Исполнение запросов
Как показывает , план выполнения любого запроса XQuery , произведенный компилятором и оптимизатором, передается на дальнейшую обработку исполнителю. Исполнитель интерпретирует план выполнения запроса, представляющий собой дерево физических операций над системой хранения, которые взаимодействуют по данным в конвейерном режиме. Набор поддерживаемых в СУБД Sedna физических операций покрывает функциональность XQuery library [] и XQuery Core . Однако этот базовый набор операций, соответствующий модели данных XQuery , не обеспечивает возможность поддержки всех разумных планов выполнения запросов. В дополнение к физическим эквивалентам понятий модели данных XQuery на физическом уровне в СУБД Sedna используются кортежи , упорядоченные наборы атомарных значений или указателей на дескрипторы узлов. Использование кортежей позволило расширить используемый набор физическими операциями, подобными операциям соединения и группировки SQL .
Конечно, набор физических операций обеспечивает и поддержку логических операций обновления базы данных. Оператор подъязыка XUpdate представляется в виде плана выполнения, состоящего из двух частей: в первой части выбираются узлы, подлежащие обновлению, а во второй части происходит обновление этих узлов. Во время выполнения операции обновления отобранные узлы, равно как и промежуточные результаты любого выражения запроса, представляются прямыми указателями. Во второй части операции для представления обновленных узлов используются косвенные указатели – идентификаторы узлов. Это решение вызвано тем, что обновление выбранных узлов может повлечь их перемещение в памяти, что делает недействительными ведущие к ним прямые указатели.
Конструкторы элементов
Кроме аналогов известных тяжеловесных операций соединения, сортировки и группировки, в XQuery имеется специфическая ресурсоемкая операция – конструктор XML -элемента. Для конструирования XML -элемента требуется глубокое копирование существующих данных, вызывающее накладные расходы, которые особенно существенны при наличии в запросе вложенных конструкторов элементов. Для оптимизации в СУБД Sedna введена операция отложенного конструирования элемента , не выполняющая глубокое копирование содержимого конструируемого элемента, а всего лишь сохраняющая требуемый для этого набор указателей. Реальное копирование происходит в тот момент, когда некоторая операция пытается воспользоваться содержимым сконструированного элемента.
Проведенные исследования [] показали, что для представительного класса XQuery -запросов глубокое копирование вообще не требуется. Большинство XQuery -запросов можно перезаписать таким образом, что в плане выполнения запроса выше конструкторов элементов не будут присутствовать операции, анализирующие содержимое элементов.
Литература
[1] Классификация Рональда Буре. http://www.rpbourret.com/xml/ProdsNative.htm
[2] Sedna XML DBMS - http://modis.ispras.ru/Development/sedna.htm
[3] XQuery 1.0: An XML Query Language, W3C Working Draft, 12 November 2003, http://www.w3.org/TR/2003/WD-xquery-20031112/
[4] XQuery 1.0 and XPath 2.0 Data Model, W3C Working Draft, 12 November 2003,
[5] P. Lehti, "Design and Implementation of a Data Manipulation Processor for an XML Query Language", Technische Universitt Darmstadt Technical Report No. KOM-D-149, http://www.ipsi.fhg.de/~lehti/diplomarbeit.pdf , August, 2001.
[6] Mary F. Fernandez, Jerome Simeon: Growing XQuery. ECOOP 2003: 405-430
[7] Maxim Grinev, Dmitry Lizorkin. XQuery Function Inlining for Optimizing XQuery Queries". Submitted to ADBIS 2004
[8] M. Grinev, P. Pleshachkov. Rewriting-based Optimization for XQuery Transformational Queries Submitted at VLDB 2004. Available at www.ispras.ru/~grinev
[9] U. Dayal. "Of Nests and Trees: A Unified Approach to Processing Queries that Contain Nested Subqueries, Aggregates, and Quanti_ers", In Proc. VLDB Conference, 1987
[10] Peter Pleshachkov, Leonid Novak. Transaction Isolation In the Sedna Native XML DBMS. In. Proc. SYRCoDIS'2004, pp. 26-30
[11] Andrey Fomichev. XML Storing and Processing Techniques. In. Proc. SYRCoDIS'2004, pp. 13-16
[12] Jagadish, H., Al-Khalifa, S., Chapman, A., Lakshmanan, L., Nierman, A., Paparizos S., Patel, J., Srivastava D., Wiwatwattana N., Wu, Y. and Yu, C.: TIMBER: A Native XML Database, The VLDB Journal, Volume 11, Issue 4 (2002) pp 274-291
[13] S. Al-Khalifa, H. Jagadish, J. Patel, Y. Wu, N. Koudas, D. Srivastava: \Structural Joins: A Primitive for Effecient XML Query Pattern Matching", Proceedings of ICDE 2002, San Jose, California
[14] H.-T. Chou, D. J. DeWitt. An Evaluation of Buffer Management Strategies for Relational Database Systems", Proceedings of VLDB, 1985
[15] K. Antipin, A. Fomichev, M. Grinev, S. Kuznetsov, L. Novak, P. Pleshachkov, M. Rekouts, D. Shiryaev. "Effecient Virtual Data Integration Based on XML", In Proc. ADBIS Conference, LNCS 2798, Springer, 2003
[16] Ronald Bourret. Native XML database use case survey. Private communication.
