доступа к ограниченным буферам" class BUFFER_ACCESS [G] is put (q: BOUNDED_BUFFER [G]; x: G) is -- Вставляет x в q, ожидая, при необходимости свободного места require not q.full do q.put (x) ensure not q.empty end remove (q: BOUNDED_BUFFER [G]) is -- Удаляет элемент из q, ожидая, при необходимости его появления require not q.empty do q.remove ensure not q.full end item (q: BOUNDED_BUFFER [G]): G is -- Старейший неиспользованный элемент require not q.empty do Result := q.item ensure not q.full end endОт процессов к объектам
Для поддержки этих захватывающих дух достижений, требующих параллельной обработки, нужна мощная программная поддержка. Как мы собираемся программировать эти вещи? Конечно, для этого предлагается ОО-технология.
Говорят, что Робин Мильнер (Robin Milner) воскликнул в 1991 на одном из семинаров ОО-конференции: "Я не могу понять, почему параллельность объектов [ОО-языков] не стоит на первом месте" (цитируется по [Matsuoka 1993]). Даже, если поставить ее на второе или на третье место, то остается вопрос, как придти к созданию параллельных объектов?
Если рассмотреть параллельную работу не в ОО-контексте, то она в большой степени основана на понятии процесса. Процесс - программная единица - действует как специализированный компьютер: он выполняет некоторый алгоритм, как правило, многократно, пока некоторое внешнее событие не приведет к его завершению. Типичным примером является процесс управления принтером, который последовательно повторяет:
"Ждать появления задания в очереди на печать" "Взять задание и удалить его из очереди" "Напечатать задание"Разные модели параллельности различаются планированием и синхронизацией, борьбой за ресурсы, обменом информацией. В одних языках параллельного программирования непосредственно описываются процессы, в других, таких как Ada, можно также описывать типы процессов, которые во время выполнения реализуются в процессах так же, как классы ОО-ПО реализуются в объектах.
Ожидание по необходимости
Предположим, что после ожидания необходимых сепаратных аргументов началось выполнение некоторого сепаратного вызова (например buffer.remove). Мы уже видели, что это не блокирует клиента, который может спокойно продолжать свои вычисления. Но, конечно, клиенту может потребоваться синхронизация с поставщиком, и для продолжения работы ему нужно дождаться завершения вызова.
Может показаться, что для этого нужен специальный механизм (он, действительно, был предложен в некоторых языках параллельного ОО-программирования, например в Hybrid) для воссоединения вычисления родителя с его расточительным вызовом. Но вместо этого можно использовать предложенную Денисом Каромелем (см. раздел "Библиографические заметки" этой лекции) идею ожидания по необходимости. Она состоит в том, чтобы ждать столько, сколько действительно необходимо.
Когда клиенту нужно точно знать, что вызов a.r (...) для сепаратной сущности a, присоединенной к сепаратному объекту O1, завершился? В тот момент, когда нужен доступ к некоторому свойству O1, требуется, чтобы объект был доступен, а все предыдущие его вызовы были завершены. До этого можно делать что-либо с другими объектами, даже запускать новый вызов процедуры a.r (...) на том же сепаратном объекте, поскольку, как мы видели, при разумной реализации можно просто ставить такие вызовы в очередь так, что они будут выполняться в порядке поступления.
Напомним, что компоненты подразделяются на команды (процедуры), выполняющие преобразование целевого объекта, и на запросы (функции и атрибуты), возвращающие информацию о нем. Завершения вызовов команд ждать не нужно, а завершения запросов - вполне возможно.
Рассмотрим, например, сепаратный стек s и последовательные вызовы:
s.put (x1); ...Другие инструкции...; s.put (x2); ... Другие инструкции ...; value := s.item(которые в соответствии с правилом сепаратного вызова должны входить в некоторую подпрограмму с формальным аргументом s). Если предположить, что ни одна из "Других инструкций" не использует s, то единственной инструкцией, требующей ожидания, является последняя; ей необходима информация о стеке - его верхнее значение (которое в данном случае должно равняться x2).
Эти наблюдения приводят к главному в понимании ожидания по необходимости: после запуска сепаратного вызова клиент должен ожидать его завершения, только если это вызов запроса. Более точная формулировка правила будет приведена ниже после рассмотрения практического примера.
Ожидание по необходимости (также называемое "ленивым ожиданием" и похожее на механизмы "вызова по необходимости" и "ленивого вычисления", знакомые лисповцам и студентам, изучающим теоретическую информатику) позволяет запускать произвольные параллельные вычисления, устраняя ненужные ожидания и гарантируя ожидание, когда это действительно требуется.
Парадокс предусловий
Только что обнаруженная ситуация может обеспокоить, поскольку, на первый взгляд, она показывает несостоятельность в параллельном контексте ключевой методологии проектирования по контракту. Для очереди при последовательных вычислениях у нас были полностью определены спецификации взаимных обязательств и преимуществ (аналогично стекам в лекции 11 курса "Основы объектно-ориентированного программирования"):
| Клиент | (Выполнить предусловие:) Вызывать put(x) только для непустой очереди | (Из постусловия:) Получить обновленную, непустую очередь с добавленным x |
| Поставщик | (Выполнить постусловие:) Обновить очередь, добавив x и обеспечив выполнение not empty | (Из постусловия:) Обработка защищена предположением о том, что очередь неполна |
Неявно за такими контрактами стоит принцип "отсутствия скрытых условий": предусловие является единственным требованием, которое должен выполнить клиент, чтобы получить результат. Если вы вызываете put с неполной очередью на входе, то вам предоставляется результат этой подпрограммы, удовлетворяющий ее постусловию.
Но в параллельном контексте при наличии сепаратных поставщиков, таких как BOUNDED_BUFFER, дела клиента складываются весьма плачевно: как бы мы не старались ублажить поставщика, обеспечивая выполнение требуемого им предусловия, мы никогда не можем быть уверены в том, что его пожелания удовлетворены! Однако выполнение предусловия необходимо для корректной работы поставщика. Например, вполне вероятно, что тело подпрограммы put из класса BOUNDED_QUEUE (то же, что и в классе BOUNDED_BUFFER) не будет работать, если не гарантирована ложность условия full.
Подведем итоги: поставщики не могут выполнять свою работу без гарантии выполнения предусловий, а клиенты не способны обеспечить выполнение этих предусловий для сепаратных аргументов. Это можно назвать парадоксом параллельных предусловий.
|
Имеется аналогичный парадокс постусловий: при возврате из сепаратного вызова put нельзя быть уверенным, что для клиента выполнено условие not empty и другие постусловия. Эти свойства имеют место сразу после завершения подпрограммы, но другой клиент может их нарушить прежде, чем вызывающий клиент продолжит работу. Поскольку проблема является более серьезной для предусловий, определяющих корректную работу поставщиков, то они и будут рассматриваться. |
Эти парадоксы возникают только для сепаратных формальных аргументов. Если аргумент не сепаратный, например, является значением развернутого типа, то можно продолжать рассчитывать на обычные свойства утверждений. Но это слабое утешение.
Хотя это еще не до конца осознано в литературе, парадокс параллельных предусловий является одним из центральных пунктов в конструировании параллельного ОО-ПО, а безрезультативность попыток сохранения обычной семантики утверждений является одним из главных факторов, отличающих параллельные вычисления от их последовательных вариантов.
|
Парадокс предусловий может также возникнуть и в ситуациях, когда обычно не думают о параллельности, например при доступе к файлу. Это изучается в упражнении У12.6. |
Параллельная архитектура
Использование объявлений separate для ответа на важный вопрос "этот объект находится здесь или в другом месте?", оставляя возможности различных физических реализаций параллельности, предполагает двухуровневую архитектуру (рис. 12.4), аналогичную той, которая подходит и для механизмов графики (с библиотекой Vision, находящейся выше библиотек, специфических для разных платформ, см. лекцию 14).
На верхнем уровне этот механизм не зависит от платформы. Большая часть приложений, рассматриваемых в этой лекции, использует этот уровень. Для выполнения параллельного вычисления приложения просто используют механизм объявлений separate.

Рис. 12.4. Двухуровневая архитектура механизма параллельности
Внутренняя реализация будет опираться на некоторую конкретную параллельную архитектуру (на рис. 12.4 это нижний уровень). На рис. 12.4 показаны следующие возможности:
Реализация может использовать процессы, предоставляемые операционной системой. Каждый процессор связывается с некоторым процессом. Такое решение поддерживает распределенные вычисления: процесс сепаратного объекта может находиться как на удаленной машине, так и на локальной. Для нераспределенной обработки его преимущество в том, что процессы стабильны и хорошо известны, а недостаток - в том, что оно приводит к интенсивной загрузке ЦПУ, так как и создание нового процесса, и обмен информацией между процессами являются дорогими операциями.Реализация может использовать потоки. Как уже отмечалось, потоки - это облегченная версия процессов, минимизирующая стоимость создания и переключения контекстов. Однако потоки должны располагаться на одной машине.Возможна также реализация, использующая механизм распределения CORBA в качестве физического уровня для обмена объектами в сети.Другими возможными механизмами являются ПВМ (PVM) (параллельная виртуальная машина - Parallel Virtual Machine), язык параллельного программирования Linda, потоки Java...Как всегда, в случае двухуровневых архитектур соответствие между конструкциями верхнего уровня и реальным распределением на уровне платформы (описателем (handle) в терминах предыдущей лекции) в большинстве случаев устанавливается автоматически, так что разработчики приложений будут видеть только верхний уровень. Но при необходимости и готовности отказаться от платформенной независимости им также должны быть доступны механизмы нижнего уровня.
Параллельная семантика предусловий
Для разрешения парадокса параллельных предусловий выделим три аспекта возникшей ситуации:
A1 Поставщикам нужны предусловия для защиты тел их подпрограмм. Например, put из классов BOUNDED_BUFFER и BOUNDED_QUEUE требует гарантии неполноты входной очереди.A2 Сепаратные клиенты не могут рассчитывать на обычную (последовательную) семантику предусловий. Проверка полноты full перед вызовом буфера еще не дает гарантий.A3 Так как каждый клиент может соперничать с другими за доступ к ресурсам, то клиент должен быть готов ждать получения требуемых ресурсов. Наградой за ожидание является гарантия корректной обработки.Отсюда неизбежен вывод: нам все еще нужны предусловия, но у них должна быть другая семантика. Они перестают быть условиями корректности, как в последовательном случае. Примененные к сепаратным аргументам они становятся условиями ожидания. Их можно назвать "предложениями сепаратного предусловия" и они применяются ко всякому предложению предусловия, содержащему вызов, целью которого является сепаратный аргумент. Типичным предложением сепаратного предусловия является not b.full для put.
Вот соответствующее правило:
|
Семантика сепаратного вызова Прежде чем начать выполнение тела подпрограммы, сепаратный вызов должен дождаться момента, когда будут свободны все блокирующие объекты и будут выполнены все предложения сепаратного предусловия. |
В этом определении объект называется блокирующим, если он присоединен к некоторому фактическому аргументу, а соответствующий формальный аргумент используется в подпрограмме в качестве цели хотя бы одного вызова.
Сепаратный объект является свободным, если он не используется в качестве фактического аргумента никакого сепаратного вызова (откуда следует, что на нем не исполняется никакая подпрограмма).
Это правило требует ожидания только для сепаратных аргументов, появляющихся в теле подпрограммы в качестве цели вызова (в нем для соответствующих объектов использовано слово "блокирующий", поскольку они могут заблокировать ее вызов в процессе выполнения).
Для программы в виде "визитной карточки":
r (x: separate SOME_TYPE) is do some_attribute := x endили в каком- либо другом виде, не содержащем вызова вида x.some_routine, не требуется ждать фактического аргумента, соответствующего x.
| Если же такой вызов имеется, то для удобства авторов клиентов он должен быть отражен в краткой форме класса. Это будет указываться в заголовке подпрограммы как r (x: blocking SOME_TYPE)... |
put (b: BOUNDED_BUFFER [T]; x: T) is require not b.full do b.put (x) ensure not b.empty endВызов вида put (buffer, y) из клиента-производителя будет ждать, пока buffer не станет свободным (доступным) и не полным. Если buffer свободен, но полон, то данный вызов не может выполняться, но какой-нибудь другой клиент-потребитель может получить доступ к буферу (поскольку предусловие not b.empty, интересующее потребителей, будет в данном случае выполнено); после того, как такой клиент удалит некоторый элемент, сделав буфер неполным, клиент-производитель сможет начать выполнение своего вызова.
| Как реализации решить, какой из двух или более клиентов, условия запуска вызовов которых выполнены (свободны блокирующие объекты и выполнены предусловия), должен получить доступ? Некоторые люди предпочитают передавать такие решения компилятору. Предпочтительнее определить по умолчанию политику FIFO, улучшающую переносимость и равнодоступность. Разработчикам приложений и в этом случае будут доступны библиотечные механизмы для изменения принятой по умолчанию политики. |
Параллельный доступ к объекту
Первый вопрос, на который требуется ответить, - это сколько вычислений может одновременно работать с объектом. Ответ на него неявно присутствует в определениях процессора и обработчика: если все вызовы компонентов объекта выполняются его обработчиком (ответственным за него процессором) и процессор реализует один поток вычисления, то отсюда следует, что лишь один компонент может выполняться в каждый момент времени.
