Адаптация через наследование
При обнаружении потенциально полезного класса иногда обнаруживается, что он не в полной мере отвечает потребностям и требует адаптации.
Если у класса нет дефектов, требующих их устранения в оригинале, то обычно предпочтительнее оставить класс в целости и сохранности, заботясь о его клиентах в полном соответствии с принципом Открыт-Закрыт. Вместо этого можно использовать наследование и переопределение, настраивающее класс (потомка) на новые потребности.
Эта техника (см. лекцию 10), которая еще будет изучаться в деталях под именем вариационное наследование (variation inheritance), предполагает, что новый класс задает вариант той же абстракции, что и оригинал. При подходящем использовании она представляет наиболее значительный вклад в Метод, позволяя разрешить проблему reuse-redo - сочетание повторного использования с расширяемостью.
Большое Заблуждение
Большинство из сигналов опасности, обсуждаемых ниже, указывают на общую и наиболее опасную ошибку, одновременно и наиболее очевидную - проектирование класса, которого нет.
При ОО-конструировании модули строятся вокруг типов объектов, а не функций. В этом ключ к преимуществам, открываемым при расширяемости системы и ее повторном использовании. Но новички склонны попадать в наиболее очевидную ловушку, называя классом то, что в действительности является функцией (подпрограммой). Записав модуль в виде class... feature ... end, еще не означает появления настоящего класса, это просто программа, скрывающаяся под маской класса.
Этого Большого Заблуждения (Grand Mistake) достаточно просто избежать, как только оно осознано. Проверка ситуации обычная: следует убедиться, что каждый класс соответствует осмысленной абстракции данных. Из этого следует, что всегда есть риск, что модуль, представленный как кандидат в классы, и носящий одежды класса, на самом деле является нелегальным иммигрантом, не заслуживающим гражданства в обществе ОО-модулей.
Другие источники классов
Несколько эвристик доказали свою полезность в битвах за правильные абстракции.
Файлы
"Хранилища" несут общую полезную идею. Иногда большая часть информации традиционных систем находятся не в их программном тексте, а в структуре используемых файлов.
Для всякого с опытом Unix эта идея достаточно ясна: основная документация содержит описание не столько специфических команд, а описание ключевых файлов и их форматов: passwd для паролей, printcap для свойств принтера, termcap или terminfo для свойств терминала. Эти файлы можно характеризовать как абстракции данных без абстракции - документированные на совершенно конкретном уровне ("Каждый вход в printcap файле описывает принтер и представляет строку, состоящую из полей, разделенных символом двоеточия" и т. д.). Файлы задают важные типы данных, доступные через хорошо определенные примитивы с ассоциированными свойствами и условиями использования. При переходе к ОО-подходу такие файлы должны играть центральную роль.
Подобное наблюдение применимо ко многим программам, использующим файлы. Однажды я консультировал менеджера программной системы, убежденного, что его система - коллекция Fortran программ - не может использоваться в целях ОО-декомпозиции. Когда он описывал, что делают его программы, он упоминал о нескольких файлах, обеспечивающих взаимодействие между программами. Я начал задавать вопросы об этих файлах, но он полагал, что они не имеют отношения к делу, считая их неважными. Я настаивал, и из объяснений стало понятно, что файлы описывают сложные структуры данных, охватывающие основные понятия программы. Урок ясен: с осознанием важности файлов пришло понимание, что они должны играть центральную роль в ОО-архитектуре, а бывшие ключевые элементы стали играть вспомогательную роль компонентов классов.
Идеальный класс
Этот обзор возможных ошибок по контрасту проявляет характерные черты идеального класса. Вот его некоторые типичные свойства:
Имеется четко ассоциированная с классом абстракция данных (абстрактная машина).Имя класса является существительным или прилагательным, адекватно характеризующим абстракцию.Класс представляет множество возможных объектов в период выполнения - его экземпляров. Некоторые классы во время выполнения могут иметь только один экземпляр, что тоже приемлемо.Для нахождения свойств экземпляра доступны запросы.Для изменения состояния экземпляра доступны команды. В некоторых случаях у класса нет команд, но есть функции, создающие новые объекты, что тоже приемлемо.Абстрактные свойства могут быть установлены неформально или формально, что предпочтительнее. Они устанавливают, как результаты различных запросов связаны друг с другом (инвариант класса), при каких условиях компоненты класса применимы (предусловия), как выполнение команд сказывается на запросах (постусловия).Этот список описывает множество неформальных целей, не являясь строгим правилом. Легитимный класс может обладать лишь одним из перечисленных свойств. Большинство из примеров, играющих важную роль в этой книге, - начиная от классов LIST и QUEUE до BUFFER, ACCOUNT, COMMAND, STATE, INTEGER, FIGURE, POLYGON и многих других, - обладают всеми этими свойствами.
Императивные имена
Предположим, что в процессе проектирования появились классы с такими именами, как PARSE (РАЗОБРАТЬ) или PRINT (ПЕЧАТАТЬ) - глагол в императивной форме. Это должно насторожить, не делает ли класс одну вещь и, следовательно, не должен быть классом.
Возможно, вы найдете, что с классом все в порядке, но тогда имя его выбрано неудачно. Вот "абсолютно положительное" правило:
|
Правило Имен класса Имя класса всегда должно быть либо: cуществительным, возможно квалифицированным;прилагательным (только для отложенных классов, описывающих структурное свойство). |
Хотя подобно любым другим правилам, относящимся к стилю, это дело соглашения, оно помогает поддерживать принцип: каждый класс представляет абстракцию данных.
Первая форма - существительные - покрывает большинство важнейших случаев. Существительное может появляться само по себе, например TREE, или с квалифицирующими словами - LINKED_LIST, квалифицируемое прилагательным, LINE_DELETION, квалифицируемое другим существительным.
Вторая форма возникает в специфических случаях - классах, описывающих структурное свойство, как, например, библиотечный класс COMPARABLE, описывающий объекты с заданным отношением порядка. Такие классы должны быть отложены, их имена (в английском и французском языках) часто заканчиваются на ABLE. Так, в системе, учитывающей ранжирование игроков в теннис, класс PLAYER может быть наследником класса COMPARABLE. В таксономии видов наследования эта схема классифицируется как структурное наследование (см. лекцию 6).
Единственный случай, который может показаться исключением из правила, задает командные классы, так как они введены в шаблоне проектирования undo-redo, покрывающем абстракции действий. Но даже и здесь можно следовать правилу, задавая имена командных классов текстового редактора в виде: LINE_DELETION и WORD_CHANGE, а не DELETE_LINE и REPLACE_WORD (Удаление_Строки, а не Удалить_Строку).
Английский язык предоставляет большую гибкость, чем многие другие языки, где грамматическая категория - это скорее дело веры, чем факта, и почти каждый глагол может быть и существительным. При использовании английского языка в программных именах легче придерживаться этого правила и строить короткие имена. Вы можете назвать класс IMPORT , рассматривая это имя как существительное, а не как глагол. В других языках вам пришлось бы строить более тяжеловесное имя, нечто вроде IMPORTATION. Но здесь не должно быть надувательства: класс IMPORT должен покрывать абстракцию данных - "объекты, подлежащие импорту", а не быть командным классом, задающим единственную операцию импорта.
|
Заметьте разницу между Правилом Имен Класса и подходом "подчеркивания существительных", обсуждаемым в начале лекции. При подчеркивании формальный грамматический критерий применяется к неформальному тексту - документу с требованиями, потому ценность его сомнительна. Наше же Правило Имен применяет тот же критерий к формальному тексту. |
Использование ситуаций
Ивар Якобсон ([Jacobson 1992]) пропагандирует использование ситуаций для выявления классов. Ситуации, называемые также сценариями (scenario) или трассами, описываются как
полный набор событий, инициированных пользователем или системой, и взаимодействий между пользователем и системой.В телефонной системе ситуация, например "вызов, инициированный заказчиком", приводит к последовательности событий: заказчик поднимает трубку телефона, системе посылается сигнал идентификации, система вырабатывает гудок и так далее.
Использование ситуаций не самый лучший способ нахождения классов. Здесь возникает несколько рискованных моментов:
В сценариях предполагается упорядоченность. Это несовместимо с объектной технологией (см. лекцию 7 курса "Основы объектно-ориентированного программирования"). Не следует основываться на порядке действий, поскольку порядок в первую очередь подвержен изменениям. Не следует фокусироваться на свойствах в форме: "система выполняет a, затем b"; вместо этого следует задавать вопрос: "Какие операции доступны для экземпляров абстракции A, и каковы ограничения на эти операции?" По-настоящему фундаментальные свойства, отражающие последовательность выполнения операций, задаются ограничениями высокого уровня. Утверждение, что для стека число операций pop не должно превосходить число операций push, можно выразить в более абстрактной форме, используя пред и постусловия этих операций. Менее абстрактные свойства порядка вообще не должны учитываться на этапе анализа. При работе со сценариями возможность таких ошибок велика.Сценарии также предполагают фокусирование на пользовательском видении операций. Но система пока еще не существует. Может существовать ее предыдущая версия, но, если бы она была полностью удовлетворительной, то не возникала бы потребность в ее переписывании. Ваша задача состоит в том, чтобы предложить лучший сценарий. Есть много примеров неудач, связанных с рабским повторением существующих процедур.Использование сценариев предпочитают при функциональном подходе, основанном на процессах (действиях).Сохраняется опасность, что под маской классов скрывается традиционная форма функционального проектирования. Этот подход противоположен ОО-декомпозиции, сфокусированной на абстракции данных. Использование нескольких сценариев исключает одну главную программу, но и здесь начальной точкой остается вопрос, что делает система, в отличие от объектного подхода, где важнее, кто это делает. Дисгармония неизбежна.Практические следствия очевидны:
|
Принцип использования сценариев За исключением очень опытных команд разработчиков (имеющих опыт создания нескольких систем, содержащих несколько тысяч классов в чистом ОО-языке) не следует основываться на сценариях как средстве ОО-анализа и проектирования. |
Еще одно применение сценариев связано с заключительными аспектами реализации - система может включать специальные программы для запуска типичных сценариев. Такие программы зачастую задают некоторый вид абстрактного поведения, описывая общую схему, которая может быть переопределена различными способами. В книге [Jacobson 1992] вводится понятие абстрактного сценария, что в объектной терминологии называется классом поведения.
В этих двух ролях - механизме проверки и управления реализацией - использование сценариев дает несомненную пользу. Но в объектной технологии они не являются полезным средством анализа или проектирования. Разработчикам следует концентрироваться на абстракциях, а не на том, в каком порядке выполняются операции.
Изучение документа "технические требования"
Для понимания проблемы поиска классов, возможно, лучше всего начать с известного и широко опубликованного подхода.
Как избежать бесполезных классов
Существительные в документе с требованиями покрывают некоторое множество классов будущего проекта, но они также включают слишком много "ложных тревог" - концепций, не заслуживающих того, чтобы быть классами.
В примере с лифтовой системой door является существительным, но необходим ли класс DOOR? Может быть, да, может быть - нет. Возможно, что единственным свойством дверей лифта является их способность открываться и закрываться. Тогда проще включить это свойство в виде соответствующего запроса и команды в класс ELEVATOR:
door_open: BOOLEAN; close_door is ... ensure not door_open end; open_door is ... ensure door_open endВ другом варианте понятие двери может заслуживать отдельного класса. Единственной реальной основой является здесь теория АТД. Вот вопрос, на который действительно следует ответить:
|
Является ли "door" независимым типом данных с собственными четко определенными операциями или все они уже включены в операции других типов данных, таких как, например, ELEVATOR? |
Только наша интуиция и опыт проектировщика даст нам правильный ответ. Грамматические правила анализа документа требований малосодержательны. Вместо них следует обращаться к теории АТД, помогающей задавать правильные вопросы заказчикам и будущим пользователям системы.
Мы уже встречались (см. лекцию 3) с подобной ситуацией при проектировании механизма откатов и возвратов. Речь шла о понятии commands и более общем понятии operation, включающем запросы, подобные Undo. Оба слова фигурировали в документе требований, однако, только COMMAND приводил к абстракции данных - важнейшему классу проекта.
Категории классов
Можно выделить три категории классов: классы анализа, классы проектирования, классы реализации. Это деление не является ни абсолютным, ни строгим (например, кто-то может привести аргументы в поддержку того, что отложенный класс LIST принадлежит к любой из трех категорий), но такое деление удобно как общее руководство.
Классы анализа описывают абстракцию данных, непосредственно выводимую из модели внешней системы. Типичными примерами являются классы PLANE в системе управления полетами, PARAGRAPH в системе обработки документов, PART в системе управления запасами.
Классы реализации описывают абстракцию данных, введенную, исходя из внутренних потребностей алгоритмов системы, например LINKED_LIST или ARRAY.
Классы проектирования описывают архитектурный выбор. Примерами могут служить класс COMMAND в системе, реализующей откаты, класс STATE в системе, управляемой панелями. Подобно классам реализации, классы проектирования принадлежат пространству решений, в то время как классы анализа принадлежат пространству проблемной области. Но подобно классам анализа и в отличие от классов реализации они описывают концепции высокого уровня.
Когда мы научимся получать классы всех трех категорий, мы обнаружим, что наиболее трудно идентифицировать классы проектирования, требующие архитектурной интуиции. Заметьте, сложность в выявлении этих классов не означает, что их трудно построить. Сложностью построения скорее отличаются классы реализации, если только мы не используем готовую библиотеку.
Классы без команд
Иногда можно обнаружить классы, вообще не имеющие команд или допускающие только запросы (доступ к объектам только в режиме чтения), но не команды (процедуры, модифицирующие объекты). Такие классы являются эквивалентами записей языка Pascal или структур Cobol и C. Такие классы могут появиться из-за ошибок проектирования, которые могут быть двух видов, а, следовательно, нуждаются в некотором исследовании.
Прежде всего, рассмотрим три случая, когда такой класс не является результатом неподходящего проектирования:
Он может представлять объекты, полученные из внешнего мира, не подлежащие изменениям в ПО. Это могут быть данные датчиков от органов системы управления прибора, пакеты, передаваемые в сети, структуры С, которых ОО-система не должна касаться.Некоторые классы не предназначены для прямого использования - они могут инкапсулировать константы или выступают в качестве родителей других классов. Такое льготное наследование (facility inheritance) будет изучаться при обсуждении методологии наследования (см. лекцию 6).Наконец, класс может быть аппликативным - описывающим объекты, не подлежащие модификации. Это означает, что у класса есть только функции, создающие новые объекты. Например, операция сложения в классах INTEGER, REAL и DOUBLE следует математическим традициям - она не модифицирует значение, но, получив x и y, вырабатывает значение: x + y. В спецификации АТД такие функции характеризуются как командные функции.Во всех этих случаях абстракции обнаруживаются довольно просто, так что не трудно идентифицировать оставшиеся два случая, которые реально могут указывать на дефекты проектирования.
Теперь вернемся к подозрительным случаям. В первом из них появление класса оправдано, команды классу нужны - проектировщик просто забыл обеспечить механизм модификации объектов. Простая техника контрольной ведомости (checklist) позволяет избежать подобных ошибок (см. лекцию 5).
Во втором случае существование класса не оправдано. Он не является настоящей абстракцией данных, представляет пассивную информацию, которая может быть задана структурой, подобной списку или массиву, добавленной в виде атрибута к какому-либо классу.
Этот случай встречается, когда разработчик пишет класс, исходя из системы, ранее написанной на Pascal или Ada, отображая запись в класс. Но не все типы записей представляют независимые абстракции данных.
Следует внимательно исследовать подобную ситуацию, чтобы понять, имеем ли мы дело с настоящим классом, теперь или в будущем. Если ответ неясен, то может быть лучше оставить класс, даже с риском неоправданных расходов. Класс влечет некоторую потерю производительности, поскольку приводит к динамическому созданию объектов, для них может потребоваться больше памяти, чем в случае простого массива. Но, если класс действительно понадобится, и он не был введен своевременно, то позднейшие затраты на адаптацию могут быть велики.
| Подобная история имела место при разработке ISE компилятора. Для внутренних потребностей идентификации классов решено было использовать целые числа, а не специальные объекты. Все это хорошо работало несколько лет. Но потом схема идентификации усложнилась, в частности пришлось перенумеровывать классы при слиянии нескольких систем в одну. Так что пришлось вводить класс CLASS_IDENTIFIER и заменять экземплярами этого класса прежние целые. Это потребовало усилий больше, чем хотелось бы. |
Ключевые концепции
Идентификация классов - одна из принципиальных задач ОО-конструирования ПО.Идентификация классов - двойственный процесс - предложение кандидатов и их отбор. Нужно уметь находить потенциальных кандидатов и уметь отсеивать неподходящих.Идентификация классов - это идентификация подходящих абстракций в моделируемой области пространстве решений."Подчеркивание существительных в документе требований" - это не подходящая техника для обнаружения потенциальных классов, так как ее результаты зависят от стиля написания документа. Она может приводить как к появлению лишних кандидатов, так и к пропуску нужных.Классы разделяются на три группы. Классы анализа связаны с концепциями моделируемого внешнего мира. Классы проектирования описывают архитектурные решения. Классы реализации описывают структуры данных и алгоритмы.Классы проектирования обычно требуют наибольшей изобретательности.При проектировании внешних классов помните, что внешние объекты включают концепции наряду с материальными предметами.Применяйте критерий абстракции данных всякий раз, когда нужно решить, представляет ли данное понятие настоящий класс.Классы реализации включают как эффективные, так и отложенные классы, описывающие абстрактные категории.Наследование обеспечивает повторное использование с одновременной адаптацией к изменившимся условиям.Способ получения классов состоит в оценке кандидатов и поиске необнаруженных абстракций, в частности путем анализа межмодульных передач данных.Использование Case-технологии или сценариев может быть полезно как средство проверки правильности и как руководство на заключительных этапах реализации, но не должно использоваться на этапах анализа и проектирования.Лучшим источником классов являются библиотеки повторного использования.