Общая архитектура системы
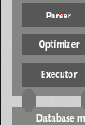
На изображена общая архитектура СУБД Sedna , в которой выделяются следующие компоненты. Регулятор ( governer ) служит “управляющим центром” системы. Все остальные компоненты регистрируются у регулятора. Регулятор знает, с какими базами данных работает система, и отслеживает выполнение транзакций. Компонент слушатель ( listener ) создает для каждого нового авторизованного клиента экземпляр компонента подключение ( connection ) и устанавливает между ними прямую связь. В компоненте подключения инкапсулируется сессия клиента. Для каждой заявки клиента “начать транзакцию” (“ begin transaction ”) его компонент подключения создает экземпляр компонента транзакция ( transaction ). В этом компоненте инкапсулируются компоненты выполнения запросов: парсер ( parser ), оптимизатор ( optimizer ) и исполнитель ( executor ).
 |
 |
 |
 |
 |
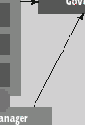 |
 |
 |
 |
 |
 |
 |
Рис. 1. Архитектура СУБД Sedna
Парсер преобразует запрос в логическое представление, представляющее собой дерево операций, близких к тем, которые специфицированы в ядре XQuery ( XQuery Core ). Оптимизатор получает логическое представление запроса и производит план выполнения запроса, дерево низкоуровневых операций над физическими структурами данных. План выполнения интерпретируется исполнителем, который взаимодействует с соответствующим экземпляром менеджера базы данных.
В каждом экземпляре менеджера базы данных ( database manager ) инкапсулируется одна база данных. Менеджер базы данных включает менеджер индексов ( index manager ) , отслеживающий индексы, построенные над базой данных; менеджер буферов ( buffer manager ) , отвечающий за взаимодействия между дисковой и основной памятью; менеджер транзакций ( transaction manager ) , обеспечивающий корректность параллельного выполнения транзакций.
Предпосылки и архитектура СУБД Sedna
Хотя язык XQuery уже является мощным и зрелым языком запросов и трансформаций XML -данных, он все еще остается развивающимся языком. Выделяются два наиболее важных направления развития языка: включение в язык средств обновления данных и добавление в него средств, превращающих XQuery в язык программирования []. Таким образом, в будущем XQuery будет являться языком, равно пригодным для запросов и обновления XML -данных, а также для программирования в традиционном смысле.
В реализациях XQuery , пригодных для практического применения, требуется учитывать совместно все три требования, обеспечивая эффективную поддержку системы на физическом уровне. Этот физический уровень основывается, прежде всего, на методах организации данных и управления памятью. Для обработки запросов требуется поддержка огромного объема данных, для работы с которыми не хватает емкости основной памяти, и требуется обработка во вспомогательной (дисковой) памяти. Для выполнения операций обновления данных требуется компромиссная организация данных, остающаяся эффективной для выполнения запросов и являющаяся достаточно гибкой, чтобы обновления XML -данных не приводили к коренному изменению структуры хранения. Наконец, для использования XQuery в качестве языка программирования требуется быстрое выполнение XQuery -“программ” в основной памяти с минимизацией накладных расходов, связанных с поддержкой внешней памяти.
При проектировании и разработке СУБД Sedna преследовались две основные цели. Во-первых, система должны быть полнофункциональной. Это означает, что в ней обязаны присутствовать все традиционные механизмы систем баз данных: управление внешней памятью, средства запросов и обновления данных, управление параллельно выполняемыми транзакциями, оптимизация запросов и т.д. Во-вторых, система должна поддерживать среду выполнения приложений, интенсивно обрабатывающих XML -данные. Для этого требуется тесная интеграция функциональных возможностей средства управления XML -данными и языка программирования.
Разработка СУБД Sedna не основана использовании какой-либо существующей системы баз данных. Вместо того, чтобы создавать некоторую надстройку над существующей СУБД, мы разрабатываем систему управления XML -данными с нуля. Для этого требуется больше времени и усилий, но зато разработчики обладают большей свободой в принятии проектных решений и могут избежать накладных расходов, которые неизбежно возникали бы при взаимодействии надстройки и “опорной” СУБД.
Различные стратегии выполнения XPath-запросов
Использование описывающей схемы в качестве индексной структуры позволяет избежать обхода дерева и ускорить выполнение запроса. Например, рассмотрим XPath -запрос // title к XML -документу, представленному на . Мы называем подобные запросы структурными путевыми запросами , потому что в них используется только информация о структуре XML -документа, и для выполнения запроса не требуется производить какие-либо проверки, связанные с данными. Для выполнения структурных запросов идеально подходит описывающая схема.
Выполнение запроса начнется с обхода описывающей схемы (см. ). В результате обхода будут получены два узла схемы, содержащие указатели на списки блоков с искомыми данными. Если просто пройти сначала по первому списку блоков, а затем – по второму, можно нарушить порядок документа. Поэтому до выдачи результата требуется выполнение операции слияния. Операция слияния получает на входе несколько списков блоков и производит список дескрипторов узлов, упорядоченный в соответствии с порядком документа. Для восстановления порядка документа в операции слияния используются метки нумерующей схемы.