Следует ли разрешить одновременное выполнение нескольких подпрограмм на данном объекте? Основная причина ответить "нет" заключена в желании сохранить способность корректно рассуждать о нашем ПО.
Изучение корректности класса в предыдущей лекции позволяет найти верный подход. Жизненный цикл объекта можно изобразить следующим образом:

Рис. 12.7. Жизненный цикл объекта
На этом рисунке объект извне наблюдается только в состояниях, заключенных в квадратики: сразу после создания (S1), после каждого применения некоторого компонента клиентом (S2 и последующие состояния). Они называются "стабильными моментами" жизни объекта. Как следствие, мы получили формальное правило: чтобы доказать корректность класса, достаточно проверить одно свойство для каждой из процедур создания и одно свойство для каждого экспортируемого компонента (здесь оно несколько упрощено, полная формулировка была дана в лекции 11 курса "Основы объектно-ориентированного программирования"). Если p - это процедура создания, то проверяемое свойство имеет вид:
{Default and prep} Bodyp {postp and INV}Для экспортируемой подпрограммы r проверяемое свойство имеет вид:
{prer and INV} Bodyr {postr and INV}Число проверяемых свойств невелико и не требует анализа сложных сценариев во время исполнения. Указанные свойства дают возможность понимания класса, рассматривая его подпрограммы независимо друг от друга, убеждаясь, пусть и неформально, в том, что каждая подпрограмма, начав работу в "правильном" состоянии, завершит ее в нужном заключительном состоянии.
Введите параллельность в этот простой корректный мир и все пойдет прахом.
Даже при простом чередовании, когда, начав выполнение некоторой подпрограммы, мы прерываем ее для выполнения другой, затем возвращаемся к первой и т. д., мы лишаемся возможности делать выводы о поведении ПО на основании текстов программ. У нас не будет никакой зацепки, помогающей понять, что может произойти во время выполнения, попытки угадать это заставят проверить все возможные варианты чередований, что сразу же приведет к уже указанному комбинаторному взрыву.
Поэтому для обеспечения простоты и корректности разрешим в каждый момент времени выполнять не более одной подпрограммы каждого объекта. Заметим, что существует возможность прервать клиента в случае крайней необходимости или при слишком долгой задержке объекта. Пока это делается насильственным способом - запуском исключения. При этом гарантируется, что неудачливый клиент получит извещение, позволяющее ему предпринять, если потребуется, корректирующие действия. Рассматриваемый далее механизм дуэлей (duels) дает такую возможность.
| В конце обсуждения выясним, могут ли какие-либо обстоятельства позволить нам ослабить запрет на одновременный доступ к подпрограммам одного объекта. |
Поддержка использования непараллельного ПО
Необходимо поддерживать возможности повторного использования существующего непараллельного ПО, особенно библиотек переиспользуемых программных компонентов.
Мы уже видели, насколько плавно можно переходить от последовательных классов (таких как BOUNDED_QUEUE) к их параллельным двойникам (таким как BOUNDED_BUFFER; надо просто написать separate class BOUNDED_BUFFER [G] inherit BOUNDED_QUEUE [G] end). Этот результат несколько ослабляется тем, что часто желательно иметь инкапсулированные классы, такие как наш BUFFER_ACCESS. Однако такая инкапсуляция представляется полезной и, по-видимому, является неизбежным следствием семантического различия между последовательными и параллельными вычислениями. Отметим также, что такие классы-оболочки пишутся достаточно легко.
Поддержка программирования сопрограмм
Как специальный случай, сопрограммы представляют собой вид квазипараллельности, интересный как сам по себе (в частности, в сфере моделирования), так и как простой тест на применимость нашего механизма, поскольку общее решение должно легко адаптироваться к крайним случаям. Мы видели, как можно выразить сопрограммы, основываясь на общем параллельном механизме и используя ОО-средства построения библиотек.
Поддержка различия между командами и запросами
В предыдущих лекциях был обоснован важный принцип различия команд и запросов. Он предписывает не смешивать команды (процедуры), изменяющие объекты, и запросы (функции и атрибуты), возвращающие информацию, что устраняет функции с побочными эффектами.
Существовала точка зрения, что в параллельном контексте этот принцип не выполняется, например нельзя написать:
next_element := buffer.item buffer.removeи быть уверенным в том, что удаленный во втором вызове элемент будет тем же, что и присвоенный в первой строке переменной next_item. Другой клиент мог испортить дело, получив доступ к буферу между этими двумя инструкциями. Такого рода примеры часто использовались для доказательства необходимости функций с побочным эффектом, в данном случае - функции get, возвращающей элемент и удаляющей его из контейнера в качестве побочного эффекта.
Этот аргумент заведомо ложен. В нем смешаны два понятия: исключительный доступ и спецификация программы. Понятия этой лекции позволяют получить исключительный доступ, не жертвуя принципом Команд и Запросов. Достаточно включить эти две инструкции, заменив buffer на b, в некоторую процедуру с формальным аргументом b, а затем вызвать эту процедуру с атрибутом buffer в качестве аргумента. Или, если вам не требуется, чтобы обе операции применялись к одному элементу, а нужно минимизировать время захвата общего ресурса, то напишите две отдельные подпрограммы. Такая гибкость важна для разработчиков. Она обеспечивается благодаря простому механизму исключительного доступа, не связанному с наличием или отсутствием побочного эффекта у функций.
Поддержка устранения блокировок
Один из вопросов, требующий дальнейшей работы, - это гарантирование отсутствия блокировок.
Потенциальная возможность блокировки - это факт параллельной жизни. Например, любой механизм, который можно использовать для программирования семафоров (а механизм, недостаточный для их реализации, выглядел бы весьма подозрительно), может вызвать блокировку, поскольку семафоры тривиально допускают такую возможность.
Частичное решение состоит в использовании механизмов инкапсуляции высокого уровня. Например, набор классов, инкапсулирующих семафоры, вроде представленного выше для замков, должен поступать вместе с классами поведения, которые автоматически обеспечивают операцию free после каждой reserve, гарантируя тем самым отсутствие блокировок для приложений, которые следуют рекомендованной практике наследования классов поведения. Мой опыт показывает, что это наилучший рецепт для устранения блокировок.
Этот подход, конечно, может оказаться недостаточным. Можно изобрести простые правила недопущения блокировок, автоматически проверяемые статическими средствами. Одно такое правило - принцип визитной карточки - приведено выше (из-за страха, что оно налагает чересчур сильные ограничения, оно представлено в виде методологического принципа, а не в виде правила языка). Но одного этого правила мало.
Полное использование наследования и других ОО-методов
Было бы недопустимо построить параллельный ОО-механизм, не использующий всех преимуществ ОО-метода, в частности наследование. Мы заметили, что "аномалия наследования" и другие потенциальные конфликты внутренне не присущи параллельному ОО-проектированию. Они являются следствиями специфического выбора параллельных механизмов - активных объектов, синхронизации с помощью путевых выражений. По этой причине мы отказались от этих конструкций и сохранили наследование.
Мы неоднократно видели, как можно использовать наследование для создания классов поведения высокого уровня (таких как PROCESS), описывая общие образцы, наследуемые их потомками. Большинство из приведенных примеров невозможно было бы реализовать без множественного наследования.
Отметим также, что скрытие информации играет центральную роль среди всех ОО-методов.
Полное использование параллелизма оборудования
Следующий пример иллюстрирует, как использовать ожидание по необходимости для извлечения максимальной пользы от параллелизма в оборудовании. Он показывает изощренную форму балансировки загрузки компьютеров в сети. Благодаря понятию процессора, можно опереться на механизм параллельности для автоматического выбора компьютеров.
Сам этот пример - вычисление числа вершин бинарного дерева - имеет небольшое практическое значение, но иллюстрирует общую схему, которая может быть чрезвычайно полезна для больших, сложных вычислений, встречающихся в криптографии или в машинной графике, для которых разработчикам нужны все доступные ресурсы, но не хочется вручную заниматься назначением абстрактных вычислительных единиц реальным компьютерам.
Рассмотрим сначала набросок класса, без параллелизма:
class BINARY_TREE [G] feature left, right: BINARY_TREE [G] ... Другие компоненты ... nodes: INTEGER is -- Число вершин в данном дереве do Result := node_count (left) + node_count (right) + 1 end feature {NONE} node_count (b: BINARY_TREE [G]): INTEGER is -- Число вершин в b do if b /= Void then Result := b.nodes end end endФункция nodes использует рекурсию для вычисления числа вершин в дереве. Эта косвенная рекурсия проходит через вызовы node_count.
В параллельном окружении, предлагающем много процессоров, можно было бы загрузить вычисления для отдельных вершин в разные процессоры. Сделаем это, объявив класс сепаратным (separate), заменив nodes атрибутом и введя соответствующие процедуры:
separate class BINARY_TREE1 [G] feature left, right: BINARY_TREE1 [G] ... Другие компоненты ... nodes: INTEGER update_nodes is -- Модифицировать nodes, подсчитав число вершин дерева do nodes := 1 compute_nodes (left); compute_nodes (right) adjust_nodes (left); adjust_nodes (right) end feature {NONE} compute_nodes (b: BINARY_TREE1 [G]) is -- Модифицировать информацию о числе вершин в b do if b /= Void then b.update_nodes end end adjust_nodes (b: BINARY_TREE1 [G]) is -- Добавить число вершин в b do if b /= Void then nodes := nodes + b.nodes end end endВ этом случае рекурсивные вызовы compute_nodes будут запускаться параллельно.
Операция сложения будет ждать, пока не завершатся два параллельных вычисления.
Если доступно неограниченное число ЦПУ (физических процессоров), то это решение, по-видимому, обеспечивает максимальное использование параллелизма оборудования. Если же число имеющихся процессоров меньше числа вершин дерева, то ускорение вычисления по сравнению с последовательным вариантом будет зависеть от того, насколько удачно реализовано распределение (виртуальных) процессоров по ЦПУ.
| Наличие двух проверок пустоты b может показаться неприятным. Однако это требуется для отделения распараллеливаемой части - вызовы процедур, запускаемых параллельно на left и right, - от сложений, которые по своему смыслу должны ждать готовности своих операндов. |
Получение сепаратных объектов
Как показывают предыдущие примеры, на практике встречаются сепаратные объекты двух видов:
В первом случае приложение при вызове захочет порождать новый сепаратный объект, заняв следующий свободный процессор. (Напомним, что такой процессор всегда можно получить, так как процессоры - это не материальные ресурсы, а абстрактные устройства, и их число не ограничено). Эта ситуация типична для BROWSER_WINDOW: новое окно создается тогда, когда это нужно. Объекты классов BOUNDED_BUFFER или PRINT_CONTROLLER также могут создаваться при необходимости.Приложению может потребоваться доступ к уже существующему сепаратному объекту, обычно разделяемому многими клиентами. Это имеет место для класса DATABASE: приложение-клиент использует сепаратную сущность db_server: separate DATABASE для доступа к базе данных через сепаратные вызовы вида db_server.ask_query (sql_query). У сервера должно быть полученное на некотором шаге извне значение указателя на базу данных server. Аналогичные схемы используются для доступа к существующим объектам классов BOUNDED_BUFFER и PRINT_CONTROLLER.Скажем, что в первом случае сепаратные объекты создаются, а во втором являются внешними.
Для создания сепаратного объекта применяется обычная инструкция создания:
create x.make (...)В дополнение к своему обычному действию по созданию и инициализации нового объекта ему назначается новый процессор. Такая инструкция называется сепаратным созданием:
Для получения существующего внешнего объекта, как правило, используется внешняя процедура, например:
server (name: STRING; ... Другие аргументы ...): separate DATABASEЕе аргументы служат для идентификации запрашиваемого объекта. Такая процедура посылает сообщение по сети и получает в ответ ссылку на объект.
Для визуализации понятия сепаратного объекта, полезно кое-что сказать о возможных реализациях. Предположим, что каждый из процессоров связан с некоторой задачей (процессом) операционной системы (например, Windows или Unix), имеющей свое адресное пространство; конечно, это только одна из возможных архитектур.
