Анализ документа
Для управления процессом анализа документа можно изменять следующие рассмотренные ранее свойства XMLDOMObject : async, validateOnParse, resolveExternals, preserveWhiteSpaces.
Необходимо запомнить, что анализ XML документа производится непосредственно после загрузки его содержимого - остановить этот процесс можно только используя метод abort. Поэтому свойства обработчика нужно изменять перед его загрузкой.
В процессе анализа документа обработчиком могут вызываться некоторые события, перехватывая которые можно отслеживать все шаги обработки. Для назначения классов обработчиков используются свойства , описанные в таблице. Вот пример программы-обработчика события , возникающего при изменении текущего состояния анализатора. <script> var xmldoc; var messages = new Array(5); var result_str = " Демонстрация обработки событий<hr/>"; messages[0]="Загрузка документа."; messages[1]="Загрузка завершена. Начинаю анализ документа"; messages[2]="Начинаю создание объектной модели"; messages[3]="Обработку завершил";
function startParse(url){ xmldoc = new ActiveXObject("Microsoft.XMLDOM"); xmldoc.onreadystatechange = onChangeState; xmldoc.load(url); xmlMessages.innerHTML = result_str; }
function onChangeState(){ var state = xmldoc.readyState; result_str += messages[state-1] + "<BR>"; } </script>
<BODY onLoad="startParse('notepad.xml')"> <DIV id="xmlMessages"></DIV> </BODY>
Другой способ назначить обработчик событий для элемента - это использование атрибута event тэга <script>:
<XML id="xmlID" src="notes.xml"></XML> <script for="xmlID" event="onreadystatechange"> alert(xmlID.readyState); </script>
DOM совместимые анализаторы
Другим способом представления внутренней структуры документа являются DOM - интерфейсы. Как уже упоминалось, их реализацией занимаются разработчики XML-анализатора, используя для этого возможности конкретного языка программирования. Программисты на Java могут найти эти классы в библиотеке org.w3.dom. Наследуя виртуальные методы DOM интерфейсов, классы анализатора предоставляют приложению стандартный способ манипулирования структурой документа. В свою очередь, приложение, использующее XML-анализатор, может не знать о способе реализации интерфейсов, ему доступна готовая библиотека методов, при помощи которой он может производить поиск нужных фрагментов документа, создавать, удалять и модифицировать его элементы.
Одним из доступных на сегодня DOM-совместимых наборов классов для работы с документами является библиотека com.ibm.dom, входящая в состав XML анализатора xml4j от IBM. Получить ее можно по адресу www.alphaworks.ibm.com. Принцип использования DOM интерфесов по сравнению с IE5 практически не изменился - поменялись только названия объектов и методов. Их краткий обзор представлен в следующей таблице.
Node
Базовый интерфейс для остальных элементов объектной модели XML, представляющий узел дерева структуры документа.
Document
Используется для получения информации о документе и изменения его структуры. Это интерфейс представляет собой корневой элемент XML документа и содержит методы доступа ко всему содержимому документа. При помощи методов объекта Document в программе можно создавать дочерние объекты, представляющие различные конструкции документа (например, createElement - создание элемента, createComment - создание комментария, createTextNode - текстового фрагмента), удалять, перемещать, добавлять объекты (removeChild, replaceChild, insertBefore, ...), перемещаться по дереву элементов(getFirstChild, getLastChild, getNextSibling, getParentNode, getPreviousSibling, ...), получать элементы по их названию (getElementsByTagName, :) и т.д. В объектной модели IE5 этот интерфейс доступен для сценариев на JScript, VB через объект XMLDOMDocument
В следующем примере демонстрируется использование DOM-объектов для вывода содержимого XML документа в двух форматах - в виде дерева элементов и обычной HTML страницы. Немного изменив пример, можно заставить программу сохранять выходной формат в файле и мы получим таким образом обычный XML-HTML конвертор.
