Что же это такое?
Рассмотрение XML-RPC проведем на упрощенном тестовом примере. Для снижения затрат мы разворачиваем систему, где на один компьютер (сервер) ставится мощное ПО для перевода, проверка синтаксиса и грамматики, а все клиенты обращаются к нему посредством XML-RPC. (Конечно, этот пример выдуман, чтобы легче было познакомить читателя с технологией - но, господа программисты, кто мешает реально сделать такую систему?)
Сообщение XML-RPC передается методом POST-протокола HTTP. Сообщения бывают трех типов: запрос, ответ и сообщение об ошибке.
| XML-RPC запрос | Описание |
| POST /RPC2 HTTP/1.0 User-Agent: MyAPP-Word/5.1.2 (WinNT) Host: server.localnet.com Content-Type: text/xml Content-length: 172 <? xml version="1.0"?> <methodCall> <methodName>CheckWord</methodName> <params> <param> <value><string>проверка</string></value> </param> </params> </methodCall> | Сначала идет стандартный заголовок http-запроса. MIME-тип данных должен быть text/xml, длина также обязательно должна присутствовать и иметь корректное значение, равное длине передаваемого сообщения. Стандартный заголовок любого корректного XML-документа. Корневой узел. Не допускается вложенности тегов <methodCall> - значит, одним запросом мы можем вызвать только один метод. Тег <methodName> указывает на объект и название метода, который вызывается. Можно указывать так, как принято в языках программирования вызывать свойства класса: имя метода - через точку после имени класса. Можно также передавать пути и имя программы. Мы вызываем метод CheckWord объекта OrfoCheck. В секции <params> задаются параметры, которые передаются в метод. Секция может содержать произвольное число подэлементов <param>, содержащих параметр, который описывается тегом <value>. Параметры и типы данных мы рассмотрим чуть дальше. В нашем варианте методу передается один параметр, слово (оно заключено в тег <string>), которое надо проверить на правильность написания. Все теги, согласно спецификации XML, должны иметь соответствующие закрывающие элементы - в XML-RPC нет одиночных тегов. |
На сцене - XML-RPC
RPC - удаленный вызов процедур с помощью XML. Сама методика удаленного вызова процедуры известна давно и используется в таких технологиях, как DCOM, SOAP, CORBA. RPC предназначен для построения распределенных клиент-серверных приложений. Это дает возможность строить приложения, которые работают в гетерогенных сетях, например на компьютерах различных систем, производить удаленную обработку данных и управление удаленными приложениями.
Приведем сильно упрощенный пример. Приложение, выполняя обработку некоторых данных на локальной машине, обращается к некоторой процедуре. Если ее реализация присутствует в программе, то процедура (функция) принимает параметры, выполняет действие и возвращает некоторые данные. Если это удаленный вызов, мы должны знать, где будет исполняться наша процедура. Запрос на выполнение процедуры вместе с параметрами записывается в виде XML-документа и посредством HTTP передается по сети на другой компьютер, где из XML-документа извлекается имя процедуры, параметры и прочая нужная информация. После завершения работы процедуры формируется ответ (например, возвращаемые данные) - и он передается компьютеру, пославшему запрос. Заметим, что для прикладной программы все действия совершенно прозрачны.
По этому принципу функционируют все системы, и различия в реализации и процедуре обмена не оказывают существенного влияния на его суть.
Хорошо, предположим, у нас есть возможность удаленно вызывать процедуры и функции - чего же нам еще? А вот чего. Формат обмена данными при классической модели RPC (DCOM, CORBA) остается бинарным - а значит, работать с ним сложнее, он не слишком подходит, если надо организовать работу распределенной системы, где между отдельными участками сети стоят firewall/прокси-серверы. Технология DCOM, например, реализована для Windows-систем, CORBA функционирует на разных платформах, но наиболее полноценна ее реализация на J2EE. Значит, всегда найдется (и действительно находится) такая конфигурация сети/платформ, чтобы для реализации распределенной системы в ней ни одна технология не подходила. Так что же делать?
Задавшись этим вопросом, компания UserLand Software Inc. создала технологию XML-RPC. Основным транспортом в ней является протокол HTTP; формат данных - XML. Это снимает ограничения, налагаемые как на конфигурацию сети, так и на маршрут следования пакетов,- вызовы XML-RPC представляют собой простой тип данных text/xml и свободно проходят сквозь шлюзы везде, где допускается ретрансляция http-трафика.
У новой технологии есть и другие преимущества. Применение XML для описания данных позволило упростить программные средства создания распределенных приложений, снизились требования к клиенту и серверу. Например, теперь есть возможность связать веб-планшет с сервером на работе и с домашним компьютером. Программы разбора (парсинга) XML сейчас существуют практически для всех операционных систем и на всех языках программирования - следовательно, препятствий для внедрения технологии вроде бы нет.
Окончательный вариант
Теперь можно окончательно описать работу нашего тестового примера. Итак, приложение MyAppWord (текстовый редактор) хочет перевести на английский, например, слово "world". Программа формирует запрос к серверу, вызывая процедуру перевода TranslateWord. Процедуре передается структура, содержащая слово, которое следует перевести, и направление перевода, которое задается символьной строкой - "en-ru".
MyAppWord
Запрос:
POST /RPC2 HTTP/1.0
User-Agent: MyAppWord/5.1.2 (WinNT)
Host: server.localnet.com
Content-Type: text/xml
Content-length: 172
<? xml version="1.0"?>
<methodCall>
<methodName>TranslateWord</methodName>
<params>
<param>
<value>
<struct>
<member>
<name>Word</name>
<value><string>world</string></value>
</member>
<member>
<name>typetranslate</name>
<value><string>en-ru</string></value>
</member>
</struct>
</param>
</params>
</methodCall>
Сервер, приняв наш запрос, передает его программе-демону, которая производит парсинг запроса, выделяет из него нужные данные и, найдя (например, по таблице) ссылку на нужный метод, вызывает его с переданными параметрами. Если тип и количество параметров правильные, то по окончании работы метода программа-демон принимает возвращенное значение, преобразует его в XML-описание и формирует ответ.
MyAppWord
Ответ:
HTTP/1.1 200 OK
Connection: close
Content-Length: 166
Content-Type: text/xml
Date: Fri, 17 Jul 1998 19:55:08 GMT
Server: MyWordCheckSerwer/5.1.2-WinNT
<? xml version="1.0"?>
<methodResponse>
<params>
<param>
<struct>
<member>
<name>WordtoTranslate</name>
<value><string>world</string></value>
</member>
<member>
<name>translatesword</name>
<value><string>мир</string></value>
</member>
<member>
<name>typetranslate</name>
<value><string>en-ru</string></value>
</member>
</struct>
</param>
</params>
</methodResponse>
MyAppWord
Сообщение об ошибке:
HTTP/1.1 200 OK
Connection: close
Content-Length: 166
Content-Type: text/xml
Date: Fri, 17 Jul 1998 19:55:08 GMT
Server: MyWordCheckSerwer/5.1.2-WinNT
<? xml version="1.0"?>
<methodResponse>
<fault>
<value>
<struct>
<member>
<name>faultCode</name>
<value><int>10</int></value>
</member>
<member>
<name>faultString</name>
<value>
<string>Перевод невозможен. Слово отсутствует в словаре.</string>
</value>
</member>
</struct>
</value></fault> </methodResponse>
Приложение получит такое сообщение, когда запрос на перевод не может быть удовлетворен, поскольку слова нет в словаре.
Хотя наш пример, на первый взгляд, кажется надуманным и простым, тем не менее, на нем показано, как можно уже сегодня использовать XML-RPC для решения конкретных задач. Конечно, его возможности намного шире, и можно, например, представить себе распределенную ОС, построенную на XML-RPC, или системы визуализации данных, построенные по архитектуре X Window, но с применением все того же XML-RPC.
Типы данных
В протоколе XML-RPC предусмотрено семь простых типов данных и два сложных, для передачи параметров методу и возвращаемых значений. Эти типы отображают основные типы данных реальных языков программирования. Более сложные типы, такие, например, как объекты, нужно передавать в двоичном виде или заменять структурами.
Целые числа - задаются тегом <i4> или <int> и представляются 4-байтовыми целыми числами со знаком. Для задания отрицательных чисел ставится знак "-", например 34, 344, -15.
Логический тип данных представляется тегом <boolean> и может иметь значения 0 (false) или 1 (true). Можно использовать как 1/0, так и символьные константы true/false.
ASCII-строка - тип данных, принимаемый по умолчанию. Представляет собой просто строку символов, заключенную в теги <string></string>. В качестве символов нельзя использовать служебные знаки "<" и "&" - их следует передавать кодами < и & соответственно.
Числа с плавающей точкой. Задаются тегом <double> и представляют собой числа с плавающей точкой двойной точности. Как разделитель целой и дробной части используется знак ",". Пробелы недопустимы. Отрицательные числа задаются знаком "-" перед числом.
Дата/время. Для передачи времени/даты служит тег <dateTime.iso8601>. Пример времени - 19980717T14:08:55 (в спецификации написано, что сервер сам должен определять, как посылать время/дату. Использовать этот тип данных, пользоваться структурой или же просто передавать дату как строку не рекомендуется).
Двоичные данные передаются в закодированном (base64) виде и описываются тегом <base64>.
Структуры. Для передачи структурированных данных можно конструировать свои структуры. Структура определяется корневым элементом <struct>, который может содержать произвольное количество элементов <member>, определяющих каждый член структуры. Член структуры описывается двумя тегами: первый, <name>, описывает имя члена, второй, <value> содержит значение члена (вместе с тегом, описывающим тип данных). Например, так описывается структура с двух строковых элементов:
<struct> <member> <name>FirstWord</name> <value><string>Hell</string></value> </member> <member> <name>SecondWord</name> <value><string>World!</string></value> </member> </struct>
Массивы. Массивы не имеют названия и описываются тегом <array>. Он содержит один элемент <data> и один или несколько дочерних элементов <value>, где задаются данные. В качестве элементов массива могут выступать любые другие типы в произвольном порядке, а также другие массивы - что позволяет описывать многомерные массивы. Так же можно описывать массив структур. Пример 4-элементного массива:
<array> <data> <value><i4>34</i4></value> <value><string>Привет, Мир!</string></value> <value><boolean>0</boolean></value> <value><i4>-34</i4></value> </data> </array>
| XML-RPC ответ | Описание |
| HTTP/1.1200 OK Connection: close Content-Length: 166 Content-Type: text/xml Date: Fri, 17 Jul 1998 19:55:08 GMT Server: MyWordCheckSerwer/5.1.2-WinNT <? xml version="1.0"?> <methodResponse> <params> <param> <value><boolean>true</boolean></value> </param> </params> </methodResponse> Тело ответа при ошибке приложения <fault> <value> <struct> <member> <name>faultCode</name> <value><int>4</int></value> </member> <member> <name>faultString</name> <value> <string>Too many рarameters.</string> </value> </member> </struct> </value> </fault> | Сначала идет стандартный заголовок http-ответа сервера. MIME-тип данных должен быть text/xml, длина также должна обязательно присутствовать и иметь корректное значение, равное длине передаваемого сообщения. Стандартный заголовок любого корректного XML-документа. Корневой узел. Не допускается вложенности тегов <methodResponse>. Теги <params> и <param> аналогичны запросу и включают один или более элементов <value>, которые содержат значение, возвращенное методом. Если сервер отвечает HTTP-кодом 200 ОК - это значит, что запрос успешно обработан. Он уведомляет лишь о том, что данные по сети переданы правильно и сервер сумел их корректно обработать. Но метод также может вернуть ошибку - и это уже будет ошибка не протокола, а логики приложения. В таком случае передается сообщение и структура, которая описывает код ошибки и текстовое объяснение. В нашем примере передается структура из двух элементов: первый элемент содержит целочисленный код ошибки (4), второй элемент - текстовая строка, описывающая ошибку (Too many рarameters - неправильное число параметров). |
XML-RPC vs SOAP
Если для реализации удаленного вызова вы используете XML, то у вас есть выбор: использовать XML-RPC или же SOAP (Simple Object Access Protocol). О последней уже написано множество статей, поэтому предлагаем только сравнить обе технологии.
Вот некоторые характеристики, которые определяют различия XML-RPC или же SOAP:
| Характеристика | XML-RPC | SOAP |
| Скалярные типы данных | + | + |
| Структуры | + | + |
| Массивы | + | + |
| Именованные массивы и структуры | - | + |
| Определяемые разработчиком кодировки | - | + |
| Определяемые разработчиком типы данных | - | + |
| Детализация ошибок | + | + |
| Легкость освоения и практического применения | + | - |
Конечно, на первый взгляд "минус" в столбце SOAP встречается только единожды. Это создает иллюзию "всереализуемости всего" в нем. Но давайте присмотримся внимательнее. Основные типы данных у обоих конкурентов одинаковые. Но в XML-RPC отсутствует возможность задавать имена для массивов и структур (все структуры и массивы являются "анонимными"). Возможно, это упущение разработчиков, но решить эту проблему можно и самому, например вводя еще одну строковую переменную с именем массива или структуры (в случае, если таких объектов много, можно завести специальный массив "имен массивов").
С "определяемыми разработчиком кодировками" ситуация уже серьезнее. Сам механизм подобного ограничения не совсем ясен - ни стандарт XML, ни, тем более, транспортный уровень (протокол HTTP) таких ограничений не имеют. Да и стремление сделать клиент/сервер XML-RPC как можно более простым тоже не привело бы к возникновению подобного ограничения. Хотя, с другой стороны, SOAP тоже не блещет поддержкой кодировок (US-ASCII, UTF-8, UTF-16). Правда, в обеих технологиях есть возможность обойти все эти недостатки сразу - тип данных base64. Но выход ли это?
Посмотрим теперь на пункт "легкость в освоении и применении". В свете сегодняшних темпов развития технологий и стандартов, особенно Web, этот пункт приобретает большую важность. Реальна ситуация, когда крупный проект начинает разрабатываться на самой передовой основе - а в конце работы новый стандарт не только "уже не новый", но и "уже не стандарт вообще". Недавно W3C опубликовала черновой вариант SOAP Version 1.2 - поверьте, и объем, и сложность документации впечатляют. Трудности возникают даже на этапе ознакомительного чтения, не говоря уже о разработке. А вот спецификация XML-RPC занимает около трех страниц А4 и предельно проста.
Да, ни одна из этих технологий не является панацеей от всех бед и не претендует на полноту. Большинство программистов и разработчиков спецификаций сходятся на том, что:
если вам нужна система для работы со сложной логикой, если вы передаете большие комплексные структуры данных, если вам нужна полная информация о клиенте, если вы хотите, чтобы запрос содержал в себе инструкции по его обработке, и, наконец, если для вас важно, чтобы за стандартом стояли гранды индустрии (Microsoft, IBM, Sun) - вам следует остановить свой выбор на SOAP; если же данные являются относительно простыми, а приложения должны работать на множестве платформ и на разных языках, если важна скорость работы и логика системы не нуждается в сложных командах - используйте XML-RPC.
XML-RPC: вызов процедур посредством XML
Александр Лозовюк,
RPC расшифровывается как Remote Procedure Call - удаленный вызов процедур с помощью XML. Как же работает XML-RPC и каковы его отличия от стандарта SOAP?
Новые спецификации W3C и IETF
В середине февраля международный консорциум W3C выпустил спецификацию "Character Model for the World Wide Web 1.0: Fundamentals" ("Символьная модель для всемирной сети, версия 1.0: основные понятия"), имеющую статус рекомендации.
Данная рекомендация - это первый документ в серии публикаций, посвященных описанию символьной модели. Авторы спецификации полагают, что она будет способствовать использованию всемирной сети всеми людьми независимо от их языка, алфавита, системы записи и культурных традиций - в соответствии с общей целью W3C, заключающейся в обеспечении универсального доступа. Одно из ключевых условий достижения этой цели - возможность передавать и обрабатывать символы в корректно определенном и хорошо понятном виде. Предлагаемая модель должна позволить пользователям всемирной сети осуществлять обмен Web-документами, подготовленными посредством различных способов письма (и на различных платформах), чтение этих документов и поиск..
В спецификации приводится общая справочная информация по обработке текстов, опирающихся на набор универсальных символов (Universal Character Set, сокр. UCS), определенных в стандартах Unicode Standard и
ISO/IEC 10646. В документе также рассмотрено использование терминов "символ" ('character'), "кодирование" ('encoding') и "строка" ('string'), выбор и идентификация кодирования символов, переключение символов и индексирование строк, описывается справочная модель обработки.
Другие документы из упомянутой выше серии публикаций включают спецификации "Character Model for the World Wide Web 1.0: Resource Identifiers" ("Символьная модель для всемирной сети, версия 1.0: идентификаторы ресурсов") и "Character Model for the World Wide Web 1.0: Normalization" ("Символьная модель для всемирной сети, версия 1.0: нормализация"). Первый документ - архитектурная спецификация, в которой содержится общая справочная информация по использованию идентификаторов ресурса и, в частности, указываются интернационализированные идентификаторы ресурса. Второй документ включает сведения о начальной унифицированной нормализации и сопоставлении идентичности строк, предназначенных для улучшения манипулирования совместимыми текстами во всемирной сети.
Помимо этого, представители консорциума заявили о поддержке двух других публикаций: "Uniform Resource Identifier (URI): Generic Syntax" ("Универсальный идентификатор ресурсов: общий синтаксис") и "Internationalized Resource Identifiers (IRIs)" ("Интернационализированные идентификаторы ресурсов"), в работе над которыми, помимо W3C, принимала участие целевая группа инженерной поддержки Internet (Internet Engineering Task Force, сокр. IETF).
Как известно, всемирная сеть определяется как универсальное, всеобъемлющее пространство, содержащее все Internet - и другие - ресурсы, указываемые с помощью универсальных идентификаторов ресурса (Uniform Resource Identifier, сокр. URI), которые иногда называют универсальными указателями ресурса (Uniform Resource Locator, сокр. URL). В
первоначальном предложении Тима Бернерса-Ли (Tim Berners-Lee) всемирная паутина состояла из относительно небольшого числа технологий, включая протокол HTTP и язык HTML. Однако, вероятно, более фундаментальными понятиями по сравнению с HTTP и HTML оказались универсальные идентификаторы ресурса, представляющие собой простые текстовые строки, указывающие на ресурсы Internet - документы, ресурсы, людей и т.д. Таким образом, универсальные идентификаторы - это "клей", который связывает всемирную паутину воедино. Что же касается интернационализированных идентификаторов ресурса, то они расширяют и усиливают этот клей, позволяя пользователям устанавливать ресурсы Web на своем родном языке.
Стоит добавить, что в ходе разработки стандартов Internet (Internet Standards Process) целевая группа инженерной поддержки Internet выпустила тысячи публикаций, в том числе приблизительно 60 стандартов Internet. Упомянутые ранее спецификации, которые в настоящий момент имеют статус стандартов, предложенных к рассмотрению (Proposed Standard) - это лишь малая часть результатов деятельности этой группы.
В первом документе описываются структура, синтаксис и разрешение универсальных идентификаторов ресурса, анализируются вопросы безопасности, нормализации и сравнения (определения эквивалентности двух идентификаторов).
Данный стандарт предназначен для использования вместо одноименной спецификации, выпущенной в 1998г. Основное отличие новой редакции - поддержка интернационализированных имен доменов ведущим компонентом универсальным идентификатором.
Одна из причин появления второй спецификации заключается в том, что, за некоторыми исключениями, многие алфавиты используют символы, отличные от A-Z. Переход от допустимых символов из подмножества US-ASCII к набору универсальных символов (Unicode/ISO 10646) разрешает разработчикам и пользователям указывать ресурсы на своих собственных языках. Кроме того, многим спецификациям W3C - XML, RDF, XHTML и SVG - необходима точная справочная информация для идентификаторов, которые поддерживают международные символы, и эта спецификация обеспечивает эту критически важную информацию.
В соответствие с новым стандартом, каждый универсальный идентификатор ресурса - это уже интернационализированный идентификатор. В результате, при поиске информации в сети пользователям не нужно предпринимать каких-либо особенных действий. В документе также обсуждается, как преобразовывать интернационализированный идентификатор в универсальный идентификатор ресурса для разрешения на существующих системах, рассматриваются такие вопросы, как особый случай двунаправленных интернационализированных идентификаторов, эквивалентность интернационализированных идентификаторов, их использование в различных ситуациях.
UDDI: долгожданный стандарт OASIS
За несколько дней до появление рассмотренной выше рекомендации консорциума W3C "Character Model for the World Wide Web 1.0: Fundamentals" международная организация OASIS утвердила в качестве стандарта третью версию спецификации UDDI (Universal Description, Discovery and Integration, Универсальное описание, обнаружение и интеграция), которая разрабатывалась с середины 2002г. В данной спецификации определяются Web-сервисы, структуры данных и поведение всех экземпляров регистра UDDI. В ней описывается регистр Web-сервисов и программных интерфейсов, предназначенных для публикации, извлечения информации об описанных в них сервисах и управления этой информацией.
В соответствие с правилами разработки и утверждения стандартов OASIS, семь членов организации предоставили подтверждение успешного использования UDDI 3.
Как отмечается во вступлении к спецификации, Web-сервисы имеют смысл только в том случае, если потенциальные пользователи могут найти информацию, достаточную для их выполнения. Предназначение UDDI - это определение набора сервисов, поддерживающих описание и обнаружение: 1) бизнесов, организаций и прочих поставщиков Web-сервисов; 2) доступных Web-сервисов; 3) технических интерфейсов, которые могут быть использованы для доступа к этим сервисам. Благодаря тому, что стандарт UDDI опирается на ряд отраслевых спецификаций, включая HTTP, XML, XML Schema (Схема XML) и SOAP (Simple Object Access Protocol, Простой протокол доступа к объектам), он обеспечивает совместимую базовую инфраструктуру для основанных на web-сервисах программных средах как для общедоступных сервисов, так и для развернутых для использования исключительно внутри организации.
Протокол UDDI - это центральный элемент группы связанных между собой спецификаций, которые сообща описывают Web-сервисы. В третьей версии стандарта определен стандартный метод публикации и обнаружения сетевых программных компонентов сервис-ориентированной архитектуры. Основная цель этой версии стандарта - поддержка безопасного взаимодействия приватных и открытых реализаций как главного элемента сервис-ориентированной инфраструктуры.
Некоторые функциональные возможности, поддержанные в спецификации UDDI, получили дальнейшее развитие в третьей версии; основное, архитектурное отличие этой редакции стандарта - концепция "присоединение регистра" ('registry affiliation'). Это изменение символизирует растущее понимание того, что UDDI является одним элементом из более крупного набора технологий Web-сервисов, которые поддерживают проектирование и операции бесчисленных программных приложений, применяемых в организациях.
Понятие присоединение означает использование UDDI для поддержки разнообразных сетевых/инфраструктурных топологий. Эта возможность появились в результате расширения автономного, основанного на одном регистре подхода до подхода, включающего иерархический, равноправный, переданный и другие регистры. Одним словом, структура регистра (регистры) UDDI теперь может воспроизводить реалии и отношения базовых бизнес-процессов, которые она поддерживает.
Таким образом, в новой версии стандарта реализуются несколько моделей взаимодействия регистров. С помощью таких механизмов, как "публикация и подписка" (publish - subscribe) и репликация среди равноправных узлов регистра, информация в серверах UDDI может быть полностью доступной, частично приватной или даже полностью приватной и изолированной от общедоступной сети.
XML-стандарты: работа не прекращается
Intersoft Lab
Одним из потрясающих достоинств языка XML, которое как ни странно упоминается достаточно редко, является удивительная "бизнес-гибкость" XML, появляющаяся в том, что XML постоянно находит новое практическое применение. Очевидно, в значительной мере именно поэтому и продолжается деятельность международных организацией, занимающихся разработкой различных XML-спецификаций.
Близкие работы
Нам известно очень небольшое число работ посвященных методам хранения XML данных с возможность оптимизации под приложение. В системе OrientStore [] был предложен подход, в котором комбинируются способы представления данных, предложенные в системах Natix [] и Senda []. Однако подход системы OrientStore не предполагает анализ запросов и основан только на анализе схемы данных. Кроме того, внутреннее представление поддерживает все возможности модели данных XQuery, что зачастую является избыточным, как мы показали в этой статье.
Подходы к хранению данных, предложенные в системах LegoDB [, ] или XCacheDB [21], очень близки к подходам, предложенным в этой статье. Тем не менее, эти системы полностью построены над реляционными системами, что накладывает свои ограничения и вызывает дополнительные накладные расходы.
Предложенные в этой статье идеи не следует путать с так называемым подходом компонентных баз данных (component databases) [, ]. По нашему мнению, компонентные база данных являются общим подходом, который не допускает эффективной реализации на практике. В отличие от компонентных баз данных, мы не предлагаем общей системы, предназначенной для принципиально различных классов приложений (таких как OLTP, OLAP и другие) и принципиально различных аппаратных платформ (таких как PDA, персональные компьютеры, серверы и другие). Предложенные в этой статье идеи ограничиваются расширением оптимизации запросов на оптимизацию структур хранения с целью избавления от избыточных свойств модели данных XQuery.
Литература
XQuery 1.0: An XML Query Language. W3C Recommendation 23 January 2007, T. Fiebig, S. Helmer et al. Anatomy of a Native XML Base Management System, The VLDB Journal 11/ 4, 2002 M. Nicola, B. van der Linden. Native XML support in DB2 universal database. In Proceedings of the VLDB, Trondheim, Norway, 2005 M. Grinev, A. Fomichev, S. Kuznetsov, K. Antipin, A. Boldakov, D. Lizorkin, L. Novak, M. Rekouts, P. Pleshachkov. Sedna: A Native XML DBMS, M. Haustein, T. Harder. An efficient infrastructure for native transactional XML processing. Data Knowledge Eng., June 2007 E. Ehrli. Walkthrough: Word 2007 XML Format Microsoft Corporation, June 2006 Издательство “Большая Российская Энциклопедия", S. Chandrasekaran, R. Bamford. Shared Cache - The Future of Parallel Databases. In Proceedings of the ICDE, 2003. A. Fomichev, M. Grinev, S Kuznetsov. Descriptive Schema Driven XML Storage. Technical Report, MODIS, Institute for System Programming of the Russian Academy of Sciences, 2004 Join methods in partitioned database environments, IBM DB2 Database Information Center, J. Dean, S. Ghemawat. MapReduce: Simplified Data Processing on Large Clusters. OSDI, December 2004 H. Berenson, P. Bernstein, J. Gray, J. Melton, E. O'Neil, P. O'Neil. A Critique of ANSI SQL Isolation Levels. SIGMOD International Conference on Management of Data San Jose, May 1995 X. Meng, D. Luo, M. Lee, J. An. OrientStore: A Schema Based Native XML Storage System. In Proceedings of the VLDB, 2003 P. Bohannon, J. Freire, J. R. Haritsa, M. Ramanath, P. Roy, J. Simeon: Bridging the XML Relational Divide with LegoDB. In Proceedings of the ICDE, 2003. M. Ramanath, J. Freire, J. Haritsa, and P. Roy. Searching for Efficient XML to Relational Mappings. Technical Report, DSL/SERC, Indian Institute of Science, 2003 M. Seltzer. Beyond Relational Databases: There is More to Data Access than SQL, ACM Queue 3/3, April 2005. S. Chaudhuri, G. Weikum. Rethinking Database System Architecture: Towards a Self-Tuning RISC-Style Database System. The VLDB Journal, 2000 D. Florescu et al. The BEA Streaming XQuery Processor. The VLDB Journal 13/3, September 2004 Q. Li, B. Moon. Indexing and Querying XML Data for Regular Path Expressions. Proceedings of the VLDB Conference, Roma, Italy, 2001 H. Garcia-Molina, J. Ullman, J. Widom. Database Systems: The Complete Book. Prentice Hall, October 2001
Мотивирующие примеры
Для демонстрации основных преимуществ и различных аспектов предлагаемого подхода мы выбрали упрощенную версию приложения, которое используется для создания электронной версии Большой Российской Энциклопедии (БРЭ) []. Иллюстрации 1 и 2 показывают фрагменты XML-документа, содержащего статью энциклопедии, и его описывающей схемы соответственно. По определению [] описывающая схема содержит ровно один путь для каждого пути в документе, и каждый путь в описывающей схеме является путем хотя бы в одном из документов. В этом примере документ представляет собой том энциклопедии, который содержит, по крайней мере, три статьи. Каждая статья состоит из заголовка, списка авторов и тела, которое содержит текст статьи. <volume> <article id="2"> <title>Cyclotron resonance</title> <authors> <author>Century S.Edelman.</author> <author>I. Kaganov</author> </authors> <body> <p> <b>Cyclotron resonance</b> Selective absorption of electromagnetic... <link idref="1">Effective weight</link> <p> ... <i> ... </i> ... <b> ... </b> ... </p> <link idref="6">Lorentz force</link>... </p> </body> </article> ... <article id="3"> <title>Dorfman Jacob Grigorevich</title> <authors> <author>I. Ivanov</author> </authors> <body> <p> <b>Dorfman Jacob Grigorevich</b> the Soviet physicist, the doctor... <link idref="2">Cyclotron resonance</link> ... <i> ... </i>... </p> </body> </article> ... <article id="1"> <title>Effective weight</title> <authors> <author>I. Kaganov</author> </authors> <body> ... </body> </article> </volume>
Рис. 1. Фрагмент Большой Российской Энциклопедии.

