CSaxHandler – класс обработчиков SAX-анализатора
Пока мы будем использовать только три обработчика SAX-анализатора – обработчики начала и конца элементов, а также обработчик символьных данных. Это минимум, который необходим для разбора документа. Дополнительно могут потребоваться обработчики ошибок fatalError() и команд обработки processingInstruction(). Последний, в частности, может использоваться для определения кодировки документа, задаваемый в декларации XML атрибутом encoding.
Класс CSaxHandler порожден от класса Qt QxmlDefaultHandler, содержащего весь необходимый набор обработчиков парсера, которые по умолчанию ничего не делают. Для того чтобы расширить функциональность нашего класса, достаточно добавить в него объявление и реализацию соответствующих методов. Очень удобно.
// csaxhandler.h
#ifndef CSAXHANDLER_H #define CSAXHANDLER_H
#include <QXmlDefaultHandler> #include <QStack>
//---------------------------------------------------------------------- // обработчики для SAX-парсера //----------------------------------------------------------------------
class CNode;
class CSaxHandler : public QXmlDefaultHandler { private: CNode* doc; // указатель на объект QStack<CNode*> nodeStack; // стек обрабатываемых элементов QString textElement; // буфер содержимого текстового элемента QString encoding; // кодировка документа public: CSaxHandler(); CSaxHandler(CNode* node); virtual ~CSaxHandler();
// связывание объекта с обработчиками void setDocument(CNode* node); void reset(); // очистить стек и буферы
// обработчики bool startElement(const QString &namespaceURI, const QString &localName, const QString &qName, const QXmlAttributes &attributes); bool characters(const QString &str); bool endElement(const QString &namespaceURI, const QString &localName, const QString &qName); }; //----------------------------------------------------------------------
#endif // CSAXHANDLER_H
Объект, с которым взаимодействует SAX-анализатор при разборе XML-документа, передается в обработчики в виде указателя doc. Это выполняется либо в конструкторе, либо в явном виде методом setDocument().
В определении класса (ниже) видно, что этот указатель помещается в стек nodeStack. В дальнейшем, по мере продвижения по содержимому документа, в этот стек помещаются и удаляются указатели на узлы объекта. Это обеспечивает работу с вложенными объектами узловых классов синхронно с разбором документа.
// csaxhandler.cpp
#include "csaxhandler.h" #include "cnode.h"
//----------------------------------------------------------------------
CSaxHandler::CSaxHandler(){ reset(); }
CSaxHandler::CSaxHandler(CNode* node){ setDocument(node); }
CSaxHandler::~CSaxHandler(){ // doc не удаляем (владелец - внешняя программа)! textElement.clear(); nodeStack.clear(); }
void CSaxHandler::reset(){ doc=0; textElement.clear(); nodeStack.clear(); }
void CSaxHandler::setDocument(CNode* node){ reset(); doc=node;
// корневой элемент nodeStack.push(doc); } //----------------------------------------------------------------------
bool CSaxHandler::startElement(const QString &namespaceURI, const QString &localName, const QString &qName, const QXmlAttributes &attributes){
if(nodeStack.isEmpty()) return false;
// текущий элемент CNode* node=nodeStack.top();
// обрабатываемый элемент if(node) node=node->getNode(localName);
// инициализация реквизитов if(node) node->setRequisites(localName,attributes);
// сделаем его текущим nodeStack.push(node); textElement.clear(); return true; } //----------------------------------------------------------------------
bool CSaxHandler::characters(const QString &str){ textElement+=str; return true; } //----------------------------------------------------------------------
bool CSaxHandler::endElement(const QString &namespaceURI, const QString &localName, const QString &qName){ if(nodeStack.isEmpty()) return false;
CNode* node=nodeStack.top();
// инициализация текстовых элементов if(node && node->isTextElement(localName)){ QXmlAttributes textAttr; textAttr.append(localName,"","",textElement); node->setRequisites(localName,textAttr); }
// элемент обработан nodeStack.pop(); return true; } //----------------------------------------------------------------------
Реквизиты объекта, соответствующие атрибутам исходного документа, инициализируются в обработчике startElement(), реквизиты, соответствующие символьным данным, – в endElement(). Для инициализации используется один и тот же метод интерфейсного класса setRequisites(). Для этого значение текстового элемента записывается в объект класса QXmlAttributes, используемого для передачи атрибутов.
Это искусственный прием, позволяющий сэкономить один метод в интерфейсе CNode. Правда, при этом немного усложняется реализация setRequisites() в узловых классах, поскольку в нем появляется дополнительный условный оператор. Альтернатива – добавление в интерфейс метода инициализации только текстовых реквизитов. Что лучше – судите сами. Автору представляется, что его вариант более экономный.
Собственно, этими двумя классами и ограничивается реализация общего подхода для разбора произвольных XML-документов. Как ими пользоваться – в следующем разделе на примере конкретного документа.
Достоинства и ограничения подхода
Главное достоинство предлагаемого способа заключается в чрезвычайной простоте работы с XML-документом. В качестве примера приведем элементарный пример работы со следующим исходным текстом: <?xml version="1.0" encoding="windows-1251"?> <ED EDNo="805253" EDDate="2005-03-01" EDAuthor="4552000000"/>
Фрагмент программного кода, показывающего работу с атрибутами документа:
// объект CED ed;
// 1. чтение документа (инициализация реквизитов объекта) ed.readDocument(fileName);
// 2. изменение реквизитов ed.EDNo = "1"; ed.EDDate = "2010-03-22"; ed.EDAuthor = "4552000001";
// 3. запись измененного XML-документа ed.writeDocument(fileName);
Выходной документ: <?xml version="1.0" encoding="windows-1251"?> <ED EDNo="1" EDDate="2010-03-22" EDAuthor="4552000001"/>
Этот пример хорошо иллюстрирует цепочку преобразований «XML –> объект –> XML», обеспечивающую последовательное чтение, изменение и запись XML-документа. Объект в середине этой цепочки является представлением документа в виде, удобном для использования в прикладных программах.
Естественно, за любое удобство надо платить. В данном случае платой является то, что с помощью таких объектов можно работать только с документами заранее известной структуры. При изменении структуры документов необходимо, кроме участков кода, где используются реквизиты объекта, менять и само объявление класса, описывающего представление документа.
Здесь мы намеренно не касаемся вопросов эффективного использования оперативной памяти – это отдельная задача, которая должна решаться для каждого конкретного случая. Во всяком случае, автору представляется, что предложенное решение в этом отношении ничуть не хуже, чем использование DOM, но обладает большей гибкостью и удобством использования.