/* Пример использования DOM анализатора. Демонстрируется возможность рекурсивного обхода дерева элементов, создание новых элементов, фильтрация элементов (поиска по параметрам) */
import java.io.OutputStreamWriter; import java.io.PrintWriter; import java.io.UnsupportedEncodingException; import java.util.*;
import org.w3c.dom.*;
import org.xml.sax.Parser; import org.xml.sax.SAXException; import org.xml.sax.helpers.ParserFactory;
import com.ibm.xml.parsers.DOMParser;
public class logParser {
static String defaultParser = "com.ibm.xml.parsers.DOMParser"; static String urlLog; static Document xmldoc = null; static PrintWriter out;
/* Конструктор нашего класса- обработчика. В нем создается выходной поток для печати */
public logParser(String url){ urlLog = url;
try { out = new PrintWriter(new OutputStreamWriter(System.out, "koi8-r")); } catch (UnsupportedEncodingException e) { System.err.println(e.toString()); }
}
public void parseDoc(){ parseDoc(defaultParser); }
/* Создание класса анализатора, обрабтка им XML-документа и создание объектной модели документа */
public void parseDoc(String parserName){
try { Parser parser = ParserFactory.makeParser(parserName); parser.parse(urlLog);
// Получение указателя на корневой элемент документа xmldoc = ((DOMParser)parser).getDocument();
} catch (Exception e) { System.err.println(e.toString()); } }
//========================================================================== // Вывод содержимого документа в виде форматированного списка XML- элементов //========================
public void viewLogAsXML(){
try {
viewLogAsXML(xmldoc,"");
} catch (Exception e) { System.out.println(e.toString()); } out.flush();
}
/* Рекурсивный обход элементов документа, начиная с указанного элемента node. */
public void viewLogAsXML(Node node,String offs){
if (node == null) { return; } int type = node.getNodeType(); // Получение информации о типе текущего узла switch (type) { /* Если текщий узел - корневой элемент документа */
case Node.DOCUMENT_NODE: { out.println("<?xml version=\"1.0\" encoding=\"koi-8\"?>"); viewLogAsXML(((Document)node).getDocumentElement(),offs); out.flush(); break; }
/* Если текщий узел - элемент */
case Node.ELEMENT_NODE: { out.print(offs+"<"); // Печать названия элемента out.print(node.getNodeName()); // Получение списка атрибутов текущего элемента
NamedNodeMap attrs = node.getAttributes(); Node attr; for (int i = 0; i < attrs.getLength(); i++) { attr = attrs.item(i); out.print(' '); out.print(attr.getNodeName()+"=\""+attr.getNodeValue()+"\""); } out.println('>');
// Получение списка дочерних элементов NodeList children = node.getChildNodes();
// Если у текщего элемента есть дочерние, то выводим и их
if (children != null) { int len = children.getLength(); for (int i = 0; i < len; i++) { viewLogAsXML(children.item(i),offs+" "); } } break; }
/* Если текщий узел - текстовый */ case Node.TEXT_NODE: { out.println(offs+node.getNodeValue()); break; }
} // Печать закрывающего тэга элемента if (type == Node.ELEMENT_NODE) { out.print(offs+"</"); out.print(node.getNodeName()); out.println('>'); }
}
//======================================================= // Вывод в формате HTML //=====================
/* Вызов рекурсивного обходчика */
public void viewLog(){
// Header viewAsHTML("All log records:");
try {
// Вывод содержимого viewLog(null);
} catch (Exception e) { System.out.println(e.toString()); }
// Header viewAsHTML();
}
/* Печать только сообщений об ошибках */
public void viewErrors(){
// Header viewAsHTML("Log errors:");
try { // Вывод содержимого viewLog("error"); } catch (Exception e) { System.out.println(e.toString()); } // Footer viewAsHTML();
}
/* Рекурсивный обход элементов, у которых атрибут type равен заданному. */
public int viewLog(String type){
int i=0; int elemNum=0; int messageCount=0; Element elem; NodeList elements;
elements = xmldoc.getElementsByTagName("event"); if(elements==null) System.out.println("Empty element collection");
elemNum = elements.getLength();
if (type == null) {
for (i = 0; i < elemNum; i++) { if(elements.item(i)==null) System.out.println("Empty element"); viewLogMessage((Element)elements.item(i)); } messageCount=elemNum;
} else { for (i = 0; i < elemNum; i++) { elem = (Element)elements.item(i);
if(elem.getAttribute("type")==type){ messageCount++; viewLogMessage(elem); }
} } return messageCount; }
/* Печать заголовка таблицы */
public void viewAsHTML(String title){ out.println("<html>"); out.println("<head><title>Log parser sample</title></head>"); out.println("<body><br><b>"+title+"</b><hr>"); out.println("<table cellspacing=\"2\" cellpadding=\"2\" border=\"1\" width=\"600\">"); out.println("<tr bgcolor=\"silver\"><th>IP</th><th>Date</th><th>Method</th><th>Request</th><th>Response</th></tr>"); }
/* Печать комментариев к таблице */
public void viewAsHTML(){ Date d = new Date(); String date = new String(""+d.getHours()+":"+d.getMinutes()+":"+d.getSeconds()); out.println("</table><hr>generated by logParser at <i>"+date+"</i><br></body></html>"); out.flush(); }
/* Форматированный вывод содержимого элемента event */