В качестве еще одного примера, рассмотрим возможные стратегии выполнения запроса / library / book [ issue / year =2004]/ title . Как и в случае предыдущего запроса, можно выбрать элементы / library / book с использованием описывающей схемы, а затем применить предикат и выполнить оставшуюся часть запроса с использованием указателей на данные. Но более эффективным является следующий алгоритм. Сначала вычисляется структурная часть запроса: / library / book / issue / year / text () . Затем применяется предикат (выбираются только те узлы, для которых text =2004 ). И, наконец, к результату этого шага применяется запрос ../../../ title .
Система хранения и управление памятью
При разработке методов структуризации данных и управления памятью преследовалась цель добиться эффективности работы системы при выполнении запросов и операций обновления базы данных, а также “программ” XQuery , не связанных с интенсивным потреблением данных и отражающих логику приложения []. Общие идеи заключаются в том, что, во-первых, содержимое блоков базы данных не изменяется при перемещении блока из внешней в основную память (т.е. не возникает известная проблема “настройки по адресам” (swizzling), для решения которой требуются существенные накладные расходы). Во-вторых, для представления связей между узлами XML -документа почти всегда используются прямые указатели, которые можно использовать для перехода от одного узла к другому сразу после перемещения блока базы данных в основную память. При этом потенциальный размер базы данных не ограничивается.
Сочетание ленивой и строгой семантики
Все запросы к базам данных обладают одной общей чертой: они обычно оперируют большими объемами данных, даже если размеры результатов являются небольшими. Поэтому процессоры запросов должны эффективно обрабатывать огромные промежуточные наборы данных. В реляционных СУБД была разработана модель итеративного исполнения запросов, позволяющая избежать излишней материализации данных. По причине общности подхода, модель можно применять и для других моделей данных. В [] была предложена адаптация итеративной модели для исполнения XQuery -запросов.
Принимая во внимание функциональную природу языка XQuery , можно относиться к итеративной модели, как к реализации ленивой ( lazy ) семантики. Если же относиться к XQuery и как к языку программирования общего назначения, который может применяться для выражения логики приложений, реализация только ленивой семантики может отрицательно сказаться на общей эффективности исполнителя. Для обеспечения реализации XQuery , достаточно эффективной при обработке и запросов, и логики приложений, в исполнителе СУБД Sedna сочетаются две модели исполнения.
В исполнителе XQuery отслеживается объем обрабатываемых данных, и может происходить автоматическое переключение из ленивого режима исполнения в строгий ( strict ) режим (и наоборот) во время исполнения. Исполнение запроса в соответствии с имеющимся планом запроса начинается в ленивом режиме. Накладные расходы ленивой модели сильно коррелируют с числом вызовов функций, производимых в процессе исполнения. Чем больше выполняется вызовов функций, тем больше производится копий тел этих функций. Цель применяемого подхода состоит в нахождении компромисса между копированием тел функций и материализацией результатов вызовов функций. В разработанном механизме каждый вызов функции побуждает к переключению на строгую модель, если размеры аргументов относительно невелики. И наоборот, наличие большой входной последовательности любой физической операции является поводом для выполнения этой операции в ленивом режиме.
Структуры данных
В СУБД Sedna в основе хранения XML -документа во внешней памяти лежит описывающая ( descriptive ) схема XML -документа, в соответствии с которой осуществляется кластеризация узлов XML -документа в блоках базы данных. Описывающая схема генерируется (и поддерживается) динамически на основе хранимых данных и представляет собой краткое и точное описание структуры этих данных. Выражаясь формально, для каждого пути в документе существует в точности один путь в описывающей схеме, и каждый путь в описывающей схеме является путем в документе.
<library> <book> <title>Foundation of Databases</title> <author>Abitboul</author> <author>Hull</author> <author>Vianu</author> </book> <book> <title>An Introduction to Database Systems</title> <author>Date</author> <issue> <publisher>Addison-Wesley</publisher> <year>2004</year> </issue> </book> ... <paper> <title>A Relational Model for Large Shared Data Banks</title> <author>Codd</author> </paper> </library>
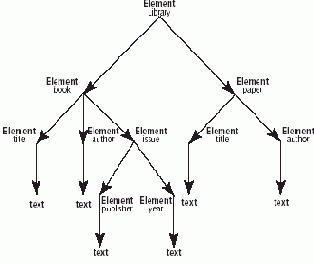
Рис. 2. Организация данных
Общие принципы организации хранения XML -документа иллюстрируются на . Центральным компонентом является описывающая схема, представляемая в виде дерева узлов. Каждый узел схемы помечается названием разновидности XML -узла (например, element , attribute , text и т.д.) и содержит указатель на блоки данных, в которых хранятся узлы XML -документа, соответствующие данному узлу схемы. Некоторые узлы схемы, в зависимости от вида узла, помечаются дополнительными именами.
Блоки данных, относящиеся к одному узлу схемы, связаны указателями в двунаправленный список. Дескрипторы узлов в списке блоков частично упорядочены в соответствии с порядком документа. Это означает, что каждый дескриптор узла в блоке i предшествует каждому дескриптору узла в блоке j в соответствии с порядком документа том и только в том случае, когда i < j (т.е. блок i предшествует блоку j в списке). Внутри блока узлы линейно не упорядочиваются, что сокращает накладные расходы на поддержку порядка документа при выполнении операций обновления.
В системе хранения разделяются структурная часть узла и его текстовое значение, являющееся содержимым текстового узла, или значением узла-атрибута и т.д. Длины текстовых значений являются переменными, и они хранятся в отдельных блоках со специальной структурой. В структурной части узла, представляемой в виде дескриптора узла, отражаются его связи с другими узлами (предком, потомками, братьями и т.д.).
