ЧТО ТАКОЕ XML
Сегодня XML может использоваться в любых приложениях, которым нужна структурированная информация - от сложных геоинформационных систем, с гигантскими объемами передаваемой информации до обычных "однокомпьютерных" программ, использующих этот язык для описания служебной информации. При внимательном взгляде на окружающий нас информационный мир можно выделить множество задач, связанных с созданием и обработкой структурированной информации, для решения которых может использоваться XML:
В первую очередь, эта технология может оказаться полезной для разработчиков сложных информационных систем, с большим количеством приложений, связанных потоками информации самой различной структурой. В этом случае XML - документы выполняют роль универсального формата для обмена информацией между отдельными компонентами большой программы. XML является базовым стандартом для нового языка описания ресурсов, RDF, позволяющего упростить многие проблемы в Web, связанные с поиском нужной информации, обеспечением контроля за содержимым сетевых ресурсов, создания электронных библиотек и т.д. Язык XML позволяет описывать данные произвольного типа и используется для представления специализированной информации, например химических, математических, физических формул, медицинских рецептов, нотных записей, и т.д. Это означает, что XML может служить мощным дополнением к HTML для распространения в Web "нестандартной" информации. Возможно, в самом ближайшем будущем XML полностью заменит собой HTML, по крайней мере, первые попытки интеграции этих двух языков уже делаются (спецификация XHTML).
XML-документы могут использоваться в качестве промежуточного формата данных в трехзвенных системах. Обычно схема взаимодействия между серверами приложений и баз данных зависит от конкретной СУБД и диалекта SQL, используемого для доступа к данным. Если же результаты запроса будут представлены в некотором универсальном текстовом формате, то звено СУБД, как таковое, станет "прозрачным" для приложения. Кроме того, сегодня на рассмотрение W3C предложена спецификация нового языка запросов к базам данных XQL, который в будущем может стать альтернативой SQL. Информация, содержащаяся в XML-документах, может изменяться, передаваться на машину клиента и обновляться по частям. Разрабатываемые спецификации XLink и Xpointer поволят ссылаться на отдельные элементы документа, c учетом их вложенности и значений атрибутов. Использование стилевых таблиц (XSL) позволяет обеспечить независимое от конкретного устройства вывода отображение XML- документов. XML может использоваться в обычных приложениях для хранения и обработки структурированных данных в едином формате.
Поверхностное описание языка можно найти в статье "Язык XML - практическое введение". Напомню лишь в общих словах, что XML-документ представляет собой обычный текстовый файл, в котором при помощи специальных маркеров создаются элементы данных, последовательность и вложенность которых определяет структуру документа и его содержание. Основным достоинством XML документов является то, что при относительно простом способе создания и обработки (обычный текст может редактироваться любым тестовым процессором и обрабатываться стандартными XML анализаторами), они позволяют создавать структурированную информацию, которую хорошо "понимают" компьютеры.
ИСПОЛЬЗОВАНИЕ JAVA XML- ОБРАБОТЧИКОВ
Internet Explorer, несмотря на мощную встроенную поддержку XML, сегодня далеко не единственное средство, которое можно использовать для работы с новым языком. Обработкой XML документа на стороне клиента или сервера может также заниматься любой другой анализатор XML-документов, который конвертирует их в обычную HTML страницу или извлекает из нее информацию для других приложений.
DOM СОВМЕСТИМЫЕ АНАЛИЗАТОРЫ
Другим способом представления внутренней структуры документа являются DOM - интерфейсы. Как уже упоминалось, их реализацией занимаются разработчики XML-анализатора, используя для этого возможности конкретного языка программирования. Программисты на Java могут найти эти классы в библиотеке org.w3.dom. Наследуя виртуальные методы DOM интерфейсов, классы анализатора предоставляют приложению стандартный способ манипулирования структурой документа. В свою очередь, приложение, использующее XML-анализатор, может не знать о способе реализации интерфейсов, ему доступна готовая библиотека методов, при помощи которой он может производить поиск нужных фрагментов документа, создавать, удалять и модифицировать его элементы.
Одним из доступных на сегодня DOM-совместимых наборов классов для работы с документами является библиотека com.ibm.dom, входящая в состав XML анализатора xml4j от IBM. Получить ее можно по адресу http://www.sinor.ru/www.alphaworks.ibm.com. Принцип использования DOM интерфесов по сравнению с IE5 практически не изменился - поменялись только названия объектов и методов. Их краткий обзор представлен в следующей таблице.
Node
Базовый интерфейс для остальных элементов объектной модели XML, представляющий узел дерева структуры документа.
Document
Используется для получения информации о документе и изменения его структуры. Это интерфейс представляет собой корневой элемент XML документа и содержит методы доступа ко всему содержимому документа. При помощи методов объекта Document в программе можно создавать дочерние объекты, представляющие различные конструкции документа (например, createElement - создание элемента, createComment - создание комментария, createTextNode - текстового фрагмента), удалять, перемещать, добавлять объекты (removeChild, replaceChild, insertBefore, ...), перемещаться по дереву элементов(getFirstChild, getLastChild, getNextSibling, getParentNode, getPreviousSibling, ...), получать элементы по их названию (getElementsByTagName, :) и т.д. В объектной модели IE5 этот интерфейс доступен для сценариев на JScript, VB через объект XMLDOMDocument
Element
Представляет элемент документа, определяя методы доступа к его названию(getTagName, getElementsByTagName), атрибутам (getAttribute, getAttributeNode, setAttribute, removeAttribute, : ) и дочерним элементам(appendChild, getChildNodes, getFirstChild, ...).
Attr
Интерфейс, представляющий атрибут элемента. Имеет методы для получения(getValue) и установления(setValue) значения атрибута. Хотя согласно синтаксису XML атрибуты должны назначаться только элементам, в DOM возможно их создание любым объектом, наследующим интерфейс Node. Поэтому можно создать атрибут для документа, который будет находится в списке атрибутов, но не принадлежать ни одному из его элементов.
CharacterData
Интерфейс, предоставляющий доступ к текстовым данным документа. В XML документе к этому типу данных относятся комментарии, текстовое содержимое элементов, секции CDATA. При помощи методов этого интерфейса можно добавлять, удалять, редактировать данные(appendData, deleteData, replaceData, setData), получать размер области текста (getLength) и извлекать текстовое содержимое(getData, substringData, ...)
Comments
Интерфейс для доступа к тексту комментариев
Text
Представляет текстовое содержимое элемента
CDATASection
Интерфейс, представляющий секции CDATA - фрагментов документа, заключенные в символы "[[" и "]]>", которые не обрабатываются XML-анализатором и поэтому могут содержать символы, "запрешенные" в спецификации XML. В эту область можно, к примеру, помещать стилевые таблицы или JavaScript сценарии, используемые при отображении HTML страницы.
ProcessingInstruction
Предоставляет доступ к т.н. области "инструкций процессора", данные из которой используются XML-анализатором при разборе документа. Доступ к этим данным возможен при помощи методо getData, setData и getTarget
Notation
Определяет инструкцию DTD описания. Для получения ее идентификаторов используются методы getPublicId и getSystemId . DOM Level 1 не поддерживает прямого доступа к DTD декларациям по записи и сейчас они доступны лишь для чтения (при помощи параметра nodeName интерфейса Node)
В следующем примере демонстрируется использование DOM-объектов для вывода содержимого XML документа в двух форматах - в виде дерева элементов и обычной HTML страницы. Немного изменив пример, можно заставить программу сохранять выходной формат в файле и мы получим таким образом обычный XML-HTML конвертор. /* Пример использования DOM анализатора. Демонстрируется возможность рекурсивного обхода дерева элементов, создание новых элементов, фильтрация элементов (поиска по параметрам) */
import java.io.OutputStreamWriter; import java.io.PrintWriter; import java.io.UnsupportedEncodingException; import java.util.*;
import org.w3c.dom.*;
import org.xml.sax.Parser; import org.xml.sax.SAXException; import org.xml.sax.helpers.ParserFactory;
import com.ibm.xml.parsers.DOMParser;
public class logParser {
static String defaultParser = "com.ibm.xml.parsers.DOMParser"; static String urlLog; static Document xmldoc = null; static PrintWriter out;
/* Конструктор нашего класса- обработчика. В нем создается выходной поток для печати */
public logParser(String url){ urlLog = url;
try { out = new PrintWriter(new OutputStreamWriter(System.out, "koi8-r")); } catch (UnsupportedEncodingException e) { System.err.println(e.toString()); }
}
public void parseDoc(){ parseDoc(defaultParser); }
/* Создание класса анализатора, обрабтка им XML-документа и создание объектной модели документа */
public void parseDoc(String parserName){
try { Parser parser = ParserFactory.makeParser(parserName); parser.parse(urlLog);
// Получение указателя на корневой элемент документа xmldoc = ((DOMParser)parser).getDocument();
} catch (Exception e) { System.err.println(e.toString()); } }
//========================================================================== // Вывод содержимого документа в виде форматированного списка XML- элементов //========================
public void viewLogAsXML(){
try {
viewLogAsXML(xmldoc,"");
} catch (Exception e) { System.out.println(e.toString()); } out.flush();
}
/* Рекурсивный обход элементов документа, начиная с указанного элемента node. */
public void viewLogAsXML(Node node,String offs){
if (node == null) { return; } int type = node.getNodeType(); // Получение информации о типе текущего узла switch (type) { /* Если текщий узел - корневой элемент документа */
case Node.DOCUMENT_NODE: { out.println("<?xml version=\"1.0\" encoding=\"koi-8\"?>"); viewLogAsXML(((Document)node).getDocumentElement(),offs); out.flush(); break; }
/* Если текщий узел - элемент */
case Node.ELEMENT_NODE: { out.print(offs+"<"); // Печать названия элемента out.print(node.getNodeName()); // Получение списка атрибутов текущего элемента
NamedNodeMap attrs = node.getAttributes(); Node attr; for (int i = 0; i < attrs.getLength(); i++) { attr = attrs.item(i); out.print(' '); out.print(attr.getNodeName()+"=\""+attr.getNodeValue()+"\""); } out.println('>');
// Получение списка дочерних элементов NodeList children = node.getChildNodes();
// Если у текщего элемента есть дочерние, то выводим и их
if (children != null) { int len = children.getLength(); for (int i = 0; i < len; i++) { viewLogAsXML(children.item(i),offs+" "); } } break; }
/* Если текщий узел - текстовый */ case Node.TEXT_NODE: { out.println(offs+node.getNodeValue()); break; }
} // Печать закрывающего тэга элемента if (type == Node.ELEMENT_NODE) { out.print(offs+"</"); out.print(node.getNodeName()); out.println('>'); }
}
//======================================================= // Вывод в формате HTML //=====================
/* Вызов рекурсивного обходчика */
public void viewLog(){
// Header viewAsHTML("All log records:");
try {
// Вывод содержимого viewLog(null);
} catch (Exception e) { System.out.println(e.toString()); }
// Header viewAsHTML();
}
/* Печать только сообщений об ошибках */
public void viewErrors(){
// Header viewAsHTML("Log errors:");
try { // Вывод содержимого viewLog("error"); } catch (Exception e) { System.out.println(e.toString()); } // Footer viewAsHTML();
}
/* Рекурсивный обход элементов, у которых атрибут type равен заданному. */
public int viewLog(String type){
int i=0; int elemNum=0; int messageCount=0; Element elem; NodeList elements;
elements = xmldoc.getElementsByTagName("event"); if(elements==null) System.out.println("Empty element collection");
elemNum = elements.getLength();
if (type == null) {
for (i = 0; i < elemNum; i++) { if(elements.item(i)==null) System.out.println("Empty element"); viewLogMessage((Element)elements.item(i)); } messageCount=elemNum;
} else { for (i = 0; i < elemNum; i++) { elem = (Element)elements.item(i);
if(elem.getAttribute("type")==type){ messageCount++; viewLogMessage(elem); }
} } return messageCount; }
/* Печать заголовка таблицы */
public void viewAsHTML(String title){ out.println("<html>"); out.println("<head><title>Log parser sample</title></head>"); out.println("<body><br><b>"+title+"</b><hr>"); out.println("<table cellspacing=\"2\" cellpadding=\"2\" border=\"1\" width=\"600\">"); out.println("<tr bgcolor=\"silver\"><th>IP</th><th>Date</th><th>Method</th><th>Request</th><th>Response</th></tr>"); }
/* Печать комментариев к таблице */
public void viewAsHTML(){ Date d = new Date(); String date = new String(""+d.getHours()+":"+d.getMinutes()+":"+d.getSeconds()); out.println("</table><hr>generated by logParser at <i>"+date+"</i><br></body></html>"); out.flush(); }
/* Форматированный вывод содержимого элемента event */
public void viewLogMessage(Element elem){
/* Получение текста внутри элемента - обращаемся к первому дочернему узлу (им должен оказаться текст) и получаем его значение, используя метод getNodeValue() интерфейса Node */
String str_from=(elem.getElementsByTagName("ip-from")).item(0).getFirstChild().getNodeValue(); String str_method=(elem.getElementsByTagName("method")).item(0).getFirstChild().getNodeValue(); String str_to=(elem.getElementsByTagName("url-to")).item(0).getFirstChild().getNodeValue(); String str_result=(elem.getElementsByTagName("response")).item(0).getFirstChild().getNodeValue();
out.println("<tr><td>"+str_from+"</td><td>"+elem.getAttribute("date")+"</td><td>"+str_method+"</td><td>"+str_to+"</td><td>"+str_result+"</td></tr>");
}
//======================================================= // Модификация дерева элементов //=============================
public void logMessage(String result, String datetime, String method, String ipfrom, String urlto, String response){
if(xmldoc==null) return;
Element root = xmldoc.getDocumentElement(); Element log_elem = xmldoc.createElement("event"); log_elem.setAttribute("result",result); log_elem.setAttribute("date",datetime);
Element elem; Text elem_value;
elem = xmldoc.createElement("method"); elem_value = xmldoc.createTextNode(method); elem.appendChild(elem_value); log_elem.appendChild(elem);
elem = xmldoc.createElement("ip-from"); elem_value = xmldoc.createTextNode(ipfrom); elem.appendChild(elem_value); log_elem.appendChild(elem);
elem = xmldoc.createElement("url-to"); elem_value = xmldoc.createTextNode(urlto); elem.appendChild(elem_value); log_elem.appendChild(elem);
elem = xmldoc.createElement("response"); elem_value = xmldoc.createTextNode(response); elem.appendChild(elem_value); log_elem.appendChild(elem);
root.appendChild(log_elem); }
//======================================================= // Пример использования методов класса logParser //==============================================
public static void main(String argv[]) {
/* Создание объекта анализатора. В качестве параметра ему передается название документа(можно и через командную строку, конечно...) */
logParser log_file = new logParser("log.xml"); log_file.parseDoc(); // Анализ документа
if (argv.length == 0) { // Что с ним делать log_file.viewLogAsXML(); System.exit(0); }
for (int i = 0; i < argv.length; i++) { String arg = argv[i];
if (arg.startsWith("-")) { if (arg.equals("-vx")) { log_file.viewLogAsXML(); break; } if (arg.equals("-va")) { log_file.viewLog(); break; } if (arg.equals("-ve")) { log_file.viewErrors(); break; }
if (arg.equals("-h")) { usage(); } } }
log_file.logMessage("success","12","GET","127.0.0.1","./index.html","200"); log_file.viewLogAsXML();
} private static void usage() {
System.err.println("usage: java logParser (options)"); System.err.println(); System.err.println("options:"); System.err.println(" -vx View result as XML tree (default)"); System.err.println(" -va View all messages as HTML page"); System.err.println(" -ve View only errors as HTML page"); System.err.println(" -h View help ");
}
}
Комментарии
Более подробные комментарии, файлы приложений и результатов их работы можно найти по адресу http://www.sinor.ru/www.mrcpk.nstu.ru
Что такое DTD?
Итак, мы создали XML документ и убедились, что набор используемых при этом тэгов позволяет осуществлять любые манипуляции с нашей информацией. В таком случае, для того, чтобы утвердить правила нашего нового языка, т.е. список допустимых элементов, их возможное содержимое и атрибуты, мы должны создать DTD - определения (на момент написания статьи спецификация схем данных для XMLдокументов еще не утверждена и пока DTD являются единственным стандартным способом описания грамматики).
Более подробно о DTD можно прочитать в предыдущей статье, посвященной XML, здесь приведеy лишь небольшой пример для нашего XML-документа: <?xml encoding="koi8-r"?> <!ELEMENT log (event)+> <!ELEMENT event (ip-from,method,uri-to,result)> <!ELEMENT method (#PCDATA)> <!ELEMENT ip-from (#PCDATA)> <!ELEMENT url-to (#PCDATA)> <!ELEMENT response (#PCDATA)> <!ATTLIST event result CDATA #IMPLIED date CDATA #IMPLIED>
Сохраните этот файл под именем log.dtd и включите в XML-документ новую строчку:
<!--DOCTYPE log SYSTEM "log.dtd"-->
Теперь верифицирующий XML-анализатор при обработке документа будет сверять порядок определения элементов и их атрибутов с тем, как это указано у нас в DTD-нотациях и в случае нарушения внутренней структуры (которая определяет "семантику" документа) выдавать сообщение об ошибке.
Что такое Namespaces?
Как уже упоминалось ранее, вся прелесть использования XML заключается в возможности придумывания собственных тэгов, названия которых наиболее полно соответствовали бы предназначению. Но фантазия и словарный запас людей не безграничны, поэтому нет абсолютно никакой гарантии того, что данные вами имена элементов не будут использованы кем-то еще. До тех пор, пока в вашем приложении обрабатываются только собственные XML-документы, никаких проблем не возникнет. Но вполне возможна ситуация, когда один и тот же документ будет содержать информацию для нескольких обработчиков одновременно. В этом случае названия некоторых элементов или их атрибутов могут совпасть, что вызовет либо ошибку в XML- анализаторе, либо неправильное представление документа. Например, в нашем случае, элемент event вполне мог бы быть использован для записи других событий и обрабатываться другим приложением.
Чтобы исправить эту ситуацию, мы должны определить уникальные названия элементов и их атрибутов, "дописывая" к их обычным именам некоторый универсальный неповторяющийся префикс. Для этого применяется механизм Namespaces (спецификация Namespaces была официально утверждена W3C в январе 1999 года и сегодня является частью стандарта XML). Согласно этой спецификации, для определения "области действия" тэга ( на самом деле этот термин, широко используемый в обычных языках программирования, неприменим в XML, потому что как такового множества, на котором могла бы быть построена "область", внутри структурированного XML документа нет) необходимо определить уникальный атрибут, описывающий название элемента, по которому анализатор документа сможет определить, к какой группе имен оно относится (Namespace идентификаторы могут применяться для описания уникальных названий как элементов, так и их атрибутов). В нашем последнем примере это может быть сделано так:
<?xml version="1.0" encoding="koi8-r"?>
<!--DOCTYPE log SYSTEM "log.dtd"-->
<log xmlns:xlg="www.mrcpk.nstu.ru/xml/ar/4/">
<xlg:event xlg:date=" 27/May/1999:02:32:46 " xlg:result="success">
<ip-from> 195.151.62.18 </ip-from>
<method>GET</method>
<url-to> /misc/</url-to>
<response>200</response>
</event>
<xlg:event date=" 27/May/1999:02:41:47 " result="success">
<ip-from> 195.209.248.12 </ip-from>
<method>GET</method>
<url-to> /soft.htm</url-to>
<response>200</response>
</event>
</log>
Уникальность атрибуту имени обеспечивает использование в качестве его значения некоторых универсальных идентификаторов ресурсов (например, URI или ISBN) .