public void viewLogMessage(Element elem){
/* Получение текста внутри элемента - обращаемся к первому дочернему узлу (им должен оказаться текст) и получаем его значение, используя метод getNodeValue() интерфейса Node */
String str_from=(elem.getElementsByTagName("ip-from")).item(0).getFirstChild().getNodeValue(); String str_method=(elem.getElementsByTagName("method")).item(0).getFirstChild().getNodeValue(); String str_to=(elem.getElementsByTagName("url-to")).item(0).getFirstChild().getNodeValue(); String str_result=(elem.getElementsByTagName("response")).item(0).getFirstChild().getNodeValue();
out.println("<tr><td>"+str_from+"</td><td>"+elem.getAttribute("date")+"</td><td>"+str_method+"</td><td>"+str_to+"</td><td>"+str_result+"</td></tr>");
}
//======================================================= // Модификация дерева элементов //=============================
public void logMessage(String result, String datetime, String method, String ipfrom, String urlto, String response){
if(xmldoc==null) return;
Element root = xmldoc.getDocumentElement(); Element log_elem = xmldoc.createElement("event"); log_elem.setAttribute("result",result); log_elem.setAttribute("date",datetime);
Element elem; Text elem_value;
elem = xmldoc.createElement("method"); elem_value = xmldoc.createTextNode(method); elem.appendChild(elem_value); log_elem.appendChild(elem);
elem = xmldoc.createElement("ip-from"); elem_value = xmldoc.createTextNode(ipfrom); elem.appendChild(elem_value); log_elem.appendChild(elem);
elem = xmldoc.createElement("url-to"); elem_value = xmldoc.createTextNode(urlto); elem.appendChild(elem_value); log_elem.appendChild(elem);
elem = xmldoc.createElement("response"); elem_value = xmldoc.createTextNode(response); elem.appendChild(elem_value); log_elem.appendChild(elem);
root.appendChild(log_elem); }
//======================================================= // Пример использования методов класса logParser //==============================================
public static void main(String argv[]) {
/* Создание объекта анализатора. В качестве параметра ему передается название документа(можно и через командную строку, конечно...) */
logParser log_file = new logParser("log.xml"); log_file.parseDoc(); // Анализ документа
if (argv.length == 0) { // Что с ним делать log_file.viewLogAsXML(); System.exit(0); }
for (int i = 0; i < argv.length; i++) { String arg = argv[i];
if (arg.startsWith("-")) { if (arg.equals("-vx")) { log_file.viewLogAsXML(); break; } if (arg.equals("-va")) { log_file.viewLog(); break; } if (arg.equals("-ve")) { log_file.viewErrors(); break; }
if (arg.equals("-h")) { usage(); } } }
log_file.logMessage("success","12","GET","127.0.0.1","./index.html","200"); log_file.viewLogAsXML();
} private static void usage() {
System.err.println("usage: java logParser (options)"); System.err.println(); System.err.println("options:"); System.err.println(" -vx View result as XML tree (default)"); System.err.println(" -va View all messages as HTML page"); System.err.println(" -ve View only errors as HTML page"); System.err.println(" -h View help ");
}
}
Комментарии
Более подробные комментарии, файлы приложений и результатов их работы можно найти по адресу www.mrcpk.nstu.ru/xml/
Назад | Содержание
Использование Java XML-обработчиков
Internet Explorer, несмотря на мощную встроенную поддержку XML, сегодня далеко не единственное средство, которое можно использовать для работы с новым языком. Обработкой XML документа на стороне клиента или сервера может также заниматься любой другой анализатор XML-документов, который конвертирует их в обычную HTML страницу или извлекает из нее информацию для других приложений.
Что такое XML Parser?
Любой XML-процессор, являясь, по сути, транслятором языка разметки, может быть разбит на несколько модулей, отвечающих за лексический, синтаксический и семантический анализ содержимого документа. Понятно, что если бы мы были вынуждены каждый раз писать все эти блоки самостоятельно, необходимость в XML как в таковом бы отпала - основное его преимущество, как уже упоминалось ранее, заключается в стандартном способе извлечения информации из документа. Синтаксически правильно составленный XML-документ может быть разобран любым универсальным XML анализатором, и нашему XML-обработчику остается лишь использовать полученные на его выходе "чистые" данные (прошедшие синтаксический анализ) - интерпретировать содержимое документа, в соответствии с его DTD-описанием или схемами данных.
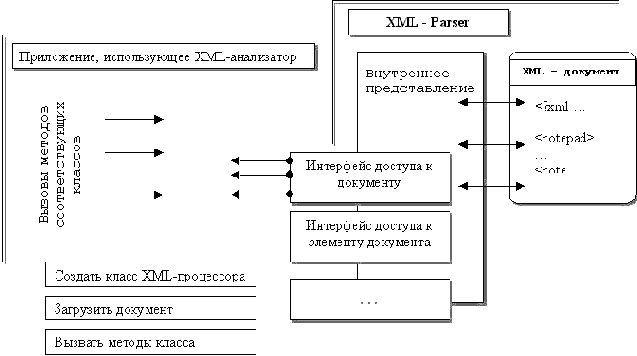
Рис. 2 Иллюстрация механизма доступа к содержимому XML-документа при помощи интерфейсов анализатора
Конечно, синтаксический анализатор может быть довольно легко реализован и самостоятельно, например, в Perl, с его мощными возможностями обработки регулярных выражений. Но в общем случае такой "ручной" способ является довольно нетривиальной задачей, требующей некоторых усилий и является дополнительным источником ошибок. Поэтому применение универсальных XML-анализаторов может существенно облегчить жизнь разработчикам, тем более, что уже сегодня количество свободно доступных программ такого рода довольно велико.