Рис. 2. Описывающая схема Большой Российской Энциклопедии
Для обработки энциклопедии в приложении используются набор запросов, которые являются предопределенными и могут изменяться только при переходе к новой версии системы. Ниже приводится список основных запросов.
(Q1) Получение списка названий статей declare ordering unordered; volume/article/title
(Q2) Получение статьи по идентификатору declare ordering unordered; volume/article[@id eq “...”]
(Q3) Получение статьи по названию declare ordering unordered; volume/article[title eq “...”]
(Q4) Перечислить названия статьей, на которые ссылается статья с идентификатором равным 1 declare ordering unordered; for $i in volume/article [@id eq “1”]//link return volume/article [@id eq $i/@idref]/title
(Q5) Перечислить звания статей, которые ссылаются на статью с названием «Атом» declare ordering unordered; let $j := volume/article [title eq “atom”]/@id for $i in volume/article where $i//link[@idref eq $j] return $i/title
Рассматривая этот пример, мы можем выделить несколько интересных моментов, которые являются общими для многих приложений.
Элементы визуализации. Контент-ориентированные XML документы часто содержат большое количество XML-элементов, которые обрабатываются исключительно front-end-приложениями (такими как браузер или текстовый процессор) при отображении документа. В приведенном выше примере к таким элементам относятся p, i, b. Такие элементы, как правило, не адресуются запросами. Однако при хранении XML-документов с использование любого общего подхода такие элементы будут представляться таким же образом, как и семантически значимые элементы. Реляционные данные. Помимо элементов визуализации в приведенном примере можно выделить элементы и атрибуты с простыми значениями (например, атрибуты id, idef и title element), которые адресуются запросами. При этом значения этих элементов и атрибутов используются только как промежуточные данные при вычислении запросов в том смысле, что это эти элементы не извлекаются сами по себе, а только как часть другого элемента (например, атрибут id используется для нахождения статьи и извлекается из базы данных только как часть статьи). Порядок узлов документа (document order). По умолчанию результат вычисления запроса неявно сортируется в порядке узлов в документе. Однако очень часто этот порядок не имеет никакого значения для приложения. Например, в рассматриваемом примере не имеет смысла взаимный порядок следования названия статьи и авторов. В приведенных запросах неявная сортировка выключается в прологе. Известные наперед запросы (рабочая нагрузка). В приведенном приложении все запросы известны еще на этапе его создания, то есть система не поддерживает ad hoc запросов к данным. Это позволяет нам, в частности, построить список путевых выражений, которые составляют основу всех этих запросов: volume/article, volume/article/link, volume/article/title.
Далее в статье мы покажем, как приведенные выше соображения могут быть использованы для выбора структур хранения и планов выполнения запросов.
Описание подхода
Для реализации предлагаемого подхода необходимо решить две основные задачи: разработать методы выбора структур хранения для наперед известной и неизменной рабочей нагрузки; разработать методы реорганизации структур хранения на случай изменения рабочей нагрузки. Как мы уже отмечали выше, предполагается, что для большинства приложений рабочая нагрузка (то есть запросы и операции модификации) известна заранее и не подвержена частым изменениям. В следующих подразделах мы рассматриваем каждый из этих методов.