Тогда одним из способов представления сепаратного объекта внутри задачи является использование небольшого локального объекта, называемого заместителем или прокси (proxy):

Рис. 12.3. Прокси для сепаратного объекта
На этом рисунке показан объект O1, экземпляр класса T с атрибутом x: separate U. Соответствующее поле - ссылка в O1 - концептуально привязано к объекту O2, обрабатываемому другим процессором. Фактически ссылка ведет к прокси-объекту, обрабатываемому процессором для O1. Прокси - это внутренний объект, не видимый автору параллельного приложения. Он содержит достаточно информации для идентификации O2: задачу, которая служит обработчиком O2, и адрес O2 внутри этой задачи. Все операции над x, проводимые от имени O1 или других клиентов той же задачи, будут проходить через прокси. У всякого другого процессора, также обрабатывающего объекты, содержащие ссылки на O2, будет свой собственный прокси для O2.
| Подчеркнем, что это лишь один из возможных методов, а не обязательное свойство рассматриваемой модели. Задачи операционной системы с раздельными адресными пространствами являются лишь одним из способов реализации процессоров. Для потоков методы могут быть другими. |
Последовательные и параллельные утверждения
Мысль о том, что утверждения, в частности предусловия, могут иметь две разные семантики - условий корректности и условий ожидания, может показаться странной. Но без этого не обойтись: последовательная семантика не применима в случае сепаратных предусловий.
Нужно ответить на одно возможное возражение. Мы видели, что проверку утверждения во время выполнения можно включать или отключать. Не опасно ли тогда придавать так много семантической важности предусловиям в параллельных ОО-системах? Нет. Утверждения являются неотъемлемой частью ПО независимо от того, проверяются ли они во время исполнения. В последовательной системе корректность означает, что утверждения всегда выполняются, поэтому из соображений эффективности можно отключить их проверку, если есть уверенность в том, что ошибок не осталось, хотя концептуально утверждения все еще присутствуют. В параллельном случае отличие состоит в том, что некоторые утверждения - предложения сепаратных предусловий - могут нарушаться во время выполнения даже в корректной системе и должны служить условиями ожидания.
Посредники запросов объектов (брокеры объектных запросов - Object Request Broker)
Другим важным недавним достижением явилось появление предложения CORBA от Группы управления объектами (Object Management Group) и архитектуры OLE 2/ActiveX от фирмы Майкрософт. Хотя их окончательные цели, детали и рынки различны, оба предложения обещают существенное продвижение в направлении распределенных вычислений1).
Общая цель состоит в том, чтобы сделать объекты и услуги различных приложений доступными друг для друга наиболее удобным образом локально или через сеть. Усилия CORBA направлены, в частности, на достижение интероперабельности (interoperability).
Приложения, поддерживающие CORBA, могут взаимодействовать между собой, даже если они основаны на "посредниках запроса объектов" разных производителей.Интероперабельность применяется также и на уровне языка: приложение на одном из поддерживаемых языков может получить доступ к объектам приложения, написанного на другом языке. Взаимодействие происходит с помощью внутреннего языка, называемого IDL (язык определения интерфейса - Interface Definition Language); у поддерживаемых языков имеется официальная привязка к IDL, в которой определено, как конструкции языка отображаются на конструкции IDL.IDL - это общий знаменатель ОО-языка, сконцентрированного на понятии интерфейса. Интерфейс IDL для класса по духу похож на его краткую форму, хотя и более примитивную (в частности, IDL не поддерживает утверждений); в нем описывается набор компонентов, доступных на некотором уровне абстракции. По классу, написанному на ОО-языке, с помощью инструментальных средств будет выводиться IDL-интерфейс класса, представляющий интерес для клиентов. Клиент, написанный на том же или на другом языке, может через этот IDL-интерфейс получать доступ по сети к компонентам, предоставляемым поставщиком класса.
Правила обоснования корректности: разоблачение предателей
Так как для сепаратных и несепаратных объектов семантика вызовов различна, то важно гарантировать, что несепаратная сущность (объявленная как x: T для несепаратного T) никогда не будет присоединена к сепаратному объекту. В противном случае, вызов x.f (a) был бы неверно понят - в том числе и компилятором - как синхронный, в то время как присоединенный объект, на самом деле, является сепаратным и требует асинхронной обработки. Такая ссылка, ошибочно объявленная несепаратной, но хранящая верность другой стороне, будет называться ссылкой-предателем (traitor). Нам нужно простое правило обоснования корректности, чтобы гарантировать отсутствие предателей в ПО, а именно, что каждый представитель или лоббист сепаратной стороны надлежащим образом зарегистрирован как таковой соответствующими властями.
У этого правила будут четыре части. Первая часть устраняет риск создания предателей посредством присоединения, т. е. путем присваивания или передачи аргументов:
|
Правило (1) корректности сепаратности Если источник присоединения (в инструкции присваивания или при передаче аргументов) является сепаратным, то его целевая сущность также должна быть сепаратной. |
Присоединение цели x к источнику y является либо присваиванием x := y , либо вызовом f (..., y, ..), в котором y - это фактический аргумент, соответствующий x. Такое присоединение, в котором y сепаратная, а x нет, делает x предателем, поскольку сущность x может быть использована для доступа к сепаратному объекту (объекту, присоединенному к y) под несепаратным именем, как если бы он был локальным объектом с синхронным вызовом. Приведенное правило это запрещает.
|
Отметим, что синтаксически x является сущностью, а y может быть произвольным выражением. Поэтому нам следует определить понятие "сепаратного выражения". Простое выражение - это сущность; более сложные выражения являются вызовами функций (напомним, в частности, что инфиксное выражение вида a + b формально рассматривается как вызов: нечто вроде a.plus (b)). Отсюда сразу получаем определение: выражение является сепаратным, если оно является сепаратной сущностью или сепаратным вызовом. |
p> Как станет ясно из последующего обсуждения, присоединение несепаратного источника к сепаратной цели безвредно, хотя, как правило, не очень полезно.
Нам нужно еще дополнительное правило, охватывающее случай, когда клиент передает сепаратному поставщику ссылку на локальный объект. Пусть имеется сепаратный вызов:
x.f (a),в котором a типа T не является сепаратной, а x является. Объявление процедуры f в классе, порождающем x, будет иметь вид:
f (u:SOME_TYPE)а тип T сущности a должен быть совместен с SOME_TYPE. Но этого недостаточно! Глядя с позиций поставщика (т. е. обработчика x) объект O1, присоединенный к a, расположен на другой стороне - имеет другого обработчика, поэтому, если не объявить соответствующий формальный аргумент u как сепаратный, он станет предателем, так как даст доступ к сепаратному объекту так, как будто он несепаратный:

Рис. 12.5. Передача ссылки в качестве аргумента сепаратному вызову
Таким образом, SOME_TYPE должен быть сепаратным, например, это может быть separate T. Отсюда получаем второе правило корректности:
|
Правило (2) корректности сепаратности Если фактический аргумент сепаратного вызова имеет тип ссылки, то соответствующий формальный аргумент должен быть объявлен как сепаратный. |
Иллюстрируя эту технику, рассмотрим объект, порождающий большое число сепаратных объектов, наделяя их возможностью обращаться в дальнейшем к его ресурсам, т. е. говоря им: "Вот вам моя визитная карточка, звоните мне, если потребуется". Типичным примером будет ядро операционной системы, которое создает сепаратные объекты, оставаясь готовым выполнять операции по их запросам. Создание объектов будет иметь вид:
create subsystem.make (Current, ... Другие аргументы ...),где Current - это визитная карточка, позволяющая subsystem запомнить своего создателя (progenitor) и в случае необходимости попросить у него помощь.
Поскольку Current - это ссылка, то соответствующий формальный аргумент в make должен быть объявлен как сепаратный. Чаще всего make будет иметь вид:
make (p: separate PROGENITOR_TYPE; ... Другие аргументы ...) is do progenitor := p ... Остальные операции инициализации ... endпри котором значение аргумента создателя запоминается в атрибуте progenitor объемлющего класса. Второе правило корректности сепаратности требует, чтобы p была объявлена как сепаратная, а первое правило требует того же от атрибута progenitor. Тогда вызовы ресурсов создателя вида progenitor.some_resource (...) будут корректно трактоваться как сепаратные.
Аналогичное правило нужно и для результатов функций.
|
Правило (3) корректности сепаратности Если источник присоединения является результатом вызова функции, возвращающей тип ссылки, то цель должна быть объявлена как сепаратная. |
|
Правило (4) корректности сепаратности Если фактический аргумент или результат сепаратного вызова имеет развернутый тип, то его базовый класс не может содержать непосредственно или опосредовано никакой несепаратный атрибут ссылочного типа. |
Рис. 12.6 иллюстрирует случай, когда формальный аргумент u является развернутым. Тогда при присоединении поля объекта O1 просто копируются в соответствующие поля объекта O'1, присоединенного к u (см. лекцию 8 курса "Основы объектно-ориентированного программирования"). Если разрешить O1 содержать ссылку, то это приведет к полю-предателю в O'1. Та же проблема возникнет, если в O1 будет подобъект со ссылкой; это отмечено в правиле фразой "непосредственно или опосредовано".

Рис. 12.6. Передача объекта со ссылками сепаратному вызову
Если формальный аргумент u является ссылкой, то присоединение является клоном; вызов будет создавать новый объект O'1, как показано на последнем рисунке, и присоединять к нему ссылку u. В этом случае можно предложить перед вызовом явно создавать клон на стороне клиента:
a: expanded SOME_TYPE; a1: SOME_TYPE ... a1 := a; -- Это клонирует объект и присоединяет a1 к клону x.f (a1)Согласно второму правилу корректности формальный аргумент u должен иметь тип, согласованный с типом сепаратной ссылки separate SOME_TYPE. Вызов в последней строке делает u сепаратной ссылкой, присоединенной ко вновь созданному клону на стороне клиента.
Предусловия при параллельном выполнении
Давайте рассмотрим типичное использование ограниченного буфера buffer клиентом, посылающим в него объект y с помощью процедуры put. Предположим, что buffer - это атрибут объемлющего класса, объявленный как buffer: BOUNDED_BUFFER [T] с элементами типа T (пусть y имеет этото же тип).
|
Клиент может, например, инициализировать buffer с помощью ссылки на реальный буфер, переданной из процедуры его создания, используя предложенную выше схему визитной карточки: |
Так как buffer, имеющий сепаратный тип, является сепаратной сущностью, то всякий вызов вида buffer.put (y) является сепаратным и должен появляться лишь в подпрограмме, одним из аргументов которой является buffer. Поэтому мы должны вместо него использовать put(buffer, y), где put - подпрограмма из класса клиента (ее не следует путать с put из класса BOUNDED_BUFFER), объявленная как:
put (b: BOUNDED_BUFFER [T]; x: T) is -- Вставить x в b. (Первая попытка) do b.put (x) endНо это не совсем верное определение. У процедуры put из BOUNDED_BUFFER имеется предусловие not full. Поскольку не имеет смысла пытаться вставлять x в полный b, то нам нужно скопировать это условие в новой процедуре из класса клиента:
put (b: BOUNDED_BUFFER [T]; x: T) is -- Вставить x в b require not b.full do b.put (x) endУже лучше. Как же можно вызвать эту процедуру для конкретных buffer и y? Конечно, при входе требуется уверенность в выполнении предусловия. Один способ состоит в проверке:
if not full (buffer) then put (buffer, y) -- [PUT1]но можно также учитывать контекст вызова, например, в:
remove (buffer); put (buffer, y) -- [PUT2]где постусловие remove включает not full. (В примере PUT2 предполагается, что начальное состояние удовлетворяет соответствующему предусловию not empty для самой операции remove.)
Будет ли это верно работать? В свете предыдущих замечаний о непредсказуемости ошибок в параллельных системах ответ неутешителен - может быть. Между проверкой на полноту full и вызовом put в варианте PUT1 или между remove и put в PUT2 может вклиниться какой-то другой клиент и снова сделать буфер полным.
Это тот же дефект, который ранее потребовал от нас обеспечить резервирование объекта через инкапсуляцию.
| Мы снова можем попробовать инкапсуляцию, написав PUT1 или PUT2 как процедуры, в которые buffer передается в качестве аргумента, например, для PUT1: |
| Но на самом деле это не очень поможет клиенту. Во-первых, причиняет неудобство проверка условия was_full при возврате, а затем что делать, если оно истинно? Попытаться снова - возможно, но нет никакой гарантии успеха. На самом деле хотелось бы иметь способ выполнить put в тот момент, когда буфер будет наверняка неполон, даже если придется ждать, пока это случится. |
Предварительный просмотр
Как и обычно, при обсуждении параллелизма мы не предложим заранее подготовленный ответ, но вместо этого тщательно построим решение, исходя из детального анализа проблемы и изучения различных путей ее решения, включая и некоторые тупиковые. Хотя такая тщательность необходима для глубокого понимания рассматриваемых методов, она могла бы привести читателя к мысли об их большой сложности, что было бы непростительно, так как тот параллельный механизм, к которому мы в конце придем, на самом деле отличается неправдоподобной простотой. Чтобы избежать такого риска, начнем с обзора этого механизма, отложив обоснования на потом.
|
Если вам не нравится забегать вперед и вы предпочитаете последовательное изучение предмета и продвижение к развязке драмы шаг за шагом и вывод за выводом, то пропустите следующую страницу с резюме и переходите к слудующему разделу. |
Расширение, полностью охватывающее параллельность и распределенность, будет самым минимальным из всех возможных: к последовательным обозначениям добавляется единственное новое ключевое слово - separate. Почему это возможно? Мы используем основную схему ОО-вычислений: вызов компонента x.f (a), выполняемый от имени некоторого объекта O1, и вызывающий компонент f объекта O2, присоединенного к x с аргументом a. Но сейчас вместо одного процессора, выполняющего операции всех объектов, мы рассчитываем на возможность использовать разные процессоры для O1 и O2, так что вычисление O1 может продолжаться, не ожидая завершения указанного вызова, поскольку он обрабатывается другим процессором.