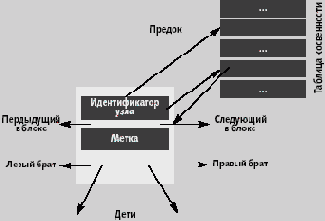
Рис. 3. Общая структура дескриптора узла
Общая структура дескриптора узла для всех разновидностей узлов показана на . Поле метки содержит метку нумерующей схемы (про нумерующую схему и идентификаторы узлов см. ниже. Указатели на следующий и предыдущий узлы в том же блоке служат для восстановления порядка документа между узлами документа, соответствующими одному и тому же узлу схемы, а указатели на левого и правого братьев по схеме – для поддержки порядка документа между узлами-братьями. В дескрипторе хранятся ссылки только на первые дочерние узлы в соответствии с описывающей схемой. Поддержка только указателя на первого потомка в соответствии со схемой позволяет экономить память и, что более важно, сохранять фиксированный размер дескриптора блока. Последнее свойство особенно существенно для эффективного выполнения операций обновления, поскольку упрощается управление свободной памятью внутри блока.
Использование прямых указателей способствует эффективному выполнению запросов, но порождает проблемы эффективного выполнения операций обновления. Чтобы организация данных была эффективно пригодна для обновлений, нужно минимизировать число модификаций данных, производимых при выполнении операции обновления. Например, выполнение некоторых операций обновления может привести к перемещению узла. Если у узла, который требуется переместить, имеются узлы-потомки, то в каждом из них необходимо поменять значения указателей на узел-предок. Чтобы избежать этой массовой операции, для ссылок на узлы-предки используются косвенные указатели, реализуемые через таблицу косвенности.
Нумерующая схема назначает уникальную метку каждому узлу XML -документа в соответствии с присущими данной схеме правилами нумерации. Метки кодируют информацию об относительной позиции узла в документе. Таким образом, основное назначение нумерующей схемы состоит в обеспечении быстрых механизмов определения структурной связи между парой узлов. При разработке СУБД Sedna требовалась нумерующая схема, обеспечивающая обнаружение связи “потомок-предок” и сравнение узлов в порядке документа. Первый механизм позволяет поддерживать планы выполнения запросов, основанные на соединениях " включению” ( containment join ) [-]. Второй механизм используется для реализации операций XQuery , основанных на порядке документа (например, сравнение узлов, XPath и т.д.).
Основная проблема существующих нумерующих схем для XML (например, схемы, предложенной в []) состоит в том, что вставка узлов может повлечь реконструкцию всего XML -документа. В СУБД Sedna используется новая нумерующая схема, не требующая подобной реконструкции. Идея этой нумерующей схемы основана на том наблюдении, что для каждых двух заданных строк str 1 и str 2 , таких что str 1 < str 2 (в лексикографическом порядке), существует строка str , такая что str 1 < str < str 2 . Например, для str 1 = " abn ", str 2 = " ghn " возможным значением str является " bcb ", а для str 1 = " ab ", str 2 = " ac " значением str может быть " abd ". Нумерующая схема, поддерживающая порядок документа, может быть использована для реализации понятия уникального идентификатора ( unique identity ), принятого в XQuery , потому что в такой схеме любые два узла с одинаковыми метками являются одним и тем же узлом.
Для реализации некоторых операций и механизмов управления базой данных требуется поддержка идентификатора узла, являющегося неизменным во все время существования узла и обеспечивающего эффективный доступ к узлу. Например, идентификаторы узлов могут использоваться для ссылки на узлы в индексных структурах. Эти идентификаторы также требуются для корректной реализации операций обновления. Как отмечалось выше, при выполнении некоторых операций обновления может потребоваться перемещение узлов. Поэтому указатели на узлы не обладают свойством неизменности. Хотя метка нумерующей схемы этим свойством обладает, для получения узла по известной метке требуется обход дерева документа. Реализация идентификатора узла показана на . Она основана на поддержке специальной таблицы косвенности, которая также используется для реализации косвенных указателей на узлы-потомки. Идентификатор узла является указателем на запись в таблице косвенности, которая содержит указатель на узел.
Технические особенности
В настоящее время оптимизация запросов в СУБД Sedna основывается на методах перезаписи XQuery -запросов под управлением набора правил. В будущих версиях системы будет использоваться и оценочная оптимизация. В текущем оптимизаторе запросов используются следующие методы.
Метод открытой подстановки тел функций [] позволяет заменить вызов определенной пользователем функции на ее тело. Открытая подстановка устраняет накладные расходы, порождаемые при вызове функции, и дает возможность совместной статической оптимизации тела функции совместно с общим кодом запроса. Реализованный алгоритм открытой подстановки корректно обрабатывает вызовы не рекурсивных и структурно рекурсивных функций и разумным образом завершается при обработке вызовов произвольных рекурсивных функций.
Метод “выдавливания” ( push down ) предикатов ниже конструкторов элементов XML [] позволяет изменить порядок операций таким образом, чтобы предикаты применялись до выполнения конструкторов XML -элементов. Это позволяет уменьшить размер промежуточных результатов, к которым применяются конструкторы.
