Абстрактные классы
С наследованием тесно связан еще один важный механизм проектирования семейства классов - механизм абстрактных классов. Начну с определений.
Класс называется абстрактным, если он имеет хотя бы один абстрактный метод.
Метод называется абстрактным, если при определении метода задана его сигнатура, но не задана реализация метода.
Объявление абстрактных методов и абстрактных классов должно сопровождаться модификатором abstract. Поскольку абстрактные классы не являются полностью определенными классами, то нельзя создавать объекты абстрактных классов. Абстрактные классы могут иметь потомков, частично или полностью реализующих абстрактные методы родительского класса. Абстрактный метод чаще всего рассматривается как виртуальный метод, переопределяемый потомком, поэтому к ним применяется стратегия динамического связывания.
Абстрактные классы являются одним из важнейших инструментов объектно-ориентированного проектирования классов. К сожалению, я не могу входить в детали рассмотрения этой важной темы и ограничусь лишь рассмотрением самой идеи применения абстрактного класса. В основе любого класса лежит абстракция данных. Абстрактный класс описывает эту абстракцию, не входя в детали реализации, ограничиваясь описанием тех операций, которые можно выполнять над данными класса. Так, проектирование абстрактного класса Stack, описывающего стек, может состоять из рассмотрения основных операций над стеком и не определять, как будет реализован стек - списком или массивом. Два потомка абстрактного класса - ArrayStack и ListStack могут быть уже конкретными классами, основанными на различных представлениях стека.
Вот описание полностью абстрактного класса Stack:
public abstract class Stack { public Stack() {} /// <summary> /// втолкнуть элемент item в стек /// </summary> /// <param name="item"></param> public abstract void put(int item); /// <summary> /// удалить элемент в вершине стека /// </summary> public abstract void remove(); /// <summary> /// прочитать элемент в вершине стека /// </summary> public abstract int item(); /// <summary> /// определить, пуст ли стек /// </summary> /// <returns></returns> public abstract bool IsEmpty(); }
Описание класса содержит только сигнатуры методов класса и их спецификацию, заданную тегами <summary>. Построим теперь одного из потомков этого класса, реализация которого основана на списковом представлении. Класс ListStack будет потомком абстрактного класса Stack и клиентом класса Linkable, задающего элементы списка. Класс Linkable выглядит совсем просто:
public class Linkable { public Linkable() { } public int info; public Linkable next; }
В нем - два поля и конструктор по умолчанию. Построим теперь класс ListStack:
public class ListStack: Stack { public ListStack() { top = new Linkable(); } Linkable top; /// <summary> /// втолкнуть элемент item в стек /// </summary> /// <param name="item"></param> public override void put(int item) { Linkable newitem = new Linkable(); newitem.info = item; newitem.next = top; top = newitem; } /// <summary> /// удалить элемент в вершине стека /// </summary> public override void remove() { top = top.next; } /// <summary> /// прочитать элемент в вершине стека /// </summary> public override int item() { return(top.info); } /// <summary> /// определить, пуст ли стек /// </summary> /// <returns></returns> public override bool IsEmpty() { return(top.next == null); } }
Класс имеет одно поле top класса Linkable и методы, наследованные от абстрактного класса Stack. Теперь, когда задано представление данных, нетрудно написать реализацию операций. Реализация операций традиционна для стеков и, надеюсь, не требует пояснений.
Приведу пример работы со стеком:
public void TestStack() { ListStack stack = new ListStack(); stack.put(7); stack.put(9); Console.WriteLine(stack.item()); stack.remove(); Console.WriteLine(stack.item()); stack.put(11); stack.put(13); Console.WriteLine(stack.item()); stack.remove(); Console.WriteLine(stack.item()); if(!stack.IsEmpty()) stack.remove(); Console.WriteLine(stack.item()); }
В результате работы этого теста будет напечатана следующая последовательность целых: 9, 7, 13, 11, 7.