Поскольку результат вызова сейчас зависит от того, обрабатываются ли объекты одним процессором или несколькими, в тексте программы об этом должно быть точно сказано для каждой сущности x. Поэтому требуется новое ключевое слово: вместо того, чтобы объявлять просто x: SOME_TYPE, будем объявлять x: separate SOME_TYPE, чтобы указать, что x обрабатывается отдельным процессором, так что вызовы с целью x могут выполняться параллельно с остальным вычислением.
При таком объявлении всякая команда создания create x.make (...) будет порождать новый процессор - новую ветвь управления - для обработки будущих вызовов x.
Нигде в тексте программы не требуется указывать, какой именно процессор нужно использовать. Все, что утверждается посредством объявления separate - это то, что два объекта обрабатываются различными процессорами, и это существенно влияет на семантику системы. Назначение конкретного процессора можно перенести на время исполнения. Мы также не устанавливаем заранее точную природу процессора: он может быть реализован как часть оборудования (компьютера), но может также оказаться заданием (процессом) операционной системы или, в случае многопоточной ОС, стать одной из нитей (потоков) задания. С точки зрения программы "процессор" - это абстрактное понятие; одно и то же параллельное приложение может выполняться на совершенно разных архитектурах (на одном компьютере с разделением времени, в распределенной сети со многими компьютерами, несколькими потоками одного задания под Unix или Windows) без всякого изменения его исходного текста. Все, что потребуется изменить, - это "Файл параллел ьной конфигурации" -_ ("Concurrency Configuration File"), задающий отображение абстрактных процессоров на физические ресурсы.
Определим ограничения, связанные с синхронизацией. Эти соглашения достаточно просты:
Клиенту не требуется никакого специального механизма для повторной синхронизации с сервером после того, как вызов x.f (a) для объявленной separate сущности x пойдет на параллельное выполнение. Клиент будет ждать столько, сколько необходимо, когда он запрашивает информацию об объекте с помощью вызова запроса, как в операторе value := x.some_query. Этот автоматический механизм называется ожидание по необходимости (wait by necessity).Для получения исключительного доступа к отдельному объекту O2 достаточно использовать присоединенную к нему сущность a, объявленную как separate, в качестве аргумента соответствующего вызова, например, r(a).Если у подпрограммы имеется предусловие, содержащее аргумент, объявленный как separate (например, такой как a), то клиенту придется ждать, пока это предусловие не выполнится.Для контроля за работой ПО и предсказуемости результатов (в частности, поддержания инвариантов класса) нужно разрешать процессору, ответственному за объект, выполнять в каждый момент времени не более одной процедуры.Однако иногда может потребоваться прервать выполнение некоторой процедуры, уступив ресурсы новому более приоритетному клиенту.Клиент, которого прервали, сможет произвести соответствующие корректирующие мероприятия; наиболее вероятно, что он повторит попытку после некоторого ожидания.Это описание охватывает основные свойства механизма, позволяющего строить продвинутые параллельные и распределенные приложения, в полной мере используя ОО-методы от множественного наследования до проектирования по контракту. Далее мы рассмотрим этот механизм детально, забыв на время то, что прочли только что в этом кратком обзоре.
Применимость ко многим видам параллельности
Общим критерием при разработке параллельного механизма была необходимость поддержки многих различных видов параллельности: разделяемой памяти, многозадачности, сетевого программирования, программирования для архитектуры клиент-сервер, распределенной обработки, реального времени.
Нельзя ожидать, что один языковый механизм обеспечит ответы на все вопросы из таких разных прикладных областей. Но должна быть возможность приспособления его к потребностям всех перечисленных видов параллельности. Это достигается за счет применения абстрактного понятия процессора и использования специальных средств (файлов управления параллельностью, библиотек) для адаптации к любой доступной архитектуре оборудования.
Для иллюстрации предложенного механизма мы
Для иллюстрации предложенного механизма мы сейчас приведем несколько примеров, выбранных из различных источников - от традиционных примеров параллельных программ до приложений реального времени.
Природа процессоров
|
Определение: процессор Процессор - это автономная ветвь управления, способная поддерживать последовательное выполнение инструкций одного или нескольких объектов. |
Это абстрактное понятие, его не надо путать с физическими устройствами, называемыми процессорами, для которых мы далее будем использовать термин ЦПУ (CPU), обычно используемый в компьютерной инженерии для обозначения процессорных единиц компьютеров. "ЦПУ" - это сокращение для названия "Центральное процессорное устройство", хотя почти ничего центрального в ЦПУ нет. ЦПУ можно использовать для реализации процессора, но понятие процессора существенно более общее и абстрактное. Например, процессор может быть:
компьютером (со своим ЦПУ) в сети;заданием, также называемым процессом, - поддерживается такими операционными системами, как Unix, Windows и многими другими;сопрограммой (сопрограммы будут более детально рассмотрены далее, они моделируют реальную параллельность, выполняясь по очереди на одном ЦПУ, после каждого прерывания каждая сопрограмма продолжает выполнение с того места, где оно остановилось);"потоком", который поддерживается в таких многопоточных операционных системах как Solaris, OS/2 и Windows NT.|
Потоки являются минипроцессами. Настоящий процесс может включать много потоков, которыми сам управляет; операционная система (ОС) видит только процесс, а не его потоки. Обычно, потоки процесса разделяют одно и то же адресное пространство (в ОО-терминологии они имеют потенциальный доступ к одному и тому же множеству объектов), а у каждого процесса имеется свое собственное адресное пространство. Потоки можно рассматривать, как сопрограммы внутри процесса. Главное достоинство потоков в их эффективности. Создание процесса и его синхронизация с другими процессами являются дорогими операциями, требующими прямого взаимодействия с ОС (для размещения адресного пространства и кода процесса). Операции над потоками производятся более просто, не затрагивая дорогостоящих операций ОС, поэтому они выполняются в сотни и даже в тысячи раз быстрее. |
Различие между процессорами и ЦПУ было ясно описано Генри Либерманом ([Lieberman 1987])(для другой модели параллельности):
Не нужно ограничивать заранее число [процессоров] и, если их оказывается больше, чем имеется реальных физических [ЦПУ] у вашего компьютера, то они автоматически будут разделять время. Таким образом, пользователь может считать, что ресурс процессоров у него практически бесконечен.Чтобы не было неверного толкования, пожалуйста, запомните, что в этой лекции "процессоры" означают виртуальные потоки управления: при ссылках на физические устройства для вычислений будет использоваться термин ЦПУ.
Раньше или позже потребуется назначать вычислительные ресурсы процессорам. Это отображение будет представлено с помощью "файла управления параллелизмом" ("Concurrency Control File"), описываемого ниже, или соответствующих библиотечных средств.
Процессоры
Для понимания специфики параллельности, полезно снова взглянуть на рисунок (он впервые появился в лекции 5 курса "Основы объектно-ориентированного программирования"), который помог нам установить основы объектной технологии путем анализа трех основных ингредиентов вычисления:

Рис. 12.2. Три силы вычисления
Выполнить программную систему - значит использовать некоторые процессоры, чтобы применить некоторые действия к некоторым объектам. В объектной технологии действия присоединяются к объектам (точнее, к типам объектов), а не наоборот.
А что же процессоры? Разумеется, нам нужен механизм для выполнения действий над объектами. Но последовательное вычисление образует лишь одну ветвь управления, для которой нужен лишь один процессор, большую часть времени присутствовавший в предыдущих лекциях неявно.
Однако в параллельном случае у нас будет несколько процессоров. Это, конечно, является самым существенным в идее параллельности и может быть даже принято за определение этого понятия. В этом и состоит основной ответ на поставленный выше вопрос: процессоры (а не процессы) будут главным новым понятием, позволяющим включить параллельность в рамки последовательных ОО-вычислений. У параллельной системы может быть любое число процессоров в отличие от последовательной системы, имеющей лишь один.
Программируемые процессы
Поскольку мы готовы избавиться от активных объектов, полезно заметить, что на самом деле мы не хотим ни от чего отказываться. Объект способен выполнять много операций: все компоненты породившего его класса. Превращая объект в процесс, приходится выбирать одну из этих операций в качестве единственной реально вычисляемой. Это не дает абсолютно никаких преимуществ! Зачем ограничивать себя одним алгоритмом, когда можно иметь их столько, сколько нужно?
Заметим, что понятие процесса не обязательно должно быть встроено внутрь механизма параллельности; процессы можно программировать, рассматривая их как обычные программы. Процесс для принтера, приведенный в начале лекции, с ОО-точки зрения может трактоваться как одна из подпрограмм, скажем, live, соответствующего класса:
indexing description: "Принтер, выполняющий в каждый момент одно задание" note: "Улучшеная версия, основанная на общем классе PROCESS, % %появится далее под именем PRINTER" class PRINTER_1 feature -- Status report stop_requested: BOOLEAN is do ... end oldest: JOB is do ... end feature -- Basic operations setup is do ... end wait_for_job is do ... end remove_oldest is do ... end print (j: JOB) is do ... end feature -- Process behavior live is -- Выполнение работы принтера do from setup until stop_requested loop wait_for_job; print (oldest); remove_oldest end end ... Другие компоненты ... endОтметим заготовку для других компонентов: хотя до сих пор все наше внимание было уделено live и окружающим его компонентам, мы можем снабдить процесс и многими другими желательными компонентами, чему способствует ОО-подход, развитый в других частях этого курса. Превращение объектов класса PRINTER_1 в процессы означало бы ограничение этой свободы, это была бы существенная потеря в выразительной силе без всякой видимой компенсации.
Абстрагируясь от этого примера, который описывает конкретный тип процесса просто как некоторый класс, можем попытаться предложить более общее описание всех типов процессов с помощью специального отложенного класса - класса поведения, как это уже не раз делалось в предыдущих лекциях.
Процедура live будет применима ко всем процессам. Мы можем оставить ее отложенной, но нетрудно заметить, что большинство процессов будут нуждаться в некоторой инициализации, некотором завершении, а между ними - в некотором основном шаге, повторяемом некоторое число раз. Поэтому мы можем учесть это на самом абстрактном уровне:
indexing description: "Самое общее понятие процесса" deferred class PROCESS feature -- Status report over: BOOLEAN is -- Нужно ли сейчас прекратить выполнение? deferred end feature -- Basic operatios setup is -- Подготовка к выполнению операций процесса -- (по умолчанию: ничего) do end step is -- Выполнение основных операций deferred end wrapup is -- Выполнение операций завершения процесса -- (по умолчанию: ничего) do end feature -- Process behavior live is -- Выполнение жизненного цикла процесса do from setup until over loop step end wrapup end end
| Методологическое замечание: компонент step является отложенным, но setup и wrapup являются эффективными процедурами, которые по определению ничего не делают. Так можно заставить каждого эффективного потомка обеспечить собственную реализацию основного действия процесса step, не беспокоясь об инициализации и завершении, если на этих этапах не требуется специальных действий. При проектировании отложенных классов выбор между отложенной версией и пустой эффективной версией приходится делать регулярно. Ошибки не страшны, поскольку в худшем случае потребуется выполнить больше работы по эффективизации или переопределению у потомков. |
indexing description: "Принтеры, выполняющие в каждый момент одно задание" note: "Пересмотренная версия, основанная на классе PROCESS" class PRINTER inherit PROCESS rename over as stop_requested end feature -- Status report stop_requested: BOOLEAN -- Является ли следующее задание в очереди запросом на -- завершение работы? oldest: JOB is -- Первое задание в очереди do ...
end feature -- Basic operations step is -- Обработка одного задания do wait_for_job; print (oldest); remove_oldest end wait_for_job is -- Ждать появления заданий в очереди do ... ensure oldest /= Void end remove_oldest is -- Удалить первое задание из очереди require oldest /= Void do if oldest.is_stop_request then stop_requested := True end "Удалить первое задание из очереди" end print (j: JOB) is -- Печатать j, если это не запрос на остановку require j /= Void do if not j.is_stop_request then "Печатать текст, связанный с j" end end endЭтот класс предполагает, что запрос на остановку принтера посылается как специальное задание на печать j, для которого выполнено условие jlis_stop_request. (Было бы лучше устранить проверку условия в print и remove_oldest, введя специальный вид задания - "запрос на остановку"; это нетрудно сделать [см. У12.1]).