КОС (CRC) карты
Для полноты картины упомянем идею, рассматриваемую иногда как метод нахождения классов. Карты КОС (Класс, Ответственность, Сотрудничество) или CRC (Class, Responsibility, Collaboration) являются бумажными карточками, используемыми разработчиками при обсуждении потенциальных классов, в терминах их ответственностей и взаимодействия. Идея проста, отличается дешевизной - набор карточек дешевле рабочей станции с CASE инструментарием. Но его технический вклад в процесс проектирования неясен.
Метод получения классов
Мало-помалу идеи, обсуждаемые в этой лекции, в совокупности дают то, что не слишком претенциозно можно называть методом получения классов при конструировании ПО (напомним, метод - это способ породить, воспитать, проложить дорогу, создать нечто стоящее).
Идентификация класса требует двух неразрывно связанных видов деятельности - выявления множества кандидатов в классы и отбора среди них действительно нужных. В двух следующих таблицах подводятся итоги.
Прежде всего начнем с источников классов.
| Существующие библиотеки | Классы, отвечающие потребностям приложения.Классы, описывающие концепции, релевантные приложению. |
| Документ требований | Часто встречающиеся термины.Термины, заданные явными определениями. Термины, не определенные точно, но считающиеся само собой разумеющимися. (Грамматические категории следует игнорировать.) |
| Обсуждения с заказчиками и будущими пользователями | Важные абстракции проблемной области. Специфический жаргон проблемной области. Помнить, что классы, приходящие из "внешнего мира", могут описывать как материальные, так и концептуальные объекты. |
| Документация (руководства пользователей) для других систем в той же проблемной области, например от конкурентов | Важные абстракции проблемной области. Специфический жаргон проблемной области. Полезные абстракции проектирования. |
| Не ОО-системы и их описания | Элементы данных, передаваемые в виде аргументов компонентам ПО.Разделяемые данные (Common блоки FORTRAN). Важные файлы. Секции данных (COBOL). Типы записей (Pascal, C, C++). Сущности при ER-моделировании. |
| Обсуждения с опытными проектировщиками | Классы проектирования, успешно используемые в предыдущих разработках. |
| Литература по алгоритмам и структурам данных | Известные структуры данных, поддержанные эффективными алгоритмами. |
| Литература по ОО-проектированию | Применимые образцы проектирования. |
Рассмотрим теперь критерии, позволяющие более внимательно исследовать классы и, возможно, отвергнуть часть из них.
| Класс с вербальным именем (инфинитив или императив) | Может быть простой подпрограммой, а не классом |
| Полностью эффективный класс с одной экспортируемой подпрограммой | Может быть простой подпрограммой, а не классом. |
| Класс, описанный как "выполняющий нечто" | Может не быть подходящей абстракцией. |
| Класс без подпрограмм | Может быть важной частью информации, но не АТД. Может быть АТД, для которого просто забыли указать операции. |
| Класс, введенный без компонентов или с небольшим их числом (но наследующий компоненты своих родителей) | Может быть результатом "таксомании". |
| Класс, покрывающий несколько абстракций | Должен быть разделен на несколько классов, по одному на каждую абстракцию. |
Мой класс выполняет...
В формальных и неформальных обсуждениях архитектуры проекта часто задается вопрос о роли некоторого класса. И часто можно слышать в ответ: "Этот класс печатает результаты" или "Класс разбирает вход" - варианты общего ответа "Этот класс делает...".
Такой ответ обычно указывает на изъяны в проекте. Класс не должен делать одну вещь, он должен предлагать несколько служб в виде компонентов над объектами некоторого типа. Если же он выполняет одну работу, то, скорее всего, имеет место "Большое Заблуждение".
Вполне вероятно, что ошибка не в самом классе, а способе его описания - использовании операционной фразеологии. Но все-таки в этой ситуации лучше провести проверку класса.
Находки других подходов
Пример анализа потока данных в нисходящей структуре иллюстрирует идею выявления класса при рассмотрении необъектной декомпозиции. Это полезно в двух непересекающихся случаях:
Может существовать не ОО-система, выполняющая свою часть работы. Тогда разумно провести ее анализ с позиций классов. Иногда, вместо работающей системы, используются результаты анализа или проектирования, выполненного другими, старыми методами.Некоторые из разработчиков могут иметь большой опыт работы в создании не объектных систем и, как следствие, вначале проектируют систему в терминах других концепций, затем реализуют ее в виде классов.Вот примеры этого процесса, начиная с языков программирования и заканчивая методами анализа и проектирования.
Программы Fortran включают обычно один или несколько общих блоков (common blocks) - данных, разделяемых многими подпрограммами. Зачастую за общими блоками стоят очень важные абстракции данных. Более точно, хорошие Fortran программисты знают, что в общий блок следует включать те переменные и массивы, которые соответствуют тесно связанным понятиям, и в этом случае за этим стоит шанс создать класс на основе общего блока. К сожалению, это не универсальная практика, - в начале этой книги упоминалось о "мусорном" общем блоке, куда сваливают все подряд. В этом случае анализ должен проводиться куда более тщательно для обнаружения подходящих абстракций.
Программы Pascal и C используют записи, известные в C как структуры. Они могут также соответствовать классам при условии выявления операций над данными записей. Если это не так, то запись будет представлена атрибутами некоторого класса.
Структуры Cobol и его секции данных (Data Division) помогают идентифицировать важные типы данных.
При рассмотрении моделей, основанных на понятиях "сущность-отношение", сущности ("entities") часто служат основой для построения классов.
При проектировании потоков данных (dataflow) немногое может быть непосредственно использовано для ОО-целей, но иногда "хранилища" (stores) могут приводить к нужным абстракциям.
Нахождение классов проектирования
Классы проектирования представляют архитектурные абстракции, помогающие создавать элегантные расширяемые программные структуры. Хорошими примерами являются классы: STATE, APPLICATION, COMMAND, HISTORY_LIST, итератор и контроллер. Мы увидим и другие полезные идеи в последующих лекциях, такие как активные структуры данных и описатели ("handles").
Хотя, как отмечалось, нет уверенного способа найти классы проектирования, дадим несколько полезных советов - это лучше, чем ничего.
Многие классы проектирования были изобретены уже до нас. Так что чтение книг и статей, описывающих решение проблем проектирования, может дать много плодотворных идей. Например, книга "Объектно-ориентированные приложения" ([M 1993]) содержит лекции, написанные ведущими разработчиками различных промышленных проектов. Приводятся точные и детальные архитектурные решения, полезные в таких областях, как телекоммуникации, автоматизированное проектирование, искусственный интеллект, и других проблемных областях.Книга Гаммы ([Gamma 1995]) посвящена образцам проектирования, за ней последовали другие подобные книги.Многие полезные классы проектирования лучше понимаются как "машины", чем как "объекты" в общем смысле этого слова.Как и в случае классов реализации, повторное использование лучше, чем изобретение. Можно надеяться, что текущие образцы перестанут быть просто идеями и превратятся в непосредственно используемые библиотечные классы.Нахождение классов реализации
Классы реализации описывают структуры, создаваемые разработчиками по внутренним соображениям, диктуемым реализацией системы. Хотя в литературе по программной инженерии часто принято принижать роль реализации, отводя ей роль кодирования, разработчики хорошо знают, реализация требует немалого интеллекта, и на нее приходится большая часть усилий по разработке системы.
Плохая новость - классы реализации трудно строить. Хорошая новость - их легко выявить. Для них может существовать хорошая библиотека, допускающая повторное использование. По крайней мере, есть хорошая литература по этой тематике. Курс "Алгоритмы и структуры данных", иногда известный как CS 2, является необходимым компонентом образования в области информатики. Хотя большинство из существующих учебников явно не используют ОО-подход, многие следуют стилю АТД. Преобразование в классы в этом случае довольно прямолинейно и естественно.
В настоящее время некоторые учебники начали применять ОО-подход при изложении традиционных тем CS 2.
Каждый разработчик, независимо от того, проходил ли он этот курс, должен держать на своей книжной полке учебники по структурам данных и алгоритмам и обращаться к ним довольно часто. Легко ошибиться и выбрать неверное представление или неэффективный алгоритм, например, применить односвязный список к последовательной структуре, где по алгоритму требуется проходы в обоих направлениях, или использовать массив для структуры, растущей или сжимающейся непредсказуемым образом. Заметьте, в вопросах реализации по-прежнему правит АТД-подход - структуры данных и их представление следуют из служб, предлагаемых клиенту.
Помимо учебников и опыта лучшим вариантом для классов реализации являются библиотеки повторного использования.
Нужен ли новый класс?
Еще одним примером существительного в примере с лифтом является слово floor. В отличие от дверей с их единственной операцией, понятие этажа является разумным АТД, однако этого мало, чтобы появился класс FLOOR.
Причина проста: в данном случае для целей лифтовой системы вполне достаточно представлять этажи целыми числами - их номерами, так расстояние между этажами может быть выражено простой разностью целых чисел.
Если, однако, этажи имеют свойства, не отображаемые номерами, тогда может потребоваться класс FLOOR. Например, некоторые этажи могут иметь специальные права доступа, разрешающие их посещение только избранным особам, и тогда класс FLOOR может включать свойство:
rights: SET [AUTHORIZATION]и связанные с ним процедуры. Но и в этом случае нет полной определенности. Возможно, стоит вместо создания класса включить в некоторый другой класс массив:
floor_rights: ARRAY [SET [AUTHORIZATION]]связывающий множество значений AUTHORIZATION с каждым этажом, идентифицируемым его номером (см. У4.1).
Еще одним аргументом в пользу создания независимого класса FLOOR могла бы послужить возможность ограничения доступных операций над классом. Так операции вычитания и сравнения этажей должны быть доступными, а сложение и умножение лишены смысла и должны быть недоступны. Такой класс мог быть представлен как наследник класса INTEGER.
Это обсуждение снова приводит нас к теории АТД. Класс не должен представлять физические "объекты" в наивном смысле. Он должен описывать абстрактный тип данных - множество программных объектов, характеризуемых хорошо определенными операциями и их формальными свойствами. Типы реальных объектов могут и не иметь двойников в программном мире - классов. Когда решается вопрос - стать ли некоторому понятию классом, только АТД является правильным критерием, позволяя сказать, соответствует ли данное понятие классу программной системы или оно покрывается уже существующими классами.
"Релевантность системе" является определяющим критерием. Цель анализа системы не в том, чтобы "моделировать мир", - об этом пусть заботятся философы. Создатели ПО не могут позволить себе этого, по крайней мере, в своей профессиональной деятельности, их задачей является моделирование мира лишь в той мере, которая касается создаваемого ПО. Подход АТД и соответственно ОО-метода основан на том, что объекты определяются только тем, что мы можем с ними делать, - это называлось (см. лекцию 6 курса "Основы объектно-ориентированного программирования") Принципом Разумного Эгоизма. Если операция или свойство объекта не отвечают целям системы, то они и не включаются в состав класса, хотя и могут представлять интерес для других целей. Понятие PERSON может включать такие компоненты, как mother и father, но для системы уплаты налогов они не нужны, здесь личность выступает сама по себе, подобно сироте.
Если все операции и свойства некоторого типа не связаны с целями системы или покрываются другими классами, то сам тип не должен рассматриваться как самостоятельный класс.
Обнаружение и селекция
Чтобы что-то изобрести, нужны двое. Один находит варианты, другой отбирает, обнаруживает, что является важным в той массе, которую представил первый. В том, что мы называем гением, значительно меньшая доля от первого, чем от второго, отбирающего нужное из того, что разложено перед ним. Поль Валери (процитировано в [Hadamard 1945])
Помимо прямых уроков это обсуждение ведет к более тонким следствиям.
Простые уроки звучали неоднократно: не слишком полагаться на документ с требованиями, не доверять грамматическим критериям.
Менее очевидный урок вытекает из обзора ложных тревог. Суть его в том, что нужен не только критерий для поиска классов, но и критерий для отбраковки (rejecting) кандидатов. Концепция может показаться вначале обнадеживающей, а в результате анализа она отбраковывается. Примеров подобных ситуаций в данной книге предостаточно (см. лекцию 5).
В книгах по ОО-анализу и проектированию, которые мне довелось читать, довольно мало рассуждений по этому вопросу. Это удивительно, поскольку в практике консультирования ОО-проектов, особенно в командах новичков, я обнаруживал, что исключение плохих идей не менее важно, чем нахождение хороших.
Это может быть даже более важно. Как правило, идей по поводу классов (обычно предлагаемых в виде объектов) хватало с избытком. Проблемой было поставить плотину на пути этого потока. Хотя некоторые важные классы пропускались, значительное большее количество отвергалось по результатам анализа.
Так что следует расширить рамки названия, вынесенного в заголовок этой лекции. Термин "Как найти классы?" означает две вещи: поиск абстракций, подходящих на роль кандидатов в классы, и исключение из них неадекватных задаче нашей системы. Эти две задачи не следует рассматривать как последовательные, - они постоянно перемешиваются. Подобно садовнику, ОО-разработчик должен постоянно высаживать новые растения и выпалывать плохие.
|
Принцип Выявления класса Выявление класса - это двойственный процесс: генерирование кандидатов, их отбраковка. |
Остаток этой лекции посвящен изучению составляющих этого процесса.
Общие эвристики для поиска классов
Давайте теперь обратимся к положительной части нашего обсуждения - практическим эвристикам поиска классов.
Оценивание кандидатов декомпозиции
Критиковать проще, чем создавать. Один из способов обучения проектированию состоит в анализе существующих проектов. В частности, когда некоторое множество классов предлагается для решения определенной проблемы, следует проанализировать их в соответствии с критериями и принципами модульности, представленными в лекции 3 курса "Основы объектно-ориентированного программирования", - составляют ли они автономные, согласованные модули со строго ограниченными каналами коммуникации? Часто обнаруживаются модули, тесно связанные, взаимодействующие с большим числом модулей, имеющие длинные списки аргументов, - все это указывает на ошибки проектирования, устранение которых ведет к построению лучшего решения.
Важный критерий исследовался (см. лекцию 2) в примере системы, управляемой панелями, - потоки данных. Мы видели тогда, как важно при рассмотрении структуры класса кандидата анализировать потоки объектов, передаваемых как аргументы в последовательных вызовах. Если, как это было с понятием состояния, обнаруживается, что некоторый элемент информации передается многим модулям, то это определенный признак того, что пропущена важная абстракция данных. Такой анализ привел нас к необходимости введения класса STATE, важного источника абстракции.
Конечно, предпочтительнее найти правильные классы с самого начала. При позднем, апостериорном обнаружении следует найти время на анализ причин, почему важная абстракция была пропущена, чтобы извлечь уроки на будущее.
Однопрограммные классы
Типичным симптомом Большого Заблуждения является эффективный класс, содержащий одну, часто весьма важную, экспортируемую подпрограмму, возможно вызывающую несколько внутренних подпрограмм. Такой класс - вероятно, результат функциональной, а не ОО-декомпозиции.
Исключением являются объекты, вполне законно представляющие абстрактные действия, например команды интерактивной системы (см. лекцию 3), или то, что в не объектном подходе представляло бы функцию, передаваемую в качестве аргумента другой функции. Но примеры, приведенные в предыдущих обсуждениях, достаточно ясно показывают, что даже в этих случаях у класса может быть несколько полезных компонентов. Так для класса, задающего подынтегральную функцию, может существовать не только компонент item, возвращающий значение функции. Другие компоненты этого класса могут задавать максимум и минимум функции на некотором интервале, ее производную. Даже если класс не содержит этих компонентов, знание того, что они могут появиться позднее, заставляет нас считать, что мы имеем дело с настоящей абстракцией.
При применении однопрограммного правила следует рассматривать все компоненты класса: те, которые введены в самом классе, и те, что введены в родительских классах. Нет ничего ошибочного, когда в тексте класса содержится описание одной экспортируемой подпрограммы, если это простое расширение вполне осмысленной абстракции, определенной его предками. Это может, однако, указывать на случай таксомании (taxomania), изучаемый позже как часть методологии наследования (см. лекцию 6).
Отложенные классы реализации
В традиционных учебниках естественно описываются эффективные (полностью реализованные) классы. На практике ценность большинства классов реализации, особенно, когда предполагается их повторное использование, связана с таксономией - структурой наследования, включающей отложенные классы. Например, различные реализации очереди могут быть потомками отложенного класса QUEUE, описывающего абстрактные концепции.
"Отложенный класс реализации" - это не нелепица (oxymoron). Классы, подобные QUEUE, хотя и абстрактны, но помогают построить таксономию с согласованными вариациями структур реализации, отводя каждому классу точное место в общей схеме.
В одной из своих книг ([M 1993]) я описал "Линнеевскую" таксономию фундаментальных структур информатики, в основе которой лежат отложенные классы, характеризующие принципиальные виды структур данных, используемых при разработке ПО.