Рис. 3. Различные способы представления данных
Ориентированные на приложения методы хранения XML-данных
,
Труды Института системного программирования РАН
Представление данных физического уровня
В этом разделе мы даем обзор основных идей для создания перестраиваемого внутреннего представления XML-данных, оптимизированного под заданную рабочую нагрузку.
Вернемся к примеру, приведенному в разд. 2. Описывающая схема используется для группировки XML-узлов по путям в документе. Для каждой группы узлов оптимальный способ хранения выбирается с учетом нагрузки (рис. 3, a-c):
Дискриптор узла (node descriptor). Каждый узел в группе может быть сохранен как дескриптор узла, который имеет прямые указатели на детей, родителей и братьев. Это дает возможность эффективной навигации для вычисления структурных путевых выражений []. Кроме того, в этом подходе может быть использована нумерующая схема [, ]. Каждый дескриптор узла содержит метку номерующей схемы (nid). Основное преимущество использования нумерующей схемы состоит в быстром определении связей предок-потомок между любой парой узлов. Нумерующая схема может быть также использована для определения связей, заданных порядком узлов в документе (document order relationship). Значения, упакованные в дескриптор узла. Для некоторых узлов могут быть использованы структуры, схожие с записями, используемыми при хранении реляционных данных []. Запись упаковывается в дескриптор узла (как значения id и title, показанные на рисунке 3, b). Такое “уплощение” данных дает несколько преимуществ. Во-первых, мы получаем практически максимально компактное представление за счет избавления от лишних указателей. Во-вторых, ускоряется выполнение путевых выражений. Особенно тех, которые накладывают условия на упакованные узлы (например, //article[@id eq “1”]). В-третьих, существенно ускоряется скорость сериализации данных. Узлы, упакованные в текст. Узлы, которые не адресуются запросами (например, элементы визуализации) могут храниться в сериализованном текстовом виде. Это позволяет существенно сэкономить место и увеличить скорость сериализации. Как упоминалось в разд. 3, этот подход не исключает полностью возможность запрашивать элементы из текстового представления, поскольку может быть использован механизм разбора текстового представления на лету. Тестовое представление может содержать заглушки (placeholders) для ссылок на узлы, сохраненные с использование двух приведенных выше методов.