Уже сейчас видны преимущества ОО-подхода. Точно так же, как переход от главной программы к классам расширил наши возможности, предоставив абстрактные объекты, не ограничивающиеся "только одним делом", рассмотрение процесса принтера как объекта, описанного некоторым классом, открывает возможность новых полезных свойств. В случае принтера можно сделать больше, чем просто выполнять обычную операцию печати, обеспечиваемую live (которую нам, возможно, придется переименовать в operate, при наследовании ее из PROCESS).
Можно добавить компоненты: perform_internal_test (выполнить внутренний тест), switch_to_Postscript_level_1(переключиться на уровень Postscript1) или set_resolution (установить разрешение). Стабилизирующее влияние ОО-метода здесь так же важно, как и для последовательного ПО.
Классы, очерченные в этом разделе, показывают, как можно применять нормальные ОО-механизмы - классы, наследование, отложенные элементы, частично реализованные образцы - к реализации процессов. Нет ничего плохого в понятии процесса в контексте ОО-программирования, и на самом деле оно требуется во многих параллельных приложениях.Но, вместо включения некоторого примитивного механизма, оно просто охватывается библиотечным классом PROCESS, основанным на версии, приведенной выше в этом разделе или, может быть, несколькими такими классами, охватывающими различные варианты этого понятия.
Что касается новой конструкции для параллельной ОО-технологии, то она будет рассмотрена далее.
Распределение процессоров: файл управления параллелизмом (Concurrency Control File)
Если в программе не задаются физические ЦПУ, то их спецификация должна быть помещена в каком-то другом месте. Вот один из способов позаботиться об этом. Подчеркнем, что это лишь одно из возможных решений, не претендующее на фундаментальность; точный формат здесь несущественен, но любой способ конфигурирования будет так или иначе предоставлять одну и ту же информацию.
В качестве примера мы выбрали "Файл управления параллелизмом" (ФУП) ("Concurrency Control File" (CCF)), описывающий доступные программам ресурсы параллельных вычислений. ФУПы по целям и по виду похожи на файлы Ace, используемые для управления сборкой системы (лекция 7 курса "Основы объектно-ориентированного программирования"). Типичный ФУП выглядит так:
creation local_nodes: system "pushkin" (2): "c:\system1\appl.exe" "akhmatova" (4): "/home/users/syst1" Current: "c:\system1\appl2.exe" end remote_nodes: system "lermontov": "c:\system1\appl.exe" "tiutchev" (2): "/usr/bin/syst2" end end external Ingres_handler: "mandelstam" port 9000 ATM_handler: "pasternak" port 8001 end default port: 8001; instance: 10 end|
Для всех рассматриваемых свойств имеются значения по умолчанию, поэтому ни одна из трех частей (creation, external, default) не является обязательной, как и сам ФУП. |
Часть creation определяет, какие ЦПУ используются для сепаратного создания (инструкций вида create x.make (...) для сепаратной x). В примере используются две группы ЦПУ: local_nodes, предположительно включающие локальные машины, и remote_nodes. Программа может выбрать группу ЦПУ с помощью вызова вида:
set_cpu_group ("local_nodes")указывающего, что последующие операции сепаратного создания будут использовать ЦПУ группы local_nodes до появления следующего вызова set_cpu_group. Эта процедура описана в классе CONCURRENCY, предоставляющем средства для механизма управления, который мы подробней рассмотрим ниже.
Соответствующие элементы ФУП указывают, какие ЦПУ следует использовать для группы local_nodes: первые два объекта будут созданы на машине pushkin, следующие четыре - на машине akhmatova, а следующие десять - на текущей машине (т. е. на той, на которой выполняются инструкции создания). После этого схема распределения будет повторяться - два объекта на машине pushkin и т. д. Если число процессоров отсутствует, как у Current в примере, то оно извлекается из пункта instance в части default (здесь оно равно 10), а если такого пункта нет, то берется равным 1. Система, используемая для создания каждого экземпляра, указывается для каждого элемента, например, для pushkin это будет c:\system1\appl.exe (очевидно, машина работает под Windows или OS/2).
В этом примере все процессоры привязаны к процессам. ФУП также поддерживают назначение процессоров потокам (для описателей, основанных на потоках) и другие механизмы параллельности, хотя мы здесь не будем входить в их детали.
Часть external указывает, где располагаются существующие внешние сепаратные объекты. ФУП ссылается на эти объекты через их абстрактные имена, в примере Ingres_handler и ATM_handler, используемые в качестве аргументов функций при установлении связи с ними. Например, для функции server с аргументами:
server (name: STRING; ... Другие аргументы ...): separate DATABASEвызов вида server ("Ingres_handler", ...) даст сепаратный объект, обозначающий сервер базы данных Ingres. ФУП указывает, что соответствующий объект расположен на машине mandelstam и доступен через порт 9000. Если порт явно не задан, то его значение извлекается из части defaults, а если и там его нет, то используется некоторое универсальное предопределенное значение.
ФУП существует отдельно от программ. Можно откомпилировать параллельное или распределенное приложение без всякой ссылки на специфическое оборудование и архитектуру сети, а затем во время выполнения каждый отдельный компонент этого приложения будет использовать свой ФУП для связи с другими существующими компонентами (часть external) и для создания новых компонентов (часть creation).
Этот набросок соглашений, принятых в ФУП, показал, как можно отобразить абстрактные понятия параллельных ОО-вычислений - процессоры и сепаратные объекты (внешние и создаваемые) - на физические ресурсы. Как уже отмечалось, эти соглашения являются только примером того, как это можно сделать, но не являются частью базового механизма параллельности. Они показывают возможность отделения архитектуры параллельной системы от архитектуры параллельного оборудования.
Резервирование объекта
Нам нужен способ, обеспечивающий некоторому клиенту исключительные права доступа к некоторому ресурсу, предоставляемому некоторым объектом.
Идея, привлекательная на первый взгляд (но недостаточная), основана на использовании понятия сепаратного вызова. Рассмотрим вызов x.f (...) для сепаратной сущности x, присоединенной во время выполнения к объекту O2, где вызов выполняется некоторым объектом-клиентом O1. Ясно, что после начала выполнения этого вызова O1 может безопасно перейти к своему следующему делу, не дожидаясь его завершения, но само выполнение этого вызова не может начаться до тех пор, пока O2 не освободится для O1. Отсюда можно заключить, что клиент дождется, когда целевой объект станет свободным, и клиент сможет выполнять над ним свою операцию.
К сожалению, эта простая схема недостаточна, так как она не позволяет клиенту удерживать объект, пока в этом есть необходимость. Предположим, что O2 - это некоторая разделяемая структура данных (например, буфер) и что соответствующий класс предоставляет процедуру remove для удаления одного элемента. Клиенту O1 может потребоваться удалить два соседних элемента, но если просто написать:
Buffer.remove; buffer.remove,то это не сработает, так как между выполнением этих двух инструкций может вклиниться другой клиент, и удаленные элементы могут оказаться не соседними.
Одно решение состоит в добавлении к порождающему классу buffer (или его потомку) процедуры remove_two, удаляющей одновременно два элемента. Но в общем случае это решение нереалистично: нельзя изменять поставщика из-за каждой потребности в синхронизации кода их клиентов. У клиента должна быть возможность удерживать поставленный ему объект так долго, как это требуется.
Другими словами, нужно нечто в духе механизма критических интервалов. Ранее был введен их синтаксис:
hold a then действия_требующие_исключительного_доступа endИли в условном варианте:
hold a when a.некоторое_свойство then действия_требующие_исключительного_доступа endТем не менее, мы перейдем к более простому способу обозначений, возможно, вначале несколько странному.
Наше соглашение состоит в том, что, если a - это непустое сепаратное выражение, то вызов вида:
действия_требующие_исключительного_доступа (a)автоматически заставляет ожидать до тех пор, пока объект, присоединенный к a, не станет доступным. В инструкции hold нет никакой необходимости - для резервирования сепаратного объекта достаточно указать его в качестве фактического аргумента вызова.
| Заметим, что ожидание имеет смысл, только если подпрограмма содержит хоть один вызов x.some_routine с формальным аргументом x, соответствующим a. В противном случае, например, если она выполняет только присваивание вида some_attribute := x, ждать нет никакой необходимости. Это будет уточнено в полной форме правила, которое будет сформулировано далее в этой лекции. |
Это соглашение также означает, что (достаточно парадоксально) большинство сепаратных вызовов не должно ждать. Выполняя тело подпрограммы с сепаратным формальным аргументом a, мы уже зарезервировали соответствующий присоединенный объект, поэтому всякий вызов с целью a может исполняться немедленно. Как уже отмечено, не требуется ждать, когда он завершится. В общем случае для подпрограммы вида:
r (a: separate SOME_TYPE) is do ...; a.r1 (...); ... ...; a.r2 (...); ... endреализация может продолжать выполнение остальных инструкций, не дожидаясь завершения любого из двух вызовов при условии, что она протоколирует вызовы для a так, что они будут выполняться в требуемом порядке. (Нам еще нужно понять, как, если это потребуется, ждать завершения сепаратного вызова; пока же, мы просто запускаем вызовы и никогда не ждем!)
| Если у подпрограммы имеется несколько сепаратных аргументов, то вызов клиента будет ждать, пока не сможет зарезервировать все соответствующие объекты. Это требование тяжело реализовать при компиляции, которая должна порождать код, используя протоколы для множественного одновременного резервирования. По этой причине компилятор мог бы требовать, чтобы подпрограмма использовала не более одного сепаратного формального аргумента. Но при полной реализации предложенного механизма разработчики приложений получают значительные удобства; в частности, рассматриваемая в качестве типичного примера далее в этой лекции знаменитая проблема "обедающих философов" допускает почти тривиальное решение. |
Резюме параллельного механизма
Приведем теперь точное описание параллельных конструкций, введенных в предыдущих разделах. В этом разделе не будет нового материала, он служит только для ссылок и может быть пропущен при первом чтении. Описание состоит из 4-х частей: синтаксиса, ограничений правильности, семантики и библиотечных механизмов. Все это является расширением последовательных механизмов, развитых в предыдущих лекциях.
Семантика
Каждый объект обрабатывается некоторым процессором - его обработчиком. Если цель t инструкции создания не является сепаратной, то новый объект будет обрабатываться тем же процессором, что и создавший его объект. Если t сепаратна, то для обработки нового объекта будет назначен новый процессор.
Будучи создан, объект в дальнейшем находится в одном из двух состояний: свободен или зарезервирован (занят). Он свободен, если в данный момент не выполняется никакой его компонент и никакой сепаратный клиент не выполняет подпрограмму, использующую в качестве фактического аргумента присоединенную к нему сепаратную ссылку.
Процессор может находиться в трех состояниях: "не занят", "занят" и "приостановлен". Он "занят", если выполняет программу, чьей целью является обрабатываемый им объект. Он переходит в состояние "приостановлен" при попытке выполнить неуспешный вызов (это определено ниже), чья цель - обрабатываемый этим процессором объект.
Семантика вызова меняется только, если один или более вовлеченный в него элемент - цель или фактический аргумент - является сепаратным. Мы будем предполагать, что вызов имеет общий вид t.f (..., s, ...), в котором f - это подпрограмма. (Если f является атрибутом, то для простоты будем считать, что имеется вызов неявной функции, возвращающей значение этого атрибута.)
Пусть вызов выполняется как часть выполнения подпрограммы некоторого объекта C_OBJ, обработчик которого на этом шаге может быть только в состоянии "занят". Основным является следующее понятие:
|
Определение: выполнимый вызов (satisfiable call) При отсутствии компонентов CONCURRENCY (описываемых далее) вызов подпрограммы f, выполняемый от имени объекта C_OBJ, является выполнимым тогда и только тогда, когда каждый сепаратный фактический аргумент, присоединенный к некоторому сепаратному объекту A_OBJ, чей соответствующий формальный аргумент используется подпрограммой как цель хотя бы одного вызова, удовлетворяет двум следующим условиям: S1A_OBJ свободен или зарезервирован (обработчиком) C_OBJ.S2Каждое сепаратное предложение предусловия f истинно для A_OBJ и заданных фактических аргументов. |
p> Если процессор исполняет выполнимый вызов, то этот вызов называется успешным и осуществляется немедленно; C_OBJ остается зарезервированным, а его процессор остается в состоянии "занят", каждый объект A_OBJ становится зарезервированным, цель остается зарезервированной, обработчик цели становится занятым и начинает выполнение подпрограммы вызова. Когда этот вызов завершается, обработчик цели возвращается в свое предыдущее состояние ("не занят" или "приостановлен"), и каждый из объектов A_OBJ также возвращается в свое предыдущее состояние (свободен или зарезервирован (обработчиком) C_OBJ).
Если вызов не является выполнимым, то он называется неуспешным; (обработчик) C_OBJ переходит в состояние "приостановлен". Эта попытка вызова никак не влияет на его цель и фактические аргументы. Если в некоторый момент один или больше ранее неуспешных вызовов становятся выполнимыми, то процессор выбирает один из них для выполнения (делает успешным). По умолчанию из нескольких выполнимых вызовов выбирается тот, который ожидал дольше других.