Полную информацию по использованию Namespace вы можете найти в официальной спецификации этого стандарта. В дальнейшем, для упрощения примеров, мы будем Namespace - описания пропускать.
Что такое SAX
Сегодня стандартным интерфейсом для большинства универсальных XML-анализаторов является событийно-ориентированное API SAX - Simple API for XML.
Термин событийно-ориентированный является ключевым в этом определении и объясняет способ использования SAX. Каждый раз, когда при разборе XML документа анализатор оказывается в каком-то новом состоянии - обнаруживает какую-либо синтаксическую конструкцию XML-документа (элемент, символ, шаблон, и т.д.), фиксирует начало, конец объявлений элементов документа, просматривает DTD-правила или находит ошибку, он воспринимает его как произошедшее событие и вызывает внешнюю процедуру - обработчик этого события. Информация о содержимом текущей конструкции документа передается ему в качестве параметров функции. Обработчик события - это какой-то объект приложения, который выполняет необходимые для обработки полученной из XML информации действия и осуществляет таким образом непосредственный разбор содержимого. После завершения этой функции управление опять передается XML-анализатору и процесс разбора продолжается.
Реализацией этого механизма в Java SAX 1.0 является библиотека классов org.xml.sax (их можно получить, например, с узла: , но обычно эти классы включаются в состав XML -анализатора). Наследуя клссы SAX-совместимого анализатора, мы получаем универсальный доступ к XML документу при помощи классов, содержимое и механизм использование которых приведено в соответствующем описании.
Последовательный разбор XML-документа SAX-обработчиком обычно производится по следующей схеме (более подробное описание приведено ниже):
загрузить документ, установить обработчики событий, начать просмотр его содержимого (если есть DTD-описания, то - их разбор); найдено начало документа (его корневой, самый первый элемент) - вызвать виртуальную функцию- обработчик события startDocument; каждый раз, когда при разборе будет найден открывающий тэг элемента вызывается обработчик-функция startElement. В качестве параметров ей передаются название элемента и список его атрибутов; найдено содержимое элемента - передать его соответствующему обработчику - characters, ignorableWhitespace,processingInstruction и т.д.; если внутри текущего элемента есть подэлементы, то эта процедура повторяется; найден закрывающий тэг элемента - обработать событие endElement(); найден закрывающий тэг корневого элемента -обработать событие endDocument; если в процессе обработки были обнаружены ошибки, то анализатором вызываются обработчики предупреждений (warning), ошибок (error) и критических ошибок обработчика (fatalError).
Ссылка на объект класса обработчика событий может передаваться объекту XML-анализатора при помощи следующих функций:
parser.setDocumentHandler(event_class); // - обработчик событий документа
parser.setEntityResolver(event_class); // - обработчик событий загрузки DTD-описаний
parser.setDTDHandler(event_class); // - обработчик событий при анализе DTD-описаний
parser.setErrorHandler(event_class); // - обработчик чрезвычайных ситуаций
Здесь event_class - объект созданного нами ранее класса.
Краткое описание некоторых из объектов-обработчиков событий приведено в следующей таблице:
Объект DocumentHandler
startDocument() |
Начало документа |
endDocument() |
Конец документа |
startElement (String name, AttributeList atts) |
Начало элемента. Функции передается название элемента(открывающий тэг) и список его атрибутов. |
endElement (String name) |
Конец элемента |
characters (char[] cbuf, int start, int len) |
Обработка массива текстовых символов |
ignorableWhitespace (char[] cbuf, int start, int len) |
Необрабатываемые символы |
processingInstruction (String target, String data) |
Обработка инструкций XML-анализатора) |
warning (SAXParseException e) |
Получение сообщения о "несерьезной" ошибке. Пдробная информация содержится в передаваемом объекте класса SAXParseException |
error (SAXParseException e) |
Сообщение об ошибке |
fatalError (SAXParseException e) |
Сообщение о критической ошибке |
import com.ibm.xml.parsers.DOMParser;
import org.xml.sax.Parser; import org.xml.sax.SAXException; import org.xml.sax.SAXParseException; import org.xml.sax.AttributeList; import org.xml.sax.HandlerBase; import org.xml.sax.helpers.ParserFactory;
class saxParser extends HandlerBase{
private PrintWriter out;
private int elements; private int attributes; private int characters; private int ignorableWhitespace; private String url;
public saxParser(String url_str) {
url = url_str;
try { out = new PrintWriter(new OutputStreamWriter(System.out, "koi8-r")); } catch (UnsupportedEncodingException e) { }
}
//======================================================= // Обработчики событий. Методы интерфейса DocumentHandler //========================
// Начало документа public void startDocument() {
// Статистика elements = 0; attributes = 0; characters = 0; ignorableWhitespace = 0;
// Процессорные инструкции
out.println("<?xml version=\"1.0\" encoding=\"UTF-8\"?>");
}
// Конец документа public void endDocument() {
out.flush();
}
// Встретился открывающий тэг элемента //
public void startElement(String name, AttributeList attrs) {
elements++; if (attrs != null) { attributes += attrs.getLength(); }
// Печать тэга элемента вместе со списком его атрибутов, например, <elem id="48"> out.print('<'); out.print(name); if (attrs != null) { int len = attrs.getLength(); for (int i = 0; i < len; i++) { out.print(' '); out.print(attrs.getName(i)); out.print("=\""); out.print(attrs.getValue(i)); out.print('"'); } } out.println('>');
}
// Встретился закрывающий тэг элемента
public void endElement(String name) {
out.println("</"+name+">");
}
// Текстовые символы
public void characters(char ch[], int start, int length) {
characters += length;
out.println(new String(ch, start, length));
}
// Необрабатываемые символы(например, содержимое секции CDATA)
public void ignorableWhitespace(char ch[], int start, int length) {
characters(ch, start, length);
}
// Инструкции XML-процессору
public void processingInstruction (String target, String data) {
out.print("<?"); out.print(target); if (data != null && data.length() > 0) { out.print(' '); out.print(data); } out.print("?>");
}
//=================================================== // Методы интерфейса ErrorHandler //===============================
// Последнее предупреждение public void warning(SAXParseException ex) { System.err.println("Warning at "+ ex.getLineNumber()+" . "+ ex.getColumnNumber()+" - "+ ex.getMessage()); }
// Произошла ошибка public void error(SAXParseException ex) { System.err.println("Error at {"+ ex.getLineNumber()+" . "+ ex.getColumnNumber()+" - "+ ex.getMessage()); }
// Такие ошибки исправить уже нельзя public void fatalError(SAXParseException ex) throws SAXException { System.err.println("Fatal error at {"+ ex.getLineNumber()+" . "+ ex.getColumnNumber()+" - "+ ex.getMessage()); throw ex; }
//======================================================= // Вывести информацию о документе //===============================
public void printInfo() {
System.out.println();
System.out.println("Документ "+url+" был успешно обработан");
System.out.println("Элементов : "+elements); System.out.println("Атрибутов : "+attributes); System.out.println("Символов : "+characters);
}
}
//======================================================= // Обработка XML документа //========================
public class saxSample{
public static void main(String argv[]) {
try { saxParser sample = new saxParser(argv[0]);
Parser parser = ParserFactory.makeParser("com.ibm.xml.parsers.SAXParser"); parser.setDocumentHandler(sample); parser.setErrorHandler(sample);
parser.parse(argv[0]); sample.printInfo(); } catch (Exception e) { e.printStackTrace(System.err); }
}
}
Комментарии
Первым шагом в процессе построения XML- обработчика является создание объекта из класса анализатора (в нашем случае это классы из паекета com.ibm.xml.parsers). Для этого можно использовать класс ParserFactory, входящий в org.xml.sax.helpers: import org.xml.sax.*; ... Parser parser = ParseFactory.createParser(); ...
Затем следует определить обработчики возникающих в процессе разбора XML-документа событий. Приложению необязательно устанавливать все обработчики сразу - в классе HandlerBase все события могут обрабатываться "по умолчанию". Более подробную информацию по использованию SAX-анализаторов можно найти в примерах приложений в пакетах анализатора или на сервере www.megginson.com. Комментарии, файлы приложений и результатов их работы можно найти по адресу
Что такое XML Parser?
Любой XML-процессор, являясь, по сути, транслятором языка разметки, может быть разбит на несколько модулей, отвечающих за лексический, синтаксический и семантический анализ содержимого документа. Понятно, что если бы мы были вынуждены каждый раз писать все эти блоки самостоятельно, необходимость в XML как в таковом бы отпала - основное его преимущество, как уже упоминалось ранее, заключается в стандартном способе извлечения информации из документа. Синтаксически правильно составленный XML-документ может быть разобран любым универсальным XML анализатором, и нашему XML-обработчику остается лишь использовать полученные на его выходе "чистые" данные (прошедшие синтаксический анализ) - интерпретировать содержимое документа, в соответствии с его DTD-описанием или схемами данных.
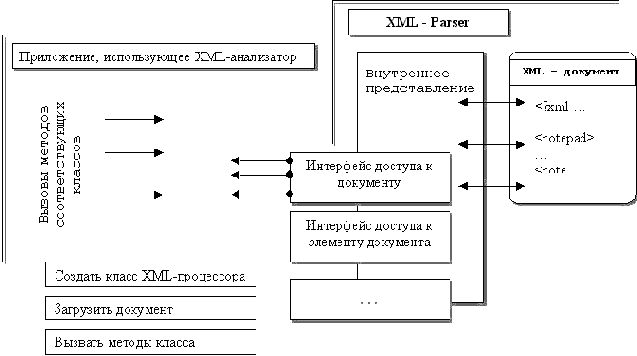
Рис. 2 Иллюстрация механизма доступа к содержимому XML-документа при помощи интерфейсов анализатора
Конечно, синтаксический анализатор может быть довольно легко реализован и самостоятельно, например, в Perl, с его мощными возможностями обработки регулярных выражений. Но в общем случае такой "ручной" способ является довольно нетривиальной задачей, требующей некоторых усилий и является дополнительным источником ошибок. Поэтому применение универсальных XML-анализаторов может существенно облегчить жизнь разработчикам, тем более, что уже сегодня количество свободно доступных программ такого рода довольно велико.
В функции современного XML-процессора обычно входит получение общих сведений о документе, извлечение информации о его структуре и построения некоторой абстрактной объектной модели данных, представляющей эту структуру. По способу проверки разбираемых документов универсальные программы-анализаторы делятся на два типа: верифицирующие, способные обнаружить DTD-описания грамматики языка и использовать их для проверки документа на семантическую корректность; и неверифицирующие, не осуществляющие такой проверки.
Описывая разобранный XML-документ, универсальная программа-анализатор должна представить его структуру в виде упорядоченной модели данных, для доступа к которой используется какая-то станадртная, описанная в соответствующей спецификации библиотека классов - интерфейсов XML документа. На сегодняшний день существует два подхода к их построению: собыйтийный - Simple API for XML, SAX и объектно-ориентированный - DOM(Document Object Model). Рассмотрим их использование на конкретных примерах.
Для чего нужен новый язык разметки?
Когда осенью 1991 года Интернет впервые услышал позывные новой технологии, название которой легко уместилось в три буквы, почти никто не мог представить себе, что завоевания ее окажутся настолько глобальными. Сегодня для многих неискушенных пользователей слово Интернет прочно ассоциируется с WWW и с уст специалистов не сходит тема будущего информационных систем и влияния на это будущее всемирной сетевой паутины.
Популярность World Wide Web и неотъемлемой ее части, HTML, безусловно, стала причиной повышенного внимания к системам гипертекстовой разметки документов. Хотя понятие гипертекста было введено В.Бушем еще в 1945 году и, начиная с 60-х годов стали появляться первые приложения, использующие гипертекстовые данные, всплеск активности вокруг этой технологии начался лишь тогда, когда возникла реальная необходимость в механизме объединения множества информационных ресурсов, обеспечения возможности создания, просмотра нелинейного текста. И примером реализации этого механизма послужила паутина WWW.
Язык разметки документов - это набор специальных инструкций, называемых тэгами, предназначенных для формирования в документах какой-либо структуры и определения отношений между различными элементами этой структуры. Тэги языка, или, как их иногда называют, управляющие дескрипторы, в таких документах каким-то образом кодируются, выделяются относительно основного содержимого документа и служат в качестве инструкций для программы, производящей показ содержимого документа на стороне клиента. В самых первых системах для обозначения этих команд использовались символы “<” и “>”, внутри которых помещались названия инструкций и их параметры. Сейчас такой способ обозначения тэгов является стандартным.
Использование гипертекстовой разбивки текстового документа в современных информационных системах во многом связано с тем, что гипертекст позволяет создавать механизм нелинейного просмотра информации. В таких системах данные представляются не в виде непрерывного потока текстовой информации, а набором взаимосвязанных компонентов, переход по которым осуществляется при помощи гиперссылок.
Самый популярный на сегодняшний день язык гипертекстовой разметки – HTML, был создан специально для организации информации, распределенной в сети Интернет, и является одной из ключевых составляющих технологии WWW. С использованием гипертекстовой модели документа способ представления разнообразных информационных ресурсов в сети стал более упорядочен, а пользователи получили удобный механизм поиска и просмотра нужной информации.
HTML [8]является упрощенной версией стандартного общего языка разметки - SGML (Standart Generalised Markup Language[10]), который был утвержден ISO в качестве стандарта еще в 80-х годах. Этот язык предназначен для создания других языков разметки, он определяет допустимый набор тэгов, их атрибуты и внутреннюю структуру документа. Контроль за правильностью использования дескрипторов осуществляется при помощи специального набора правил, называемых DTD- описаниями(более подробно о DTD мы поговорим чуть позже), которые используются программой клиента при разборе документа. Для каждого класса документов определяется свой набор правил, описывающих грамматику соответствующего языка разметки. С помощью SGML можно описывать структурированные данные, организовывать информацию, содержащуюся в документах, представлять эту информацию в некотором стандартизованном формате. Но в виду некоторой своей сложности, SGML использовался, в основном, для описания синтаксиса других языков(наиболее известным из которых является HTML), и немногие приложения работали с SGML- документами напрямую.
Гораздо более простой и удобный, чем SGML, язык HTML позволяет определять оформление элементов документа и имеет некий ограниченный набор инструкций - тэгов, при помощи которых осуществляется процесс разметки. Инструкции HTML, в первую очередь, предназначены для управления процессом вывода содержимого документа на экране программы-клиента и определяют этим самым способ представления документа, но не его структуру. В качестве элемента гипертекстовой базы данных, описываемой HTML, используется текстовый файл, который может легко передаваться по сети с использованием протокола HTTP. Эта особенность, а также то, что HTML является открытым стандартом и огромное количество пользователей имеет возможность применять возможности этого языка для оформления своих документов, безусловно, повлияли на рост популярности HTML и сделали его сегодня главным механизмом представления информации в Web
Однако современные приложения нуждаются не только в языке представления данных на экране клиента, но и в механизме, позволяющем определять структуру документа, описывать содержащиеся в нем элементы. HTML обладает несложным набором команд и вполне успешно справляется с задачей описания текстовой информации и отображением ее на экране программы просмотра- броузера. Однако сами отображаемые данные никак не связаны с теми тэгами, которые используются для форматирования, поэтому у программ-анализаторов нет возможности использовать тэги HTML для поиска нужных нам фрагментов документа. Т.е. встретив, например, такое описание
<font color="red">rose</font>,
программа просмотра будет знать, каким цветом отобразить текст, содержащийся внутри тэгов <font></font> и, вероятно, отобразит его правильно, но ей абсолютно безразлично, в каком месте документа встретился этот тэг, в какие другие тэги заключен текущий фрагмент, существуют ли вложенные в него фрагменты, правильно ли построены отношения между объектами. Такое "безразличие" к структуре документа приводит к тому, что поиск или анализ информации внутри него ничем не будет отличаться от работы со сплошным, не разбитым на элементы текстовым файлом. А это, как известно, не самый эффективный способ работы с информацией.
Другим существенным недостатком HTML можно назвать ограниченность набора его тэгов. DTD- правила для HTML определяют фиксированный набор дескрипторов и поэтому у разработчика нет возможности вводить собственные, специальные тэги. Хотя время от времени появляются новые расширения языка(на сегодняшний день последней версией HTML является HTML 4.0), но долгий путь их стандартизации, сопровождаемый постоянными разногласиями между основными производителями броузеров делают практически невозможной быструю адаптацию языка, его использование для отображения специализированной информации(например, мультимедийной, математических, химических формул и т.д.).
Подводя итог всему сказанному, можно утверждать, что HTML уже сегодня не удовлетворяет в полной мере требованиям, предъявляемым современными разработчиками к языкам подобного рода. И ему на смену был предложен новый язык гипертекстовой разметки, мощный, гибкий, и, одновременно с этим, удобный язык XML. В чем же заключается его достоинства?
XML (Extensible Markup Language[1]) - это язык разметки, описывающий целый класс объектов данных, называемых XML- документами. Этот язык используется в качестве средства для описания грамматики других языков и контроля за правильностью составления документов. Т.е. сам по себе XML не содержит никаких тэгов, предназначенных для разметки, он просто определяет порядок их создания. Таким образом, если, например, мы считаем, что для обозначения элемента rose в документе необходимо использовать тэг <flower>;, то XML позволяет свободно использовать определяемый нами тэг и мы можем включать в документ фрагменты, подобные следующему:
<flower>rose</flower>
Набор тэгов может быть легко расширен. Если, предположим, мы хотим также указать, что описание цветка должно по смыслу идти внутри описания оранжереи, в которой он цветет, то просто задаем новые тэги и выбираем порядок их следования:
<conservatory> <flower>rose</flower> </conservatory>
Если мы хотим посадить туда еще несколько цветочков, то должны внести следующие изменения:
<conservatory> <flower>rose</flower> <flower>tulip</flower> <flower>cactus</flower> </conservatory>
Как видно, сам процесс создания XML документа очень прост и требует от нас лишь базовых знаний HTML и понимания тех задач, которые мы хотим выполнить, используя XML в качестве языка разметки. Таким образом, у разработчиков появляется уникальная возможность определять собственные команды, позволяющие им наиболее эффективно определять данные, содержащиеся в документе. Автор документа создает его структуру, строит необходимые связи между элементами, используя те команды, которые удовлетворяют его требованиям и добивается такого типа разметки, которое необходимо ему для выполнения операций просмотра, поиска, анализа документа.
Еще одним из очевидных достоинств XML является возможность использования его в качестве универсального языка запросов к хранилищам информации. Сегодня в глубинах W3C находится на рассмотрении рабочий вариант стандарта XML-QL(или XQL), который, возможно, в будущем составит серьезную конкуренцию SQL. Кроме того, XML-документы могут выступать в качестве уникального способа хранения данных, который включает в себя одновременно средства для разбора информации и представления ее на стороне клиента. В этой области одним из перспективных направлений является интеграция Java и XML - технологий, позволяющая использовать мощь обеих технологий при построении машинно-независимых приложений, использующих, кроме того, универсальный формат данных при обмене информации.