Рис. 4. Пример внутреннего представления данных
На рис. 4 показан план хранения для примера, приведенного в разд. 2. В соответствии с этим планом получается следующее:
Узлы article и link представляются в структурном виде с использованием дескрипторов узлов. Это связано с тем, что эти узлы напрямую запрашиваются и сериализуются в запросах Q1-Q5. При этом метки описывающей схемы и указатели на братьев не хранятся, поскольку они не используются для выполнения запросов. Атрибуты id и idref упакованы в дескрипторы родительских узлов, поскольку по ним производится поиск для извлечения этих родительских узлов. Узел title запрашивается и сериализуется в путевых выражениях запросов Q1-Q5, поэтому он также «уплощается». Узлы author и другие дети узла article упакованы в текстовые представления. При сериализации узла article, заглушки #id, #title и #link заменяются полями id, title и link соответственно.
Реорганизация структур хранения при изменении приложения
В случае изменения приложения (то есть изменения рабочей нагрузки) в общем случае необходимо полностью перестраивать хранимые данные с целью изменения структуры их хранения. При этом политика реорганизации может быть достаточно гибкой. Во-первых, частота, с которой производится реорганизация, может быть сделан зависимой от выбранного уровня оптимизации, который задается в приложении. Во-вторых, реорганизация будет требоваться не так часто, как это может показаться на первый взгляд. В самом деле, мало вероятно, что новые запросы, которые обращены к «реляционным» XML-данным начнут использовать ссылки на братьев (sibling pointers), которые были удалены на этапе компиляции плана хранения.
Тем не менее, в общем случае реорганизация все равно может потребоваться. Реорганизация может проводиться следующим образом. Вся база данных целиком может быть перестроена с использование массивно-параллельных распределенных вычислений. На современном оборудовании такое перестроение базы данных небольшого и даже среднего объема может быть осуществлено за приемлемое время, равное одному прочтению базы данных с диска.
Как отмечалось выше, «уплощение» структур хранения облегчает создание распределенных баз данных. Если база данных является распределенной, то такая перестройка может быть произведена еще быстрее. В простом случае (когда не были использованы методы оптимизации распределенных баз данных, например, collocated join []) перестройка может быть выполнена параллельно и независимо для каждого узла распределенной базы данных. В более сложном случае (данные распределены по узлам для возможности использовать collocated join) могут быть применены методы, подобные map-reduce [], для перераспределения данных.
При реорганизации базы данных существует две основные альтернативы. Во-первых, простое решение состоит в остановке базы данных на время перестройки. Если предположить, что для малых и средних баз данных перестройка не займет много времени, то такое решение приемлемо для многих приложений и может осуществляться в ночное время. Более продвинутое решение состоит в использовании механизма теневых страниц (или snapshot isolation []) для реорганизации базы данных без ее остановки.
является стандартной моделью данных для
Модель данных XQuery [] является стандартной моделью данных для работы со слабоструктурированными данными, представленными в формате XML. Поддержка слабоструктурированных данных делает эту модель достаточно универсальной и пригодной для преставления данных различной степени структурированности от регулярных реляционных данных до текстовых документов с размытой структурой.
Оборотной стороной такой универсальности является достаточно низкая эффективность существующих реализаций. На сегодняшний день уже сложился ряд подходов [, , , ] к реализации модели данных, но каждый из этих подходов обладает очевидными преимуществами и недостатками, что делает эти подходы применимыми только для достаточно узких классов приложений. Более того, модель данных XQuery поддерживает возможности, которые являются избыточными для каждого конкретного вида приложения.
Например, предположим, что приложение использует XML для представления реляционных данных. Запросы к таким данным обычно не требуют поддержки таких возможностей модели данных как братские (sibling) и родительские (parent) оси или порядок узлов в документе (document order).
Другой пример – это запросы к контент-ориентированным XML-данным, таким как энциклопедические статьи [] или текстовый документ, представленный в формате Microsoft Word XML []. Зачастую такие запросы не адресуют XML-элементы, предназначенные для описания способов визуализации данных (примеры такие элементов: para, bold, emphasize и другие, которые составляют, как правило, большую часть элементов в документе), но адресуют семантически значимые элементы, такие как author, дата, библиография. Следовательно, элементы визуализации могут быть представлены на уровне хранения в сжатом незапрашиваемом виде для увеличения скорости операций модификации и сериализации XML данных (под сериализацией здесь и далее мы понимаем процесс трансляции внутреннего представления данных в строковое представление, соответствующее формату XML).
Приведенные выше рассуждения позволяют нам прийти к выводу, что эффективное внутреннее представление и обработка XML-данных не могут быть достигнуты с использованием какого-либо общего подхода. По нашему мнению, единственно возможным подходом, способным обеспечить высокую эффективность для такой универсальной модели данных, является выбор способов внутреннего представления и методов обработки данных под потребности конкретного приложения. При этом достаточной информацией для описания потребностей является схема XML-данных и рабочая нагрузка в виде возможных запросов и операций модификации данных.
То есть мы предлагаем пойти дальше построения планов выполнения запросов при фиксированных структурах хранения данных, как это делается в большинстве современных систем управления XML-данными, и, кроме того, выбирать структуры хранения данных, необходимые для эффективного выполнения запросов и модификаций для данного приложения. Такой подход позволит поддерживать XQuery модель данных на логическом уровне, но избежать излишних накладных расходов на физическом уровне хранения данных.
С использованием такого подхода можно добиться эффективности обработки регулярных реляционных данных в формате XML, сопоставимой с эффективностью, которая обеспечивается реляционными базами данных. При этом контент-ориентированные данные будут обрабатываться с эффективностью, сопоставимой с эффективностью систем хранения текстовых документов. В данной статье мы описываем наши первые результаты по разработки таких методов хранения и обработки XML-данных.
Статья имеет следующую структуру. В следующем разделе мы рассматриваем примеры, демонстрирующие преимущества предлагаемого подхода. В разд. 3 дается обзорное описание подхода. В разд. 4 описывается физическое представление данных и иллюстрируется на примерах. Разд. 5 посвящен обзору близких работ и существующих подходов хранения XML-данных. В заключительном, шестом разделе мы намечаем пути дальнейших исследований.
Выбор структур хранения ориентированных на приложение
Имея заранее известную рабочую нагрузку, мы компилируем планы выполнения запросов и соответствующий план хранения данных для заданной нагрузки. В этих планах возможности языка XQuery, которые являются избыточными для поддержки требуемых запросов, не поддерживаются при выполнении. Для построения плана хранения мы используем следующие основные методы:
Комбинирование структурного и текстового представления данных. Как уже упоминалось выше, большинство элементов в контент-ориентированных XML документах никогда не адресуются запросами. Нами был разработан метод анализа запросов, позволяющий выявить узлы документов, которые необходимо хранить в структурном представлении (т.е. поддерживая необходимые указатели для навигации между узлами документов) для возможности вычислить все запросы эффективным способом. Все остальные элементы (как правило, это элементы визуализации) сохраняются в текстовом представлении в виде текстовых узлов XML модели данных.
Разработанный метод является достаточно гибким и не ограничивается сохранением всего XML поддерева в виде текста. Элементы со структурным представлением могут иметь в качестве детей элементы с текстовым представлением, которые в свою очередь содержат в качестве детей элементы со структурным представлением. Мы также расширили этот подход для хранения в текстовом представлении некоторых элементов, адресуемых запросом, но по которым не производится поиск. Например, рассмотрим запрос «найти имена все сотрудников старше 60 лет». В этом запросе поиск производится по элементу «возраст» и этот элемент имеет смысл хранить в структурном виде. В то же время элемент «имя» можно хранить в текстовом виде как часть элемента «сотрудник», поскольку предполагается, что в результате поиска обычно возвращается небольшое число элементов, и для них извлечение имени из текстового представления через разбор на лету не является дорогостоящей операцией для всех найденных сотрудников. Для эффективного разбора на лету предлагается использовать методы потоковой обработки XML []. Комбинирование методов кластеризации узлов в блоках внешней памяти. Кластеризация по описывающей схеме, используемая в Sedna XML Database [], может быть использована совместно с методом хранения рядом детей и родителей, который используется в системах Natix и DB2 [, ]. Выбор способа кластеризации для различных групп узлов производится на основе анализа запросов. Комбинирование этих двух методов должно дать существенный выигрыш в производительности. Исключение избыточных структур и выравнивание вложенности. Анализируя запросы, можно установить, какие структуры являются избыточными для их выполнения. Главным образом, можно удалять излишние указатели и группирующие элементы. Например, реляционные XML-данные могут быть сохранены в виде компактных записей близко к тому, как они хранятся в реляционных системах. Такие записи не имеют такую же строгую структуру, как в реляционных системах, поскольку необходимо поддерживать возможность нерегулярности в данных, но группировка элементов в записи существенно повышает эффективность системы, так как сокращается количество блоков, которые необходимо прочитать.
Подобное «уплощение» данных можно проводить и в ряде других случаев для исключения промежуточных элементов. Например, если элемент «сотрудник» содержит элемент «адрес», содержащий, в свою очередь, элементы «улицы» и «дом», то элемент адрес может быть исключен, если на его уровне нет элементов с именем «улицы» и «дом», которые могут значить что-либо другое.
Обратим внимание, что метод не приводит к потере или размножению данных, а только исключает излишние структурные элементы, однако он может быть естественным образом расширен использованием проекции данных выполняемой при загрузке или модификации данных или поддержкой материализованных представлений. Проекции могут быть построены по анализу путевых выражений или предикатов с константами.
Кроме того, исключение избыточных структур (особенно указателей) имеет еще и потенциальное преимущество, связанное с тем, что узлы становятся менее связанными, что не только повышает скорость выполнения запросов и модификаций, но и открывает новые перспективы в улучшении гранулярности транзакционных блокировок и построении распределенных баз данных. Например, это создает предпосылки для реализации параллелизма по данным (data parallelism) на архитектуре shared-nothing.
Заключение и будущие работы
В данной статье были предложены методы оптимизации структур физического хранения XML данных для эффективного выполнения запросов из предопределенной рабочей нагрузки. Нами были описаны только предварительные результаты, однако предварительные эксперименты подтверждают действенность предложенного подхода. Он позволяет существенно сократить размер внутреннего представления, а также увеличить скорость выполнения запросов. Основным результатом данной работы должно стать создание системы, реализующей модель данных XQuery достаточно эффективно для использования XQuery-систем на практике. В будущих работах мы планируем разработать формальные методы анализа запросов, позволяющие автоматически строить планы хранения данных. Кроме того, мы планируем создать методы, позволяющие производить эффективную реорганизацию базы данных без необходимости ее остановки.
Эквивалентные преобразования
Утверждение 7 (Эквивалентные регулярные выражения) Следующие регулярные выражения являются эквивалентными:

Доказательство этого утверждения хорошо известно из теории регулярных грамматик. Заметим, что перечисленные пары регулярных выражений далеко не исчерпывают полный список эквивалентных регулярных выражений.
Утверждение 8 (Эквивалентные преобразования структурных схем) Пусть S=( T,E,A,p,a,r) - структурная схема. Тогда любая схема, получаемая из данной путем замены регулярного выражения на эквивалентное приводит к схеме S'=( T,E,A,p',a,r) эквивалентной исходной схеме.
Классы регулярных грамматик
В этом разделе мы приводим классификацию структурных схем. Данный метод заимствован из работы [13], где он используется для классификации грамматик деревьев.
Определение 8 (Локальные структурные схемы) Структурная схема называется локальной, если не существует двух типов элементов с одинаковым именем.
Структурная схема из примера 3 является локальной, в то время как схема из примера 4 не является таковой. Следующее утверждение выполняется для локальных схем.
Утверждение 3 (Единственность интерпретации) Пусть S=(T,E,A,p,a,r) локальная структурная схема и XML документ D валиден для S. Пусть также любые два домена из множества Т не пересекаются и для любого типа элемента e, мультимножество имен типов атрибутов из множества a(e) содержит только уникальные значения. Тогда существует и притом единственная интерпретация документа D в терминах S.
Существование интерпретации следует из самой формулировки утверждения. Для доказательства единственности воспользуемся формулировкой интерпретации. Из правила согласования имён элементов, и локальности схемы следует, что в любой интерпретации каждый элемент документа XML должен отображаться на один и тот же тип элемента, так как имена всех типов уникальны. Из того, что любые два домена не пересекаются и из свойства согласования текстовых узлов следует, что в любой интерпретации каждый узел документа XML должен отображаться на один и тот же домен. Таким образом, достаточно проверить, что отображение атрибутов сохраняется в любой интерпретации. Это следует из свойств согласования атрибутов с элементами, согласования имен и значений атрибутов и из того, что для любого типа элемента e, мультимножество имен типов атрибутов из множества a(e) содержит только уникальные значения.
Прежде чем описать следующий класс структурных схем, приведем следующее определение, относящееся к регулярным выражениям:
Определение 9 (Допустимые символы) Пусть r- регулярное выражение над множеством M. Тогда ? M(r) - это множество, содержащее все элементы из M, которые присутствуют в записи регулярного выражения.
Например, если E={0,1,2}, то ?M((0*,1*))= {0,1}
Теорема 2 ( Критерий допустимости) Пусть r- регулярное выражение над E. Тогда
 e
e  E: e ? M(r)
E: e ? M(r) 
 s=[e0,..,ei-1,e,ei+1,..,en]: s|=r
s=[e0,..,ei-1,e,ei+1,..,en]: s|=rОпределение 10 (Однотипные структурные схемы) Структурная схема S=(T,E,A,p,a,r) называется однотипной, если для любого типа элемента e, все типы элемента из множества ?E(p(e)) обладают разными именами.
Определение 11(Ограничено-однотипные структурные схемы) Структурная схема S=(T,E,A,p,a,r) называется ограниченно-однотипной, если для любого типа элемента e, выполняется следующее условие:
s1=(e0,..,en), s2=( e'0,..,e'm), где s1|=p(e) и s2|=p(e), и i: j< i e'j= ej 
name(ei) ? name(e'i)
Следующие два утверждения очевидны и будут приведены без доказательств.
Утверждение 4 (Вложение типов) Любая локальная структурная схема является однотипной структурной схемой. Любая однотипная структурная схема является ограниченно-однотипной структурной схемой
Утверждение 5 (Достаточное условие однотипности) Пусть структурная схема S=(T,E,A,p,a,r) обладает следующим свойством:
e E: |? M(p(e))|(Количество допустимых символов не превышает 1). Тогда S является однотипной структурной схемой. Утверждение 6 (Единственность интерпретации) Пусть S=(T,E,A,p,a,r) ограниченно-однотипная структурная схема и XML документ D валиден для S. Пусть также любые два домена из множества Т не пересекаются и для любого типа элемента e, мультимножество имен типов атрибутов из множества a(e) содержит только уникальные значения. Тогда существует и притом единственная интерпретация документа D в терминах S.
Для доказательства этого утверждения необходимо воспользоваться свойством согласования содержания элемента.
В заключении этого раздела, заметим, что исследования, проведенные в работе [13] показали, что множество структурных схем, соответствующих схемам, выраженным на языке DTD принадлежит классу локальных структурных схем. Множество структурных схем, соответствующих схемам, выраженным на языке DTD принадлежит классу однотипных структурных схем. И наконец, множество структурных схем, соответствующих схемам, выраженным на языке Relax NG, является полным множеством структурных схем.
Нормальные формы структурных схем
В этом разделе мы опишем нормальные формы структурных схем: представлений структурных ограничений, записанных определенным образом. Также мы сформулируем и докажем теоремы существования нормальных форм для любой структурной схемы.
Ограничения целостности XML
В последнем разделе 2 главы мы опишем различные виды ограничений целостности для XML-данных. Эти исследования, направленные на систематизацию логических способов задания ограничений целостности, были проведены в работах [8,12].
Итак, пусть S=(T,E,A,p,a,r) - Структурная схема, D- произвольный XML-документ, валидируемый S. Рассмотрим следующие логические выражения, являющиеся определениями ограничений целостности над схемой S.
Определение 26 (Ограничение ключа) Ограничением ключа ? над схемой S=(T,E,A,p,a,r) называется логическое выражение вида K(e)-> e , где e
E, K(e) a(e).
a(e).
Определение 27 ( документ удовлетворяет ограничению ключа) XML-документ D, валидируемый схемой S=(T,E,A,p,a,r) удовлетворяет ограничению ключа ? = K(e)-> e, если для любой интерпретации I=(ф,? ,?) выполняется следующее условие:
x,yф-1 (e): -> x? y
-> x? y
где x.l - это прообраз типа атрибута l, являющийся атрибутом элемента x. Под равенством атрибутов в документе, здесь и далее, подразумевается равенство значений.
Пример 9