Архитектура приложений
Существенно расширился набор возможных архитектурных типов построения приложений. Помимо традиционных Windows- и консольных приложений, появилась возможность построения Web-приложений. Большое внимание уделяется возможности создания повторно используемых компонентов - разрешается строить библиотеки классов, библиотеки элементов управления и библиотеки Web-элементов управления. Популярным архитектурным типом являются Web-службы, ставшие сегодня благодаря открытому стандарту одним из основных видов повторно используемых компонентов. Для языков C#, J#, Visual Basic, поддерживаемых Microsoft, предлагается одинаковый набор из 12 архитектурных типов приложений. Несколько особняком стоит Visual С++, сохраняющий возможность работы не только с библиотекой FCL, но и с библиотеками MFC и ATL, и с построением соответствующих MFC и ATL-проектов. Компиляторы языков, поставляемых другими фирмами, создают проекты, которые удовлетворяют общим требованиям среды, сохраняя свою индивидуальность. Так, например, компилятор Eiffel допускает создание проектов, использующих как библиотеку FCL, так и собственную библиотеку классов.
Арифметические операции
В языке C# имеются обычные для всех языков арифметические операции - "+, -, *, /, %". Все они перегружены. Операции "+" и "-" могут быть унарными и бинарными. Операция деления "/" над целыми типами осуществляет деление нацело, для типов с плавающей и фиксированной точкой - обычное деление. Операция "%" определена над всеми арифметическими типами и возвращает остаток от деления нацело. Тип результата зависит от типов операндов. Приведу пример вычислений с различными арифметическими типами:
/// <summary> /// Арифметические операции /// </summary> public void Ariphmetica() { int n = 7,m =3, p,q; p= n/m; q= p*m + n%m; if (q==n) Console.WriteLine("q=n"); else Console.WriteLine("q!=n"); double x=7, y =3, u,v,w; u = x/y; v= u*y; w= x%y; if (v==x) Console.WriteLine("v=x"); else Console.WriteLine("v!=x"); decimal d1=7, d2 =3, d3,d4,d5; d3 = d1/d2; d4= d3*d2; d5= d1%d2; if (d4==d1) Console.WriteLine("d4=d1"); else Console.WriteLine("d4!=d1"); }//Ariphmetica
При проведении вычислений в двух первых случаях проверяемое условие оказалось истинным, в третьем - ложным. Для целых типов можно исходить из того, что равенство n = n/m*m + n%m истинно. Для типов с плавающей точкой выполнение точного равенства x = x/y*y следует считать скорее случайным, а не закономерным событием. Законно невыполнение этого равенства, как это имеет место при вычислениях с фиксированной точкой.
Библиотека классов FCL - статический компонент каркаса
Понятие каркаса приложений - Framework Applications - появилось достаточно давно; по крайней мере оно широко использовалось еще в четвертой версии Visual Studio. Десять лет назад, когда я с Ильмиром писал книгу [В.А. Биллиг, И.Х. Мусикаев "Visual C++, 4-я версия. Книга для программистов"], для нас это было еще новое понятие. Мы подробно обсуждали роль библиотеки классов MFC (Microsoft Foundation Classes) как каркаса приложений Visual C. Несмотря на то, что каркас был представлен только статическим компонентом, уже тогда была очевидна его роль в построении приложений. Уже в то время важнейшее значение в библиотеке классов MFC имели классы, задающие архитектуру строящихся приложений. Когда разработчик выбирал один из возможных типов приложения, например, архитектуру Document-View, то в его приложение автоматически встраивались класс Document, задающий структуру документа, и класс View, задающий его визуальное представление. Класс Form и классы, задающие элементы управления, обеспечивали единый интерфейс приложений. Выбирая тип приложения, разработчик изначально получал нужную ему функциональность, поддерживаемую классами каркаса. Библиотека классов поддерживала и более традиционные для программистов классы, задающие расширенную систему типов данных, в частности, динамические типы данных - списки, деревья, коллекции, шаблоны.
За прошедшие 10 лет роль каркаса в построении приложений существенно возросла - прежде всего, за счет появления его динамического компонента, о котором чуть позже поговорим подробнее. Что же касается статического компонента - библиотеки классов, то и здесь за десять лет появился ряд важных нововведений.