XML позволяет также осуществлять контроль за корректностью данных, хранящихся в документах, производить проверки иерархических соотношений внутри документа и устанавливать единый стандарт на структуру документов, содержимым которых могут быть самые различные данные. Это означает, что его можно использовать при построении сложных информационных систем, в которых очень важным является вопрос обмена информацией между различными приложениями, работающими в одной системе. Создавая структуру механизма обмена информации в самом начале работы над проектом, менеджер может избавить себя в будущем от многих проблем, связанных с несовместимостью используемых различными компонентами системы форматов данных.
Также одним из достоинств XML является то, что программы-обработчики XML- документов не сложны и уже сегодня появились и свободно распространяются всевозможные программные продукты, предназначенные для работы с XML-документами. XML поддерживается сегодня в Microsoft Internet Explorer 4/0 и в бэта-версиях IE5. Было заявлено о его поддержке в последующих версиях Netscape Communicator, СУБД Oracle, DB-2, в приложениях MS-Office . Все это дает основания предполагать, что, скорее всего, в ближайшем будущем XML станет основным языком обмена информации для информационных систем, заменив собой, тем самым, HTML. На основе XML уже сегодня созданы такие известные специализированные языки разметки, как SMIL, CDF, MathML, XSL, и список рабочих проектов новых языков, находящихся на рассмотрении W3C, постоянно пополняется.
Как выглядит XML-документ?
Если Вы знакомы с HTML, изучение XML не потребует от вас особых усилий. Хотя XML, безусловно, сильно отличается по своим возможностям и предназначению от языка гипертекстовой разметки, оба эти языка являются подмножествами SGML, и, следовательно, наследуют его базовые принципы.
DOCUMENTS TYPE DEFINITIONS (DTD)
4. DOCUMENTS TYPE DEFINITIONS (DTD)
В XML- документах DTD определяет набор действительных элементов, идентифицирует элементы, которые могут находиться в других элементах, и определяет действительные атрибуты для каждого из них. Синтаксис DTD весьма своеобразен и от автора-разработчика требуются дополнительные усилия при создании таких документов(сложность DTD является одной из причин того, что использование SGML, требующего определение DTD для любого документа, не получило столь широкого распространения как, например, HTML). Как уже отмечалось, в XML использовать DTD не обязательно - документы, созданные без этих правил, будут правильно обрабатываться программой-анализатором, если они удовлетворяют основным требованиям синтаксиса XML. Однако контроль за типами элементов и корректностью отношений между ними в этом случае будет полностью возлагаться на автора документа. До тех пор, пока грамматика нашего нового языка не описана, его сможем использовать только мы, и для этого мы будем вынуждены применять специально разработанное программное обеспечение, а не универсальные программы-анализаторы..
В DTD для XML используются следующие типы правил: правила для элементов и их атрибутов, описания категорий(макроопределений), описание форматов бинарных данных. Все они описывают основные конструкции языка - элементы, атрибуты, символьные константы внешние файлы бинарных данных.
Для того, чтобы использовать DTD в нашем документе, мы можем или описать его во внешнем файле и при описании DTD просто указать ссылку на этот файл или же непосредственно внутри самого документа выделить область, в которой определить нужные правила. В первом случае в документе указывается имя файла, содержащего DTD- описания:
<?xml version="1.0" standalone="yes" ?> <! DOCTYPE journal SYSTEM "journal.dtd"> ...
Внутри же документа DTD- декларации включаются следующим образом:
... <! DOCTYPE journal [ <!ELEMENT journal (contacts, issues, authors)> ... ]> ...
В том случае, если используются одновременно внутренние и внешние описания, то программой-анализатором будут сначала рассматриваться внутренние, т.е. их приоритет выше. При проверке документа XML- процессор в первую очередь ищет DTD внутри документа. Если правила внутри документа не определены и не задан атрибут standalone ="yes" , то программа загрузит указанный внешний файл и правила, находящиеся в нем, будут считаны оттуда. Если же атрибут standalone имеет значение "yes", то использование внешних DTD описаний будет запрещено.
Определение элемента
Элемент в DTD определяется с помощью дескриптора !ELEMENT, в котором указывается название элемента и структура его содержимого.
Например, для элемента <flower> можно определить следующее правило:
<!ELEMENT flower PCDATA>
Ключевое слово ELEMENT указывает, что данной инструкцией будет описываться элемент XML. Внутри этой инструкции задается название элемента(flower) и тип его содержимого.
В определении элемента мы указываем сначала название элемента(flower), а затем его модель содержимого - определяем, какие другие элементы или типы данных могут встречаться внутри него. В данном случае содержимое элемента flower будет определяться при помощи специального маркера PCDATA( что означает parseable character data - любая информация, с которой может работать программа-анализатор). Существует еще две инструкции, определяющие тип содержимого: EMPTY,ANY. Первая указывает на то, что элемент должен быть пустым(например, <red/>), вторая - на то, что содержимое элемента специально не описывается.
Последовательность дочерних для текущего элемента объектов задается в виде списка разделенных запятыми названий элементов. При этом для того, чтобы указать количество повторений включений этих элементов могут использоваться символы +,*, ? :
<!ELEMENT issue (title, author+, table-of-contents?)>
В этом примере указывается, что внутри элемента <issue> должны быть определены элементы title, author и table-of-contents, причем элемент title является обязательным элементом и может встречаться лишь однажды, элемент author может встречаться несколько раз, а элемент table-of-contents является опциональным, т.е. может отсутствовать. В том случае, если существует несколько возможных вариантов содержимого определяемого элемента, их следует разделять при помощи символа "|" :
<!ELEMENT flower (PCDATA | title )*>
Символ * в этом примере указывает на то, что определяемая последовательность внутренних элементов может быть повторена несколько раз или же совсем не использоваться.
Если в определении элемента указывается "смешанное" содержимое, т.е. текстовые данные или набор элементов, то необходимо сначала указать PCDATA, а затем разделенный символом "|" список элементов.
Пример корректного XML- документа:
<?xml version="1.0"?> <! DOCTYPE journal [ <!ELEMENT contacts (address, tel+, email?)> <!ELEMENT address (street, appt)> <!ELEMENT street PCDATA> <!ELEMENT appt (PCDATA | EMPTY)*> <!ELEMENT tel PCDATA> <!ELEMENT email PCDATA> ]> ... <contacts> <address> <street>Marks avenue</street> <appt id="4"> </address> <tel>12-12-12</tel> <tel>46-23-62</tel> <email>info@j.com</email> </contacts>
Определение атрибутов
Списки атрибутов элемента определяются с помощью ключевого слова !ATTLIST. Внутри него задаются названия атрибутов, типы их значений и дополнительные параметры. Например, для элемента <article> могут быть определены следующие атрибуты:
<!ATTLIST article id ID #REQUIRED about CDATA #IMPLIED type (actual | review | teach ) 'actual' '' >
В данном примере для элемента article определяются три атрибута: id, about и type, которые имеют типы ID(идентификатор), CDATA и список возможных значений соответственно. Всего существует шесть возможных типов значений атрибута:
CDATA - содержимым документа могут быть любые символьные данные ID - определяет уникальный идентификатор элемента в документе IDREF( IDREFS )- указывает, что значением атрибута должно выступать название(или несколько таких названий, разделенных пробелами во втором случае) уникального идентификатора определенного в этом документе элемента ENTITY( ENTITIES) - значение атрибута должно быть названием(или списком названий, если используется ENTITIES) компонента (макроопределения), определенного в документе NMTOKEN (NMTOKENS) - содержимым элемента может быть только одно отдельное слово(т.е. этот параметр является ограниченным вариантом CDATA) Список допустимых значений - определяется список значений, которые может иметь данный атрибут.
Также в определении атрибута можно использовать следующие параметры:
#REQUIRED - определяет обязательный атрибут, который должен быть задан во всех элементах данного типа #IMPLIED - атрибут не является обязательным #FIXED "значение" - указывает, что атрибут должен иметь только указанное значение, однако само определение атрибута не является обязательным, но в процессе разбора его значение в любом случае будет передано программе-анализатору Значение - задает значение атрибута по умолчанию
Определение компонентов(макроопределений)
Компонент (entity) представляет собой определения, содержимое которых может быть повторно использовано в документе . В других языках программирования подобные элементы называются макроопределениями. Создаются DTD- компоненты при помощи инструкции !ENTITY:
<!ENTITY hello ' Мы рады приветствовать Вас!' >
Программа-анализатор, просматривая в первую очередь содержимое области DTD- определений, обработает эту инструкцию и при дальнейшем разборе документа будет использовать содержимое DTD- компонента в том месте, где будет встречаться его название. Т.е. теперь в документе мы можем использовать выражение &hello; , которое будет заменено на строчку "Мы рады приветствовать Вас"
В общем случае, внутри DTD можно задать три типа макроопределений:
Внутренние макроопределения - предназначены для определения строковой константы, с их помощью можно организовывать ссылки на часто изменяемую информацию, делая документ более читабельным. Внутренние компоненты включаются в документ при помощи амперсанта &
В XML существует пять предустановленных внутренних символьных констант:
< - символ "<" > - символ ">" & - символ "&" ' - символ апострофа "'" " - символ двойной кавычки """
Внешние макроопределения - указывают на содержимое внешнего файла, причем этим содержимым могут быть как текстовые, так и двоичные данные. В первом случае в месте использования макроса будут вставлены текстовые строки, во втором - бинарные данные, которые анализатором не рассматриваются и используются внешними программами
<!ENTITY logotype SYSTEM "/image.gif" NDATA GIF87A>
Макроопределения правил - макроопределения параметров могут использоваться только внутри области DTD и обозначаются специальным символом %, вставляемым перед названием макроса. При этом содержимое компонента будет помещено непосредственно в текст DTD- правила
Например, для следующего фрагмента документа:
<!ELEMENT name (PCDATA)> <!ELEMENT title (PCDATA | name)*> <!ELEMENT author (PCDATA | name)*> <!ELEMENT article (title, author)*> <!ELEMENT book (title, author)*> <!ELEMENT bookstore (book | article)*> <!ELEMENT bookshelf (book | article)*>
можно использовать более короткую форму записи:
<!ELEMENT name (PCDATA)> <! ENTITY %names 'PCDATA | name'> <!ELEMENT article (%names;)*> <!ELEMENT book (%names;)*> <!ENTITY %content 'book | article'> <!ELEMENT bookstore (%content;)*> <!ELEMENT bookshelf (%content;)*>
Макроопределения часто используются для описания параметров в правилах атрибутов. В этом случае появляется возможность использовать одинаковые определения атрибутов для различных элементов:
<!ENTITY %itemattr 'id ID #IMPLIED src CDATA'> <!ENTITY %bookattr "ISDN ID #IMPLIED type CDATA'> <!ENTITY %artattr " size CDATA'> <!ELEMENT book (title, author,content)*> <!ATTLIST book %itemattr %bookattr;> <!ELEMENT article (title, author, content)*> <!ATTLIST article %itemattr %artattr;>
Типизация данных
Довольно часто при создании XML- элемента разработчику требуется определить, данные какого типа могут использоваться в качестве его содержимого. Т.е. если мы определяем элемент <last-modified>10.10.98</last-modified>, то хотим быть уверенными, что в документе в этом месте будет находиться строка, представляющая собой дату, а не число или произвольную последовательность символов. Используя типизацию данных, можно создавать элементы, значения которых могут использоваться, например, в качестве параметров SQL- запросов. Программа клиент в этом случае должна знать, к какому типу данных относится текущее значение элемента и в случае соответствия формирует SQL-запрос.
Если в качестве программы на стороне клиента используется верифицирующий XML-процессор, то информацию о типе можно передавать при помощи специально созданного для этого атрибута элемента, имеющего соответствующее DTD- определение. В процессе разбора программа-анализатор передаст значение этого атрибута клиентскому приложению, которое сможет использовать эту информацию должным образом. Например, чтобы указать, что содержимое элемента должно быть длинным целым, можно использовать следующее DTD- определение:
<!ELEMENT counter (PCDATA)> <!ATTLIST counter data_long CDATA #FIXED "LONG">
Задав атрибуту значение по умолчанию LONG и определив его как FIXED, мы позволили тем самым программе-клиенту получить необходимую информацию о типе содержимого данного элемента, и теперь она может самостоятельно определить соответствие типа этого содержимого указанному в DTD- определении .
Вот пример XML- документа, в котором определяются и используются несколько элементов с различными типами данных:
<!ELEMENT price (PCDATA)> <!ATTLIST price data_currency CDATA #FIXED "CURRENCY"> <!ELEMENT rooms_num (PCDATA)> <!ATTLIST rooms_num data_byte CDATA #FIXED "BYTE"> <!ELEMENT floor (PCDATA)> <!ATTLIST floor data_byte CDATA #FIXED "INTEGER"> <!ELEMENT living_space (PCDATA)> <!ATTLIST living_space data_float CDATA #FIXED "FLOAT"> <!ELEMENT counter (PCDATA)> <!ATTLIST counter data_long CDATA #FIXED "LONG"> <!ELEMENT is_tel (PCDATA)> <!ATTLIST is_tel data_bool CDATA #FIXED "BOOL"> <!ELEMENT house (rooms_num, floor,living_space, is_tel, counter, price)> <!ATTLIST house id ID #REQUIED> ... <house id="0"> <rooms_num>5</rooms_num> <floor>2</floor> <living_space>32.5</living_space> <is_tel>true</is_tel> <counter>18346</counter> <price>34 р. 28 к.</price> </house> ...
Как видно из примера, механизм создания элементов документа при этом нисколько не изменился. Все необходимая для проверки типов данных информация заложена в определения элементов внутри блока DTD.
В заключении хотелось бы отметить, что DTD предоставляет нам весьма удобный механизм осуществления контроля за содержимым документа. На сегодняшний день, практически все программы просмотра документов Интернет используют DTD-правила. Однако это далеко не единственный способ проверки корректности документа. В настоящий момент в W3 консорциуме находится на рассмотрении новый стандарт языка описания структуры документов, называемый схемами данных. Следующий раздел посвящен работе с ними.
Инструментарий
Очевидно, что ручной способ создания структурированной информации не может применяться для наполнения больших информационных узлов. Для этого существуют специальные средства разработки, список которых сегодня постоянно пополняется (их обзор будет приведен в одной из следующих статей). Одним их самых простых и удобных, на мой взгляд, является редактор XML Notepad, получить который можно здесь -msdn.microsoft.com/xml/notepad/intro.asp).
Internet Explorer DOM
В настоящий момент Microsoft Internet Explorer является первым броузером, поддерживающим спецификацию DOM Level 1. Для сценариев на стороне клиента доступно множество объектов для работы с XML-документом. Полное их описание является темой отдельной статьи, здесь же рассмотрим лишь самые важные из них, объекты XMLDOMDocument, XMLDOMNode, XMLDOMNodeList, представляющие интерфейс для доступа ко всему документу, отдельным его узлам и поддеревьям соответственно. Также рассмотрим объект XMLDOMParseError, предоставляющий необходимую для отладки информацию о произошедших ошибках анализатора (т.к. его методы, к сожалению, на первых шагах используются очень часто). Описание дается по материалам официального руководства, расположенного на сервере Microsoft: msdn.microsoft.com/xml/, и является упрощенным и сокращенным его вариантом, поэтому если приведенных в таблице сведений будет недостаточно, нужно обратиться к первоисточнику.
Использование ASP
Доступ к свойствам XML- анализатора возможен также из сценариев ASP(Active Server Pages), выполняющихся на стороне сервера. Если при написании ASP-модуля используется язык VBscript, то для создания объекта, представляющего XML- документ, необходимо включить следующее выражение: Set myxml=Server.CreateObject("msxml")
Однако необходимо учитывать, что в качестве сервера в этом случае надо использовать Web- сервер, поддерживающий ISAPI, и так же на компьютере должны быть установлены или броузер Internet Explorer версии 4 и выше, или зарегистрированный в реестре ActiveX- компонент msxml.
Вот пример использования свойств XML-документа в ASP- программе: <% Set myxml=Server.CreateObject("msxml") myxml.url = "http://localhost/xml/sample1.xml" url=myxml.url Set root=myxml.root version=myxml.version charset=myxml.charset %> <html> <body bgcolor="white"> <center> <table width=80%> <tr> <td align="center" bgcolor="silver">URL</td> <td align="center"><%=url%></td> </tr> <tr> <td align="center" bgcolor="silver">Version</td> <td align="center"><%=version%></td> </tr> <tr> <td align="center" bgcolor="silver">Root element</td> <td align="center"><%=root.tagName%></td> </tr> <tr> <td align="center" bgcolor="silver">Charset</td> <td align="center"><%=charset%></td> </tr> </table> </body> </html>
Создавая msxml- объект при помощи CreateObject, мы в дальнейшем вызываем его методы и свойства привычным нам способом. Отличается лишь способ вставки полученной информации в HTML- страницу - она генерируется не на стороне клиента, а приходит к нему в уже готовом виде.
В заключение хотелось бы отметить, что рассмотренные способы работы с XML- документами могут применяться для отображения их элементов на экране броузера. Не всегда они являются наиболее эффективными для форматирования текста - для каждого нового документа с измененной структурой требуются частично или полностью переписывать обработчик(в следующем разделе мы попробуем использовать для этих же целей стилевые таблицы XSL). Однако использование Java Script позволяет уже сегодня разрабатывать реальные Интернет- приложения, использующие встроенный в броузер клиента анализатор в качестве средства для доступа к структурированной информации XML.
Если на Вашем компьютере установлен
Если на Вашем компьютере установлен броузер Internet Explorer 4 (или более поздняя версия), то Вы можете использовать встроенный в этот броузер XML- анализатор msxml в своих сценариях, написанных на Java Script ил VBScript,. В настоящий момент существуют две его реализации, - одна предназначена для использования в виде написанного на C++ ActiveX- объекта(реализация на базе COM- технологии) другая, написанная на Java, не зависит от платформы. Оба анализатора не сложны, имеют сравнительно небольшой размер - msxml на C++ занимает около 100k, версия на Java - 127k. Анализатор, написанный на C++, в текущей реализации не поддерживает DTD- правил, более компактный и быстрый, чем его Java-версия. Оба они имеют поддержку иностранных языков, т.е. в составе Internet Explorer C++- анализатор работает со всеми языками, "понимаемыми" броузерами, а анализатор на Java - с теми языками, с которыми может работать виртуальная Java-машина.
Т.к. обе версии разрабатывались параллельно, объектная модель, заложенная в основу каждой из них, внешне схожа, поэтому больших сложностей при переходе от одной версии к другой обычно не возникает.
Рассмотрим основные свойства и методы, доступные JavaScript- сценарию в процессе его выполнения на стороне броузера. В наших примерах мы будем использовать XML- анализатор в сценариях Java Script, т.к. этот способ более понятен и быстрее работает. Полное описание C++ интерфейсов анализатора доступны в документации по Internet Client SDK
Объектная модель XML в Internet Explorer 4.0
Перед тем, как использовать свойства и методы анализатора, его необходимо создать. Делается это при помощи стандартного метода, предназначенного для создания ActiveX- объектов: var mydoc = new ActiveXObject("msxml");
Если ActiveX- компонент был зарегистрирован на Вашей машине(или у Вас установлен броузер Internet Explorer 4), то в результате выполнения этой функции переменной mydoc будет присвоен объект, имеющий тип msxml, свойства и методы которого используются в дальнейшем для получения доступа к структуре XML- документа.