Подход снизу вверх
Начиная с этапа анализа, следует применять разработку снизу вверх. Подход, сосредоточенный исключительно на документе с требованиями и запросами пользователей (как это делается в case-технологии) приводит к системам, требующим больших затрат и не учитывающим важного понимания сути, достигнутой в предыдущих проектах. Одной из задач команды разработчиков является, начиная с фазы рассмотрения требований к системе, учет того, что уже доступно, как существующие классы могут помочь в новой разработке. В ряде случаев это приводит к пересмотру требований.
Довольно часто, когда мы говорим о нахождении классов, подразумевается их изобретение (devising). В объектной технологии с ростом качества библиотек и осознания идей повторного использования приобретает смысл именно поиск (finding) классов.
Предыдущие разработки
Совет искать то, что доступно, применим не только к библиотечным классам. Когда вы пишете приложения, вы аккумулируете классы, облегчающие при правильном проектировании дальнейшие разработки.
Не все повторно используемое ПО таким и рождалось. Зачастую первая версия класса рождается для удовлетворения текущих потребностей. Однако затем, через некоторое время после разработки выясняется, что стоит затратить усилия на то, чтобы сделать класс общим и более устойчивым, улучшить документацию, добавить утверждения. Это отличается от ситуации, когда класс создается с самого начала как повторно используемый, но не менее плодотворно. Включенные в реальную систему классы проходят первую проверку на повторное использование, называемую используемость, - они служат, по крайней мере, одной полезной цели.
Преждевременная классификация
Упомянув таксоманию, следует отметить еще одну общую ошибку новичков - преждевременное построение иерархии классов.
Наследование занимает центральное место в ОО-методе, так что хорошая структура наследования, или более аккуратно, хорошая модульная структура, включающая отношения наследования и вложенности (клиентские), - основа качества проектирования. Но наследование уместно только для хорошо понимаемых абстракций. Когда они только разыскиваются, то думать о наследовании может быть рано.
Единственным четким исключением является ситуация, в которой для области приложения разработана и широко применяется таксономия, как это имеет место в некоторых областях науки. Тогда соответствующие абстракции будут появляться вместе со структурой наследования.
В других случаях к созданию иерархии наследования следует приступать после появления основных абстракций. Конечно, в результате этих усилий может потребоваться пересмотр ранее введенных абстракций; задачи выявления классов и структуры наследования взаимно питают друг друга. Если на ранних стадиях процесса проектирования некоторые разработчики фокусируются на проблемах классификации, когда родительские классы еще не до конца поняты, то, вероятно, речь идет о попытках запрячь телегу впереди лошади.
Мне приходилось видеть людей, начинавших с создания классов SAN_FRANCISCO и HOUSTON наследников класса CITY, когда нужно было промоделировать ситуацию с одним классом CITY и несколькими его экземплярами - объектами периода выполнения.
Пропуск важных классов
Подчеркивание существительных может не только приводить к понятиям, не создающим классов, но и к пропуску понятий, которые должны быть классами. Есть, по меньшей мере, три причины возникновения таких ситуаций.
|
Напомню, мы анализируем ограничения подхода "подчеркивания существительных" лишь для лучшего понимания процесса поиска классов. |
Первой причиной пропуска классов являются гибкость и неоднозначность естественного языка - те самые качества, благодаря которым он применим в самых широких областях - от ораторских речей и романов до любовных писем. Но эти же качества становятся недостатком при написании сухой и строгой технической документации. Предположим, что наш документ с требованиями к лифтовой системе содержит предложение:
|
Запись базы данных должна создаваться всякий раз, когда лифт перемещается от одного этажа к другому (A database record must be created every time the elevator moves from one floor to another). |
Существительное "record" предполагает класс DATABASE_RECORD; но при этом можно пропустить более важную абстракцию данных: понятие move, определяющее перемещение между этажами. Из смысла данного предложения скорее следует необходимость класса MOVE, например, в форме:
class MOVE feature initial, final: FLOOR; -- Или INTEGER, если нет класса FLOOR record (d: DATABASE) is ... ... Другие компоненты... endЭтот важный класс вполне мог быть пропущен при простом грамматическом разборе предложения. Правда, наше предложение могло появиться и в другой форме:
|
Каждое перемещение лифта приводит к созданию записи в базе данных (A database record must be created for every move of the elevator from one floor to another). |
Здесь "move" из глагола переходит в разряд существительных, претендуя на класс в соответствии с грамматическим критерием. Угрозы и абсурдность подхода, основанного на анализе документа, написанного на естественном языке, очевидны. Такое серьезное дело, как проектирование системы, в частности ее модульная структура, не может зависеть от причуд стиля и настроения автора документа.
Другая важная причина в пропуске критически важных абстракций состоит в том, что они могут не выводиться непосредственно из документа с требованиями. Примерами подобных ситуаций изобилует данная книга. Вполне возможно, что в документе, определяющем требования к системе, управляемой панелями (см. лекцию 2) ни слова нет о понятиях состояние или приложение (State, Application), задающих ключевые абстракции нашего заключительного проекта. Ранее уже отмечалось, что некоторые понятия внешнего мира могут не иметь двойников среди классов системы ПО. Имеет место и обратная ситуация: классы ПО могут не соответствовать никаким объектам внешнего мира. Аналогично, если автор требований к текстовому редактору, включающему откаты, написал: "система должна поддерживать вставку и удаление строк" (the system must support line insertion and deletion), то нам повезло, и мы обратим внимание на существительные insertion и deletion. Но необходимость этих свойств точно также должна следовать из предложения в форме:
| Редактор должен позволять пользователям вставлять и удалять строки в текущей позиции курсора (The editor must allow its users to insert or delete a line at the current cursor position). |
Третья главная причина пропуска классов характерна для любого метода, использующего документ с требованиями как основу анализа, поскольку такая стратегия не учитывает повторного использования. Удивительно, но литература по ОО-анализу (см. лекцию 9) исходит из традиционного взгляда на разработку - все начинается с документа с техническими требованиями на систему и движется к поиску решения проблемы, описанной в документе. Один из главных уроков объектной технологии как раз состоит в том, что не существует четко выраженного различия между постановкой проблемы и ее решением. Существующее ПО может и должно влиять на новые разработки.
Когда ОО-разработчик сталкивается с новым программным проектом, он не должен смотреть на документ с требованиями как на альфу и омегу мудрости по данной проблеме - он должен сочетать его со знанием предыдущей разработки и доступных программных библиотек.
При необходимости он может предложить обновления документа, облегчающие конструирование системы, например, удалив свойство, представляющее ограниченный интерес для пользователей, но кардинально упрощающее систему, возможно, в интересах повторного использования. Подходящие абстракции, скорее всего, находятся в существующем ПО, а не в документе с требованиями для нового проекта.
Классы COMMAND и HISTORY_LOG из примера, посвященного откатам, являются в этом отношении типичными. Способ нахождения подходящих абстракций для этой проблемы состоит не в том, чтобы сушить мозги над документом с требованиями к текстовому редактору. Это может быть процесс интеллектуального озарения ("Эврика", для которого не существует рецептов), или кто-то до нас уже нашел решение, и нам остается повторно использовать его абстракции. Конечно, можно повторно использовать и существующую реализацию, если она доступна как часть библиотеки, в этом случае вся работа по анализу, проектированию и реализации уже была бы сделана для нас.
Сигналы опасности
Наш поиск предпочтительнее начать с процесса отбраковки кандидатов. Давайте рассмотрим типичные признаки, указывающие на плохой выбор. Поскольку проектирование не является строго формализованной дисциплиной, не следует рассматривать эти признаки как доказательство - в конкретной ситуации, несмотря на признаки, предложенное решение может быть вполне законным. В терминах предыдущей лекции эти признаки не являются "абсолютно отрицательными", но "рекомендательно отрицательными" - сигналами опасности, предупреждающими о присутствии подозрительных образцов, требующих тщательного рассмотрения.
Сказка о поиске классов
Жил да был в стране ООП молодой человек, которому страстно хотелось узнать секрет нахождения классов. Он расспрашивал всех местных мастеров, но никто из них не знал этой тайны.
Будучи подвергнутым публичной епитимии Схемом-Блоком - аббатом Священного Порядка Стрелок и Пузырей, - он решил, что тому известна истина и настал конец его поискам. С трудом он отыскал пещеру Схема, вошел в нее и увидел Схема, погруженного в поиски вечного различия между Классами и Объектами. Осознав, что не здесь обретается истина, без единого вопроса он покинул пещеру и отправился в дальнейшие странствия.
Однажды он нечаянно подслушал разговор двух людей, один из которых занимался вталкиванием какого-то груза в тележку, а другой немедленно его выталкивал. Они шептались о неком старце, знающем секрет классов. Молодой человек решил найти этого великого Мастера. Много дорог он прошел, на многие горы он поднимался, многие реки пересекал, пока не нашел убежище Мастера. Поиски продолжались так долго, что он давно уже перестал быть молодым человеком. Но, как всем пилигримам, ему еще предстояло пройти очищение в течение тридцати трех месяцев, прежде чем он был допущен к объекту своих поисков.
Наконец, в один из темных зимних дней, когда снег покрыл все окружающие горные вершины, он вошел в комнату Мастера. С бьющимся сердцем, пересохшим от волнения голосом он задал свой сакраментальный вопрос: "Мастер, как мне найти классы?"
Мудрец склонил свою голову и ответил медленно и спокойно: "Возвращайся назад, откуда пришел. Классы уже найдены".
Оглушенный, он и не заметил, как слуги Мастера выводили его прочь. "Мастер", - теперь он почти кричал, - "пожалуйста, еще только один вопрос. Как называется эта история?" Старый Учитель покачал головой: "Разве ты еще не понял? Это сказка о повторном использовании".
Смешение абстракций
Еще один признак несовершенного проектирования состоит в том, что в одном классе смешиваются две или более абстракций.
|
В ранней версии библиотеки NeXT текстовый класс обеспечивал полное визуальное редактирование текста. Пользователи жаловались, что, хотя класс полезен, но очень велик. Большой размер класса - это симптом, истинная причина состояла в том, что были слиты две абстракции - собственно редактирование строк и визуализация текста. Класс был разделен на два класса: NSAttributedString, определяющий механизм обработки строк, и NSTextView, занимающийся интерфейсом. |
Мэйлир Пейдж Джонс ([Page-Jones 1995]) использует термин соразвитие (connascence), означающий совместное рождение и совместный рост. Для классов соразвитие означает отношение, существующее между двумя тесно связанными компонентами, когда изменение одного влечет одновременное изменение другого. Как он указывает, следует минимизировать соразвитие между классами библиотеки, но компоненты, появляющиеся внутри данного класса, все должны быть связаны одной и той же четко определенной абстракцией.
Этот факт заслуживает отдельного методологического правила, сформулированного в "положительной" форме:
|
Принцип Согласованности класса Все компоненты класса должны принадлежать одной, хорошо определенной абстракции. |
Существительные и глаголы
В нескольких публикациях предлагается простое правило для получения классов, - начинайте с документа "технические требования" (считается, что кто-то его создал, но это уже другая история). В функционально-ориентированном проекте следует концентрироваться на глаголах, соответствующих действиям. При ОО-проектировании отмечайте существительные, описывающие объекты. Так из предложения:
Лифт закрывает дверь, прежде чем двигаться к следующему этажу (The elevator will close its door before it moves to another floor)функционально-ориентированный разработчик извлечет необходимость создания функции "move", а ОО-разработчик увидит необходимость создания объектов трех типов: ELEVATOR, DOOR and FLOOR, приводящих к классам. Вот?!
Как было бы прекрасно, если бы жизнь была такой простой! Вы бы захватили документ с требованиями домой на вечерок, сыграли бы за обеденным столом в игру "Погоня За Объектами". Это был бы хороший способ отвлечь детей от телевизора, повторить заодно грамматику и помочь маме с папой в их важной работе по конструированию ПО.
К сожалению, такой примитивный метод не слишком помогает. Естественный язык, используемый экспертами при составлении технических требований, обладает столь многими нюансами, субъективными вариациями, двусмысленностями, что крайне опасно принимать важные решения на основе грамматического анализа такого документа. Вполне возможно, что учитывались бы не столько свойства проектируемой системы, сколько особенности авторского стиля.
Метод "подчеркивание существительных" дает лишь очевидные понятия. Любой разумный ОО-метод проектирования системы управления лифтом будет включать класс ELEVATOR. Получение подобных классов не самая трудная часть задачи. Повторяя сказанное в предыдущих обсуждениях, генерируемые понятия нуждаются в прополке - необходимо отделить зерна от плевел.
Хотя идея подчеркивания существительных не заслуживает особого рассмотрения, мы будем использовать ее для контраста, для лучшего понимания тех ограничений, подстерегающих нас на пути поиска классов.
У4.1 Floors как integers
Определите класс FLOOR как наследника INTEGER, ограничив применимые операции.
У4.2 Инспектирование объектов
Даниел Холберт и Патрик О-Брайен обсуждали проблему, возникающую при проектировании окружения разработки ПО:
Рассмотрим свойство inspector, используемое для отображения информации об объекте в окне отладки. Для разных объектов нужны разные инспекторы. Например, информация о точке может быть выведена в простом формате, а о большом идвумерном массиве может потребовать вертикального и горизонтального скроллинга. Прежде всего следует решить, где описать поведение инспектора - в классе, связанном с инспектируемым объектом, или в отдельном классе?Отвечая на это вопрос, рассмотрите все за и против каждого варианта. Заметьте, могут оказаться полезными результаты обсуждения, приведенные в последующих лекциях, посвященных наследованию.

Внешние объекты: нахождение классов анализа
Давайте начнем с классов анализа, моделирующих внешние объекты.
Мы используем ПО для получения ответов на некоторые вопросы о внешнем мире, для взаимодействия с этим миром, для создания новых сущностей этого мира. В каждом случае ПО должно основываться на некоторой модели мира, на законах физики или биологии в научных программах, на синтаксисе и семантике языка программирования при построении компилятора, налоговых постановлений в системе расчета налогов.
|
В нашем разговоре мы избегаем термина "реальный мир", вводящего в заблуждение, поскольку ПО не менее реально, чем что-либо другое. Миры, которыми интересуются при создании ПО, зачастую искусственны, как, например, миры математика. Мы должны говорить о внешнем мире в противовес внутреннему миру ПО. |
Любая программная система основывается на операционной модели некоторых аспектов внешнего мира. Операционной, поскольку используется для генерирования практических результатов, а иногда и для создания обратной связи, возвращая результаты во внешний мир. Модель, потому что любая полезная система должна следовать определенной интерпретации некоторых феноменов этого мира.
Эта точка зрения наиболее явно проявляется в такой области как моделирование (simulation). Неслучайно, что первый ОО-язык программирования Simula 67 вырос из Simula 1 - языка моделирования дискретных событий. Хотя Simula 67 является универсальным языком общего назначения, он сохранил имя своего предшественника и включил множество мощных примитивов моделирования. В семидесятые годы моделирование являлось принципиальной областью приложения объектной технологии. Привлекательность ОО-идей для моделирования легко понять - создавать структуру программной системы, моделирующей поведение множества внешних объектов, проще всего при прямом отображении этих объектов в программные компоненты.
В широком смысле построение любой программной системы является моделированием. Исходя из операционной модели, ОО-конструирование ПО использует в качестве первых абстракций некоторые типы, непосредственно выводимые из анализа объектов в непрограммном смысле этого термина, объектов внешнего мира: датчиков, устройств, самолетов, служащих, банковских счетов, интегрируемых функций.
|
Эти примеры рисуют лишь часть общей картины. Как заметили Валден и Нерсон ([Walden 1995]) в представлении метода B.O.N: "Класс, описывающий автомобиль, не более осязаем, чем тот, который моделирует удовлетворенность служащих своей работой" Следует всегда иметь в виду этот комментарий при поиске внешних классов - они могут быть довольно абстрактными: SENIORITY_RULE в парламентской системе голосования, MARKET_TENDENCY в рыночной системе могут быть также реальны, как SENATOR и STOCK_EXCHANGE. Улыбка Чеширского Кота - такой же объект, как и сам Чеширский Кот. |
Будучи материальными или абстрактными, внешние классы, используемые специалистами, всегда дают хороший шанс породить полезные внутренние классы. Но ключом остается абстракция. Хотя и желательно добиваться соответствия классов анализа концепциям проблемной области, но не эта близость делает класс удачным. Первая версия нашей системы, управляемой панелями, драматично это показала, - она была прекрасной моделью, построенной по образцу внешней системы, но оказалась ужасной с позиций инженерии программ. Хороший внешний класс должен базироваться на абстрактных концепциях проблемной области, характеризуемых внешними свойствами долговременной значимости.
Для ОО-разработчиков предварительно существующие абстракции являются драгоценными - они дают некоторые из фундаментальных классов системы, но, отметим еще раз, являются объектами для прополки.
Абстрактное состояние, конкретное состояние
Из дискуссии о ссылочной прозрачности, казалось бы, следует желательность запрета конкретного побочного эффекта у функций. Такое правило имело то преимущество, что его можно было бы встроить непосредственно в язык, так как компилятор может легко обнаруживать наличие конкретного побочного эффекта у функций.
