Инициатива SDMX: новые подходы к обмену статистическими данными
Подготовлено: по материалам зарубежных сайтов
Перевод: Intersoft Lab
В сентябре 2001 г. в г. Вашингтоне состоялся международный семинар, организованный крупнейшими мировыми финансовыми и статистическими организациями: Банком международных расчетов (Bank for International Settlements - BIS), Европейским Центральным Банком (European Central Bank - ECB), Статистическим бюро европейского сообщества (Statistical Office of the European Communities - EUROSTAT), Международным валютным фондом (International Monetary Fund - IMF), Организацией экономического сотрудничества и развития (Organization for Economic Co-operation and Development - OECD) и Статистическим департаментом ООН (United Nations Statistical Division). Семинар был посвящен проблеме обмена статистическими данными и метаданными. Участники семинара признали необходимым начать работу по созданию международных стандартов в этой области. В результате возникла так называемая инициатива SDMX - Statistical Data and Metadata Exchange Initiative, которая и поставила своей целью выработку таких стандартов. В настоящее время, помимо вышеназванных организаций, в состав SDMX входит также Мировой банк (World Bank).
История вопроса
Считается, что история мировой стандартизации статистических данных началась в 1928 г. на Международной конференции по экономической статистике (International Conference Relating to Economic Statistics), организованной Лигой Наций (League of Nations). После Второй мировой войны история создания международных стандартов продолжилась выпуском в 1947 г. документа "Система мер для оценки национального дохода и составления социальных счетов" (Measurement of National Income and the Construction of Social Accounts), созданного под эгидой ООН, и "Руководства по составлению платежного баланса" (Balance of Payments Manual) от Мирового банка в 1948 г.
Всплеск активности в области стандартизации данных начался с появлением компьютеров в 1953 г. Вначале эта деятельность ограничивалась созданием внутренних стандартов кодирования статистических данных, а в конце 20-го века, с развитием недорогих электронных средств коммуникации, на первый план вышла задача разработки стандартов для электронного обмена информацией. Первыми здесь оказались коммерческие корпорации - авиакомпании и банки, за ними последовали и организации государственного сектора. К началу 21-го века электронный обмен статистическими данными стал стандартной практикой для таких организаций, как EUROSTAT, IMF, BIS, ECB и стран - членов этих организаций.
Наряду с разработкой правил синтаксиса развивалось и другое направление обмена данными - создание стандартного языка для описания документов. Первым стал стандартный обобщенный язык описания документов (Standard Generalized Markup Language - SGML), одобренный Международной организацией по стандартизации (International Standard Organization) в 1986 г. Без его производной - языка разметки гипертекста (Hypertext Markup Language - HTML) сейчас невозможно представить существование интернета.
Следующим шагом стало создание так называемого расширяемого языка разметки (Extensible Markup Language - XML), с помощью которого можно описать формат для передачи данных. Первая версия этого языка была опубликована в 1998 г.
Разработка стандартов для обмена информацией совпала с появлением потребности в новых экономических данных на международном уровне. Развитие экономики привело к тому, что возникла необходимость в макроэкономических данных, а великая депрессия 1930-х годов продемонстрировала, что для достижения более стабильной экономики в мировом масштабе государства должны сотрудничать. Стало ясно, что макроэкономические данные различных стран должны быть легко сравнимы между собой. Помимо этого, появилась потребность в новом типе стандартизованной информации, описывающей, откуда берутся данные национальных экономик, т.е. источники этих данных и способы их распространения.
В результате актуальной стала проблема так называемых метаданных, т.е. данных, описывающих другие данные. В документе "Руководство по размещению статистических метаданных в интернете" (Guidelines for Statistical Metadata on the Internet), выпущенном Европейской экономической комиссией ООН (Economic Commission for Europe - ЕСЕ), статистические метаданные определяются как "данные, необходимые для правильного получения и использования тех данных, которые они описывают". То есть это данные, дающие информацию о статистических данных и, до некоторой степени, о процессах и средствах, вовлеченных в получение и использование статистических данных.
Как и в случае с обычными данными, вновь появляющиеся наборы метаданных также вовлекаются в обмен между государствами, региональными и международными организациями и общественностью. Из этого логически вытекает необходимость разработки стандартов обмена метаданными.
Возвращаясь к инициативе SDMX, необходимо отметить, что в рамки ее деятельности входит обмен данными и метаданными в пределах совместной работы финансовых и экономических организаций, входящих в это сообщество. Таким образом, ее деятельность направлена на выработку стандартов преимущественно в области социально-экономической статистики.
Важно подчеркнуть, что одним из основных принципов деятельности организации SDMX является открытость в разработке стандартов и обеспечение доступа всех государств - членов организации и заинтересованных потребителей данных к участию в этой работе. При этом стоимость участия в процессе должна быть минимальной, чтобы не создавать препятствий для желающих присоединиться к данной деятельности. Интеллектуальная собственность, которая появится в результате работы организации, должна быть доступна бесплатно и без ограничений.
Практическое применение стандарта SDMX
Федеральный резервный банк Нью-Йорка (Federal Reserve Bank of New York) разместил на своем сайте данные об обменных курсах, используя стандарты SDMX, разработанные в ходе практического исследования новых электронных стандартов обмена данными в 2003 г. (http://www.newyorkfed.org/xml/fx.html).
Данные, оформленные таким образом, доступны для автоматизированного использования. Структуры, схемы и списки кодов, поддерживающие эти файлы, также совместимы со стандартами SDMX.
Это первый известный случай применения SDMX-стандартов для публикации данных в интернете.
Помимо этого, Федеральный резервный банк Нью-Йорка информировал организации, входящие в SDMX-инициативу, о том, что банком также рассматривается вопрос о размещении в интернете и других статистических рядов данных на основе тех же стандартов.
рубрики будет посвящена техническому описанию стандарта SDMX.
Проекты SDMX
Наряду с разработкой первого стандарта SDMX в рамках этой инициативы выполняется и ряд других проектов, направленных на поддержку и развитие новых электронных стандартов обмена данными. Проекты SDMX нацелены на использование новых интернет-технологий и опыта тех, кто занимается бизнес-требованиями и IT поддержкой для сбора, компиляции и распространения статистической информации.