В Приложении 2 приведен полный текст сценария JavaScrtipt, выводящего на экран броузера Internet Explorer 4.0 XML- документ, созданный в Приложении 1. Вы можете использовать этот пример и комментарии к нему в качестве еще одного средства для более быстрого понимания принципов использования свойств и методов объектов Microsoft XML и создания собственных сценариев.
Объектная модель XML- анализатора Microsoft может быть представлена в виде следующего набора внутренних объектов: XML Document, XML Element и Element Collection. Объект XML Document содержит свойства и методы, необходимые нам для работы с XML- документом в целом. XML Element отвечает за работу с каждым из элементов XML- документа. Element Collection представляет из себя набор элементов, доступ к которым доступен при помощи имени или порядкового номера. В следующих примерах мы рассмотрим каждый из этих объектов подробнее.
Элементы данных
Элемент - это структурная единица XML- документа. Заключая слово rose в в тэги <flower> </flower> , мы определяем непустой элемент, называемый <flower>, содержимым которого является rose. В общем случае в качестве содержимого элементов могут выступать как просто какой-то текст, так и другие, вложенные, элементы документа, секции CDATA, инструкции по обработке, комментарии, - т.е. практически любые части XML- документа.
Любой непустой элемент должен состоять из начального, конечного тэгов и данных, между ними заключенных. Например, следующие фрагменты будут являться элементами:
<flower>rose</flower> <city>Novosibirsk</city> ,а эти - нет: <rose> <flower> rose
Набором всех элементов, содержащихся в документе, задается его структура и определяются все иерархическое соотношения. Плоская модель данных превращается с использованием элементов в сложную иерархическую систему со множеством возможных связей между элементами. Например, в следующем примере мы описываем месторасположение Новосибирских университетов (указываем, что Новосибирский Университет расположен в городе Новосибирске, который, в свою очередь, находится в России), используя для этого вложенность элементов XML :
<country id="Russia"> <cities-list> <city> <title>Новосибирск</title> <state>Siberia</state> <universities-list> <university id="2"> <title>Новосибирский Государственный Технический Университет</title> <noprivate/> <address URL="www.nstu.ru"/> <description>очень хороший институт</description> </university> <university id="2"> <title>Новосибирский Государственный Университет</title> <noprivate/> <address URL="www.nsu.ru"/> <description>тоже не плохой</description> </university> </universities-list> </city> </cities-list> </country>
Производя в последствии поиск в этом документе, программа клиента будет опираться на информацию, заложенную в его структуру - используя элементы документа. Т.е. если, например, требуется найти нужный университет в нужном городе, используя приведенный фрагмент документа, то необходимо будет просмотреть содержимое конкретного элемента <university>, находящегося внутри конкретного элемента <city>. Поиск при этом, естественно, будет гораздо более эффективен, чем нахождение нужной последовательности по всему документу.
В XML документе, как правило, определяется хотя бы один элемент, называемый корневым и с него программы-анализаторы начинают просмотр документа. В приведенном примере этим элементом является <country>
В некоторых случаях тэги могут изменять и уточнять семантику тех или иных фрагментов документа, по разному определяя одну и ту же информацию и тем самым предоставляя приложению-анализатору этого документа сведения о контексте использования описываемых данных. Например, прочитав фрагмент <city>Holliwood</city> мы можем догадаться, что речь в этой части документа идет о городе, а вот во фрагменте <restaurant>Holliwood</restaurant> - о забегаловке.
В случае, если элемент не имеет содержимого, т.е. нет данных, которые он должен определять, он называется пустым. Примером пустых элементов в HTML могут служить такие тэги HTML, как <br>, <hr>, <img>;. Необходимо только помнить, что начальный и конечные тэги пустого элемента как бы объединяется в один, и надо обязательно ставить косую черту перед закрывающей угловой скобкой (например, <empty/>;)
Комментарии
Комментариями является любая область данных, заключенная между последовательностями символов <!-- и --> Комментарии пропускаются анализатором и поэтому при разборе структуры документа в качестве значащей информации не рассматриваются.
Атрибуты
Если при определении элементов необходимо задать какие-либо параметры, уточняющие его характеристики, то имеется возможность использовать атрибуты эдлемента. Атрибут - это пара "название" = "значение", которую надо задавать при определении элемента в начальном тэге. Пример:
<color RGB="true">#ff08ff</color> <color RGB="false">white</color> или <author id=0>Ivan Petrov</author>
Примером использования атрибутов в HTML является описание элемента <font>:
<font color=”white” name=”Arial”>Black</font>
Cпециальные символы
Для того, чтобы включить в документ символ, используемый для определения каких-либо конструкций языка (например, символ угловой скобки) и не вызвать при этом ошибок в процессе разбора такого документа, нужно использовать его специальный символьный либо числовой идентификатор. Например, < , > " или $(десятичная форма записи),  (шестнадцатеричная) и т.д. Строковые обозначения спецсиволов могут определяться в XML документе при помощи компонентов (entity), о чем мы еще поговорим немного позже.
Директивы анализатора
Инструкции, предназначенные для анализаторов языка, описываются в XML документе при помощи специальных тэгов - <? и ?>;. Программа клиента использует эти инструкции для управления процессом разбора документа. Наиболее часто инструкции используются при определении типа документа (например, <? Xml version=”1.0”?>) или создании пространства имен[11].
CDATA
Чтобы задать область документа, которую при разборе анализатор будет рассматривать как простой текст, игнорируя любые инструкции и специальные символы, но, в отличии от комментариев, иметь возможность использовать их в приложении, необходимо использовать тэги <![CDATA] и ]]>. Внутри этого блока можно помещать любую информацию, которая может понадобится программе- клиенту для выполнения каких-либо действий (в область CDATA, можно помещать, например, инструкции JavaScript). Естественно, надо следить за тем, чтобы в области, ограниченной этими тэгами не было последовательности символов ]].
Что дальше
Мы рассмотрели в общих чертах основные структурные части XML- документа, правила описания элементов XML и теперь можем создать синтаксически правильный XML- документ, содержащий каким-то образом структурированные данные( более подробный пример приведен в Приложении 1.) Однако при этом почти не коснулись вопросов практического применения XML. Как отображать содержимое XML- документов на Web- страницах, осуществлять контроль над правильностью их составления; существуют ли уже сегодня какие-либо удобные средства для создания, анализа и просмотра таких документов? В следующих разделах мы попробуем ответить на эти вопросы.
Как создать XML документ?
Для создания XML документа в простейшем случае вам не понадобится ничего кроме обычного текстового редактора (по мнению многих Web-дизайнеров, лучший инструмент для создания Web-страниц). Вот пример небольшого XML-документа, используемого вместо обычной записной книжки: <?xml version="1.0" encoding="koi-8"?> <notepad> <note id="1" date="12/04/99" time="13:40"> <subject>Важная деловая встреча</subject> <importance/> <text> Надо встретиться с <person id="1625">Иваном Ивановичем</person>, предварительно позвонив ему по телефону <tel>123-12-12</tel> </text> </note> ... <note id="2" date="12/04/99" time="13:58"> <subject>Позвонить домой</subject> <text> <tel>124-13-13</tel> </text> </note> </notepad>
При создании собственного языка разметки вы можете придумывать любые названия элементов, (почти любые, т.к. список допустимых символов ограничен и приведен в спецификации XML), соответствующих контексту их использования. В нашем примере приведен лишь один из многочисленных способ создания структуры дневника. В этом и заключается гибкость и расширяемость XML-производных языков - они создаются разработчиком "на лету", согласно его представлениям о структуре документа, и могут затем использоваться универсальными программами просмотра наравне с любыми другими XML-производными языками, т.к. вся необходимая для синтаксического анализа информация заключена внутри документа.
Создавая новый формат, необходимо учитывать тот факт, что документов, "написанных на XML", не может быть в принципе - в любом случае авторы документа для его разметки используют основанный на стандарте XML (т.н. XML-производный) язык, но не сам XML. Поэтому при сохранении созданного файла можно выбрать для него какое-то подходящее названию расширение (например, noteML).
XML может использоваться вами для создания документов какого-то определенного типа и структурой, необходимой для конкретного приложения. Однако если сфера применения языка оказывается достаточно широкой и он начинает представлять интерес для большого числа разработчиков, то его спецификация вполне может быть представлена на рассмотрение в W3C и после согласования всеми заинтересованными сторонами, утверждена консорциумом в качестве официальной рекомендации.
Надо заметить, что процесс появления новой спецификации очень длителен и сложен. Любой документ, предлагаемый W3C, прежде чем стать стандартом проходит несколько этапов. Сначала пожелания и рекомендации, поступающие от различных компаний, участвующих в его разработке, оформляются в виде принятого к сведению замечания (Note), своеобразного протокола о намерениях. Информация, изложенная в таких документах предназначена только для обсуждения членами консорциума и никто не дает гарантии того, что эти замечания потом станут рекомендацией.
Следующей этапом продвижения документа является рабочий вариант спецификации, который составляет и изменяет в дальнейшем специально созданная рабочая группа (Working Group), в состав которой входят представители заинтересовавшихся идеей компаний. Все изменения, вносимые в этот документ обязательно публикуются на сервере консорциума www.w3.org и до тех пор, пока рабочий вариант не станет рекомендацией, он может служить для разработчиков лишь "путеводной звездой", с которой компания может сверять свои планы, но не должна использовать при разработке ПО.
В том случае, если стороны договорились по всем основным вопросам и существенных изменений в документ больше вносится, рабочий вариант становится Предложенной Рекомендацией и после голосования членами рабочей группы может стать уже Официальной Рекомендаций W3C, что по статусу соответствует стандарту в WWW.
Конструкции языка
Содержимое XML- документа представляет собой набор элементов, секций CDATA, директив анализатора, комментариев, спецсимволов, текстовых данных. Рассмотрим каждый из них подробней.
Объект XMLDOMNode
Общая информация о текущем элементе дерева
nodeName
Возвращает полное название(вместе с Namaspace атрибутом) текущего узла в виде строки. Доступно только для чтения.
baseName
Возвращает название элемента без префикса Namespace. Только для чтения.
prefix
Возвращает Namespace префикс. Только для чтения.
namespaceURI
Возвращает URI Namespace префикса текущего элемента
dataType
Определяет тип содержимого текущего узла(описываемое схемами данных). Доступно для записи и чтения
nodeType
Возвращает тип текущего узла:
NODE_ELEMENT (1) - элемент
NODE_ATTRIBUTE (2) - атрибут
NODE_TEXT (3) - текст
NODE_CDATA_SECTION (4) - область CDATA
NODE_ENTITY_REFERENCE (5) - объект ссылки на "макроподстановки"
NODE_ENTITY (6) - объект ссылки на т.н. "подстановочые символы" - entity"
NODE_PROCESSING_INSTRUCTION (7) - область инструкций XML процессору
NODE_COMMENT (8) - комментарий
NODE_DOCUMENT (9) - корневой элемент документа
NODE_DOCUMENT_TYPE (10) - описание типа документа, задаваемое тэгом <!DOCTYPE>
NODE_DOCUMENT_FRAGMENT (11) - фрагмент XML-документа - несвязанное поддерево
NODE_NOTATION (12) - DTD нотация.
Свойство доступно только для чтения.
nodeTypeString
Возвращает тип узла в виде текста. Только для чтения.
attributes
Возвращает список атрибутов текущего узла в виде коллекции XMLDOMNamedNodeMap. Если атрибутов нет, то свойство length будет содержать нулевое значение. Для тех узлов, у которых не может быть атрибутов (в XML документе они могут быть назначены лишь объектам элементов, макроподстановок и нотаций) возвращается null. Для объектов макроподстановок и нотаций содержимым коллекции будут являться атрибуты SYSTEMID, PUBLICID и NDATA. Доступно только для чтения.
definition
Возвращает DTD определение для текущего узла дерева.
Содержимое текущего узла
text
Возвращает содержимое текущего поддерева(узла и всех его дочерних элементов). Доступно для записи и чтения
xml
Возвращает XML-представление текущего поддерева. Доступно только для чтения
nodeValue
Возвращает содержимое текущего узла. Доступно для чтения и записи.
Работа со списком дочерних элементов
childNodes
Для тех узлов, которые имеют дочерние элементы возвращает их список в виде XMLDOMNodeList. В том случае, если дочерних элементов нет, значение свойства length списка равно нулю . Только для чтения.
lastChild
Возвращает последний дочерний элемент или null, если таковых не имеется. Свойство доступно только для чтения.
firstChild
Возвращает последний дочерний элемент или null. Только для чтения.
nextSibling
Возвращает следующий дочерний элемент. Только для чтения.
previousSibling
Возвращает предыдущий дочерний элемент. Доступно только для чтения.
parentNode
Содержит ссылку на родительский элемент. В том случае, когда такого элемента нет, возвращает null. Доступно только для чтения.
ownerDocument
Возвращает указатель на документ, в котором находится текущий узел. Если в процессе модификации дерева узел будет перенесен в другой документ, то значение этого свойства автоматически изменится. Только для чтения.
Добавление новых элементов в объектную модель документа
appendChild(newChild)
Добавляет текущему узлу новый дочерний элемент. Возвращает ссылку на объект этого нового элемента. То же самое можно сделать и при помощи insertBefore (newChild, null)
insertBefore(newChild, refChild)
Вставляет дочерний узел, располагая его в текущем поддереве "левее" узла, указанного параметром refChild. Если последний параметр не задан, то новый узел будет добавлен в конец списка.
Модификация и удаление узлов
cloneNode (deep)
Создание копии текущего элемента. Параметр deep определяет, будет ли эта процедура рекурсивно выполняться для всех дочерних элементов. Возвращаемое значение - ссылка на новый элемент
replaceChild(newChild, oldChild)
Замена объекта oldChild текущего списка дочерних объектов на newChild. Если newChild=null, то старый объект будет просто удален.
removeChild(oldChild)
Удаление объекта oldChild из списка дочерних элементов
Поиск узлов (выделение поддеревьев)
selectNodes(patternString)
Возвращает объект XMLDOMNodeList, содержащий поддерево, выбранное по шаблону поиска pattertnString
selectSingleNode(patternString)
Аналогичен методу selectNodes, только возвращает первый узел из найденного поддерева
Обработка поддеревьев стилевыми таблицами
transformNode(stylesheet)
Назначает стилевую таблицу для поддерева текущего узла и возвращает строку - результат обработки. В качестве параметра передается ссылка на объект DOMDocument, в котором находятся XSL инструкции.
transformNodeToObject(stylesheet, outputObject)
То же, что и transformNode, только результат - обработанное дерево передается в объект XMLDocument(другое дерево), задаваемый параметром outputObject
| Объект XMLDOMDocument | |
| Представляет верхний уровень объектной иерархии и содержит методы для работы с документом: его загрузки, анализа, создания в нем элементов, атрибутов, комментариев и т.д. . Многие свойства и методы этого объекта реализованы также в рассмотренном выше класса Node, т.к. документ может быть рассмотрен как корневой узел с вложенными в него поддеревьями. | |
| Свойства | |
async
Свойство, доступное для записи и чтения, идентифицирующее текущий режим обработки (синхронный или асинхронный)
parseError
Возвращает ссылку на объект XMLDOMParseError, при помощи которого можно получить всю необходимую информацию о последней ошибке анализатора. Только для чтения.
readyState
Содержит информацию о текущем состоянии анализатора:
LOADING (1) - находится в процессе загрузки документа LOADED (2) - загрузка завершена, но объектная модель документа еще не создана INTERACTIVE (3) - объектная модель создана(все элементы документа разобраны, установлены их связи и атрибуты) но доступна пока только для чтения COMPLETED (4) - с ошибками или без, но документ разобран
Для получения своевременной информации о текущем состоянии анализатора можно воспользоваться обработчиком событий onreadystatechange
Только для чтения.
ondataavailable
Свойство, доступное только для записи, которое содержит ссылку на обработчик события ondataavailable (вызывается, когда обработчик обрабатывает очередную порцию данных документа)
onreadystatechange
Ссылка на обработчик события onreadystatechange (вызывается каждый раз, когда меняется состояние обработчика - свойство readyState)
ontransformnode
Ссылка на обработчик события ontransformnode (вызывается перед каждой трансформацией узла стилевыми таблицами)
Изменение параметров обработчика.
preserveWhiteSpace
Определяет, должны ли при разборе документа игнорироваться символы разделителей. Если значение свойства ложно, то будут, если истина - то разделители будут сохранены. По умолчанию установлено в false. Доступно для чтения и записи.
resolveExternals
Свойство определяет, будут ли в процессе анализа разбираться внешние определения (DTD-описания, макроподстановки и т.д.) - значение true или нет(false). Доступно для чтения и записи.
validateOnParse
Включение - выключение верификации документа. Значения true или false. Доступно для чтения и записи.
Получение информации о загруженном документе
doctype
Возвращает тип документа, определяемый при его создании тэгом <!DOCTYPE>, включающим DTD. Если в документе нет DTD описаний, возвращается null. Только для чтения.
url
Возвращает URL документа(в случае успешной его загрузки, в противном случае возвращает null). Доступно только для чтения.
implementation
Возвращет объект XMLDOMImplementation для данного документа. Только для чтения.
documentElement
Содержит ссылку на корневой элемент документа в виде объекта XMLDOMElement. Если корневого элемента нет, то возвращается null. Доступно для записи
Загрузка и сохранение документов
load(url)
Загружает документ, адрес которого задан параметром url. В случае успеха возвращает логическое значение true. Необходимо иметь в виду, что вызов этого метода сразу же обнуляет содержимое текущего документа
loadXML(xmlString)
Загружает XML - фрагмент, определенный в передаваемой строке
save(objTarget)
Сохраняет документ в файле (objTarget - строка, содержащая URL файла) или внутри другого документа (objTarget - объект XMLDOMDoument).
abort()
Прерывание процесса загрузки и обработки документа. Обработчик ошибок XMLDOMParseError будет содержать в коде ошибки соответствующее значение.
