Неупорядоченные списки (UL), упорядоченные списки (OL) и элементы списков ()
<!ELEMENT - - (LI)+ -- неупорядоченный список --> <!ATTLIST UL -- , , -- > <!ELEMENT - - (LI)+ -- упорядоченный список --> <!ATTLIST OL -- , , -- >
Начальный тег: обязателен, Конечный тег: обязателен
<!ELEMENT - O ()* -- элемент списка --> <!ATTLIST LI -- , , -- >
Начальный тег: обязателен, Конечный тег: не обязателен
Определения атрибутов
type = информация о стиле
Этот атрибут устанавливает стиль элемента списка. Доступные в настоящее время значения предназначены для визуальных агентов пользователей. описаны ниже (включая информацию о регистре).
start
=
Только для . Этот атрибут задает начальный номер первого элемента в упорядоченном списке. По умолчанию начальный номер - "1". Помните, что, хотя значением этого атрибута является целое число, соответствующая метка может быть нецифровая. Если в качестве стиля выбраны латинские буквы верхнего регистра (A, B, C, ...), start=3 означает "C". Если в качестве стиля выбраны римские цифры нижнего регистра, start=3 означает "iii" и т.д.
value = число [CN] Нежелетельно. Только для . Этот атрибут устанавливает номер текущего элемента списка. Помните, что, хотя значением атрибута является целое число, соответствующая метка может быть нечисловая (см. атрибут ).
compact
Если этот логический атрибут установлен, он сообщает визуальным агентам пользователей о том, что генерировать список нужно более компактно. Интерпретация этого атрибута зависит от агента пользователя.
Атрибуты, определяемые в любом другом месте
, () (), () () () , , , , , , , , , (внутренние события)
Упорядоченные и неупорядоченные списки генерируются одинаково за исключением того, что визуальные агенты пользователей нумеруют упорядоченные списки. Агенты пользователей могут представлять эти номера несколькими способами. Элементы неупорядоченного списка не нумеруются.
Оба эти типа списков состоят из последовательностей элементов списков, определяемых элементом LI (конечный тег которого можно опустить).
В этом примере показана общая структура списка.
<UL> <LI> ... первый элемент списка...
<LI> ... второй элемент списка...
... </UL>
Списки могут быть вложенными:
ПРИМЕР НЕЖЕЛАТЕЛЬНОГО ИСПОЛЬЗОВАНИЯ:
<UL> <LI> ... Уровень один, номер один...
<OL> <LI> ... Уровень два, номер один...
<LI> ... Уровень два, номер два...
<OL start="10"> <LI> ... Уровень три, номер один...
</OL> <LI> ... Уровень два, номер три...
</OL> <LI> ... Уровень один, номер два...
</UL>
Информация о порядке номеров. В упорядоченных списках невозможно продолжать нумерацию автоматически из предыдущего списка или убрать нумерацию для некоторых элементов. Однако авторы могут пропустить несколько элементов списка, установив для них атрибут value. Нумерация для последующих элементов списка продолжается с нового значения. Например:
<ol> <li value="30"> элемент списка номер 30. <li value="40"> элемент списка номер 40. <li> элемент списка номер 41. </ol>
Объявление и инициализация объекта
В приведенных выше примерах были показаны отдельные определения объектов. Если в документе должно содержаться несколько экземпляров одного и того же объекта, объявление и инициализацию объекта можно разделить. Такой способ имеет несколько преимуществ:
Данные могут загружаться агентом пользователя из сети один раз (во время объявления) и повторно использоваться в каждой инициализации. Инициализировать объект можно из местоположения, отличного от того, в котором объект объявлялся, например, из ссылки. Объекты можно определять в качестве рабочих данных для других объектов.
Чтобы объявить объект так, чтобы он не обрабатывался агентом пользователя при чтении, установите логический атрибут элемента . В то же время авторы должны идентифицировать объявление, установив уникальное значение для атрибута в элементе . Инициализация объекта позже будет ссылаться на этот идентификатор.
Объявленный должен присутствовать в документе до первого экземпляра .
Объект, определенный с атрибутом , инициализируется каждый раз, когда необходима генерация элемента, ссылающегося на этот объект (например, активизируется ссылка на него, активизируется объект, ссылающийся на него и т.д.).
В следующем примере мы объявляем и вызываем его инициализацию, указав его в ссылке. Таким образом объект можно активизировать, щелкнув, например, на выделенном тексте.
<P><OBJECT declare id="earth.declaration" data="TheEarth.mpeg" type="application/mpeg"> Вид <STRONG>Земли</STRONG> из космоса. </OBJECT> ...далее в документе...
<P>Красивое<A href="#earth.declaration"> анимационное изображение Земли!</A>
В следующем примере показано, как указать рабочие значения, являющиеся другими объектами. В этом примере мы отправляем текст (стихотворение) гипотетическому механизму для просмотра стихотворений. Объект распознает рабочий параметр с именем "font" (скажем, для генерации текста стихотворения с использованием определенного шрифта). Значение этого параметра само является объектом, вставляющим (но не генерирующим) объект шрифта. Отношение между объектом шрифта и объектом механизма просмотра стихотворений достигается с помощью (1) назначения атрибута в объявлении объекта шрифта и (2) ссылки на него в элементе объекта механизма просмотра стихотворений (с помощью и value).
<P><OBJECT declare id="tribune" type="application/x-webfont" data="tribune.gif"> </OBJECT> ...просмотр стихотворения из файла KublaKhan.txt...
<P><OBJECT classid="http://foo.bar.com/poem_viewer" data="KublaKhan.txt"> <PARAM name="font" valuetype="object" value="#tribune"> <P>У вас нет такой классной программы просмотра стихотворений... </OBJECT>
Агенты пользователей, не поддерживающие атрибут , должны генерировать содержимое объявления .
Общее включение: элемент OBJECT
<!ELEMENT - - (PARAM | )* -- общий внедренный объект --> <!ATTLIST OBJECT -- , , -- (declare) #IMPLIED -- объявить, но не instantiate флаг -- #IMPLIED -- определяет применение -- #IMPLIED -- базовый URI для classid, data, archive-- #IMPLIED -- ссылка на данные объекта -- #IMPLIED -- тип содержимого для данных -- #IMPLIED -- тип содержимого для кода -- #IMPLIED -- разделенный пробелами список архивов -- #IMPLIED -- сообщение, отображаемое при загрузке -- #IMPLIED -- переопределение высоты -- #IMPLIED -- переопределение ширины -- #IMPLIED -- использовать клиентскую навигационную карту -- #IMPLIED -- представить в качестве части формы -- #IMPLIED -- положение в последовательности перехода -- >
Начальный тег: обязателен, Конечный тег: обязателен
Определения атрибутов
classid = uri
Этот атрибут может использоваться для указания местоположения объекта с помощью URI. Он может использоваться вместе с атрибутом или как альтернатива ему, в зависимости от типа объекта.
codebase =
Этот атрибут определяет базовый путь, используемый для разрешения относительных адресов URI, задаваемых в атрибутах , и . Если этот атрибут отсутствует, значением по умолчанию является базовый адрес URI текущего документа.
codetype = [CI]
Этот атрибут определяет тип содержимого данных, получения которых следует ожидать при загрузке объекта, задаваемого атрибутом . Этот атрибут не является обязательным, но рекомендуется, если используется атрибут , поскольку он позволяет агенту пользователя избежать загрузки информации для типа содержимого, который он не поддерживает. Если этот атрибут отсутствует, по умолчанию используется значение атрибута type.
data = uri
Этот атрибут может использоваться для указания местоположения данных объекта, например, данных изображения для объектов, определяющих изображения, или в более общем случае - serialized формы объекта, который может использоваться для повторного его создания. Если дается относительный адрес URI, он должен интерпретироваться относительно атрибута codebase.
type = [CI]
Этот атрибут определяет тип содержимого для данных, задаваемых атрибутом . Этот атрибут не является обязательным, но рекомендуется, если используется атрибут , поскольку он позволяет агенту пользователя избежать загрузки информации для типа содержимого, который они не поддерживают.
archive =
Этот атрибут может использоваться для определения разделенного пробелами списка адресов URI архивов, содержащих относящиеся к объекту ресурсы, который может включать ресурсы, задаваемые атрибутами и . Предварительная загрузка архивов приведет к уменьшению времени загрузки объекта. Архивы, указанные в виде относительных адресов URI, должны интерпретироваться относительно атрибута codebase.
declare
Если этот логический атрибут указан, он делает текущее определение только объявлением. Объект должен быть instantiated последующим определением , ссылающимся на это объявление.
standby = text
Этот атрибут определяет сообщение, которое агент пользователя может генерировать при загрузке implementation и данных объекта.
Атрибуты, определенные в другом месте
, () (), () () () , , , , , , , , , (внутренние события) () () () , , , , , ()
В большинстве агентов пользователей имеются встроенные механизмы для генерации основных типов данных, таких как текст, изображения в формате GIF, цвета, шрифты и ряд графических элементов. Для генерации типов данных, которые агенты пользователей не поддерживают по умолчанию, они обычно запускают внешние приложения. Элемент позволяет авторам управлять генерацией данных - задавать внешнюю генерацию или использование некоторой определяемой автором программы, генерирующей данные в агенте пользователя.
В более общем случае автор должен будет определить три типа информации:
Реализация включенного объекта. Например, если включенный объект - апплет, автор должен указать местоположение исполняемого кода апплета.
Генерируемые данные. Например, если включенный объект является программой, генерирующей данные шрифта, автор должен указать местоположение этих данных.
Дополнительные значения, необходимые объекту. Например, некоторым апплетам могут быть нужны исходные значения для их параметров.
Элемент позволяет авторам указать все три типа данных объекта, но авторы не обязательно должны указывать их все. Например, некоторым объектам не требуются данные (например, апплет, выполняющий анимацию). Другим может быть не нужна инициализация. Другим же может не понадобиться дополнительная информация о реализации, то есть сам агент пользователя может уже знать, как генерировать этот тип данных (например, изображения в формате GIF).
Авторы задают реализацию объекта и местоположение данных, генерируемых с помощью элемента . Однако для указания рабочих значений авторы используют элемент , обсуждаемый в разделе об
Элемент OBJECT может также присутствовать внутри элемента . Поскольку агенты пользователей обычно не генерируют элементы в , авторам следует убедиться, что во всех элементах в нет содержимого, которое можно генерировать. Пример включения элемента в элемент см. в разделе о совместном использовании данных кадра.
Информацию об элементе в формах см. в разделе об управлении формами.
Отношения документов: элемент LINK
<!ELEMENT - O EMPTY -- независимая от устройства ссылка --> <!ATTLIST LINK -- , , -- #IMPLIED -- кодировка символов связанного ресурса -- #IMPLIED -- URI связанного ресурса -- #IMPLIED -- код языка -- #IMPLIED -- рекомендуемый тип содержимого -- #IMPLIED -- тип прямой связи -- #IMPLIED -- тип обратной связи -- #IMPLIED -- для представления на этих устройствах -- >
Начальный тэг: обязателен, Конечный тэг: запрещен
Атрибуты, определяемые в другом месте
, ()
(), ()
()
()
, , , , , , , , , (внутренние события)
, , , , ()
()
(информация о стиле заголовка)
()
Этот элемент определяет связь. В отличие от элемента , он может присутствовать только в разделе документа, хотя может присутствовать неограниченное число раз. Хотя элемент не имеет содержимого, он содержит информацию об отношениях, которая может представляться агентами пользователей различными способами (например, в виде панели с выпадающим списком ссылок).
В данном примере показано, как несколько определений элемента могут быть представлены в разделе документа. Текущим документом является "Chapter2.html". Атрибут указывает отношение связанного документа с текущим документом. Значения "Index", "Next" и "Prev" описаны в разделе, посвященном .
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0//EN" "http://www.w3.org/TR/REC-html40/strict.dtd"> <HTML> <HEAD> <TITLE>Глава 2</TITLE> <LINK rel="Index" href="../index.html"> <LINK rel="Next" href="Chapter3.html"> <LINK rel="Prev" href="Chapter1.html"> </HEAD> ...продолжение документа...
Отображение информации в кавычках
Визуальные агенты пользователей обычно генерируют элемент как блок с отступом.
Визуальные агенты пользователей должны обеспечивать отображение содержимого элемента с кавычками в начале и в конце. Авторы не должны помещать кавычки в начало и в конец текста в элементе .
Агенты пользователей должны генерировать кавычки с учетом принятого в данном языке стиля (см. атрибуты ). Во многих языках используются различные стили для внешних и внутренних (вложенных) кавычек, которые должны соответственно отображаться агентами пользователей.
В примере ниже показаны вложенные кавычки в элементе .
John said, <Q lang="en">I saw Lucy at lunch, she says <Q lang="en">Mary wants you to get some ice cream on your way home.</Q> I think I will get some at Ben and Jerry's, on Gloucester Road.</Q>
Поскольку в обеих цитатах используется английский язык, агенты пользователей должны генерировать их соответственно - одиночные кавычки во внутренних кавычках и двойные - во внешних:
John said, "I saw Lucy at lunch, she told me 'Mary wants you to get some ice cream on your way home.' I think I will get some at Ben and Jerry's, on Gloucester Road."