В функции современного XML-процессора обычно входит получение общих сведений о документе, извлечение информации о его структуре и построения некоторой абстрактной объектной модели данных, представляющей эту структуру. По способу проверки разбираемых документов универсальные программы-анализаторы делятся на два типа: верифицирующие, способные обнаружить DTD-описания грамматики языка и использовать их для проверки документа на семантическую корректность; и неверифицирующие, не осуществляющие такой проверки.
Описывая разобранный XML-документ, универсальная программа-анализатор должна представить его структуру в виде упорядоченной модели данных, для доступа к которой используется какая-то станадртная, описанная в соответствующей спецификации библиотека классов - интерфейсов XML документа. На сегодняшний день существует два подхода к их построению: собыйтийный - Simple API for XML, SAX и объектно-ориентированный - DOM(Document Object Model). Рассмотрим их использование на конкретных примерах.
Что такое SAX
Сегодня стандартным интерфейсом для большинства универсальных XML-анализаторов является событийно-ориентированное API SAX - Simple API for XML.
Термин событийно-ориентированный является ключевым в этом определении и объясняет способ использования SAX. Каждый раз, когда при разборе XML документа анализатор оказывается в каком-то новом состоянии - обнаруживает какую-либо синтаксическую конструкцию XML-документа (элемент, символ, шаблон, и т.д.), фиксирует начало, конец объявлений элементов документа, просматривает DTD-правила или находит ошибку, он воспринимает его как произошедшее событие и вызывает внешнюю процедуру - обработчик этого события. Информация о содержимом текущей конструкции документа передается ему в качестве параметров функции. Обработчик события - это какой-то объект приложения, который выполняет необходимые для обработки полученной из XML информации действия и осуществляет таким образом непосредственный разбор содержимого. После завершения этой функции управление опять передается XML-анализатору и процесс разбора продолжается.
Реализацией этого механизма в Java SAX 1.0 является библиотека классов org.xml.sax (их можно получить, например, с узла: www.megginson.com, но обычно эти классы включаются в состав XML -анализатора). Наследуя клссы SAX-совместимого анализатора, мы получаем универсальный доступ к XML документу при помощи классов, содержимое и механизм использование которых приведено в соответствующем описании.
Последовательный разбор XML-документа SAX-обработчиком обычно производится по следующей схеме (более подробное описание приведено ниже):
загрузить документ, установить обработчики событий, начать просмотр его содержимого (если есть DTD-описания, то - их разбор);
найдено начало документа (его корневой, самый первый элемент) - вызвать виртуальную функцию- обработчик события startDocument;
каждый раз, когда при разборе будет найден открывающий тэг элемента вызывается обработчик-функция startElement. В качестве параметров ей передаются название элемента и список его атрибутов;
найдено содержимое элемента - передать его соответствующему обработчику - characters, ignorableWhitespace,processingInstruction и т.д.;
если внутри текущего элемента есть подэлементы, то эта процедура повторяется;
найден закрывающий тэг элемента - обработать событие endElement();
найден закрывающий тэг корневого элемента -обработать событие endDocument;
если в процессе обработки были обнаружены ошибки, то анализатором вызываются обработчики предупреждений (warning), ошибок (error) и критических ошибок обработчика (fatalError).
Ссылка на объект класса обработчика событий может передаваться объекту XML-анализатора при помощи следующих функций:
parser.setDocumentHandler(event_class); // - обработчик событий документа
parser.setEntityResolver(event_class); // - обработчик событий загрузки DTD-описаний
parser.setDTDHandler(event_class); // - обработчик событий при анализе DTD-описаний
parser.setErrorHandler(event_class); // - обработчик чрезвычайных ситуаций
Здесь event_class - объект созданного нами ранее класса.
Краткое описание некоторых из объектов-обработчиков событий приведено в следующей таблице:
Объект DocumentHandler
| startDocument() | Начало документа |
|
endDocument() |
Конец документа |
|
startElement (String name, AttributeList atts) |
Начало элемента. Функции передается название элемента(открывающий тэг) и список его атрибутов. |
|
endElement (String name) |
Конец элемента |
|
characters (char[] cbuf, int start, int len) |
Обработка массива текстовых символов |
|
ignorableWhitespace (char[] cbuf, int start, int len) |
Необрабатываемые символы |
|
processingInstruction (String target, String data) |
Обработка инструкций XML-анализатора) |
| warning (SAXParseException e) | Получение сообщения о "несерьезной" ошибке. Пдробная информация содержится в передаваемом объекте класса SAXParseException |
|
error (SAXParseException e) |
Сообщение об ошибке |
|
fatalError (SAXParseException e) |
Сообщение о критической ошибке |
Для демонстрции использования этих методов рассмотрим небольшой пример обработчика регистрационного XML-документа (его структура описана в примере 2 первого раздела статьи). Java-приложение выводит содержимое документа и информацию о его структуре, путь к документу задается в командной строке. Для компилирования потребуется JDK 1.1.4 и классы SAX, находящиеся либо в текущем пакете, либо вместе с другими классами в classes.zip.