Создание новых объектов. Необходимо отметить, что все методы лишь создают указанные объекты и для включения их в объектную модель документа надо дополнительно использовать методы insertBefore, insertAfter или appendChild.
createAttribute (name)
Создает для текущего элемента новый атрибут с указанным именем. Новый атрибут добавляется в объектную модель документа только после определения его значения методом setAttribute.
createNode(Type, name, nameSpaceURI)
Создает узел указанного типа и названия. Namespace префикс задается параметром nameSpaceURI. Возвращаемым значением будет созданный объект указанного типа.
createCDATASection(data)
Создает область CDATA - возвращает объект XMLDOMCDATASection
createDocumentFragment()
Создает новый пустой фрагмента документа - объект XMLDOMDocumentFragment
createComment(data)
Создает комментарий.
createElement(tagName)
Создает элемент документа с указанным названием.
createEntityReference(name)
Создает ссылку на подстановочные символы
createProcessingInstruction(target, data)
Создает новую директиву XML-процессора
createTextNode(data)
Создает текст внутри документа
Поиск узлов дерева документа
getElementsByTagName(tagname)
Возвращает ссылку на коллекцию элементов документа с заданным именем (или всех элементов, если значение tagname равно "*")
nodeFromID(idString)
Поиск элемента по идентификатору
hasChildNodes()
Возвращает истину, если текущий узел содержит поддерево.
| Объект XMLDOMNodeList | |
| Представляет собой список узлов - поддеревья и содержит методы, при помощи которых можно организовать процедуру обхода дерева. | |
| Свойства | |
length
число элементов списка узлов
item(i)
Выбор i- того элемента из списка. Возвращает объект XMLDOMNode
nextNode()
Выбор следующего элемента в списке. Если такого элемента нет, то возвращает null. первый вызов этого метода(после сброса итератора) возвратит ссылку на первый элемент списка.
reset()
Сброс внутреннего указателя текущего элемента
| Объект XMLDOMParserError | |
| Объект позволяет получить всю необходимую информацию об ошибке, произошедшей в ходе разбора документа. Все свойства этого объекта доступны только для чтения. | |
| Свойства | |
Содержит код возникшей ошибки либо 0, если таковой не случилось.
url
Возвращает URL обрабатываемого документа
filepos
Возвращает смещение относительно начала файла фрагмента, в котором обнаружена ошибка
line
Содержит номер строки, содержащей ошибку
linepos
Позицию ошибки в строкев которой была обнаружена ошибка
reason
Описание ошибки
srcText
Содержит полный текст строки, в которой произошла ошибка
Объектная модель документа DOM
Одним из самых мощных интерфейсов доступа к содержимому XML документов является Document Object Model - DOM.
Объектная модель XML документов является представлением его внутренней структуры в виде совокупности определенных объектов. Для удобства эти объекты организуются в некоторую древообразную структуру данных - каждый элемент документа может быть отнесен к отдельной ветви, а все его содержимое, в виде набора вложенных элементов, комментариев, секций CDATA и т.д. представляется в этой структуре поддеревьями. Т.к. в любом правильно составленном XML-документе обязательно определен главный элемент, то все содержимое можно рассматривать как поддеревья этого основного элемента, называемого в таком случае корнем дерева документа. Для следующего фрагмента XML документа: <tree-node> <node-level1> <node-level2/> <node-level2>text</node-level2> <node-level2/> </node-level1> <node-level1> <node-level2>text</node-level2> <node-level1> <node-level2/> <node-level2><node-level3/></node-level2> </node-level1> </tree-node>
дерево элементов выглядит так:
Рис.1Дерево элементов
Объектное представление структуры документа не является чем-то новым для разработчиков. Для доступа к содержимому HTML страницы в сценариях давно используется объектно-ориентированный подход, - доступные для Java Script или VBScript элементы HTML документа могли создаваться, модифицироваться и просматриваться при помощи соответствующих объектов. Но их список и набор методов постоянно изменяется и зависит от типа броузера и версии языка. Для того, чтобы обеспечить независимый от конкретного языка программирования и типа документа интерфейс доступа к содержимому структурированного документа в рамках W3 консорциума была разработана и официально утверждена спецификация объектной модели DOM Level 1.
DOM - это спецификация универсального платформо- и программно-независимого доступа к содержимому документов и является просто своеобразным API для их обработчиков. DOM является стандартным способом построения объектной модели любого HTML или XML документа, при помощи которой можно производить поиск нужных фрагментов, создавать, удалять и модифицировать его элементы.
Для описания интерфейсов доступа к содержимому XML документов в спецификации DOM применяется платформонезависимый язык IDL и для использования их необходимо "перевести" на какой-то конкретный язык программирования. Однако этим занимаются создатели самих анализаторов, нам можно ничего не знать о способе реализации интерфейсов - с точки зрения разработчиков прикладных программ DOM выглядит как набор объектов с определенными методами и свойствами. В следующем разделе мы вкратце рассмотрим объектную модель Microsoft Internet Explorer 5, доступную из Java Script и VBScript сценариев.
Обработка XML-документов
Основным сдерживающим фактором в продвижении XML технологии в Web на сегодняшний день является отсутствие полной поддержки этого формата всеми производителями броузеров - программ, наиболее часто используемых на стороне клиента. Выходом из создавшейся ситуации может стать вариант, при котором обработкой XML документов занимается серверная сторона Используя любой существующий XML-анализатор, можно формировать необходимую информацию уже на сервере и посылать клиенту нормальный HTML-документ. Однако такой способ, конечно, менее гибок, и позволяет использовать XML технологию лишь для хранения структурированной информации, но не для ее динамического изменения на стороне клиента.
В августе 1997 RFC 2376 были утверждены MIME типы для XML-ресурсов: text/xml и application/xml. Поэтому XML документы могут передаваться по HTTP и отображаться программой просмотра также, как и обычные HTML- страницы. Для этого нужно немного изменить конфигурацию Web-сервера (в Apache - добавить в файл mime.types строчку "text/xml xml ddt"), а на стороне клиента иметь броузер, поддерживающий стилевые таблицы или JavaScript. Сегодня такими броузерами являются Microsoft Internet Explorer 5, первый броузер, поддерживающий спецификацию XML 1.0 и стилевые таблицы XSL; броузер Amaya, предлагаемый консорциумом специально для тестовых целей (http://www.sinor.ru/www.w3.org/Amaya/User/BinDist.html) и поддерживающий практически все разрабатываемые стандарты W3C. Поддержка XML также планируется в будущих версиях Netscape Navigator.
Very Useful
ПРИЛОЖЕНИЕ 1
Пример XML-документа <?xml version="1.0"?> <journal> <title> Very Useful Journal</title> <contacts> <address>sdsds</address> <tel>8-3232-121212</tel> <tel>8-3232-121212</tel> <email>j@j.ru</email> <url>www.j.ru</url> </contacts> <issues-list>
<issue index="2"> <title>XML today</title> <date>12.09.98</date> <about>XML</about> <home-url>www.j.ru/issues/</home-url> <articles>
<article ID="3"> <title>Issue overview</title> <url>/article1</url>
<hotkeys> <hotkey>language</hotkey> <hotkey>marckup</hotkey> <hotkey>hypertext</hotkey> </hotkeys> <article-finished/> </article>
<article> <title>Latest reviews</title> <url>/article2</url> <author ID="3"/> <hotkeys> <hotkey/> </hotkeys> </article>
<article ID="4"> <title/> <url/>
<hotkeys/> </article> </articles> </issue> </issues-list> <authors-list>
<author ID="1"> <firstname>Ivan</firstname> <lastname>Petrov</lastname> <email>vanya@r.ru</email> </author>
<author ID="3"> <firstname>Petr</firstname> <lastname>Ivanov</lastname> <email>petr@r.ru</email> </author>
<author ID="4"> <firstname>Sidor</firstname> <lastname>Sidorov</lastname> <email>sidor@r.ru</email> </author> </authors-list> </journal>
Отображение заголовка документа, определяемого элементом
ПРИЛОЖЕНИЕ 2
JavaScript сценарий, обрабатывающий XML-документ, приведенный в приложении 1
<HTML> <head> <title></title> <script language="javascript"> <!-- var xmldoc = new ActiveXObject("msxml"); var xmlsrc = "http://localhost/xml/journal.xml"; function viewTitle(elem){ // Отображение заголовка документа, определяемого элементом <title> this.document.writeln('<center><table width="100%" border=0><tr><td width="100%" align="center" bgcolor="silver"><b><font color="black">'+elem.text+'</font></b></td></tr></table></center><br>'); } function viewContactsList(elem){ // Отображение содержимого дочерних элементов <author-list> this.document.writeln('<tr><td align="right" colspan="2" bgcolor="gray"><b><font color="white">Наши реквизиты</font></b></td></tr>'); this.document.writeln('<tr><td bgcolor="silver" colspan="2"><center><table width="80%" border=0>'); if(elem.type==0){ if(elem.children!=null){ this.document.writeln('<tr><td colspan=2 width="100%"> </td></tr>'); var cur_item=elem.children.item("address"); if(cur_item!=null){ this.document.writeln('<tr><td><font color="blue">Адрес</font></td><td align="right" ><b><font color="red">'+cur_item.text+'</font></b></td></tr>'); } var cur_item=elem.children.item("tel",0); if(cur_item!=null){ this.document.writeln('<tr><td><font color="blue">Телефон</font></td><td align="right" ><b><font color="red">'+cur_item.text+'</font></b></td></tr>'); } var cur_item=elem.children.item("email"); if(cur_item!=null){ this.document.writeln('<tr><td><font color="blue">E-Mail</font></td><td align="right"><b><font color="red">'+cur_item.text+'</font></b></td></tr>'); } var cur_item=elem.children.item("url"); if(cur_item!=null){ this.document.writeln('<tr><td><font color="blue">URL</font></td><td align="right"><b><font color="red">'+cur_item.text+'</font></b></td></tr>'); } } } this.document.writeln('<tr><td colspan=2 width="100%"> </td></tr>'); this.document.writeln('</table></center></td></tr>'); } function viewAuthorsList(elem){ // Отображение содержимого дочерних элементов <author-list> this.document.writeln('<tr><td align="right" colspan="2" bgcolor="gray"><b><font color="white">Наши авторы</font></b></td></tr>'); this.document.writeln('<tr><td bgcolor="silver" colspan="2"><center><table width="80%" border=0>'); if(elem.type==0){ if(elem.children!=null){ for(i=0;i<elem.children.length;i++){ var cur_author = elem.children.item("author",i); this.document.writeln('<tr><td colspan=2 width="100%"> </td></tr>'); if(cur_author.children!=null){ var cur_item=cur_author.children.item("firstname"); if(cur_item!=null){ this.document.writeln('<tr><td><font color="blue">Имя</font></td><td align="right" ><b><font color="red">'+cur_item.text+'</font></b></td></tr>'); } var cur_item=cur_author.children.item("lastname"); if(cur_item!=null){ this.document.writeln('<tr><td><font color="blue">Фамилия</font></td><td align="right" ><b><font color="red">'+cur_item.text+'</font></b></td></tr>'); } var cur_item=cur_author.children.item("email"); if(cur_item!=null){ this.document.writeln('<tr><td><font color="blue">E-Mail</font></td><td align="right"><b><font color="red">'+cur_item.text+'</font></b></td></tr>'); } } } } } this.document.writeln('</table></center></td></tr>'); } function viewError(){ this.document.writeln('<center><hr>Error was detected'); } function parse(root){ if(root==null) return; var i=0; var elem; if(root.children!=null){ // Если вложенные элементы не были определены, то свойство children будет установленно в null this.document.writeln('<center><table width="80%" border=0><tr><td>'); // Перебор дочерних элементов for(i=0;i<root.children.length;i++){ elem=root.children.item(i); if(root.children.item(i).tagName=="TITLE"){ viewTitle(elem); // Разбор подэлементов <title> } if(elem.tagName=="CONTACTS"){ viewContactsList(elem); // Разбор подэлементов <contacts> } if(elem.tagName=="AUTHORS-LIST"){ viewAuthorsList(elem); // Разбор подэлементов <authors-list> } } this.document.writeln('</td></tr></table>'); } } function viewDocument(){ xmldoc.URL = xmlsrc; // Загрузка XML документа this.document.writeln('<body bgcolor="white">'); parse(xmldoc.root); // Начало разбора документа this.document.writeln('</body>'); } // Генерирование страницы viewDocument(); //--> </script> </head>
Элемент title должен определяться внутри
ПРИЛОЖЕНИЕ 3
Пример XSL-документа
<xsl> <!-- Корневое правило --> <rule> <root/> <HTML><HEAD> <!-- Область сценария--> <SCRIPT LANGUAGE="JSCRIPT"><![CDATA[ var ie4=((navigator.appName=="Microsoft Internet Explorer")&&(parseInt(navigator.appVersion) >= 4 )); function msover(){ if (ie4){ event.srcElement.style.color="red"; event.srcElement.style.cursor = "hand"; } } function msout(){ if (ie4){ event.srcElement.style.color="black"; event.srcElement.style.cursor = "auto"; } } ]]></SCRIPT> </HEAD> <BODY bgcolor="white"> <center> <table width="80%" border="1"> <children/> </table></center> </BODY> </HTML> </rule> <!-- Использование элемента select-elements --> <rule> <target-element type="journal"/> <select-elements> <target-element type="title"/> </select-elements>, <select-elements> <target-element type="contacts"/> </select-elements>, <select-elements> <target-element type="issues-list"/> </select-elements>, <select-elements> <target-element type="authors-list"/> </select-elements>. </rule> <!-- Formatting title element --> <rule> <element type="journal"> <target-element type="title"/> <!-- Элемент title должен определяться внутри элемента journal --> </element> <tr><td align="center"><center> <table width="80%" border="1"><tr><td width="100%"> <b><font color="blue"> <children/> </font></b></td></tr> </table></center> </td></tr> </rule> <!-- Issues list --> <rule> <element type="journal"> <target-element type="issues-list"/> </element> <tr><td align="center"> <children/> </td></tr> </rule> <rule> <element type="issues-list"> <target-element type="issue"/> </element> <tr><td><center> <table width="100%" border="0"> <tr><td colspan="2" bgcolor="gray"> <font color="white">Issues list</font></td></tr> <children/> <tr><td> </td></tr></table></center></td></tr> </rule> <rule> <target-element type="issue"/> <tr><td> <table width="100%" border="0"> <tr><td colspan="2">Issue number <b><eval>childNumber(this);</eval></b></td></tr> <children/> <tr><td> </td></tr></table></td></tr> </rule> <rule> <element type="issue"> <target-element type="title"/> <target-element type="date"/> <target-element type="about"/> <target-element type="home-url"/> </element> <tr> <td width="40%"><font color="blue"><eval>tagName</eval></font></td> <td width="60%" align="right"><div align="right"><b><font color="red"> <children/></font></b> </div></td></tr> </rule> <rule> <element type="issue"> <target-element type="articles"/> </element> <tr><td colspan="2" align="right" bgcolor="silver"> <center>Articles list</center></td></tr> <children/> </rule> <rule> <element type="articles"> <target-element type="article"/> </element> <tr><td colspan="2" align="right">Article number <b><eval>childNumber(this);</eval></b></td></tr> <children/> </rule> <rule> <element type="article"> <target-element type="title"/> <target-element type="url"/> <target-element type="author"/> </element> <tr> <td width="40%"><font color="maroon"><eval>tagName</eval></font></td> <td width="60%" align="right"><div align="right"><b><font color="red"> <children/></font></b> </div></td></tr> </rule> <rule> <target-element type="article" position="last-of-type"/> <children/> <tr><td colspan="2" bgcolor="silver" width="100%"> </td></tr> </rule> <rule> <element type="hotkeys"> <target-element type="hotkey"/> </element> <tr> <td width="40%"><font color="maroon"><eval>tagName</eval></font></td> <td width="60%" align="right"><div align="right"><b><font color="red"> <children/></font></b> </div></td></tr> </rule> <!-- Contacts --> <rule> <element type="journal"> <target-element type="contacts"/> <select-elements> <target-element type="address"/> </select-elements>, <select-elements> <target-element type="tel"/> </select-elements>, <select-elements> <target-element type="email"/> </select-elements>, <select-elements> <target-element type="url"/> </select-elements>. </element> <tr><td><center><table width="100%" border="1"> <tr><td colspan="2" bgcolor="gray"><font color="white">Contact us:</font></td></tr> <children/> <tr><td> </td></tr></table></center></td></tr> </rule> <rule> <element type="contacts"> <target-element type="address"/> <target-element type="tel"/> <target-element type="email"/> <target-element type="url"/> </element> <tr> <td width="40%"><font color="blue"><eval>tagName</eval></font></td> <td width="60%" align="right"><div align="right"><b><font color="red"> <children/></font></b> </div></td></tr> </rule> <!-- Authors --> <rule> <element type="journal"> <target-element type="authors-list"/> </element> <tr><td bgcolor="gray"><font color="white">Authors list</font></td></tr> <tr><td> <children/> </td></tr> </rule> <rule> <element type="authors-list"> <target-element type="author"/> <select-elements> <target-element type="firstname"/> </select-elements>, <select-elements> <target-element type="lastname"/> </select-elements>, <select-elements> <target-element type="email"/> </select-elements>. </element> <table width="100%" border="1"> <tr><td colspan="2">Author index <b><eval>getAttribute("ID");</eval></b></td></tr> <children/> <tr><td> </td></tr></table> </rule> <rule> <element type="author"> <attribute name="ID" has-value="yes"/> <target-element type="firstname"/> <target-element type="lastname"/> <target-element type="email"/> </element> <tr> <td width="40%"><font color="blue"><eval>tagName</eval></font></td> <td width="60%" align="right"><b><font color="black"> <!-- Подсветка элементов --> <DIV id='=tagName + formatNumber(childNumber(this),"1")' background-color="marron" onmouseover='="msover("+ tagName + formatNumber(childNumber(this),1)+")"' onmouseout='="msout("+ tagName + formatNumber(childNumber(this),1)+")"'> <children/> </DIV> </font></b> </td></tr> </rule> <!-- Определение стиля. Изменение стиля комнется всех элементов title и url, вне зависимости от их месторасположения --> <style-rule> <target-element type="title"/> <target-element type="url"/> <apply font-style="italic" color="maroon"/> </style-rule> </xsl>
element contents ANYgt;
ПРИЛОЖЕНИЕ 4
DTD-определения для XML-документа приложения 1
<!ENTITY % idattr 'id ID #IMPLIED'gt; <!ENTITY % opt 'title?,date,about'gt; <!ENTITY % cont 'tel*,url*,email*'gt; <!element title (PCDATA)?gt; <!element firstname (PCDATA)?gt; <!element lastname (PCDATA)?gt; <!element email (PCDATA)?gt; <!element url (PCDATA)?gt; <!element tel (PCDATA)?gt; <!element address (PCDATA)?gt; <!element fax (PCDATA)?gt; <!element date (PCDATA)?gt; <!element home-url (PCDATA)?gt; <!element article-url (PCDATA)?gt; <!element hotkey (PCDATA)? gt; <!element article-finished EMPTYgt; <! element contents ANYgt; <!element hotkeys (PCDATA|hotkey)? gt; <!element author (PCDATA|firstname?,lastname?,%cont;) gt; <!attlist author %idattr;gt; <!element authors (PCDATA|author*)? gt; <!element article (%opt;,author,article-url,hotkeys*,contents*,article-finished) gt; <!attlist article %idattr;gt; <!element articles (article)? gt; <!element issue (%opt;,home-url?,articles*) gt; <!attlist issue %idattr; index CDATA #REQUIRED gt; <!element issues-list (PCDATA|issue*)* gt; <!element contacts (address,%cont;)gt; <!element journal (title?,contacts?,isues-list,authors-list)gt; <!attlist journal %idattr; src CDATA #IMPLIED gt;
Приведем некоторые примеры использования
Создание объекта из сценариев осуществляется при помощи стандартных методов new ActiveXObject(JScript) и CreateObject: <script language="JScript"> var docobj = new ActiveXObject("Microsoft.XMLDOM"); ... и <script language="VBScript"> Dim docobj Set docobj = CreateObject("Microsoft.XMLDOM"). ...