К сожалению, это неприемлемое ограничение. Принцип Разделения Команд и Запросов запрещает только абстрактные побочные эффекты, к объяснению которых мы и переходим. Дело в том, что некоторые конкретные побочные эффекты не только безвредны, но и полезны. Есть два таких вида.
Первая категория включает функции, модифицирующие состояние по ходу выполнения. Они изменяют видимые компоненты, но, заканчивая свою работу, все приводят в порядок, восстанавливая исходное состояние. Рассмотрим в качестве примера класс, описывающий целочисленный список с курсором и функцию, вычисляющую максимальный элемент списка:
max is -- Максимальное значение элементов списка require not empty local original_index: INTEGER do original_index := index from start; Result := item until is_last loop forth; Result := Result.max (item) end go (original_index) endДля прохода по списку алгоритму необходимо перемещать курсор поочередно ко всем элементам, так что функция, вызывающая такие процедуры, как start, forth и go, полна побочными эффектами, но, начиная свою работу с курсором в позиции original_index, она и заканчивает свою работу в этой же позиции, благодаря вызову процедуры go. Но ни один компилятор в мире не может обнаруживать, что подобные побочные эффекты только кажущиеся, а не реальные.
Побочные эффекты второго приемлемого типа могут реально изменять состояние объектов, воздействуя на невидимые клиентам свойства. Для более глубокого понимания концепции полезно вернуться к обсуждению понятий абстрактной функции и инвариантов реализации, рассматриваемых в лекции 11 курса "Основы объектно-ориентированного программирования", в частности стоит взглянуть на рисунки, соответствующие этим понятиям.
Сделать это нетрудно. На практике АТД определяется интерфейсом, предлагаемым классом своим клиентам (отраженным, например, в краткой форме класса). Побочный эффект будет действовать на абстрактный объект, если он изменяет результат какого-либо из запросов, доступных клиентам. Вот определение:
|
Определение: абстрактный побочный эффект Абстрактным побочным эффектом является такой конкретный эффект, который может изменить значение несекретного запроса. |
Определение ссылается на "несекретные", а не на экспортируемые запросы. Причина в том, что между статусами "секретный" (закрытый) и "экспортируемый" допускается статус выборочно экспортируемых запросов. Как только запрос "несекретный" - экспортируемый какому-либо из клиентов за исключением NONE, - мы полагаем, что изменение его результата является абстрактным побочным эффектом.
Активные структуры данных
Примеры этой и предыдущих лекций часто используют понятие списка или последовательности, характеризуемой в каждый момент "позицией курсора", указывающей точку доступа, вставки и удаления. Такой вид структуры данных широко применим и заслуживает детального рассмотрения.
Для понимания достоинств такого подхода полезно начать с общего рассмотрения и оценки его ограничений.
Апостериорная схема
Когда не работает априорная схема, иногда возможна простая апостериорная схема. Идея состоит в том, чтобы раньше выполнить операцию, а затем определить, как она прошла. Идея работает, если неудачи при выполнении операции не имеют печальных последствий прерывания вычислений.
Примером может служить по-прежнему решение системы линейных уравнений. При апостериорной схеме клиентский код может выглядеть так:
a.invert (b) if a.inverted then x := a.inverse else ... Подходящие действия для сингулярной матрицы... endФункция inverse заменена процедурой invert, более аккуратным именем которой было бы attempt_to_invert. При вызове процедуры вычисляется атрибут inverted, истинный или ложный в зависимости от того, найдено ли решение. В случае успеха решение становится доступным через атрибут inverse. (Инвариант класса может быть задан в виде: inverted = (inverse /= Void).)
При таком подходе любая функция, выполнение которой может давать ошибку, преобразуется в процедуру, вычисляющую атрибут, характеризующий ошибку и атрибут, задающий результат, если он получен. Для экономии памяти вместо атрибута можно использовать однократную функцию (см. лекцию 18 курса "Основы объектно-ориентированного программирования").
Это также работает и для операций, связанных с внешним миром. Например, функцию чтения входных данных "read" лучше представить процедурой, осуществляющей попытку чтения с двумя атрибутами - одним булевым, указывающим была ли операция успешной, и другим, дающим результат ввода в случае успеха.
Эта техника, как можно заметить, полностью согласуется с Принципом Разделения Команд и Запросов. Функция, которая может давать ошибку при выполнении, не должна представлять результат как побочный эффект. Лучше преобразовать ее в процедуру (команду) и иметь два запроса к атрибутам, вычисляемым командой. Все согласуется и с идей представления объектов как машин, чье состояние изменяется командами и доступно через запросы.
Пример с функциями ввода типичен для случаев, когда эта схема дает преимущества. Большинство функций чтения, поддерживаемых языками программирования или встроенными библиотеками, имеют форму "next integer", "next string", требуя от клиента предоставления корректного формата данных. Неизбежно они приводят к ошибкам, когда ожидания не совпадают с реальностью. Предлагаемые процедуры чтения могут осуществлять попытку ввода без всяких предусловий, а затем уведомлять о ситуации, используя запросы, доступные клиенту.
Этот пример наглядно показывает правило, относящееся к "работе над ошибками": лучше избегать ошибок, чем исправлять их последствия.
Априорная схема
Вероятно, наиболее важный критерий, позволяющий справляться с особыми случаями на уровне интерфейса модуля - это спецификация. Если вы точно знаете, какие входы готов принять каждый программный элемент и какие гарантии он дает на выходе, то половина битвы уже выиграна.
Эта идея была глубоко разработана в лекции 11 курса "Основы объектно-ориентированного программирования", где изучалось Проектирование по Контракту. В частности, мы видели, что, противореча общепринятой мудрости, надежность не достигается включением возможных проверок. Ответственность четко разделяется, каждый класс - клиент или поставщик - несет свою долю ответственности.
Включение ограничений в предусловие подпрограммы означает, что за их выполнение отвечает клиент. Предусловие выражает те требования, которые необходимы, чтобы операцию можно было выполнить.
operation (x:...) is require precondition (x) do ... Код, работающий только при условии выполнения предусловия... endПредусловие должно быть полным, когда это возможно, гарантируя, что любой удовлетворяющий ему вызов успешно закончится. В этом случае у клиента есть два способа работы. Один - явная проверка условия перед вызовом операции:
if precondition (y) then operation (y) else ... Подходящие альтернативные действия... end(Для краткости этот пример использует неквалифицированный вызов, но, конечно же, большинство вызовов будут квалифицированными в форме: z.operation (y).) Чтобы избежать теста if...then...else, следует убедиться, что из контекста следует выполнение предусловия:
...Некоторые инструкции, которые, среди прочего, гарантируют выполнение предусловия... check precondition (y) end operation (y)Желательно в этих случаях включать инструкцию check, дающую два преимущества: для читателя программного текста становится ясным, что предусловие не забыто, в случае же, если вывод о выполнении предусловия был ошибочным, при включенном мониторинге утверждений облегчается отладка. (Если вы забыли детали инструкции check, обратитесь к лекции 11 курса "Основы объектно-ориентированного программирования".)
Такое использование предусловий, обеспечиваемое клиентом до вызова - либо путем явной проверки, либо как следствие выполнения других инструкций, - может быть названо априорной схемой: клиента просят выполнить некие мероприятия во избежание любых ошибок.
АТД и абстрактные машины
Понятие активной структуры данных широко применимо и согласуется с ранее введенными принципами, в частности с Принципом Разделения Команд и Запросов. Явно вводя состояние структуры данных, зачастую приходим к простому интерфейсу документа.
Кто-то может высказать опасение, что в результате структура становится менее абстрактной, но это не тот случай. Абстракция не означает пассивность. Теория АТД говорит, что объекты становятся известными через описания применимых операций и свойств, но это не предполагает их рассмотрение как хранилищ данных. Введение состояния и операций над ним фактически обогащает спецификацию АТД, добавляя функции и свойства. Состояние является чистой абстракцией, всегда непосредственно доступной благодаря командам и запросам.
Взгляд на объекты как на машину с состояниями соответствует тому, что АТД становятся более императивными, но не менее абстрактными.
Чистый стиль для интерфейса класса
Из принципа Разделения Команд и Запросов следует стиль проектирования, вырабатывающий простой, понятный при чтении программный текст, способствующий надежности, расширяемости и повторному использованию.
Как вы могли заметить, этот стиль отличается от доминирующей сегодня практики, в частности от стиля программирования на языке C, предрасположенного к побочным эффектам. Игнорирование разницы между действием и значением - не просто свойство общего C-стиля (иногда кажется, что C-программисты не в силах противостоять искушению, получая значение, что-нибудь не изменить при этом). Все это глубоко встроено в язык, в такие его конструкции, как x++, означающую возвращение значения x, а затем его увеличение на 1; нимало не смущающую конструкцию ++x, увеличивающую x до возвращения значения; Эти конструкции сокращают несколько нажатий клавиш: y = x++ эквивалентно y = x; x := x+1. Целая цивилизация фактически построена на побочном эффекте.
Было бы глупо полагать бездумным стиль побочных эффектов. Его широкое распространение говорит о том, что многие находят его удобным, чем частично объясняется успех языка C и его потомков. Но то, что было привлекательным в прошлом веке, когда популяция программистов возрастала каждые несколько лет, когда важнее было сделать работу, не задумываясь о ее долговременном качестве, - не может подходить инженерии программ двадцать первого столетия. Мы хотим, чтобы ПО совершенствовалось вместе с нами, чтобы оно было понятным, управляемым, повторно используемым, и ему можно было бы доверять. Принцип Разделения Команд и Запросов является одним из требуемых условий достижения этих целей.
Строгое разделение команд и запросов при запрете побочных эффектов в функциях особенно важно при построении больших систем, где ключом успеха является сохранение полного контроля над каждым межмодульным взаимодействием.
Если вы пользовались противоположным стилем, то на первых порах ограничение может показаться довольно строгим. Но, получив практику, я думаю, вы быстро осознаете его преимущества.
В предыдущих лекциях этот принцип Разделения применялся повсюду. Вспомните, в наших примерах интерфейс для всех стеков включал процедуру remove, описывающую операцию выталкивания (удаление элемента из вершины стека), и функцию item, возвращающую элемент вершины. Первая является командой, вторая - запросом. При других подходах обычно вводят подпрограмму (функцию) pop, удаляющую элемент из стека и возвращающую его в качестве результата. Этот пример, надеюсь, ясно показывает выигрыш в ясности и простоте, получаемый при четком разделении двух аспектов.
Другие следствия принципа могут показаться более тревожными. При чтении ввода многие пользуются функциями, подобными getint, - имя взято из C, но ее эквиваленты имеются во многих языках. Эта функция читает очередной элемент из входного потока и возвращает его значение, очевидно, она обладает побочным эффектом:
если дважды вызвать getint (), то будут получены два разных ответа;вызовы getint () + getint () и 2 * getint () дают разные результаты (если сверхусердный "оптимизирующий" компилятор посчитает первое выражение эквивалентным второму, то вы пошлете его автору разгневанный отчет об ошибке, и будете правы).Другими словами, мы потеряли преимущества ссылочной прозрачности - рассмотрение программных функций как их математических аналогов с кристально ясным взглядом на то, как можно строить выражения из функций и что означают эти выражения.
Принцип Разделения возвращает ссылочную прозрачность. Это означает, что мы будем отделять процедуру, передвигающую курсор к следующему элементу, и запрос, возвращающий значение элемента, на который указывает курсор. Пусть input имеет тип FILE; инструкция чтения очередного целого из файла input будет выглядеть примерно так:
input.advance n := input.last_integerВызвав last_integer десять раз подряд, в отличие от getint, вы десять раз получите один и тот же результат. Вначале это может показаться непривычным, но, вкусив простоту и ясность такого подхода, вам уже не захочется возвращаться к побочному эффекту.
| В этом примере, как и в случае x++, традиционная форма явно выигрывает у ОО-формы, если считать, что целью является уменьшение числа нажатий клавиш. Объектная технология вообще не обязательно является оптимальной на микроуровне (игра, в которой выигрывают языки типа APL или современные языки сценариев типа PERL). Выигрыш достигается на уровне глобальной структуры за счет повторного использования, за счет таких механизмов, как универсальность (параметризованные классы), за счет автоматической сборки мусора, благодаря утверждениям. Все это позволяет уменьшить общий размер текста системы намного больше, чем уменьшение числа символов в отдельной строчке. Мудрость локальной экономии зачастую оборачивается глобальной глупостью. |
Документирование класса и системы
Владея совершенными методами проектирования интерфейса классов, можно построить множество великолепных классов. Для достижения успеха, которого они заслуживают, необходима еще хорошая документация. Мы уже видели основное средство документирования - краткую форму - и ее вариант - плоскую краткую форму. Давайте обобщим их использование и исследуем дополняющие механизмы, работающие со всей системой, а не с отдельными классами.
Упоминание краткой формы в этом обсуждении будет также относиться и к плоской краткой форме. Разница между ними, как помните, состоит в том, что плоская краткая форма учитывает и наследуемые компоненты, в то время как просто краткая форма ссылается только на компоненты, непосредственно объявленные в классе. В большинстве случае авторам клиентских модулей необходима плоская краткая форма.
Документирование на уровне системы
Инструментарий short и flat-short, разработанный в соответствии с правилами этой книги (утверждения, Проектирование по Контракту, скрытие информации, четкие соглашения именования, заголовочные комментарии и так далее) применяет принцип Документации на уровне модуля. Но есть необходимость для документации более высокого уровня - документации на уровне всей системы или одной из ее подсистем. Но здесь текстуального вывода, хотя и необходимого, явно недостаточно. Для того чтобы охватить организацию возможно сложной системы, полезно графическое описание.
Инструментарий Case из окружения ISE, основанный на концепциях BON (Business Object Notation), обеспечивает такое видение. На рис.5.15 показана сессия, предназначенная для реверс-инженерии (reverse-engineering) библиотек Base.
Хотя детализация инструментария выходит за рамки этой книги (см. [M 1995c]), можно отметить, что это средство поддерживает анализ больших систем, позволяет изменять масштаб диаграммы, поддерживает возможность фокусироваться на кластерах (подсистемах), позволяет объединять графические снимки с текстовой информацией о подсистемах.
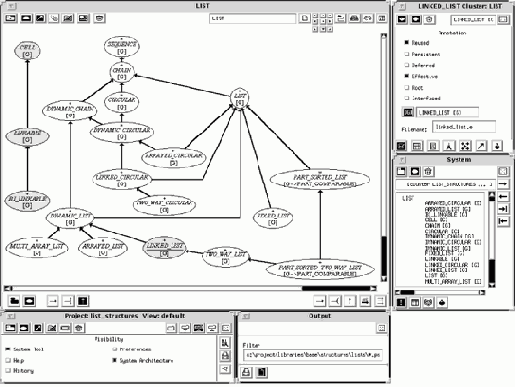
Рис. 5.15. Диаграмма архитектуры системы
Все эти средства, являясь приложением Принципа Документирования, приближают нас к идеалу Самодокументирования. Все это достигается благодаря тщательно спроектированной нотации и современному окружению.
Формы побочного эффекта
Определим, какие конструкции могут приводить к побочным эффектам. Операциями, изменяющими объекты, являются: присваивание a := b, попытка присваивания a = b, инструкция создания create a. Если цель a является атрибутом, то выполнение операции присвоит новое значение его полю для объекта, соответствующего цели текущего вызова подпрограммы.
Нас будут интересовать только такие присваивания, в которых a является атрибутом; если же a - это локальная сущность, то его значение используется только в момент выполнения подпрограммы и не имеет постоянного эффекта, если a - это Result, присваивание вычисляет результат функции, но не действует на объекты.
Заметим, что, применяя принципы скрытия информации, мы при проектировании ОО-нотации тщательно избегали любых косвенных форм модификации объектов. В частности, синтаксис исключает присваивания в форме obj.attr := b, чья цель должна быть достигнута через вызов obj.set_attr (b), где процедура set_attr (x:...) выполняет присваивание атрибуту attr := x (см. лекцию 7 курса "Основы объектно-ориентированного программирования").
Присваивание атрибуту, ставшее причиной побочного эффекта, может находиться в самой функции или встроено глубже - в другой подпрограмме, вызываемой функцией. Вот полное определение:
Определение: конкретный побочный эффект Функция производит конкретный побочный эффект, если ее тело содержит: присваивание, попытку присваивания или инструкцию создания, чьей целью является атрибут;вызов процедуры. |
Термин "конкретный" будет пояснен ниже. В последующем определении мы второе предложение сформулируем как "вызов подпрограммы, создающей (рекурсивно) конкретный побочный эффект". Определение побочного эффекта будет расширено и не будет, как теперь, относиться только к функциям. Но выше приведенное определение на практике предпочтительнее, хотя по разным причинам его можно считать либо слишком строгим, либо слишком слабым:
Определение кажется слишком строгим, поскольку любой вызов процедуры рассматривается как создающий побочный эффект, в то время как можно написать процедуру, ничего не меняющую в мире объектов.Такие процедуры могут менять нечто в окружении: печатать страницу, посылать сообщения в сеть, управлять рукой робота. Мы будем рассматривать это как своего рода побочный эффект, хотя программные объекты при этом не меняются.Определение кажется слишком слабым, поскольку оно игнорирует случай функции f, вызывающей функцию g с побочным эффектом. Соглашение состоит в том, что в этом случае сама f считается свободной от побочного эффекта. Это допустимо, поскольку правило, которое будет выработано в процессе нашего рассмотрения, будет запрещать все побочные эффекты определенного вида, так что нет необходимости в независимой сертификации каждой функции.Преимущество этого соглашения в том, что для определения статуса побочного эффекта достаточно анализировать тело только самой функции. Достаточно тривиально, имея анализатор языка, встроить простой инструментарий, который для каждой функции независимо определял бы, обладает ли она конкретным побочным эффектом в соответствии с данным определением
Функции, создающие объекты
Следует ли рассматривать создание объекта как побочный эффект? Ответ - да, если целью создания является атрибут a, то инструкция create a изменяет значение поля объекта. Ответ - нет, если целью является локальная сущность подпрограммы. Но что если целью является результат самой функции - create Result или в общей форме create Result.make (...)? Такая инструкция не должна рассматриваться как побочный эффект, она не меняет объектов и не нарушает ссылочной прозрачности.