В настоящее время в рамках организации SDMX выполняется четыре проекта:
практическое исследование новых электронных стандартов обмена данными;
пакетный обмен данными: развитие и поддержка "Общего статистического протокола для временных рядов - Версия 3.0" (Generic Statistical Message for Time Series (GESMES/TS) - Version 3.0);
создание общего словаря метаданных;
репозитории метаданных: разработка стандартного подхода для создания и использования репозиториев метаданных с целью доступа к, анализа и повторного использования статистических метаданных.
Практическое исследование новых электронных стандартов обмена данными
В фокусе данного проекта было изучение способов, с помощью которых новые интернет-технологии, такие как XML, web-сервисы и другие, могут быть использованы для упрощения сбора, компиляции и распространения статистической информации.
К настоящему времени подготовлен набор технических проектов, устанавливающих стандарты. Эти проекты доступны для комментариев на сайте SDMX-инициативы (http://www.sdmx.org/). В них содержится детальная информация о результатах проекта.
Если говорить коротко, то в рамках этого проекта новые и экспериментальные стандарты, основанные на web-технологиях, были использованы для обработки статистики внешнего долга, предоставленной BIS, IMF, OECD и Мировым банком.
Данные этих организаций доступны на web-узле, который они поддерживают совместно. Основной результат проекта - это то, что, используя интернет, можно получать данные с такого "виртуального" узла без использования центральной базы данных (т.е. с помощью ссылок на данные, которые хранятся на разных сайтах). Этот результат дает дополнительные основания считать, что распространение статистической информации через интернет с помощью новых стандартов и технологий может стать основанием для создания web-сервисов, посредством которых можно будет напрямую обмениваться данными, минуя промежуточную стадию пересылки данных в централизованные базы. Если расширить рамки этой концепции, то данные, находящиеся в интернете, могут рассматриваться как библиотека статистической информации с широким доступом, способная удовлетворять самые разнообразные требования пользователей.
Более подробную информацию об этом проекте можно найти по адресу
http://www.registrysolutions.co.uk/sdmxDemo/notes/index.htm.
Пакетный обмен данными
Generic Statistical Message - это синтаксис, разработанный для стандарта EDIFACT в начале 1990-х годов. В 1998-99 годах BIS, ЕСВ и EUROSTAT представили новый вариант этого синтаксиса, названный GESMES/СВ. Все участники SDMX-инициативы договорились поддерживать и использовать именного его как стандарт для пакетного обмена данными временных рядов.
К настоящему времени в рамках проекта разработана модель синтаксиса GESMES для временных рядов, названная GESMES/TS. На сайте SDMX-инициативы (http://www.sdmx.org/) сейчас доступна третья, последняя версия этого синтаксиса, а также руководство для пользователей. Последнее описывает модель данных, которая используется в этой версии, синтаксис EDIFACT и дает указания по разработке приложений, необходимых для использования GESMES/TS при пакетном обмене данных.
Создание общего словаря метаданных
Задачей этого проекта является создание и поддержка ключевого набора элементов метаданных и связанных с ними определений с целью улучшения стандартизации содержимого метаданных и стимулирования работы по совместимости данных на международном уровне.
Обновленная версия этого словаря была выпущена в апреле 2004 г. Она содержит полный набор определений, описывающих статистические данные и процессы, которые используются для их компиляции государственными агентствами и международными организациями. Эта версия также доступна на сайте SDMX-инициативы.
Репозитории метаданных
Целью проекта является содействие и расширение обмена метаданными среди международных агентств и между странами с помощью стандартизации процедуры организации репозиториев метаданных.
Проект имеет две краткосрочных цели: 1) идентификация общих моментов в структурах метаданных, входящих в состав наборов макроэкономических данных, которые собираются и хранятся в репозиториях; 2) использование этих общностей для развития стандартизации. В работе должен учитываться уже накопленный опыт создания репозиториев метаданных, который есть у IMF и EUROSTAT.
Долгосрочной целью проекта является создание web-сайтов государственных и международных структур и организаций частного сектора с использованием одного и того же словаря поиска. Такие сайты должны предоставлять возможности поиска по ним. При этом один запрос может быть одновременно отправлен по разным адресам, что сделает возможной компиляцию агрегированных результатов. Выполнение этого проекта также будет связано как с деятельностью по практическому исследованию новых электронных стандартов обмена данными, так и с работами по другим проектам, связанным с моделями и словарями данных и метаданных.
Текущее состояние дел по этому проекту также отражено на сайте SDMX-инициативы.
Публикации
Общие открытые стандарты для обмена социально-экономическими данными и метаданными: инициатива SDMX (Common Open Standards for the Exchange and Sharing of Socio-economic Data and Metadata: the SDMX Initiative).
SDMX: движение вперед ().
http://www.sdmx.org/.
Примечани:
1
Инициатива обмена статистическим данными и метаданными.
2
Временной ряд - это набор наблюдений одного и того же явления, при котором каждому наблюдению соответствует определенный момент или период во времени. При этом во внимание принимаются календарные параметры (т.е. моменты или периоды времени) и общественные нормы, связанные с ними (например, что такое рабочая неделя). Макроэкономические данные обычно представлены в виде временных рядов.
3
Термин "перекрестные форматы или данные" (cross-sectional formats/data) используется в случаях, когда основным параметром для организации данных является не время, а какое-либо другое измерение.
4
EDIFACT - Electronic Data Interchange for Administration, Commerce and Transport - Электронный обмен данными для административных органов, коммерческих и транспортных предприятий. Это стандарт синтаксических правил для обмена данными в указанных областях, выпущенный Международной организацией по стандартизации (International Standard Оrganization - ISO) в 1988 г.
document.write('');

Новости мира IT:
02.08 - 02.08 - 02.08 - 02.08 - 02.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 31.07 - 31.07 - 31.07 - 31.07 - 31.07 -
Архив новостей
(66)
2 Август, 17:53
(19)
2 Август, 17:51
(34)
2 Август, 15:40
(42)
2 Август, 15:35
(1)
2 Август, 14:54
(3)
2 Август, 14:34
(3)
2 Август, 14:15
(2)
2 Август, 13:34
(7)
2 Август, 13:04
(3)
2 Август, 12:28
BrainBoard.ru
Море работы для программистов, сисадминов, вебмастеров.