Если данные включаются в документ в виде DSO-объектов, то для доступа к документу можно также использовать объектную модель HTMLстраницы, получая ссылку на XML-документ по идентификаторам соответствующих тэгов: <XML id="source" src="source-file.xml"></XML> <XML id="style" src="style-file.xsl"></XML> <SCRIPT FOR="window" EVENT="onload"> xslArea.innerHTML = source.transformNode(style.XMLDocument); </SCRIPT> ... <DIV id="xslArea"></DIV>
Первым способом создаются объекты при "ручной"загрузке нового документа. Если же мы хотим получить доступ к данным, встроенным в страницу при помощи тэгов xml или object, то используется второй способ.
Объектной переменной XMLDOMDocument также можно присвоить ссылку на другой объект созданного раннее документа:
docobj.documentElement = otherobj;
Загрузка XML-документа
Все необходимые манипуляции с XML документом осуществляются после его загрузки и создания дерева элементов. Загрузка может осуществляться либо при помощи указателя на соответствующий ресурс: docobj.load("http://myserver/xml/notes.xml"), либо "на лету", при помощи метода loadXML, которому в качестве параметра передается строка- отрывок XML документа:
docobj.loadXML("<recipe><step id='1'>Насыпать чай</step><step id='2'>Залить кипятком </step> <step id='3'>Вылить</step></recipe>");
Анализ документа
Для управления процессом анализа документа можно изменять следующие рассмотренные ранее свойства XMLDOMObject : async, validateOnParse, resolveExternals, preserveWhiteSpaces.
Необходимо запомнить, что анализ XML документа производится непосредственно после загрузки его содержимого - остановить этот процесс можно только используя метод abort. Поэтому свойства обработчика нужно изменять перед его загрузкой.
В процессе анализа документа обработчиком могут вызываться некоторые события, перехватывая которые можно отслеживать все шаги обработки. Для назначения классов обработчиков используются свойства , описанные в таблице. Вот пример программы-обработчика события , возникающего при изменении текущего состояния анализатора. <script> var xmldoc; var messages = new Array(5); var result_str = " Демонстрация обработки событий<hr/>"; messages[0]="Загрузка документа."; messages[1]="Загрузка завершена. Начинаю анализ документа"; messages[2]="Начинаю создание объектной модели"; messages[3]="Обработку завершил";
function startParse(url){ xmldoc = new ActiveXObject("Microsoft.XMLDOM"); xmldoc.onreadystatechange = onChangeState; xmldoc.load(url); xmlMessages.innerHTML = result_str; }
function onChangeState(){ var state = xmldoc.readyState; result_str += messages[state-1] + "<BR>"; } </script>
<BODY onLoad="startParse('notepad.xml')"> <DIV id="xmlMessages"></DIV> </BODY>
Другой способ назначить обработчик событий для элемента - это использование атрибута event тэга <script>: <XML id="xmlID" src="notes.xml"></XML> <script for="xmlID" event="onreadystatechange"> alert(xmlID.readyState); </script>
Обработка ошибок
Информация об обнаруженных в результате разбора XML-документа ошибках передается сценарию через объект XMLDOMParseError. Ссылку на него возвращает метод parseError объекта XMLDOMDocument. Узнать о типе ошибки можно по ее коду, содержащемся в свойстве errorCode (если разбор закончился успешно, то значение errorCode равно 0). При помощи свойств filepos, line, linepos, reason, srcText и url можно получить полную информацию о причине появления ошибки и ее местонахождении. <SCRIPT language="JavaScript"> var docobj; var result_str = "<hr/>";
function view(){ docobj = new ActiveXObject("Microsoft.XMLDOM"); docobj.load("music.xml");
if (docobj.parseError.errorCode != 0){ xmlTree.innerHTML=reportParseError(docobj.parseError); return; } xmlTree.innerHTML = docobj.xml; }
function reportParseError(error){ error_str = "<H4>Ошибка при загрузке документа '" + error.url + "'</H4>" + "<p><font color='red'>" + error.reason + "</font></p>"; if (error.line > 0) error_str += "<H5>" + "Строка " + error.line + ", символ " + error.linepos + "\n" + error.srcText + "</H4>"; return error_str;
}
</script> <BODY onLoad="startParse()"> <DIV id="xmlTree"></DIV> </BODY> </HTML> ...
Сохранение XML документа.
Созданное в памяти компьютера объектное дерево можно сохранить в текстовый файл, используя метод save:
xmlobj.save ("menu.xml");
Кроме этого, XML-документ можно сохранить в другом XMLDOMDOcument объекте, передав в качестве аргумента функции ссылку на него.
Обход дерева элементов
Для работы со списком элементов в объектной модели XML-анализатора Microsoft предназначены специальные объекты: XMLDOMNode - представляющий узел дерева и XMLDOMNodeList - список узлов, поддерево. Их описание приведено в таблице.
Просмотр списка элементов документа всегда начинается с получения нужного поддерева. Для этого у объекта XMLDOMNode используется методы childNodes, selectNodes или getElementsByTagName, возвращающие объект XMLDOMNodeList. Количество элементов этом поддереве можно узнать при помощи свойства length.
Вот, например, как будет выглядеть процедура рекурсивного просмотра документа произвольной структуры: <SCRIPT language="JavaScript"> var result_str = "<hr/>"; var docobj = new ActiveXObject("Microsoft.XMLDOM");
function printElements(){ docobj.load("music.xml"); viewNode(docobj.documentElement); xmlTree.innerHTML = result_str; }
function viewNode(node){ var childnodes = curNode.childNodes.length; result_str+=" "+curNode.nodeName+"<br/>"; for(var i=0;i<childnodes;i++){ viewNode(curNode.childNodes.item(i)); } } </SCRIPT>
<BODY onLoad="printElements()"> <DIV id="xmlTree"></DIV> </BODY> </HTML>
Навигация по документу осуществляется обычным перебором массива элементов в цикле for или при помощи методf nextNode. И в том и в другом случае мы сначала выбираем нужное поддерево, а затем обрабатываем его элементы. Необходимо заметить также, что в XMLDOMNodeList отражаются все изменения, вносимые в структуру XML-документа, и информация в результате будет всегда актуальной.
Поиск элемента
Поиск нужного элемента или поддерева осуществляется при помощи методов selectNode и selectSingleNode (то же что и selectNode, только возвращает первый найденный элемент). В качестве параметров им необходимо указать строку XSL запроса (образец поиска - XSL pattern).
Синтаксис языка запросов очень гибок и является одним из самых мощных механизмов в XSL - при помощи них можно осуществлять поиск элемента по названию, значению атрибутов, содержанию, учитывая вложенность и положение в дереве элементов. Наиболее ярко все эти возможности демонстрируются при обработке XML-документов стилевыми таблицами XSL , когда мы можем выделять из общего дерева необходимые нам элементы и применять к ним специальные форматирующие инструкции.
Внешне язык XSL запросов немного напоминает обычный способ определения пути к ресурсу в файловой системе - список узлов дерева, разделенных символом /. Для указания на текущий элемент используется символ "." , на родительский - "..", для выделения всех дочерних элементов - символ "*", для выделения элемента, расположенного просто "ниже" по дереву(не важно на каком уровне вложенности) - "//".
Вот примеры простых XSL шаблонов:
"/music-collection" - корневой элемент
"bards/" - возвращает дочерние элементы для элемента bards
"authors-list//" - список всех элементов, вложенных в authors-list
"author[@id]" - список элементов author, в котором определен атрибут id
"author[@id=2]" - элемент author, в котором значение атрибута id равно двум
"author[address]" - список элементов author, которые содержат хотя бы один элемент address
"author[address or city]" - список элементов author, содержащих элементы address или city
Условие на значение в запросе должно заключаться в символы "[" и "]". Для выбора значения атрибута в условии указывается символ @.
Применяя к XML- документу различные шаблоны поиска, можно осуществлять сложные манипуляции с его содержимым, динамически изменяя объем отображаемой пользователю информации в зависимости от производимых им действий (например, динамическая сортировка, отображение подчиненных таблиц и т.д.) Более подробное описание XSL-таблиц будет приведено в одной из следующих статей.
СХЕМЫ ДАННЫХ
5. СХЕМЫ ДАННЫХ
Схемы данных (Schemas) являются альтернативным способом создания правил построения XML-документов. По сравнению с DTD, схемы обладают более мощными средствами для определения сложных структур данных, обеспечивают более понятный способ описания грамматики языка, способны легко модернизироваться и расширяться. Безусловным достоинством схем является также то, что они позволяют описывать правила для XML- документа средствами самого же XML.
Однако это не означает, что схемы могут полностью заменить DTD- описания - этот способ определения грамматики языка используется сейчас практическими всеми верифицирующими анализаторами XML и, более того, сами схемы, как обычные XML- элементы, тоже описываются DTD. Но серьезные возможности нового языка и его относительная простота, безусловно, дают основания утверждать, что будущий стандарт найдет широкое применение в качестве удобного и эффективного средства проверки корректности составления документов.
В настоящее время в W3 консорциуме идет работа над первой спецификацией схем данных, рабочий ее вариант сейчас доступен на сервере []. В этом разделе мы рассмотрим основные возможности схем данных, попытаемся использовать их для проверки корректности ранее описываемых XML- документов.
Как это выглядит
Внешне документы схем очень похожи на те документы XML, с которыми мы уже встречались в предыдущих разделах. Мы размечаем документ при помощи специальных элементов, выполняющих в схемах роль инструкций. Эти инструкции составляют набор правил, используя которые, программа-клиент будет делать вывод о том, корректен документ или нет. Схема данных, например, может выглядеть следующем образом:
<schema id="OurSchema"> <elementType id="#title"> <string/> </elementType> <elementType id="photo"> <element type="#title"> <attribute name="src"/> </elementType> <elementType id="gallery"> <element type="#photo"> </elementType> </schema>
Если мы включим приведенные правила внутрь XML- документа, программа-клиент сможет использовать их для проверки. Т.е. она теперь сможет определить, что правильным будет являться следующий фрагмент:
<gallery> <photo id="1"><title>My computer</title></photo> <photo id="2"><title>My family</title></photo> <photo id="3"><title>My dog</title></photo> </gallery>
, а некорректным этот:
<gallery> <photo id="1"/> <photo index="2"><title>My family</title></photo> <photo index="3"><title> My dog </title><dogname>Sharik</dogname></photo> </gallery>
Все конструкции языка схем описываются правилами "XML DTD for XML-Data-Schema". Этот документ вы можете найти среди другой официальной документации, доступной на сервере W3 - консорциума. В этой статье мы коснемся лишь основных приемов для работы со схемами данных. Ссылки на более подробные источники приведены в конце.
Область схемы данных
Создавая схемы данных, мы определяем в документе специальный элемент, <schema>;, внутри которого содержатся описания правил:
<schema id="OurSchema"> <!-- последовательность инструкций --> </schema>
Если использовать отдельное пространство имен, то полный XML-документ, содержащий в себе схему данных, будет выглядеть следующим образом:
<?XML version='1.0' ?> <?xml:namespace href="http://www.mrcpk.nstu.ru/schemas/" as="s"/?> <s:schema id="OurSchema"> <!-- последовательность инструкций --> </s:schema>
Описание элементов
Для определения класса элемента, к которому в дальнейшем будут применяться инструкции, описывающие его содержимое и структуру, предназначен специальный элемент схемы elementType,
<elementType id="issue"> <descript>Элемент содержит информацию об очередном выпуске журнала</descript> </elementType>
Название элемента задается атрибутом id . Все дальнейшие инструкции, которые относятся к описываемому классу, определяют его внутреннюю структуру и набор допустимых данных, содержатся внутри блока, заданного тэгами <elementType> и </elementType>. Мы рассмотрим эти инструкции чуть позже.
Как видно из примера, при определении класса элемента, можно также использовать комментарии к нему, которые заключаются в тэги <descript></descript>
Атрибуты элемента
Для того, чтобы в описании элемента определить его атрибуты и описать свойства этих атрибутов мы должны использовать элемент attribute:
<elementType id="photo"> <attribute name="src"/> <empty/> </elementType>
В данном примере элементу <photo> определяется атрибут src, значением которого может быть любая последовательность разрешенных символов:
<photo src="0"/> <photo src="some text">
Подобно DTD, схемы данных позволяют устанавливать ограничения на значения и способ использования атрибутов. Для этого в дескрипторе <attribute> необходимо использовать параметр atttype.
Например, если мы хотим указать, что значение атрибута должно использоваться программой-анализатором как уникальный идентификатор, то нам необходимо создать следующее правило:
<elementType id="bouquet"> <attribute name="id" atttype="ID"> </elementType>
Если же требуется задать список возможных значений атрибута, то пример будет выглядеть следующим образом:
<attribute name="flower" atttype="ENUMERATION" values="red green blue" default="red">
Для приведенных примеров корректным будет являться следующий фрагмент XML-документа:
<bouquet id="0"> <flower color="red">rose</flower> <flower color="green">leaf</flower> <flower color="blue">bluet</flower> </bouquet>
Модель содержимого элемента
Под моделью содержимого в схеме данных понимают описание всех допустимых объектов XML- документа, использование которых внутри данного элемента является корректным. Модель содержимого определяется инструкциями, расположенными внутри блока <elementType>.
<elementType id="article"> <attribute name="id" atttype="ID"> <element type="#title"> <string/> </elementType>
Для этого правила корректным будет являться следующий фрагмент документа:
<article id="0"> <title>Психи и маньяки в Интернет</title> </article>
Вложенные элементы описываются при помощи инструкции element, в которой параметром type указывается класс объекта - ссылка на его определение:
<elementType id="article"> <element type="#title"/> <element type="#author"/> </elementType>
Если требуется указать режим использования вложенного элемента, то надо определить параметр occurs:
<elementType id="article"> <element type="#title" occurs="REQUIRED"/> <element type="#author" occurs="OPTIONAL"/> <element type="#subject" occurs="ONEORMORE"/> </elementType> Возможные значения этого параметра таковы:
REQUIRED - элемент должен быть обязательно определен OPTIONAL - использование элемента не является обязательным ZEROORMORE - вложенный элемент может встречаться несколько раз или ни разу ONEORMORE - элемент должен встречаться хотя бы один раз
Примеры правильных XML-документа, использующих приведенную выше схему:
<article> <title>Зачем он нужен, XML?</title> <author>Иван Петров</author> <subject>Что такое XML</subject> <subject>нужен ли он нам</subject> </article> или <article> <title>Зачем он нужен, XML?</title> <subject>Что такое XML</subject> </article>
Кроме элементов, содержимым XML-документа могут также является обычный текст и области CDATA. Для обозначения типов содержимого текущего элемента в схемах используются следующие инструкции:
<string/> - указывает на то, что содержимым элемента является только свободная текстовая информация(секция PCDATA) : <elementType id="flower"> <string/> </elementType>
<any/> - указывает на то, что содержимым элемента должны являться только элементы, без текста, незаключенного ни в один элемент: <elementType id="issue"> <any/> </elementType>
<mixed> - любое сочетание элементов и текста <elementType id="contacts"> <mixed/> </elementType>
<empty> - пустой элемент Пример: <elementType id="title"> <string/> </elementType> <elementType id="chapter"> <string/> </elementType> <elementType id="chapters-list"> <any/> </elementType> <elementType id="content"> <element type="#chapters-list" occurs="OPTIONAL"> </elementType> <elementType id="article"> <mixed><element type="#title"></mixed> <element type="#content" occurs="OPTIONAL"> </elementType>
О типах данных, которые можно определять с помощью схем, мы поговорим чуть позже
Группировка элементов
Элемент group используется для того, чтобы задать некоторую последовательность вложенных объектов:
<elementType id="contacts"> <element type="#tel" occurs="ONEORMORE"> <group occurs="OPTIONAL"> <element type="#email"> <element type="#url"> </group> </elementType>
Группировка объектов позволяет определять сразу группу объектов различных типов, которые могут находится внутри данного объекта. В приведенном примере мы указали, что внутри объекта типа contacts могут быть включены элементы tel, email, и url, причем атрибутом occurs мы указали, что элементы в группе являются необязательными. Корректным для таких схем будут являться следующие фрагменты документов:
<contacts> <tel>12-12-12</tel> <email>info@j.com</email> <url>http://www.j.com</url> </contacts> ... <contacts> <tel>12-12-12</tel> </contacts> ... <contacts> <tel>12-12-12</tel> <email>info@j.com</email> </contacts>
При помощи атрибута groupOrder можно также задавать режим использования группированных элементов При установленном значении OR возможно использование не всех элементов группы, а лишь некоторых из них. Если задано значение AND, то оба элемента должны быть включены в обязательном порядке. Например, для следующей группы правил:
<elementType id="contacts"> <element type="#tel" occurs="ONEORMORE"> <group groupOrder="AND" occurs="OPTIONAL"> <element type="#email"> <element type="#url"> </group> </elementType> будут считаться правильными только следующие варианты: <contacts> <tel>12-12-12</tel> <email>info@j.com</email> <url>http://www.j.com</url> </contacts> или <contacts> <tel>12-12-12</tel> </contacts>
Закрытая и открытая модели описания содержимого элемента
Когда мы определяем модель содержимого текущего элемента, список дополнительных допустимых элементов правилами не ограничивается - он может свободно расширяться. Например, для приведенного выше правила, кроме обозначенных элементов <tel>,<url> и <email> вполне могут использоваться дополнительные элементы, неописанные правилами, например, <fax>:
<contacts> <tel>12-12-12</tel> <fax>21-21-21</fax> <email>info@j.com</email> <url>http://www.j.com</url> </contacts>
Однако в том случае, если мы хотим ограничить создаваемые нами правила от включения дополнительных элементов, мы должны использовать атрибут content и установить для него специальное значение CLOSED:
<elementType id="contacts" content="CLOSED"> <element type="#tel"> <element type="#email"> <element type="#url"> </elementType>
Теперь приведенный фрагмент XML-документа будет считаться некорректным, т.к. параметром content запрещено использование внутри элемента contacts других объектов, кроме указанных в правиле.
Иерархия классов
Для того, чтобы при описании класса ограничить список объектов, которые могут являться родительскими для данного элемента, необходимо использовать элемент схемы domain.