Интерфейсный класс CNode
Класс CNode является предком всех узловых классов объектного представления, включая корневой узел. Объявление этого класса следующее:
// cnode.h
#ifndef CNODE_H #define CNODE_H
#include <QString>
//---------------------------------------------------------------------- // CNode - узел объекта // Интерфейсный класс, обеспечивающий взаимодействие объекта и XML //----------------------------------------------------------------------
// Forward Decls class QXmlAttributes; class QXmlStreamWriter; class QIODevice;
class CNode { private: // вспомогательные методы работы с устройствами записи/чтения bool writeToDevice(QIODevice* device); bool readFromDevice(QIODevice* device); protected: // пространство имен и префикс элемента QString nodeNamespace; QString nodePrefix;
// методы для записи в XML необязательных реквизитов void writeAttribute(QXmlStreamWriter& writer,const QString& name, const QString& value); void writeTextElement(QXmlStreamWriter& writer,const QString& nsUri,const QString& name,const QString& text);
// интерфейсные методы - используются для чтения из XML SAX-парсером friend class CSaxHandler; virtual void setRequisites(const QString &name,const QXmlAttributes &attributes); virtual CNode* getNode(const QString &name); virtual bool isTextElement(const QString &name);
// интерфейсный метод - запись объекта в XML virtual bool writeNode(QXmlStreamWriter& writer,const QString& nsUri); public: CNode();
// наименование узла QString nodeName;
// чтение объекта из XML - из файла или символьного массива bool readDocument(const QString &fileName); bool readDocument(QByteArray* array);
// запись объекта в XML - в файл или символьный массив bool writeDocument(const QString &fileName); bool writeDocument(QByteArray* array);
// флаги, используемые при записи static QString encoding; // кодировка, используемая при записи static bool autoFormatting; // флаг форматирования XML при записи }; //----------------------------------------------------------------------
#endif // CNODE_H
Класс обработчиков парсера CSaxHandler объявлен дружественным, чтобы скрыть интерфейсные методы в защищенной области. Как ранее говорилось, интерфейс должен включать четыре метода:
void setRequisites(const QString &name,const QXmlAttributes &attributes) – инициализация реквизитов объекта; CNode* getNode(const QString &name) – получение указателя на объект узлового класса; метод должен возвращать указатель на объект в случае успеха или 0, если объект с именем name не существует; bool isTextElement(const QString &name) – метод индикации текстовых реквизитов, возвращает true, если реквизит с именем namе является текстовым, и false в противном случае; bool writeNode(QXmlStreamWriter& writer,const QString& nsUri) – запись реквизитов узлового класса; реализация этого метода в прикладных классах зависит от того, какие средства используются для формирования XML-документа; ниже приведен пример реализации с использованием класса Qt QxmlStreamWriter.
Интерфейсный класс обеспечивает методами readDocument() и writeDocument() чтение и запись XML-документа в файл или символьный массив QByteArray, которые подключаются в качестве устройств ввода/вывода. Символьный массив играет роль строки, но с более широкими возможностями работы с различными кодировками XML-документов.
Обратите внимание на реквизит nodeName: его необходимо инициализировать в конструкторах прикладных классов именем элементов XML-документов, отображением которых эти классы являются.
Определение класса CNode также не отличается чрезмерной сложностью. Как уговаривались, для базового класса все интерфейсные методы имеют реализации по умолчанию, позволяющие не определять их в наследниках, если в этом нет необходимости:
// cnode.cpp
#include "cnode.h"
#include "cnode.h" #include "csaxhandler.h" #include <QFile> #include <QBuffer> #include <QXmlStreamWriter> //----------------------------------------------------------------------
QString CNode::encoding = "WINDOWS-1251"; bool CNode::autoFormatting = true; //----------------------------------------------------------------------
CNode::CNode(){ } //---------------------------------------------------------------------- // интерфейсные методы //----------------------------------------------------------------------
void CNode::setRequisites(const QString &name,const QXmlAttributes &attributes){ // ничего не делается - для классов, не содержащих реквизиты }
// указатель на узел элемент CNode* CNode::getNode(const QString &name){ if(name==nodeName) return this; else return 0; }
// проверка, является ли элемент текстовым bool CNode::isTextElement(const QString &name){ return false; }
bool CNode::writeNode(QXmlStreamWriter& writer,const QString& nsUri){ return true; } //---------------------------------------------------------------------- // запись необязательных реквизитов ЭС //----------------------------------------------------------------------
void CNode::writeAttribute(QXmlStreamWriter& writer,const QString& name, const QString& value){ if(!value.isEmpty()) writer.writeAttribute(name, value); }
void CNode::writeTextElement(QXmlStreamWriter& writer,const QString& nsUri,const QString& name,const QString& text){ if(!text.isEmpty()) writer.writeTextElement(nsUri,name,text); } //---------------------------------------------------------------------- // чтение из XML (при совпадении типов документа и объекта) //----------------------------------------------------------------------
bool CNode::readDocument(const QString &fileName){ QFile device(fileName); return readFromDevice(&device); }
bool CNode::readDocument(QByteArray* array){ QBuffer device(array); return readFromDevice(&device); }
bool CNode::readFromDevice(QIODevice* device){ if(!device->open(QIODevice::ReadOnly | QIODevice::Text)) return false;
QXmlInputSource xmlInputSource(device); CSaxHandler handler(this);
QXmlSimpleReader reader; reader.setContentHandler(&handler); bool ok=reader.parse(xmlInputSource);
device->close(); return true; } //---------------------------------------------------------------------- // запись в XML //----------------------------------------------------------------------
bool CNode::writeDocument(const QString &fileName){ QFile device(fileName); return writeToDevice(&device); }
bool CNode::writeDocument(QByteArray* array){ array->clear(); QBuffer device(array); return writeToDevice(&device); }
bool CNode::writeToDevice(QIODevice* device){ QXmlStreamWriter writer(device);
if(!device->open(QIODevice::WriteOnly)) return false;
writer.setAutoFormatting(autoFormatting);
// формирование xml-документа writer.setCodec(encoding.toAscii().data()); writer.writeStartDocument(); if(!nodeNamespace.isEmpty()) writer.writeNamespace(nodeNamespace, nodePrefix); // вызов виртуального метода writeNode(writer,nodeNamespace); writer.writeEndDocument();
device->close(); return true; } //----------------------------------------------------------------------
В качестве SAX-анализатора в приведенном коде используется класс Qt QXmlSimpleReader. Для его работы нужны обработчики, которые реализованы в виде класса CSaxHandler и помещены в отдельный модуль. Для записи документа используется, как уже упоминалось, класс Qt QXmlStreamWriter .
Для методов, обеспечивающих чтение и запись XML-документов, необходимо дать некоторые пояснения.
Во-первых, понятно, что метод чтения readDocument() вызывается для уже созданного объекта конкретного типа, и исходный XML-документ должен соответствовать этому типу. Поэтому в общем случае при чтении не известного заранее документа необходимо сначала определить его тип по имени корневого элемента и создать нужный объект. Это несложно, а то, как это сделать – смотрите в библиотеке QLibUfebs по приведенному выше адресу. Здесь же этот случай не рассматривается.