Иди и выбирай!
google.load('search', '1', {language : 'ru'}); google.setOnLoadCallback(function() { var customSearchControl = new google.search.CustomSearchControl('018117224161927867877:xbac02ystjy'); customSearchControl.setResultSetSize(google.search.Search.FILTERED_CSE_RESULTSET); customSearchControl.draw('cse'); }, true);
|
|
| IT-консалтинг | Software Engineering | Программирование | СУБД | Безопасность | Internet | Сети | Операционные системы | Hardware |
| PR-акции, размещение рекламы — , тел. +7 495 6608306, ICQ 232284597 | Пресс-релизы — |
|
|
|
| This Web server launched on February 24, 1997 Copyright © 1997-2000 CIT, © 2001-2009 |
|
|
| Внимание! Любой из материалов, опубликованных на этом сервере, не может быть воспроизведен в какой бы то ни было форме и какими бы то ни было средствами без письменного разрешения владельцев авторских прав. |
|
. |
Стандарт SDMX
Стандарт SDMX определяет форматы для обмена агрегированных статистических данных и метаданных, необходимых для понимания того, как эти данные структурированы. Основное внимание обращается на данные, представленные в виде временных рядов, но также поддерживаются и так называемые перекрестные XML-форматы3. Первая версия стандарта SDMX содержит технические спецификации форматов данных на основе общей информационной модели. Эти форматы используют синтаксис языка XML и технологии EDIFACT4.
Первая версия стандарта SDMX была выпущена в сентябре 2004 г. В декабре того же года, перед представлением стандарта на утверждение в Международную организацию по стандартизации (International Standard Organization - ISO), в некоторые секции первоначальной версии были внесены незначительные изменения. Первая версия стандарта SDMX была представлена в ISO в декабре 2004 г.
Форматы данных SDMX
В отличие от формата SDMX-EDI, который разработан для поддержки преимущественно пакетного обмена, формат SDMX-ML должен удовлетворять более широкому спектру требований. Действительно, XML-форматы используются для множества различных видов автоматизированной обработки данных и, следовательно, должны поддерживать более разнообразные сценарии обработки. Вот почему язык SDMX-ML включает несколько типов сообщений. Каждый из них приспособлен для поддержки определенного набора требований к обработке данных:
Определение структуры (Structure Definition). Все типы сообщений формата SDMX-ML имеют общий способ представления метаданных, необходимых для понимания и обработки набора данных. Этот способ представления основывается на языке XML.
Данные родового типа (Generic Data). Все статистические данные, которые можно оформить с помощью стандарта SDMX-ML, могут быть размечены в соответствии с этим форматом данных согласно содержанию сообщения об определении структуры. Этот формат разработан для предоставления данных на web-сайтах, а также для работы с ними при таких сценариях, когда приложения, получающие данные, не могут детально распознать структуру набора данных до его окончательной загрузки. Данные, оформленные в таком формате, не отличаются компактностью, но зато предоставляют возможность легко использовать все аспекты набора данных. Однако этот формат не обеспечивает строгой проверки соответствия между набором данных и его структурным определением с помощью родового XML-парсера.
Компактные данные (Compact Data). Этот формат имеет отношение только к ключевому понятию того набора данных, который он определяет. Он создается путем последовательных операций преобразования ("мэппинга") между конструкциями метаданных, заданных в сообщении об определении структуры, и компактным форматом. Формат поддерживает обмен больших наборов данных в формате XML (похожем на SDMX-EDI) и предусматривает передачу как неполных (поэтапное обновление), так и целых наборов данных.
Вспомогательные данные (Utility Data). От многих инструментов и технологий XML ожидают выполнения функций, за которые "отвечает" схема XML. Одна из этих функций - тесная связь между XML-конструкциями, описанными в схеме, и данными в соответствующем XML-документе. Жесткое определение типа данных также рассматривается как нормальное явление; оно поддерживает полную проверку данных, снабженных тэгами. Этот тип сообщений, также как и сообщения компактных данных, относится только к ключевому понятию набора данных, но он разработан для поддержки проверки и других функций XML-схемы. Он также может быть получен из сообщения об определении структуры путем проведения ряда стандартных операций преобразования. Для проведения проверки с помощью XML-парсера необходимо, чтобы набор данных был полным.
Перекрестные данные (Cross-Sectional Data). В отличие от данных, ориентированных на обработку в виде временных рядов, часть статистических данных состоит из большого количества наблюдений, полученных в один и тот же момент времени. Этот тип сообщений, так же как и сообщения компактных данных, относится только к ключевому понятию набора данных, но ориентирован на этот отличный от временных рядов способ представления данных. Перекрестный формат основывается на том же описании структуры набора данных, что и другие форматы (форматы временных рядов) для того, чтобы поиск мог осуществляться среди временных рядов, а его результаты затем форматировались для этого типа обработки, если это необходимо.
Запрос (Query). Данные и метаданные часто находятся в базах данных, доступных через интернет. Поэтому возникает необходимость в стандартном документе запроса, который позволял бы осуществлять поиск в базах данных и возвращать результаты в формате SDMX-ML. Документ запроса - это практическое применение информационной модели SDMX для использования в web-сервисах и приложениях, которые управляются базами данных. Он позволяет посылать стандартные запросы провайдерам данных, используя эти технологии.
Поскольку все форматы SDMX-ML являются практическим воплощением одной и той же информационной модели, а все сообщения о данных могут быть получены из сообщения об определении структуры, которое описывает набор данных, то между всеми форматами данных возможно осуществление стандартных операций преобразования. Эти операции могут проводиться с помощью родовых инструментов трансформации, полезных для всех пользователей SDMX-ML. Помимо того, эти инструменты не относятся только к отдельным ключевым понятиям наборов данных, а являются общеупотребительными (даже если форматы, с которыми они имеют дело, являются таковыми).
Модули XML-схемы
В рассматриваемой архитектуре XML-схемы существует так называемая "схема упаковки" (packaging scheme). В основе этой схемы лежит идея, что пространства имен XML могут быть использованы как модули для того, чтобы любой пользователь или приложение могли иметь доступ ко всей библиотеке, даже зная только часть ее.