Примечание.В реализации таблиц стилей рекомендуется обеспечение механизма вставки кавычек перед цитатой, определяемой элементом , и после нее в соответствии с текущим языком и степенью вложенности кавычек.
Однако, поскольку некоторые авторы использовали элемент в основном для отступа текста, чтобы не нарушать намерения авторов, агенты пользователей не должны вставлять кавычки в стиль по умолчанию.
В связи с этим использование элемента для смещения текста .
Переход к ресурсу, на который указывает ссылка
По умолчанию со ссылкой связана загрузка другого ресурса Web. Это поведение достигается обычно путем выбора ссылки (например, с помощью щелчка мыши, ввода с клавиатуры и т.д.).
В следующем HTML-фрагменте содержится две ссылки, у одной целевым anchor является документ HTML с именем "chapter2.html", а у второй целевой anchor - изображение в формате GIF, расположенное в файле "forest.gif":
<BODY> ...какой-то текст...
<P>Подробнее см. в <A href="chapter2.html">главе два</A>. См. также <A href="../images/forest.gif">карту леса.</A> </BODY>
Путем активизации этих ссылок (с помощью щелчка мыши, ввода с клавиатуры, голосовых команд и т.д.) пользователи могут перейти к этим ресурсам. Обратите внимание, что атрибут в каждом исходном anchor указывает адрес целевого anchor с использованием URI.
Целевой anchor ссылки может быть элементом в документе HTML. Целевому anchor должно даваться имя и адрес URI, адресующий этот anchor, Должен содержать это имя в качестве идентификатора фрагмента.
Целевые anchors в документах HTML могут указываться с помощью элемента (именующего его с помощью атрибута ) или с помощью любого другого элемента (именующего с помощью атрибута ).
Таким образом, например, автор может создавать оглавление, элементы Которого являются ссылками на элементы заголовков , и т.д. в том же документе. Используя элемент для создания целевых anchors, можно записать:
<H1>Содержание;/H1> <P><A href="#section1">Введение</A><BR> <A href="#section2">Предыстория</A><BR> <A href="#section2.1">Более конкретные заметки</A><BR> ...продолжение содержания...
...тело документа...
<H2><A name="section1">Введение</A></H2> ...раздел 1...
<H2><A name="section2">Предыстория</A></H2> ...раздел 2...
<H3><A name="section2.1">Более конкретные заметки</A></H3> ...раздел 2.1...
Этого же эффекта можно достигнуть, сделав якорями сами элементы заголовка:
<H1>Содержание</H1> <P><A href="#section1">Введение</A><BR> <A href="#section2">Предыстория</A><BR> <A href="#section2.1">Более конкретные заметки</A><BR> ...продолжение содержания...
...тело документа...
<H2 id="section1">Введение</H2> ... раздел 1...
<H2 id="section2">Предыстория</H2> ... раздел 2...
<H3 id="section2.1">Более конкретные заметки</H3> ...раздел 2.1...
Переносы
В HTML имеется два типа переносов: простой и мягкий перенос. Простой перенос должен интерпретироваться агентами пользователя просто как любой другой символ. Мягкий перенос показывает агенту пользователя, где можно сделать переход на новую строку.
Браузеры, которые интерпретируют мягкие переносы, должны обеспечивать следующую семантику: если строка прекращается в месте мягкого переноса, в конце первой строки должен отображаться символ переноса. Если строка не прерывается в месте мягкого переноса, символ переноса отображаться не должен. При выполнении таких операций как поиск и сортировка мягкие переносы всегда должны игнорироваться.
В языке HTML простой перенос представляется символом "-" (- или -). Мягкий перенос представляется комбинацией символов ­ (­ или ­)
Подсчет числа столбцов в таблице
Имеется два способа определения числа столбцов в таблице (в порядке старшинства):
Если элемент включает элементы или , агенты пользователей должны подсчитывать число столбцов, суммируя следующие цифры:
Для каждого элемента - значение его атрибута (по умолчанию 1).
Для каждого элемента , содержащего по крайней мере один элемент - игнорировать атрибут для элемента . Для каждого элемента выполнить вычисление из шага 1.
Для каждого пустого элемента - значение его атрибута (по умолчанию 1).
В противном случае, если элемент не содержит элементов или , агенты пользователей определять число столбцов из того, что необходимо для строк. Число столбцов равно число столбцов, необходимых строке с наибольшим числом столбцов, включая ячейки, span несколько столбцов. Для любой строки, число столбцов в которой меньше, конец этой строки будет дополняться пустыми ячейками. "Конец" строки зависит от .
Если таблица содержит элементы или , и эти два способа подсчет дают разные результаты, это является ошибкой.
Когда агент пользователя подсчитал число столбцов в таблице, он может сгруппировать их в
Например, для каждой из следующих таблиц, оба способа подсчета числа столбцов должны дать три столбца. Первые три таблицы могут генерироваться последовательно.
<TABLE> <COLGROUP span="3"></COLGROUP> <TR><TD> ...
...строки...
</TABLE>
<TABLE> <COLGROUP> <COL> <COL span="2"> </COLGROUP> <TR><TD> ...
...строки...
</TABLE>
<TABLE> <COLGROUP> <COL> </COLGROUP> <COLGROUP span="2"> <TR><TD> ...
...строки...
</TABLE>
<TABLE> <TR> <TD><TD><TD> </TR> </TABLE>
Подсчет ширины столбцов
Авторы могут указывать ширину столбцов тремя способами:
Фиксированная
Указание фиксированной ширины дается в пикселах (например, width="30"). Использование фиксированной ширины позволяет использовать последовательную генерацию.
В процентах
Указание ширины в процентах (например, width="20%") означает процент горизонтального пространства, доступного для таблицы (между текущим левым и правым полями, включая floats). Помните, что это пространство не зависит от самой таблицы, поэтому указание ширины в процентах позволяет использовать последовательную генерацию.
Пропорциональная
Указание пропорциональной ширины (например, width="3*") означает число частей горизонтального пространства, необходимого для таблицы. Если ширина таблицы определяется как фиксированное значение (с помощью атрибута width элемента ), агенты пользователей могут генерировать таблицу последовательно и с указанием пропорциональной ширины.
Однако если ширина таблицы не фиксирована, агенты пользователей должны получить все данные таблицы перед тем, как они смогут определить горизонтальное пространство, необходимое для таблицы. Только тогда это пространство может быть распределено между столбцами, для которых указана пропорциональная ширина.
Если автор не указывает для столбца информацию о ширине, агент пользователя не сможет форматировать таблицу последовательно, поскольку он вынужден будет ждать получения всех данных столбца для определения его ширины.
Если указанная для столбца ширина недостаточна для размещения содержимого какой-либо ячейки, агенты пользователей могут переформатировать таблицу.
Таблица в этом примере содержит шесть столбцов. Первый не принадлежит к явной группе столбцов. Следующие три образуют первую явную группу столбцов, а последние два - вторую явную группу столбцов. Эту таблицу нельзя отформатировать последовательно, поскольку она содержит столбцы пропорциональной ширины, а значение атрибута для элемента не указано.
Когда агент пользователя (визуальный) получит данные таблицы, доступное горизонтальное пространство будет распределяться агентом пользователя следующим образом: сначала агент пользователя распределит 30 пикселов на первый и второй столбец. Затем будет зарезервировано минимальное пространство, необходимое для третьего столбца. Оставшееся горизонтальное пространство будет разделено на шесть равных частей (поскольку 2* + 1* + 3* = 6 частей). Четвертый столбец (2*) получит две таких части, пятый (1*) - одну, а шестой - (3*) три.
<TABLE> <COLGROUP> <COL width="30"> <COLGROUP> <COL width="30"> <COL width="0*"> <COL width="2*"> <COLGROUP align="center"> <COL width="1*"> <COL width="3*" align="char" char=":"> <THEAD> <TR><TD> ...
...строки...
</TABLE>
Для атрибута во второй группе столбцов мы установили значение "center". Все ячейки в каждом столбце этой группы будут наследовать это значение, но могут переопределять его. В действительности последний элемент делает именно это, потому что в нем указано, что каждая ячейка столбца, которым он управляет, будет выровнена с использованием символа ":".
В следующей таблице спецификации ширины столбца позволяют агентам пользователя форматировать таблицу последовательно:
<TABLE width="200"> <COLGROUP span="10" width="15"> <COLGROUP width="*"> <COL id="penultimate-column"> <COL id="last-column"> <THEAD> <TR><TD> ...
...строки...
</TABLE>
Первые десять столбцов имеют ширину 15 пикселов каждый. Последние два столбца получают по половине из оставшихся 50 пикселов. Помните, что элемент расположен так, что значение можно указать только для последних двух столбцов.
Примечание. Хотя атрибут элемента не является нежелательным, авторам рекомендуется использовать для указания ширины таблицы стилей.
Поля ячейки
Определения атрибутов
cellspacing =
Этот атрибут определяет пространство, которое агент пользователя должен оставить между левой стороной таблицы и левым краем крайнего левого столбца, верхней границей таблицы и верхним краем самой верхней строки и так далее для правой и нижней границ таблицы. Этот атрибут также определяет пространство между ячейками.
cellpadding =
Этот атрибут определяет пространство между границей ячейки и ее содержимым. Если значение этого атрибута указано в пикселах, все четыре поля должны иметь этот размер. Если значение атрибута указано в процентах, верхнее и нижнее поля должны быть отделены от содержимого на одинаковый процент доступного вертикального пространства, а левое и правое поля должны быть отделены от содержимого на одинаковый процент доступного горизонтального пространства.
Эти два атрибута управляют расстоянием между ячейками и внутри них. Они объясняются на следующей иллюстрации:
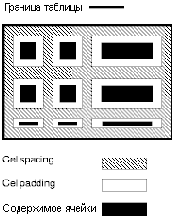
В следующем примере атрибут задает расстояние в двадцать пикселов между ячейками и от края таблицы. Атрибут определяет, что верхнее и нижнее поля ячейки отделяются от содержимого ячейки на 10% доступного вертикального пространства (всего 20%). Точно так же, левое и правое поле ячейки будут отделены от содержимого на 10% доступного горизонтального пространства (всего 20%).
<TABLE cellspacing="20" cellpadding="20%"> <TR> <TD>Данные1 <TD>Данные2 <TD>Данные3 </TABLE>
Если таблица или данный столбец имеет фиксированную ширину, и могут занимать больше пространства, чем назначено. Агенты пользователей могут давать этим атрибутам приоритет над атрибутом в случае конфликта, но они не обязательно должны это делать.
Правила генерации объектов
Агент пользователя должен интерпретировать элемент в соответствии со следующими правилами старшинства:
Сначала агент пользователя должен попытаться сгенерировать объект. Он не должен генерировать содержимое элемента, но должен проверить его на случай, если элемент содержит дополнительные дочерние элементы (см. ) или элементы (см. ).
Если агент пользователя по какой-либо причине не может сгенерировать объект (не сконфигурирован для этого, недостаточно ресурсов, ошибочная архитектура и т.д.), он должен попытаться сгенерировать его содержимое.
Авторам не следует включать содержимое в элементы , расположенные в элементе .
В следующем примере мы вставляем в документ апплет, представляющий часы, с помощью элемента . Апплету, написанный на языке Python, не нужны дополнительные и рабочие значения. Атрибут определяет местоположение апплета:
<P><OBJECT classid="http://www.miamachina.it/analogclock.py"> </OBJECT>
Обратите внимание на то, что часы будут генерироваться, как только агент пользователя интерпретирует это объявление . Можно отложить генерацию объекта, начав с объявления объекта (описывается ниже).
Авторы должны выполнять объявление, включая альтернативный текст в качестве содержимого элемента в случае, если агент пользователя не может сгенерировать часы.
<P><OBJECT classid="http://www.miamachina.it/analogclock.py"> Часы с анимацией. </OBJECT>
Одним важным последствием создания элемента является то, что он предлагает механизм задания альтернативной генерации объектов; в каждом внедренном объявлении могут задаваться альтернативные типы содержимого. Если агент пользователя не может сгенерировать outermost , он пытается сгенерировать содержимое, которое может юыть другим элементом и т.д.
В следующем примере мы внедряем несколько объявлений для того, чтобы показать работу альтернативной генерации. Агент пользователя попытается сгенерировать первый элемент , который он может, в следующем порядке: (1) апплет Earth, написанный на языке Python, (2) клип Земли в формате MPEG, (3) изображение Земли в формате GIF, (4) альтернативный текст.