Что касается записи XML-документа, то в нашем случае для записи атрибутов и текстовых элементов в методах прикладного класса используются, соответственно, методы QXmlStreamWriter::writeAttribute() и QXmlStreamWriter::writeTextElement(). Чтобы облегчить реализацию записи необязательных реквизитов, предусмотрены методы CNode::writeAttribute() и CNode::writeTextElement() с очень похожим синтаксисом, которые формируют атрибут или элемент только для непустых значений.
Исходный XML-документ
В качестве исходного документа, для которого будем реализовывать объектное представление, возьмем слегка упрощенный документ специализированного формата ED201 (по сравнению с оригинальным форматом, в нашем документе отсутствуют один атрибут и пара текстовых элементов). Это сделано с целью упрощения иерархии объекта:
<?xml version="1.0" encoding="WINDOWS-1251"?> <ED201 xmlns="urn:cbr-ru:ed:v2.0" CtrlCode="0999" CtrlTime="10:13:37" EDNo="805253" EDDate="2010-03-24" EDAuthor="4552000000"> <Annotation>Ошибка при обработке ЭС</Annotation> <EDRefID EDNo="1000" EDDate="2010-03-24" EDAuthor="4525545000"/> </ED201>
Использование в прикладной программе
Здесь приведен пример использования сконструированных классов в прикладной программе.
Входной документ: <?xml version="1.0" encoding="WINDOWS-1251"?> <ED201 xmlns="urn:cbr-ru:ed:v2.0" CtrlCode="0999" CtrlTime="10:13:37" EDNo="805253" EDDate="2010-03-24" EDAuthor="4552000000"> <Annotation>Ошибка при обработке ЭС</Annotation> <EDRefID EDNo="1000" EDDate="2010-03-24" EDAuthor="4525545000"/> </ED201>
Слот xmlSlot() выполняет чтение XML-документа text, содержащегося в текстовом редакторе textEdit, в объект ed. Затем с использованием этого объекта выполняется изменение реквизитов и запись объекта в выходной XML-документ out, который добавляется в текстовый редактор для отображения на экране: void MainWindow::xmlSlot(){ QByteArray in; QString text=textEdit->toPlainText(); in.append(text);
// 1. чтение XML-документа CED201 ed; ed.readDocument(&in);
// 2. работа с реквизитами ed.EDNo = "1"; ed.EDDate = "2010-03-01"; ed.EDAuthor = "4552000001";
// 3. запись XML-документа QByteArray out; ed.writeDocument(&out);
textEdit->append(""); textEdit->append(out); }
В результате получаем XML-документ: <?xml version="1.0" encoding="windows-1251"?> <ed:ED201 xmlns:ed="urn:cbr-ru:ed:v2.0" EDNo="1" EDDate="2010-03-01" EDAuthor="4552000001" CtrlCode="0999" CtrlTime="10:13:37"> <Annotation>Ошибка при обработке ЭС</Annotation> <EDRefID EDNo="1000" EDDate="2010-03-24" EDAuthor="4525545000"/> </ed:ED201>
Объявления узловых классов
Узловые (прикладные) классы конструируются очень просто:
Порождаем их от CNode. В защищенной части (protected) класса объявляем четыре виртуальных интерфейсных метода. Для классов в конце иерархии наследования их можно объявлять и в закрытой области (private). Есть только особенность, касающаяся метода writeNode() – он вызывается для объектов, являющихся членами других объектов (в документе это – вложенные элементы). В таких случаях есть выбор – либо прятать этот метод и объявлять друзей класса, либо объявлять его в открытой области; В открытой части объявляем конструктор по умолчанию и реквизиты с именами, совпадающими с именами атрибутов или текстовых элементов. Вложенные элементы объявляются как члены в виде объектов других узловых классов.
Часто бывает, что нет необходимости объявлять некоторые из методов. Например, в CEDRefID нет текстовых элементов, вложенных объектов, поэтому отсутствуют isTextElement() и getNode(): // cbr_ed201.h
#ifndef cbr_ed201H #define cbr_ed201H
#include "cnode.h"
//----------------------------------------------------------------------
// EDRefID
class CEDRefID : public CNode { protected: virtual void setRequisites(const QString &name,const QXmlAttributes &attributes); public: virtual bool writeNode(QXmlStreamWriter& writer,const QString& nsUri); CEDRefID();
// Methods & Properties QString EDNo; QString EDDate; QString EDAuthor; }; //----------------------------------------------------------------------
// ED201
class CED201 : public CEDRefID { private: virtual void setRequisites(const QString &name,const QXmlAttributes &attributes); virtual CNode* getNode(const QString &name); virtual bool isTextElement(const QString &name); virtual bool writeNode(QXmlStreamWriter& writer,const QString& nsUri); public: CED201();
// Methods & Properties QString CtrlCode; QString CtrlTime; QString Annotation; CEDRefID EDRefID; }; //----------------------------------------------------------------------
#endif
Имена реквизитов в классах объявлены с нарушением принятого в C++ стиля именования (с прописной буквы). Это не небрежность автора. Дело в том, что в описании форматов XML-документов, для которых реализованы эти классы, принята именно такая нотация. А в объявление класса они попали методом «copy/paste». И вообще, весь подход объектного представления направлен на то, чтобы процесс конструирования сводился к простым формальным приемам.
Пример для документа с повторяющимися элементами
Случай, когда в XML-документе имеется множественное включение одноименных элементов, встречается достаточно часто, и поэтому стоит рассмотреть реализацию объектного представления для таких документов. В качестве примера возьмем документ ED232 (тоже немного упрощенный): <?xml version="1.0" encoding="WINDOWS-1251"?> <ED232 xmlns="urn:cbr-ru:ed:v2.0" EDAuthor="4525000000" EDDate="2008-03-14" EDNo="1005"> <PLAN BS="10101" RKC="2" Type="2"/> <PLAN BS="10207" RKC="1" Type="2"/> <PLAN BS="10208" RKC="1" Type="2"/> </ED232>
Объявление класса для этого документа может выглядеть так (опускаем объявление класса CPLAN): class CPLAN; typedef QVector<CPLAN *> CPLANList;
class CED232 : public CED { private: virtual CNode* getNode(const QString &name); virtual bool writeNode(QXmlStreamWriter& writer,const QString& nsUri); public: CED232(); ~CED232();
CEDRefID InitialED; CPLANList PLAN; };
Как видно, повторяющаяся часть документа реализована в виде списка с использованием шаблона QVector, аналогичного вектору стандартной библиотеки. В список содержатся указатели на объекты, созданные в памяти. Поэтому для класса CED232 нужен деструктор, который освобождает память, занятую объектами CPLAN: CED232::~CED232(){ for(int i=0; i<PLAN.size(); i++) delete PLAN[i]; }
Методы класса можно реализовать так: CNode* CED232::getNode(const QString &name){ if(name==nodeName) return this; else if(name=="PLAN"){ CPLAN* info=new CPLAN(); PLAN.push_back(info); return info; }else return 0; } //----------------------------------------------------------------------
bool CED232::writeNode(QXmlStreamWriter& writer,const QString& nsUri){ writer.writeStartElement(nsUri,nodeName); writer.writeAttribute("EDNo", EDNo); writer.writeAttribute("EDDate", EDDate); writer.writeAttribute("EDAuthor", EDAuthor);
for(int i=0; i<PLAN.size(); i++) PLAN[i]->writeNode(writer,nsUri);
writer.writeEndElement(); return true; }
Пример иерархии прикладных классов
На рисунке представлена статическая UML-диаграмма класса, являющегося объектным представлением нашего XML-документа:
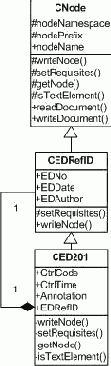
Намеренно выбран пример, где один из узловых классов (CEDRefID), объект которого включен в качестве члена класса CED201, используется также и как предок этого класса. Такие структурные решения являются обычным делом в объектном проектировании, и позволяют значительно сэкономить затраты за счет повторного использования кода. И, как можно будет убедиться далее, это оказывает влияние на метод записи данных при формировании XML-документа.