Каждый модуль - это отдельный экземпляр элемента схемы W3C XML (W3C XML Schema Language), связанный со своим собственным пространством имен XML. В тех случаях, когда эти модули взаимозависимы, они используют механизм импортирования XML-схемы для использования конструкций, описанных в других модулях. Ниже приведено краткое описание этих модулей:
модуль, содержащий конструкции общего сообщения, в том числе общую информацию заголовка, используется со всеми другими модулями SDMX (Файл схемы - "SDMXMessage.xsd");
модуль, содержащий описание структурных метаданных, таких как ключевые понятия, концепции и перечни кодов (Файл схемы - "SDMXStructure.xsd");
модуль, содержащий конструкции, общие для всех типов SDMX-сообщений (Файл схемы - "SDMXCommon.xsd"). Он необходим для всех остальных SDMX-ML-модулей. Для удобства добавлено пространство имен XML ["xml.xsd"], предоставляемое W3C для включения атрибута xml:lang в схемы;
модуль, описывающий родовой формат (т.е. формат, не относящийся только к какому-то одному ключевому понятию) для форматирования данных (Файл схемы "SDMXGenericData.xsd");
модуль для описания структуры сообщения родового запроса (Файл схемы "SDMXQuery.xsd"). Этот модуль необходим, в частности, создателям и пользователям web-сервисов;
модуль, устанавливающий общие рамки для использования во всех схемах, относящихся только к одному ключевому понятию, для обмена, обновления и исправления баз данных (Файл схемы "SDMXCompactData.xsd"). Этот модуль может использоваться при двустороннем взаимодействии;
набор модулей, создаваемых и поддерживаемых теми, кто создает "компактные" схемы, относящиеся к конкретным к ключевым понятиям. Этот набор не поддерживается организацией SDMX;
модуль, устанавливающий общие рамки для использования во всех схемах, относящихся только к одному ключевому понятию, для web-мастеров и разработчиков, использующих стандартные инструменты XML (Файл схемы "SDMXUtilityData.xsd"). Этот модуль необходим для обработки и публикации;
набор модулей, создаваемых и поддерживаемых теми, кто создает "прикладные" ("Utility") схемы, относящиеся только к одному ключевому понятию. Этот набор не поддерживается организацией SDMX;
модуль, устанавливающий общие рамки для использования во всех схемах, относящихся только к одному ключевому понятию, для перекрестных данных (Файл схемы "SDMXCrossSectionalData.xsd"). Этот модуль используется для двусторонней и перекрестной обработки данных;
набор модулей, создаваемых и поддерживаемых теми, кто создает "перекрестные" (Файл схемы "Cross-sectional") схемы, относящиеся только к одному ключевому понятию. Этот набор не поддерживается организацией SDMX.
Пример электронного документа в формате SDMX-ML
В заключение кратко рассмотрим основных конструкций языка SDMX-ML, для чего воспользуемся небольшим примером, входящим в состав пакета спецификаций языка SDMX-ML.
Статистические данные, приведенные в этом примере, это величины внешнего долга, подлежащие погашению, в млн. долларов США. Данные приводятся на каждый месяц на начало отчетного периода:
| Отчетный период | Данные |
| 2000-01 | 3.14 |
| 2000-02 | 3.14 |
| 2000-03 | 4.29 |
| 2000-04 | 6.04 |
| 2000-05 | 5.18 |
| 2000-06 | 5.07 |
| 2000-07 | 3.13 |
| 2008-08 | 1.17 |
| 2000-09 | 1.14 |
| 2000-10 | 3.04 |
| 2000-11 | 1.14 |
| 2000-12 | 3.24 |
XML-код этого примера представлен в
Листинге 1.
Прежде всего стоит обратить внимание на объявления пространств имен, реализующее принцип модульности, о котором шла речь выше.
Корневой элемент <GenericData> используется для передачи данных относящихся к различным основных понятиям. В данном примере в элементе <GenericData> содержатся два сложенных элемента <Header> и <DataSet>. Остановимся на каждом из них.
Элемент первого уровня <Header> определяет заголовочные поля, некоторые из которых представлены в этом примере. Элемент <ID> описывает поток данных, которое в сочетании с указанием времени однозначно идентифицирует набор данных. Элемент <Test> показывает, является ли сообщение тестовым или нет. <Truncated> используется в сообщениях, которые генерируются в ответ на запрос (<Query>), и содержит значение true (истина) только в том случае, если ответ был сокращен в соответствии с требованиями, предъявляемыми к размеру и задаваемыми с помощью атрибута defaultLimit в сообщении запроса. Элементы <Name> и <Prepared> - указывают имя передачи и дату подготовки, соответственно, а <Sender> и <Receiver> несут информацию о передающей и получающей стороне. Элемент <DataSetAgency> содержит идентификатор/сокращение учреждения, хранящего набор данных, а <DataSetID> - идентификатор передаваемого набора данных. Значение элемента <DataSetAction> определяет, является ли данное сообщение обновлением (Update) или подразумевает удаление (Delete) - сообщение нельзя использовать с сообщением UtilityData. <Extracted> -это временная отметка из системы, предоставляющей данные. Наконец, <ReportingBegin> и <ReportingEnd> указывают начало и конец отрезка времени, к которому относится сообщение.
Элемент второго уровня <DataSet> включает одну или несколько групп, которые составляют передаваемый набор данных. Рассмотрим некоторые элементы, входящие в состав <DataSet>: <GroupKey>, <Attributes> и <Series>.
Элемент <GroupKey> содержит знания ключей (элементы <Value>); заметим, что все эти элементы, если они не являются групповыми символами, должны присутствовать и в элементе <Series>. <GroupKey> - необязательный элемент, однако если передаются элементы <Attributes> (т.е. документация - значения ключевых понятий), то <GroupKey> должен присутствовать в сообщении.
Элемент <Series> определяет структуру временного ряда и включает значения ключей (элемент <SeriesKey>), значения для всех атрибутов (элемент <Attributes>) и совокупность наблюдений (элемент <Obs>). Элемент <SeriesKey> описывает содержание ключа временного ряда, при этом для каждого невременного измерения должно быть передано значение (элемент <Value>), причем в том порядке, в котором во ключевом понятии определены измерения. Элемент <Obs> определяет структуру наблюдения - время (элемент <Time>) и значение (элемент <ObsValue>), а также значения для каждого атрибута (<Attributes>), назначенного ключевым понятием для наблюдения.