Последнее изменение в семантике связано с ожиданием по необходимости: если клиент запускает на некотором сепаратном объекте один или более вызовов и выполняет на этом объекте вызов запроса, то этот вызов может выполняться лишь после завершения всех ранее начавшихся, а все остальные операции клиента будут ждать завершения этого вызова запроса. (Мы уже отмечали, что оптимизирующая реализация может применять это правило только к запросам, возвращающим развернутый результат.) Во время ожидания завершения этих вызовов клиент остается в состоянии "зарезервирован".
Сепаратные сущности
Общее правило разработки ПО заключается в том, что семантическое различие всегда должно отражаться на различии текстов программ.
Сейчас, когда у нас появилось два варианта семантики вызова, нужно сделать так, чтобы в тексте программы можно было однозначно указать, какой из них имеется в виду. Ответ определяется тем, совпадает ли обработчик (процессор) цели вызова O2 с обработчиком инициатора вызова O1. Поэтому нужно маркировать не вызов, а сущность x, обозначающую целевой объект. В соответствии с выработанной в предыдущих лекции политикой статической проверки типов соответствующая метка должна появиться в объявлении x.
Это рассуждение приводит к тому, что для поддержки параллельности достаточно одного расширения нотации. Наряду с обычным объявлением:
x: SOME_TYPEмы будем использовать объявление вида:
x: separate SOME_TYPEдля указания того, что x может присоединяться только к объектам, обрабатываемым специальным процессором. Если класс предназначен только для объявления сепаратных сущностей, то его можно объявить как:
separate class X ... Остальное как обычно ... вместо обычных объявлений class X ... или deferred class X ...|
Это соглашение аналогично тому, что можно объявить y как сущность типа expanded T или, что эквивалентно, как сущность типа T , если T - это класс, объявленный как expanded class T. Три возможности - развернутый (expanded), отложенный (deferred), сепаратный (separate) - являются взаимно исключающими, только одно из этих квалифицирующих слов может стоять перед словом class. |
Это даже поразительно, что достаточно добавить одно ключевое слово для превращения последовательной ОО-нотации в систему обозначений, поддерживающую параллельные вычисления.
Уточним терминологию. Слово "сепаратный" ("separate") можно применять к различным элементам, как статическим (появляющимся в тексте программы), так и динамическим (существующим во время выполнения). Статически: сепаратный класс - это класс, объявленный как separate class; сепаратный тип основывается на сепаратном классе; сепаратная сущность это сущность сепаратного типа или сущность, объявленная как separate T для некоторого T; x.f (...) - это сепаратный вызов, если его цель x является сепаратной сущностью.
Динамически: значение сепаратной сущности является сепаратной ссылкой; если она не пуста, то присоединяется к объекту, обрабатываемому отдельным процессором - сепаратному объекту.
Типичными примерами сепаратных классов являются:
BOUNDED_BUFFER (ОГРАНИЧЕННЫЙ_БУФЕР) задает буфер, позволяющий параллельным компонентам обмениваться данными (некоторые компоненты - производители - помещают объекты в буфер, а другие - потребители - получают объекты из него).PRINTER (ПРИНТЕР), который, по-видимому, правильней называть PRINT_CONTROLLER (КОНТРОЛЕР_ПЕЧАТИ), управляет одним или несколькими принтерами. Считая контроллеры печати сепаратными объектами, приложения не должны ждать завершения заданий на печать (в отличие от ранних Макинтошей, в которых вы застревали до тех пор, пока последняя страница не выползала из принтера).DATABASE (БАЗА ДАННЫХ), клиентская часть которой в архитектуре клиент-сервер может служить для описания базы данных, расположенной на удаленном сервере, которому клиент может посылать запросы по сети.BROWSER_WINDOW (ОКНО_БРАУЗЕРА) позволяет порождать новое окно для просмотра запрошенной страницы.
Сходство
Это соответствие кажется очевидным. Когда мы начинаем сравнивать идеи параллельного программирования и ОО-построения программ, то кажется естественным идентифицировать процессы с объектами, а типы процессов с классами. Каждый, кто вначале изучил параллельные вычисления, а затем открыл ОО-разработку (или наоборот) будет удивлен сходством между этими двумя технологиями:
Обе основаны на автономных, инкапсулированных модулях: процессах или типах процессов и на классах.Объекты и процессы сохраняют содержащиеся в них значения от одной активации до следующей.Для построения параллельной системы на практике требуется налагать строгие ограничения на межмодульный обмен информацией. ОО-подход, как мы видели, тоже налагает строгие ограничения на межмодульную коммуникацию.В обоих случаях механизм коммуникации можно упрощенно описать как "передачу сообщений".Поэтому неудивительно, что многие люди восклицают "Эврика!", когда впервые начинают размышлять, подобно Мильнеру, о наделении объектов параллельностью. Кажется, что можно легко достичь унификации этих понятий.
К сожалению, это первое впечатление ошибочно: после обнаружения первого сходства быстро сталкиваешься с различиями.
Синхронизация параллельных ОО-вычислений
Многие из только что рассмотренных идей помогут выбрать правильный подход к параллельности в ОО-контексте. В полученном решении будут видны понятия, пришедшие из ВПП, из мониторов и условных критических интервалов.
Упор ВПП на взаимодействии представляется нам правильным, поскольку главный метод нашей модели вычислений - вызов компонента с аргументами для некоторого объекта - является механизмом взаимодействия. Но есть и другая причина предпочесть решение, основанное на взаимодействии: механизм, основанный на синхронизации, может конфликтовать с наследственностью.
Этот конфликт наиболее очевиден при рассмотрении путевых выражений. Идея использования выражений на путях привлекла многих исследователей ОО-параллельности. Она дает возможность разделить реальную обработку, заданную компонентами класса, и ограничения синхронизации, задаваемые путевыми выражениями. При этом параллельность не затрагивала бы чисто вычислительные аспекты ПО. Например, если у класса BUFFER имеются компоненты remove (удаление самого старого элемента буфера) и put (добавить элемент), то можно выразить синхронизацию с помощью ограничений, используя обозначения в духе путевых выражений:
empty: {put} partial: {put, remove} full: {remove}|
Эти обозначения и пример взяты из [Matusoka 1993], где введен термин "аномалия наследования". Более подробный пример смотри в У12.3. |
Здесь перечислены три возможных состояния и для каждого из них указаны допустимые операции. Но предположим далее, что потомок класса NEW_BUFFER задал дополнительный компонент remove_two, удаляющий из буфера два элемента одновременно (если размер буфера не менее трех). В этом случае придется почти полностью изменить множество состояний:
empty: {put} partial_one: {put, remove} -- Состояние, в котором в буфере ровно один -- элемент partial_two_or_more: {put, remove, remove_two} full: {remove, remove_two}и если в процедурах определяются вычисляемые ими состояния, то их необходимо переопределять при переходе от BUFFER к NEW_BUFFER, что противоречит самой сути наследования.
Эта и другие проблемы, выявленные исследователями, получили название аномалии наследования (inheritance anomaly) и привели разработчиков параллельных ОО-языков к подозрительному отношению к наследованию. Например, из первых версий параллельного ОО-языка POOL наследование было исключено.
Заботы о проблеме "аномалии наследования" породили обильную литературу с предложениями ее решения, которые по большей части сводились к уменьшению объема переопределений.
Однако при более внимательном рассмотрении оказывается, что эта проблема связана не с наследованием или с конфликтом между наследованием и параллелизмом, а с идеей отделения программ от определения ограничений синхронизации.
Для читателя этой книги, знакомого с принципами проектирования по контракту, методы, использующие явные состояния и список компонентов, применимых в каждом из них, выглядят чересчур низкоуровневыми. Спецификации классов BUFFER и NEW_BUFFER следует задавать с помощью предусловий: put требует выполнения условия require not full, remove_two - require count >= 2 и т. д. Такие более компактные и более абстрактные спецификации проще объяснять, адаптировать и связывать с пожеланиями клиентов (изменение предусловия одной процедуры не влияет на остальные процедуры). Методы, основанные на состояниях, налагают больше ограничений и подвержены ошибкам. Они также увеличивают риск комбинаторного взрыва, отмеченный выше для сетей Петри и других моделей, использующих состояния: в приведенных выше элементарных примерах число состояний уже равно три в одном случае и четыре - в другом, а в более сложных системах оно может быстро стать совершенно неконтролиру емым.
"Аномалия наследования" происходит лишь потому, что такие спецификации стремятся быть жесткими и хрупкими: измените хоть что-нибудь, и вся спецификация рассыплется.
| В начале этой лекции мы наблюдали другой мнимый конфликт между параллельностью и наследованием, но оказалось, что в этом виновно понятие активного объекта. В обоих случаях наследование находится в противоречии не с параллельностью, но с конкретными подходами к ней (активные объекты, спецификации, основанные на состояниях). Поэтому прежде, чем отказываться от наследования или ограничивать его - отрубать руку, на которой чешется палец, - следует поискать более подходящие механизмы параллельности. |
Синхронизация versus взаимодействия
Для понимания того, как следует поддерживать синхронизацию в ОО-параллелизме, полезно начать с обзора не ОО-решений. Процессы (единицы параллельности в большинстве этих решений) нуждаются в механизмах двух видов:
Синхронизации, обеспечивающей временные ограничения. Типичное ограничение утверждает, что некоторая операция одного процесса (например доступ к элементу базы данных), может выполняться только после некоторой операции другого процесса (инициализации этого элемента).Взаимодействия, позволяющего процессам обмениваться информацией, представляющей в ОО-случае объекты (как частный случай, простые значения) или объектные структуры.Одни подходы к параллельности основываются на механизме синхронизации, используя для коммуникации обычные непараллельные методы такие, как передача аргументов. Другие рассматривают в качестве основы взаимодействие, добиваясь затем синхронизации. Можно говорить о механизмах, основанных на синхронизации, и о механизмах, основанных на взаимодействии.
Синтаксис расширяется
Синтаксис расширяется за счет введения только одного нового ключевого слова separate.
Объявление сущности или функции, которое в обычном случае выглядит как:
x: TYPEсейчас может также иметь вид:
x: separate TYPEКроме этого, объявление класса, которое обычно начиналось с class C, deferred class C или expanded class C, сейчас может также иметь вид separate class C. В этом случае C называется сепаратным классом. Из этого синтаксического соглашения вытекает, что у класса может быть не более одного определяющего ключевого слова, например, он не может быть одновременно отложенным и сепаратным. Как и в случае развернутости и отложенности, свойство сепаратности класса не наследуется: класс является или не является сепаратным в соответствии с его собственным объявлением независимо от статуса сепаратности его родителя.
Тип T называется сепаратным, если он основан на сепаратном классе или определен как separate T (если T сам сепаратный, то это не ошибка, хотя и избыточно, действует то же соглашение, что и для развернутых типов). Сущность или функция являются сепаратными, если имеют сепаратный тип. Выражение является сепаратным, если это сепаратная сущность или вызов сепаратной сущности. Вызов или инструкция создания являются сепаратными, если их цель (выражение) является сепаратной. Предложение предусловия сепаратно, если оно содержит сепаратный вызов (чья цель, в соответствии с приведенным далее правилом, является формальным аргументом).
Система управления лифтом
Следующий пример демонстрирует случай использования ОО-технологии и определенного в этой лекции механизма для получения привлекательной децентрализированной управляемой событиями архитектуры для некоторого приложения реального времени.
В этом примере описывается ПО управления системой нескольких лифтов, обслуживающих много этажей. Предлагаемый ниже проект объектно-ориентирован до фанатичности. Каждый сколь нибудь существенный компонент физической системы - например, кнопка с номером этажа в кабине лифта - отображается в свой сепаратный класс. Каждый соответствующий объект, такой как кнопка, имеет свой собственный поток управления (процессор). Тем самым мы приближаемся к процитированному в начале лекции пожеланию Мильнера сделать все объекты параллельными. Преимущество такой системы в том, что она полностью управляется событиями, не требуя никаких циклов для постоянной проверки состояний объектов (например, нажата ли кнопка).
Тексты классов, приведенные ниже, являются лишь набросками, но они дают хорошее представление о том, каким будет полное решение. В большинстве случаев мы не приводим процедуры создания.
|
Данная реализация примера с лифтом, приспособленная к показу управления на экранах нескольких компьютеров через Интернет (а не для реальных лифтов), была использована на нескольких конференциях для демонстрации ОО-механизмов параллельности и распределенности. |
Класс MOTOR описывает мотор, связанный с одной кабиной лифта и интерфейс с механическим оборудованием:
separate class MOTOR feature {ELEVATOR} move (floor: INTEGER) is -- Переместиться на этаж floor и сообщить об этом do "Приказать физическому устройству переместится на floor" signal_stopped (cabin) end signal_stopped (e: ELEVATOR) is -- Сообщить, что лифт остановился на этаже e do e.record_stop (position) end feature {NONE} cabin: ELEVATOR position: INTEGER is -- Текущий этаж do Result := "Текущий этаж, считанный с физических датчиков" end endПроцедура создания этого класса должна связать кабину лифта cabin с мотором.