При применении метода “проекции преобразования” ( projection of transformation ) [] выражение XPath статически применяется к конструкторам элементов. Это позволяет избежать избыточных вычислений в конструкторах XML -элементов на стадии выполнения запроса.
Метод упрощения запроса на основе использования схемы оказывается полезным в тех случаях, когда схема XML -документа доступна оптимизатору, а запрос сформулирован пользователем, не имеющим отчетливого представления об этой схеме. Получение более точной формулировки запроса позволяет избежать избыточного сканирования данных, свойственного запросам, при формулировке которых не учитывалась схема. Этот оптимизационный метод базируется на статическом выводе типов данных в языке XQuery .
Метод повышения уровня декларативности формулировки запроса дает возможность расширить пространство поиска оптимизатора при выборе оптимального плана выполнения запроса. Метод является адаптацией аналогичного SQL -ориентированного метода [], позволяющего преобразовывать SQL -запросы со вложенными подзапросами в эквивалентные запросы с соединениями.
Нормализация предикатов соединения состоит в их приведении в конъюнктивную нормальную форму, чтобы можно было использовать различные алгоритмы выполнения операции соединения, а не только алгоритм вложенных циклов. Для достижения этой цели в оптимизаторе СУБД Sedna из предикатов соединения извлекаются подвыражения, подобные операторам XPath , и помещаются вне операций соединения, где они вычисляются только один раз.
Наконец, метод распознавания инвариантных подвыражений в теле итерационных операций и вынесения их за пределы этих операций позволяет уменьшить вычислительную сложность запроса.
Для обеспечения сериализуемости транзакций применяется вариант известного строгого двухфазного протокола синхронизационных блокировок (2 PL ). В текущей версии системы единицей блокировки является XML -документ целиком. Однако во многих случаях блокировка всего XML -документа не требуется и приводит к уменьшению уровня параллельности. Поэтому разрабатывается новый метод “гранулированных” блокировок, позволяющий поддерживать высокий уровень параллельности [].
Основная идея метода состоит в использовании нумерующей схемы для блокировки узлов и поддеревьев XML -документа. Блокировка целого поддерева реализуется посредством блокировки интервала меток нумерующей схемы, включающего метки всех узлов этого поддерева. Этот интервал может быть вычислен на основе метки корневого узла поддерева. При этом подходе для блокировки поддерева не требуется блокировка узлов-предков корня поддерева в “целевом” ( intention ) режиме.
Управление памятью
Как уже говорилось, одним из основных проектных решений, имеющих отношение к организации памяти в СУБД Sedna , является использование прямых указателей для представления связей между узлами. Хотя использование обычных указателей языков программирования, поддерживаемых механизмом управления виртуальной памяти операционной системы, идеально с точки зрения эффективности и простоты программирования, в данном случае это решение не является удовлетворительным. Во-первых, оно накладывает ограничение на размер адресного пространства, свойственное стандартным 32-битовым архитектурам, которые превалируют в настоящее время. Во-вторых, при обработке запросов над большими объемами данных СУБД не может полагаться на механизм виртуальной памяти, обеспечиваемый ОС, потому что требуется собственное управление процедурой замещения страниц для выталкивания страниц на диск в соответствии логикой выполнения запроса [].
Для решения этой проблемы в проекте Sedna был разработан собственный механизм управления памятью, поддерживающий 64-битовое адресное пространство ( Sedna Address Space , SAS ) и тесно взаимодействующий с менеджером буферов. Каждой базе данных, управляемой СУБД Sedna , соответствует свое SAS , полностью отображаемое на внешнюю память, где реально хранится база данных, и частично отображаемое на виртуальное адресное пространство каждого процесса, в котором выполняется транзакция с соответствующей базой данных ( Process Virtual Address Space , PVAS ). В отображенной части SAS можно использовать обычные указатели.
SAS разбивается на уровни одинакового размера. Размер уровня выбирается таким, чтобы диапазон адресов уровня умещался в PVAS . Уровень стоит из страниц (они соответствуют блокам внешней памяти, в которых хранятся узлы XML -документа). Все страницы имеют один и тот же размер, что облегчает работу менеджера буферов. В заголовке каждой страницы сохраняется номер уровня, которому принадлежит данная страница. Адрес объекта в SAS (длиной 64 бита) состоит из номера уровня (первые 32 бита) и адреса внутри уровня (последние 32 бита). Адрес внутри уровня отображается в точно такой же адрес PVAS . Диапазон адресов PVAS , на который отображаются уровни SAS , в свою очередь, отображается менеджером буферов Sedna в адреса основной памяти с использованием средств управления памятью, обеспечиваемых ОС.
При использовании указателя ( layer _ num , addr ) в любом процессе- транзакции для перехода от дескриптора некоторого узла к узлу, который потенциально может находиться в другом блоке (левый и правый братья, потомки) выполняется процедура разыменования указателя. Эта процедура проверяет, присутствует ли страница, на которую указывает адрес addr , в основной памяти, и если да, то соответствует ли значение layer _ num данного указателя соответствующему значению в заголовке страницы. Если оба эти условия выполнены, то процедура завершается, и addr используется как обычный указатель в PVAS . В противном случае происходит обращение к менеджеру буферов, который находит в основной памяти требуемую страницу или выделяет свободную страницу (возможно, выталкивая из основной памяти во внешнюю некоторую занятую страницу), считывая на нее соответствующий блок внешней памяти, и обеспечивает ее расположение по требуемому адресу в PVAS . После этого в данной транзакции можно использовать addr как обычный указатель в PVAS . Следует также заметить, что, помимо прочего, выполнение процедуры разыменования в данном процессе приводит к фиксации соответствующей страницы в основной памяти до явного указания возможности отмены фиксации.