<P> <!- Сначала попробовать апплет на языке Python --> <OBJECT title="Вид Земли из космоса" classid="http://www.observer.mars/TheEarth.py"> <!- Затем попробовать воспроизвести видеоклип в формате MPEG --> <OBJECT data="TheEarth.mpeg" type="application/mpeg"> <!- Затем попробовать изображение в формате GIF --> <OBJECT data="TheEarth.gif" type="image/gif"> <!- Затем сгенерировать текст --> Вид <STRONG>Земли</STRONG> из космоса. </OBJECT> </OBJECT> </OBJECT>
Внешнее объявление определяет апплет, которому не нужны данные или начальные значения. Второе объявление определяет клип в формате MPEG и, поскольку местоположение обработчика формата MPEG не указано, предполагается, что клип будет обрабатываться агентом пользователя. Мы также установили атрибут type, так что агент пользователя, который знает, что он не может сгенерировать клип в формате MPEG, не будет загружать файл "TheEarth.mpeg" из сети. В третьем объявлении задается местоположение файла в формате GIF и определяется альтернативный текст на случай, если все прочие механизмы не сработают.
Встроенные и внешние данные. Данные, которые должны генерироваться, могут указываться двумя способами: в виде встроенного или внешнего ресурса. Последний метод обычно обеспечивает более быструю генерацию, но неудобен при генерации большого объема данных.
Ниже приводится пример, показывающий, как встроенные данные могут be fed to an :
<P> <OBJECT id="clock1" classid="clsid:663C8FEF-1EF9-11CF-A3DB-080036F12502" data="data:application/x-oleobject;base64, ...данные base64..."> Часы. </OBJECT>
Информацию о размере, выравнивании и границах объекта см. в разделе .
Пример таблицы
В этом примере показаны сгруппированные строки и столбцы. Пример взят из книги "Разработка интернационального программного обеспечения" Надин Кэно.
В "формате ascii" следующая таблица:
<TABLE border="2" frame="hsides" rules="groups" summary="Поддержка кодовых страниц в различных версиях MS Windows."> <CAPTION>ПОДДЕРЖКА КОДОВЫХ СТРАНИЦ В MICROSOFT WINDOWS</CAPTION> <COLGROUP align="center"> <COLGROUP align="left"> <COLGROUP align="center" span="2"> <COLGROUP align="center" span="3"> <THEAD valign="top"> <TR> <TH>ИД кодовой<BR>страницы <TH>Название <TH>ACP <TH>OEMCP <TH>Windows<BR>NT 3.1 <TH>Windows<BR>NT 3.51 <TH>Windows<BR>95 <TBODY> <TR><TD>1200<TD>Unicode (BMP of ISO/IEC-10646)<TD><TD><TD>X<TD>X<TD>* <TR><TD>1250<TD>Windows 3.1 Восточноевропейская<TD>X<TD><TD>X<TD>X<TD>X <TR><TD>1251<TD>Windows 3.1 Кириллица<TD>X<TD><TD>X<TD>X<TD>X <TR><TD>1252<TD>Windows 3.1 США (ANSI)<TD>X<TD><TD>X<TD>X<TD>X <TR><TD>1253<TD>Windows 3.1 Греческая<TD>X<TD><TD>X<TD>X<TD>X <TR><TD>1254<TD>Windows 3.1 Турецкая<TD>X<TD><TD>X<TD>X<TD>X <TR><TD>1255<TD>Иврит<TD>X<TD><TD><TD><TD>X <TR><TD>1256<TD>Арабская<TD>X<TD><TD><TD><TD>X <TR><TD>1257<TD>Балтийская<TD>X<TD><TD><TD><TD>X <TR><TD>1361<TD>Корейская (Johab)<TD>X<TD><TD><TD>**<TD>X <TBODY> <TR><TD>437<TD>США MS-DOS<TD><TD>X<TD>X<TD>X<TD>X <TR><TD>708<TD>Арабская (ASMO 708)<TD><TD>X<TD><TD><TD>X <TR><TD>709<TD>Арабская (ASMO 449+, BCON V4)<TD><TD>X<TD><TD><TD>X <TR><TD>710<TD>Арабская (Прозрачная арабская)<TD><TD>X<TD><TD><TD>X <TR><TD>720<TD>Арабская (Прозрачная ASMO)<TD><TD>X<TD><TD><TD>X </TABLE>
может быть сгенерирована следующим образом:
ПОДДЕРЖКА КОДОВЫХ СТРАНИЦ В MICROSOFT WINDOWS ================================================================================= ИД кодовой| Название | ACP OEMCP | Windows Windows Windows Страницы | | | NT 3.1 NT 3.51 95 --------------------------------------------------------------------------------- 1200 | Unicode (BMP of ISO 10646) | | X X * 1250 | Windows 3.1 Восточноевропейская| X | X X X 1251 | Windows 3.1 Кириллица | X | X X X 1252 | Windows 3.1 США (ANSI) | X | X X X 1253 | Windows 3.1 Греческая | X | X X X 1254 | Windows 3.1 Турецкая | X | X X X 1255 | Иврит | X | X 1256 | Арабская | X | X 1257 | Балтийская | X | X 1361 | Корейская (Johab) | X | ** X ------------------------------------------------------------------------------- 437 | США MS-DOS | X | X X X 708 | Арабская (ASMO 708) | X | X 709 | Арабская (ASMO 449+, BCON V4) | X | X 710 | Арабская (Прозрачная арабская) | X | X 720 | Арабская (Прозрачная ASMO) | X | X ===============================================================================
Графический агент пользователя может сгенерировать ее следующим образом:

В данном примере показано, как можно использовать для группировки столбцов и установки выравнивания столбцов по умолчанию. Точно так же используется для группировки строк. Атрибуты и сообщают агенту пользователя, какие границы и rules должны генерироваться.
Примеры клиентских навигационных карт
В следующем примере мы создаем клиентскую навигационную карту для элемента . Сы не хотим генерировать содержимое карты при генерации элемента , поэтому мы "скроем" элемент в содержимом элемента . Затем содержимое элемента будет генерироваться, только если нельзя сегенировать содержимое элемента .
<HTML> <HEAD> <TITLE>Крутая страница!</TITLE> </HEAD> <BODY> <P><OBJECT data="navbar1.gif" type="image/gif" usemap="#map1"> <MAP name="map1"> <P>Перемещение по узлу: <A href="guide.html" shape="rect" coords="0,0,118,28">Руководство по доступу</a> | <A href="shortcut.html" shape="rect" coords="118,0,184,28">Переход</A> | <A href="search.html" shape="circle" coords="184,200,60">Поиск</A> | <A href="top10.html" shape="poly" coords="276,0,373,28,50,50,276,0">Первые десять</A>< </MAP> </OBJECT> </BODY> </HTML>
Нам может понадобиться генерация содержимого карты, даже если агент пользователя может сгенерировать элемент . Например, мы хотим связать навигационную карту с элементом и включить текстовую навигационную панель внизу страницы. Чтобы это сделать, определим элемент вне элемента :
<HTML> <HEAD> <TITLE>Крутая страница!</TITLE> </HEAD> <BODY> <P><OBJECT data="navbar1.gif" type="image/gif" usemap="#map1"> </OBJECT>
...продолжение страницы...
<MAP name="map1"> <P>Перемещение по узлу: <A href="guide.html" shape="rect" coords="0,0,118,28">Руководство по доступу</a> | <A href="shortcut.html" shape="rect" coords="118,0,184,28">Переход</A> | <A href="search.html" shape="circle" coords="184,200,60">Поиск</A> | <A href="top10.html" shape="poly" coords="276,0,373,28,50,50,276,0">Первые десять</A> </MAP> </BODY> </HTML>
В следующем примере мы создаем сходную навигационную карту, на этот раз используя элемент . Обратите внимание на использование текста :
<P><OBJECT data="navbar1.gif" type="image/gif" usemap="#map1"> <P>Это навигационная панель. </OBJECT>
<MAP name="map1"> <AREA href="guide.html" alt="Руководство по доступу" shape="rect" coords="0,0,118,28"> <AREA href="search.html" alt="Поиск" shape="rect" coords="184,0,276,28"> <AREA href="shortcut.html" alt="Переход" shape="circle" coords="184,200,60"> <AREA href="top10.html" alt="Первые десять" shape="poly" coords="276,0,373,28,50,50,276,0"> </MAP>
Вот версия с использованием элемента вместо элемента (с тем же самым объявлением ):
<P><IMG src="navbar1.gif" usemap="#map1" alt="навигационная панель">
В следующем примере показано, как элементы могут совместно использовать навигационные карты.
Вложенные элементы полезны для обеспечения fallbacks в случае, если агент пользователя не поддерживает определенные форматы. Например:
<P> <OBJECT data="navbar.png" type="image/png"> <OBJECT data="navbar.gif" type="image/gif"> текст с описанием изображения...
</OBJECT> </OBJECT>
Если агент пользователя не поддерживает формат PNG, он пытается сгенерировать изображение в формате GIF. Если он не поддерживает GIF (например, это речевой агент пользователя), он воспроизводит текстовое описание, указанное в содержимсом внутреннего элемента . Если элементы вложены таким образом, авторы могут обеспечивать совместное использование этими элементами навигационных карт:
<P> <OBJECT data="navbar.png" type="image/png" usemap="#map1"> <OBJECT data="navbar.gif" type="image/gif" usemap="#map1"> <MAP name="map1"> <P>Перемещение по узлу: <A href="guide.html" shape="rect" coords="0,0,118,28">Руководство по доступу</a> | <A href="shortcut.html" shape="rect" coords="118,0,184,28">Переход</A> | <A href="search.html" shape="circle" coords="184,200,60">Поиск</A> | <A href="top10.html" shape="poly" coords="276,0,373,28,50,50,276,0">Первые десять</A> </MAP> </OBJECT> </OBJECT>
В следующем примере показано, как можно указать anchors для создания неактивных зон в навигационной карте. Первый anchor определяет небольшую круглую область, с которой не связана ссылка. Второй anchor определяет круглую область большего размера с той же координатой центра. Обе они вместе образуют кольцо, центр которого неактивен, а внешняя часть активна. Порядок определения anchor важен, поскольку меньший круг должен иметь приоритет над большим.
<MAP name="map1"> <P> <A shape="circle" coords="100,200,50">Я неактивная.</A> <A href="outer-ring-link.html" shape="circle" coords="100,200,250">Я активная.</A> </MAP>
Точно так же атрибут элемента объявляет, что с геометрической областью не связана ссылка.
Принудительный переход на новую строку: элемент BR
<!ELEMENT - O EMPTY -- принудительный переход на новую строку --> <!ATTLIST BR -- , , , -- >
Начальный тег: обязателен, Конечный тег: запрещен
Атрибуты, определяемые в любом другом месте
, ()
()
()
()
Элемент принудительно разбивает (заканчивает) текущую строку текста.
Для визуальных агентов пользователей можно использовать атрибут для определения того, обтекает ли следующая за элементом разметка изображения и другие объекты, плавающие относительно левого или правого поля или начинается ниже объекта. Дальнейшая информация приведена в разделе о . Авторам рекомендуется использовать таблицы стилей для управления обтеканием текстом изображений и других объектов.
С использованием двунаправленного форматирования, элемент должен действовать так же, как действует символ РАЗДЕЛИТЕЛЬ СТРОКИ [ISO10646] в двунаправленном алгоритме.
Приоритет над двунаправленным алгоритмом: элемент BDO
<!ELEMENT - - ()* -- приоритет над I18N BiDi --> <!ATTLIST BDO -- , , , -- #IMPLIED -- код языка -- (ltr|rtl) #REQUIRED -- направление -- >
Начальный тег: обязателен, Конечный тег: обязателен
Определения атрибутов
dir = LTR | RTL
Этот обязательный атрибут указывает основное направление текстового содержимого элемента. Это направление имеет приоритет по отношению к наследуемому направлению символов, как определено в [UNICODE]. Возможные значения:
LTR: Направление слева направо. RTL: Направление справа налево.
Атрибуты, определяемые в любом другом месте
()
Двунаправленного алгоритма и атрибута обычно достаточно для управления изменением направления внедренного текста. Однако в некоторых ситуациях двунаправленный алгоритм может привести к некорректному представлению. Элемент позволяет авторам отключать двунаправленный алгоритм для выбранных фрагментов текста.
Рассмотрите документ с тем же текстовым фрагментом:
английский1 ИВРИТ2 английский3 ИВРИТ4 английский5 ИВРИТ6
но предположите, что этот текст уже представлен в нужном порядке. Одной причиной этого может быть то, что стандарт MIME ([RFC2045], [RFC1556]) благоприятствует визуальному порядку, то есть последовательности с направлением справа налево вставляются в байтовый поток с направлением справа налево. В электронной почте это может форматироваться, включая перевод строки, например:
английский1 2ТИРВИ английский3 4ТИРВИ английский5 6ТИРВИ
Это конфликтует с двунаправленным алгоритмом [UNICODE], поскольку этот алгоритм инвертирует 2ТИРВИ, 4ТИРВИи 6ТИРВИ во второй раз, так что слова на иврите отображаются слева направо, а не справа налево.