рис 3 пример документа XML
На рис. 3 представлена документ XML, удовлетворяющий следующей структурной схеме:
T
 {a}
{a}E
{{a, A}, {b, B}} A {(C,c, CDATA, Required), (D,d, CDATA, Required)} p:p(a)= (b*) p(b)= ? a:a(b)={C,D} a(a)={}
r=a
Из утверждения 3 следует, что существует единственная интерпретация документа в терминах этой схемы. Рассмотрим следующее ограничение ключа ? = {C}-> B. Существует два элемента c именем b, у которых значения атрибута c совпадают. Следовательно, документ не удовлетворяет данному ограничению ключа. Однако тот же самый документ удовлетворяет другому ограничению ключа: {С,D}-> B.
Определение 28 (Ограничение включения) Ограничением включения над схемой S=(T,E,A,p,a,r) называется логическое выражение вида L1(e1)-> L2(e2) , где e1,e2 E, L1и L2 упорядоченные множества, такие что L1
a(e1), L2 a(e2), | L1|=| L2| .
Определение 29 ( документ удовлетворяет ограничению включения) XML-документ D, валидируемый схемой S=(T,E,A,p,a,r) удовлетворяет ограничению включения? = L1(e1)- > L2(e2), если для любой интерпретации I=(ф,? ,? ) выполняется следующее условие:
x ф-1(e1) y ф-1(e2):
где x.i и y.i - это прообразы i- х по порядку типов атрибута из упорядоченных множеств L1(e1) и L2(e2) , являющихся атрибутами элементов x и y соответственно.
Пример 10 Рассмотрим структурную схему и XML-документ из предыдущего примера. Приведенный XML-документ удовлетворяет следующему ограничению включения: ? ={C}B -> {D}B.
Определение 30 (Ограничение внешнего ключа) Ограничением включения ? над схемой S=(T,E,A,p,a,r) называется комбинация ограничения включения L1(e1)-> L2(e2) и ограничения ключа L2(e2) -> e
Определение 31 ( документ удовлетворяет ограничению внешнего ключа) XML-документ D, валидируемый схемой S=(T,E,A,p,a,r) удовлетворяет ограничению внешнего ключа ? = L1(e1) -> L2(e2); L2(e2) -> e2, если он удовлетворяет обоим ограничениям целостности, составляющим ограничение внешнего ключа для любой интерпретации.
После того, как мы определили логические выражения, предназначенные для формулирования ограничений целостности, мы можем сформулировать определения, соответствующие формальным определениям из раздела 1.6 (опр. 1.4-1.7)
Определение 32 (Схема данных XML) Схема данных XML - это пара (S,E), где S - это структурная схема, а E- множество ограничений целостности над S, сформулированных в виде логических выражений следующего вида - ограничение ключа, ограничение включения, ограничение внешнего ключа.
Определение 33 (Валидируемость документа XML) XML-документ D валидируется схемой (S,E), если D|=S и D удовлетворяет всем ограничениям целостности из E.
Первая нормальная форма.
Определение 19 (Конъюнктивно-множественные регулярные выражения) Конъюнктивно-множественные (к.-м.) регулярные выражения над множеством E (regKM(E))определяются следующим образом:
?- к.-м. регулярное выражение, где ? обозначает "пустой список"
e E: e- к.-м. регулярное выражение Если r1- к.-м. регулярное выражение, то (r1), r1*- к.-м. регулярные выражения Если r1 и r2- к.-м. регулярные выражения, то r1, r2 - к.-м. регулярные выражения
Определение 20 (Первая нормальная форма) Схема S=(T,E,A,p,a,r) представлена в первой нормальной форме (эквивалентная форма), если :
e E p(e)=r0|..|rn , где i ri regKM({id(E),T})
Teoрема 5 (Существование первой нормальной формы) Для любой схемы S=(T,E,A,p,a,r) существует схема эквивалентная ей, которая представлена в первой нормальной форме.
Для доказательства этой теоремы следует воспользоваться следствием 1 из теоремы 3. Пусть e - некий элемент схемы S=(T,E,A,p,a,r). Соответственно p(e) - регулярное выражение. Используя эквивалентные преобразования регулярных выражений r?
r|? (3.1.2) и r+ r*,r (3.1.3) мы приходим к регулярному выражению, соответствующему исходному, но не содержащему операций ? и +. После чего следует воспользоваться преобразованиями (r1| r2),r3 ( r1, r3)|( r1, r2) (3.1.6) и (r1| r2)* ( r1*, r2*)* (3.1.8) , после которых операция конкатенации ("|") "поднимается". Таким образом, для любого типа элемента e, p(e) преобразуется в выражение p'(e) вида r0|..|rn , где i ri regKM({id(E),T}). В силу следствия 1 новая схема S'=(T,E,A,p',a,r) , представленная в первой нормальной форме, эквивалентна схеме S
Следует заметить, что для регулярных выражений с использованием операции позитивного замыкания ("+") вместо операции Клини ("*")теорема о существовании нормальной формы также верна.
Определение 19' (Конъюнктивно-множественные регулярные выражения) Конъюнктивно-множественные (к.-м.) регулярные выражения над множеством E (regKM(E))определяются следующим образом:
? - к.-м. регулярное выражение, где обозначает "пустой список"
e E: e- к.-м. регулярное выражение Если r1 - к.-м. регулярное выражение, то (r1), r1+- к.-м. регулярные выражения
Если r1 и r2- к.-м. регулярные выражения, то r1, r2 - к.-м. регулярные выражения
Принимая альтернативное определение конъюнктивно-множественных регулярных выражений, доказательство теоремы 5 частично меняется. Так, вместо преобразования r+
r*,r используется r* r+|? (3.1.9). А вместо преобразования (r1| r2)* ( r1*, r2*)* для поднятия конкатенации применяется (r1|r2)+ ( r1+,r2+)+|( r2+, r1+)+| r1+| r2+|( r1+, r2+)+,r1+|( r2+, r1+),r2+ (3.1.17)Пример 6
Приведем к первой форме r0|..|rn , где
i ri regKM({id(E),T}) следующее регулярное выражение: ((b|c)?,(f?,b*)*), используя эквивалентные преобразования(b|c)?,(f?,b*)*
(b|c|? ),((f|? ),b*)* (b|c|? ),((f,b*)|(b*))* (b|c|? ),((f,b*)*,(b**))* (b|c|? ),((f,b*)*,b*)*
(b|c|? ),((f,b*)*)* (b|c|? ),(f,b*)* b,(f,b*)*| c,(f,b*)*| (f,b*)*Преобразования структурных схем
В этом разделе мы обсудим различные методы преобразования структурных схем. Эти преобразования можно разделить на три вида:
Эквивалентные преобразования - приводящие к схеме эквивалентной исходной,
Слабо-эквивалентные - приводящие к схеме, множество валидируемых документов, которой совпадает с множеством валидируемых документов исходной схемы с точностью до перестановки порядка элементов в документе,
Упрощающие - приводящие к схеме не эквивалентной исходной. Однако для любого документа, валидируемого исходной схемой должен существовать документ валидируемый получаемой схемой, отличающийся только порядком следования элементов.
Определение 12 (Эквивалентность структурных схем) Схемы D и D' эквивалентны, если множества валидируемых XML документов каждой из этих схем совпадают.
Теорема 3 (Достаточное условие эквивалентности) Две схемы S=(T,E,A,p,a,r) и S'=( T',E',A',p',a',r') эквивалентны если существует взаимно однозначное отображение M=( ф,? ,? ), где ф:E> E' ;? : E> E'; ? : T > T' обладающее следующими свойствами (отображение M-1 обладает аналогичными свойствами):
?(t)? t name(e)= name( ф( e)) ф(r)? r a ?? (a)(сохраняются все свойства типов атрибута)
e a a(e): ? (a) a'(ф (e)) и R(ф (e)) ?(a(e)) s=[s0,..,sn] s|=p(e)==>s'=[M(e0),..,M(en)]|=p'(ф (e))
Для доказательства достаточно проверить, что каждый XML документ, удовлетворяющий схеме S должен удовлетворять схеме S' . Проверка того, что каждый XML документ, удовлетворяющий схеме S' удовлетворяет схеме S, производится аналогично. Итак, пусть D|=S , где D - XML документ. В силу определения 6 должна существовать интерпретация I=( ф',?',?') документа D в терминах S. Рассмотрим отображение I'=M*I =(ф*ф', ?*? ', ?*?'). Докажем, что это интерпретация документа D в терминах S'.
e ED: name(e)= name ( ф'(e))=name(ф*ф '(e)) (согласование имени элементов) a AD: name(e)= name (? '(a))=name(?*? ' (a)) value(a) dom(? '(a)) = dom(?*? '(a)) (согласование имен и значений атрибутов) t TD: value(t) ?' (t) ? ?*? ' (t)(согласование текстовых узлов) ae Ae : ?'( ae) a(ф '(e)) ==>?*? ' ( ae) a( ф*ф' (e)) (согласование атрибутов с элементами) e ED: I(e0),.., I(en) |= p( ф'(e)) ==> I(e0),.., I(en) |= p(ф *ф' (e)) (согласование содержания элемента)
Остальные свойства интерпретации проверяются аналогично.
В случае, когда E? E' шестое условие принимает следующий вид p
p'.Следствие 1 (Критерий эквивалентности схем, отличающихся только структурами) Пусть S=(T,E,A,p,a,r) и S'=( T,E,A,p',a,r) две структурные схемы, у которых множество валидируемых XML документов непустое, и отличающиеся только регулярными выражениями, задающими структурное вложение. Тогда схемы S и S' эквивалентны тогда и только тогда, когда
e E p(e) p'(e) Достаточное условие является следствием теоремы 3, а необходимое условие проверяется на множестве экземпляров XML документов, удовлетворяющих схемам.
Применение Нормальных форм
В этом разделе мы приводим краткий обзор способов применения нормальных форм при решении типичных задач управления данными.
Валидация XML документов. Валидация XML документов является одним из наиболее распространенных средств управления XML документами. Валидация документов используется при создании XML-СУБД, обмене сообщениями, трансформации XML документов. Одна из основных проблем при валидации документа заключается в том, что до сих пор не существует единого стандарта для XML схем: схемы могут быть выражены на языках DTD, XML Schema, Relax NG, и.т.д. Однако на сегодняшний день существует ряд исследований [], ориентированных на создание универсального валидатора. В этих работах схемы представляются в виде регулярных грамматик деревьев, аналогичных структурным схемам. Основная часть алгоритмов валидации - разбор списка потомков - заключается в следующем: определить удовлетворяет ли упорядоченный список потомков данного элемента его модели содержания (структурному ограничению).
Преобразование схем к первой нормальной форме, как впрочем, и применение эквивалентных преобразований имеют следующее значение для алгоритмов валидации:
После преобразования к 1НФ операции ? и + устраняются, что позволяет воспользоваться алгоритмами валидации "классических" регулярных выражений, определяемых как замыкание операций "*", "|", "," над базовым алфавитом. Все операции конкатенации ("|") становятся внешними, что сильно структурирует модель содержания. Это приводит к упрощению алгоритма разбора списка потомков
Сопоставление схем. Задача сопоставления схем заключается в поиске эквивалентных частей в разных схемах. Решение этой проблемы применяется для интеграции данных. В текущее время ведутся исследования по автоматическому поиску зависимостей[16]. Методы автоматического сопоставления схем можно классифицировать следующим образом [16]:
Поиск в схемах/поиск в данных. Алгоритмы сопоставления схем могут исследовать зависимости только в схемах или зависимости по удовлетворяющим XML-документам.
Элементный/ структурный поиск. Поиск зависимостей может применяться либо к отдельным элементам, либо к структурам (фактически, учитываются или нет структурные ограничения)
Лингвистический/логический поиск. Поиск зависимостей осуществляется по лингвистическому принципу (например, по именам элементов) или по семантическим ограничениям (например, по типам данным).
В первую очередь, приведение схем к нормальным формам оказывает влияние на элементный лингвистический поиск. Приведение схем к 3НФс заданным отношением порядка существенно упрощает поиск зависимостей и фактически сводит задачу к поиску изоморфных поддеревьев в деревьях с именованными узлами и с ребрами, размеченными "*", "+" и "?". Подробнее способы сопоставления схем будут описаны в следующей главе.
Трансляция моделей. Одна из основных задач, встречающихся при создании систем хранения, управления и интеграции данных, заключается в трансляции моделей, в терминах которых экземпляры данных предоставляются, в термины "единой" модели данных. Так, несмотря на то, что XML и языки запросов к XML-данным завоёвывают в последнее время всё большую популярность, потребность хранения XML данных в "традиционных" СУБД и, соответственно, необходимость трансляции до сих пор остаётся. Обосновано это тем, что многолетний опыт, накопленный при изучении и реализациях реляционных и объектно-ориентированных СУБД невозможно игнорировать. Рассмотрим основные виды трансляции данных, определенных в терминах модели XML.
Relational -> XML
В работе [21] перечислены основные методы автоматизации представления реляционных данных в терминах модели данных XML: Плоская трансляция. Данный подход является наиболее тривиальным способом отображения схемы реляционной базы данных в XML-схему. Трансляция задается следующим образом:
Имя отношения переходит в элемент с таким же именем. Содержимое корневого элемента состоит из произвольного набора элементов, имена которых соответствуют именам отношения в базе данных. Каждому отношению базы данных ставится в соответствие тип элемента, имя которого совпадает с именем отношения. Множество типов атрибутов, относящихся к данному типу элемента, соответствуют паре {тип домена, имя атрибута} из заголовка отношения.
Вложенная трансляция (Nesting-Based Translation). Основной недостаток плоской трансляции заключается в том, что при создании XML-схемы не используются такая структурная возможность для моделирования XML, как наличие повторяющихся подэлементов. Вложенная трансляция устраняет этот недостаток. В работе [22] показано, каким образом достигается вложенная трансляция для отношений, представленных в 3НФ.
Трансляция с использованием "зависимостей по включению". Термин "зависимость по включению" используется в теории баз данных [21] как обобщение внешних ключей. Использование трансляции такого типа [21] позволяет вкладывать элементы, построенные из разных отношений друг в друга, исходя из информации о внешних ключах отношений и прочих зависимостей по включению. Если у отношения существует внешний ключ "на себя", получаемая схема XML будет рекурсивной.
Дополнительную информацию об этих и прочих видах трансляции из модели XML в другие модели и наоборот, можно получить в работе [21].
Слабо-эквивалентные преобразования.
Определение 13 (Слабо-эквивалентные регулярные выражения) Два выражения r1 и r2 являются слабо-эквивалентными (r1? r2) , если для любой последовательности s=[s0..sn], такой что s|= r11 существует последовательность s'=[sk(0)..sk(n)] , где k есть подстановка на множестве {0,..,n} , такая что s'|= r2 и наоборот, для любой последовательности s=[s0..sn], такой что s|= r2 существует последовательность s'=[sk(0)..sk(n) , где k есть подстановка на множестве {0,..,n} , такая что s'|= r1 .
Утверждение 9 (Слабо-эквивалентные регулярные выражения) Следующие регулярные выражения являются слабо-эквивалентными:
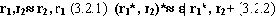
Докажем сначала первое утверждение. Пусть s=[s0..sn] |= r1,r2 . Тогда из определения 2 следует, что s [e0,…,ek, f0,..,fn], где [e0,…,ek] |=r1 и [f0,..,fn] |=r2 . Значит s' [ f0,..,fn ,e0,…,ek] |= r2, r1
Докажем второе утверждение. Пусть s|=(r1*, r2)* Рассмотрим два случая: s- пустая или непустая последовательность. Если s=[ ], то s|=? . Пусть s непустая последовательность символов. Тогда s можно представить в следующем виде
 , где sji |= r1 , si |= r Тогда последовательность
, где sji |= r1 , si |= r Тогда последовательность  =r1*,r2+ Что и требовалось доказать. В обратную сторону утверждение доказывается аналогично.
=r1*,r2+ Что и требовалось доказать. В обратную сторону утверждение доказывается аналогично.
Определение 14 (Ослабленная интерпретация) Ослабленной интерпретацией I XML документа D в терминах структурной схемы S=(T,E,A,p,a,r) называется набор отображений I=(ф,?,?), удовлетворяющий всем свойствам интерпретации, кроме согласования содержания элемента. Условие согласования содержания элемента заменяется следующим:
- (согласование содержания элемента) Пусть Ce = [e0,..,en] - есть упорядоченная последовательность элементов и текстовых узлов, вложенных в e. Тогда
e ED: |(e k(0)),.., |(e k(n)) |= p(ф (e)), где k(i)- есть подстановка на множестве {0,..,n}
Определение 15 (Ослабленная Валидность) Документ D является ослабленно-валидным документом для структурной схемы S (слабо удовлетворяет схеме S), если существует ослабленная интерпретация I в терминах S (Обозначается D|? S).
Определение 16 (Слабая эквивалентность структурных схем) Схемы D и D' слабо эквивалентны, если множества слабо валидируемых XML документов каждой из этих схем совпадают.
Следующие утверждения являются очевидными и приводятся без доказательства.
Утверждение 10 ( Слабая эквивалентность эквивалентных регулярных выражений) Если регулярные выражения являются эквивалентными, то они являются слабо-эквивалентными.
Следствие 2 (Достаточное условие слабой эквивалентности) Если схема S и S' являются эквивалентными, то они являются слабо-эквивалентными.
Teoрема 4 (Критерий слабой эквивалентности схем, отличающихся только структурами) Пусть S=(T,E,A,p,a,r) и S'=( T,E,A,p',a,r) две структурные схемы, у которых множество валидируемых XML документов непустое, и отличающиеся только регулярными выражениями, задающими структурное вложение. Тогда схемы S и S' эквивалентны тогда и только тогда, когда
e E p(e) ? p'(e) Как будет показано в дальнейшем, в силу того, что при слабо-эквивалентных преобразованиях (замене регулярного выражения на слабо-эквивалентное) теряется только семантика порядка следования элементов, то их удобно использовать для трансляции из XML модели в модели, не использующие порядок в структурном описании.
Также, преобразование 3.2.2 ведет к "выравниванию" схемы (в английской литературе используется термин "flattening"), тем самым, приводя её к более простому виду - без вложенных операторов Клини (*).
Отдельно стоит заметить, что преобразование (r1, r2)* > r1*, r2* , часто встречающееся в алгоритмах трансляции XML модели в реляционную, не является слабо-эквивалентным.
Список литературы
Extensible Markup Language (XML) 0 (Second Edition) W3C Recommendation 6 October 2000. http://www.w3.org/TR/2000/REC-xml-20001006 Бумфрей Ф. , Диренцо О. И др. XML:Новые перспективы WWW. М.:ДМК 2000 Bourret R. XML and Databases, http://www.rpbourret.com/xml/XMLAndDatabases.htm Suciu, D. Semistructured Data and XML. In Proc. of the Int. Conf. on Foundations of Data Organization. 1998. H. S. Thompson, D. Beech, M. Maloney, and N.Mendelsohn (Eds). XML Schema Part 1: Structures, W3C Recommendation, May 200http://www.w3.org/TR/xmlschema-1/. J. Clark and M. Murata (Eds). "RELAX NG Tutorial".OASIS Working Draft, Jun. 200 http://www.oasisopen.org/committees/relax-ng/tutorial.html. Microsoft. XML Schema Developer's guide Internet document, May 2000 http://msdn.microsoft.com/xml/XMLGuide/schema-overwiew.asp W. Fan and L. Libkin. On XML integrity constraints in the presence of dtds. In Proc. ACM PODS, 200 J. Shanmugasundaram, K. Tufte, G. He, C. Zhang, D. DeWitt, and J. Naughton. "Relational Databases for Querying XML Documents: Limitations and Opportunities". In VLDB, Edinburgh, Scotland, Sep. 1999. Murali Mani, Dongwon Lee, XML to Relational Conversion using Theory of Regular Tree Grammars , Proceedings of the 28th VLDB Conference,Hong Kong, China, 2002 D.Florescu, D. Kossmann, Storing and Querying XML Data Using RDBMS , IEEE Data Eng. Bulletin, 22(3):27-34, Sep 1999 W. Fan and J. Simeon. "Integrity Constraints for XML". In ACM PODS, Dallas, TX, May 2000. M. Murata, D. Lee, and M. Mani. Taxonomy of XML Schema Languages using Formal Language Theory. In Extreme Markup Languages, Montreal, Canada, 2001 S. Cluet et al. "Your mediator needs data conversion!." In Proc. of the ACM SIGMOD Conf. on Management of Data, Washington, USA, pp. 177--188, 1997. L. Novak Mediation system implementation based on specification of XML schema integration: generic approach. To be appeared E. Rahm, and P.A. Bernstein. A Survey of Approaches to Automatic Schema Matching. VLDB Journal 10(4):334-350. Dec. 200 Dongwon Lee, Wesley W. Chu.Comparative Analysisof Six XML Schema Languages. SIGMOD Record 29(3): 76-87 (2000). P. Bohannon, J. Freire, P. Roy, and J. Simeon. "From XML Schema to Relations: A Cost-Based Approach to XML Storage". In IEEE ICDE, San Jose, CA, Feb. 200 A. Deutsch, M. F. Fernandez, and D. Suciu. "Storing Semistructured Data with STORED". In ACM SIGMOD, Philadephia, PA, Jun.1998. T. Shimura, M. Yoshikawa, and S. Uemura. "Storage and Retrieval of XML Documents using Object-Relational Databases". In Int'l Conf. on Database and Expert Systems Applications (DEXA), pp. 206-217,Florence, Italy, Aug. 1999. Dongwon Lee, Murali Mani, Frank Chiu, Wesley W. Chu, "NeT and CoT: Translating Relational Schemas to XML Schemas using Semantic Constraints ",CIKM, 2002 D. Lee, M. Mani, F. Chiu, and W. W. Chu., "Nesting-based Relational-to-XML Schema Translation". In Int'l Workshop on the Web and Databases (WebDB), Santa Barbara, CA, May 2001.
Структурные ограничения XML
В этом разделе мы приводим формальное определение схем, состоящих из структурных ограничений, и формулируем термин "валидируемость". Также мы приводим определения эквивалентности схем и отношения порядка на схемах, которые будут использоваться в дальнейшем. Раздел начинается с определения регулярных выражений хорошо известных из литературы по грамматикам и языкам программирования.
Определение 1 (Регулярные выражения над множеством символов E) Множество регулярных выражений над множеством E (reg(E))определяется следующим образом:

Определение 2 (Порождаемые последовательности) Пусть r- регулярное выражение над множеством E. Тогда конечная (м.б. пустая) последовательность s=[e0,..,en] символов, где
 , порождается выражением r (s|=r), тогда и только тогда, когда выполняется одно из следующих соотношений:
, порождается выражением r (s|=r), тогда и только тогда, когда выполняется одно из следующих соотношений:

Множество всех порождаемых последовательностей регулярного выражения r над множеством Е называется регулярным множеством и обозначается так:

Пример 1
Пусть E={0,1}.
Множество последовательностей, порождаемых регулярным выражением (0|1)(0|1) состоит из множества последовательностей длины 2, содержащих элементы 0 и 1:
[0,0];[0,1];[1,0];[1,1].
Регулярное выражение (0|1)* порождает множество последовательностей произвольной длины, состоящих из 0 и 1, то есть полное множество всех последовательностей над множеством E.
Определение 3 (Эквивалентность регулярных выражений) Пусть r1,r2
reg(E) . Тогда

Определение 3' (Эквивалентность регулярных выражений)Пусть r1,r2
reg(E) . Тогда

Пример 2
Регулярные выражения r*,r и r+ эквивалентны, где r - произвольное регулярное выражение над множеством r. Покажем это. Пусть s|= r+ . Тогда по определению 2 s ? [s1,..,sn], где
i: si |=r. Тогда s1|=r и [s2,..,sn]|=r* и, значит, s|= r*,r . В обратную сторону утверждение доказывается аналогично.
Teoрема 1 (Замена выражений) Пусть
 1 и 2 - есть идентичные регулярные выражения над множеством {E,r1} и {E,r2}, соответственно ,где r1 и r2- обозначения регулярных выражений над множеством E (f1 получается из f2 путем замены символа r2 на r1 и наоборот). Пусть
1 и 2 - есть идентичные регулярные выражения над множеством {E,r1} и {E,r2}, соответственно ,где r1 и r2- обозначения регулярных выражений над множеством E (f1 получается из f2 путем замены символа r2 на r1 и наоборот). Пусть  1 и 2 - это два регулярных выражения над множеством E, получаемые, соответственно, из 1 и 2, с помощью замены символов r1 и r2 на регулярные выражения над множеством E. Тогда r2 r1 ==> 1
1 и 2 - это два регулярных выражения над множеством E, получаемые, соответственно, из 1 и 2, с помощью замены символов r1 и r2 на регулярные выражения над множеством E. Тогда r2 r1 ==> 1
Например, из этой теоремы следует, что выражение a|a+
a|(a*,a), так как a+ (a*,a) Определение 4 (Структурные схемы XML документов) [12] Структурная схема XML документов есть совокупность (T,E,A,p,a,r), где:
T - множество, состоящее из всевозможных доменов.
Е - множество типов элементов; тип элемента состоит из имени и условного обозначения, являющегося уникальным идентификатором типа
A - множество типов атрибутов. Каждый тип включает в себя:
имя атрибута,
домен принимаемых значений
идентификатор обязательности (должен ли атрибут быть заполнен)
уникальный идентификатор типа атрибута
p есть функция из множества E в reg({E,T}) . p:E
 reg({id(E),T}), где id(E)- множество уникальных идентификаторов типа элемента
reg({id(E),T}), где id(E)- множество уникальных идентификаторов типа элемента a есть функция из множества E в множество всех подмножеств множества A - pows(A). a: E
pows(A), причем для любого типа элементов e типы атрибутов из множества a(e) должны обладать уникальным именем. r
E и называется типом корневого элемента. Для Множества E должно быть соблюдено следующее условие: e0 E, e ? r (e0,e1,..,en): i < n ei E и последовательность s=[a0,..,aj-1,ei,aj,..an] s  { id(E),T} (p(ei+1)), en=r. Это условие означает "достижимость до любого элемента от корня"
{ id(E),T} (p(ei+1)), en=r. Это условие означает "достижимость до любого элемента от корня" Определение, данное выше, является достаточно универсальным способом спецификации структурных ограничений схем XML. Достаточно легко показать, что структурные ограничения, заданные выражениями на таких языках спецификации схем, как XML Schema, DTD, Relax NG отображаются в структурные схемы. В качестве примера, мы приведем пример отображения схемы, выраженной на языке DTD в структурную схему:
Пример 3