Таким образом, в любом PVAS могут одновременно находиться страницы с разными значениями layer _ num , а в пуле страниц основной памяти, управляемом менеджером буферов, могут даже одновременно находиться заполненные страницы с разными layer _ num , которым соответствует один и тот же виртуальный адрес в PVAS (конечно, в одном PVAS может в одно и то же время присутствовать только одна из этих страниц).
Варианты использования
Упоминавшийся нами во введении Рональд Буре собирается подготовить обзор вариантов использования прирожденных XML -СУБД. С этой целью он подготовил документ [], в котором содержатся его предварительные соображения о вариантах использования и вопросы к разработчикам и пользователям прирожденных XML -СУБД. Нельзя сказать, чтобы все соображения Буре были обоснованными, а некоторые даже производят впечатление не вполне продуманных фантазий. Однако на сегодняшний день этот материал является единственным, исходящим от независимого эксперта. Коротко обсудим некоторые из вариантов использования из списка Буре и соотнесем их с возможностями СУБД Sedna . (В начале каждого из следующих четырех пунктов приводится пересказ текста Буре, за которым следует наш коментарий.)
Вариант 1: Большие документы. Во многих приложениях XML -документы обрабатываются в модели DOM или преобразуются с использованием процессоров XSLT . В обоих случаях, как правило, требуется присутствие в прямо адресуемой памяти всего обрабатываемого элемента. Поскольку для хранения документа, например, в модели DOM требуется примерно в десять раз больше памяти, чем для исходного XML -документа, большие документы обрабатывать оказывается невозможно. Здесь может помочь прирожденная XML -СУБД, в базе данных которой DOM или XSLT будут хранить узлы документа, извлекая их по мере потребности.
Конечно, любая прирожденная (скорее всего, и любая приспособленная к XML ) СУБД справится с поддержкой DOM или XSLT . Но кажется, что в подобных приложениях будет использоваться только незначительная часть функциональных возможностей системы. Нужна ли здесь, например, полная поддержка XQuery , или достаточен XPath ? Требуется ли поддержка транзакционности? И т.д.
Вариант 2: Документно-центрические ( document - centric ) XML -данные. Прирожденные XML -СУБД хорошо подходят для управления документно-центрическими XML -данными, потому что в них сохраняется порядок документа, и они легко справляются с обработкой смешанного контента (чего нет в большинстве СУБД, приспособленных к XML ). При управлении контентом могут оказаться востребованными развитые средства формулировки запросов. Однако Буре приводит ряд доводов в пользу того, что на практике для хранения фрагментов документов в системах управления контентом ( content management system ) оказывается достаточным применение CLOB 'ов SQL -ориентированных баз данных, если в соответствующей СУБД поддерживается полнотекстовый поиск с учетом специфики XML . Более развитые запросы могут быть полезны, но пользователи могут без них и обойтись.
Как кажется нам, при анализе этого варианта использования нельзя говорить как про полезность абстрактных прирожденных XML -СУБД вообще, так и про потребности абстрактных систем управления контентом. Если (как в случае СУБД Sedna ) в системе полностью поддерживается язык XQuery , и его средства запросов и трансформации данных хорошо оптимизированы, а приложению требуется не только формировать, но и визуализировать контент, то этот вариант использования прирожденных XML -СУБД выглядит очень заманчивым (см. также конец этого раздела).
Вариант 3: Управление полуструктурированными данными. В соответствии с Буре, полуструктурированным данными свойственны следующие характеристики: самоописательность – метаданные ассоциируются с элементарными частями данных; возможность представления разными способами одного и того же вида данных; возможность наличия произвольных дополнительных полей; разреженность данных. XML и прирожденные XML -СУБД весьма пригодны для представления полуструктурированных данных и управления ими соответственно: наличие схемы необязательно, разреженные данные представляются эффективно (последнее свойство отсутствует – по Буре! – в реляционных системах.
Здесь снова опасно говорить про пригодность для управления полуструктурированными данными абстрактной прирожденной XML -СУБД. Имеется сильная зависимость от конкретных технических особенностей индивидуальной системы. Например, СУБД Sedna пригодна для этого варианта использования, поскольку в основе структуры хранения XML -документа и обеспечения доступа к его узлам лежит описывающая схема, которая строится вне зависимости от наличия или отсутствия предписывающей схемы. Язык XQuery позволяет формулировать запросы без предварительного знания схемы документа. Все, что потеряется в СУБД Sedna при работе с базой XML -данных без предписывающей схемы, – это возможность выполнения некоторых оптимизационных преобразований запросов (см. выше), полезных, но не обязательных.