В этом случае решением будет переопределить действие двунаправленного алгоритма, поместив выдержку Email в элемент (для сохранения переводов строки) и каждую строку, для которой атрибут установлен в LTR, в элемент :
<PRE> <BDO dir="LTR">английский1 2ТИРВИ английский3</BDO> <BDO dir="LTR">4ТИРВИ английский5 6ТИРВИ</BDO> </PRE>
Двунаправленному алгоритму выдается команда "Я должен быть слева направо!", что приведет к нужному представлению:
английский1 2ТИРВИ английский3 4ТИРВИ английский5 6ТИРВИ
Элемент следует использовать в сценариях, где необходим абсолютный контроль над последовательностью (например, многоязыковые номера частей). Атрибут для этого элемента является обязательным.
Авторы могут также использовать специальные символы Unicode для того, чтобы избежать использования двунаправленного алгоритма -- LEFT-TO-RIGHT OVERRIDE (202D) или RIGHT-TO-LEFT OVERRIDE (шестнадцатеричный код 202E). Символ POP DIRECTIONAL FORMATTING (шестнадцатеричный код 202C) заканчивает любую последовательность, используемую для обхода двунаправленного алгоритма.
Примечание.
Помните, что при использовании атрибута во встроенных элементах (включая ) одновременно с соответствующими символами форматирования [UNICODE], могут возникать конфликты.
Двунаправленность и кодировка символов В соответствии с [RFC1555] и [RFC1556] существуют специальные соглашения относительно использования значений параметра "charset" для указания обработки двунаправленности в почте MIME, в частности для отличия визуальной, явной и неявной направленности. Значение параметра "ISO-8859-8" (для иврита) обозначает визуальную кодировку, "ISO-8859-8-i" обозначает неявную двунаправленность, а "ISO-8859-8-e" обозначает явную направленность.
Поскольку HTML использует двунаправленный алгоритм Unicode, соответствующие документы, использующие кодировку ISO 8859-8, должны помечаться как "ISO-8859-8-i". Явное управление направлением в HTML также возможно, но его нельзя выразить в ISO 8859-8, поскольку не следует использовать "ISO-8859-8-e".
Значение "ISO-8859-8" подразумевает, что документ отформатирован визуально, и некоторая разметка будет использоваться неправильно (например, с выравниванием по правому краю без разбивки строк), чтобы гарантировать правильное отображение для более старых агентов пользователя, не поддерживающих двунаправленность. Такие документы не удовлетворяют настоящей спецификации. При необходимости их можно изменить (и одновременно они будут корректно отображаться в старых версиях агентов пользователей), добавив, где нужно, разметку .
Вопреки сказанному в [RFC1555] и [RFC1556], кодировка ISO-8859-6 (арабская) не представляет визуального порядка.
Прямые и обратные ссылки
Атрибуты и играют дополнительные роли - атрибут задает прямую ссылку, а атрибут - обратную.
Рассмотрим два документа - A и B.
Документ A: <LINK href="docB" rel="foo">
имеет точно то же значение, что и:
Документ B: <LINK href="docA" rev="foo">
Оба атрибута могут определяться одновременно.
Профили метаданных
Атрибут элемента указывает местоположение профиля метаданных. Значением атрибута является URI. Агенты пользователей могут использовать этот URI двумя способами:
Как глобальное уникальное имя. Агенты пользователя могут распознавать имя (не загружая в действительности профиль) и выполнять некоторые действия на базе известных соглашений для этого профиля. Например, поисковые машины могут обеспечивать интерфейс для поиска в каталогах документов HTML, где все эти документы используют один и тот же профиль для представления записей каталога.
Как ссылку. Агенты пользователей могут разыменовывать URI и выполнять некоторые действия на базе определений из профиля (например, авторизовать использование профиля в текущем документе HTML). В этой спецификации не определяются форматы профилей.
В этом примере используется гипотетический профиль, определяющий полезные свойства для индексирования документов. Для свойств, определяемых этим профилем - включая "author", "copyright", "keywords" и "date" -- значения устанавливаются с помощью последовательных объявлений .
<HEAD profile="http://www.acme.com/profiles/core"> <TITLE>How to complete Memorandum cover sheets</TITLE> <META name="author" content="John Doe"> <META name="copyright" content="© 1997 Acme Corp."> <META name="keywords" content="corporate,guidelines,cataloging"> <META name="date" content="1994-11-06T08:49:37+00:00"> </HEAD>
Во время написания этой спецификации распространенной стала практика использования форматов дат, описанных в [RFC2068], раздел 3.3. Поскольку обработка этих форматов относительно сложна, мы рекомендуем авторам использовать формат даты [ISO8601]. Подробнее см. разделы об элементах и .
Атрибут позволяет авторам предоставлять агентам пользователей дополнительный контекст для корректной интерпретации метаданных. Иногда такая дополнительная информация может иметь важное значение, например, если метаданные указаны в другом формате. Например, автор может указать дату в формате "10-9-97" (неоднозначно); означает ли это 9 октября 1997 г. или 10 сентября 1997 г.? Значение атрибута "Month-Date-Year" устранит неоднозначность.
В других случаях атрибут может предоставлять агентам пользователей полезную, но не столь важную информацию.
Например, следующее объявление поможет агентам пользователей определить, что значение свойства "identifier" - номер кода ISBN:
<META scheme="ISBN" name="identifier" content="0-8230-2355-9">
Значения атрибута зависят от свойства name и связанного .
Примечание. Примером профиля является Dublin Core (см. [DCORE]). Этот профиль определяет набор рекомендуемых свойств для электронных библиографических описаний и предназначен для обеспечения интероперабельности в несопоставимых моделях описаний.
Пространство вокруг изображений и объектов
Атрибуты vspace и hspace определяют свободное пространство слева и справа (hspace) и над и под (vspace) , , . По умолчанию значение этого атрибута не определено, но обычно это небольшое ненулевое значение. Оба атрибута имеют значение типа .
Разметка изменений в документе: Элементы INS и DEL
<!-- INS/DEL are handled by inclusion on BODY --> <!ELEMENT (|) - - ()* -- вставленный текст, удаленный текст --> <!ATTLIST (INS|DEL) -- , , -- #IMPLIED -- информация о причине изменения -- #IMPLIED -- дата и время изменения -- >
Начальный тег: обязателен, Конечный тег: обязателен
Определения атрибутов
cite =
Значением этого атрибута является адрес URI, определяющий источник документа или сообщения. Этот атрибут указывает на информацию, объясняющую причины изменения документа.
datetime
=
Значение этого атрибута указывает дату и время выполнения изменения.
Атрибуты, определяемые в любом другом месте
, ()
(), ()
()
()
, , , , , , , , , (внутренние события)
Элементы и используются для разметки вставленных или удаленных разделов документа по отношению к другой версии документа (например, в черновике законопроекта, куда юристы должны вносить поправки).
Эти два элемента необычны для HTML, поскольку они могут служить элементами уровня блока или встроенными элементами (но не теми и другими). Они могут содержать одно или несколько слов в абзаце или один или несколько элементов уровня блока - абзацев, списков и таблиц.
Это пример законопроекта о количестве депутатов у окружного шерифа - 3 исправлено на 5.
<P> У шерифа может быть <DEL>3</DEL><INS>5</INS> депутатов. </P>
Элементы и не должны включать содержимое уровня блока, если они являются встроенными элементами.
ПРИМЕР НЕДОПУСТИМОГО ИСПОЛЬЗОВАНИЯ:
Ниже показан недопустимый код HTML.
<P> <INS><DIV>...содержимое уровня блока...</DIV></INS> </P>
Агенты пользователей должны генерировать вставленный и удаленный текст так, чтобы изменения были очевидны. Например, вставленный текст может отображаться специальным шрифтом, удаленный текст может вообще не отображаться, отображаться перечеркнутым или со специальными пометками и т.д.
Оба примера ниже соответствуют 5 ноября 1994 года, 20 ч. 15 мин. 30 с по стандартному восточному времени США.
1994-11-05T13:15:30Z 1994-11-05T08:15:30-05:00
С использованием элемента получаем:
<INS datetime="1994-11-05T08:15:30-05:00" cite="http://www.foo.org/mydoc/comments.html"> Более того, последние цифры из отдела маркетинга говорят о том, что это полезная практика. </INS>
В документе "http://www.foo.org/mydoc/comments.html" должны содержаться комментарии о том, почему эта информация помещена в документ.
Авторы также могут оставлять комментарии о вставленном или удаленном тексте для элементов и с помощью атрибута . Агенты пользователей могут представлять эту информацию пользователю (например, в виде всплывающего сообщения). Например:
<INS datetime="1994-11-05T08:15:30-05:00" title="Изменено в результате комментариев Михаила А. о встрече."> Более того, последние цифры из отдела маркетинга говорят о том, что это полезная практика. </INS>
Разрешение относительных URI
Агенты пользователей должны вычислять базовый URI для разрешения относительных URI в соответствии с [RFC1808], раздел 3. Далее описано, как [RFC1808]
применяется именно к HTML.
Агенты пользователей должны вычислять базовый URI в соответствии со следующим приоритетом (от высшего приоритет к низшему):
Базовый URI, устанавливаемый элементом .
Базовый URI, задаваемый метаданными, обнаруженными в процессе работы по протоколу, такими как заголовок HTTP (см. [RFC2068]).
По умолчанию базовым URI является URI текущего документа. Не все документы HTML имеют базовый URI (например, документ HTML может присутствовать в сообщении электронной почты и может не определяться никаким URI). Такие документы HTML считаются erroneous, если они содержат относительные URI и используют базовый URI по умолчанию.
Кроме того, элементы и определяют атрибуты, имеющие преимущество над значением, установленным для элемента . Подробнее об относящихся к ним определениям URI см. в определениях этих элементов.
Ссылки, указанные в заголовках HTTP, обрабатываются в точности так, как элементы , явно установленные в документе.
Серверные навигационные карты
Серверные навигационные карты представляют интерес в случаях, когда карта слишком сложна.
Определить серверную навигационную карту можно только для элементов и . В случае элемента этот элемент должен быть включен в элемент . В случае элемента он должен иметь тип "image". В обоих случаях для элемента должен быть установлен логический атрибут ismap .
Когда пользователь активизирует ссылку, щелкнув на изображении, экранные координаты отправляются непосредственно на сервер, на котором располагается документ. Экранные координаты выражаются в виде пикселов относительно изображения. Нормативную информацию об определении пикселов и об их масштабировании см. в [CSS1].
В следующем примере активная область определяет серверную ссылку. Таким образом щелчок в любой точке изображения вызовет передачу координат на сервер.
<P><A href="http://www.acme.com/cgi-bin/competition"> <IMG src="game.gif" ismap alt="target"></A>
Координаты области, в которой произошел щелчок, передаются на сервер следующим образом. Агент пользователя получает новый адрес URI из адреса URI, указанного в атрибуте элемента , добавляя `?', за которым следуют координаты x и y, разделенные запятой. Затем происходит переход по ссылке с использованием нового адреса URI. Например, в данном примере, если пользователь щелкает в точке с координатами x=10, y=27, то новый адрес URI - "http://www.acme.com/cgi-bin/competition?10,27".
Агенты пользователей, не предлагающие пользователям средств выбора определенных координат (например, неграфические агенты пользователей, зависящие от ввода с клавиатуры, речевые агенты пользователей и т.д.) должны при активизации ссылки передавать на сервер координаты "0,0".
Ширина и высота
Определения атрибутов
width =
Переопределение ширины изображения и объекта.
height =
Переопределение для изображения и объекта.
Если указаны атрибуты и , они сообщают агентам пользователя о необходимости переопределения исходного размера изображения или объекта этими значениями.
Если объектом является изображение, оно масштабируется. Агенты пользователей должны наилучшим образом масштабировать объект или изображение, чтобы они соответствовали ширине и высоте, определенным автором. Обратите внимание, что длины, выраженные в процентах, зависят от доступного горизонтального или вертикального пространства, а не от исходного размера изображения, объекта или апплета.
Атрибуты и дают агентам пользователей представление о размере изображения или объекта, чтобы они могли зарезервировать соответствующее пространство и продолжать генерацию документа, ожидая данных об изображении.
Синтаксис имен якорей
Именем якоря является значение атрибута или атрибута , используемого в контексте якоря. К именам якорей применяются следующие правила:
Уникальность: Имена якорей должны быть уникальны в пределах документа. Имена якорей в одном документе не могут отличаться только регистром.
Соответствие строк: Сравнение между идентификаторами фрагментов и именами якорей должно проводиться на основе полного (с учетом регистра) совпадения.
Таким образом, следующий пример является корректным в смысле соответствия строк и должен рассматриваться агентами пользователей как совпадение:
<P><A href="#xxx">...</A> ...некоторый текст...
<P><A name="xxx">...</A>
ПРИМЕР НЕДОПУСТИМОГО ИСПОЛЬЗОВАНИЯ:
Следующий пример не является корректным в смысле уникальности, поскольку два имени отличаются только регистром:
<P><A name="xxx">...</A> <P><A name="XXX">...</A>
Хотя далее приводится допустимый код HTML, поведение агента пользователя в данном случае не определено; некоторые агенты пользователей могут (ошибочно) считать это совпадением, другие могут так не считать.