Реализация классов
Для наглядности в данном подразделе текст модуля cbr_ed201.cpp разделен на части, с комментариями перед каждой его частью.
В конструкторе узлового класса CEDRefID задаются пространство имен nodeNamespace и его префикс nodePrefix. Это не обязательно. Можно опустить либо оба присвоения (тогда действует ранее объявленное или пространство имен по-умолчанию), либо опустить префикс. Если не задавать префикс, тогда он будет формироваться в соответствии с областью действия пространства имен в форме «n1», «n2» и т.д.: // cbr_ed201.cpp
#include "cbr_ed201.h" #include <QXmlAttributes> #include <QXmlStreamWriter> //----------------------------------------------------------------------
// EDRefID CEDRefID::CEDRefID(){ // пространство имен nodeNamespace = "urn:cbr-ru:ed:v2.0"; nodePrefix = "ed"; }
Так выполняется присвоение реквизитов объекта, являющихся аналогом атрибутов XML-документа (для текстовых элементов будет показано ниже): // инициализация реквизитов документа при чтении ЭД void CEDRefID::setRequisites(const QString &,const QXmlAttributes &attributes){ EDNo=attributes.value("EDNo"); EDDate=attributes.value("EDDate"); EDAuthor=attributes.value("EDAuthor"); }
Поскольку EDRefID является элементом исходного документа (узлом), для него определен метод writeNode(), начинающийся с записи открывающего тега writeStartElement() и заканчивающийся записью закрывающего тега writeEndElement(): bool CEDRefID::writeNode(QXmlStreamWriter& writer,const QString& nsUri){ writer.writeStartElement(nsUri,nodeName); writer.writeAttribute("EDNo", EDNo); writer.writeAttribute("EDDate", EDDate); writer.writeAttribute("EDAuthor", EDAuthor); writer.writeEndElement(); return true; }
Для узловых классов задаем имя nodeName, совпадающее с именем открывающего тега элемента исходного документа. Для вложенных элементов надо придерживаться правила – если элементы одинакового типа встречаются в документах с разными именами, то nodeName задается в конструкторе класса-владельца, если везде имена одинаковые – то в своем конструкторе. Однако, чтобы избежать ошибок, предпочтителен первый способ: // ED201 CED201::CED201(){ nodeName="ED201"; EDRefID.nodeName="EDRefID"; }
В методе setRequisites() приведен пример инициализации текстового реквизита Annotation, об этой особенности уже упоминалось выше. Если опустить первое условие, то после инициализации текстового реквизита произойдет очистка остальных реквизитов, т.к. аргумент attributes их не содержит.
Инициализацию реквизитов класса-родителя CEDRefID можно выполнить либо явным образом, как и остальные реквизиты (что может привести к проблемам при изменении формата документа), либо вызовом метода с явным разыменованием (предпочтительно): // инициализация реквизитов документа при чтении ЭД void CED201::setRequisites(const QString &name,const QXmlAttributes &attributes){ if(name=="Annotation") Annotation=attributes.value(name); else{ // инициализация реквизитов базового класса CEDRefID::setRequisites(name,attributes);
CtrlCode=attributes.value("CtrlCode"); CtrlTime=attributes.value("CtrlTime"); } }
Этот метод должен быть определен в двух случаях – если класс содержит вложенные объекты (в нашем случае – EDRefID), либо если в классе есть реквизиты, являющиеся аналогом текстовых элементов (Annotation): CNode* CED201::getNode(const QString &name){ if(name==nodeName name=="Annotation") return this; else if(name=="EDRefID") return &EDRefID; else return 0; }
Для класса, содержащего реквизиты – аналог текстовых элементов, нужно определить этот метод: bool CED201::isTextElement(const QString &name){ return (name=="Annotation"); }
В данном примере есть небольшая особенность. Реквизиты EDNo, EDDate, EDAuthor наследуются от класса СEDRefID, но использовать метод СEDRefID::writeNode() мы не можем, т.к. в этом случае сформируются открывающий и закрывающий теги элемента. Поэтому запись этих реквизитов выполняется так, как если бы они были объявлены в CED201: bool CED201::writeNode(QXmlStreamWriter& writer,const QString& nsUri){ writer.writeStartElement(nsUri,nodeName); writer.writeAttribute("EDNo", EDNo); writer.writeAttribute("EDDate", EDDate); writer.writeAttribute("EDAuthor", EDAuthor); writer.writeAttribute("CtrlCode", CtrlCode); writer.writeAttribute("CtrlTime", CtrlTime); writer.writeTextElement(nsUri,"Annotation", Annotation); EDRefID.writeNode(writer,nsUri); writer.writeEndElement(); return true; }
В заключение несколько слов о записи необязательных реквизитов. Если какой-либо атрибут может отсутствовать в XML-документе, то его запись нужно выполнять, используя альтернативные методы интерфейсного класса CNode::writeAttribute(),CNode::writeTextElement(). Например, запись writer.writeAttribute("EDNo", EDNo);
надо заменить на следующую: writeAttribute(writer, "EDNo", EDNo);
Реализация подхода
Объем кода, который обеспечивает реализацию предложенного подхода, не очень большой, поэтому он приведен в этом разделе почти полностью. Из классов удалены лишь некоторые несущественные детали (например, флаги, специфичные для конкретной реализации, обработчик ошибок).
Исходные тексты, приведенные ниже, разбиты на два модуля – cnode.cpp и csaxhandler.cpp.
Список использованной литературы
Мартин Д., Бирбек М., Кэй М. и др. XML для профессионалов. – М.: Лори, 2001. – 900 с. Qt 4.6.2 Reference Documentation. Copyright © 2010 Nokia Corporation and/or its subsidiary(-ies).
Структура класса повторяет структуру XML-документа
Само по себе использование объекта для представления XML-документа никакого выигрыша не дает, все дело в том, как инициализировать реквизиты объекта. Те примеры, которые приведены в [1] или в составе Qt SDK, оптимизма не вселяли – организация работы по использованию данных документа в этих примерах возлагалось на обработчики SAX-анализатора: startElement(),endElement() и characters(). Естественно, такое решение для работы с большим набором различных форматов XML-документов не подходило.