SDMX-ML - XML-формат обмена статистическими данными и метаданными
Подготовлено: по материалам зарубежных сайтов
Перевод: Intersoft Lab
В статье было рассказано о появлении нового стандарта для обмена статистическими данными и метаданными - SDMX (Statistical Data and Metadata Exchange). Предлагаемый ниже материал посвящен техническим деталям нового стандарта - описанию его основных конструкций и понятий; в нем также приводится фрагмент кода. Первая версия стандарта SDMX выпущена в двух вариантах - на основе XML и синтаксиса EDIFACT1.
Способы организации данных
Основным положением стандарта SDMX является структурированность статистических данных, эта структура названа "ключевым понятием" (key family). "Наборы данных" (data sets) состоят из категорий более низкого порядка - "групп" (groups), которые формируются в зависимости от степени их сходства. Каждая группа, в свою очередь, состоит из одного или нескольких "рядов" (series) данных (или "профилей" (sections) в том случае, если данные представлены не во временных рядах). Каждому ряду или профилю ставится в соответствие так называемый "ключ" (key), т.е. набор значений, соответствующих каждому кластеру так называемых "понятий" (concepts), которые также именуются "измерениями" (dimensions). Этот ключ определяет (идентифицирует) ряд или профиль данных. При этом каждый ряд или профиль данных состоит из одного или более так называемых "наблюдений" (observations), которые обычно включают два элемента: время получения данных и собственно значение (т.е. наблюдаемая величина). Помимо того, метаданные могут быть добавлены на любом уровне этой структуры в качестве описательных "атрибутов" (attributes). "Списки кодов" (сode lists) (или "перечисления" - enumerations) и другие элементы, необходимые для представления данных и метаданных, также используются в тех случаях, когда они могут быть представлены в соответствующих синтаксических форматах.
Между структурой "куба" (cube structure), обычно используемой для обработки статистических данных, и "ключевым понятием" информационной модели SDMX существует некоторое сходство. Важно отметить, что данные, структурированные в соответствие с информационной моделью SDMX, оптимизированы для обмена, в т.ч. с партнерами, которые не имеют технической возможности для обработки данных, поступающих от сложных статистических систем в виде кубических структур. Временные ряды стандарта SDMX могут рассматриваться как "продольные срезы" (slices) куба. Такой срез определяется своим ключом. Ключ содержит значения всех характеристик, входящих в ключевое понятие, за исключением временного измерения. Данные, структурированные в соответствии со стандартом SDMX, могут быть преобразованы в кубические форматы; полученные в результате базы данных могут использоваться для обмена в соответствие с этим стандартом.
и предыдущей статье был рассмотрен
В этой и предыдущей статье был рассмотрен новый стандарт SDMX для обмена статистическими данными и метаданными между различными организациями как на национальном, так и на международном уровне. Данный формат был разработан в рамках так называемой инициативы SDMX - Statistical Data and Metadata Exchange Initiative, возникшей при непосредственном участии крупнейших финансовых и экономических международных организаций, таких как Международный валютный фонд, Европейский Центральный Банк и др.
С полной спецификацией этого стандарта можно познакомиться на сайте SDMX-инициативы: http://www.sdmx.org.
Примечания:
1 См. прим. 4 в статье .
2
Инициатива обмена статистическим данными и метаданными.
document.write('
02.08 - 02.08 - 02.08 - 02.08 - 02.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 31.07 - 31.07 - 31.07 - 31.07 - 31.07 -
Архив новостей
(66)
2 Август, 17:53
(19)
2 Август, 17:51
(34)
2 Август, 15:40
(42)
2 Август, 15:35
(1)
2 Август, 14:54
(3)
2 Август, 14:34
(3)
2 Август, 14:15
(2)
2 Август, 13:34
(7)
2 Август, 13:04
(3)
2 Август, 12:28
BrainBoard.ru
Море работы для программистов, сисадминов, вебмастеров.
Иди и выбирай!
google.load('search', '1', {language : 'ru'}); google.setOnLoadCallback(function() { var customSearchControl = new google.search.CustomSearchControl('018117224161927867877:xbac02ystjy'); customSearchControl.setResultSetSize(google.search.Search.FILTERED_CSE_RESULTSET); customSearchControl.draw('cse'); }, true);
|
|
| IT-консалтинг | Software Engineering | Программирование | СУБД | Безопасность | Internet | Сети | Операционные системы | Hardware |
| PR-акции, размещение рекламы — , тел. +7 495 6608306, ICQ 232284597 | Пресс-релизы — |
|
|
|
| This Web server launched on February 24, 1997 Copyright © 1997-2000 CIT, © 2001-2009 |
|
|
| Внимание! Любой из материалов, опубликованных на этом сервере, не может быть воспроизведен в какой бы то ни было форме и какими бы то ни было средствами без письменного разрешения владельцев авторских прав. |
Будущее Web - за семантикой
Перевод: Intersoft Lab
Оригинал: The future of the Web is Semantic
Общее определение понятия семантика - это изучение значений. (Слово семантика происходит от греческого понятия semantikos, т.е. "важное значение", а в основе последнего лежит слово sema, т.е. знак). Семантические технологии Web помогают выделять полезную информацию из данных, содержания документов или кодов приложений, опираясь на открытые стандарты. Если компьютер понимает семантику документа, то это не означает, что он просто интерпретирует набор символов, содержащихся в документе. Это значит, что компьютер понимает смысл документа.
Семантические технологии Web очерчивают общие рамки, позволяющие осуществлять обмен данными и их многократное использование в различных приложениях, корпорациях и даже сообществах. Семантические технологии Web - это эффективный способ представления данных в интернете. Такую структуру также можно символически отождествить с базой данных, которая связана в глобальном масштабе с содержанием документов в интенете. Причем эта связь осуществляется способом, понятным компьютерам. Семантические технологии представляют значения с помощью онтологии и обеспечивают аргументацию, используя связи, правила, логику и условия, оговоренные в онтологии.
Глобальная схема имен - URI
URI - это просто идентификатор Web, т.е. адреса, начинающиеся с http или ftp. Любой пользователь может создать URI, но права собственности на них четко организованы, поэтому они представляют идеальную базовую технологию для построения глобальной сети. Фактически, интернет является именно такой структурой: все, что имеет URI, считается находящимся в глобальной сети. Любой объект, схема или модель данных семантической сети должны иметь собственный уникальный адрес (URI).