<P><A href="#xxx">...</A> ...некоторый текст...
<P><A name="XXX">...</A>
Имена якорей должны содержать только символы набора ASCII. Подробнее см. в разделе .
Списки определений: элементы DL, DT и DD
<!-- списки определений - DT - термин, DD - его определение -->
<!ELEMENT - - (DT|DD)+ -- список определений --> <!ATTLIST DL -- , , -- >
Начальный тег: обязателен, Конечный тег: обязателен
<!ELEMENT - O ()* -- термин --> <!ELEMENT - O ()* -- определение --> <!ATTLIST (DT|DD) -- , , -- >
Начальные тег: обязателен, Конечный тег: не обязателен
Атрибуты, определяемые в любом другом месте
, () (), () () () , , , , , , , , , (внутренние события)
Списки определений незначительно отличаются от других типов списков - тем, что элементы состоят из двух частей: термина и определения. Термин обозначается с помощью элемента и может иметь только встроенное содержимое. Описание указывается с помощью элемента , имеющим содержимое уровня блока.
Пример:
<DL> <DT>Dweeb <DD>young excitable person who may mature into a <EM>Nerd</EM> or <EM>Geek</EM>
<DT>Cracker <DD>hacker on the Internet
<DT>Nerd <DD>male so into the Net that he forgets his wife's birthday </DL>
Вот пример с несколькими терминами и определениями:
<DL> <DT>Center <DT>Centre <DD> A point equidistant from all points on the surface of a sphere. <DD> In some field sports, the player who holds the middle position on the field, court, or forward line. </DL>
Другим применением элемента , например, может быть разметка диалогов, где каждый элемент означает говорящего, а в каждом элементе содержатся его слова.
Ссылки и поисковые машины
Авторы могут использовать элемент для указания различной информации для поисковых машин, включая:
Ссылки на альтернативные версии документа, написанные на других языках.
Ссылки на альтернативные версии документа, разработанные для других устройств, например, на версии, предназначенные специально для печати.
Ссылки на начальные страницы набора документов.
В примерах ниже показано, как информация о языке, типах устройств и типах ссылок может использоваться для улучшения обработки документа поисковыми машинами.
В следующем примере мы используем атрибут , чтобы сообщить поисковым машинам, где находятся голландская, португальская и арабская версии документа. Обратите внимание на использование атрибутов и для руководства на арабском языке, а также на использование атрибута для указания того, что значением атрибута для элемента , указывающего руководство на французском языке, задано по-французски.
<HEAD> <TITLE>Руководство на английском языке</TITLE> <LINK title="Руководство на голландском языке" type="text/html" rel="alternate" hreflang="nl" href="http://someplace.com/manual/dutch.html"> <LINK title="Руководство на португальском языке" type="text/html" rel="alternate" hreflang="pt" href="http://someplace.com/manual/portuguese.html"> <LINK title="Руководство на арабском языке" dir="rtl" type="text/html" rel="alternate" charset="ISO-8859-6" hreflang="ar" href="http://someplace.com/manual/arabic.html"> <LINK lang="fr" title="La documentation en Français" type="text/html" rel="alternate" hreflang="fr" href="http://someplace.com/manual/french.html"> </HEAD>
В следующем примере мы сообщаем поисковым машинам, где находится печатная версия руководства.
<HEAD> <TITLE>Руководство</TITLE> <LINK media="print" title="Руководство в формате postscript" type="application/postscript" rel="alternate" href="http://someplace.com/manual/postscript.ps"> </HEAD>
В следующем примере мы сообщаем поисковым машинам, где находится первая страница набора документов.
<HEAD> <TITLE>Руководство - страница 5</TITLE> <LINK rel="Start" title="Первая страница руководства" type="text/html" href="http://someplace.com/manual/start.html"> </HEAD>
Дальнейшая информация приведена в замечаниях в приложении о том, .
Ссылки и внешние таблицы стилей
Если элемент ссылается на внешнюю таблицу стилей для документа, атрибут указывает язык таблицы стилей, а атрибут - предполагаемое устройство или устройства для представления документа. Агенты пользователей могут сэкономить время, загружая из сети только те таблицы стилей, которые применяются к текущему устройству.
обсуждаются в разделе, посвященном таблицам стилей.
Ссылки на символы для управления направлением и объединением
Поскольку иногда возникает двусмысленность относительно некоторых символов (например, символов пунктуации), спецификация [UNICODE] включает символы для правильного определения назначения. Спецификация Unicode также включает некоторые символы для управления объединением при необходимости (например, в некоторых ситуациях с арабскими символами). HTML 4.0 включает для этих символов .
Следующее DTD определяет представление некоторых объектов направления:
<!ENTITY zwnj CDATA "‌"--=нулевая ширина без объединения --> <!ENTITY zwj CDATA "‍"--=объединитель нулевой ширины--> <!ENTITY lrm CDATA "‎"--=метка слева направо--> <!ENTITY rlm CDATA "‏"--=метка справа налево-->
Объект zwnj используется для блокировки объединения в тех контекстах, где объединение произойдет, но оно происходить не должно. Объект zwj имеет обратное действие; он производит объединение в случае, когда оно не предполагается, но должно произойти. Например, арабская буква "HEH" используется для сокращения "Hijri", названия исламской системы летоисчисления. Поскольку отдельный иероглиф "HEH" в арабской письменности выглядит как цифра пять, для того, чтобы не путать букву "HEH" с последней цифрой пять в годе, используется исходная форма буквы "HEH". Однако, нет последующего контекста (например, буквы для объединения), с которым можно объединить "HEH". Символ zwj предоставляет такой контекст.
Точно так же в персидских текстах буква может иногда объединяться с последующей буквой, в то время как в рукописном тексте этого быть не должно. Символ zwnj используется для блокировки объединения в таких случаях.
Символы порядка, lrm и rlm, используются для определения направления нейтральных по отношению к направлению символов. Например, если двойные кавычки ставятся между арабской (справа налево) и латинской (слева направо) буквами, направление кавычек неясно (относятся ли они к арабскому или к латинскому тексту?). Символы lrm и rlm имеют свойство направления, но не имеют свойств ширины и разделения слов/строк. Подробнее см. [UNICODE].
Отражение глифов символов.
Вообще двунаправленный алгоритм не отражает глифы символов и не влияет на них. Исключением являются такие символы как скобки (см. [UNICODE], таблица 4-7). Если отражение желательно, например, для египетских иероглифов, греческих знаков или специальных эффектов дизайна, можно сделать это с помощью стилей.
Строки и абзацы
Авторы традиционно разделяют свои тексты на последовательности абзацев. Организация информации в абзацы не влияет на представление абзаца: абзацы с двойным выравниванием содержат те же мысли, что и абзацы с выравниванием влево.
Разметка HTML для определения абзаца проста: элемент определяет новый абзац.
Визуальное представление абзаца не так просто. Имеется ряд проблем, стилистических и технических:
Обработка непечатных символов
Перенос строки и продолжение слов
Выравнивание
Перенос
Соглашения относительного письменного языка и направления текста
Форматирование абзацев относительно окружающего
Эти вопросы обсуждаются ниже. обсуждаются далее в этом документе.
Строки таблицы: элемент TR
<!ELEMENT - O (TH|TD)+ -- строка таблицы --> <!ATTLIST TR -- строка таблицы -- -- , , -- -- горизонтальное выравнивание в ячейках -- -- вертикальное выравнивание в ячейках -- >
Начальный тег: обязателен, Конечный тег: не обязателен
Атрибуты, определяемые в любом другом месте
, ()
(), ()
()
()
, , , , , , , , , ()
, , , ()
Элементы служат контейнерами для строки ячеек таблицы. Конечный тег можно опустить.
Эта простая таблица состоит из трех строк, каждая из которых начинается с элемента :
<TABLE summary="В этой таблице показан график числа чашек кофе, выпиваемых каждым сенатором, тип кофе (без кофеина или обычный) и наличие сахара."> <CAPTION>Сколько чашек кофе выпивает каждый сенатор</CAPTION> <TR> ...Строка заголовка...
<TR> ...Первая строка данных...
<TR> ...Вторая строка данных...
...продолжение таблицы...
</TABLE>
Связь информации заголовка с ячейками данных
Невизуальные агенты пользователей, такие как синтезаторы речи и устройства на базе азбуки Бройля, могут использовать следующие атрибуты элементов и для более intuitive генерации ячеек таблицы:
Для данной ячейки данных в атрибуте перечислено, в каких ячейках находится pertinent информация заголовка. С этой целью каждая ячейка заголовка должна получить имя с использованием атрибута . Помните, что не всегда возможно явно разделить ячейки на заголовки и данные. В таких ячейка следует использовать элемент вместе с атрибутами или .
Для данной ячейки заголовка атрибут сообщает агенту пользователя ячейки данных, информация для которых указывается этим заголовком. Авторы могут использовать этот атрибут вместо в зависимости от того, что более удобно; эти два атрибута имеют одну и ту же функцию. Атрибут обычно нужен, если заголовки помещаются в нестандартном положении по отношению к данным, к которым они применяются.
Атрибут abbr задает сокращенный заголовок для ячеек заголовков, так что агенты пользователя могут быстрее генерировать информацию заголовка.
В следующем примере мы назначаем информацию заголовка ячейкам, устанавливая атрибут . Каждая ячейка в одном и том же столбце относится к одной и той же ячейке заголовка (с помощью атрибута ).
<TABLE border="1" summary="В этой таблице приводится информация о том, сколько чашек кофе выпивает каждый сенатор, о типа кофе (без кофеина или обычный) и о сахаре."> <CAPTION>Сколько чашек кофе выпивает каждый сенатор</CAPTION> <TR> <TH id="t1">Имя</TH> <TH id="t2">Сколько</TH> <TH id="t3" abbr="Тип">Тип кофе</TH> <TH id="t4">Сахар?</TH> <TR> <TD headers="t1">Т. Секстон</TD> <TD headers="t2">10</TD> <TD headers="t3">Эспрессо</TD> <TD headers="t4">Нет</TD> <TR> <TD headers="t1">Дж. Диннен</TD> <TD headers="t2">5</TD> <TD headers="t3">Без кофеина</TD> <TD headers="t4">Да</TD> </TABLE>
Синтезатор речи может генерировать эту таблицу следующим образом:
Заголовок: Сколько чашек кофе выпивает каждый сенатор Summary: В этой таблице приводится информация о том, сколько чашек кофе выпивает каждый сенатор, о типа кофе (без кофеина или обычный) и о сахаре. Имя: Т. Секстон, Сколько: 10, Тип: Эспрессо, Сахар: Нет Имя: Дж. Диннен, Сколько: 5, Тип: Без кофеина, Сахар: Да
Заметьте, что заголовок "Тип кофе" сокращается до "Тип" с помощью атрибута .
Вот тот же пример, использующий атрибут вместо атрибута . Обратите внимание на значение "col" для атрибута , означающее "все ячейки в текущем столбце":
<TABLE border="1" summary="В этой таблице приводится информация о том, сколько чашек кофе выпивает каждый сенатор, о типа кофе (без кофеина или обычный) и о сахаре."> <CAPTION>Сколько чашек кофе выпивает каждый сенатор</CAPTION> <TR> <TH scope="col">Имя</TH> <TH scope="col">Сколько</TH> <TH scope="col" abbr="Тип">Тип кофе</TH> <TH scope="col">Сахар?</TH> <TR> <TD>Т. Секстон</TD> <TD>10</TD> <TD>Эспрессо</TD> <TD>Нет</TD> <TR> <TD>Дж. Диннен</TD> <TD>5</TD> <TD>Без кофеина</TD> <TD>Да</TD> </TABLE>
Ниже приводится несколько более сложный пример, в котором показаны другие значения атрибута :
<TABLE border="1" cellpadding="5" cellspacing="2" summary="Исторические курсы, предлагаемые округа Бат, упорядоченные по названию, преподавателю, описанию, коду и стоимости"> <TR> <TH colspan="5" scope="colgroup">Курсы - Бат, осень 1997 г.</TH> </TR> <TR> <TH scope="col" abbr="Название">Название курса</TH> <TH scope="col" abbr="Преподаватель">Преподаватель курса</TH> <TH scope="col">Описание</TH> <TH scope="col">Код</TH> <TH scope="col">Стоимость</TH> </TR> <TR> <TD scope="row">После Гражданской войны</TD> <TD>Доктор Джон Раутон</TD> <TD> В этом курсе изучаются turbulent годы в Англии после 1646 года. <EM>6 еженедельных занятий, начиная с понедельника, 13 октября.</EM> </TD> <TD>H27</TD> <TD>£32</TD> </TR> <TR> <TD scope="row">Англо-саксонская Англия - введение</TD> <TD>Марк Коттл</TD> <TD> Однодневный курс - введение в раннесредневековый период Реконструкции англо-саксонского общества. <EM>Суббота, 18 октября.</EM> </TD> <TD>H28</TD> <TD>£18</TD> </TR> <TR> <TD scope="row">Греция</TD> <TD>Валери Лоренц</TD> <TD> Колыбель демократии, философии, сердце театра, родина аргумента. Это могли сделать римляне, если бы греки не опередили их. <EM>Субботняя школа 25 октября 1997 года</EM> </TD> <TD>H30</TD> <TD>£18</TD> </TR> </TABLE>
Графический агент пользователя может сгенерировать это следующим образом:

Обратите внимание на использование атрибута со значением "row". Хотя первая ячейка в каждой строке содержит данные, а не заголовок, благодаря атрибуту ячейки данных выглядят как ячейки заголовка строки. Это позволяет синтезаторам речи указывать соответствующее название курса по запросу или произносить его непосредственно перед содержимым ячейки.