Вариант 4: Иерархические данные. Модель данных XML является иерархической, поэтому иерархические данные представляют собой естественный вариант использования прирожденных XML-СУБД. Иерархические данные могут быть однородными или неоднородными. У однородных иерархических данных большая часть узлов ветвления или все узлы имеют один и тот же тип. Однородные иерархические данные могут иметь произвольную глубину. В неоднородных иерархических данных – к которым относится большая часть иерархических данных – узлы потомков имеют типы, отличные от типов своих предков. По определению, неоднородные иерархии имеют фиксированную глубину. Реляционные базы данных могут управлять и однородными, и неоднородными иерархическими данными, хотя в каждом случае могут встретиться проблемы. Большая часть данных в реляционных базах данных используется для построения неоднородных иерархий. Здесь ограничивающим фактором является глубина. Каждая таблица представляет отдельный тип узла, и для построения иерархии требуется соединение данных из нескольких таблиц. Построение глубокой иерархии означает выполнение многих соединений, что, в конце концов, вызовет деградацию производительности до недопустимого уровня. Вот почему в базах данных, приспособленных к работе с XML путем использования объектно-реляционных отображений, возникают проблемы эффективности при работе с глубоко вложенными XML-документами. Однородные иерархии хранятся в одной таблице. Имеется ряд способов запросов однородных иерархических данных, большинству из которых свойственны проблемы
Конечно, прирожденные XML -СУБД обеспечивают возможности работы и с однородными, и с неоднородными иерархическими данными. Конечно, такие возможности существуют и в SQL -ориентированных СУБД. Например, в стандарте SQL :1999 имеются средства формулировки рекурсивных запросов, прямо оптимизированные для эффективной работы с однородными иерархиями неизвестной глубины. По всей видимости, сравнивать эффективность можно только на разных классах запросов. При выполнении запросов над иерархическими данными, в которых соединения требуются только для воссоздания иерархии, прирожденные XML -СУБД могут оказаться эффективнее реляционных. Для тех запросов, в которых потребность в соединениях возникает и в реляционных СУБД, и в прирожденных XML -СУБД, более эффективными могут оказаться реляционные системы (по крайней мере, до тех пор, пока методы выполнения операции соединения в прирожденных XML -СУБД не будут оптимизированы до такого же уровня, как в реляционных системах).
На этом мы прекратим обсуждение вариантов использования из списка Рональда Буре, поскольку оставшиеся пять вариантов являются менее понятными, и кратко рассмотрим еще один вариант, для которого оптимизирована XML -СУБД Sedna . Предлагаемый вариант использования можно назвать “ XML -СУБД как платформа Web -приложений управления контентом”.
Основная идея (которая в менее явной форме затрагивалась в первых разделах статьи) состоит в следующем. В настоящее время во многих прирожденных XML -СУБД поддерживается язык XQuery . Этот язык можно считать не только языком запросов и трансформации XML -данных, но и функциональным языком программирования общего назначения (поскольку он полон по Тьюрингу, и в нем поддерживается возможность определения пользовательских функций – к сожалению, только функций первого порядка). Поэтому на языке XQuery можно реализовать Web -приложение целиком, не только ту часть, которая связана с запросами XML -данных, но и визуализацию путем трансформации XML -данных в форматы XHTML , VoiceML и т.д., а также и логику приложений. В этом случае XML -СУБД являлась бы единственным движущим механизмом всего Web -приложения.
Некоторым разработчикам предложение использовать XQuery (с применением XML для представления структур данных) для выражения логики приложения может показаться неожиданным и даже пугающим, но эта возможность вполне реальна и обеспечивает ряд преимуществ.
Во-первых, этот подход позволяет избежать потребности в решении проблемы потери соответствия ( impedance mismatch ), которая возникает при одновременном использовании ряда языков, основанных на разных моделях и парадигмах. Например, если разработчик использует Java (для выражения логики приложения) и XSLT (для визуализации), он вынужден заботиться об отображении между объектно-ориентированной моделью данных и моделью данных XML . Обеспечение такого отображения не только чревато техническими сложностями, но может также привести и к общему падению эффективности.
Во-вторых, становится возможной статическая проверка наличия ошибок. Например, если динамическая XHTML -страница генерируется с использованием некоторого (обычно, скриптового) языка, не основанного на модели данных XML (например, Java / JSP ), то ошибки в динамической части страницы могут быть обнаружены только во время выполнения. Если же динамическая XHTML -страница реализуется с использованием XQuery , то ее динамическая часть может быть проверена на предмет наличия ошибок путем использования механизма статического вывода типов XQuery.
Наконец, если в XML -СУБД наряду со средствами управления собственными базами данных поддерживаются средства интеграции данных, то тот же язык XQuery может быть использован для запросов внешних источников данных (например, реляционных баз данных) в терминах XML . В этом случае XQuery позволяет избежать еще одной потери соответствия – между моделью языка, на котором выражается логика приложения, и моделью данных внешнего источника данных.
Из описания особенностей СУБД Sedna , приведенного в первых разделах статьи, легко увидеть, что система действительно оптимизируется в расчете на этот вариант использования. Чтобы обеспечить эффективное выполнение запросов и операций обновления наряду с эффективным выполнением “программ” XQuery , в системе хранения СУБД Sedna поддерживаются прямые указатели в 64-разрядном адресном пространстве базы данных, эффективно отображаемые в указатели 32-разрядной виртуальной памяти. При выполнении операций XQuery исполнитель динамически изменяет режим исполнения с ленивого на строгий, и наоборот в зависимости от природы исполняемой операции (связана ли эта операция с интенсивным потреблением данных, или же в основном имеет вычислительный характер).
Для обеспечения эффективного использования XQuery в качестве языка трансформаций введена операция отложенного конструирования XML -элемента. Использование этой операции позволяет при выполнении большинства трансформационных запросов XQuery избежать дорогостоящего глубокого копирования XML -элементов.