Поэтому сразу появилась мысль всю работу по чтению (инициализации) и записи объектов возложить на сами объекты, а обработчики парсера сделать независимыми от формата исходного документа. Сделать это достаточно просто, используя такие замечательные свойства C++, как наследование и полиморфизм. А третий «кит» объектно-ориентированного языка (инкапсуляция) позволяет так реализовать классы объектного представления, что будущее (неизбежное!) изменение формата документов уже не будет представляться такой уж сложной задачей.
Итак, вспомним, как SAX-анализатор выполняет разбор XML-документа – он начинает с верхнего (корневого) узла и проходит по дереву, в узлах которого находятся элементы XML-документа. Когда встречается открывающий тег элемента, происходит вызов обработчика startElement(), куда передается список значений атрибутов этого элемента; когда парсер достигает закрывающего тега – вызывается endElement(). Обработка символьных данных выполняется иначе, но, как будет показано ниже, эти отличия не играют существенной роли.
Для выполнения инициализации реквизитов объекта необходимо, чтобы каждому структурному элементу XML-документа был поставлен в соответствие структурный элемент класса, описывающего представление. Иными словами, необходимо, чтобы структура класса повторяла структуру XML-документа. Это легко выполнить, если потребовать, чтобы при конструировании классов каждый элемент (узел) исходного документа отображался в свой класс, который назовем узловым классом.
Атрибуты или текстовые элементы исходного документа реализуются в классе в виде членов-данных, вложенные элементы исходного документа – в виде объектов других узловых классов. Как правило, если XML-документ был спроектирован правильно, каждый узловой класс представляет собой некую сущность предметной области, поэтому узловые классы еще называют прикладными.
И, наконец, если у каждого узлового класса будет общий предок, на которого возложим интерфейсные функции, то нетрудно обеспечить, чтобы из обработчиков вызывались соответствующие методы этого интерфейсного класса. Для этого обработчики должны оперировать указателем на интерфейсный класс (да здравствует полиморфизм!).
Узловые классы имеют общего предка
Интерфейс между парсером и объектным представлением XML-документа обеспечивается специальным классом, который, как уже было указано выше, должен быть предком всех узловых (прикладных) классов. Требования к интерфейсному классу (назовем его CNode, префикс «C» от англ. class) диктуются спецификацией SAX-анализатора.
Во-первых, самое очевидное:
Интерфейсный класс должен предоставить метод инициализации (присвоения) реквизитов объекта.
Атрибуты и текстовые элементы (символьные данные) отображаются в объектном представлении одинаково – в виде реквизитов (членов-данных) класса. Однако обрабатываются они по-разному: атрибуты – в обработчике startElement(), символьные данные – в обработчике endElement(). Дело в том, что парсер передает программе символьные данные посредством обработчика characters(), однако уверенность в том, что данные были переданы полностью, появляется только при достижении парсером конца элемента, содержащего эти данные. Для того чтобы вызвать интерфейсный метод инициализации для текстового элемента, необходимо знать, что тип этого элемента – текстовый. Таким образом, можно сформулировать второе требование к интерфейсу: В интерфейсе должен быть предусмотрен метод индикации текстовых элементов. Он должен выполнять простую задачу – по имени элемента сообщить, является ли он символьным или нет.
Получив в обработчике endElement() информацию о том, что текущий элемент был символьным, можно смело вызывать метод инициализации реквизитов.
И, наконец, обработчики должны обращаться к методам конкретного объекта (или его структурной части). Начинается разбор всегда с корневого узла, но по мере продвижения по дереву документа, должен меняться указатель на текущий узел объекта. Таким образом: Интерфейсный класс должен иметь метод получения указателя на текущий узел объекта.
Если текущий узел объекта не содержит других объектов, то метод просто возвращает this. В противном случае указатель инициализируется на нужный вложенный узел. Последнее требование должно сопровождаться организацией в обработчиках парсера стека указателей таким образом, чтобы обработчики всегда работали с текущим узлом объекта.
Сформулированные выше требования относятся к взаимодействию объектного представления с SAX-анализатором в процессе чтения (разбора) XML-документа.
Запись документа может выполняться с использованием любых средств, предоставляемых выбранным средством программирования. В Qt такие достаточно удобные средства предоставляет класс QXmlStreamWriter. Реализация записи, учитывая древовидную природу XML, должна быть распределена по иерархии объектного представления, поэтому в интерфейсе выделяем еще один метод, а именно: В нем должен иметься метод записи узлового объекта в XML-документ.
Итак, для обеспечения интерфейса с парсером и классом записи документа в интерфейсе CNode должны быть предусмотрены четыре виртуальных метода. Все эти методы должны иметь реализацию по умолчанию, чтобы в порожденных классах можно было выполнять определение только тех методов, какие действительно необходимы. Взаимодействие объектов с парсером осуществляется через средства, представляемые CNode. Обработчики парсера в данном случае выполнены в виде класса CSaxHandler.
Это, так сказать, обеспечение заявленного универсального подхода. О реализации этих двух классов – в следующем разделе.
В данной статье предлагается простой
В данной статье предлагается простой и достаточно универсальный способ работы с XML-документами в программах C++ с использованием SAX-анализатора, приводятся примеры его использования.
Подход был разработан при реализации классов C++ для работы с XML-документами специализированных форматов. Библиотека была предназначена для проектов Qt, поэтому предлагаемый способ также опирается на средства Qt. Соответственно, приводимые здесь примеры взяты из упомянутого проекта. Но, поскольку интерфейс SAX хорошо стандартизован, этот подход можно перенести на другие реализации SAX-анализатора.
Термин «объектное представление» XML-документов, используемый в данной статье, означает то, что содержимое документов описывается в программе C++ в виде классов, и работа с XML-документами, элементами и атрибутами документа в программе сводится к работе с объектами и членами-данными этих объектов. Далее для простоты вместо термина «член-данное» будем использовать «реквизит».
Статья ориентирована на программистов, знакомых с объектно-ориентированным программированием на C++ и принципами работы SAX-анализатора.
то может показаться, что объем
Кому- то может показаться, что объем кода, который нужно определить при использовании предложенного объектного представления XML-документа, больше, чем хотелось бы. Однако это не так. Например, для того чтобы использовать так называемые «свойства» классов (property, расширение C++Builder), в реализации аналогичной библиотеки с использованием DOM приходится определять довольно много кода. К примеру, определение класса CED101 в упомянутой библиотеке занимает около 300 строк, когда как при использовании предлагаемого подхода – всего 120. И это притом, что в DOM не надо заботиться о записи XML-документов в файл.
Правда, справедливости ради надо отметить, что большая часть кода в C++Builder генерируется автоматически по XSD-схемам специальным инструментом XML Data Binding wizard. Но и ручной работы после этого остается достаточно.