С позиций математика можно полагать, что все интересующие нас объекты в прошлом, настоящем и будущем уже описаны в Великой Книге Объектов и инструкция создания просто получает один их этих готовых объектов, ничего не меняя. Так что вполне законно и допустимо, чтобы функция создавала, инициализировала и возвращала такие объекты.
|
Эти же рассуждения применимы и для второй формы создания объектов - процедуры make, которая тоже не создает побочного эффекта, а возвращает уже созданный объект. |
Генераторы псевдослучайных чисел: упражнение
В защиту функций с побочным эффектом приводят пример генератора псевдослучайных чисел, возвращающего при каждом вызове случайное число из последовательности, обладающей определенными статистическими свойствами. Последовательность инициализируется вызовом в форме:
random_seed (seed)Здесь seed задается клиентом, что позволяет при необходимости получать одну и ту же последовательность чисел. Каждое очередное число последовательности возвращается при вызове функции:
xx := next_random ()Но и здесь нет причин делать исключение и не ввести дихотомию команда/запрос. Забудем о том, что мы видели выше и начнем все с чистого листа. Как описать генерирование случайных чисел в ОО-контексте?
Как всегда, в объектной технологии зададимся вопросом - зачастую первым и единственным:
Что является абстракцией данных?Соответствующей абстракцией здесь не является "генерирование случайного числа" или "генератор случайных чисел" - обе они функциональны по своей природе, фокусируясь на том, что делает система, а не на том, кто это делает.
Рассуждая дальше, рассмотрим в качестве кандидата понятие "случайное число", но и оно все же не является правильным ответом. Вспомним, что абстракция данных должна сопровождаться командами и запросами, довольно трудно придумать, что можно делать с одним случайным числом.
|
Понятие "случайное число" приводит к тупику. При изучении общих правил выявления классов уже говорилось, что ключевой шаг состоит в отсеве кандидатов. И опять-таки мы видим, что не все многообещающие существительные документа требований ведут к нужным классам. Можно не сомневаться, что данный термин обязательно встретится в любом документе, описывающем рассматриваемую проблему. |
Случайное число не имеет смысла само по себе, оно должно рассматриваться в связи со своими предшественниками в генерируемой последовательности.
Стоп - появился термин последовательность, или, более точно, последовательность псевдослучайных чисел. Это и есть разыскиваемая абстракция! Она вполне законна и напоминает рассмотренный ранее список с курсором, только является бесконечной.
Ее свойства включают:
команды: make - инициализация некоторым начальным значением seed; forth - передвинуть курсор к следующему элементу последовательности;запросы: item - возвращает элемент в позиции курсора.

Рис. 5.2. Бесконечный список как машина
Для получения новой последовательности rand клиенты будут использовать create rand.make (seed), для получения следующего значения - rand.forth, для получения текущего значения - xx := rand.item.
Как видите, нет ничего специфического в интерфейсе последовательности случайных чисел за исключением аргумента seed в процедуре создания. Добавив процедуру start, устанавливающую курсор на первом элементе (которую процедура make может вызывать при создании последовательности), мы получаем каркас отложенного класса COUNTABLE_SEQUENCE, описывающего произвольную бесконечную последовательность. На его основе можно построить, например, последовательность простых чисел, определив класс PRIMES - наследника COUNTABLE_SEQUENCE, чьи последовательные элементы являются простыми числами. Другой пример - последовательность чисел Фибоначчи.
| Эти примеры противоречат часто встречающемуся заблуждению, что на компьютерах нельзя представлять бесконечные структуры. АТД дает ключ к их построению - структура полностью определяется аппликативными операциями, число которых конечно (здесь их три - start, forth, item) плюс любые дополнительные компоненты, добавляемые при желании. Конечно, любое выполнение будет всегда создавать только конечное число элементов этой бесконечной структуры. |
Инкапсуляция и утверждения
До рассмотрения лучших версий несколько комментариев к первой попытке.
Класс LINKED_LIST1 показывает, что даже на совершенно простых структурах манипуляции со ссылками - это некий вид трюков, особенно в сочетании с циклами. Использование утверждений помогает в достижении корректности (смотри процедуру put и инвариант), но явная трудность операций этого типа является сильным аргументом в пользу их инкапсуляции раз и навсегда в повторно используемых модулях, как рекомендуется ОО-подходом.
Обратите внимание на применение Принципа Унифицированного Доступа; хотя count это атрибут и empty это функция, клиентам нет необходимости знать такие детали. Они защищены от возможных последующих изменений в реализации.
Утверждения для put полны, но из-за ограничений языка утверждений они не полностью формальны. Аналогично подробные предусловия следует добавить в другие подпрограммы.
Исключения из Принципа Операндов?
Принцип Операндов универсально применим. Но два специальных случая, не являясь настоящими исключениями, требуют некоторой адаптации.
Во-первых, можно получить преимущества от существования множества процедур создания. Класс поддерживает разные способы инициализации объектов, вызывая create x.make_specific (argument, ...), где make_specific - соответствующая процедура создания. Можно ослабить Принцип Операндов для таких процедур, облегчая задачу клиенту, предлагая различные способы установки значений, отличные от значений по умолчанию. Однако имеют место два ограничения:
помните, что, как всегда, процедура создания должна обеспечить выполнение инварианта класса;множество процедур создания должно включать минимальную процедуру (называемую make в рекомендованном стиле), не включающую опций в качестве аргументов и устанавливающую значения опций по умолчанию.Другой случай ослабления Принципа Операндов следует из последнего наблюдения. Можно заметить, что некоторые операции часто используют установки опций, соответствующие некоторому стандартному образцу, например:
my_document.set_printing_size ("...") my_document.set_printer_name ("...") my_document.printВ таком случае может быть удобнее во имя инкапсуляции и повторного использования, а также в согласии с Принципом Списка Требований, изучаемом далее, обеспечить для удобства клиентов специальную процедуру:
print_with_size_and_printer (printer_name: STRING; size: SIZE_SPECIFICATION)Это предполагает, конечно, что основная минимальная программа (print в нашем примере) остается доступной и что новая программа является дополнением, упрощая задачу клиента в тех случаях, когда она действительно часто встречается.
|
В действительности речь не идет о нарушении принципа, так как аргументы действительно требуются по природе решаемой задачи, так что здесь они являются не опциями, а операндами. |
Эволюция классов. Устаревшие классы
Мы пытаемся сделать наши классы совершенными. Все приемы, аккумулированные в этом обсуждении, направлены на эту цель - недостижимую, конечно, но полезную, как всякое стремление к идеалу.
К сожалению, (нисколько не собираясь обидеть читателя) все мы не являемся примером совершенства. Что делать, если после нескольких месяцев, а может быть, и лет работы, мы осознаем, что интерфейс класса мог бы быть спроектирован лучше? Не самая приятная дилемма, которую предстоит разрешить:
В интересах текущих пользователей: это означает продолжать жить с устаревшим дизайном, чьи неприятные эффекты будут по прошествии времени становиться все более тяжкими. В индустрии это называется восходящей совместимостью (upward compatibility). Совместимость, как много преступлений совершается во имя твое, как писал Виктор Гюго (правда, говоря о свободе).
|
В соответствие с фольклором Unix одно из наиболее неприятных соглашений в инструментарии Make обеспокоило нескольких новых пользователей, обнаруживших его незадолго после выхода первой версии инструментария. Так как исправление вело к изменению языка, а неудобство показалось не слишком серьезным, то было принято решение оставить все как есть, дабы не тревожить сообщество пользователей. Следует сказать, что сообщество пользователей Make включало тогда одну или две дюжины людей из Bell Laboratories. |
Иногда - но только иногда - есть другой выход. Мы вводим в нашу нотацию концепцию устаревших компонентов (obsolete features) или устаревших классов (obsolete classes). Вот пример подобной подпрограммы:
enter (i: INTEGER; v: G) is obsolete "Используйте put (value, index)" require correct_index (i) do put (v, i) ensure entry (i) = v endЭто реальный пример, хотя и неиспользуемый в настоящее время. Ранее при эволюции библиотек Base мы пришли к пониманию необходимости замены некоторых имен и соглашений (тогда еще принципы стиля, изложенные в лекции 8, не были сформулированы).
Предполагалось изменить имя put на enter и item на entry и, что еще хуже, изменить порядок следования аргументов для совместимости с компонентами других классов в библиотеке.
Приведенное выше объявление сглаживало эволюцию. Обратите внимание, как старый компонент enter получает новую реализацию, основанную на новом компоненте put. Следует использовать эту схему, когда компонент становится устаревшим для избежания двух конкурирующих реализаций с риском потери надежности и расширяемости.
Каковы следствия того, что компонента объявляется устаревшей? На практике они незначительны. Инструментарий окружения должен обнаружить это свойство и вывести соответствующее предупреждение, когда клиентская система использует класс. Компилятор, в частности, выведет сообщение, включающее строку, следующую за ключевым словом obsolete, такую как "Используйте put (value, index)" в нашем примере. Это все. Компонент, с другой стороны, продолжает нормально использоваться.
Подобный синтаксис позволяет объявить целый класс устаревшим.
Разработчикам клиентов это открывает дорогу к миграции. Сказав им, что компонент будет удален, вы поощряете их адаптацию, но не приставляете нож к горлу. Если изменение обосновано, как и должно быть, пользователи не должны обновлять свою часть сразу же, что было бы неприемлемо, но при переходе к новой версии они могут внести все изменения непосредственно. Дав им время, получите готовность принять нововведения.
На практике период миграции должен быть ограничен. При выпуске очередной версии (через месяцы или через год) следует удалить все устаревшие классы и компоненты. В противном случае предупреждения об устарелости никто не будет принимать всерьез. Вот почему упоминавшийся пример с устарелыми именами enter и entry уже не является текущим. Но в свое время он сыграл свою положительную роль, сделав счастливым не одного разработчика.
Старение компонентов и классов решает одну специфическую проблему. Когда в проекте обнаруживается изъян, единственно разумный подход его коррекции состоит в приложении усилий, помогающих пользователям совершить переход.Ни переопределение в потомках, ни объявление проекта устарелым не заменят необходимости исправления обнаруженных ошибок существующего ПО. Но старение - это прекрасный механизм в ситуациях, когда существующий проект, отличный во всех отношениях, перестает соответствовать современности. Хотя в старом проекте нет серьезных пороков, но сейчас все можно сделать лучше: упростить интерфейс, обеспечить лучшую согласованность с остальным ПО, обеспечить взаимодействие с другими продуктами, применить лучшие соглашения по наименованию. В таких ситуациях объявление классов и компонентов устаревшими - прекрасный способ защитить вложения текущих пользователей, пока они не пройдут свою часть пути к светлому будущему.
Как справляться с особыми ситуациями
Наша следующая тема проектирования интерфейса связана с проблемой, возникающей перед каждым разработчиком: как управлять случаями, отклоняющимися от нормальных, ожидаемых схем?
Вне зависимости от причин возникновения ошибок - по вине пользователя системы, операционного окружения, сбоев аппаратуры, некорректных исходных данных или некорректного поведения других модулей - специальные случаи являются головной болью разработчиков. Необходимость учета всех возможных ситуаций - серьезное препятствие в постоянной битве со сложностью ПО.
Эта проблема оказывает серьезное влияние на проектирование интерфейса модулей. Если бы эти заботы были сняты с разработчика, то можно было бы писать ясные, элегантные алгоритмы для нормальных случаев и полагаться на внешние механизмы, берущие на себя заботу в остальных ситуациях. Много надежд возлагалось на механизм исключений. В языке Ada, например, можно написать нечто такое:
if some_abnormal_situation_detected then raise some_exception; end; "Далее - нормальная обработка"Выполнение инструкции raise прервет выполнение текущей программы и передаст управление "обработчику события", написанному в модуле, вызывающем программу. Но это всего лишь управляющая структура, а не метод, позволяющий справиться с ненормальными ситуациями. В конечном счете придется решать, что делать в той или иной ситуации: возможно ли ее исправить? Если да, то как это сделать, и что делать потом, как вернуть управление системе? Если нет, то как лучшим способом, быстро и элегантно завершить выполнение?
Мы видели в лекции 12 курса "Основы объектно-ориентированного программирования", что механизм дисциплинированных исключений полностью соответствует ОО-подходу, в частности согласуется с Принципом Проектирования по Контракту. Но не во всех специальных случаях обоснованно обращаться к исключениям. Техника проектирования, которой мы сейчас займемся, на первый взгляд, покажется менее выразительной, может характеризоваться как "техника низкого уровня" ("low-tech"). Но она чрезвычайно мощная и подходит ко многим возможным практическим ситуациям. После ее изучения дадим обзор тех ситуаций, где использование исключений остается непременным.
Команды и запросы
Напомним используемую терминологию. Компоненты, характеризующие класс разделяются на команды и запросы. Команды модифицируют объекты, а запросы возвращают информацию о них. Команды реализуются процедурами, а запрос может быть реализован либо атрибутом - тогда в момент запроса возвращается значение соответствующего поля экземпляра класса, либо функцией - тогда происходит вычисление значения по алгоритму, заданному функцией. Процедуры и функции называются подпрограммами.
В определении запроса не сказано, могут ли изменяться объекты в момент запроса. Для команд ответ очевиден - да, поскольку в этом и состоит их назначение. Для запросов вопрос имеет смысл только в случае их реализации функциями, поскольку доступ к атрибуту ничего не меняет. Изменение объектов, выполняемое функцией, называется ее побочным эффектом (side effect). Функция с побочным эффектом помимо основной роли - возвращения ответа на запрос, меняя объект, играет одновременно и дополнительную роль, которая часто является фактически основной. Но следует ли допускать побочные эффекты?
Контрольный перечень
Принцип Операндов, заставляющий уделять опциям должное внимание, подсказывает технику, помогающую получить правильный класс. Для каждого класса перечислите все поддерживаемые опции и создайте таблицу, содержащую одну строку для каждой опции. Эта техника иллюстрируется на классе DOCUMENT следующей таблицей, представленной одной строкой:
| Paper size | default:A4 (international) make_LTR: LTR (US) | size | set_size set_LTR set_A4 |
Столбцы таблицы последовательно перечисляют: назначение опции, как она инициализируется различными процедурами создания, как она доступна клиентам, как она может устанавливать различные значения. Тем самым задается полезный контрольный перечень для часто встречающихся дефектов:
Initialized помогает обнаружить ошибочную инициализацию, особенно в случае умолчаний. (Если, например, по умолчанию хотим установить цветную печать, то значение опции Black_and_white_only должно быть установлено как false.)Queried помогает обнаружить ошибки доступа. Заметьте, программа, получающая объект, может изменять опции в своих собственных целях, но затем восстанавливать их начальное состояние. Это возможно, если разрешен запрос начального состояния.Set помогает обнаружить пропущенные опции установочных процедур.Ни одно из правил, предлагаемых здесь, не является абсолютным. Но они применимы в большинстве случаев, так что важно проверить, что входы таблицы отвечают ожидаемому поведению класса. Таблица может также помочь в документировании класса.
Критика интерфейса класса
Удобно ли использование LINKED_LIST1? Давайте оценим наш проект.
Беспокоящий аспект - существенная избыточность: item и put содержат почти идентичные циклы. Похожий код следует добавить в процедуры, оставленные читателю (occurrence, replace, remove). Все же не представляется возможным вынести за скобки общую часть. Не слишком многообещающее начало.
Это внутренняя проблема реализации, - отсутствие повторно используемого внутреннего кода. Но это указывает на более серьезный изъян - плохо спроектированный интерфейс класса.
Рассмотрим процедуру occurrence. Она возвращает индекс элемента, найденного в списке, или 0 в случае его отсутствия. Недостаток ее в том, что она дает только первое вхождение. Что, если клиент захочет получить последующие вхождения? Но есть и более серьезная трудность. Клиент, выполнивший поиск, может захотеть изменить значение найденного элемента или удалить его. Но любая из этих операций требует повторного прохода по списку!
Проектируя компонент библиотеки общецелевого использования, нельзя допустить такую неэффективность. Любые потери производительности в повторно используемых решениях неприемлемы, в противном случае разработчики просто откажутся платить, обрекая на провал идею повторного использования.
Много ли аргументов должно быть у компонента?
Пытаясь сделать классы, особенно повторно используемые, простыми в использовании, следует особое внимание обратить на число аргументов у компонентов. Как мы увидим, объектная технология вырабатывает стиль интерфейса компонентов, радикально отличающийся от традиционных подходов, в частности характеризуемый небольшим числом аргументов.