Таблицы стилей и двунаправленность
Вообще использование таблиц стилей для изменения визуального представления элемента с уровня блока до встроенного и наоборот используется в прямом направлении. Однако, поскольку двунаправленный алгоритм использует , во время преобразования нужно быть внимательным.
Если встроенный элемент, не имеющий атрибута преобразуется в стиль элемента уровня блока с помощью таблицы стилей, для определения основного направления блока он наследует атрибут от ближайшего родительского элемента блока.
Если элемент блока, не имеющий атрибута a преобразуется к стилю встроенного элемента с помощью таблицы стилей, результирующее представление должно быть эквивалентным, в терминах двунаправленного форматирования, форматированию, получаемому путем явного добавления атрибута (которому назначено унаследованное значение) преобразованному элементу.
Текст
В следующих разделах обсуждаются вопросы структурирования текста. Элементы (элементы выравнивания, шрифта, таблицы стилей и т.д.) обсуждаются в других частях этой спецификации. Информацию о символах см. в разделе о наборе символов документа.
Указание метаданных
В общем случае задание метаданных состоит из двух шагов:
Объявление свойства и его значения. Это можно сделать двумя способами:
Из документа с помощью элемента .
Не из документа с помощью ссылки на метаданные через элемент (см. раздел о ).
Сославшись на в котором определяются свойства и их допустимые значения. Для назначения профиля используйте атрибут элемента .
Помните, что поскольку профиль определяется для элемента , этот профиль применяется ко всем элементам и в заголовке документа.
Агенты пользователей не обязательно должны поддерживать механизмы метаданных. В этой спецификации не определяется интерпретация метаданных.
Указание направления текста и таблиц: атрибут dir
Определения атрибутов
dir = LTR | RTL
Этот атрибут задает основное направление нейтрального в смысле направления текста (например, текста, который не наследует направленность, как определено в [UNICODE]) и . Возможные значения:
LTR: Слева направо. RTL: Справа налево.
Кроме задания языка документа с помощью атрибута , авторы могут указать основное направление (слева направо или справа налево) частей текста, таблицы и т.д. Это делается с помощью атрибута .
Спецификация [UNICODE] назначает направление символам и определяет (сложный) алгоритм для определения соответствующего направления текста. Если документ не содержит отображаемых справа налево символов, агент пользователя не должен использовать двунаправленный алгоритм [UNICODE]. Если документ содержит такие символы, и если агент пользователя и отображает, он должен использовать двунаправленный алгоритм.
Хотя в Unicode определены специальные символы, отвечающие за направление текста, HTML предлагает конструкции разметки высшего уровня, выполняющие те же функции: атрибут (не спутайте с элементом ) и элемент . Таким образом, чтобы привести цитату на иврите, проще написать
<Q lang="he" dir="rtl">...цитата на иврите...</Q>
чем с эквивалентными ссылками Unicode:
‫״...цитата на иврите...״‬
Агенты пользователей не должны использовать атрибут lang для определения направления текста.
Атрибут наследуется, и его можно переопределить. Подробнее см. в разделе о .
Управление переходом на следующую строку
Переходом на следующую строку считается возврат каретки (
), перевод строки (�OA;) или пара возврат каретки/перевод строки. Все переходы на другую строку являются
Подробнее о переходе на другую строку в спецификации SGML см. в разделе в приложении.
Установка направления внедренного текста
Двунаправленный алгоритм [UNICODE] автоматически обращает последовательности внедренных символов в соответствии с наследуемым направлением (как показано в предыдущих примерах). Однако в общем в расчет принимается только один уровень внедрения. Для того, чтобы изменения направления достигали дополнительных уровней, используйте атрибут во встроенном элементе.
Рассмотрите текст предыдущего примера:
английский1 ИВРИТ2 английский3 ИВРИТ4 английский5 ИВРИТ6
Предположим, основным языком для документа, содержащего этот абзац, является английский. В этом английском предложении содержится фрагмент на иврите, продолжающийся от ИВРИТ2 до ИВРИТ4, и в нем содержится англоязычный фрагмент (английский3). Таким образом, желаемое представление текста:
английский1 4ТИРВИ английский3 2ТИРВИ английский5 6ТИРВИ -------> А <----------------------- И ----------------------------------------------------> А
Для изменения направления текста двух внедренных фрагментов необходимо задать дополнительную информацию, что мы и делаем, явно разделяя второе внедрение. В этом примере мы используем для разметки текста элемент и атрибут :
английский1 <SPAN dir="RTL">ИВРИТ2 английский3 ИВРИТ4</SPAN> английский5 ИВРИТ6
Авторы также могут использовать для изменения направления нескольких внедренных фрагментов символы Unicode. Для указания направления слева направо во внедряемом фрагменте окружите текст символами LEFT-TO-RIGHT EMBEDDING ("LRE", шестнадцатеричный код 202A) и POP DIRECTIONAL FORMATTING ("PDF", шестнадцатеричный код 202C). Для указания направления справа налево во внедряемом фрагменте окружите текст символами RIGHT-TO-LEFT EMBEDDING ("RTE", шестнадцатеричный код 202B) и PDF.
Использование разметки направленности HTML с символами Unicode. Авторы и разработчики средств создания HTML-документов должны знать о возможных конфликтах, возникающих при использовании атрибута со встроенными элементами (включая ) одновременно с соответствующими символами форматирования [UNICODE]. Предпочтительнее использовать только один метод. Метод с использованием разметки гарантирует структурную целостность документа и устраняет некоторые проблемы с редактированием двунаправленного текста HTML в простых текстовых редакторах, но некоторое программное обеспечение может лучше использовать символы [UNICODE]. Если используются оба метода, следует хорошо позаботиться о правильном вложении разметки и символов, иначе результаты могут быть непредсказуемыми.
Верхние и нижние индексы: элементы SUBи SUP
<!ELEMENT (|) - - ()* -- нижний индекс, верхний индекс--> <!ATTLIST (SUB|SUP) -- , , -- >
Начальный тег: обязателен, Конечный тег: обязателен
Атрибуты, определяемые в любом другом месте
, ()
(), ()
()
()
, , , , , , , , , (внутренние события)
Часто для правильной генерации необходимы верхние и нижние индексы (например, во французском языке). В этих случаях для разметки текста должны использоваться элементы и .
H<sub>2</sub>O E = mc<sup>2</sup> <SPAN lang="fr">M<sup>lle</sup> Dupont</SPAN>
Визуальное отображение абзацев
Примечание.В следующем разделе содержится информативное описание обработки некоторыми из визуальных агентов пользователя форматированного текста. Таблицы стилей предоставляют лучшие возможности управления форматированием текста.
Визуальное генерирование абзацев зависит от агента пользователя. Обычно абзацы генерируются с выравниванием влево и неровным правым полем. Для направления текста справа налево используются другие значения по умолчанию.
Агенты пользователей HTML традиционно генерируют абзацы с непечатным символом перед абзацем и после него, например,
Одновременно начали формироваться система нумерации, календарь, иероглифическое письмо и технически развитое искусство, все, что позже повлияло на других людей.
В рамках этого развития или культурного прогресса Предклассическая эпоха подразделяется на Ранний, Средний и Поздний периоды, к которым можно добавить переходный или протоклассический период, некоторые черты которого будут потом присущи цивилизациям Америки.
Это отличается от стиля, используемого в романах, где первая строка каждого абзаца смещена, а интервал между последней строкой текущего абзаца и первой строкой следующего не отличается от межстрочных интервалов внутри абзаца, например,
Одновременно начали формироваться система нумерации, календарь, иероглифическое письмо и технически развитое искусство, все, что позже повлияло на других людей. В рамках этого развития или культурного прогресса Предклассическая эпоха подразделяется на Ранний, Средний и Поздний периоды, к которым можно добавить переходный или протоклассический период, некоторые черты которого будут потом присущи цивилизациям Америки.
Следуя установкам браузера NCSA Mosaic, созданного в 1993 году, агенты пользователей обычно не выравнивают оба поля, частично из-за сложности этого процесса при отсутствии специальных процедур расстановки переносов. Использование таблиц стилей и шрифтов без псевдонимов с субпиксельным позиционированием обещает авторам текстов на языке HTML более широкие возможности.
Таблицы стилей предоставляют широкие возможности управления размером и стилем шрифтов, полями, расстояниями перед и после абзацев, отступом первой строки, выравниванием и многими другими аспектами. Таблица стилей агента пользователя, используемая по умолчанию, генерирует элементы как показано выше. В принципе, можно переопределить такую генерацию абзацев, без использования символов перехода на следующую строку, которые существенно изменяют абзац. Вообще же, поскольку это может запутать читателей, так делать не рекомендуется.
По соглашению визуальные агенты HTML разбивают текстовые строки так, чтобы они входили в пределы используемых полей. Алгоритмы разбиения зависят от сценария форматирования.
В западных сценариях, например, текст должен разбиваться только в позиции, где стоит неотображаемый символ. Ранние версии агентов пользователей некорректно разбивали строки сразу же после начального тега или перед конечным тегом элемента, что приводило к нарушению пунктуации. Например, рассмотрите предложение:
Статуя <a href="cih78">Свободы</a>, которая является ...
Разбиение строки сразу перед конечным тегом элемента приведет к тому, что запятая будет помещена в начало следующей строки:
Статуя Свободы , которая является ...
Это ошибка, поскольку в разметке в этой позиции нет неотображаемого символа.
Визуальное отображение списков
Примечание.Ниже приводится информативное описание поведения некоторых имеющихся на настоящий момент визуальных агентов пользователей при форматировании списков. Таблицы стилей предоставляют большие возможности управления форматированием списков (например, в отношении нумерации, соглашений, используемых в разных языках, отступов и т.д.).
Визуальные агенты пользователей обычно сдвигают вложенные списки соответственно уровню вложенности.
Для элементов и атрибут определяет параметры генерации для визуальных агентов пользователей.
Для элемента возможными значениями атрибута являются disc, square и circle. Значение, используемое по умолчанию, зависит от уровня вложенности текущего списка. Эти значения не учитывают регистр.
Представление каждого значения зависит от агента пользователя. Агенты пользователей должны пытаться представлять "disc" в виде небольшого заполненного кружка, "circle" - в виде окружности, а "square" в виде небольшого квадрата.
Графические агенты пользователь могут генерировать их как:



Для элемента возможные значения атрибута приведены в следующей таблице (они учитывают регистр):
| 1 | арабские цифры | 1, 2, 3, ... |
| a | буквы нижнего регистра | a, b, c, ... |
| A | буквы верхнего регистра | A, B, C, ... |
| i | римские цифры в нижнем регистре | i, ii, iii, ... |
| I | римские цифры в верхнем регистре | I, II, III, ... |
Помните, что использование атрибута , и стили списков должны определяться с помощью таблиц стилей.
Например, с помощью CSS можно указать, что стиль нумерации для элементов списка в нумерованном списке - римские цифры нижнего регистра. В приведенном ниже примере каждый элемент , принадлежащий классу "withroman", обозначается римской цифрой.
<STYLE type="text/css"> OL.withroman { list-style-type: lower-roman } </STYLE> <BODY> <OL class="withroman"> <LI> Шаг один ... <LI> Шаг два ... </OL> </BODY>
Генерация списка определений также зависит от агента пользователя. Например, список:
<DL> <DT>Dweeb <DD>young excitable person who may mature into a <EM>Nerd</EM> or <EM>Geek</EM>
<DT>Cracker <DD>hacker on the Internet
<DT>Nerd <DD>male so into the Net that he forgets his wife's birthday </DL>
может генерироваться следующим образом:
Dweeb young excitable person who may mature into a Nerd or Geek
Cracker hacker on the Internet Nerd male so into the Net that he forgets his wife's birthday
Визуальное представление изображений, объектов и апплетов
Все атрибуты элементов и , относящиеся к визуальному выравниванию и представлению, являются , вместо них следует использовать таблицы стилей.
Включение апплета: элемент APPLET
Элемент APPLET является , вместо него следует использовать элемент .
Формальное определение см. в .