import java.io.OutputStreamWriter; import java.io.PrintWriter; import java.io.UnsupportedEncodingException;
import com.ibm.xml.parsers.DOMParser;
import org.xml.sax.Parser; import org.xml.sax.SAXException; import org.xml.sax.SAXParseException; import org.xml.sax.AttributeList; import org.xml.sax.HandlerBase; import org.xml.sax.helpers.ParserFactory;
class saxParser extends HandlerBase{
private PrintWriter out;
private int elements; private int attributes; private int characters; private int ignorableWhitespace; private String url;
public saxParser(String url_str) {
url = url_str;
try { out = new PrintWriter(new OutputStreamWriter(System.out, "koi8-r")); } catch (UnsupportedEncodingException e) { }
}
//======================================================= // Обработчики событий. Методы интерфейса DocumentHandler //========================
// Начало документа public void startDocument() {
// Статистика elements = 0; attributes = 0; characters = 0; ignorableWhitespace = 0;
// Процессорные инструкции
out.println("<?xml version=\"1.0\" encoding=\"UTF-8\"?>");
}
// Конец документа public void endDocument() {
out.flush();
}
// Встретился открывающий тэг элемента //
public void startElement(String name, AttributeList attrs) {
elements++; if (attrs != null) { attributes += attrs.getLength(); }
// Печать тэга элемента вместе со списком его атрибутов, например, <elem id="48"> out.print('<'); out.print(name); if (attrs != null) { int len = attrs.getLength(); for (int i = 0; i < len; i++) { out.print(' '); out.print(attrs.getName(i)); out.print("=\""); out.print(attrs.getValue(i)); out.print('"'); } } out.println('>');
}
// Встретился закрывающий тэг элемента
public void endElement(String name) {
out.println("</"+name+">");
}
// Текстовые символы
public void characters(char ch[], int start, int length) {
characters += length;
out.println(new String(ch, start, length));
}
// Необрабатываемые символы(например, содержимое секции CDATA)
public void ignorableWhitespace(char ch[], int start, int length) {
characters(ch, start, length);
}
// Инструкции XML-процессору
public void processingInstruction (String target, String data) {
out.print("<?"); out.print(target); if (data != null && data.length() > 0) { out.print(' '); out.print(data); } out.print("?>");
}
//=================================================== // Методы интерфейса ErrorHandler //===============================
// Последнее предупреждение public void warning(SAXParseException ex) { System.err.println("Warning at "+ ex.getLineNumber()+" . "+ ex.getColumnNumber()+" - "+ ex.getMessage()); }
// Произошла ошибка public void error(SAXParseException ex) { System.err.println("Error at {"+ ex.getLineNumber()+" . "+ ex.getColumnNumber()+" - "+ ex.getMessage()); }
// Такие ошибки исправить уже нельзя public void fatalError(SAXParseException ex) throws SAXException { System.err.println("Fatal error at {"+ ex.getLineNumber()+" . "+ ex.getColumnNumber()+" - "+ ex.getMessage()); throw ex; }
//======================================================= // Вывести информацию о документе //===============================
public void printInfo() {
System.out.println();
System.out.println("Документ "+url+" был успешно обработан");
System.out.println("Элементов : "+elements); System.out.println("Атрибутов : "+attributes); System.out.println("Символов : "+characters);
}
}
//======================================================= // Обработка XML документа //========================
public class saxSample{
public static void main(String argv[]) {
try { saxParser sample = new saxParser(argv[0]);
Parser parser = ParserFactory.makeParser("com.ibm.xml.parsers.SAXParser"); parser.setDocumentHandler(sample); parser.setErrorHandler(sample);
parser.parse(argv[0]); sample.printInfo(); } catch (Exception e) { e.printStackTrace(System.err); }
}
}
обработчика является создание объекта из
Первым шагом в процессе построения XML- обработчика является создание объекта из класса анализатора (в нашем случае это классы из паекета com.ibm.xml.parsers). Для этого можно использовать класс ParserFactory, входящий в org.xml.sax.helpers:
import org.xml.sax.*; ... Parser parser = ParseFactory.createParser(); ...
Затем следует определить обработчики возникающих в процессе разбора XML-документа событий. Приложению необязательно устанавливать все обработчики сразу - в классе HandlerBase все события могут обрабатываться "по умолчанию". Более подробную информацию по использованию SAX-анализаторов можно найти в примерах приложений в пакетах анализатора или на сервере www.megginson.com. Комментарии, файлы приложений и результатов их работы можно найти по адресу www.mrcpk.nstu.ru/xml/
Назад | Содержание | Вперед
Обход дерева элементов
Для работы со списком элементов в объектной модели XML-анализатора Microsoft предназначены специальные объекты: XMLDOMNode - представляющий узел дерева и XMLDOMNodeList - список узлов, поддерево. Их описание приведено в таблице.
Просмотр списка элементов документа всегда начинается с получения нужного поддерева. Для этого у объекта XMLDOMNode используется методы childNodes, selectNodes или getElementsByTagName, возвращающие объект XMLDOMNodeList. Количество элементов этом поддереве можно узнать при помощи свойства length.