В классе ELEVATOR имеется обратная информация: с помощью атрибута puller указывается мотор, перемещающий данный лифт.
Причиной для выделения лифта и его мотора как сепаратных объектов является желание уменьшить "зернистость" запираний: сразу после того, как лифт пошлет запрос move своему мотору, он станет готов, благодаря политике ожидания по необходимости, к приему запросов от кнопок внутри и вне кабины. Он будет рассинхронизирован со своим мотором до получения вызова процедуры record_stop через процедуру signal_stopped. Экземпляр класса ELEVATOR будет только на очень короткое время зарезервирован вызовами от объектов классов MOTOR или BUTTON.
separate class ELEVATOR creation make feature {BUTTON} accept (floor: INTEGER) is -- Записать и обработать запрос на переход на floor do record (floor) if not moving then process_request end end feature {MOTOR} record_stop (floor: INTEGER) is -- Записать информацию об остановке лифта на этаже floor do moving := false; position := floor; process_request end feature {DISPATCHER} position: INTEGER moving: BOOLEAN feature {NONE} puller: MOTOR pending: QUEUE [INTEGER] -- Очередь ожидающих запросов -- (каждый идентифицируется номером нужного этажа) record (floor: INTEGER) is -- Записать запрос на переход на этаж floor do "Алгоритм вставки запроса на floor в очередь pending" end process_request is -- Обработка очередного запроса из pending, если такой есть local floor: INTEGER do if not pending.empty then floor := pending.item actual_process (puller, floor) pending.remove end end actual_process (m: separate MOTOR; floor: INTEGER) is -- Приказать m переместится на этаж floor do moving := True; m.move (floor) end endИмеются кнопки двух видов: кнопки на этажах, нажимаемые для вызова лифта на данный этаж, и кнопки внутри кабины, нажимаемые для перемещения лифта на соответствующий этаж. Эти два вида кнопок посылают разные запросы: запросы кнопок, расположенных внутри кабины, направляются этой кабине, а запросы кнопок на этажах могут обрабатываться любым лифтом, и поэтому они посылаются объекту-диспетчеру, опрашивающему разные лифты для выбора того, кто будет выполнять этот запрос. (Мы не приводим реализацию этого алгоритма выбора, поскольку это не существенно для данного рассмотрения, то же относится и к алгоритмам, используемым лифтами для управления их очередями запросов pending в классе ELEVATOR).
В классе FLOOR_BUTTON предполагается, что на каждом этаже имеется только одна кнопка. Нетрудно изменить этот проект так, чтобы поддерживались две кнопки: одна для запросов на движение вверх, а другая - вниз.
Удобно, хотя и не очень существенно, иметь общего родителя BUTTON для классов, представляющих оба вида кнопок. Напомним, что компоненты, экспортируемые ELEVATOR в BUTTON, также экспортируются в соответствии со стандартными правилами скрытия информации в оба потомка этого класса:
separate class BUTTON feature target: INTEGER end separate class CABIN_BUTTON inherit BUTTON feature cabin: ELEVATOR request is -- Послать своему лифту запрос на остановку на этаже target do actual_request (cabin) end actual_request (e: ELEVATOR) is -- Захватить e и послать запрос на остановку на этаже target do e.accept (target) end end separate class FLOOR_BUTTON inherit BUTTON feature controller: DISPATCHER request is -- Послать диспетчеру запрос на остановку на этаже target do actual_request (controller) end actual_request (d: DISPATCHER) is -- Послать d запрос на остановку на этаже target do d.accept (target) end endВопрос о включении и выключении света в кнопках здесь не рассматривается. Нетрудно добавить вызовы подпрограмм, которые будут этим заниматься.
Наконец, вот класс DISPATCHER. Чтобы разработать алгоритм выбора лифта в процедуре accept, потребуется разрешить ей доступ к атрибутам position и moving класса ELEVATOR, которые в полной системе должны быть дополнены булевским атрибутом going_up (движется_вверх). Такой доступ не вызовет никаких проблем, поскольку наш проект гарантирует, что объекты класса ELEVATOR никогда не резервируются на долгое время.
separate class DISPATCHER creation make feature {FLOOR_BUTTON} accept (floor: INTEGER) is -- Обработка запроса о посылке лифта на этаж floor local index: INTEGER; chosen: ELEVATOR do "Алгоритм определения лифта, выполняющего запрос для этажа floor" index := "Индекс выбранного лифта" chosen := elevators @ index send_request (chosen, floor) end feature {NONE} send_request (e: ELEVATOR; floor: INTEGER) is -- Послать лифту e запрос на перемещение на этаж floor do e.accept (floor) end elevators: ARRAY [ELEVATOR] feature {NONE} -- Создание make is -- Настройка массива лифтов do "Инициализировать массив лифтов" end end
Сопрограммы (Coroutines)
Хотя наш следующий пример и не является полностью параллельным (по крайней мере в его первоначальном виде), но он важен как способ проверки применимости нашего параллельного механизма.
|
Первым (и, возможно, единственным) из главных языков программирования, включившим конструкцию сопрограмм, был также и первый ОО-язык Simula 67; мы будем рассматривать его механизм сопрограмм при его описании в лекции 17. Там же будут приведены примеры практического использования сопрограмм. |
Сопрограммы моделируют параллельность на последовательном компьютере. Они представляют собой программные единицы, отражающие симметричную форму взаимодействия:
При вызове обычной подпрограммы имеется хозяин и раб. Хозяин запускает подпрограмму, ожидает ее завершения и продолжает с того места, где закончился вызов; однако подпрограмма при вызове всегда начинает работу с самого начала. Хозяин вызывает, а подпрограмма-раб возвращает.Отношения между сопрограммами - это отношения равных. Когда сопрограмма a застревает в процессе своей работы, то она призывает сопрограмму b на помощь; b запускается с того места, где последний раз остановилась, и продолжает выполнение до тех пор, пока сама не застрянет или не выполнит все, что от нее в данный момент требуется; затем a возобновляет свое вычисление. Вместо разных механизмов вызова и возврата здесь имеется одна операция возобновления вычисления resume c, означающая: запусти сопрограмму c с того места, в котором она последний раз была прервана, а я буду ждать, пока кто-нибудь не возобновит (resumes) мою работу.
Рис. 12.12. Последовательность выполнения сопрограмм
Все это происходит строго последовательно и предназначено для выполнения в одном процессе (задании) одного компьютера. Но сама идея получена из параллельных вычислений; например, операционная система, выполняемая на одном ЦПУ, будет внутри себя использовать механизм сопрограмм для реализации разделения времени, многозадачности и многопоточности.
Можно рассматривать сопрограммы как некоторый ограниченный вид параллельности: бедный суррогат параллельного вычисления, которому доступна лишь одна ветвь управления.
Обычно полезно проверять общие механизмы на их способность элегантно упрощаться для работы в ограниченных ситуациях, поэтому давайте посмотрим, как можно представить сопрограммы. Эта цель достигается с помощью следующих двух классов:
separate class COROUTINE creation make feature {COROUTINE} resume (i: INTEGER) is -- Разбудить сопрограмму с идентификатором i и пойти спать do actual_resume (i, controller) end feature {NONE} -- Implementation controller: COROUTINE_CONTROLLER identifier: INTEGER actual_resume (i: INTEGER; c: COROUTINE_CONTROLLER) is -- Разбудить сопрограмму с идентификатором i и пойти спать. -- (Реальная работа resume). do c.set_next (i); request (c) end request (c: COROUTINE_CONTROLLER) is -- Запрос возможного повторного пробуждения от c require c.is_next (identifier) do -- Действия не нужны end feature {NONE} -- Создание make (i: INTEGER; c: COROUTINE_CONTROLLER) is -- Присвоение i идентификатору и c котроллеру do identifier := i controller := c end end separate class COROUTINE_CONTROLLER feature {NONE} next: INTEGER feature {COROUTINE} set_next (i: INTEGER) is -- Выбор i в качестве следующей пробуждаемой сопрограммы do next := i end is_next (i: INTEGER): BOOLEAN is -- Является ли i индексом следующей пробуждаемой сопрограммы? do Result := (next = i) end endОдна или несколько сопрограмм будут разделять один контроллер сопрограмм, создаваемый не приведенной здесь однократной функцей (см. У12.10). У каждой сопрограммы имеется целочисленный идентификатор. Чтобы возобновить сопрограмму с идентификатором i, процедура resume с помощью actual_resume установит атрибут next контроллера в i, а затем приостановится, ожидая выполнения предусловия next = j, в котором j - это идентификатор самой сопрограммы. Это и обеспечит требуемое поведение.
Хотя это выглядит как обычная параллельная программа, данное решение гарантирует (в случае, когда у всех сопрограмм разные идентификаторы), что в каждый момент сможет выполняться лишь одна сопрограмма, что делает ненужным назначение более одного физического ЦПУ. (Контроллер мог бы использовать собственное ЦПУ, но его действия настолько просты, что этого не следует делать.)
Обращение к целочисленным идентификаторам необходимо, поскольку передача resume аргумента типа COROUTINE, т. е. сепаратного типа, вызвала бы блокировку. На практике можно воспользоваться объявлениями unique, чтобы не задавать эти идентификаторы вручную. Такое использование целых чисел имеет еще одно интересное следствие: если мы допустим, чтобы две или более сопрограмм имели одинаковые идентификаторы, то при наличии одного ЦПУ получим механизм недетерминированности: вызов resume (i) позволит перезапустить любую сопрограмму с идентификатором i. Если же ЦПУ будет много, то вызов resume (i) позволит параллельно выполняться всем сопрограммам с идентификатором i.
Таким образом, у приведенной схемы двойной эффект: в случае одного ЦПУ она обеспечивает работу механизма сопрограмм, а в случае нескольких ЦПУ - механизма управления максимальным числом одновременно активных процессов определенного вида.
Состояния и переходы
Рис. 12.10 подводит итог предшествующего обсуждения, показывая различные возможные состояния, в которых могут находиться объекты и процессоры, и их изменения в результате вызовов.
Вызов является успешным, если обработчик его цели не занят или приостановлен, все его непустые сепаратные аргументы присоединены к свободным объектам, а все имеющиеся предложения соответствующего сепаратного предусловия выполнены. Заметим, что это делает определения состояний объекта и процессора взаимно зависимыми.

Рис. 12.10. Состояния объектов и процессоров и переходы между ними
Совместимость с Проектированием по Контракту
Крайне важно сохранение систематического подхода, выраженного в принципах Проектирования по Контракту. Результаты этой лекции основывались на изучении утверждений и их существования в параллельном контексте.
По ходу изучения обнаружилось поразительное свойство. Парадокс параллельных предусловий заставил нас определить новую семантику утверждений для параллельного случая, что подтвердило важную роль утверждений в параллельном механизме.
Сторожевой механизм
Как и предыдущий, следующий пример показывает применимость нашего механизма к задачам реального времени. Он также хорошо иллюстрирует понятие дуэли.
Мы хотим дать возможность некоторому объекту вызвать некоторую процедуру action при условии, что этот вызов будет прерван и булевскому атрибуту failed будет присвоено значение истина (true), если процедура не завершит свое выполнение через t секунд. Единственным доступным средством измерения времени является процедура wait (t), которая будет выполняться в течение t секунд.
Приведем решение, использующее дуэль. Класс, которому нужен указанный механизм, будет наследником класса поведения TIMED и предоставит эффективную версию процедуры action, отложенной в классе TIMED. Чтобы разрешить action выполняться не более t секунд, достаточно вызвать timed_action (t). Эта процедура запускает сторожа (экземпляр класса WATCHDOG), который выполняет wait (t), а затем прерывает клиента. Если же сама процедура action завершится в предписанное время, то сам клиент прервет сторожа. Отметим, что в приведенном классе у всех процедур с аргументом t: REAL имеется предусловие t>=0, опущенное для краткости.
deferred class TIMED inherit CONCURRENCY feature {NONE} failed: BOOLEAN; alarm: WATCHDOG timed_action (t: REAL) is -- Выполняет действие, но прерывается после t секунд, если не завершится -- Если прерывается до завершения, то устанавливает failed в true do set_alarm (t); unset_alarm (t); failed := False rescue if is_concurrency_interrupt then failed := True end end set_alarm (t: REAL) is -- Выдает сигнал тревоги для прерывания текущего объекта через t секунд do -- При необходимости создать сигнал тревоги: if alarm = Void then create alarm end yield; actual_set (alarm, t); retain end unset_alarm (t: REAL) is -- Удалить последний сигнал тревоги do demand; actual_unset (alarm); wait_turn end action is -- Действие, выполняемое под управлением сторожа deferred end feature {NONE} -- Реальный доступ к сторожу actual_set (a: WATCHDOG; t: REAL) is -- Запуск a для прерывания текущего объекта после t секунд do a.set (t) end ...Аналогичная процедура actual_unset предоставляется читателю...feature {WATCHDOG} -- Операция прерывания stop is -- Пустое действие, чтобы позволить сторожу прервать вызов timed_action do -- Nothing end end separate class WATCHDOG feature {TIMED} set (caller: separate TIMED; t: REAL) is -- После t секунд прерывает caller; -- если до этого прерывается, то спокойно завершается require caller_exists: caller /= Void local interrupted: BOOLEAN do if not interrupted then wait (t); demand; callerl stop; wait_turn end rescue if is_concurrency_interrupt then interrupted:= True; retry end end unset is -- Удаляет сигнал тревоги (пустое действие, чтобы дать -- клиенту прервать set) do -- Nothing end feature {NONE} early_termination: BOOLEAN endЗа каждым использованием yield должно, как это здесь сделано, следовать retain в виде: yield; "Некоторый вызов"; retain. Аналогично каждое использование demand (или insist) должно иметь вид: demand; "Некоторый вызов "; wait_turn. Для принудительного выполнения этого правила можно использовать классы поведения.