Определения атрибутов
codebase =
Этот атрибут определяет базовый адрес URI апплета. Если этот атрибут не указан, по умолчанию используется базовый адрес URI, используемый для всего документа. Значениями этого атрибута могут быть только подкаталоги каталога, в котором расположен текущий документ.
code =
Этот атрибут определяет имя файла класса, содержащего скомпилированный подкласс апплета или путь, по которому можно получить класс, включая сам файл класса. Он интерпретируется с учетом кода апплета. Для этого должен быть указан один из атрибутов или .
name =
Этот атрибут определяет имя экземпляра апплета, что дает возможность апплетам на одной странице находить друг друга и взаимодействовать друг с другом.
archive =
Этот атрибут определяет разделенный запятыми список адресов URI архивов, содержащих классы и другие ресурсы, которые будут "предварительно загружаться". Классы загружаются с помощью экземпляра AppletClassLoader с заданным . Относительные адреса URI архивов интерпретируются относительно codebase апплета. Предварительная загрузка ресурсов может существенно увеличить производительность апплетов.
object =
Этот атрибут определяет имя ресурса, содержащего serialized представление состояния апплета. Он интерпретируется относительно codebase апплета. serialized данные содержат имя класса апплета, но не обработчика. Имя класса используется для загрузки обработчика из файла класса или архива.
Если апплет "deserialized", метод start() вызывается вместо метода init(). Атрибуты, допустимые при serialized исходного объекта, не восстанавливаются. Атрибуты, переданные в этот экземпляр , будут доступны апплету. Авторам следует очень осторожно использовать это свойство. Перед serialized вапплет должен быть остановлен.
Должен присутствовать один из атрибутов или . Если даны оба атрибута и , и в них указаны разные имена классов, это является ошибкой.
width =
Этот атрибут определяет начальную ширину области отображения апплета (не включая окна и диалоги, создаваемые апплетом).
height =
Этот атрибут определяет начальную высоту области отображения апплета (не включая окна и диалоги, создаваемые апплетом).
Атрибуты, определенные в другом месте
, () () () () , , ()
Этот элемент, поддерживаемый всеми программами просмотра с поддержкой Java, позволяет дизайнерам внедрять апплеты Java в документы HTML. Он является нежелательным, и вместо него следует использовать элемент .
Содержимое элемента служит альтернативной информацией для агентов пользователей, не поддерживающих этот элемент или не сконфигурированных для поддержки апплетов. В противном случае агенты пользователей должны игнорировать содержимое.
ПРИМЕР НЕЖЕЛАТЕЛЬНОГО ИСПОЛЬЗОВАНИЯ:
В следующем примере элемент включает в документ апплет на языке Java. Поскольку атрибут не установлен, предполагается, что апплет находится в том же каталоге, что и сам документ.
<APPLET code="Bubbles.class" width="500" height="500"> Java-апплет, рисующий движущиеся пузыри. </APPLET>
Этот пример можно переписать с использованием элемента следующим образом:
<P><OBJECT codetype="application/java" classid="java:Bubbles.class" width="500" height="500"> Java-апплет, рисующий движущиеся пузыри. </OBJECT>
Задать для апплета исходные значения можно с помощью элемента .
ПРИМЕР НЕЖЕЛАТЕЛЬНОГО ИСПОЛЬЗОВАНИЯ:
Следующий апплет на языке Java:
<APPLET code="AudioItem" width="15" height="15"> <PARAM name="snd" value="Hello.au|Welcome.au"> Java-апплет, воспроизводящий звуковой файл приветствия. </APPLET>
можно определить с использованием элемента следующим образом:
<OBJECT codetype="application/java" classid="AudioItem" width="15" height="15"> <PARAM name="snd" value="Hello.au|Welcome.au"> Java-апплет, воспроизводящий звуковой файл приветствия. </OBJECT>
Включение изображения: элемент IMG
<!-Во избежание проблем с текстовыми агентами пользователей, а также для того, чтобы включение изображений было понятно пользователям невизуальных агентов и могло использоваться ими, Вы должны указывать описания в элементе ALT и избегать использования Серверных навигационных карт--> <!ELEMENT - O EMPTY -- Внедренное изображение --> <!ATTLIST IMG -- , , -- #REQUIRED -- URI внедряемого изображения -- #REQUIRED -- краткое описание -- #IMPLIED -- ссылка на длинное описание (дополняет alt) -- #IMPLIED -- переопределение высоты -- #IMPLIED -- переопределение ширины -- #IMPLIED -- использовать клиентскую навигационную карту -- (ismap) #IMPLIED -- использовать серверную навигационную карту -- >
Начальный тег: обязателен, Конечный тег: запрещен
Определения атрибутов
src = uri
Этот атрибут задает местоположение изображения. Примерами широко распознаваемых форматов являются GIF, JPEG и PNG.
longdesc = uri
Этот атрибут определяет ссылку на длинное описание изображения. Это описание должно дополнять краткое описание, задаваемое атрибутом . Если с изображением связана , в этом атрибуте должна приводиться информация о ее содержимом. Это особенно важно для серверных навигационных карт.
Атрибуты, определенные в другом месте
, () () (), () () () , , , , , , , , , () , ()
, , , , , ()
Элемент внедряет изображение в текущий документ по адресу из определения элемента. Элемент не имеет содержимого; обычно он замещается изображением, назначаемым атрибутом , исключение при этом составляют выровненные влево или вправо изображения, которые out of line.
В приведенном ранее примере мы определили ссылку на семейную фотографию. Здесь мы вставим фотографию непосредственно в текущий документ:
<BODY> <P>Я только что вернулся из отпуска! Вот фотография моей семьи на озере: <IMG src="http://www.somecompany.com/People/Ian/vacation/family.png" alt="Фотография моей семьи на озере."> </BODY>
Этого же эффекта можно достичь с помощью элемента следующим образом:
<BODY> <P> Я только что вернулся из отпуска! Вот фотография моей семьи на озере: <OBJECT data="http://www.somecompany.com/People/Ian/vacation/family.png" type="image/png"> Фотография моей семьи на озере. </OBJECT> </BODY>
Атрибут задает альтернативный текст, который генерируется, если изображение невозможно отобразить (информацию о том, , см. ниже ). Агенты пользователей должны генерировать альтернативный текст, если они не поддерживают изображение, если они не поддерживают определенный тип изображений или если они сконфигурированы так, чтобы не выводить изображений.
В следующем примере показано, как можно использовать атрибут longdesc для ссылки на более подробное описание:
<BODY> <P> <IMG src="sitemap.gif" alt="Карта узла лабораторий HP" longdesc="sitemap.html"> </BODY>
Атрибут задает краткое описание изображения. Его должно быть достаточно для того, чтобы пользователи могли решить, хотят ли они следовать по ссылке, определяемой атрибутом longdesc для более получения подробного описания, здесь это ссылка "sitemap.html".
Информацию о размере изображения, выравнивании и границах см. в разделе о .
Вложенные ссылки недопустимы
Ссылки и якоря, определяемые элементом , не могут быть вложенными; элемент не должен содержать других элементов .
Поскольку DTD определяет элемент как пустой, элементы также не могут быть вложенными.
Введение в двунаправленный алгоритм
В следующем примере проиллюстрировано ожидаемое поведение двунаправленного алгоритма. В нем показаны английский текст слева направо и текст на иврите справа налево.
Рассмотрите следующий текст:
английский1 ИВРИТ2 английский3 ИВРИТ4 английский5 ИВРИТ6
Символы в этом примере (и во всех реплицированных примерах) хранятся в компьютере в том же виде, в каком они отображаются здесь: первый символ - "а", второй - "н", последний "6".
Предположим, для содержащего этот абзац документа определен английский язык. Это означает, что основным направлением является направление слева направо. Корректное представление этой строки:
английский1 2ТИРВИ английский3 4ТИРВИ английский5 6ТИРВИ <----- <----- <----- H H H ----------------------------------------------------> E
Строки точек указывают структуру предложения: основным языком является английский, но встроены некоторые элементы на иврите. Для получения корректного представления не нужно никакой дополнительной разметки, поскольку фрагменты на иврите корректно обращаются агентами пользователя, применяющими двунаправленный алгоритм.
С другой стороны, если для документа определен язык иврит, основным будет направление справа налево. Корректное представление, таким образом, будет:
6ТИРВИ английский5 4ТИРВИ английский3 2ТИРВИ английский1 -------> -------> -------> E E E <------------------------------------------------- H
В это случае все предложение представляется справа налево, а фрагменты на английском языке обращаются двунаправленным алгоритмом.
Введение в объекты, изображения и апплеты
Функции мультимедиа языка HTML позволяют авторам включать в свои страницы изображения, апплеты (программы, которые автоматически загружаются и выполняются на машине пользователя), видеоклипы и другие документы в формате HTML.
Например, чтобы включить в документ изображение в формате PNG, авторы могут использовать следующий код:
<BODY> <P>Около Большого Каньона: <OBJECT data="canyon.png" type="image/png"> <EM>Около</EM> Большого Каньона. </OBJECT> </BODY>
В предыдущих версиях HTML авторы могли включать изображения (с помощью ) и апплеты (с помощью ). Эти элементы имеют несколько ограничений:
Они не могут решить более общей проблемы - включение новых и возможных в будущем типов устройств.
Элемент работает только с апплетами языка Java. Этот элемент теперь , вместо него используется элемент .
Они вызывают проблемы доступности.
Для решения всех этих вопросов в HTML 4.0 вводится элемент , обеспечивающий всестороннее решение для включения объектов. Элемент позволяет авторам документов в формате HTML указывать всю информацию, необходимую для представления объекта агентом пользователя: исходный код, начальные значения и рабочие данные. В данной спецификации термин "объект" используется для описания всех объектов, которые Вы захотите включить в HTML-документы; другие термины: апплеты, подключаемые модули (plug-ins), дескрипторы устройств и т.д.
Новый элемент , таким образом, subsumes некоторые задачи, выполняемые существующими элементами. Рассмотрим следующую классификацию функций:
| Изображение | ||
| Апплет | (.) | |
| Другой документ HTML |
Из таблицы видно, что каждый тип включения имеет конкретное и общее решение. Общий элемент служит решением для использования возможных в будущем типов устройств.
Для включения изображений авторы могут использовать элемент или элемент .
Для включения апплетов авторам следует использовать элемент , поскольку использование элемента .
Для включения одного документа HTML в другой авторы могут использовать новый элемент или элемент . В обоих случаях внедренный документ не зависит от основного документа. Визуальные агенты пользователей могут представлять внедренный документ в виде отдельного окна в основном документе. Для сравнения элементов и обратитесь к .
С изображениями и другими включаемыми объектами могут быть связаны ссылки, с помощью стандартных , а также и с помощью . На навигационной карте задаются геометрические области включаемого объекта, и каждой из них назначается ссылка. При активизации эти ссылки могут вызывать загрузку документа, запускать программу на сервере и т.д.
В следующих разделах мы обсудим различные механизмы, которые авторы могут использовать для включения мультимедиа и создания навигационных карт для этих объектов.
Введение в списки
Язык HTML предлагает авторам несколько механизмов создания списков информации. В каждом списке должен быть один или несколько элементов списков. Списки могут содержать:
Неупорядоченную информацию. Упорядоченную информацию. Определения.
Предыдущий список, например, не упорядочен, он создан с помощью элемента :
<UL> <LI>Неупорядоченную информацию. <LI>Упорядоченную информацию. <LI>Определения. </UL>
Упорядоченный список, создаваемый с помощью элемента , может содержать информацию, в которой важен порядок, например, рецепт:
Тщательно смешать сухие ингредиенты. Влить жидкость. Смешивать 10 минут. Выпекать в течение часа при температуре 300 градусов.
Списки определений, создаваемые с помощью элемента , могут содержать ряд пар термин/определение (хотя списки определений могут иметь и иные применения). Например, список определений можно использовать в рекламе изделия:
Низкая цена
Новая модель этого изделия существенно дешевле предыдущей! Проще работа
Мы изменили изделие, так что с ним теперь легко работать! Безопасно для детей
Вы можете оставить своих детей в комнате, и изделие не причинит им вреда (не гарантируется).
На языке HTML он определяется следующим образом:
<DL> <DT><STRONG>Низкая цена</STRONG> <DD> Новая модель этого изделия существенно дешевле предыдущей! <DT><STRONG>Проще работа</STRONG> <DD>Мы изменили изделие, так что с ним теперь легко работать! <DT><STRONG> Безопасно для детей </STRONG> <DD> Вы можете оставить своих детей в комнате, и изделие не причинит им вреда (не гарантируется). </DL>
Списки могут быть вложенными, разные типы списков можно использовать вместе, как в следующем примере, где список определений содержит неупорядоченный список (ингредиенты) и упорядоченный список (процедуру):
Ингредиенты:
100 г муки 10 г сахара 1 стакан воды 2 яйца соль, перец
Процедура:
Тщательно смешайте сухие ингредиенты. Влейте жидкие ингредиенты. Смешивайте 10 минут. Выпекайте в течение часа при температуре 300 градусов.
Примечания:
Можно добавить изюм.