Вот, например, как будет выглядеть процедура рекурсивного просмотра документа произвольной структуры:
<SCRIPT language="JavaScript"> var result_str = "<hr/>"; var docobj = new ActiveXObject("Microsoft.XMLDOM");
function printElements(){ docobj.load("music.xml"); viewNode(docobj.documentElement); xmlTree.innerHTML = result_str; }
function viewNode(node){ var childnodes = curNode.childNodes.length; result_str+=" "+curNode.nodeName+"<br/>"; for(var i=0;i<childnodes;i++){ viewNode(curNode.childNodes.item(i)); } } </SCRIPT>
<BODY onLoad="printElements()"> <DIV id="xmlTree"></DIV> </BODY> </HTML>
Навигация по документу осуществляется обычным перебором массива элементов в цикле for или при помощи методf nextNode. И в том и в другом случае мы сначала выбираем нужное поддерево, а затем обрабатываем его элементы. Необходимо заметить также, что в XMLDOMNodeList отражаются все изменения, вносимые в структуру XML-документа, и информация в результате будет всегда актуальной.
Обработка ошибок
Информация об обнаруженных в результате разбора XML-документа ошибках передается сценарию через объект XMLDOMParseError. Ссылку на него возвращает метод parseError объекта XMLDOMDocument. Узнать о типе ошибки можно по ее коду, содержащемся в свойстве errorCode (если разбор закончился успешно, то значение errorCode равно 0). При помощи свойств filepos, line, linepos, reason, srcText и url можно получить полную информацию о причине появления ошибки и ее местонахождении.
<SCRIPT language="JavaScript"> var docobj; var result_str = "<hr/>";
function view(){ docobj = new ActiveXObject("Microsoft.XMLDOM"); docobj.load("music.xml");
if (docobj.parseError.errorCode != 0){ xmlTree.innerHTML=reportParseError(docobj.parseError); return; } xmlTree.innerHTML = docobj.xml; }
function reportParseError(error){ error_str = "<H4>Ошибка при загрузке документа '" + error.url + "'</H4>" + "<p><font color='red'>" + error.reason + "</font></p>"; if (error.line > 0) error_str += "<H5>" + "Строка " + error.line + ", символ " + error.linepos + "\n" + error.srcText + "</H4>"; return error_str;
}
</script> <BODY onLoad="startParse()"> <DIV id="xmlTree"></DIV> </BODY> </HTML> ...
Поиск элемента
Поиск нужного элемента или поддерева осуществляется при помощи методов selectNode и selectSingleNode (то же что и selectNode, только возвращает первый найденный элемент). В качестве параметров им необходимо указать строку XSL запроса (образец поиска - XSL pattern).
Синтаксис языка запросов очень гибок и является одним из самых мощных механизмов в XSL - при помощи них можно осуществлять поиск элемента по названию, значению атрибутов, содержанию, учитывая вложенность и положение в дереве элементов. Наиболее ярко все эти возможности демонстрируются при обработке XML-документов стилевыми таблицами XSL , когда мы можем выделять из общего дерева необходимые нам элементы и применять к ним специальные форматирующие инструкции.
Внешне язык XSL запросов немного напоминает обычный способ определения пути к ресурсу в файловой системе - список узлов дерева, разделенных символом /. Для указания на текущий элемент используется символ "." , на родительский - "..", для выделения всех дочерних элементов - символ "*", для выделения элемента, расположенного просто "ниже" по дереву(не важно на каком уровне вложенности) - "//".
Вот примеры простых XSL шаблонов:
"/music-collection" - корневой элемент
"bards/" - возвращает дочерние элементы для элемента bards
"authors-list//" - список всех элементов, вложенных в authors-list
"author[@id]" - список элементов author, в котором определен атрибут id
"author[@id=2]" - элемент author, в котором значение атрибута id равно двум
"author[address]" - список элементов author, которые содержат хотя бы один элемент address
"author[address or city]" - список элементов author, содержащих элементы address или city
Условие на значение в запросе должно заключаться в символы "[" и "]". Для выбора значения атрибута в условии указывается символ @.
Применяя к XML- документу различные шаблоны поиска, можно осуществлять сложные манипуляции с его содержимым, динамически изменяя объем отображаемой пользователю информации в зависимости от производимых им действий (например, динамическая сортировка, отображение подчиненных таблиц и т.д.) Более подробное описание XSL-таблиц будет приведено в одной из следующих статей.
Назад | Содержание | Вперед
Сохранение XML документа.
Созданное в памяти компьютера объектное дерево можно сохранить в текстовый файл, используя метод save:
xmlobj.save ("menu.xml");
Кроме этого, XML-документ можно сохранить в другом XMLDOMDOcument объекте, передав в качестве аргумента функции ссылку на него.