У12.1 Принтеры
Завершите определение класса PRINTER из третьего раздела этой лекции, реализующего очередь с помощью ограниченного буфера. Обратите внимание на то, что подпрограммы для работы с очередью, такие как print, не нуждаются в обработке специального "запроса на остановку" задания печати (у print в качестве предусловия может быть not j.is_stop_request).
У12.2 Почему импорт должен быть глубоким
Предположим, что доступен только механизм поверхностного (а не deep_import). Постройте пример, в котором порождалась бы некорректная структура, в которой сепаратный объект был бы присоединен к несепаратной сущности.
У12.3 "Аномалия наследования"
Предположим, что в примере BUFFER, использованном для иллюстрации "аномалии наследования" каждая подпрограмма специфицирует свое выходное состояние с помощью инструкции yield, например, как в:
put (x: G) is do "Добавляет x к структуре данных, представляющей буфер" if "Все места сейчас заняты" then yield full else yield partial end endНапишите соответствующую схему для remove. Затем определите класс NEW_BUFFER с дополнительной процедурой remove_two (удалить_два) и покажите, что в этом классе должны быть переопределены оба наследуемых компонента (одновременно определите, какие компоненты применимы в каких состояниях).
У12.4 Устранение тупиков (проблема для исследования)
Начав с принципа визитной карточки, выясните, реально ли устранение некоторых из возможных тупиков с помощью введения правила корректности, налагающего ограничения на использование несепаратных фактических аргументов в сепаратных вызовах. Это правило должно быть разумным (т. е. оно не должно мешать широко используемым схемам), его выполнение должно поддерживаться компилятором (в частности, инкрементным компилятором) и быть легко объяснимым разработчикам.
У12.5 Приоритеты
Исследуйте, как добавить схему приоритетов к механизму дуэлей класса CONCURRENCY, сохранив совместимость вверх с семантикой, определенной для процедур yield, insist и других процедур, связанных с ними.
У12.6 Файлы и парадокс предусловия
Рассмотрите следующий простой фрагмент некоторой подпрограммы для работы с файлом:
f: FILE ... if f /= Void and then f.readable then f.some_input_routine -- some_input_routine - программа, которая читает -- данные из файла; ее предусловием является readable endОбсудите, как, несмотря на отсутствие явной параллельности в этом примере, к нему может примениться парадокс предусловий. (Указание: файл - это сепаратная постоянная структура, поэтому другой интерактивный пользователь или другая программная система могут получить к нему доступ между выполнением двух операций из указанного фрагмента.) К чему в данном случае может привести эта проблема, каковы возможные пути ее решения?
У12.7 Замки (Locking)
Перепишите класс LOCKING_PROCESS как наследника класса PROCESS.
У12.8 Бинарные семафоры
Напишите один или несколько классов, реализующих понятие бинарного семафора. (Указание: начните с классов, реализующих замки.) Как было предложено в конце обсуждения замков, разработайте классы поведения высокого уровня, используемые с помощью наследования и предоставляющие корректные образцы для операций reserve и free.
У12.9 Целочисленные семафоры
Напишите один или несколько классов, реализующих понятие целочисленного семафора.
У12.10 Контроллер сопрограмм
Завершите реализацию сопрограмм, объяснив, как создать для них контроллер.
У12.11 Примеры сопрограмм
В представлении языка Simula имеется несколько примеров сопрограмм. Примените классы сопрограмм из данной лекции для реализации этих примеров.
У12.12 Лифты
Завершите пример с лифтами, добавив все процедуры создания и все опущенные алгоритмы, в частности алгоритм для выбора запросов кнопок на этажах.
У12.13 Сторожа и принцип визитной карточки
Покажите, что процедура set класса WATCHDOG нарушает принцип визитной карточки. Объясните, почему в этом случае все в порядке.
У12.14 Однократные подпрограммы и параллельность
Какова подходящая семантика для однократных подпрограмм в параллельном контексте (как программ, исполняемых один раз при каждом запуске системы, или как программ, исполняемых не более одного раза каждым процессором)?
 |
|
|
Условия ожидания
Осталось рассмотреть еще одно правило синхронизации. Оно имеет отношение к двум вопросам:
как можно заставить клиента ожидать выполнения некоторого условия (как это сделано в условных критических интервалах);что означают утверждения, в частности, предусловия, в контексте параллелизма?Устранение блокировок (тупиков)
Наряду с несколькими важными примерами передачи сепаратных ссылок в сепаратные вызовы, мы видели, что возможна также передача несепаратных ссылок при условии, что соответствующие формальные аргументы объявлены как сепаратные (поскольку на стороне поставщика они представляют чужие объекты и нам не нужны предатели). Несепаратные ссылки увеличивают риск блокировок, и с ними нужно обходиться аккуратно.
Обычный способ передачи несепаратных ссылок состоит в использовании схемы визитной карточки: используется сепаратный вызов вида x.f (a) , где x - сепаратная сущность, а a - нет; иначе говоря, a - это ссылка на локальный объект клиента, возможно, на сам Current. На стороне поставщика f имеет вид:
f (u: separate SOME_TYPE) is do local_reference := u endгде local_reference типа separate SOME_TYPE является атрибутом объемлющего класса поставщика. Далее поставщик может использовать local_reference в подпрограммах, отличных от f, для выполнения операций над объектами на стороне клиента с помощью вызовов вида local_reference.some_routine (...).
Эта схема корректна. Предположим, однако, что f делает еще что-то, например, включает для некоторого g вызов вида u.g (...). Это с большой вероятностью приведет к тупику: клиент (обработчик объекта, присоединенного к u и a) занят выполнением f или, быть может, ожиданием по необходимости выполнения другого вызова, резервирующего тот же объект.
Следующее правило позволяет избежать таких ситуаций:
|
Принцип визитной карточки Если сепаратный вызов использует несепаратный фактический аргумент типа ссылки, то соответствующий формальный аргумент должен использоваться в подпрограмме только в качестве источника присваиваний. |
Пока это только методологическое руководящее указание, хотя было бы желательно ввести соответствующее формальное правило (в упражнениях У12.4 и У12.13 эта идея рассматривается глубже). Дополнительные комментарии о блокировках появятся еще при общем обсуждении.
Вопросы синхронизации
У нас имеется базовый механизм для начала параллельных вычислений (сепаратное создание) и для запроса операций в этих вычислениях (обычный механизм вызова компонентов). Всякое параллельное вычисление, ОО или не ОО, должно также предоставлять возможности для синхронизации параллельных вычислений, т. е. для определения временных зависимостей между ними.
Если вы знакомы с параллелизмом, то, возможно, будете удивлены заявлением, что одного языкового механизма - сепаратных объявлений - достаточно, чтобы включить полную поддержку параллелизма в ОО-подход. Нужен ли на самом деле специальный механизм синхронизации? Оказывается, нет. Основные ОО-конструкции достаточны, чтобы покрыть большую часть потребностей в синхронизации при условии, что определения их семантики будут приспособлены для применения к сепаратным элементам. Это является еще одним свидетельством силы ОО-метода, легко и элегантно адаптирующегося к параллельным вычислениям.
Возникновение параллельности
Вернемся к началу. Чтобы понять, как эволюция потребовала от разработчиков сделать параллельность частью их образа мысли, проанализируем различные виды параллельности. В дополнение к традиционным понятиям мультипроцессорной обработки (multiprocessing) и многозадачности (multiprogramming) за несколько последних лет было введено два новых понятия: посредники запроса объекта (object request brokers) и удаленное выполнение в Сети.
Введение параллельного выполнения
Что же, если не понятие процесса, фундаментально отличает параллельное вычисление от последовательного?
Замки
Предположим, что мы хотим разрешить многим клиентам, которых будем называть ключниками (lockers), получать исключительный доступ к сейфам - закрываемым ресурсам (lockable) - без явного выделения разделов, где происходит этот доступ, исключающий других ключников. Это даст нам механизм типа семафоров. Вот решение:
class LOCKER feature grab (resource: separate LOCKABLE) is -- Запрос исключительного доступа к ресурсу require not resource.locked do resource.set_holder (Current) end release (resource: separate LOCKABLE) is require resource.is_held (Current) do resource.release end end class LOCKABLE feature {LOCKER} set_holder (l: separate LOCKER) is -- Назначает l владельцем require l /= Void do holder := l ensure locked end locked: BOOLEAN is -- Занят ли ресурс каким-либо ключником? do Result := (holder /= Void) end is_held (l: separate LOCKER): BOOLEAN is -- Занят ли ресурс l? do Result := (holder = l) end release is -- Освобождение от текущего владельца do holder := Void ensure not locked end feature {NONE} holder: separate LOCKER invariant locked_iff_holder: locked = (holder /= Void) endВсякий класс, описывающий ресурсы, будет наследником LOCKABLE. Правильное функционирование этого механизма предполагает, что каждый ключник выполняет последовательность операций grab и release в этом порядке. Другое поведение приводит, как правило, к блокировке работы, эта проблема уже была отмечена при обсуждении семафоров как один из существенных недостатков этого метода. Но можно и в этом случае получить требуемое поведение системы, основываясь на силе ОО-вычислений. Не доверяя поведению каждого ключника, можно требовать от них вызова процедуры use, определенной в следующем классе поведения:
deferred class LOCKING_PROCESS feature resource: separate LOCKABLE use is -- Обеспечивает дисциплинированное использование resource require resource /= Void do from create lock; setup until over loop lock.grab (resource) exclusive_actions lock.release (resource) end finalize end set_resource (r: separate LOCKABLE) is -- Выбирает r в качестве используемого ресурса require r /= Void do resource := r ensure resource /= Void end feature {NONE} lock: LOCKER exclusive_actions -- Операции во время исключительного доступа к resource deferred end setup -- Начальное действие; по умолчанию: ничего не делать do end over: BOOLEAN is -- Закончилось ли закрывающее поведение? deferred end finalize -- Заключительное действие; по умолчанию: ничего не делать do end endВ эффективных наследниках класса LOCKING_PROCESS процедуры exclusive_actions и over будут эффективизированы, а setup и finalize могут быть доопределены.
Отметим, что желательно писать класс LOCKING_PROCESS как наследник класса PROCESS.
Независимо от того, используется ли LOCKING_PROCESS, подпрограмма grab не отбирает сейф у всех возможных клиентов: она исключает только ключников, не соблюдающих протокол. Для закрытия доступа к ресурсу любому клиенту нужно включить операции доступа в подпрограмму, которой ресурс передается в качестве аргумента.
Подпрограмма grab из класса LOCKER является примером того, что называется схемой визитной карточки: ресурсу resource передается ссылка на текущего ключника Current, трактуемая как сепаратная ссылка.
Основываясь на представляемых этими классами образцах, нетрудно написать и другие реализации разных видов семафоров (см. У12.7). ОО-механизмы помогают пользователям таких классов избежать классической опасности семафоров: выполнить для некоторого ресурса операцию резервирования reserve и забыть выполнить соответствующую операцию освобождения free. Разработчик, использующий класс поведения типа LOCKING_PROCESS, допишет отложенные операции в соответствии с нуждами своего приложения и сможет рассчитывать на то, что предопределенная общая схема обеспечит выполнение после каждой reserve соответствующей операции free.
Запросы специальных услуг
Мы завершили описание основ политики взаимодействия и синхронизации. Для большей гибкости полезно было бы определить еще несколько способов прерывания нормального процесса вычисления, доступных в некоторых случаях.
Так как эти возможности не являются частью основной модели параллелизма, а добавляются для удобства, то они вводятся не как конструкции языка, а как библиотечные компоненты. Мы будем считать, что они помещены в класс CONCURRENCY, из которого могут наследоваться классами, нуждающимися в таких механизмах. Аналогичный подход был уже дважды использован в этой книге:
для дополнения базисной обработки исключений более тонкими средствами управления с помощью библиотечного класса EXCEPTIONS лекция 12 курса "Основы объектно-ориентированного программирования";для дополнения стандартного механизма управления памятью и сбором мусора более тонкими средствами управления с помощью библиотечного класса MEMORY (см. лекцию 9 курса "Основы объектно-ориентированного программирования").