Инструкция <domain> указывает, что текущий объект должен определяться строго внутри элемента, заданного этим тэгом. Например, в следующем фрагменте указывается, что элемент <author> может быть определен строго внутри тэга <article>:
<elementType id="author"> <element type="#lastname"> <element type="#firstname"> <domain type="#article"/> </elementType>
Ограничения на значения
Значения элементов могут быть ограничены при помощи тэгов <min> и <max>;:
<elementType id="room"> <element type="#floor"><min>0</min><max>100</max> </elementType>
Внутри этих элементов могут указываться и символьные ограничения:
<elementType id="line"> <element type="#character"><min>A</min><max>Z</max> </elementType>
Использование правил из внешних схем
Схема может использовать элементы и атрибуты из других схем. Для этого надо использовать атрибут href, в котором указывается название внешней схемы. Например:
<?XML version='1.0' ?> <?xml:namespace name="urn:uuid:BDC6E3F0-6DA3-11d1-A2A3-00AA00C14882/" as="s"/?> <s:schema> <elementType id="author"> <string/> </elementType> <elementType id="title"> <string/> </elementType> <elementType id="Book"> <element type="#title" occurs="OPTIONAL"/> <element type="#author" occurs="ONEORMORE"/> <element href="http://mrcpk.org/" /> </elementType></s:schema> </elementType> </s:schema>
Компоненты схем
Компоненты, или макроопределении, используются в схемах точно также, как и в DTD. Для их определения предназначены тэги <intEntityDcl/> и <extEntityDcl/>;:
<intEntityDcl name="MRCPK"> Новосибирский Межотраслевой Региональный Центр Переподготовки Кадров </intEntityDcl> <extEntityDcl name="logo" notation="#gif" systemId="http://www.mrcpk.nstu.ru/logo.gif"/>
Типы данных
В разделе, посвященном DTD, мы уже выяснили, для чего программе-клиенту необходима информация о формате данных содержимого элемента. В схемах существует возможность задавать тот или иной тип данных, используя при определении элемента директиву <datatype> с указанием конкретного типа:
<elementType id="counter"> <datatype dt="int"> </elementType>
В DTD мы должны были создать атрибут с конкретным названием, определяющим операцию назначения формата данных, и значением, определенным как fixed .Использование элемента <datatype> позволяет указывать это автоматически, но для обеспечения программной независимости необходимо сначала договориться об обозначениях типов данных(значения, которые должны передаваться параметру dt элемента dataype), для чего могут использоваться, например, универсальные идентификаторы ресурсов URI. В любом случае, как и прежде, все необходимые действия, связанные с конкретной интерпретацией данных, содержащихся в документе, осуществляются программой-клиентом и определяются логикой его работы. В разделе, посвященном DTD, мы уже рассматривали пример XML- документа, реализующего описанные нами возможности. Вот как выглядел бы этот пример при использовании схем данных:
<schema id="someschema"> <elementType id="#rooms_num"> <string/> <datatype dt="int"> </schema> <elementType id="#floor"> <string/> <datatype dt="int"> </schema> <elementType id="#living_space"> <string/> <datatype dt="float"> </schema> <elementType id="#is_tel"> <string/> <datatype dt="boolean"> </schema> <elementType id="#counter"> <string/> <datatype dt="float"> </schema> <elementType id="#price"> <string/> <datatype dt="float"> </schema> <elementType id="#comments"> <string/> <datatype dt="string"> </schema> <elementType id="#house"> <element type="#rooms_num" occurs="ONEORMORE"/> <element type="#floor" occurs="ONEORMORE"/> <element type="#living_space" occurs="ONEORMORE"/> <element type="#is_tel" occurs="OPTIONAL"/> <element type="#counter" occurs="ONEORMORE"/> <element type="#price" occurs="ONEORMORE"/> <element type="#comments" occurs="OPTIONAL"/> </elementType> </schema> ... <house id="0"> <rooms_num>5</rooms_num> <floor>2</floor> <living_space>32.5</living_space> <is_tel>true</is_tel> <counter>18346</counter> <price>34.28</price> <comments>С видом на cеверный полюс</comments> </house> ...
Подводя итог всему сказанному, необходимо отметить, что процесс развития современных информационных систем настолько динамичен, что временной промежуток между появлением новой технологии и ее практическим использованием в реально действующих приложениях сегодня слишком мал. На смену устаревающему стандарту HTML в самое ближайшее время должен будет прийти новый, более гибкий и универсальный язык описания данных. И тот факт, что XML как язык еще не стандартизирован и некоторые его составляющие до сих пор находятся в стадии разработки, видимо, не является причиной невозможности его использования уже сегодня, для решения конкретных задач в реальных системах. Примером этому может служить возникновение огромного количества языков описания документов, некоторые из которых приведены в Приложении
В этой статье были рассмотрены лишь самые основные аспекты, касающиеся новой XML- технологии. В будущем, мы, возможно, остановимся несколько подробнее на производных от XML языках описания данных - SMIL, RDF, MathML, механизмах описания пространства имен и рассмотрим некоторые вопросы, касающиеся создания программ-анализаторов для этих языков.
СТИЛЕВЫЕ ТАБЛИЦЫ XSL
3. СТИЛЕВЫЕ ТАБЛИЦЫ XSL
В предыдущем разделе для вывода элементов XML- документа на экран броузера мы применяли Java Script-сценарии Однако, как уже отмечалось, для этих целей предпочтительней использование специально предназначенного для этого средства - стилевых таблиц XSL(Extensible Stylesheet Language).
Стилевыми таблицами (стилевыми листами) принято называть специальные инструкции, управляющие процессом отображения элемента в окне программы-клиента(например, в окне броузера). Предложенные в качестве рекомендация W3C, каскадные стилевые таблицы(CSS- Cascading Style Sheets []) уже больше года используются Web- разработчиками для оформления Web- страниц. Поддержка CSS наиболее известными на сегодняшний день броузерами Netscape Navigator(начиная с версии 4.0) и Microsoft Explorer(начиная с версии 3.0), позволила использовать стилевые таблицы для решения самого широкого спектра задач - от оформления домашней странички до создания крупного корпоративного Web-узла. Слово каскадные в определении CSS означает возможность объединения отдельных элементов форматирования путем вложенных описаний стиля. Например, атрибуты текста, заданные в тэге <body>, будут распространяться на вложенные тэги до тех пор, пока в них не встретятся стилевые описания, отменяющие или дополняющие текущие параметры. Таким образом, использование таблиц CSS в HTML было весьма эффективно - отпадала необходимость явного задания тэгов форматирования для каждого из элементов документа.
Являясь очень мощным средством оформления HTML- страниц, CSS- таблицы, тем не менее, не могут применяться в XML-документах, т.к. набор тэгов в этом языке не ограничен и использование статических ссылок на форматируемые объекты документа в этом случае невозможно.
Поэтому для форматирования XML- элементов был разработан новый язык разметки, являющийся подмножеством XML, и специально был предназначен для форматирования XML- элементов.
Некоторые его отличия от CSS:
Во-первых, стилевые таблицы XSL позволяют определять оформление элемента в зависимости от его месторасположения внутри документа, т.е. к двум элементам с одинаковым названием могут применяться различные правила форматирования.
Во-вторых, языком, лежащем в основе XSL, является XML, а это означает, что XSL более гибок, универсален и у разработчиков появляется возможность использования средства для контроля за корректностью составления таких стилевых списков(используя DTD или схемы данных)
В-третьих, таблицы XSL не являются каскадными, подобно CSS, т.к. чрезвычайно сложно обеспечить "каскадируемость" стилевых описаний, или, другими словами, возможность объединения отдельных элементов форматирования путем вложенных описаний стиля, в ситуации, когда структура выходного документа заранее неизвестна и он создается в процессе самого разбора. Однако в XSL существует возможность задавать правила для стилей, при помощи которых можно изменять свойства стилевого оформления, что позволяет использовать довольно сложные приемы форматирования
В настоящий момент язык XSL находится на стадии разработки в W3C[3] и в будущем, видимо, станет частью стандарта XML. Это означает, что использование этого механизма является наиболее перспективным способом оформления XML- документов. В текущем рабочем варианте W3C, XSL рассматривается не только как язык разметки, определяющий стилевые таблицы - в него заложены средства, необходимые для выполнения действий по фильтрации информации, выводимой в окно клиента, поиска элементов, сложного поиска, основанного на зависимостях между элементами и т.д. На сегодняшний день единственным броузером, поддерживающим некоторые из этих возможностей, является бэта-версия Internet Explorer 5.0, однако в самом ближайшем будущем, безусловно, XSL будет использоваться также широко, как сегодня стандартные тэги HTML
В этом разделе мы рассмотрим упрощенную объектную модель XSL- документа, используемую в текущей версии XSL-конвертора Microsoft msxsl, и поэтому информацию, изложенную далее, нельзя считать описанием стандарта языка. Полный рабочий вариант спецификации XSL в последней его редакции доступен на сервере [3].
Все примеры, приводимые далее, могут быть проверены при помощи XSL- конвертора, свободно доступного на странице Mcrosoft [ http://www.sinor.ru/www.microsoft.com/xml/xsl/default.htm ]
С чего начать
Принцип обработки XML- документов стилевыми таблицами заключается в следующем: при разборе XSL-документа программа-анализатор обрабатывает инструкции этого языка и каждому элементу, найденному в XML- дереве ставит в соответствие набор тэгов, определяющих форматирование этого элемента. Другими словами, мы задаем шаблон форматирования для XML- элементов, причем сам этот шаблон может иметь структуру соответствующего фрагмента XML-документа. Инструкции XSL определяют точное месторасположение элемента XML в дереве, поэтому существует возможность применять различные стили оформления к одинаковым элементам, в зависимости от контекста их использования. На рисунке 3.1 представлена схема, иллюстрирующая этот процесс.

Рис 1
В общем случае, XSL позволяет автору задавать параметры отображения элемента XML, используя любые языки, предназначенные для форматирования - HTML, RTF и т.д. В этом разделе мы будем использовать в качестве такого языка HTML, т.к. документы, созданные при помощи этого языка разметки могут просматриваться любой подходящей программой просмотра Web-страниц
Структура XSL- таблиц
Рассмотрим основные структурные элементы XSL, используемые, в частности, в конверторе msxsl, для создания оформления XML-документов.
Правила XSL
XSL- документ представляет собой совокупность правил построения, каждое из которых выделено в отдельный блок, ограниченный тэгами <rule> и </rule>;. Правила определяют шаблоны, по которым каждому элементу XML ставится в соответствие последовательность HTML- тэгов, т.е. внутри них содержатся инструкции, определяющие элементы XML- документа и тэги форматирования, применяемые к ним.
Элементы XML, к которым будет применяться форматирование, обозначаются в XSL дескриптором <target-element/>;. Для указания элемента с конкретным названием (название элемента определяется тэгами, его обозначающими), т.е. определения класса элемента, можно использовать атрибут type="<имя_элемента>"
Вот пример простейшего XSL-документа, определяющего форматирование для фрагмента <flower>rose</flower> : <xsl> <rule> <target-element type="flower"/> <p color="red" font-size="12"> <children/> </p> </rule> </xsl>
Уже на этом примере можно проследить особенность использования стилевых таблиц: в любых правилах при помощи соответствующих элементов декларативно задается область, которая определяет фрагмент XML-документа, как мы чуть позже увидим, программа-анализатор заново проходит все элементы, начиная с текущего, всякий раз, когда в структуре XML- документа обнаруживаются новые вложенные элементы.
Инструкция <target-element> указывает на то, что данное правило определяет элемент. Параметром type="flower" задается название XML-элемента, для которого будет использоваться это правило. Программа-конвертор будет использовать HTML-тэги, помещенные внутри блока <rule></rule> для форматирования XML-элемента, которому "предназначался" текущий блок. В том случае, если для какого-то элемента XML шаблон не определяется, в выходной документ будут добавлены тэги форматирования по умолчанию (например, <DIV></DIV> )
Процесс разбора XSL-правил является рекурсивным, т.е. если у элемента есть дочерние элементы, то программа будет искать определения этих элементов, расположенных "глубже" в дереве документа. Указанием на то, что необходимо повторить процесс разбора XML документа, теперь уже для дочерних элементов, является инструкция <children/>. Дойдя до нее, анализатор выберет из иерархического дерева XML- элементов нужную ветвь и найдет в XSL-шаблонах правила, определяющие форматирование этих нижележащих элементов. В том случае, если вместо <children> мы укажем инструкцию <empty/>;, программа закончит движение по данной ветви и возвратится назад, в родительское правило. При этом текущее правило никакой информации в выходном HTML-документе изменять не будет, т.к. <empty/> в данном случае означает, что содержимое элемента отсутствует.
Если в одном правиле <target-element> используется несколько раз, то инструкции по форматированию будут распространены на все описываемые внутри него XML-элементы, т.е. можно задавать единый шаблон форматирования для нескольких элементов одновременно: <xsl> <rule> <target-element type="item1"/> <target-element type="item2"/> <target-element type="item3"/> <hr> <children/> <hr> </rule> </xsl>
Ниже приведен пример более сложного XSL- описания, некоторые фрагменты которого будут пояснены позже.
XML-документ: <?XML Version="1.0"?> <documents> <books> <book id="Book1"> <title>Макроэномические показатели экономики Римской Империи в период ее расцвета</title> <author>Иван Петров</author> <date>21.08.98</date> </book> <book id="Book2"> <title>Цветоводство и животноводство. Практические советы</title> <author>Петр Сидоров</author> <date>10.10.98</date> </book> </books> <articles> <article id="Article1"> <author>Петр Иванов</author> <title>Влияние повышения тарифов оплаты за телефон на продолжительность жизни населения</title> <date>12.09.98</date> </article> </articles> </documents>
Содержимое XSL-документа: <xsl> <rule> <root/> <HTML> <BODY bgcolor="white"> <center><hr width="80%"/><b>Library</b><hr width="80%"/><br/> <table width="80%" border="2"> <children/> </table></center> </BODY> </HTML> </rule> <rule> <element type="book"> <target-element type="author"/> </element> <td align="center"> <p color="red" font-size="14"> <b> <children/> </b></p></td> </rule> <rule> <element type="article"> <target-element type="author"/> </element> <td align="center"> <p color="red" font-size="14" font-style="italic"><children/></p></td> </rule> <rule> <target-element type="book"/> <tr><children/></tr> </rule> <rule> <target-element type="article"/> <tr><children/></tr> </rule> <rule> <target-element/> <td align="center"><p><children/></p></td> </rule> <rule> <target-element type="books"/> <tr><td colspan="3" bgcolor="silver" >Books</td></tr> <children/> </rule> <rule> <target-element type="articles"/> <tr><td colspan="3" bgcolor="silver" >Articles</td></tr> <children/> </rule> </xsl>
Корневое правило
Разбор любого XSL- документа всегда начинается с правила для корневого элемента, в котором определяется область всего разбираемого XML документа и поэтому тэги форматирования, помещенные сюда, будут действовать на весь документ в целом. Для обозначения корневого правила необходимо включить в него элемент <root/>;. Например, для того, чтобы задать тэг <body> для формируемой нами выходной HTML- страницы, мы можем использовать следующий фрагмент: <xsl> <rule> <root/> <html><head><title> Flowers</title></head> <body bgcolor="white" link="blue" alink="darkblue" vlink="darckblue"> <children/> </body> </html> </rule> </xsl>
В этом примере при помощи инструкций <root/> и <children/> мы определили ряд начальных и конечных HTML-тэгов для нашей страницы, между которыми затем в процессе рекурсивного обхода XSL- анализатора будут помещены остальные элемента документа.
В том случае, если мы не определяем правило для корневого элемента, разбор документа начнется с первого правила с инструкцией <target-element>(для оформления же заголовка документа будет использован образец форматирования, применяющийся по умолчанию).
Отношения между элементами
Дочерние элементы в XML-документе всегда находятся внутри области, определяемой тэгами родительского по отношению к ним элемента. Для того, чтобы точно указать месторасположение обрабатываемого элемента в дереве XML, в XSL используется дополнительный тэг <element>;. При помощи него можно указать, какие элементы должны предшествовать текущему, а какие - следовать после него. Например, в следующем фрагменте определяется, что форматирование элемента <title> будет зависеть от его месторасположения внутри XML-документа: <xsl> <rule> <element type="journal"> <target-element type="title"/> </element> <center> <hr width=80%> <children/> <hr width=80%> </center> </rule> <rule> <element type="article"> <target-element type="title"/> </element> <td align="center"><p color="blue" font-size="14" font-style="italic"><children/> </td> </rule> </xsl>
Как видно из примера, если в XML- документе будет найден элемент <title>, являющийся дочерним по отношению к элементу <article> (название статьи), то его форматирование будет несколько отличаться от элемента <title>, расположенного внутри тэгов <journal>
Приоритеты правил
В том случае, если внутри XSL- документа встречается несколько правил для одного и того же элемента, то msxsl будет использовать то из них, которое более точно определяет позицию данного элемента. Т.е. если XSL- документ содержит следующие правила: <rule> <element type="journal"> <target-element type="title"/> </element> <center> <hr width=80%> <children/> <hr width=80%> </center> </rule> <rule> <target-element type="title"/> <b> <children/> </b> </rule>
, то при использовании этой стилевой таблицы в случае, когда элемент <title> является потомком <journal>, к нему будет применено первое правило. Для любых же других элементов будет действовать правило без тэга <element>
В общем случае приоритет правил определяется следующим образом (в порядке убывания приоритета):
правила, помеченные специальным тэгом <importance> правила с наибольшим значением атрибута id, если он определен правила с наибольшим значением атрибута class, если он определен правила, имеющие наибольшую вложенность, определяемую тэгом <element> правила, использующие атрибут type совместно с <target-element> правила, в которых отсутствует атрибут type в <target-element> или <element> правила с более высоким приоритетом, задаваемым атрибутом priority тэга <rule> правила с наибольшим значением квалификаторов <only>, <position>, <attribute>
Использование атрибутов элементов
Применительно к <target-element> и <element> в правилах также могут использоваться специальные элементы <attribute>;, при помощи которых можно уточнять характеристики обрабатываемых элементов, задавая различные инструкции форматирования для одинаковых элементов с различными атрибутами. Указываемые в <attribute> параметры name и value определяют атрибут XML, который должен иметь текущий обрабатываемый элемент. Например, в следующем фрагменте все элементы с атрибутом free_lance ="true" будут выделены в выходном HTML- документе серым цветом <rule> <target-element type="author"> <attribute name="free_lance" value="true"> </target-element> <p color="gray"> <children/> </p> </rule>
Фильтрация элементов
Одним из самых мощных средств XSL является возможность сортировки и выборки элементов, выделяемых из общего дерева элементов документа. Для этого используется элемент <select-elements>;, который заменяет <children/> в правилах, определяя те элементы, которые следует обработать в процессе рекурсивного обхода. Например, в следующем примере будут обработаны только элементы <author>: <rule> <target-element type=" staff"/> <div> <select-elements> <target-element type = "author"/> </select-elements> </div> </rule>
Элемент <select-elements> сам по себе не определяет шаблон форматирования, он лишь управляет работой анализатора, обозначая, подобно <children/>, "нижележащие" элементы. В приведенном примере элемент <author> должен быть расположен внутри элемента <staff>
Для того, чтобы в шаблоне выделить не только собственные дочерние элементы, но и дочерние элементы потомков, т.е. использовать несколько уровней вложенности, необходимо задать параметр from = "descendants". Если параметр имеет значение "children", что указывает на то, что выбор должен производится из списка собственных дочерних элементов, то атрибут from может опускаться, т.к. "children" является значением по умолчанию.
Правила стилей
В отличие от CSS, в XSL невозможно использование каскадных стилевых определений(т.е. нельзя использовать несколько правил для определения стиля одного того же элемента), т.к. такие ограничения вводит рекурсивный алгоритм работы программы - анализатора. Однако использование правил определения стиля(Style Rules) элемента позволяет каким-то образом скомпенсировать этот недостаток.
Для определения правила стилевого оформления необходимо воспользоваться элементом <style-rule>;, который используется точно также, как и <rule>, но инструкции, содержащиеся в нем, никак не влияют на структуру выходного документа. Поэтому все команды внутри этого правила должны описываться в рамках элемента <apply>. Вот как будет выглядеть, например, определение стиля для элемента <flower>rose</flower>;: <style-rule> <target-element type ="flower"/> <apply color ="red"/> </style-rule> <rule> <target-element type="flower"/> <div font-style="italic";> <children/> </div> </rule>
Если бы мы не определили правила <rule>, то в выходной документ не было бы помещено никакой информации, т.к. элемент <style-rule> только определяет параметры стилевого оформления, не предпринимая никаких других действий.