PMML и главенство Хранилищ данных
Есть и еще одно различие во взглядах (а также подспудно существующая причина непонимания) в области data mining.
Всегда существует различие во мнениях между аналитиками, разрабатывающими модели, и SQL-программистами, обслуживающими Хранилище данных. Оно возникает из-за не очень изящного (с точки зрения аналитиков) традиционного способа осуществления data mining.
Хранилище данных всегда было важной составляющей анализа, поскольку это то место, где данные согласованы и объединены. Но во многих случаях data mining не производится в самом Хранилище. Вместо этого данные выгружаются из Хранилища и помещаются во внешний репозиторий.
Такой подход, однако, является не самым эффективным в смысле производительности и оперативности. Эти проблемы могут быть решены с помощью SQL-моделей. Компании, использующие уже существующие стандарты, вложили в это большие инвестиции, и в том числе в оплату недешевых услуг аналитиков. Поэтому они хотят окупить свои вложения в программное обеспечение и ресурсы, но они также хотят использовать и возможности осуществления data mining в самом Хранилище.
И PMML позволяет им это сделать. PMML устраняет необходимость перемещения данных на другой сервер, сокращая, таким образом, время на доставку данных и запуск модели. Теперь аналитики, разрабатывающие модели, могут просто предложить клиенту свою продукцию, которая работает в самой базе данных, а необходимость создания запросов на языке SQL отпадает.
PMML: возможности data mining для всех?
Подготовлено: по материалам зарубежных сайтов
Перевод: Intersoft Lab
Мы продолжаем знакомить читателей с различными XML-форматами. В предыдущем номере журнала мы подробно рассказывали о стандарте обмена статистическими данными и метаданными (Инициатива SDMX: новые подходы к обмену статистическими данными и ), в этом вы можете найти статью о - языке определения данных о рынках. Предлагаемый материал посвящен важному событию - появлению на рынке еще одного нового формата - языка разметки для прогнозного моделирования (predictive modeling mark-up language, сокр. PMML), который наконец-то начинает широко использоваться после восьми лет, потраченных на его создание и усовершенствование.
PMML - это XML-диалект, который используется для описания статистических моделей и моделей data mining. Его главное преимущество заключается в том, что PMML-совместимые приложения позволяют легко обмениваться моделями данных с другими PMML-инструментами. Разработка и внедрение PMML осуществляется IT-консорциумом Data Mining Group.
Одно из существенных достоинств PMML, по словам его сторонников, - это то, что PMML делает data mining более демократичным, т.е. превращает его из занятия, доступного лишь избранным, искушенным в тонкостях уже существующих программных продуктов, в средство, которым могут воспользоваться многие. В результате пользователи, не знакомые с тонкостями ранее разработанных программ, могут эффективно работать с уже созданными моделями данных PMML. Пользователям необходимо часто использовать модели - ежедневно или даже несколько раз в день, и это именно то, для чего существует PMML, - для практической работы с моделями данных.
Как и другой долго разрабатывавшийся стандарт, XML-язык запросов (XML Query language, сокр. XQuery), PMML также потребовал немало времени для своего создания. Но в отличие от Xquery, PMML развивался с течением времени. Пять лет назад появилась его первая версия - 1.1. Сегодня существует уже третья версия этого диалекта (3.0), а многие компании предлагают различные виды поддержки для использования этой технологии.
Практическое использование PMML
По мнению Дэна Фридмэна (Dan Friedman), директора консалтинговой фирмы по маркетингу программного обеспечения DHF Consulting, существует несколько причин, заставляющих поставщиков программного обеспечения включать PMML-поддержку в свои продукты. Но основной из них является необходимость удовлетворения разнообразных требований к разработке и практическому использованию моделей данных.
Фридмэн считает, что для прогнозных статистических моделей важны два элемента: время разработки и продолжительность рабочего цикла. Разработка осуществляется независимо, обычно с использованием уже существующих статистических пакетов. Она может занять несколько недель или месяцев и обычно выполняется высоко квалифицированными аналитиками.
Преимущество PMML, по его мнению, заключается в том, что этот диалект может способствовать сокращению рабочего цикла модели. Продолжительность рабочего цикла зависит от того, как модель встраивается в операционную систему, такую как CRM (Customer Relationship Management - системы управления отношениями с клиентами) или финансовую систему. Обычно модель запускается и используется для получения неких показателей, с которыми потом работают в соответствии с определенными бизнес-правилами или иной бизнес-логикой. Такая оценка проводится в режиме реального времени и занимает менее секунды.
Фридмэн также указывает на различия во взглядах между статистиками и специалистами в той или иной сфере бизнеса. PMML может помочь и здесь. Проблема заключается в том, что практическое использование модели и ее создание требуют совершенно разных навыков. На практике использование модели осуществляется "предметниками", которые глубоко понимают бизнес-процесс, но не являются экспертами компьютерного обучения или статистиками. Статистики же хорошо знают математику, но не знакомы с бизнес-процессом. Поэтому те, кто на практике работает с моделями, хотят иметь доступ к инструментам моделирования и других компаний, а также быть уверенными в том, что они могут максимально эффективно использовать эти инструменты. Поскольку практические пользователи моделей не являются специалистами в области моделирования, они стараются применять уже существующие стандарты для того, чтобы быть уверенными: они смогут работать с большинством моделей, которые будут созданы сегодня или в будущем.
По мнению Тоби Данна (Toby Dunn), IT-специалиста отдела образования одного из известных штатов Юго-Запада, в этом случае PMML может оказаться наиболее практичным выбором для решения многих неприятных проблем бизнеса. Ему можно верить: ранее он работал в фирме, которая разрабатывала модели данных для банков и компаний, выпускающих кредитные карты. Эти модели включали оценки кредитоспособности, прогноз доходов и формирование очередей в центре обработки запросов. Они разрабатывались с помощью SAS и устанавливались на сайте клиента с использованием соответствующей программы, написанной на языке Java.
Одна из проблем, связанных с таким подходом, заключается в том, что программа на Java, созданная в компании клиента, должна быть способна работать с моделями данных, разработанными в другой организации, а также с уже существующими и будущими моделями самих клиентов.
Как утверждает Данн, диалект PMML способен решить эту проблему. PMML стал использоваться по двум причинам. Во-первых, это известный и стабильный стандартный набор тэгов, который каждый может найти в интернете. Таким образом, независимо от того, кто разрабатывал модель, ее авторам необходимо было всего лишь представить эту модель клиенту в определенной версии PMML. Клиент, в свою очередь, мог быстро и легко внедрить ее в свою систему. Во-вторых, с помощью PMML можно было производить вычисления, необходимые для того, чтобы соответствующая программа Java работала надлежащим образом и выдавала отчет пользователю.
Часто используемые конструкции (встречаются, по крайней мере, в трети из рассмотренных схем)
Наиболее часто используемые конструкции XML-схем. Здесь также доминирует упрощение. Лучше всего начать проектирование схемы с этого набора.