Объекты как машины
Следующий принцип выражает этот запрет в более точной форме:
|
Принцип: Разделение Команд и Запросов Функции не должны обладать абстрактным побочным эффектом. |
Заметьте, к этому моменту мы определили только понятие конкретного побочного эффекта, но пока можно игнорировать разницу между абстрактным и конкретным побочными эффектами.
Только командам (процедурам) будет разрешено обладать побочным эффектом. Фактически мы не только допускаем, но и ожидаем изменения объектов командами, что и отличает императивный подход от аппликативного, полностью свободного от побочных эффектов.
Рис. 5.1. Объект list как list-машина
Из этого обсуждения следует, что объекты можно рассматривать как машины с ненаблюдаемым внутренним состоянием и двумя видами кнопок - командными, изображенными на рисунке в виде прямоугольников, и кнопками запросов, отображаемыми кружками. Метафору "машины", как обычно, следует принимать с осторожностью.
При нажатии командной кнопки машина изменяет состояние, она начинает гудеть, щелкать и работает, пока не придет в новое стабильное состояние. Увидеть состояние (открыть машину) невозможно, но можно нажать кнопку с запросом. Состояние при этом не изменится, но в ответ появится сообщение, показанное в окне дисплея в верхней части нашей машины. Для запросов булевского типа предусмотрены две специальные кнопки над окном сообщения: одна из них загорается, когда запрос имеет значение true, другая - false. Многократно нажимая кнопки запросов, мы всегда будем получать одинаковые ответы, если в промежутке не нажимать командные кнопки (задание вопроса не меняет ответ).
Команды, как и запросы, могут иметь аргументы. В нашей машине для их ввода предназначен слот, показанный слева вверху.
Наш рисунок основан на примере объекта list, интерфейс которого описан в предыдущих лекциях и будет еще обсуждаться подробнее в данной лекции. Команды включают start (курсор передвигается к первому элементу), forth (продвижение курсора к следующей позиции), search (передвижение курсора к следующему вхождению элемента, введенного в верхний левый слот). Запросы включают item (показ на дисплее панели значения элемента в позиции курсора), index (показ текущей позиции курсора). Заметьте разницу между понятием "курсора", связанного с внутренним состоянием и, следовательно, напрямую не наблюдаемым, и понятиями item или index, более абстрактными, задающими официально экспортируемую информацию о состоянии.
Операнды и необязательные параметры (опции)
Аргументы подпрограммы могут быть одного из двух возможных видов: операнды и опции.
Для понимания разницы рассмотрим пример класса DOCUMENT и его процедуру печати print. Предположим - просто для конкретизации изложения, - что печать основана на Postscript. Типичный вызов иллюстрирует возможный интерфейс, не совместимый с ниже излагаемыми принципами. Вот пример:
my_document.print (printer_name, paper_size, color_or_not, postscript_level, print_resolution)Какие из пяти аргументов являются обязательными? Если не задать, например, Postscript уровень, то по умолчанию используется наиболее доступное значение, это же касается и остальных аргументов, включая и имя принтера.
Этот пример иллюстрирует разницу между операндами и опциями:
|
Определение: операнд и опция Аргумент является операндом, если он представляет объект, с которым оперирует программа. Аргумент является опцией, если он задает режим выполнения операции. |
Это определение носит общий характер и оставляет место для неопределенности. Существуют два прямых критерия:
|
Как отличать опции от операндов Аргумент является опцией, если предполагается, что клиент может не поддерживать его значение, для него может быть установлено разумное значение по умолчанию.При эволюции класса аргументы имеют тенденцию оставаться неизменными, а опции могут добавляться или удаляться. |
В соответствии с первым критерием аргументы print являются опциями. Заметьте, однако, что цель вызова - неявный аргумент my_document, как и все цели, должна быть операндом. Если не сказать, какой документ следует печатать, никто не сделает за вас этот выбор.
Второй критерий менее очевиден, так как требует некоторого предвидения, но он отражает то, что является предметом наших забот, начиная с первой лекции. Класс не является неизменным продуктом - он может изменяться в процессе жизненного цикла. Некоторые его свойства меняются чаще, чем другие. Операнды - это долго живущая информация, добавление или удаление операнда является изменением, затрагивающим сущность класса. Опции, с другой стороны, могут появляться и исчезать. Например, нетрудно понять, что поддержка цвета при печати могла появиться не сразу. Это типично для опций.
Определение размера класса
Следует определить, как измерять размер класса. Можно посчитать общее число строк или, что более разумно, число определений и инструкций, в меньшей степени зависящих от текстуальных предпочтений автора. В последнем случае простой анализатор языка справится с этой задачей. Хотя это и интересно для некоторых приложений, эти измерения отражают позицию поставщика класса. Если же нас интересует, как много функциональности предоставляет класс своим клиентам, то подходящим критерием является, скорее, число его компонентов.
Все же остаются два вопроса:
Скрытие информации: следует ли учитывать все компоненты (внутренний размер) или только экспортируемые (внешний размер)?Наследование: следует ли учитывать только непосредственные компоненты, введенные в самом классе, - непосредственный (immediate) размер - или считать все компоненты, включая наследованные от всех предков, - плоский (flat) размер, связанный с понятием плоской формы класса. Возможно, следует считать только непосредственные компоненты, присоединяя к ним компоненты, модифицируемые в классе через переопределение и эффективизацию, не учитывая переименования, которое не влияет на возрастающий (incremental) размер?Различные комбинации могут представлять интерес. Для нашего обсуждения наиболее важны два измерения - внешнее и возрастающее. Внешний размер означает, что мы смотрим на класс с позиций клиента, и нас мало волнует, что там делается внутри в собственных интересах класса. Возрастающий размер позволяет сосредоточиться на ценностях, добавляемых классом. При этом игнорируется важная наследуемая часть функциональности, но иначе одни и те же компоненты учитывались бы многократно, как у класса, так и у всех его потомков.
Отделение состояния
Возможно развитие предыдущей техники. До сих пор курсор был лишь концепцией, реализованной атрибутами previous, active и index, но не был одним из классов. Можно определить класс CURSOR, имеющий потомков, вид которых зависит от структуры курсора. Тогда мы можем отделить атрибуты, задающие содержимое списка (zeroth_element, count), от атрибутов, связанных с перемещением по списку, хранимых в объекте курсора.
Хотя мы не будем доводить до логического конца эту идею, отметим ее полезность для параллельного доступа. Если нескольким клиентам нужно разделять доступ к структуре данных, то каждый из них мог бы иметь свой собственный курсор.
Пассивные классы
Ясно, что нам нужны два класса: LINKED_LIST для списка (более точно, заголовка списка), LINKABLE для элементов списка - звеньев. Оба они являются универсальными.
Понятие LINKABLE является основой реализации, но не столь важно для большинства клиентов. Следует позаботиться об интерфейсе, обеспечивающем модули клиентов нужными примитивами, но не следует беспокоить их такими деталями реализации как представление элементов в звене списка. Атрибуты, соответствующие рисунку, появятся как:
indexing description: "Звенья, используемые в связном списке" note: "Частичная версия, только атрибуты" class LINKABLE1 [G] feature {LINKED_LIST} item: G -- Значение звена right: LINKABLE [G] -- Правый сосед endТип right можно было бы задавать как like Current, но предпочтительнее на этом этапе сохранить больше свободы в переопределении, поскольку пока непонятно, что может потребовать изменений у потомков LINKABLE.
Для получения настоящего класса следует добавить подпрограммы. Что допустимо для клиентов при работе со звеньями? Они могут изменять поля item и right. Можно также ожидать, что многие из клиентов захотят при создании звена инициализировать его значение, что требует процедуры создания. Вот подходящая версия класса:
indexing description: "Звенья, используемые в связном списке" class LINKABLE [G] creation make feature {LINKED_LIST} item: G -- Значение звена right: LINKABLE [G] -- Правый сосед make (initial: G) is -- Инициализация item значением initial do put (initial) end put (new: G) is -- Замена значения на new do item := new end put_right (other: LINKABLE [G]) is -- Поместить other справа от текущего звена do right := other end endДля краткости в классе опущены очевидные постусловия процедуры (такие как ensure item = initial для make). Предусловий здесь нет.
Ну, вот и все о LINKABLE. Теперь рассмотрим сам связный список, внутренне доступный через заголовок. Рассмотрим его экспортируемые компоненты: запрос на получение числа элементов (count), пуст ли список (empty), значение элемента по индексу i(item), вставка нового элемента в определенную позицию (put), изменение значения i-го элемента (replace), поиск элемента с заданным значением (occurrence).
Нам также понадобится запрос, возвращающий ссылку на первый элемент (void, если список пуст), который не должен экспортироваться.
Вот набросок первой версии. Некоторые тела подпрограмм опущены.
indexing description: "Односвязный список" note: "Первая версия, пассивная" class LINKED_LIST1 [G] feature -- Access count: G empty: BOOLEAN is -- Пуст ли список? do Result := (count = 0) ensure empty_if_no_element: Result = (count = 0) end item (i: INTEGER): G is -- Значение i-го элемента require 1 <= i; i <= count local elem: LINKABLE [G]; j: INTEGER do from j := 1; elem := first_element invariant j <= i; elem /= Void variant i - j until j = i loop j := j + 1; elem := elem.right end Result := elem.item end occurrence (v: G): INTEGER is -- Позиция первого элемента со значением v (0, если нет) do ... end feature -- Element change put (v: G; i: INTEGER) is -- Вставка нового элемента со значением v, -- так что он становится i-м элементом require 1 <= i; i <= count + 1 local previous, new: LINKABLE [G]; j: INTEGER do -- Создание нового элемента create new.make (v) if i = 1 then -- Вставка в голову списка new.put (first_element); first_element := new else from j := 1; previous := first_element invariant j >= 1; j <= i - 1; previous /= Void -- previous - это j-й элемент списка variant i - j - 1 until j = i - 1 loop j := j + 1; previous := previous.right end Вставить после previous previous.put_right (new) new.put_right (previous.right) end count := count + 1 ensure one_more: count = old count + 1 not_empty: not empty inserted: item (i) = v -- For 1 <= j < i, -- элемент с индексом j не изменил свое значение -- For i < j <= count, -- элемент с индексом j изменил свое значение -- на то, которое элемент с индексом j - 1 -- имел перед вызовом end replace (i: INTEGER; v: G) is -- Заменить на v значение i-го элемента require 1 <= i; i <= count do ... ensure replaced: item (i) = v end feature -- Removal prune (i: INTEGER) is -- Удалить i-й элемент require 1 <= i; i <= count do ...ensure one_less: count = old count - 1 end ... Другие компоненты ... feature {LINKED_LIST} -- Implementation first_element: LINKABLE [G] invariant empty_definition: empty = (count = 0) empty_iff_no_first_element: empty = (first_element = Void) end
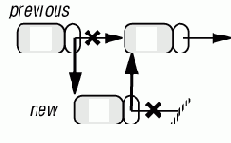
Это хорошая идея попытаться самому закончить определение occurrence, replace и prune в этой первой версии. Убедитесь при этом, что поддерживается истинность инварианта.
Побочные эффекты в функциях
Первый вопрос, исследованием которого мы займемся, оказывает глубокое влияние на стиль нашего проектирования. Законно ли для функций - подпрограмм, возвращающих результат, - иметь еще и побочный эффект, то есть изменять нечто в их окружении?
Наш ответ - нет. Но почему? Обоснование требует понимания роли побочных эффектов, осознания различий между "хорошим" и "плохим" побочным эффектом. Рассмотрим этот вопрос в свете наших знаний о классах - их происхождения от АТД, понятия абстрактной функции и роли инварианта класса.
Поддержка согласованности
Некоторые авторы, в том числе Поль Джонсон ([Johnson 1995]) настаивают на ограничении размеров класса:
Проектировщики класса часто пытаются включить в него много компонентов. В результате, в интерфейсе появляется несколько обще используемых компонентов и довольно много странных подпрограмм. Совсем плохо, когда список компонентов велик.Из опыта ISE следует другая точка зрения. Мы полагаем, что сам по себе размер класса не создает проблем. Хотя большинство классов относительно невелико (от нескольких компонентов до дюжины), встречаются и большие классы (от 60 до 80 компонентов, а иногда и больше), и с ними не возникает никаких особых проблем, если они хорошо спроектированы.
Этот опыт привел нас к подходу, называемому список требований (shopping list). Реализация не ухудшается при добавлении в класс компонентов, связанных с ним концептуально. Если вы колеблетесь, включать ли в класс экспортируемый компонент, то вас не должен беспокоить размер класса. Единственный критерий, подлежащий учету, - это согласованность компонента с остальными членами класса. Этот критерий отражен в следующей рекомендации:
|
Совет: Список Требований При рассмотрении добавления нового экспортируемого компонента следите за следующими правилами: S1 Компонент должен соответствовать абстракции данных, задающей класс.S2 Он должен быть совместимым с другими компонентами класса.S3 Он не должен дублировать цель другого компонента класса.S4 Он должен поддерживать инвариант класса. |
Первые два требования связаны с Принципом Согласованности (см. лекцию 4), устанавливающим, что все компоненты класса должны относиться к одной хорошо идентифицируемой абстракции. В качестве контрпримера рассматривался строковый класс string из библиотеки NEXTSTEP, покрывающий фактически две абстракции, разделенный, в конечном итоге, на два класса. Проблемой здесь был не размер исходного класса, а качество проектирования.
Интересно отметить, что тот же пример - класс string - один из самых больших классов в библиотеках ISE, был подвергнут критике из-за своих размеров Полем Джонсоном.
Но реакция пользователей библиотеки в течение многих лет была противоположной, - они просили добавления свойств. Класс, хотя и обладал богатой функциональностью, но был прост в использовании, поскольку все компоненты четко применяли одну и ту же абстракцию - строку символов, над которой по ее природе определено много операций, начиная от извлечения подстроки и замены до конкатенации и глобальной подстановки.
Класс STRING показывает, что большой не означает сложный. Некоторые абстракции по своей природе обладают многими компонентами. Процитирую Валдена и Нерсона ([Walden 1995]):
Класс, обрабатывающий документ, содержит 100 различных операций, позволяющих выполнять различные вариации со шрифтом, <...> фактически имеет дело с небольшим числом лежащих в его основе концепций, довольно простых и легко усваиваемых. Простота выбора надлежащей операции поддерживается прекрасно уорганизованным руководством.В этом случае разделение класса, вероятнее всего, ухудшило, а не улучшило бы простоту использования класса.
Чрезвычайно минималистская точка зрения состоит в том, что класс должен содержать только атомарные компоненты, - не выражаемые в терминах уже введенных операций. Это бы привело бы к исключению некоторых фундаментальных схем, успешных ОО-конструкций, в частности классов поведения (behavior classes), в которых эффективный компонент описывается через другие низкоуровневые компоненты класса, большинство которых являются отложенными.
Минимализм приведет к запрету двух теоретически избыточных, но практически важных дополнительных компонентов. Обратимся к классу COMPLEX, описывающему комплексные числа, разработанному в этой лекции. Для арифметических операций некоторым клиентам могут понадобиться функциональные версии:
infix "+", infix "-", infix "*", infix "/"Вычисление выражения z1 + z2 создаст новый объект, представляющий сумму z1 и z2, аналогично для других функций. Другие клиенты, или тот же клиент в другой ситуации предпочтет процедурную версию операции, где вызов z1.add(z2) обновляет объект z1.Теоретически избыточно включать и функции и процедуры в класс, поскольку они взаимно заменимы. На практике удобно иметь обе версии по меньшей мере по трем причинам: удобства, эффективности, повторного использования.
Поддержка согласованности: инвариант реализации
При построении класса для фундаментальной структуры данных следует тщательно позаботиться обо всех деталях. Утверждения здесь обязательны. Без них велика вероятность пропуска важных деталей. Например:
Является ли вызов start допустимым, если список пуст; если да, то каков эффект вызова?Что случится с курсором после remove, если курсор был в последней позиции? Неформально мы к этому подготовились, позволяя курсору передвигаться на одну позицию левее и правее списка. Но нам нужны более точные утверждения, недвусмысленно описывающие все случаи.Ответы на вопросы первого вида будут даны в виде предусловий и постусловий.
Для таких свойств, как допустимые позиции курсора, следует использовать предложения, устанавливающие инвариант реализации. Напомним, он отражает согласованность представления, задающего класс - визави АТД. В данном случае он включает свойство:
0 <= index; index <= count + 1Что можно сказать о пустом списке? Необходима симметрия по отношению к левому и правому. Одно решение, принятое в ранних версиях библиотеки, состояло в том, что пустой список это тот единственный случай, когда before и after оба истинны. Это работает, но приводит в алгоритмах к частой проверке тестов в форме: if after and not empty. Это привело нас к концептуальному изменению точки зрения и введению в список двух специальных элементов - стражей (sentinel), изображаемых на рисунке в виде специальных картинок.
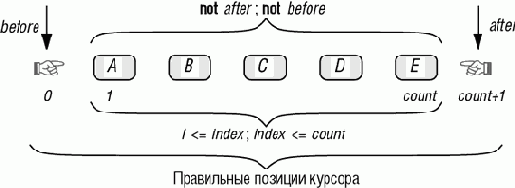
Рис. 5.8. Список со стражами
Стражи помогают нам разобраться в структуре, но нет причин хранить их в представлении. Реализация рассматривает возможность хранения только левого стража, но не правого, можно также использовать реализацию совсем без стражей, хотя и продолжающую соответствовать концептуальной модели, представленной на предыдущем рисунке.