Универсальный указатель ресурсов (Uniform Resource Locator, сокр. URL) - это URI, который, помимо идентификации ресурса, указывает на способ действия или представления ресурса путем описания основного механизма доступа к нему или его положения в сети. Например, URL http://www.webifysolutions.com - это URI, который идентифицирует ресурс (домашняя страница компании Webify Solutions) и указывает, что его представление (т.е. текущий код HTML домашней страницы как набор закодированных символов) можно получить по протоколу HTTP с сетевого узла www.webifysolutions.com.
Универсальное имя ресурса (Uniform Resource Name, сокр. URN) - это URI, который идентифицирует ресурс с помощью имени в определенном пространстве имен. Оно позволяет говорить о ресурсе без использования его местоположения или снятия ссылок на него. Например, URN urn:ISBN:1-0-7666-98-0 - это URI, который, аналогично номеру ISBN, позволяет упоминать книгу, но при этом не указывает, где и как ее можно приобрести.
Компоненты онтологического языка Web на основе OWL
Основные компоненты OWL включают классы, свойства и индивидуальные элементы.
Классы
Классы - это основные блоки онтологии OWL. Класс - это концепция в домене. Классы обычно образуют таксономическую иерархию (т.е. систему подкласс-надкласс).
Классы определяются с помощью элемента owl:Class. В языке OWL существует два заранее определенных класса: owl:Thing и owl:Nothing. Первый из них является наиболее общим и включает все, второй - это пустой класс. Любой класс, определяемый пользователем, является подклассом класса owl:Thing и надклассом класса owl:Nothing. Примеры классов в области банковского дела могут включать классы Счет (Account) или Клиент (Customer).
В листинге 2 представлен пример класса OWL.
Листинг 2. Пример класса OWL
<owl:Class rdf:ID="SavingsAccount"> <rdfs:subclassOf rdf:resource="#Account"/> </owl:Class>
Код в листинге 2 указывает, что элемент SavingAccount - это класс, являющийся подклассом класса Account.
OWL поддерживает шесть основных способов описания классов. Самый простой - это класс с именем (named). Другие типы - это классы пересечений (intersection), объединений (union), дополнений (complement), ограничений (restrictions) и классы перечислений (enumerated). В листинге 2 представлены два из этих способов описания классов: класс ограничений определяет SavingAccount как подкласс класса с именем Account. Ссылку на полный пакет спецификаций классов W3C OWL можно найти в разделе Ресурсы.
Свойства
Свойства включают две основные категории:
свойства объекта (Object properties), которые связывают индивидуальные элементы между собой; свойства типов данных (Datatype properties), которые связывают индивидуальные элементы со значениями типов данных, такими как целые числа, числа с плавающей запятой и строки. Для определения типов данных OWL использует схему XML.
Свойство может включать домен и некоторую область, связанную с ним. Любое свойство попадает в одну из следующих категорий:
функциональная: для любого объекта свойство может принимать только одно значение (например, возраст, рост или вес человека); обратно-функциональная: два различных индивидуальных элемента не могут иметь одно и то же значение. Например, у каждого человека свой уникальный номер банковского счета или так называемый SSN (social security number)1; симметричная: если свойство связывает элемент А с элементом В, то из этого можно сделать вывод, что оно также связывает элемент В с элементом А. Примеры симметричных свойств включают выражения типа "является братом (сестрой)" или "такой же, как"; транзитивная: если свойство связывает элемент А с элементом В, а элемент В с элементом С, то можно предположить, что оно также связывает элемент А с элементом С. Например, если А выше В, а В выше С, то А выше С.
К классам и свойствам могут применяться различные ограничения. Например, ограничения мощности множества указывают на число связей, в которых может участвовать класс или индивидуальный элемент.
Ссылку на полный пакет спецификаций W3C OWL можно найти в разделе Ресурсы.
Индивидуальные элементы
Индивидуальные элементы - это элементы классов; свойства могут связывать их друг с другом. Например, индивидуальный элемент Smith может быть описан как элемент, принадлежащий классу Person (индивидуум). Свойство hasEmployer (имеет работодателя) может связывать его с другим индивидуальным элементом - Webify Solutions, указывая, таким образом, что Smith работает в компании Webify Solutions.
В листинге 3 приведен пример индивидуального элемента OWL.
Листинг 3. Индивидуальный элемент OWL
<owl:Thing rdf:about="SmithAccount"> <rdfs:type="#Account"/> </owl:Class>
Элемент rdf:type - это свойство RDF, которое связывает индивидуальный элемент с тем классом, к которому он принадлежит. Листинг 3 указывает, что элемент SmithAccount принадлежит к типу Account.
На рисунке 2 показаны основные блоки онтологии OWL.
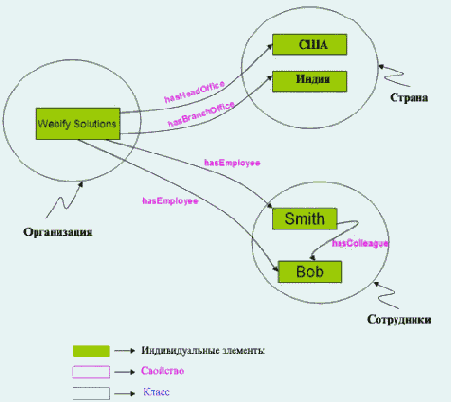
Рис. 2. Онтология OWL, описывающая организационную структуру компании Webify Solutions
Преимущества семантических сетей для интернета
Интернет - это крупнейший из когда-либо существовавших информационных репозиториев, причем его содержание все время растет и представлено на самых разнообразных языках и практически во всех областях знаний. Но в конечном счете становится все труднее находить смысл во всем этом содержимом. Поисковые системы способны находить информацию, содержащую определенные слова, но эта информация не всегда оказывается именно той, что требуется. Какой-то элемент всегда оказывается упущенным. Поиск основан на содержании страниц, но не на семантическом значении этого содержания или информации о странице.
Как только будет создан семантический интернет, он даст возможность разметки всего содержания интернета, описания каждого элемента информации и обеспечения семантического значения этих элементов. Таким образом, поисковые системы становятся более эффективными, чем сейчас, а пользователи могут находить именно ту информацию, которая им необходима. Организации, оказывающие различные услуги, способны индексировать их с особым значением. А пользователи будут в состоянии оперативно находить эти услуги, используя программные средства на основе интернета, и использовать их для своей пользы или в сочетании с другими услугами.