Наконец, еще одна возможность, не упоминавшаяся ранее в этой статье. В предыдущем проекте группы MODIS была реализована система виртуальной интеграции BizQuery [], обеспечивающая доступ через глобальную схему к совокупности распределенных внешних источников данных. В планах группы MODIS числится включение возможностей BizQuery в СУБД Sedna.
с непрерывно возрастающим масштабом использования
В связи с непрерывно возрастающим масштабом использования языка XML и связанных с ним дополнительных спецификаций и инструментальных средств в последние годы одной из основных задач мирового сообщества (как исследователей, так и поставщиков коммерческих программных продуктов) является обеспечение систем управления базами данных, максимально пригодных и удобных для долговременного хранения XML -документов и управления ими. К настоящему времени имеется множество программных систем, так или иначе решающих эту задачу. Эти системы весьма различаются как по своим функциональным возможностям, так и в отношении архитектурной организации. Было предпринято несколько попыток классификации систем в соответствии с теми или иными критериями. По-видимому, наиболее известной и используемой является классификация Рональда Буре [], но и она не является вполне обоснованной и убедительной.
В этой статье мы не намериваемся критиковать или совершенствовать классификацию систем управления XML -данными. Однако отметим, что если говорить о системах, обладающих, помимо специфических возможностей управления XML -данными, развитыми традиционными функциями СУБД (многопользовательский режим, транзакционность, авторизация доступа, восстановление после сбоев и т.д.), то можно условно разделить существующие системы на два крупных класса. Первый класс составляют системы, существовавшие до появления потребности в работе с XML , и впоследствии к этому приспособленные (Буре лаконично называет их XML - enabled DBMS , а мы в этой статье, не претендуя на введения термина, будем называть их СУБД, приспособленные к XML ). Ко второму классу относятся системы, специально спроектированные и разработанные для управления XML -данными. В классификации Буре эти системы называются native XML DBMS , и в статье мы будем их называть прирожденными XML -СУБД .
Системы обоих классов плодятся и размножаются. Очевидно, что имеется потенциальная потребность и в СУБД, приспособленных к XML , и во врожденных XML -СУБД. Например, на предприятиях, которые традиционно пользуются некоторой развитой SQL -ориентированной СУБД, естественно пытаться удовлетворить свои потребности в поддержке XML -приложений за счет дополнительных возможностей новых версий того же продукта. Напротив, в тех случаях, когда компания делает стратегическую ставку на XML , и все ее будущие приложения будут основаны на работе с XML -данными, разумно опираться на некоторую прирожденную XML- СУБД.
Между системами указанных двух классов, помимо технических различий, имеется важное маркетинговое различие. У СУБД, приспособленных к XML , как правило, наличествуют традиционные потребители. Конечно, компании, производящие такие системы, стремятся к расширению рынка за счет повышения качества продукта и расширения его функциональности, но главным стимулом являются потребности традиционных потребителей. У прирожденных XML -СУБД, по причине их молодости, традиционных потребителей мало или нет вовсе. Для нахождения своей рыночной ниши компании, производящие прирожденные XML -СУБД, должны оптимизировать свои системы в расчете на наиболее перспективный вариант использования.
Тема вариантов использования прирожденных XML -СУБД широко обсуждается как в исследовательской среде, так и среди производственных разработчиков. В этой статье мы также хотим затронуть эту тему, представив сначала вниманию читателей некоторые интересные и важные особенности отечественной прирожденной XML -СУБД Sedna , разрабатываемой исследовательской группой MODIS Института системного программирования РАН [].
Текущая реализация СУБД Sedna базируется на спецификациях языка XQuery 1.0 [] и его модели данных []. Для обеспечения поддержки обновлений баз XML -данных язык XQuery расширен средствами обновления данных (в контексте СУБД Sedna этот подъязык называется Xupdate ). При разработке XUpdate использовались идеи и предложения, описанные в []. Для кодирования СУБД Sedna применялись языки программирования Scheme и C ++. Язык Scheme использовался при написании компонентов статического анализа и оптимизации запросов. Компоненты синтаксического разбора, исполнения запросов, управления памятью и транзакциями и т.д. кодировались на языке C ++. Первой реализационной платформой было семейство Windows . В настоящее время ведется работа по переносу системы в среду Linux и других UNIX -платформ. СУБД Sedna можно свободно получить на сайте [].
и большинство существующих прирожденных XML
Как и большинство существующих прирожденных XML -СУБД, Sedna является молодой и интенсивно развивающейся системой. До сих пор эта система еще не использовалась в реальных производственных проектах, но у группы MODIS уже имеются многочисленные единомышленники, которые работают с системой в опытном режиме, высказывают советы и рекомендации по совершенствованию системы и планируют использовать СУБД в реальных проектах.
Испытать возможности системы может любой желающий. Члены группы MODIS глубоко заинтересованы в наибольшем числе откликов, желательно, критических и конструктивных. И конечно, нас, как и разработчиков всех прирожденных XML -СУБД интересуют предложения новых вариантов использования системы, готовность к которым мы должны проверить и/или обеспечить.
Прочитать дополнительную информацию о СУБД Sedna и скачать полноценную версию системы можно на сайте modis.ispras.ru/Development/sedna.htm .