Также надо учитывать, что XSL- анализатор использует CSS для определения задаваемого правилами <style-rule> стиля в выходном HTML-документе, тем самым предоставляя нам возможность использования этого мощного средства при оформлении HTML-страниц После обработки приведенного в примере фрагмента в выходной документ будут помещены следующие элементы: <div style= "font-style: italic; color : red;">rose</div> Еще один пример:
Стили в формате CSS: issue {font-weight=bold; color=blue;} .new {font-weight=bold; color=red;}
Фрагмент XSL- документа, позволяющего использовать подобные стилевые определения: <style-rule> <target-element type ="issue"/> <apply color ="blue"/> </style-rule> <style-rule> <target-element type ="issue"> <attribute name ="class" value ="new" /> </target-element> <apply color ="red"/> </style-rule> <rule> <target-element type="issue"/> <div> <children/> </div> </rule>
Сценарии
Сценарии могут использоваться в документах XSL точно также, как и в HTML. Кроме того, сценарии, содержащиеся внутри XSL-документа и запускаемые броузером в процессе обработки документа могут динамически создавать HTML-документы, извлекая необходимую для этого информацию непосредственно из элементов XSL-документа.
Для написания сценариев XSL использует специальный скриптовый язык - ECMAScript. Однако в msxsl для этих целей можно применять Microsoft JavaScript,- язык, который объединил в себе некоторые элементы стандартного JavaScript и ECMAScript.
Вычисление выражений
Наиболее простым примером использования сценариев в XSL -документе является вычисление значений параметров описываемых элементов. Для этого надо просто поставить знак равенства в качестве первого символа параметра, что заставит XSL-процессор вычислить значение выражения(синтаксис этого выражения должен отвечать требованиям JavaScript). Например, после разбора этого правила: <rule> <target-element type="header"> <hr width="=100-20+'%'"> <children/> <hr width="80%"> </rule>
, в выходном документе окажутся следующие инструкции: <hr width=80%> ... <hr width=80%>
Очень часто в правилах XSL необходимо использовать атрибуты описываемого в них элемента. Для этого мы должны воспользоваться методом getAttribute(), описанным в объектной модели XML (мы рассматриваем объектную модель XML-документов, предложенную Microsoft, список этих функций приведен в конце раздела). Т.к. каждому элементу XSL доступен указатель на соответствующий ему объект, сценарий может обращаться к внутренним функциям и свойствам этих элементов, при помощи которых и осуществляются необходимые действия.
В следующем фрагменте XML- документа определяется элемент <article>, в котором атрибут src используется для задания адреса файла, содержащего текст статьи. <articles> <article src="http://server/pages/article.html">Bugs report</article> </articles>
Для того, чтобы использовать этот атрибут в выходном HTML-документе, необходимо определить следующее правило: <rule> <target-element type="article"> <a href='=getAttribute("src")'> <children/> </a> </rule>
После обработки этого фрагмента в выходной документ будет помещен элемент: <a href="http://server/pages/article.html">Bugs report</a>
Выполнение инструкций
Другим способом помещения в выходной HTML- документ информации, являющейся результатом выполнения каких-либо операций JavaScript – сценариев является использовнаие инструкции <eval>;: <rule> <element type="articles"> <target-element type="article"> </element> <tr><td><eval>childNumber(this)</eval></td><td> <children/> </td><tr> </rule>
Метод childNumber в данном случае возвращает текущий номер дочернего элемента.
Определение функций и глобальных переменных
Аналогично тэгу <SCRIPT> в HTML, элемент <define-script> содержит функции и определения глобальных переменных. Обычно в XSL-документе определяется один элемент <define-script>, расположенный в самом начале. <xsl> <define-script> <![CDATA[ var fontSize=12; function getColor(elem){ return elem.children.item("color",0).text; // Возвращает содержимое дочернего элемента <color> }]]> </define-script> <rule> <target-element type = "flower"> <div background-color="=getColor(this)"; font-size="=fontSize"> <children/> </div> </rule> </xsl>
Если применить эти правила к такому фрагменту XML- документу: <xml> <flower> rose <color>red</color> </flower> , то на выходе HTML -документ будет содержать следующие элементы: <div background-color="red"; font-size="12">
Необходимо отметить, что использование глобальных переменных в некоторых случаях может приводить к серьезным ошибкам, вызванным попытками одновременного к ним доступа. Поэтому рекомендуется использовать такие переменные только в качестве констант.
Использование Java Script для HTML
Создавая шаблон HTML-документа, Вы можете указывать в нем практически любые элементы HTML, в том числе и блоки <SCRIPT>, внутри которых можно задавать любые конструкции Java Script, используя для этого область CDATA: <xsl> <rule> <root/> <HTML> <HEAD> <SCRIPT LANGUAGE="JSCRIPT"><![CDATA[ var ie4=((navigator.appName=="Microsoft Internet Explorer")&&(parseInt(navigator.appVersion) >= 4 )); function msover(){ if (ie4){ event.srcElement.style.color="red"; event.srcElement.style.cursor = "hand"; } } function msout(){ if (ie4){ event.srcElement.style.color="black"; event.srcElement.style.cursor = "auto"; } } ]]></SCRIPT> </HEAD> <BODY> <children/> </BODY> </HTML> </rule> <rule> <target-element type="chapter"/> <DIV id='=tagName + formatNumber(childNumber(this),"1")' background-color="marron" onmouseover='="msover("+ tagName + formatNumber(childNumber(this),"1")+")"' onmouseout='="msout("+ tagName + formatNumber(childNumber(this),"1")+")"' <children/> </DIV> </rule> </xsl> Если использовать эти правила для следующего XML- документа: <contents> <chapter>Part1</chapter> <chapter>Part2</chapter> <chapter>Part3</chapter> </contents> то в результате мы получим такой HTML-файл: <HTML> <HEAD> <SCRIPT LANGUAGE="JSCRIPT"> var ie4=((navigator.appName=="Microsoft Internet Explorer")&&(parseInt(navigator.appVersion) >= 4 )); function msover(){ if (ie4){ event.srcElement.style.color="red"; event.srcElement.style.cursor = "hand"; } } function msout(){ if (ie4){ event.srcElement.style.color="black"; event.srcElement.style.cursor = "auto"; } } </SCRIPT> </HEAD> <BODY> <DIV id=''chapter1" onmouseover="msover("chapter1")"' onmouseout="msout("chapter1")"' Part 1 </DIV> <DIV id=''chapter2" onmouseover="msover("chapter2")"' onmouseout="msout("chapter2")"' Part 2 </DIV> <DIV id=''chapter3" onmouseover="msover("chapter3")"' onmouseout="msout("chapter3")"' Part 3 </DIV> </BODY> </HTML>
Встроенные функции XSL
В завершении приведем список внутренних функций, которые можно использовать в JavaScript –сценариях, предназначенных для анализатора msxsl:
| Ancestor(elementType, elem) | Возвращает для текущего элемента ссылку на ближайший родительский элемент заданного типа. Если такого элемента нет или текущий элемент пустой, то возвращает null |
| ChildNumber(elem) | Возвращает индекс текущего элемента в списке других дочерних элементов данного типа. |
| AncestorChildNumber() | Возвращает номер ближайшего предка текущего элемента или null, если такового не существует |
| path(xsl) | Возвращает массив, содержащий "путь" к текущему элементу - в каждую ячейку этого массива помещается цифровое значение, указывающее на количество элементов одинакового типа, находящихся на текущем уровне вложенности. Первым значением этого массива будет представлен корневой элемент, последним - текущий. Размер массива определяет глубину вложенности текущего элемента. |
| HierarchicalNumberRecursive(elementType,elem) | Метод, похожий на метод path, но возвращает только дочерние элементы |
| FormatNumber(n,format) | Возвращает строку - символьное представление номера(т.е. "один", "два" и т.д.). Возможно определение следующих форматов: "1" - 0,1,2,.. "01" - 01,02,03,... "a" - a,b,c,..z, aa, ab,..zz "A" - A,..,Z,AA, .. ZZ |
| FormatNumberList(list,format,separator) | Возвращает строку, представляющую список, элементами которого являются символьные представления чисел |
Структура документа
Простейший XML- документ может выглядеть так, как это показано в Примере 1
<?xml version="1.0"?> <list_of_items> <item id="1"><first/>Первый</item> <item id="2">Второй <sub_item>подпункт 1</sub_item></item> <item id="3">Третий</item> <item id="4"><last/>Последний</item> </list_of_items>
Обратите внимание на то, что этот документ очень похож на обычную HTML-страницу. Также, как и в HTML, инструкции, заключенные в угловые скобки называются тэгами и служат для разметки основного текста документа. В XML существуют открывающие, закрывающие и пустые тэги (в HTML понятие пустого тэга тоже существует, но специального его обозначения не требуется).
Тело документа XML состоит из элементов разметки (markup) и непосредственно содержимого документа - данных (content). XML - тэги предназначены для определения элементов документа, их атрибутов и других конструкций языка. Более подробно о типах применяемой в документах разметки мы поговорим чуть позже.
Любой XML- документ должен всегда начинаться с инструкции <?xml?>, внутри которой также можно задавать номер версии языка, номер кодовой страницы и другие параметры, необходимые программе-анализатору в процессе разбора документа
Правила создания XML- документа
В общем случае XML- документы должны удовлетворять следующим требованиям:
В заголовке документа помещается объявление XML, в котором указывается язык разметки документа, номер его версии и дополнительная информация Каждый открывающий тэг, определяющий некоторую область данных в документе обязательно должен иметь своего закрывающего "напарника", т.е., в отличие от HTML, нельзя опускать закрывающие тэги В XML учитывается регистр символов Все значения атрибутов, используемых в определении тэгов, должны быть заключены в кавычки Вложенность тэгов в XML строго контролируется, поэтому необходимо следить за порядком следования открывающих и закрывающих тэгов Вся информация, располагающаяся между начальным и конечными тэгами, рассматривается в XML как данные и поэтому учитываются все символы форматирования ( т.е. пробелы, переводы строк, табуляции не игнорируются, как в HTML)
Если XML- документ не нарушает приведенные правила, то он называется формально-правильным и все анализаторы, предназначенные для разбора XML- документов, смогут работать с ним корректно.
Однако кроме проверки на формальное соответствие грамматике языка, в документе могут присутствовать средства контроля над содержанием документа, за соблюдением правил, определяющих необходимые соотношений между элементами и формирующих структуру документа. Например, следующий текст, являясь вполне правильным XML- документом, будет абсолютно бессмысленным:
<country><title>Russia</title><city><title>Novosibirsk</country></title></city>
Для того, чтобы обеспечить проверку корректности XML- документов, необходимо использовать анализаторы, производящие такую проверку и называемые верифицирующими.
На сегодняшний день существует два способа контроля правильности XML- документа: DTD - определения(Document Type Definition) и схемы данных(Semantic Schema). Более подробно об использовании DTD и схемах мы поговорим в следующих разделах. В отличии от SGML, определение DTD- правил в XML не является необходимостью, и это обстоятельство позволяет нам создавать любые XML- документы, не ломая пока голову над весьма непростым синтаксисом DTD.
Свойства и методы документа(объект XML Document)
| Свойство, доступное для записи и чтения. Задает или возвращает URL обрабатываемого документа. В случае изменения этого свойства текущий документ уничтожается и начинается загрузка нового по указанному URL |
| Возвращает корневой элемент XML- документа |
| Свойство, доступное для записи и чтения.Возвращает или устанавливает название текущее кодировочной таблицы согласно требованиям ISO. |
| Возвращает номер версии XML |
| Возвращает содержимое элемента !DOCTYPE |
| Метод, позволяющий создать новый элемент, который будет добавлен в качестве дочернего для текущего элемента дерева. В качестве первого параметра задается тип элемента, в качестве второго - название элемента xml.createElement(0,"new_element") |
| Возвращает размер XML- документа. Это свойство в C++- версии анализатора еще не реализовано |
| Возвращает дату последнего изменения XML- документа. Это свойство в C++- версии анализатора еще не реализовано |
| Возвращает дату последнего обновления XML- документа. Это свойство в C++- версии анализатора еще не реализовано |
| Возвращает MIME-тип(MIME- Multipurpose Internet Mail Extension, RFC 1341).Это свойство в C++- версии анализатора еще не реализовано |
Ниже приведен фрагмент JavaScript- сценария, использующего эти методы и свойства для вывода информации о текущем документе: var xmldoc = new ActiveXObject("msxml"); var xmlsrc = "http://localhost/xml/journal.xml"; xmldoc.URL = xmlsrc; function viewProperties(){ this.document.writeln('<center><table width=90% >'); this.document.writeln('<tr>'); this.document.writeln('<td align="center" bgcolor="silver">Document URL</td> <td align="center">'+xmldoc.URL+'</td></tr>'); this.document.writeln('<tr>'); this.document.writeln('<td align="center" bgcolor="silver">Document root</td> <td align="center">'+xmldoc.root+'</td></tr>'); this.document.writeln('<tr>'); this.document.writeln('<td align="center" bgcolor="silver">Document doctype</td> <td align="center">'+xmldoc.doctype+'</td></tr>'); this.document.writeln('<tr>'); this.document.writeln('<td align="center" bgcolor="silver">Document version</td> <td align="center">'+xmldoc.version+'</td></tr>'); this.document.writeln('<tr>'); this.document.writeln('<td align="center" bgcolor="silver">Document charset</td> <td align="center">'+xmldoc.charset+'</td></tr>'); this.document.writeln('</table></center>'); }
Свойства и методы элементов документа
| Возвращает тип элемента. Это свойство может быть использовано для того, чтобы разделить имена тэгов и данные, содержащиеся внутри них. В данной версии анализатора определены следующие типы элементов: 0 - элемент 1 - текст 2 - комментарий 3 - Document 4 - DTD |
| Возвращает или устанавливает название тэга(в виде строки с символами, приведенными к верхнему регистру). Названия метатэгов(например, <?xml?>) начинаются с символа ?. Названия тэгов комментариев начинаются с символа !. |
| Возвращает текстовое содержимое элементов и комментариев. |
| Добавление нового дочернего элемента и всех его потомков в текущую ветвь дерева. В качестве первого параметра этой функции необходимо передать объект типа Element, который затем будет помещен в список дочерних элементов. Также необходимо задать индекс нового элемента в списке и в качестве последнего параметра обязательно передать значение -1. Т.к. в данной модели любой элемент в документе может иметь ссылку только на один родительский элемент, при выполнении данной процедуры у добавляемого объекта старая ссылка на родительский элемент теряется. Используя это свойство, можно перемещать элементы из одного XML- документа в другое, но том случае, если у дочерних ссылок перемещаемого элемента существуют внешние ссылки или сами дочерние элементы ссылаются на внешние возможно возникновение ошибки elem.addChild(elem.children.item().children.item(0),0,-1) |
| Удаляет дочерний элемент и всех его потомков. Элементы остаются в памяти и могут быть вновь добавлены к дереву при помощи метода addChild(). elem.removeChild(elem.children.item(1)) |
| Возвращает указатель на текущий родительский элемент. Ссылки на родительский элемент имеют все элементы, за исключением корневого. |
| Возвращает значение указанного атрибута в виде текстовой строки. elem.getAttribute("color") |
| Устанавливает указанный атрибут и его значение. Прежнее значение атрибута теряется elem.setAttribute("color","red") |
| Уничтожает указанный атрибут elem.removeAttribute("color") |
| Возвращает ассоциированный список дочерних элементов(коллекцию). Такой список позволяет приложению получать нужные элементы как по названию, так и по порядковому номеру при помощи метода item(). В том случае, если потомков у текущего элемента нет, функция возвратит null |
Пример использования
Вот пример использования описанных функций: <script language="javascript"> <!-- var xmldoc = new ActiveXObject("msxml"); var xmlsrc = "http://localhost/xml/sample.xml"; function parse(root){ var i=0; if(root.type==0){ this.document.writeln('<UL>Current tag is '+root.tagName+' (parent is '+root.parent+'). '); }else if(root.type==1){ this.document.writeln('<LI>It is a text of '+root.parent.tagName+' element: <i>'+root.text+'</i></LI>'); }else{ this.document.writeln('<br><br>Error'); } if(root.children!=null){ this.document.writeln('It consist of '+root.children.length+' elements:'); for(i=0;i<root.children.length;i++){ parse(root.children.item(i)); } } else{ this.document.writeln('</UL>'); } } function viewDocument(){ xmldoc.URL = xmlsrc; this.document.writeln('<body bgcolor="white">'); this.document.writeln('<p><center><hr width=80%>XML sample page <hr width=80%></center><p>'); parse(xmldoc.root); this.document.writeln('</body>'); } viewDocument(); //--> </script>
Как видно из примера, в процессе обработки XML- документа необходимо рекурсивно обходить все ветви создаваемого анализатором дерева, причем, на каждом шаге возможны следующие ситуации:
Встретился новый элемент. В этом случае его название(задаваемое тэгом) доступно при помощи свойства tagName, а содержимое - свойством text. У любого непустого элемента существует хотя бы один потомок, представляющий собой содержимое этого элемента(в этом отличие представленной объектной модели msxml от реальной структуры документа - в XML под элементом понимается как название тэга, так и текстовое содержимое его) Встретилось текстовое поле. Это поле может быть либо комментарием, либо просто текстом, содержащемся в текущем элементе
Для обработки потомков текущего элемента используется метод item(), который вызывается в цикле столько раз, сколько потомков у текущего элемента. Обработка каждого дочернего элемента осуществляется вызовом этой же функции, в чем и заключается рекурсия.
XML-генераторы
XML документы могут служить промежуточным форматом для передачи информации от одного приложения к другому (например, как результат запроса к базе данных), поэтому их содержимое иногда генерируется и обрабатывается программами автоматически. Далеко не всегда XML документ нужно создавать вручную.
Пусть, например, нашей задачей является создание формата хранения данных регистрации каких-то происходящих в системе событий (log-файла). В простейшем случае можно ограничиться фиксированием успешных и ошибочных запросов к нашим ресурсам - в таком документе должна присутствовать информация о времени произошедшего события, его результате (удача/ошибка), IP адресе источника запроса, URI ресурса и коде результата.
Наш XML документ может выглядеть следующим образом: <?xml version="1.0" encoding="koi-8"?> <log> <event date=" 27/May/1999:02:32:46 " result="success"> <ip-from> 195.151.62.18 </ip-from> <method>GET</method> <url-to> /misc/</url-to> <response>200</response> </event> <event date=" 27/May/1999:02:41:47 " result="success"> <ip-from> 195.209.248.12 </ip-from> <method>GET</method> <url-to> /soft.htm</url-to> <response>200</response> </event> </log>
Структура документа довольно проста - корневым в данном случае является элемент log, каждое произошедшее событие фиксируется в элементе event и описывается при помощи его атрибутов(date - время и result - тип события ) и внутренних элементов (method - метод доступа, ip-from - адрес источника, url-to - запрашиваемый ресурс, response - код ответа). Генерацией этого документа может заниматься, например, модуль аутентификации запросов в систему, а использованием - программа обработки регистрационных данных (log viewer).