Ресурсы
Учебные
Роль онтологии в автономных компьютерных системах (The role of ontologies in autonomic computing systems). L. Stojanovic, J. Schneider, A. Maedche, S. Libischer, R. Studer, Th. Lumpp, A. Abecker, G. Breiter и J. Dinger. (IBM Research Journal, 2004). Введение в Jena (Introduction to Jena). Philip McCarthy (developerWorks, June 2004). Основы XML и технологий RDF для управления знанием (Basic XML and RDF techniques for knowledge management). Uche Ogbuji (developerWorks, March 2002). Конструирование основ сервис-ориентированной архитектуры с помощью технологии J2EE (Design service-oriented architecture frameworks with J2EE technology). Naveen Balani (developerWorks, January 2004). Предметная классификация с помощью DITA и SKOS (Subject classification with DITA and SKOS). (developerWorks, October 2005). Архитектура Web на портале developerWorks. Блоги на портале developerWorks. Спецификации OWL, RDF и RDF Schema. Язык Notation3.
Продукты и технологии
Webify Solutions: партнер IBM, Webify предоставляет среду интегрированных сервисов на основе онтологии, которая помогает компаниям соответствовать требованиям государства и быстро меняющегося рынка при достижении и поддержки семантического взаимодействия сетей в пределах корпорации, отдельных приложений и доменов партнеров. Интегрированный набор инструментов IBM для разработки онтологии (IBM Integrated Ontology Development Toolkit).
Роль и значение семантических технологий для СОА
Для того чтобы соответствующим образом моделировать и управлять СОА (сервис-ориентированной архитектурой), корпоративные архитекторы должны поддерживать активное представление услуг, доступных для корпорации. В частности, для выявления и организации своих услуг, архитекторы должны использовать передовой опыт в моделировании и объединении услуг с использованием метаданных, преобразовывать бизнес-логику в метаданные для динамического объединения и осуществлять управление с помощью метаданных. Онтология обеспечивает очень мощный и гибкий способ для агрегирования, визуализации и нормализации этого слоя услуг с помощью метаданных.
Онтология - это сеть концепций, связей и ограничений, которые обеспечивают контекст для данных и информации, а также для процессов. Онтология способствует улучшению обнаружения услуг, моделирования, объединения, посредничества и семантического взаимодействия сетей. Она усовершенствует для пользователей способы поиска, изучения и взаимодействия со сложными информационными пространствами метаданных. Бизнес-онтология - это формальная спецификация бизнес-концепций и их взаимосвязей, которая улучшает машинные причинно-следственные связи и взаимодействия. Бизнес-онтология связывает системы, используя метаданные, во многом аналогично тому, как база данных объединяет разрозненные данные. Такая абстракция обеспечивает гибкость и подвижность, поскольку позволяет легко менять интерфейсы, а также добавлять новые ресурсы и пользователей, причем даже во время работы системы.
Семантика - это будущее сервис-ориентированной интеграции. Семантические технологии обеспечивают существование определенного уровня абстракции над существующими IT-технологиями. Этот уровень позволяет осуществлять связь данных, содержания и процессов между различными видами бизнеса и изолированными IT-структурами. Наконец, с точки зрения взаимодействия людей, семантические технологии добавляют новый уровень семантических порталов, которые обеспечивают гораздо более аналитические, соответствующие теме и контексту взаимодействия, чем те, которые доступны с помощью традиционных точечных подходов к интеграции, использующихся в информационных порталах.
Семантические технологии Web
К семантическим технологиям Web относятся следующие:
глобальная схема имен (URI); стандартный синтаксис описания данных (RDF); стандартные способы описания свойств данных (схема RDF); стандартные способы описания связей между объектами данных (онтология, определяемая с помощью онтологического языка Web (Web Ontology Language)).
Ниже более подробно рассматривается каждая из этих технологий.
Стандартные способы описания связей
Синтаксическое взаимодействие сетей - необходимое условие для того, чтобы множественные приложения могли по-настоящему "понимать" данные и работать с ними как с информацией. Это также необходимое условие для корректной проверки данных. Синтаксическое взаимодействие сетей требует преобразования ("мэппирования") между терминами, для чего, в свою очередь, необходим контент-анализ.
Такой контент-анализ требует формальных и подробных спецификаций моделей доменов, которые определяют используемые термины и их связи. Подобные формальные модели доменов иногда называются онтологиями. Они определяют модели данных в терминах классов, подклассов и свойств.
Онтологический язык Web (Web Ontology Language), рекомендуемый консорциумом W3C, помогает в выражении онтологий. Рабочий онтологический язык (Ontology Working Language, сокр. OWL) добавляет больше словарных возможностей для описания свойств и классов, чем RDF или схема RDF. В частности, он позволяет описывать связи между классами (например, неперекрываемость), мощность множества (например, "ровно один"), равенство, более богатую типологию свойств и их характеристики (например, симметрия).
Онтологический язык Web на основе OWL разработан для использования приложениями, которые должны работать с содержанием информации, а не просто предоставлять ее пользователю. OWL улучшает возможности автоматической интерпретации содержимого интернета по сравнению с теми, что могут обеспечить XML, RDF и схема RDF. Это происходит благодаря тому, что OWL предоставляет дополнительные словарные возможности наряду с формальной семантикой. OWL включает три подъязыка: полный OWL (OWL Full), OWL DL и облегченный OWL (OWL Lite) (перечислены в порядке убывания их выразительных возможностей).
Полная версия онтологического языка Web на основе OWL называется OWL Full. Этот язык использует все базисные элементы языка OWL и позволяет комбинировать их случайным образом с RDF и схемой RDF. Полный OWL совместим "снизу вверх" с RDF, как синтаксически, так и семантически: любой разрешенный документ RDF является также разрешенным документом OWL Full. Маловероятно, что какие-либо интеллектуальные программные средства способны поддерживать все возможности OWL Full, поскольку этот язык предлагает максимум выразительных средств и синтаксической свободы RDF при отсутствии вычислительных гарантий. OWL DL предназначен для тех пользователей, кому необходим максимум выразительных средств без потери вычислительных возможностей. OWL DL - это подъязык конструкций языка OWL Full с некоторыми ограничениями, такими как разделение типов (type separation) (например, класс не может быть одновременно индивидуальным элементом или свойством, а свойство не может одновременно быть индивидуальным элементом или классом). OWL Lite предназначен для пользователей, которым необходима классификационная иерархия и простые ограничительные возможности. Преимуществом этого языка являются большая легкость его понимания и внедрения по сравнению с двумя другими. Но в то же время его выразительные возможности гораздо ниже. Например, хотя OWL Lite и поддерживает ограничения мощности множества, единственными допустимыми значениями этого параметра являются 0 или 1.