Часто хочется установить, что некоторый индекс соответствует позиции какого-либо элемента списка. Для этого можно предложить соответствующий запрос:
on_item (i: INTEGER): BOOLEAN is -- Есть ли элемент в позиции i? do Result := ((i >= 1) and (i <= count)) ensure within_bounds: Result = ((i >= 1) and (i <= count)) no_elements_if_empty: Result implies (not empty) endДля установления того, что есть элемент списка в позиции курсора, можно определить запрос readable, чье значение определялось бы как on_item (index).
Это хороший пример Принципа Списка Требований, поскольку readable концептуально избыточен, то минималистская позиция отвергала бы его, в то же время его включение обеспечивало бы клиентов лучшей абстракцией, освобождая их от необходимости запоминания того, что точно означает индекс на уровне реализации.
Инвариант устанавливает истинность утверждения: not (after and before). В граничном случае пустого списка картина выглядит так:
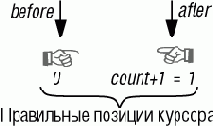
Рис. 5.9. Пустой список со стражами
Итак, пустой список имеет два возможных состояния: empty and before и empty and after, соответствующие двум позициям курсора на рисунке. Это кажется странным, но не имеет неприятных последствий и на практике предпочтительнее прежнего соглашения empty = (before and after), сохраняя справедливость empty implies (before or after).
Отметим два общих урока: важность, как во многих математических и физических задачах, проверки граничных случаев, важность утверждений, выражающих точные свойства проекта. Вот некоторые принципиальные предложения, включенные в инвариант:
0 <= index; index <= count + 1 before = (index = 0); after = (index = count + 1) is_first = ((not empty) and (index = 1)); is_last = ((not empty) and (index = count)) empty = (count = 0) -- Три следующих предложения являются теоремами, -- выводимыми из предыдущих утверждений: empty implies (before or after) not (before and after) empty implies ((not is_first) and (not is_last))Этот пример иллюстрирует общее наблюдение, что написание инварианта - лучший способ придти к настоящему пониманию особенностей класса. Утверждения инварианта применимы ко всем реализациям последовательных списков, они будут дополнены еще несколькими, отражающими специфику выбора связного представления.
Последние три предложения инварианта выводимы из предыдущих (см. У5.6). Для инвариантов минимализм не требуется, часто полезно включать дополнительные предложения, если они устанавливают важные, нетривиальные свойства. Как мы видели (см. лекцию 6 курса "Основы объектно-ориентированного программирования"), АТД и, как следствие, реализация класса является теорией, в данном случае теорией связных списков.Утверждения инварианта выражают аксиомы теории, но любая полезная теория имеет также и интересные теоремы.
| Конечно, если вы хотите проверять инварианты в период выполнения, то рассматривать дополнительные предложения имеет смысл, если вы не доверяете обоснованности теории. Но это делается только на этапах разработки и отладки. В производственной системе нет причин наблюдения за инвариантами. |
Показ интерфейса
Краткая форма непосредственно применяет правило Скрытия Информации, удаляя закрытую от клиента информацию, включающую:
любой неэкспортируемый компонент и все, что с ним делается (например, утверждения, относящиеся к компоненту);любую реализацию подпрограммы, заданную предложением do...То, что остается, представляет абстрактную информацию о классе, обеспечивая авторов клиентских модулей - настоящих и будущих - описанием, независимым от реализации, необходимым для эффективного использования класса.
|
Напомним, что основной целью является абстракция, а не защита. Мы не намереваемся скрыть от авторов клиентов закрытые свойства классов, мы желаем лишь освободить их от лишней информации. Отделяя функции от реализации, скрытие реализации должно рассматриваться как помощь авторам клиентов, а не как помеха в их работе. |
Краткая форма избегает техники, поддерживаемой в отсутствие утверждений такими языками, как Ada, Modula-2 and Java, написание раздельных и частично избыточных частей реализации и интерфейса. Такое разделение всегда чревато ошибками при эволюции классов. Как это всегда бывает в программной инженерии, повторение ведет к несогласованности. Вместо этого все помещается в один класс, а специальный инструментарий извлекает оттуда абстрактную информацию.
В начале этой книги был введен принцип, согласно которому ПО должно быть самодокументированным, насколько это возможно. Фундаментальную роль в этом играет здравый выбор утверждений. Просмотрев примеры этой лекции и построив, хотя бы мысленно, краткие формы, можно получить достаточно явные свидетельства этому.
Чтобы краткая форма давала наилучшие результаты, следует при написании классов всегда применять следующий принцип:
|
Принцип Документации Пытайтесь писать программный текст так, чтобы он включал все элементы, необходимые для документирования, обнаруживаемые автоматически на разных уровнях абстракции. |
Это простая трансляция общего Принципа Самодокументирования в практическое правило, которое следует применять ежедневно и ежечасно в своей работе. В частности, крайне важны:
хорошо спроектированные предусловия, постусловия и инварианты;тщательный выбор имен как для классов, так и для их компонентов;информативное индексирование предложений программного текста.Лекция 8, посвященная стилю, подробно рассмотрит два последних пункта.
Представление связного списка
Обсуждение будет основываться на примере списков. Хотя результаты не зависят от выбора реализации, необходимо иметь некоторое представление, позволяющее описывать алгоритмы и иллюстрировать проблемы. Будем использовать популярный выбор - односвязный линейный список. Наша общецелевая библиотека должна иметь классы со списковыми структурами и среди них класс LINKED_LIST.
Вот некоторые сведения о связных списках, применимые ко всем стилям интерфейса, обсуждаемым далее, - с курсором и без курсора.
Связный список является полезным представлением последовательной структуры с эффективно реализуемыми операциями вставки и удаления элементов. Элементы хранятся в отдельных ячейках, называемых звеньями (linkables). Каждое звено содержит значение и ссылку на следующий элемент списка:

Рис. 5.3. Элемент списка - звено (linkable)
Соответствующий класс должен быть универсальным (синонимы: родовым, параметризованным), так как структура должна быть применима к спискам с элементами любого типа. Значение звена, заданное компонентом item, имеет тип G - родовой параметр. Оно может быть непосредственно встроено, если фактический родовой параметр развернутого типа, например, для списка целых, или быть ссылкой в общем случае. Другой атрибут right типа LINKABLE[G] всегда представляет ссылку.
Сам список задается отдельной ячейкой - заголовком, содержащим ссылку first_element на первое звено, и, возможно, дополнительной информацией, например count - текущим числом элементов списка. Вот как выглядит связный список символов:
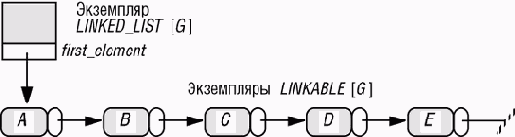
Рис. 5.4. Связный список (linked list)
Это представление позволяет быстро выполнять операции вставки и удаления, если есть ссылка, указывающая на звено слева от цели операции. Достаточно выполнить несколько манипуляций над ссылками, как показано на следующем рисунке:
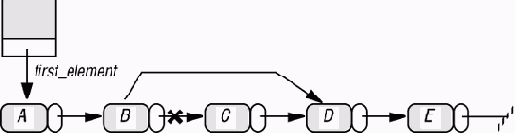
Рис. 5.5. Удаление в связном списке
Но, с другой стороны, списковое представление не очень подходит для таких операций как поиск элемента по его значению или позиции, поскольку они требуют прохода по списку. Представление массивом, по контрасту, хорошо подходит для получения нужного элемента по индексу (позиции), но не подходит для операций вставки и удаления. Существует много других представлений, некоторые из которых объединяют преимущества обоих миров. Связный список остается одной из наиболее употребительных реализаций, предлагая эффективную технику для приложений, где большинство операций связано со вставкой и удалением и почти не требуется случайный доступ.
Технический момент: рисунок не фиксирует в деталях атрибуты LINKED_LIST кроме first_element, показывая просто затененную область. Хотя можно обойтись first_element, классы ниже включают атрибут count. Этот запрос может быть функцией, но неэффективно при каждом проходе по списку подсчитывать число элементов. Конечно, при использовании атрибута каждая операция вставки и удаления должна обновлять его значение. Здесь применим Принцип Унифицированного Доступа - можно менять реализацию, не нанося вреда клиентам класса.
Преимущества, обеспечиваемые Принципом Операндов
Комментарии, сделанные в свое время при рассмотрении Принципа Разделения Команд и Запросов, относятся и к Принципу Операндов. Они противоречат доминирующей сегодня практике и некоторые читатели, несомненно, будут на первых порах отвергать их. Но я могу рекомендовать их без всякого зазрения совести, поскольку применяю их многие годы и получаю в результате большие выгоды. Они приводят к простому, элегантному стилю, способствуя ясности и расширяемости.
Этот стиль вскоре становится естественным для разработчиков. (Мы сделали его частью стандарта в ISE.) Вы создаете требуемые объекты, устанавливаете любые значения, отличающиеся от принятых по умолчанию, затем применяете нужные операции. Эта схема была показана на примере solve в библиотеке Math. Она, конечно, предпочтительнее передачи 19 аргументов.
Препятствия на пути априорной схемы
Из-за простоты и ясности априорная схема, в принципе, идеальна. По трем причинам она не является универсально применимой:
A1 По соображениям эффективности непрактично в некоторых случаях проверять предусловия перед вызовом.A2 Ограничения языка утверждений приводят к тому, что некоторые утверждения не могут быть выражены формально.A3 Наконец, некоторые условия успешного выполнения зависят от внешних событий и не являются утверждениями.Примером случая А1 является решатель линейных уравнений. Функция, дающая решение системы линейных уравнений в форме a x = b, где a - матрица, а x и b - векторы, может быть взята из соответствующего библиотечного класса MATRIX:
inverse (b: VECTOR): VECTORРешение системы находится так: x := a.inverse(b). Единственное решение системы существует, только если матрица не "сингулярна". (Сингулярность здесь означает линейную зависимость уравнений, признаком которой является равенство 0 определителя матрицы.) Можно было бы ввести проверку на сингулярность в предусловие inverse, требуя, чтобы вызовы клиента имели вид:
if a.singular then ...Подходящие действия для сингулярной матрицы... else x := a.inverse (b) endЭта техника работает, но она неэффективна, поскольку определение сингулярности, по сути, дается тем же алгоритмом, что и нахождение решения системы. Так что одну и ту же работу придется выполнять дважды - сплошное расточительство.
Примеры A2 включают случаи, когда предусловие представляет глобальное свойство всей структуры данных и не может быть выражено кванторами, например, граф не содержит циклов или список отсортирован. Наша нотация не поддерживает такие утверждения. Как отмечалось, в таких утверждениях мы можем использовать функции, но это может возвращать нас к случаю А1 - вычисление функций в предусловиях может дорого стоить, столько же, как и решение задачи.
Наконец, ограничение A3 возникает, когда невозможно проверить применимость операции без попытки выполнить ее, поскольку она взаимодействует с внешним миром - пользователем системы, линиями связи и так далее.
Принцип
Определение операндов и опций дает правило для аргументов:
|
Принцип операндов Аргументы подпрограмм должны быть только операндами, но не опциями. |
|
Два случая ослабления правила, не рассматриваемые как исключения, упоминаются ниже. |
В стиле, продвигаемом этим принципом, опции к операциям устанавливаются не при вызове операции, а при вызове специальных процедур, задачей которых является установка опций:
my_document.set_printing_size ("A4") my_document.set_color my_document.print -- Совсем нет аргументовБудучи однажды установленной, опция действует, пока целевой объект не изменит установку при новом вызове. В отсутствие любого вызова соответствующей процедуры или явной установки в момент создания объекта действует значение опции, устанавливаемой по умолчанию.
Для любого типа, отличного от Boolean, процедуры, устанавливающие опцию, имеют ровно один аргумент соответствующего типа, как это проиллюстрировано при вызове set_printing_size. Стандартное имя для таких процедур имеет форму set_property_name. Заметьте, аргументы таких процедур сами удовлетворяют Принципу Операнда. Так, например, аргумент, задающий размер страницы, является опцией для процедуры print, но операндом для установочной процедуры set_printing_size.
Для булевских процедур та же техника приводила бы к аргументу, принимающему всего два значения - True or False. Оказывается, что пользователи часто забывают, какая из двух возможностей соответствует True, поэтому лучше использовать пару процедур с удобными именами в форме set_property_name и set_no_property_name, например, set_color и set_no_color, во втором случае можно предложить и другой вариант set_black_and_white.
Применение Принципа Операндов дает несколько преимуществ:
Необходимо указывать только то, что отличается от установок по умолчанию.Новички не обязаны изучать все, они могут игнорировать специальные свойства, оставляя их профессионалам.При более глубоком изучении класса осваиваются новые свойства, но помнить нужно только то, что используется.Вероятно, наиболее важно то, что эта техника сохраняет расширяемость и отвечает Принципу Открыт-Закрыт.При добавлении новых опций нет необходимости изменять интерфейс подпрограммы и, следовательно, нарушать работу существующих клиентов. Если значение по умолчанию соответствует прежним неявным установкам, существующие клиенты не должны вносить никаких изменений.Рассмотрим возможные возражения Принципу Операндов. Мы не избавляемся от сложности, а только переносим ее глубже: вместо вызова аргументов приходится вызывать специальные процедуры. Это не совсем точно. Вызовы нужны только для тех опций, для которых мы явно хотим установить значения, отличные от значений по умолчанию.
Заметьте также, часто одно и то же значение опции успешно работает для многих вызовов. Использование аргументов заставляло бы задавать значение при каждом вызове, наша техника позволяет установить его один раз.
Некоторые языки поддерживают необязательные аргументы, дающие преимущества Принципа Операндов, но лишь частично. Сравнение двух подходов является предметом упражнения, но уже сейчас заметим, что, если значение опции многократно используется и отличается от значения по умолчанию, то придется задавать его при каждом вызове.
Простые, напрашивающиеся решения
Как справиться с неэффективностью? На ум приходят два возможных решения:
Пусть occurrence возвращает не целое, а ссылку на звено LINKABLE, где впервые появилось искомое значение, или void при неуспешном поиске. Тогда клиент имеет прямой указатель на нужный ему элемент и может выполнить требуемые операции без прохода по списку. (Например, использовать put класса LINKABLE для изменения элемента; при удалении нужна еще ссылка на предыдущий элемент.)Можно было бы обеспечить дополнительные примитивы, реализующие различные комбинации: поиск и удаление, поиск и замена.Первое решение, однако, противоречит всей идее инкапсуляции данных, - клиенты должны манипулировать внутренним представлением, со всеми вытекающими отсюда угрозами. Понятие звена является внутренним, а мы хотим, чтобы программист клиентского модуля думал в терминах списка и его значений, а не в терминах звеньев и указателей. В противном случае теряется смысл абстракции данных.
Второе решение мы пытались реализовать в ранней версии ISE. Для вставки элемента непосредственно перед вхождением известного значения клиент вместо вызова search вызывал:
insert_before_by_value (v: G; v1: G) is -- Вставка нового элемента со значением v перед первым -- вхождением элемента со значением v1 или в конец списка, -- когда нет вхождений do ... endЭто решение сохраняет скрытым внутреннее представление, устраняя неэффективность первой версии.
Но вскоре мы осознали, на какой скользкий путь мы встали. Рассмотрим все потенциально полезные варианты: search_and_replace, insert_before_by_value, insert_ after_by_value, insert_after_by_position, insert_after_by_position, delete_before_by_value, insert_at_ end_if_absent и так далее.
Это затрагивает жизненно важные вопросы проектирования библиотек. Написание общецелевого, повторно используемого ПО является трудной задачей, и нет гарантии, что с первого раза все хорошо получится. Конечно, хотелось бы, чтобы проект при его повторных использованиях следовал горизонтальной линии, показанной на рис. 5.6. Но так не бывает, нужно быть готовым добавлять в классы новые компоненты для удовлетворения потребностей, возникающих у новых пользователей. Но этот процесс должен быть сходящимся. К сожалению, наше решение соответствует графику, показанному пунктиром на рис.5.6.
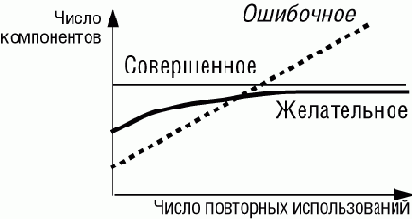
Рис. 5.6. Эволюция библиотечного класса
Размер класса: Подход списка требований
Мы твердили, как параноики, что нужно ограничивать внешний размер компонента, измеряемый числом его аргументов, поскольку он во многом определяет простоту использования и, следовательно, качество интерфейса. В меньшей степени мы заботились о внутреннем размере, измеряемом, например, числом инструкций, поскольку он зависит от сложности алгоритма. Как показывает практика, при хорошем ОО-проектировании тела подпрограмм, как правило, имеют также небольшие размеры.
Следует ли подобным образом сосредоточиться на рассмотрении размеров класса как целого? Уверенного ответа здесь нет.
Роль механизма исключений
Предыдущее обсуждение показало, что разбор случаев является основой для того, чтобы справиться с особыми ситуациями. Хотя априорная схема не всегда практична, часто можно проверять успешность результата после его получения.