квалифицированные элементы пространства имен: использование конструкции elementFormDefault="qualified" для эксплицитности пространства имен элемента;
xsd:sequence: использование элемента xsd:sequence. Это наиболее часто используемый композитор. Он рекомендуется вместо конструкции xsd:all, поскольку устраняет двусмысленные модели и дочерние элементы следуют в определенном порядке;
расширение complexType: создание типа, которые расширяет другой тип, – одна из главных возможностей повторного использования и расширяемости;
анонимные типы (anonymous types): используются в тех случаях, когда создаваемые типы имеют локальный масштаб и, следовательно, у них отсутствует атрибут @name. Это бывает очень часто. В инструментальных средствах анонимные типы не приветствуются, но практически везде есть их поддержка;
ограничение simpleType: производное от simpleType, ограничивающее базовый тип;
перечисления (enumerations): перечень значений - одна из наиболее часто встречающихся конструкций.
Чем занимаются проектировщики схем?
Следующим этапом исследования предполагалось сделать шаг вперед по сравнению с работой Костелло и попытаться выяснить, какие из элементов xml-схемы нашли реальное практическое применение. Есть ли согласие во мнениях касательно наиболее часто используемых конструкций? Существуют ли особенности, которых проектировщики стараются избегать?
Для этого были собраны данных из 1400 схем, полученных от множества консорциумов. Цель состояла в том, чтобы выяснить, существует ли единый профиль xml-схемы, отражающий согласие практиков.
Предполагалось, что именно схемы консорциумов, стандартные и внедряющиеся в каждой предметной области множество раз, не только имеют различное влияние на рынке, но и должны показать групповое согласие по критериям разработки. Кроме того, они находятся в свободном доступе.
Достоинства и недостатки
Первый шаг на пути изучения профиля – анализ схемы как таковой. Плюсы и минусы многих методов разработки схем нам, фактически, уже известны. Они описаны на вебсайте Роджера Костелло (Roger Costello), который проделал огромную работу по сбору комментариев и мнений разработчиков, а также по объединению и анализу преимуществ и недостатков многих критериев проектирования. Разработчики схем уже несколько лет обращаются к его сайту.
На практике при создании схем также может быть интересен вопрос влияния каждой из конструкций на дальнейшее внедрение. Некоторые возможности используются повсеместно и хорошо поддерживаются в интегрированных средах разработки (IDEs) и других инструментах, как, например, кодогенерирующее ПО. Однако среди них есть и малоиспользуемые, которые могут вызвать определенные проблемы из-за отсутствия достаточной инструментальной поддержки.
Инструментальная поддержка
Во многих зарекомендовавших себя инструментах поддержка XML-схемы обеспечивается на высоком уровне. В частности, интегрированные среды разработки (IDE) для редактирования схем предлагают достаточно средств поддержки даже для проблемных конструкций, таких как xsd:union. Проблема инструментальной поддержки может проявляться в двух формах:
если принято решение не поддерживать выбранные конструкции схемы. Это усложняет формирование профиля.
«специализированные» инструменты часто предлагают поддержку только для самых общих конструкций схем, в их первичном виде. По мере развития инструмента могут добавляться дополнительные конструкции. Автор данной публикации ведет блог, связанный с поддержкой xml-схем, где содержатся ссылки на несколько инструментов генерирования кода и опубликованных заявок на поддержку.
Источники
Рассматривались схемы следующих организаций:
The Open Applications Group (OAGi)
The Open Travel Alliance (OTA)
Human Resources XML (HR-XML)
Chemical Industry Data Exchange (CIDX)
IMS Global Learning Consortium (IMS)
Association for Retail Technology Standards (ARTS)
Mortgage Industry Standards Maintenance Organization (MISMO)
World Wide Web Consortium (W3C, including mathML)
Global Justice XML
ACORD
Есть еще множество других консорциумов, информация от которых могла бы использоваться и, скорее всего, будет добавлена к данному анализу.
История вопроса
Профиль – это набор согласованных методик, отражающих наиболее приемлемые практические способы применения данной технологии. Профиль использования XML-схемы отражает ряд конструкций, которые обычно реализуются и поддерживаются инструментами.
Концепция профиля XML-схемы обсуждалась уже несколько лет. В 2004-м году консорциум Web Services Interoperability сформировал для исследования идеи формального профиля XML-схемы. В результате консорциум W3C вынужден был провести (XML Schema 1.0 User Experiences), где данные из множества источников были объединены в один план действий. Недавно появился проект документа , где представлены .
Кроме того, многие отраслевые консорциумы разработали руководства или шаблоны для разработки библиотек схем, согласно своему профилю. Изучив как формально, так и неформально многие из них, можно сделать вывод о допустимости или недопустимости тех или иных возможностей XML-схемы. Появились и инструменты, помогающие в разработке профилей схем.
Schematron используется для добавления дополнительных ограничений, помимо тех, что уже есть в схеме. Mindreef's SOAPScope Server
содержит подробно разработанную поддержку для создания настраиваемых профилей схем, предлагая стандартный список ограничений, которые налагаются в различных тестовых случаях. Однако сложно сказать, является ли этот профиль пригодным для межотраслевого использования.
данные
Данные в представленных ниже таблицах отражают результаты исследования. Они взяты с соответствующих сайтов (большинство из которых перечислено здесь). Рис. 1 – это итоговые результаты. На рис. 2 показано, какое количество схем содержит ту или иную конструкцию, а на рис. 3 – число раз, когда эта функция была встречена в той или иной схеме.
Рис. 1. Итоговые показатели
Рис. 2. Количество схем, где используются перечисленные конструкции
Рис. 3. Как часто встречаются данные конструкции
Проблемы с инструментальной поддержкой
Эти возможности XML-схем используются часто, но инструментальная поддержка для них не развита. Прежде чем добавить тот или иной элемент в схему, стоит выяснить, поддерживается ли он конкретным программным средством.
attributeGroup: группировка атрибутов по имени для повторного использования; конструкция похожа на xsd:group.
Эта конструкция встречалась в тестируемых схемах чаще, чем используется на практике. Во-первых, одна организация использовала ее очень часто, а многие другие – избегали. Во-вторых, в анализе учитывался xsd:attributeGroup как для объявлений, так и для повторного использования конструкции @ref. Поэтому, фактически, частота примененияattributeGroups может быть существенно меньше. В большинстве инструментов поддержка этой конструкции не слишком осложнена, но просто не имеет высокого приоритета;
xsd:choice: использование композитора xsd:choice.Некоторые поставщики инструментов озабочены применением этой функции, поскольку ее сложно отобразить в виде программной конструкции. Однако используют ее часто;
значения по умолчанию (default values): объявление значений по умолчанию для данных в XML-сущности. О них говорилось здесь;
xsd:union: использование конструкции xsd:union для комбинирования типов в декларации. Эта функция XML-схемы реже всего поддерживается программными инструментами;
шаблоны (pattern): Использование регулярных выражений, в частности, для подстановки строк;
другие фасеты (facets): к ним относятся фасеты, отличные от шаблонов и перечислений, в том числе: minInclusive, maxInclusive, maxInclusive, minExclusive, whitespace, fractionDigits, length, minLength, maxLength . Поддержка в инструментах может различаться;
списковые типы (list types): использование элемента xsd:list. Эта функция встречается только в 10% схем из тестовой выборки. Иногда не поддерживается программным инструментом, что может быть причиной проблем. Программисты часто жалуются на сложности с обработкой и синтаксическим анализом списковых типов. Предпочитают перечисления или отдельные типы данных.