Примерами онтологий являются каталоги сайтов интерактивных покупок, таких как Amazon.com, стандартные терминологии той или иной области деятельности, например, UNSPSC - The United Nations Standard Products and Services Code (система стандартных продуктов и услуг ООН), или различные таксономические системы интернета, такие как категории сайта "My Yahoo".
В следующих разделах будет подробнее рассказано о различных компонентах OWL.
Стандартные способы описания свойств данных - схема RDF
Схема RDF - это семантическое расширение RDF. Она обеспечивает механизмы описания связанных ресурсов, а также собственно этих связей.
Система классов и свойств схемы RDF похожа на систему типов языков объектно-ориентированного программирования, таких, например, как Java, но отличается от многих других систем. Так, описательный язык словаря RDF определяет свойства в терминах того класса ресурсов, к которому эти свойства относятся. Другие системы же описывают класс в терминах свойств его элементов.
RDF и схема RDF основаны на XML и схеме XML. Существование стандартов для описания данных (RDF) и их атрибутов (схема RDF) позволяет создавать пакеты легко доступных инструментов для чтения и использования данных из многочисленных источников. То, насколько глубоко различные приложения могут обмениваться данными и использовать их, иногда называется синтаксическим взаимодействием сетей (syntactic interoperability). Чем более стандартизированными и распространенными являются эти инструменты работы с данными, тем выше степень синтаксического взаимодействия сетей и тем легче и привлекательнее становится использование подхода на основе семантических сетей по сравнению с точечными интеграционными решениями.
Ссылку на полный пакет моделей данных и спецификаций схемы RDF консорциума W3C можно найти в разделе Ресурсы.
Стандартный синтаксис описания данных - RDF
RDF - это спецификация, которая определяет модель представления мира и синтаксис для сериализации и обмена этой модели. Консорциум всемирной сети (World Wide Web Consortium, сокр. W3C) разработал XML-сериализацию для RDF. RDF XML - это стандартный формат обмена для RDF в семантической сети, хотя он не является единственным. Например, Notation3 - это отличная тестовая альтернативная сериализация.
RDF обеспечивает последовательный стандартный способ описания и работы практически с любыми интернет-ресурсами: от текстовых страниц и графиков до аудио-файлов и видео-клипов. Он предлагает синтаксические возможности для взаимодействия сетей и формирует базовый слой для создания семантической сети. RDF определяет управляемые графы связей, представленные тройками объект-атрибут-значение. Например, объект О имеет атрибут А со значением V.
В листинге 1 представлен пример RDF XML.
Листинг 1. Пример RDF XML
<?xml version="1.0"?> <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:contact="http://www.w3.org/2000/05/contact#">
<contact:Company rdf:about="http://www.w3.org/Organization/contact#WebifySolutions"> <contact:name>Webify Solutions</contact:name> <contact:mailbox rdf:resource="mailto:info@webifysolutions.com"/> <contact:phone>1-800-4WEBIFY</contact:phone> </contact:Company>
</rdf:RDF>
Элемент RDF в листинге 1 несет информацию о ресурсе, в данном случае это компания http://www.w3.org/Organization/contact#WebifySolutions. Компания может быть идентифицирована по URI http://www.w3.org/Organization/contact#WebifySolutions, ее название - Webify Solutions, ее e-mail - info@webifysolutions.com, а номер телефона - 1-800-4WEBIFY.
На рис. 1 показан управляемый граф связей, представляющий ту же информацию.
В данной статье были представлены
В данной статье были представлены основные стандарты, составляющие технологии семантических сетей, а также причины, побуждающие организации использовать эти технологии. С помощью данных технологий организации могут создавать единое унифицированное представление данных во всех приложениях, что позволяет точно находить необходимую информацию, упрощает корпоративную интеграцию и интеграцию СОА, сокращает избыточность данных и обеспечивает единство семантических значений во всех приложениях. Все это, в свою очередь, облегчает разработку, поддержку и обновление приложений в пределах корпорации.
Значение онтологии для бизнеса
IT-системы организуют значения с помощью реляционных моделей данных, плоских файлов, объектно-ориентированных моделей или специально разработанных моделей данных. Время от времени, в связи с изменениями бизнес-требований, возникает необходимость добавления новых элементов и связей в реляционные модели данных или объектно-ориентированные модели.
Более того, если организация использует множественные приложения от различных поставщиков, то придется копировать одни и те же модели во все базы данных приложений. Например, банк предлагает набор различных продуктов для обслуживания разнообразных категорий клиентов. Корпоративному клиенту может потребоваться услуга по обнаружению мошенничества, а обычному потребителю окажется достаточно функциональных возможностей интерактивного осуществления банковских операций с помощью интернета. Обычно банк приобретает приложения у нескольких поставщиков, но каждое из них повторяет одну и ту же общую информацию - номера счетов, имена клиентов и т. д. - в своей базе данных. По мере того как организация добавляет новые продукты для удовлетворения растущих запросов бизнеса, одна и та же избыточная информация распространяется по всей корпорации.
Целый ряд услуг является общим для всех приложений, например, просмотр банковских транзакций и электронных переводов. Каждая из этих услуг также дублируется в формате, присущем тому или иному приложению, что ведет к необходимости осуществления точечной интеграции.
Если же банк принимает подход, основанный на онтологии, то он может собирать и представлять общую информацию о продуктах в нейтральной по отношению к языку форме и сохранять эту информацию в центральном репозитории. С помощью такой общей адаптированной онтологии организация может обеспечивать единое стандартизированное представление данных для всех приложений. Такое стандартизированное представление позволяет точно извлекать необходимую информацию и без проблем осуществлять корпоративную интеграцию, поскольку бизнес-процессы и различные источники данных могут быть связаны ("мэппированы") друг с другом с помощью общей мета-модели. Таким образом, общая онтология исключает необходимость в точечной интеграции и упрощает интеграцию приложений, сокращая избыточность данных и обеспечивая одно и то же семантическое значение для всех приложений, что облегчает поддержание функционирования банка и его обновление.