Точное представление трех типов списков зависит от агента пользователя. Не стоит использовать списки для создания отступов в тексте. Это делается с помощью таблиц стилей.
Введение в ссылки и якоря
HTML предлагает множество условных оборотов для текстовых и структурированных документов, но что отличает его от большинства других языков разметки - его возможности разметки гипертекста и интерактивных документов. В этом разделе вводится понятие ссылки (или гиперссылки или ссылки Web), основной гипертекстовой конструкции. Ссылки связывают один ресурс Web с другим. Несмотря на простоту, ссылки стали основным залогом успеха Web.
Ссылка имеет два конца - называемых anchors -- и направление. Ссылка начинается в "исходном" anchor (источнике) и указывает на "целевой" anchor, который может быть любым ресурсом Web (например, изображением, видеоклипом, звуковым файлом, программой, документом HTML, элементом в документе HTML и т.д.).
Введение в структуру документа HTML
Документ в формате HTML 4.0 состоит из трех частей:
строки, содержащей ,
раздела заголовков (определяемого элементом ),
тела, которое включает собственно содержимое документа. Тело может вводиться элементом или элементом .
Перед каждым элементом или после каждого элемента может находиться пустое пространство (пробелы, переход на новую строку, табуляции и комментарии). Разделы 2 и 3 должны отделяться элементом .
Вот пример простого документа HTML:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0//EN" "http://www.w3.org/TR/REC-html40/strict.dtd"> <HTML> <HEAD> <TITLE>Мой первый документ HTML</TITLE> </HEAD> <BODY> <P>Всем привет! </BODY> </HTML>
Введение в таблицы
Модель таблиц HTML позволяет авторам упорядочивать данные -- текст, форматированный текст, изображения, ссылки, формы, поля форм, другие таблицы и т.д. - в строки и столбцы ячеек.
С каждой таблицей может быть связан заголовок (см. элемент ), предоставляющий краткое описание таблицы. Можно также указать и более длинное описание (с помощью атрибута ) для удобства людей, использующих агенты на базе азбуки Бройля или речи.
могут группироваться в разделы заголовков, нижних заголовков и тела, (с помощью элементов , и соответственно). Группы строк convey дополнительную структурную информацию и могут генерироваться агентами пользователей различными способами, отображающими эту структуру. Агенты пользователей могут использовать подразделение на заголовки/тело/нижние заголовки для поддержки прокрутки тела независимо от заголовков. При печати длинных таблиц информация из заголовков может повторяться на каждой странице таблицы.
Авторы также могут для предоставления дополнительной структурной информации, которая может использоваться агентами пользователей. Более того, авторы могут объявлять свойства столбцов в начале определения таблицы (с помощью элементов и ) таким образом, который позволяет агентам пользователей генерировать таблицу последовательно, а не ждать считывания всех данных таблицы перед тем, как начать генерацию.
могут содержать "заголовок" (см. элемента ) или "данные" (см. элемент ). Ячейки могут распространяться на несколько строк или столбцов. Модель таблиц языка HTML 4.0 позволяет авторам помечать каждую ячейку, так что будет проще работать с информацией о ячейках. Эти механизмы не только существенно облегчают доступ пользователям с физическими недостатками, но и делают его обработку таблиц возможной для мультирежимных беспроводных браузеров с ограниченными возможностями отображения (например, Web-совместимых пейджеров и телефонов).
Не следует использовать таблицы только как средство компоновки содержимого документа, поскольку это может вызвать проблемы при генерации для невизуальных средств. Кроме того, если метки использовать с графикой, это может привести к тому, что пользователям придется выполнять горизонтальную прокрутку, чтобы просмотреть таблицу, созданную в системе с большим экраном. Для уменьшения возможности этих проблем авторам следует использовать для компоновки документа , а не таблицы.
Примечание.
В этой спецификации более подробная информация о таблицах приводится в разделах о .
Ниже показана простая таблица, на примере которой иллюстрируются некоторые возможности модели таблиц языка HTML. Следующее определение:
<TABLE border="1" summary="В этой таблице приводится некоторая статистика о фруктовых мухах: средняя высота и вес, процент мух с красными глазами (особей мужского и женского пола)."> <CAPTION><EM>Тестовая таблица с объединенными ячейками</EM></CAPTION> <TR><TH rowspan="2"><TH colspan="2">Средний <TH rowspan="2">Красные<BR>глаза <TR><TH>высота<TH>вес <TR><TH>мужской пол<TD>1.9<TD>0.003<TD>40% <TR><TH>женский пол<TD>1.7<TD>0.002<TD>43% </TABLE>
должно генерироваться на терминале примерно следующим образом:
Тестовая таблица с объединенными ячейками /----------------------------------------------------------\ | | Средний | Красные | | |-------------------| глаза | | | высота | вес | | |----------------------------------------------------------| | Мужской пол | 1.9 | 0.003 | 40% | | |----------------------------------------------------------| | Женский пол | 1.7 | 0.002 | 43% | | \----------------------------------------------------------/
или следующим образом - графическими агентами пользователей:

Выравнивание
Атрибут align определяет положение , или относительно его содержимого.
Следующие значения атрибута относятся к положению объекта относительно окружающего текста:
bottom: означает, что окно объекта должно быть вертикально выровнено относительно текущей базовой линии. Это значение используется по умолчанию. middle: означает, что центр объекта должен быть выровнен вертикально относительно текущей базовой линии. top: означает, что верх объекта должен быть вертикально выровнен относительно верха текущей текстовой строки.
Два других значения, left и right, приводят к перемещению изображения к текущему левому или правому полю. Они обсуждаются в разделе о плавающих объектах.
Различие интерпретаций атрибута align.
Агенты пользователей по-разному интерпретируют атрибут . Некоторые принимают в расчет только текстовую строку, находящуюся перед элементом, некоторые учитывают текст по обеим сторонам элемента.
Задание якорей и ссылок
Хотя некоторые элементы и атрибуты языка HTML создают ссылки на другие ресурсы (например, элемент , элемент и т.д.), в этой главе обсуждаются ссылки и якоря, создаваемые элементами и . Элемент может присутствовать только в заголовке документа. Элемент может присутствовать только в теле документа.
Если для элемента установлен атрибут , этот элемент определяет исходный якорь для ссылки, которая может активизироваться пользователем для загрузки ресурса Web. Исходный якорь - это местоположение экземпляра элемента и целевой якорь ресурса Web.
Загруженный ресурс может обрабатываться агентом пользователя различными способами: открытием нового документа HTML в том же окне агента, открытием нового документа HTML в другом окне, запуском новой программы для обработки ресурса и т.д. Поскольку элемент имеет содержание (текст, изображения и т.д.), агенты пользователей могут генерировать это содержимое так, чтобы показать наличие ссылки (например, подчеркивая содержимое).
Если установлены атрибуты или элемента , этот элемент определяет якорь, который может служить целью других ссылок.
Авторы могут устанавливать атрибуты и одновременно в одном экземпляре элемента .
Элемент определяет отношение между текущим документом и другим ресурсом. Хотя элемент не имеет содержимого, определяемые им отношения могут отображаться некоторыми агентами пользователей.
Задание языка содержимого: атрибут lang
Определения атрибутов
lang
=
Этот атрибут указывает основной язык значений атрибутов элементов и секстового содержимого. По умолчанию значение этого атрибута не установлено.
Информация о языке, указанная с помощью атрибута , может использоваться агентом пользователя для управления генерацией изображения различными способами. Некоторые ситуации, в которых указываемая автором информация а языке, может быть полезна:
Помощь поисковым машинам Помощь синтезаторам речи Помощь агентам пользователей в выборе вариантов глифов для высококачественной типографии Помощь агенту пользователя в выборе набора кавычек Помощь агенту пользователя в вопросах , лигатур и интервалов Помощь программа проверки грамматики и орфографии
Атрибут указывает код содержимого элемента и значений атрибутов; относится ли он к данному атрибуту, зависит от синтаксиса и семантики атрибута и от операции.
Атрибут предназначен для того, чтобы позволить агентам пользователей более осмысленно генерировать изображение на основе принятой культурной практики для данного языка. Это не подразумевает, что агенты пользователей должны генерировать символы, не являющиеся типичными для конкретного языка, менее осмысленным способом; агенты пользователей должны пытаться сгенерировать се символы, независимо от значения, указанного в атрибуте .
Например, если в русском тексте должен появиться символ греческого алфавита:
<P><Q lang="ru">"Эта супермощность была результатом γ-радиации,</Q> объяснил он.</P>
агент пользователя (1) должен попытаться сгенерировать русский текст соответствующим образом (например, в соответствующих кавычках) и (2) попытаться сгенерировать символ γ, даже если это не русский символ.
Дополнительную информацию см. в разделе о неотображаемых символах.
Заголовок кратко описывает содержание раздела,
<!ENTITY % heading "|"> <!-- Существует шесть уровней заголовков - с H1 (наиболее важный) до H6 (наименее важный). -->
<!ELEMENT () - - ()* -- заголовки --> <!ATTLIST () -- , , -- >
Начальный тег: обязателен, Конечный тег: обязателен
Атрибуты, определяемые в любом другом месте
, () (), () () () () , , , , , , , , , (внутренние события)
Заголовок кратко описывает содержание раздела, которому он предшествует. Информация из заголовка может использоваться агентами пользователей, например, для автоматического построения оглавления документа.
В языке HTML существует шесть уровней заголовков: - наиболее важный - и - наименее важный. Визуальные браузеры обычно отображают более важные заголовки более крупным шрифтом.
В следующем примере показано, как использовать элемент для того, чтобы связать заголовок с последующим разделом документа. Это позволит Вам определить стиль для раздела (цвет фона, шрифт и т.д.) с использованием таблиц стилей.
<DIV class="section" id="forest-elephants" > <H1>Лесные слоны</H1> <P>В этом разделе мы обсуждаем менее известных лесных слонов. ...продолжение раздела...
<DIV class="subsection" id="forest-habitat" > <H2>Ариал</H2> <P>Лесные слоны не живут в деревьях, а среди них. ...продолжение раздела...
</DIV> </DIV>
Эту структуру можно представить с использованием информации о стиле, например:
<HEAD> <TITLE>... название документа ...</TITLE> <STYLE type="text/css"> DIV.section { text-align: justify; font-size: 12pt} DIV.subsection { text-indent: 2em } H1 { font-style: italic; color: green } H2 { color: green } </STYLE> </HEAD>
Пронумерованные разделы и ссылки
Язык HTML не генерирует номера разделов из заголовков. Это может выполняться агентами пользователей. Вскоре языки описания таблиц стилей, такие как CSS, предоставят авторам возможность управления генерацией номеров разделов (для удобства в ссылках в печатной документации, например "См. раздел 7.2").
Некоторые люди считают пропуск уровней заголовков дурным тоном. Они принимают порядок заголовков H1 H2 H1, но не принимают порядок H1 H3 H1, поскольку пропущен уровень H2.
Заголовки ссылок
Атрибут может устанавливаться как для элемента , так и для элемента ; в нем указывается информация о природе ссылки. Эта информация может проговариваться агентом пользователя, отображаться в виде подсказки, изменять вид курсора и т.д.
Таким образом можно augment , указав для каждой ссылки заголовок:
<BODY> ...некоторый текст...
<P>Подробнее Вы можете узнать об этом в <A href="chapter2.html" title="Перейдите к главе 2">главе 2</A>. <A href="./chapter2.html" title="Переход к главе 2.">глава 2</A>. См. также <A href="../images/forest.gif" title="Изображение леса в формате GIF">карту леса.</A> </BODY>
Замечания о внедренных документах
Иногда вместо на документ автору нужно внедрить его непосредственно в первичный документ HTML. Авторы могут использовать для этого элемент или , но эти элементы несколько различны. Эти два элемента не только имеют различные модели содержимого, но также элемент может быть целевым кадром (подробнее см. раздел об ) и может быть "выделен" агентом пользователя для печати, просмотра кода HTML и т.д. Агенты пользователя могут генерировать выделенные кадры способом, отличным от генерации невыделенных кадров (например, отображать границу вокруг выделенного кадра).
Внедренный документ полностью независим от документа, в который он внедрен. Например, относительные адреса URI во внедренном документе в соответствии с базовым адресом URI, указанным во внедренном документе, а не в основном документе. Внедренный документ только генерируется в другом документе (например, во вложенном окне); it во всех остальных отношениях он остается независимым.
Например, следующая строка внедряет содержимое файла embed_me.html в то место документа, в котором встречено определение .
...предшествующий текст...
<OBJECT data="embed_me.html"> Внимание: невозможно внедрить файл embed_me.html. </OBJECT> ...последующий текст...
Вспомните, что содержимое элемента должно генерироваться, только если файл, задаваемый атрибутом , невозможно загрузить.
Поведение агента пользователя в случаях, когда файл включает сам себя, не определено.
Запрет перехода на новую строку
Иногда авторам нужно избежать перехода на новую строку между двумя определенными словами. Комбинация символов (  или  ) действует как неразрывный пробел.