Остаются, однако, ситуации, когда обе схемы не являются адекватными. Возможны три таких категории:
Некоторые исключительные события - при вычислениях, запросах памяти - могут приводить к отказам аппаратуры или операционной системы, возбуждая исключения, и, если наша программная система их не перехватывает, то они приводят к вынужденному прерыванию ее выполнения. Зачастую это неприемлемо, особенно в жизненно важных системах, например медицинских.Некоторые особые ситуации, хотя и не обнаруживаемые предусловием, должны диагностироваться как можно раньше: операция не должна завершаться (для апостериорной проверки), поскольку это может привести к катастрофическим последствиям - нарушить целостность базы данных, подвергнуть опасности человеческую жизнь, как, например, в системах управления роботом.Наконец, разработчик может пожелать включить некую форму защиты от катастрофических последствий любых оставшихся ошибок в системе, поэтому использует механизм исключений для придания системе устойчивости.В таких ситуациях механизм обработки исключений необходим, его детали рассмотрены в лекции 12 курса "Основы объектно-ориентированного программирования".
С точки зрения клиента
Этот проект обеспечивает простой и элегантный интерфейс реализации связных списков. Операции, такие как "поиск, а затем вставка", используют два последовательных вызова, хотя и без существенной потери эффективности:
l: LINKED_LIST [INTEGER]; m, n: INTEGER ... l.search (m) if not after then l.put_right (n) endВызов search (m) передвинет курсор к следующему вхождению m после текущей позиции курсора или after, если таковой нет. (Здесь предполагается, что курсор изначально установлен на первом элементе, если нет, то клиент должен прежде выполнить l.start.)
Для удаления третьего вхождения некоторого элемента клиент выполнит:
l.start; l.search (m); l.search (m); l.search (m) if not after then l.remove endДля вставки элемента в позицию i:
l.go (i); l.put_left (i)и так далее. Мы получили простое и ясное использование интерфейса, сделав явным внутреннее состояние, обеспечив клиента подходящими командами и запросами об этом состоянии.
Слияние списка и стражей
(Этот раздел описывает улучшенную оптимизацию и может быть опущен при первом чтении.)
Пример связного списка со стражами может быть улучшен благодаря еще одной оптимизации, которая реально используется в последней версии библиотек ISE. Мы бегло ее рассмотрим, поскольку она достаточно специфична и не носит общего характера. Такие оптимизации, тщательно выполняемые, должны осуществляться только для широко используемых компонентов повторного использования. Другими словами, они не для домашних разработок.
Можно ли получить преимущества от стражей без соответствующих потерь памяти? При рассмотрении их концепции отмечалось, что их можно рассматривать фиктивно, но тогда мы потеряем критически важную оптимизацию, позволившую нам написать тело forth следующим образом:
index := index + 1 previous := active active := active.rightбез дорогих проверок предыдущей версии. Мы избежали тестов, будучи уверенными, что active не равно Void, когда список не находится в состоянии after. Это следствие утверждения инварианта (active = Void) = after; верного потому, что у нас есть настоящее звено - страж, доступный как active, даже если список пуст.
Для других программ, отличных от forth, оптимизация не столь существенна. Но forth, как отмечалось, - насущная потребность, "хлеб и масло" клиентов, обрабатывающих списки. Из-за последовательной природы списков типичное использование имеет вид:
from your_list.start until your_list.after loop ...; your_list.forth endНет ничего необычного, если при построении профиля, измеряя, как выполняются вычисления, вы обнаружите, что большая доля времени приходится на работу forth. Так что стоило заплатить за ее оптимизацию, поскольку она обеспечивает кардинальное улучшение производительности, будучи свободной от тестов.
За выигрыш во времени мы заплатили, как обычно, проигрышем в памяти, - теперь каждый список имеет дополнительный элемент, не хранящий информации. Это кажется проблемой лишь в случае большого числа коротких списков, иначе относительные потери несущественны.
Но могут возникнуть более серьезные проблемы:
Во многих случаях, как упоминалось, могут понадобиться двунаправленные списки, полностью симметричные с элементами класса BI_LINKABLE , имеющие ссылки на левого и правого соседа. Класс TWO_WAY_LIST (который, кстати, может быть написан как дважды наследуемый от LINKED_LIST, основываясь на технике дублируемого наследования) будет нуждаться как в левом, так и правом страже.Связные деревья (см. лекцию 15 курса "Основы объектно-ориентированного программирования") представляют более серьезную проблему. Практически важным является класс TWO_WAY_TREE, задающий удобное представление деревьев с двумя ссылками (на родителя и потомка). Построенный на идеях, описываемых при представлении множественного наследования, класс объединяет понятия узла и дерева, так что он является наследником TWO_WAY_LIST и BI_LINKABLE. Но тогда каждый узел является списком, может быть двунаправленным и хранить обоих стражей.Хотя во втором случае есть и другие способы решения проблемы - переобъявление структуры наследования - давайте попробуем получить лучшее из возможного.
Для нахождения решения зададимся неожиданным вопросом.

Рис. 5.12. Заголовок и страж
В нашей структуре нужны ли действительно два объекта, занимающиеся учетом? По настоящему полезная информация находится в фактических элементах списка, не показанных на рисунке. Для управления ими мы добавили заголовок списка и страж - двух стражей для двунаправленного списка. Для длинных списков можно игнорировать эту раздутую структуру учета, подобно большой компании, содержащую много сотрудников среднего звена во времена процветания, но в тяжелые времена, объединяющую функции управления.
Можем ли мы заставить заголовок списка играть роль стража? Оказывается, можем. Все, что имеет LINKABLE - это поле item и ссылку right. Для стража необходима только ссылка, указывающая на первый элемент, так что, если поместить ее в заголовок, то она будет играть ту же роль, как когда она называлась first_element в первом варианте со стражами.
Проблема, конечно, была в том, что first_element мог иметь значение void для пустого списка, что принуждало во все алгоритмы встраивать тесты в форме if before then ... Мы точно не хотим возвращаться назад к этой ситуации. Но можем использовать концептуальную модель, показанную на рисунке, избавленную от стража

Рис. 5.13. Заголовок как страж (на непустом списке)
Концептуально решение является тем же самым, что и прошлое, с заменой zeroth_element ссылкой на сам заголовок списка. Для представления того, что ранее было zeroth_element.right, теперь используется first_element.

Рис. 5.14. Заголовок как страж (на пустом списке)
На пустом списке следует присоединить first_element к самому заголовку. Таким образом, first_element никогда не будет void - критическая цель, сохраняющая ситуацию простой. Осталось лишь выполнить правильные замены.
Сохраним все желательные утверждения инварианта предыдущей версии со стражами:
previous /= Void (active = Void) = after; (active = previous) = before (not before) implies (previous.right = active) is_last = ((active /= Void) and then (active.right = Void))Предложения, включающие ранее zeroth_element:
zeroth_element /= Void empty = (zeroth_elemenеt.right = Void) (previous = zeroth_element) = (before or is_first)теперь будут иметь вид:
first_element /= Void empty = (first_element = Current) (previous = Current) = (before or is_first)Но чтобы все получилось так просто, необходимо (нас ждут опасные вещи, поэтому пристегните ремни) сделать LINKED_LIST наследником LINKABLE:
class LINKED_LIST [G] inherit LINKABLE [G] rename right as first_element, put_right as set_first_element end ...Остальное в классе остается как ранее с выше показанной заменой zeroth_element...Не нонсенс ли это - позволить LINKED_LIST быть наследником LINKABLE? Совсем нет! Вся идея в том, чтобы слить воедино два понятия заголовка списка и стража, другими словами рассматривать заголовок списка как элемент списка. Поэтому мы имеем прекрасный пример отношения "is-a" ("является") при наследовании.
Мы решили рассматривать каждый LINKED_LIST как LINKABLE, поэтому наследование вполне подходит. Заметьте, отношение "быть клиентом" даже не участвует в соревновании - не только потому, что оно не подходит по сути, но оно добавляет лишние поля к нашим объектам!
Убедитесь, что ваши ремни безопасности все еще застегнуты, - мы начинаем рассматривать, что происходит в наследуемой структуре. Класс BI_LINKABLE дважды наследован от LINKABLE. Класс TWO_WAY_LIST наследован от LINKED_LIST (один раз или, возможно, дважды в зависимости от выбранной техники наследования) и, в соответствии с рассматриваемой техникой, от BI_LINKABLE. Со всем этим повторным наследованием каждый может подумать, что вещи вышли из-под контроля и наша структура содержит все виды ненужных полей. Но нет, правила разделения и репликации при дублируемом наследовании позволяют нам получить то, что мы хотим.
Последний шаг - класс TWO_WAY_TREE, по разумным причинам наследуемый от TWO_WAY_LIST и BI_LINKABLE. Достаточно для небольшого сердечного приступа, но нет - все прекрасно сложилось в нужном порядке и в нужном месте. Мы получили все необходимые компоненты, ненужных компонентов нет, концептуально все стражи на месте, так что forth, back и все связанные с ними циклы выполняются быстро, как это требуется, и стражи совсем не занимают памяти.
Это схема реально применяется ко всем действующим классам библиотеки Base. Прежде чем закончить наш полет, еще несколько наблюдений:
Ни при каких обстоятельствах не следует выполнять работу такого вида, включающую трюки с манипуляцией структурой данных, без использования преимуществ, обеспечиваемых утверждениями. Просто невозможно обеспечить правильную работу, не установив точные утверждения инварианта и проверки совместимости.Механизмы дублируемого наследования являются основой (см. лекцию 15 курса "Основы объектно-ориентированного программирования"). Без методов, введенных нотацией этой книги, позволяющих дублируемым потомкам добиваться разделения или покомпонентной репликации, основываясь на простом критерии имен, невозможно эффективно описать любую ситуацию с серьезным использованием дублируемого наследования.Повторим наиболее важный комментарий: такие оптимизации, требующие крайней осторожности, имеют смысл только в общецелевых библиотеках, предназначенных для широкого повторного использования.В обычных ситуациях они стоят слишком дорого. Это обсуждение включено с целью дать читателю почувствовать, какие усилия требуются для разработки профессиональных компонентов от начала и до конца. К счастью, большинство разработчиков не должны прилагать столько усилий в своей работе.
Ссылочная прозрачность
Почему нас волнуют побочные эффекты функций? Ведь в природе ПО заложено изменение вещей в процессе выполнения.
Если позволить функциям, подобно командам, изменять объекты, то мы потеряем многие из их простых математических свойств. Как отмечалось при обсуждении АТД (см. лекцию 6 курса "Основы объектно-ориентированного программирования"), математики знают, что их операции над объектами не меняют объектов (Вычисление |21/2| не меняет числа 2). Эта неизменяемость является основным отличием мира математики и мира компьютерных вычислений.
|
Некоторые подходы в программировании стремятся к этой неизменяемости - Lisp в его так называемой "чистой" форме, языки функционального программирования, например язык FP, предложенный Бэкусом, другие аппликативные языки. Но в практической разработке ПО изменения объектов являются основой вычислений. |
Неизменяемость объектов имеет важное практическое следствие, известное как ссылочная прозрачность (referential transparency) и определяемое следующим образом:
|
Определение: ссылочная прозрачность Выражение e является ссылочно-прозрачным, если возможно заменить любое его подвыражение эквивалентным значением без изменения значения e. |
Если x имеет значение 3, мы можем использовать x вместо 3, и наоборот, в любом ссылочно-прозрачном выражении. (Только академики Лапуты из "Путешествий Гулливера" Свифта игнорировали ссылочную прозрачность, - они всегда носили с собой вещи, предъявляя их при каждом упоминании.) Ссылочную прозрачность называют также "заменой равного равным".
При наличии функций с побочным эффектом ссылочная прозрачность исчезает. Предположим, что класс содержит атрибут и функцию:
attr: INTEGER sneaky: INTEGER is do attr := attr + 1 endЗначение sneaky при ее вызове всегда 0; но 0 и sneaky не являются взаимозаменяемыми, например:
attr := 0; if attr /= 0 then print ("Нечто странное!") endничего не будет печатать, но напечатает "Нечто странное!" при замене 0 на sneaky.
Поддержка ссылочной прозрачности в выражениях важна, поскольку позволяет строить выводы на основе программного текста.
Одна из центральных проблем конструирования ПО четко сформулирована Э. Дейкстрой ([Dijkstra 1968]). Она состоит в сложности динамического поведения (миллионы различных вычислений даже для простых программ), порождаемого статическим текстом программы. Поэтому крайне важно сохранить проверенную форму вывода, обеспечиваемую математикой. Потеря ссылочной прозрачности означает и потерю основных свойств, которые настолько укоренились в нашем сознании и практике, что мы и не осознаем этого. Например, n + n не эквивалентно 2* n, если n задано функцией, подобной sneaky:
n: INTEGER is do attr := attr + 1; Result := attr endЕсли attr инициализировать нулем, то 2* n возвратит 2, в то время как n + n вернет 3.
Функции без побочных эффектов можно рассматривать в программных текстах как термы в обычном математическом смысле. Мы будем поддерживать четкое различение команд, изменяющих объекты, но не возвращающих результатов, и запросов, обеспечивающих информацией об объектах, но не изменяющих их.
Это же правило неформально можно выразить так: "задание вопроса не меняет ответ".
Стратегия
Абстрактные побочные эффекты, в отличие от конкретных, не могут легко обнаруживаться компиляторами. В частности, недостаточно проверить, что сама функция сохраняет значения всех несекретных атрибутов - эффект может быть непрямым и зависит от вызовов других процедур и функций. Другая причина в том, что, как в примере max некоторые побочные эффекты могут в конечном итоге исчезать. Многие из компиляторов способны выдавать предупреждение, если функция модифицирует экспортируемый атрибут.
Поэтому Принцип Разделения Команд и Запросов является методологическим предписанием, а не языковым ограничением. Это не снижает его важности.
Каждый ОО-разработчик должен применять этот принцип без исключения. Я следую ему многие годы и не пишу функций с побочным эффектом. Наша фирма ISE применяет его во всех своих продуктах. Конечно, для тех, где используется язык C, этот принцип нельзя выдержать полностью, но и там мы применяем его всюду, где можно. Он помогает нам добиваться лучших результатов - в инструментарии и библиотеках, допускающих повторное использование, при расширениях и масштабировании.
У5.1 Функция с побочным эффектом
Пример управления памятью на уровне компонентов (см. лекцию 9 курса "Основы объектно-ориентированного программирования") для связных списков имеет функцию fresh, вызывающую процедуру remove для стеков, следовательно, имеющую побочный эффект. Обсудите, является ли это приемлемым.
У5.2 Операнды и опции
Исследуйте класс или доступную библиотеку и определите, какие аргументы подпрограмм являются операндами и какие - опциями.
У5.3 Возможные аргументы
Некоторые языки, такие как Ada, предполагают в подпрограммах возможные аргументы, каждый с ассоциированным ключевым именем. Если ключевое имя не включено, аргумент может быть установлен по умолчанию. Обсудите, какие преимущества принципа Операндов эта техника поддерживает, а какие определенно нарушаются.
У5.4 Число элементов как функция
Адаптируйте определение класса LINKED_LIST [G] так, чтобы count стал функцией, а не атрибутом, оставив неизменным интерфейс класса.
У5.5 Поиск в связных списках
Напишите процедуру search (x: G) для класса LINKED_LIST, разыскивающую следующее вхождение x.
У5.6 Теоремы в инварианте
Докажите истинность трех утверждений из первой части инварианта класса LINKED_LIST, отмеченных как теоремы (см. лекцию 5).
У5.7 Двунаправленные списки
Напишите класс, задающий двунаправленные списки с интерфейсом LINKED_LIST, но более эффективной реализацией таких операций, как back, go и finish.
У5.8 Альтернативный проект связного списка
Предложите вариант класса для связного списка, использующий соглашение о том, что для пустого списка одновременно выполняются after и before. (В первом издании книги использовался этот прием.) Оцените оба подхода.
У5.9 Вставка в связный список
Глядя на remove, напишите процедуры put_left и put_right для вставки элементов слева и справа от позиции курсора.
У5.10 Циклические списки
Объясните, почему класс LINKED_LIST не может использоваться для циклических списков. (Подсказка: покажите, что утверждения будут нарушаться.) Напишите класс CIRCULAR_LINKED, реализующий циклические списки.
У5.11 Функции ввода, свободные от побочных эффектов
Спроектируйте класс, описывающий входные файлы с операциями ввода без любых функций с побочным эффектом. Достаточно написать только интерфейс класса без предложений do, но с заголовками подпрограмм и всеми подходящими утверждениями.
У5.12 Документация
Обсудите, расширив и переопределив, принцип Самодокументирования и его различные разработки в этой книге, рассматривая различные виды документации. Проанализируйте, какие стили документации подходят при определенных обстоятельствах и различных уровнях абстракции.
У5.13 Самодокументированное ПО
Подход к самодокументированию, защищаемый в этой книге, предполагает лаконичность и не поддерживает долгих объяснений проектных решений. Стиль "грамотного программирования" Кнута комбинирует методы программирования и текстовой обработки так, чтобы полная документация проекта и его история содержались в одном документе. Метод основан на классической парадигме разработки проекта сверху вниз. Отталкиваясь от работы Кнута, обсудите, как его метод может быть транспонирован при объектном подходе.