Данной схеме DTD соответствует структурная схема (T,E,A,p,a,r), где:
T
{#PCDATA}E
{{Product, product}, {Name, name}, {Developer, developer},{Summary, summary}
,{Description, description },{Para, para },{List, list}, {Item, item}, {Link, link}} (здесь и далее тип элемента
представляется как пара - {имя, Идентификатор})
A
{(URL, CDATA, Required,url)}p:
p(product)= (name, developer?, summary?, description?)
p(name)= p(Developer)=p(Summary)= #PCDATA
p(description)= (para | list)+
p(para)=p(Item) = (#PCDATA | link)*
p(list)= Item+
p(link)= ?
a:
a(link)={URL}
a(product)=a(name)=...=a(list)
{}r=product
Таким образом, можно установить, что при отображении в структурную схему каждому имени элемента в DTD соответствует уникальный тип элемента. Множество T состоит из типа #PCDATA (Термин PCDATA обозначает произвольный набор символов, интерпретируемый синтаксическим анализатором как текстовый узел). Каждому атрибуту соответствует свой тип атрибута, значения которого устанавливаются согласно свойствам типа атрибута в DTD. Наконец, отображение p задается исходя из регулярных выражений, определяющих структуру элемента DTD. Однако, стоит отметить, что ограничения целостности, которые могут присутствовать в DTD (атрибуты типа ID или IDREF) никоим образом не отображаются на структурную схему. Ограничения целостности мы обсудим в последнем разделе работы.
Заметим, что в зависимости от регулярного выражения, соответствующего элементам их типы можно классифицировать следующим образом:
- элементы пустого содержания : p(e)
{? },- элементы, содержащие данные : p(e)
reg(T)/{? },- элементы элементного содержания: p(e)
reg(id(E))/ {? },- элементы смешанного содержания : p(e)
reg({id(E),T})/{ reg(E) reg(T)}
reg(T)}В нашем примере, link -это элемент пустого содержания, name, developer, summary - элементы содержащие данные, product , description и list - элементного содержания, и наконец para и item - смешанного.
Стоит заметить, что структурные схемам вида (T,E,A,p,a,r) однозначно соответствуют регулярные грамматики деревьев [13], если положить следующее:
- множество F и id(Е) являются нетерминальными символами грамматики, где F - множество типов текстовых узлов, id(E) - множество уникальных идентификаторов типов элементов
- T и name(E) - терминалы грамматики, где name(E) - множество имен элементов
- Отображение p(e) заменяется правилом продукции одного из следующих двух видов:
x
a r, где x id(E), a name(E), r reg({E,F}) или x
a ? ,где x F, a TВ следующем разделе, мы опишем классы регулярных грамматик и их соответствие языкам спецификаций схем.
Следующие определения описывают понятие валидируемости XML документа. Здесь и далее, XML документ рассматривается в рамках модели XML , представленной в первой главе.
Определение 5 (Интерпретация) Интерпретация I XML документа D в терминах структурной схемы S=(T,E,A,p,a,r) - это набор отображений I=(ф ,? ,? ), где
ф - это отображение ED, -множества элементов документа, на множество E
? - это отображение AD, -множества атрибутов документа на множество A
? - это отображение TD, - множества текстовых узлов документа на множество T
Также должны выполняться следующие условия:
(согласование имен элементов)Пусть name - функция, ставящая в соответствие узлу документа его имя. Тогда
e ED: name(e)= name (ф (e)) (согласование имен и значений атрибутов)Пусть value- функция, ставящая в соответствие узлу документа его значение. Тогда
a AD: name(a)= name (? (a)) , value(a) dom(? (a)), где dom(x) - это домен принимаемых значений типа атрибута (согласование текстовых узлов)
t TD: value(t) ? (t) (согласование атрибутов с элементами)Пусть Ae={ai} i=[0,..,ne] - множество атрибутов элемента е. Тогда
e ED: i [0,.., ne] ? (ai) ; a(ф(e)) (согласование обязательных атрибутов) ф-1(es) - множество элементов документа D, которые отображаются в тип элемента es. Также пусть R(es) - это подмножество a(es), в которое входят те и только те типы атрибутов, у которых проставлен идентификатор обязательности. Тогда
es E as R(es) e ф-1(es) a Ae : ?(a)= as(согласование корневого элемента) Для rD - корневого элемента документа D : ф( rD)=r
(согласование содержания элемента)Пусть Ce = [e0,..,en] - есть упорядоченная последовательность элементов и текстовых узлов, вложенных в e. Тогда
e ED: I(e0),.., I(en) |= p(ф (e)), где I(ei) - это одно из двух отображений {ф ,? } (в зависимости от типа узла) Определение 6 (Валидность) Документ D является валидным документом для структурной схемы S (удовлетворяет схеме S), если существует интерпретация I в терминах S (Обозначается D|=S).
Данное определение является ключевым для всего дальнейшего рассмотрения. Введем следующее обозначение: DB(S) - множество всех документов XML, удовлетворяющих данной схеме.
Утверждение 1 (Корректность валидности) Пусть D - схема, выраженная на языке спецификации DTD и S - соответствующая ей структурная схема. Тогда DB(D)
DB(S). Если схема D не содержит ограничений целостности, тогда DB(D)=DB(S).Для доказательства утверждения достаточно использовать свойства отображения схем DTD в структурные схемы (они очевидно следуют из примера 3).
Аналогичные утверждения можно сформулировать и доказать для других языков спецификации схем.
Заметим, что далеко не всегда существует единственная интерпретация одного и того же документа. Нижеследующий пример демонстрирует случай множественной интерпретации одного и того же документа.
Пример 4
На рис. 1 представлена структурная схема и документ XML

рис. 1 а) структурная схема б) документ
Документ XML содержит три элемента: A, B и C. Исходя из определения интерпретации, отображение I должно ставить в соответствие каждому элементу тип элемента из множества Е с таким же именем, как и у элемента. Поэтому в любой интерпретации элементу A соответствует тип a, элементу С тип с. А вот для элемента B существует два разных типа в которые он мог бы отображаться b1 и b Достаточно легко убедиться, что в обоих случаях будут выполняться условия интерпретации.
Определение 7 (Тривиальные схемы) Структурная схема называется тривиальной, если существует и притом единственный XML документ, валидный для данной схемы.
Утверждение 2 (Существование тривиальной схемы) Для любого XML документа существует тривиальная структурная схема, для которой данный документ валиден.
Для доказательства утверждения достаточно воспользоваться индукцией по глубине документа XML - максимальному расстоянию от корня дерева XML до листа. База индукции при n= В этом случае документ XML должен иметь следующий вид (представление в терминах модели XML [1]) - рис 2

Рис 2 XML документ глубины 1
Как видно из рисунка, все узлы дерева помимо корня являются листами. Для формирования структурной схемы, необходимо выполнить следующие действия:
Множество E формируется следующим образом: для каждого узла типа "элемент", мы создаем отдельный тип элемента Множество A формируется следующим образом: для каждого узла типа "атрибут", мы создаем отдельный тип атрибута. Доменный тип состоит из одного значения - значения данного узла в документе Множество T формируется следующим образом: для каждого текстового узла в документе мы создаем отдельный домен, состоящий только из одного значения Отображение a задается по следующим правилам: для любого типа элемента e - множество a(e) состоит из типов атрибутов, соответствующих атрибутам того элемента XML, который задавал e. Отображение e задается по следующим правилам: для любого типа элемента e - p(e) - это выражение вида (e0,..,en) где ei это либо тип элемента, либо домен, задаваемый i-м дочерним узлом того элемента XML, который задавал e. Тип элемента r (корневой тип) задается корневым элементом дерева XML.
Легко убедиться, что исходный документ удовлетворяет данной схеме. Также любой XML документ, удовлетворяющий данной схеме, совпадает с исходным документом. То есть схема является тривиальной. Индуктивный переход осуществляется следующим образом. Пусть утверждение доказано для документа, максимальная глубина которого равна n. Пусть у нас есть документ XML глубины n+1. В терминах XML модели, его можно представить в виде дерева глубины n+1. Рассмотрим множество поддеревьев, с корнями в дочерних узлах корневого документа исходного дерева. Их максимальная глубина не превышает n. По предположению индукции им ставится в соответствие тривиальные схемы. Общая схема формируется путем объединения множеств E,T,A каждой из этих тривиальных схем и продлением отображений a и p . Затем мы формируем еще один тип элемента r, соответствующий корню исходного XML документа, и продляем отображения a и p на него. Отображение a(r) возвращает множество атрибутов корневого элемента, а p(r)=(r0,..,rn), где ri - корневой тип элемента тривиальной схемы, порожденный i-м узлом.
Способ создания тривиальной схемы, использованный в утверждении 2, задает инъективное отображение множества документов XML на множество схем. Этот результат используется в работе [15] для реализации алгоритмов трансляции выражений алгебры управления структурными схемами в выражения языка запроса к данным XML. Легко показать, что все домены из множества T - доменных типов тривиальной схемы содержат в точности одно значение.
Лемма 1 (Достаточное условие тривиальности) Любая схема S=(T,E,A,p,a,r) такая, что для любого типа элементов e, регулярное выражение p(e) имеет вид r1,..,rnn, где ri есть символы базового алфавита, является тривиальной или пустой схемы.
Третья нормальная форма.
Определение 23 (Простые регулярные выражения) Простые (п.) регулярные выражения над множеством E (regS(E))определяются следующим образом:
?-п. регулярное выражение, где обозначает "пустой список"
e E: e- п. регулярное выражение Если r1 и r2- п. регулярные выражения, то r1, r2 - тоже п. регулярное выражение Если r =e , где e E, то r* ,r? r+ - п. регулярные выражения
Определение 24 (Третья нормальная форма) Схема S=(T,E,A,p,a,r) представлена во третьей нормальной форме (простая нормальная форма), если:
e E p(e)=r , где r regS(E)
Teoрема 7 (Существование третьей нормальной формы) Для любой схемы S=(T,E,A,p,a,r) существует схема, являющаяся ее упрощением, и представленная в третьей нормальной форме.
Для доказательства этой теоремы следует воспользоваться упрощающими преобразованиями для построения новой структурной схемы, являющейся упрощением исходной схемы и представленной в третьей нормальной форме. Для доказательства того, что такая схема существует необходимо воспользоваться индукцией по длине регулярного выражения.
Пример 8 Рассмотрим регулярное выражение из примера 7.
(b|c)?,(f?,b*)*-> (b?,c?)?,f?*,b** -> b??,c??,f?*,b** -> b?,c?,f*,b* -> b*,c?,f*
В отличие от первой и второй нормальных форм, для третьей нормальной формы можно сформулировать и доказать теорему единственности. Пусть на множестве E введено отношение порядка. Тогда, определим простые упорядоченные регулярные выражения следующим образом:
Определение 25 (Простые упорядоченные регулярные выражения) Простые упорядоченные (п. у.) регулярные выражения над множеством E (regSO(E))определяются следующим образом:
? -п. у. регулярное выражение, где обозначает "пустой список"
e E: e- п. у. регулярное выражение Если r =e , где e E, то r* ,r? r+ - п. у. регулярные выражения Если r1 и r1- п. регулярные выражения, и a1,a2 E, таких, что s1= [e0,..,ei-1,a1,ei+1,..,en], s2= [e'0,..,e'i-1,a2,e'i+1,..,e'n] s1|=r1, и s2|=r2 верно, что e1e2, то r1, r2 - тоже п. у. регулярное выражение
Определение 24 (Третья нормальная форма) Схема S=(T,E,A,p,a,r) с заданным отношением порядка на множестве E представлена в третьей нормальной форме (простая нормальная форма), если:
e E p(e)=r , где r regSO(E)Если не существует двух типов элементов с одинаковым именем, то отношение порядка на множестве E может соответствовать лексикографическому порядку на множестве имен элементов.
Teoрема 8 (Существование и единственность третьей нормальной формы) Для любой схемы S=(T,E,A,p,a,r), такой, что на множестве Е задано отношение порядка, существует и единственная схема S'=(T,E,A,p',a,r) , представленная в третьей нормальной форме, являющаяся ее упрощением.
Упрощающие преобразования.
Все преобразования, которые будут представлены ниже, ведут к потере определенной, достаточно большой части информации о структуре документа. Однако они достаточно часто используются на практике. Обусловлено это тем, что упрощение структурных ограничений приводит к существенному уменьшению сложности решения многих задач, встречающихся на практике.
Определение 17 (Упрощение регулярного выражения) Регулярное выражение r2 над E является упрощением р.в. r1 над E (r1 < r2) , если множество символов E, формирующих r2 , совпадает с множеством символов, формирующих r1, и выполняется следующее условие. Для любой последовательности s=[s0..sn] такой, что s|= r1 существует последовательность s'=[sk(0)..sk(n)] , где k есть подстановка на множестве [0,n] и s'|= r
Утверждение 3. Для регулярных выражений r1 и r2
r1 < r2, r2 < r1 < = > r1 ? r2,
r1
r2==> r1 < r2 , r2 < r1
Для доказательства первого предложения в прямую сторону (r1 < r2 , r2 < r1==> r1 ? r2) достаточно воспользоваться определением упрощения. Чтобы доказать утверждение в обратную сторону, необходимо воспользоваться критерием допустимости символов из множества E (теорема 2). Вторая часть утверждения вытекает и первой и из утверждения 10
Из этого утверждения непосредственно вытекает, что слабо-эквивалентные и эквивалентные преобразования являются упрощающими.
Утверждение 4. (Упрощающие преобразования) Следующие преобразования регулярных выражений являются упрощающими:

Доказательство этого утверждения напрямую следует из определения порождаемых последовательностей. Заметим, что мы перечислили не все упрощающие преобразования.
Пример 5
Дано следующее описание элемента : < !ELEMENT a ((b|c|e|)?,(e?|(f?,(b,b)*))*)>

Как видно из примера исходная схема приобретает весьма простой вид. Следует учесть, что информация об относительном порядке элементов утеряна, но при этом семантика множественности сохранена (например, элемент с может быть максимум один у элемента а).
Определение 18 (Упрощение схемы) Схемы D' является упрощением схемы D, если множество валидируемых документов первой схемы принадлежит множеству слабо-валидируемых элементов второй.
Критерий и достаточное условие того, что схема S является упрощением схемы S', формулируются и доказываются таким же образом, как и для слабо-эквивалентных схем.
В следующем разделе, мы определим нормальные формы схем XML документов и докажем теоремы существования нормальных форм произвольных структурных схем.
Вторая нормальная форма.
Определение 21(Конъюнктивные регулярные выражения) Конъюнктивные (к.) регулярные выражения над множеством E (regK(E))определяются следующим образом:
?- регулярное выражение, где обозначает "пустой список"
e E: e- к. регулярное выражение Если r1 - к. регулярное выражение, то (r1)-к. регулярные выражения Если r1 и r2- к. регулярные выражения, то r1, r2 - тоже к. регулярное выражение Если r =(e0,..,en) , где > i : ei E, то r* и r+ - к. регулярные выражения
Определение 22 (Вторая нормальная форма) Схема S=(T,E,A,p,a,r) представлена во второй нормальной форме (слабо-эквивалентная нормальная форма), если:
e E p(e)=r0|..|rn , где i ri regK(E)
Teoрема 6 (Существование второй нормальной формы) Для любой схемы S=(T,E,A,p,a,r) существует схема слабо-эквивалентная ей, представленная во второй нормальной форме.
Для доказательства этой теоремы, необходимо воспользоваться результатами Теоремы 5. Для исходной схемы S существует эквивалентная схема S', структурные ограничения которой имеют вид r0|..|rn , где
i ri regKM(E). Далее, для каждого ri мы воспользуемся преобразованием (r1*, r2)* ? ? | r1*, r2+ (3.2.2) для уменьшения вложенных операторов * и +. После чего, если выражение r2 содержит операцию *, то воспользуемся преобразованием (3.1.3) для замены оператора r2+ на r2*,r Таким образом, используя индукцию по длине регулярного выражения и по глубине "вложенности" операций * и +, приходим к доказательству теоремы. Используя преобразования (3.2.1) и (3.1.11)-(3.1.16) можно добиться существенного упрощения выходной формы
Пример 7 Приведем регулярное выражение из предыдущего примера ко второй нормальной форме.
(b|c)?,(f?,b*)*
b,(f,b*)*| c,(f,b*)*| (f,b*)*? (b|c|? )(b*f+|? )? b+f+|b|cb*f+|c|b*f+|?? b|cb*f+|c|b*f+|? (в последнем переходе использовалось эквивалентное преобразование r*|r+ r*)
в последнее время доминирующим стандартом
Расширяемый Язык Разметки (XML) [1] становится в последнее время доминирующим стандартом представления и обмена данными в Интернете. Подобно языку HTML, XML является поднабором языка SGML. Однако существует набор фундаментальных отличий XML от других языков разметки, одно из которых заключается в том, что разметка документа является семантической. Перечислим основные свойства языка XML [2]:
Независимый формат данных. При использовании XML как формата выходных и входных данных приложения, данные становятся независимы от самого приложения, что повышает способность взаимодействия.
Одни данные, несколько представлений. В силу того, что формат не зависит от приложения, очевидно, что одни и те же данные можно отображать разными способами и разными приложениями.
Улучшенные возможности поиска данных. Поскольку XML определяет семантическую структуру документа, это способствует созданию дополнительных возможностей для поиска информации. Например, индексирующие и поисковые средства могут работать не только с самими данными, но и с разметкой (метаданными)
Облегчение доступа к данным. В мире в настоящее время существует большое количество информации, доступ к которой затруднен из-за того, что она хранится в разнородных и несовместимых форматах. Перевод в формат XML откроет доступ к таким данным.
Более простая разработка приложений. XML делает необязательной реализацию поддержки большого количества бинарных форматов, вследствие чего разработка приложений становится значительно проще.
Использование готовых решений. При управлении данными, как правило возникает необходимость решения "шаблонных" задач, таких, как верификация данных, лексический и синтаксический разбор, и.т.д. Переход к формату XML способен убрать необходимость создания своих собственных реализаций для решения подобных задач.
XML файл может быть прочитан человеком.
XML поддерживается большим количеством стандартов. Эти стандарты предназначены для того, чтобы гарантировать совместимость приложений пользователя и готовых решений. В их число входят стандарты API для лексического и синтаксического анализа (SAX), стандарт для управления объектной моделью документа (DOM) и другие стандарты, которые будут рассмотрены ниже.
Основной целью данной работы является изучение свойств XML-схем и методов преобразования схем данных над моделью XML, которые могут быть использованы в качестве вспомогательного инструмента для создания и реализации некоторых задач, связанных с управлением данными и мета-данными XML. Основная идея нашего подхода заключается в разработке методики, позволяющей существенно упростить реализацию этих алгоритмов, за счет выделения подклассов из всего многообразия XML-схем. Выделенный подкласс должен обладать следующим свойством: реализация алгоритма для схем, принадлежащих данному подклассу, существенно упрощается по сравнению с алгоритмом, работающим на всем многообразии схем XML. Схемы, принадлежащие определенному подклассу, называются схемами, представленными в нормальной форме.
Статья организована следующим образом. В начале мы приводим формальное определение структурных частей (сигнатур) схем XML, основанное на регулярных грамматиках деревьев. Преимущество такого представления структурных ограничений заключается в том, что любую схему, выраженную на языке регулярных грамматиках деревьев, можно отобразить на существующие языки спецификаций схем XML и наоборот, структурные ограничения, выраженные на наиболее распространенных языках спецификаций схем выразимы с помощью регулярных грамматик деревьев. В следующем разделе, мы приводим классификацию типов регулярных грамматик и их соответствие языкам спецификаций схем XML. Далее мы вводим преобразования схем XML, приводящие их к эквивалентному виду (с точностью до отношения эквивалентности). В четвертом разделе мы определяем нормальные формы схем и приводим теоремы существования нормальных форм для любой схемы. Затем, мы обсуждаем методы использования алгоритмов нормализации для решения практических задач, связанных с управлением XML-данными, в частности для построения отображения моделей данных. Наконец, в последнем разделе, мы описываем логические языки, предназначенные для формулирования ограничений целостности XML.
XML->Relational
Одним из основных направлений исследования методов трансляции моделей является трансляция XML-модели данных в реляционную [9,10]. Отличительными особенностями реляционной модели данных являются:
отсутствие упорядоченности кортежей и атрибутов,
трехуровневая модель (отношение-кортеж- атрибут), в отличие от произвольной глубины XML схем
отсутствие атрибутов, имеющих своим значением множество
отсутствие рекурсии
Существует различные методы автоматического представления XML документов в реляционных СУБД:
Хранение XML- данных в BLOB.
Модельно-ориентированная трансляция. Данный вид трансляции не зависит от структурных ограничений, определенных в схеме схемы, а целиком опирается на свойства модели данных XML [20].
Трансляция, ориентированная на данные. Данные алгоритмы трансляции оперируют с XML-данными, не представленными никакой схемой [19]. На начальном этапе трансляции производится вывод схемы, представляющей XML-данные.
Трансляция с оценкой эффективности. Алгоритм трансляции, представленный в работе [18], анализирует способ трансляции XML-данных таким образом, чтобы запросы, предопределенные приложением, выполнялись наиболее эффективно.
Структурно-ориентированная трансляция. Эта трансляция опирается на информацию, полученную из XML-схемы. В алгоритмах этого типа [9,10] используются структурные ограничения, явно присутствующие в схеме, а также выводятся неявные ограничения, исследуемые в процессе анализа схемы.
Проведенные исследования [9,10], касающиеся проблемы структурно-ориентированной трансляции из XML в реляционную модель выявили ряд возникающих трудностей и показали методы решения:
Наличие оператора конкатенации в модели содержания. Например, пусть у нас есть определение модели содержания элемента < !ELEMENT r (a|b)>. Переводя в реляционную модель, наиболее близким отображением будет таблица r с двумя полями: a и b. Однако эта схема не будет отражать тот факт, что в элементе r может встретиться либо a либо b. Поэтому необходимо добавить семантическое ограничение: "если значение в поле a непустое, то значение в поле b должно быть пустым и наоборот". Если есть вложенные конкатенации (то есть конкатенации не на самом верхнем уровне регулярного выражения), мы должны использовать 1НФ для вынесения конкатенаций на самый верхний уровень. Наличие оператора Клини (*). Если в модели содержания какого-то узла встречается другой элемент с оператором * (< !ELEMENT r a*>), то в этом случае для элемента придется создавать отдельное отношение. Если же структура содержит вложенные операторы * (< !ELEMENT r (a*,b)*), то количество отношений существенно увеличится. Обычно для решения этой проблемы используются преобразования схем аналогичных 3НФ (упрощение схемы).
Однако, на наш взгляд, правильнее использовать 2 НФ для представления схемы XML:
- Во первых, 2НФ оставляет практически всю семантику схемы
- Во вторых, семантика порядка, которая теряется во 2НФ, не оказывает никакого влияния на трансляцию в реляционную модель, вследствие отсутствия семантики порядка в реляционной модели.
XML->Semistructured
Другим направлением трансляции XML является трансляция в полуструктурированные и объектно-ориентированные модели. Существенное отличие этих моделей от реляционной заключается в том что, данные представляются в виде ориентированного графа с именованными узлами. Последнее свойство, как правило, снимает необходимость использования 2НФ и 3НФ. Поэтому, в общем случае транслируется схема, приведенная к 1НФ или непосредственно исходная схема. Например, для полуструктурированной модели данных YAT [14] мы использовали представление структурных схем в 1НФ, в силу особенностей данной модели (отсутствие операторов + и ? и наличие оператора | с ограниченными свойствами )[15].
Основной целью данной работы является
Основной целью данной работы является изучение свойств схем данных XML-документов. В работе представлено формальное определение структурных схем и изучены методы преобразования схем-экземпляров, обладающих свойством сохранения той или иной семантики. Также в работе представлены нормальные формы структурных ограничений и доказаны теоремы существования нормальных форм для произвольной структурной схемы. Как уже было показано выше, в большинстве исследований, касающихся проблем управления данными и моделями XML тем или иным образом можно установить класс семантических правил, которыми можно пренебречь для эффективности реализации. Нормальные формы схем как раз и являются способом приведения схемы к более простому виду с потерей части семантики. В заключительной части работы мы описываем способы поддержки ограничений целостности
В данный момент нами разработаны алгоритмы преобразования схем DTD и Relax NG в структурные схемы с последующим приведением к нормальным формам. На следующем этапе мы планируем расширить список поддерживаемых языков спецификаций схем (XDR, XML Schema). Затем мы планируем перейти к более детальному изучению способов применения нормальных форм схем на практике.