Замечание по поводу групповых символов (wildcards)
По результатам анализа они находятся в середине списка по частоте использования, однако, вероятнее, их применяют чаще. Некоторые из консорциумов создают единый элемент расширения группового символа, на который в дальнейшем ссылаются (с помощью конструкции "@ref") по мере необходимости. Поэтому фактическое количество встретившихся в анализе групповых символов ниже, чем в реальности.
Профилирование XML-схемы
Пол Киль (Paul Kiel)
Перевод:
Оригинал:
XML-схеме уже пять лет, из «новорожденного младенца» эта спецификация превратилась в довольно энергичного «юношу». Что же нам известно о нем? С самого начала было ясно, что явление это сложное. И действительно, исходные дебаты том, стоит ли сделать эту спецификацию Рекомендации, уже выявили проблему. (См. материалы «Последнее слово» и «Опрос разработчиков XML-схем»). Этот богатый инструментарий поставил перед разработчиками задачу выбора тех функций, которые им нужно (или не нужно) использовать. Если проанализировать, что фактически было реализовано, то можно дать какие-то рекомендации.
Автор попытался провести исследование, которое позволит скомпилировать некий профиль XML-схемы, основанный на известном на сегодняшний день опыте.
Редко используемые конструкции (встречающиеся в схемах реже, чем в 10% случаев)
Перечисленные ниже функции либо не встречались вообще, либо использовались крайне редко.
xsd:all: использование композитора xsd:all. Предпочтительно применять вместо него xsd:choice или xsd:sequence;
финализация (finalizing): использование атрибутов @final или @finalDefault. Ни одна из протестированных схем не содержала таких атрибутов. Как правило, в схемах используются разрешающие конструкции, а не отменяющие (как эта);
substitutionGroup: позволяет подставлять одни элементы в другие. В рассмотренных схемах такая возможность не использовалась, хотя является обычным механизмом расширения. Вероятно, ее отсутствие обусловлено характером рассмотренных схем. Схемы открытых стандартных отраслевых консорциумов могут обойтись и без нее, однако при внедрении организации могут использовать substitutionGroups для расширяемости;
уникальность (Uniqueness): использование элемента unique требует, чтобы его содержимое отличалось от остальных элементов в пределах его области видимости. Казалось бы, это удобно, ведь потребность в уникальных идентификаторах вполне естественна. Однако, как выяснилось, в большинстве случаев для таких элементов используются строковые данные. Возможно, уникальность используется на бизнес-уровне передачи данных между системами;
квалифицированные атрибуты (qualified attributes): использование конструкции attributeFormDefault="qualified". Она не применяется практически ни в одной схеме, хотя многие разработчики используют квалифицированные элементы;
ключи (keys): использование элементов key и keyref;
переопределение: использование элемента redefine для определения существующего компонента. Эта функция практически не поддерживается в инструментах. Можно сказать, что ее избегают.
nillable: использование атрибута @nillable, обуславливающее использование xsi:nil в экземпляре, указывающее, что содержимое имеет значение null;
block: использование атрибута @block для запрета производных;ограничение
complexType: ограничение модели типом complexType. Несколько лет назад, в HR-XML, эту функцию рассматривали как возможность использовать генерализованный тип данных, который ограничивается в зависимости от контекста его применения. Однако эта конструкция оказалась громоздкой и плохо поддерживалась;
абстрактные типы (аbstract types): использование конструкции abstract="true" на элементах или типах;
mixed: установка атрибута mixed="true" позволяет комбинировать данные и дочерние элементы в одном месте.
Разработчики схем четко разделили эти концепции на определенные типы;
группы (groops): использование xsd:group позволяет определять группу для дальнейшего повторного использования. Однако такие элементы чаще всего употребляются с конструкцией "@ref", а не добавляются в группы;
фиксированные значения (fixed values): использование атрибута @fixed на элементах, атрибутах или простых типах;
отказ от использования @targetnamespace: возможно, в дальнейшем связывании схем не будут использоваться конструкции @targetNamespace. Однако в большинстве протестированных схем они применялись. Более того, в некоторых руководствах их использование считается обязательным;
отказ от объявления области имен по умолчанию (default namespace): отсутствие "@xmlns" областей имен по умолчанию.
Возможно, в дальнейшем это ограничение войдет в силу. Однако в проанализированных схемах такие области имен применялись повсеместно;
области имен по умолчанию не должны совпадать с @targetnamespace: такая ситуация возникает, когда области имен по умолчанию не соответствуют @targetNamespace. Однако в большинстве схем они имеют одно и то же значение. Это еще раз свидетельствует о тенденции к упрощению.
Результаты: Профиль XML-схемы
1414 рассмотренных схем показали очевидное стремление к упрощению. По крайней мере, где-то треть из них имела всего шесть структурных средств. И лишь в десяти и менее процентов случаев можно было наблюдать 17 средств. Многие из неиспользуемых конструкций применяются только в очень специфических случаях.
Кроме упрощения, характерна эксплицитность схем. Она выражается в очень четком и ясном задании имен в отсутствии моделей со смешанным содержимым и абстрактными типами, в предпочтении конструкции xsd:sequence перед xsd:all.
схем можно сформировать, рассматривая существующие
Четкий профиль использования XML- схем можно сформировать, рассматривая существующие на сегодняшний день наработки. Именно в нем отражены основные черты пятилетнего развития технологии. Основная тенденция - упрощение. В большинстве своем, конструкции содержат простые используемые типы, которые комбинируются в последовательности элементов, и дополняются перечислениями. Многие сложные функции оказались неиспользуемыми. Кроме того, тестирование показало эксплицитность схем. Редко комбинируется или абстрагируется содержимое, элементы отделяются от значений по умолчанию. Для проектировщиков использование основных шаблонов, предложенных в профиле XML-схемы, может оказаться очень полезным.
Замечания к рисункам
Несколько дублированных схемы не использовались в анализе, такие как схемы схем (XMLSchema.xsd), которые обычно распространяются со многими библиотеками. Ассоциация ACORD предлагает для своих схем отмену пространства имен. В данном исследовании использовались только именованные версии. В тестовых файлах организаций HR-XML и OAGi анализировались версии разработчиков или неавтономные версии. И хотя в OAGi-схемах не применялись substitutionGroups, но проектирование глобальных элементов все-таки предполагает использование подстановок в качестве возможности расширения. Набор схем W3C включает mathML.