Создание объекта документа
Работа с содержимым XML документа в DOM начинается с создания объекта, реализующего методы класса Document. В IE5 этим объектом является XMLDOMDocument. Создание объекта из сценариев осуществляется при помощи стандартных методов new ActiveXObject(JScript) и CreateObject:
<script language="JScript"> var docobj = new ActiveXObject("Microsoft.XMLDOM"); ...
и
<script language="VBScript"> Dim docobj Set docobj = CreateObject("Microsoft.XMLDOM"). ...
Если данные включаются в документ в виде DSO-объектов, то для доступа к документу можно также использовать объектную модель HTMLстраницы, получая ссылку на XML-документ по идентификаторам соответствующих тэгов:
<XML id="source" src="source-file.xml"></XML> <XML id="style" src="style-file.xsl"></XML> <SCRIPT FOR="window" EVENT="onload"> xslArea.innerHTML = source.transformNode(style.XMLDocument); </SCRIPT> ... <DIV id="xslArea"></DIV>
Первым способом создаются объекты при "ручной"загрузке нового документа. Если же мы хотим получить доступ к данным, встроенным в страницу при помощи тэгов xml или object, то используется второй способ.
Объектной переменной XMLDOMDocument также можно присвоить ссылку на другой объект созданного раннее документа:
docobj.documentElement = otherobj;
использующие Dynamic HTML для создания
Разработчики, использующие Dynamic HTML для создания динамических HTML страниц, видимо, оценят новые возможности по управлению информацией, появившейся с включением в Internet Explorer 5 поддержки DOM Level1 и стилевых таблиц XSL.
HTML-документы давно уже стали привычным форматом для представления информации в Web. Но, к сожалению, их содержимое практически не описывается тэгами и единственное, что может делать с данными броузер, это форматировать их и выводить на экран. Передаваемая клиенту информация в виде HTML страницы доступна для пользователя лишь в том виде, в котором она была сформирована на стороне сервера и практически невозможно динамическое изменение данных в зависимости от текущих потребностей пользователя. Впервые попытка хранения информации независимо от форматирующих ее тэгов была сделана в спецификации Dynamic HTML для IE 4 - в объектную модель броузера были добавлены т.н. объекты источников данных (Data Source Object - DSO). Эти объекты позволяли динамически "назначать" информацию для тех или иных фрагментов HTML документа(например, таблицам), которую затем отображал броузер, и являлись, по сути, "островками данных" для моря остальных форматирующих тэгов документа. Следующим шагом в этом направлении стало появление нового тэга <xml> и включение в объектную модель Internet Explorer новых объектов доступа к XML-данным.
Говоря об объектной модели броузера необходимо уточнить, что в данном случае имеется в виду интерфейс доступа к содержимому документа для сценариев, а вовсе не часть программного обеспечения броузера. Некоторые интерфейсы доступны для других приложений и являются, по сути, COM-интерфейсами, некоторые могут использоваться только внутри. Для нас не важно, как представлены объекты в программной модели броузера - мы будем рассматривать объектную модель как набор объектов, их методов и событий, доступных для сценария внутри страницы.
Из внутренних сценариев HTML страницы обращение к методам объекта данных выглядит также, как и для любого другого элемента документа - при помощи его идентификатора или по индексу в коллекции классов страницы. Вот например, как можно это сделать через JScript (версия JavaScript от Microsoft):
<xml ID="xmlNotes" src="notes.xml"></xml> <script language=JAVASCRIPT> var node_value = xmlNotes.document.all("xmlNotes").XMLDocument.nodeValue; var document_text = xmlNotes.documentElement.text; </script>
При этом ссылка на элемент данных HTML страницы в сценарии автоматически предоставляет нам доступ к объектной модели XML документа, создаваемой обработчиком в памяти компьютера сразу после загрузки документа.
В настоящий момент поддержка XML в IE5 реализована, практически, в на трех вариантах. Во-первых, это возможность загрузки XML документа, так же, как загружается обычная HTML страница. Он будет нормально обработан броузером и отображен в виде дерева содержащихся в нем элементов.
Во-вторых, XML документы можно форматировать при помощи стилевых таблиц XSL. Стилевые таблицы позволяют управлять процессом отображения элемента на экране броузера, меняя в зависимости от его типа и месторасположения в документе используемые для этого форматирующие тэги. Кроме того, стилевые таблицы могут использоваться также и для поиска нужных фрагментов внутри документа, выводя по желанию пользователя отдельные его части независимо от остального содержимого. XSL инструкции в Internet Explorer 5.0 позволяют "фильтровать" и обрабатывать сложные XML документы, со множеством рекурсивно вложенных, сложноподчиненных элементов с нефиксированным набором атрибутов и строгими требованиями к порядку их определения внутри документа.
В-третьих, доступ к XML-данным возможен из сценариев внутри страницы, имеющих доступ практически к любому элементу документа через соответствующие объекты. Использование Dynamic HTML представляет собой наиболее гибкий и мощный способ формирования динамически изменяемой информации на стороне клиента. Структурированные данные XML-документа могут загружаться в страницу при помощи тэгов <xml>, <object> или <script>, в которых указывается либо адрес документа, либо непосредственно сами XML-элементы:
<xml ID="xmlNotes1" src="notes.xml"></xml> ... <xml ID="xmlNotes2"> <notepad> <note id="5"> <text>Очень важная информация</text> </note> </notepad> </xml> ... <script language="xml" ID="xmlNotes3"> <notepad id="6"> <note> <text>Очень важная информация</text> </note> </notepad> </script> ... <script language=JAVASCRIPT> var root_node = document.all.("SCRIPT").XMLDocument; </script>
Возможны комбинации всех этих подходов - загрузка и обработка XML документа в сценариях через методы объектов DOM; включение стилевых таблиц в страницу при помощи тэга <xml>, их модификация в соответствии с запросами пользователя, назначение XSL-стилей для XML-документов прямо из сценариев, включение фрагментов скриптов непосредственно в XML документы при помощи блока CDATA.
Internet Explorer DOM
В настоящий момент Microsoft Internet Explorer является первым броузером, поддерживающим спецификацию DOM Level 1. Для сценариев на стороне клиента доступно множество объектов для работы с XML-документом. Полное их описание является темой отдельной статьи, здесь же рассмотрим лишь самые важные из них, объекты XMLDOMDocument, XMLDOMNode, XMLDOMNodeList, представляющие интерфейс для доступа ко всему документу, отдельным его узлам и поддеревьям соответственно. Также рассмотрим объект XMLDOMParseError, предоставляющий необходимую для отладки информацию о произошедших ошибках анализатора (т.к. его методы, к сожалению, на первых шагах используются очень часто). Описание дается по материалам официального руководства, расположенного на сервере Microsoft: msdn.microsoft.com/xml/, и является упрощенным и сокращенным его вариантом, поэтому если приведенных в таблице сведений будет недостаточно, нужно обратиться к первоисточнику.
| Объект XMLDOMNode |
| Объект XMLDOMNode, реализующий базовый DOM интерфейс Node, предназначен для манипулирования с отдельным узлом дерева документа. Его свойства и методы позволяют получать и изменять полную информацию о текущем узле - его тип (является ли текущий узел элементом, комментарием, текстом и т.д.), название, полное название (вместе с Namespace префиксом), его содержимое, список дочерних элементов и т.д. |
| Свойства |
NODE_ELEMENT (1) - элемент
NODE_ATTRIBUTE (2) - атрибут
NODE_TEXT (3) - текст
NODE_CDATA_SECTION (4) - область CDATA
NODE_ENTITY_REFERENCE (5) - объект ссылки на "макроподстановки"
NODE_ENTITY (6) - объект ссылки на т.н. "подстановочые символы" - entity"
NODE_PROCESSING_INSTRUCTION (7) - область инструкций XML процессору
NODE_COMMENT (8) - комментарий
NODE_DOCUMENT (9) - корневой элемент документа
NODE_DOCUMENT_TYPE (10) - описание типа документа, задаваемое тэгом <!DOCTYPE>
NODE_DOCUMENT_FRAGMENT (11) - фрагмент XML-документа - несвязанное поддерево
NODE_NOTATION (12) - DTD нотация.
Свойство доступно только для чтения.
| Объект XMLDOMDocument |
| Представляет верхний уровень объектной иерархии и содержит методы для работы с документом: его загрузки, анализа, создания в нем элементов, атрибутов, комментариев и т.д. . Многие свойства и методы этого объекта реализованы также в рассмотренном выше класса Node, т.к. документ может быть рассмотрен как корневой узел с вложенными в него поддеревьями. |
| Свойства |
LOADING (1) - находится в процессе загрузки документа
LOADED (2) - загрузка завершена, но объектная модель документа еще не создана
INTERACTIVE (3) - объектная модель создана(все элементы документа разобраны, установлены их связи и атрибуты) но доступна пока только для чтения
COMPLETED (4) - с ошибками или без, но документ разобран
Для получения своевременной информации о текущем состоянии анализатора можно воспользоваться обработчиком событий onreadystatechange
Только для чтения.
| Объект XMLDOMNodeList |
| Представляет собой список узлов - поддеревья и содержит методы, при помощи которых можно организовать процедуру обхода дерева. |
| Свойства |
| Объект XMLDOMParserError |
| Объект позволяет получить всю необходимую информацию об ошибке, произошедшей в ходе разбора документа. Все свойства этого объекта доступны только для чтения. |
| Свойства |
Приведем некоторые примеры использования объектной модели.
Загрузка XML-документа
Все необходимые манипуляции с XML документом осуществляются после его загрузки и создания дерева элементов. Загрузка может осуществляться либо при помощи указателя на соответствующий ресурс: docobj.load("http://myserver/xml/notes.xml"), либо "на лету", при помощи метода loadXML, которому в качестве параметра передается строка- отрывок XML документа:
docobj.loadXML("<recipe><step id='1'>Насыпать чай</step><step id='2'>Залить кипятком </step> <step id='3'>Вылить</step></recipe>");