Блок finally
До сих пор ничего не было сказано о важном участнике схемы обработки исключений - блоке finally. Напомню, рассматриваемая схема является схемой без возобновления. Это означает, что управление вычислением неожиданно покидает try-блок. Просто так этого делать нельзя - нужно выполнить определенную чистку. Прежде всего удаляются все локальные объекты, созданные в процессе работы блока. В языке С++ эта работа требовала вызова деструкторов объектов. В C#, благодаря автоматической сборке мусора, освобождением памяти можно не заниматься, достаточно освободить стек. Но в блоке try могли быть заняты другие ресурсы - открыты файлы, захвачены некоторые устройства. Освобождение ресурсов, занятых try-блоком, выполняет finally-блок. Если он присутствует, он выполняется всегда, сразу же после завершения работы try-блока, как бы последний ни завершился. Блок try может завершиться вполне нормально без всяких происшествий и управление достигнет конца блока, выполнение может прервано оператором throw, управление может быть передано другому блоку из-за выполнения таких операторов как goto, return - во всех этих случаях, прежде чем управление будет передано по предписанному назначению ( в том числе, прежде чем произойдет захват исключения), предварительно будет выполнен finally-блок, который освобождает ресурсы, занятые try-блоком, а параллельно будет происходить освобождение стека от локальных переменных.
Блок или составной оператор
С помощью фигурных скобок несколько операторов языка (возможно, перемежаемых объявлениями) можно объединить в единую синтаксическую конструкцию, называемую блоком или составным оператором:
{ оператор_1 ... оператор_N }
|
В языках программирования нет общепринятой нормы для использования символа точки с запятой при записи последовательности операторов. Есть три различных подхода и их вариации. Категорические противники точек с запятой считают, что каждый оператор должен записываться на отдельной строке (для длинных операторов определяются правила переноса). В этом случае точки с запятой (или другие аналогичные разделители) не нужны. Горячие поклонники точек с запятой (к ним относятся языки С++ и C#) считают, что точкой с запятой должен оканчиваться каждый оператор. В результате в операторе if перед else появляется точка с запятой. Третьи полагают, что точка с запятой играет роль разделителя операторов, поэтому перед else ее не должно быть. В приведенной выше записи блока, следуя синтаксису C#, каждый из операторов заканчивается символом "точка с запятой". Но, заметьте, блок не заканчивается этим символом! |
Синтаксически блок воспринимается как единичный оператор и может использоваться всюду в конструкциях, где синтаксис требует одного оператора. Тело цикла, ветви оператора if, как правило, представляются блоком. Приведу достаточно формальный и слегка запутанный пример, где тело процедуры представлено блоком, в котором есть встроенные блоки, задающие тело оператора цикла for и тела ветвей оператора if:
/// <summary> /// демонстрация блоков (составных операторов) /// </summary> public void Block() { int limit = 100; int x = 120, y = 50; int sum1 =0, sum2=0; for (int i = 0; i< 11; i++) { int step = Math.Abs(limit -x)/10; if (x > limit) {x -= step; y += step;} else {x += step; y -= step;} sum1 += x; sum2 +=y; } //limit = step; //переменная step перестала существовать //limit = i; // переменная i перестала существовать Console.WriteLine("x= {0}, y= {1}, sum1 ={2}, sum2 = {3}", x,y,sum1,sum2); }
Заметьте, здесь в тело основного блока вложен блок, задающий тело цикла, в котором объявлены две локальные переменные - i и step.
В свою очередь, в тело цикла вложены блоки, связанные с ветвями then и else оператора if. Закомментированные операторы, стоящие сразу за окончанием цикла, напоминают, что соответствующие локальные переменные, определенные в блоке, перестают существовать по его завершении.
Приведенная процедура Block является методом класса Testing, который входит в проект Statements, созданный для работы с примерами этой лекции. Вот описание полей и конструктора класса Testing:
/// <summary> /// Класс Testing - тестирующий класс. Представляет набор /// скалярных переменных и методов, тестирующих работу /// с операторами, процедурами и функциями C#. /// </summary> public class Testing { public Testing(string name, int age) { this.age = age; this.name = name; } //поля класса public string name; public int age;
private int period; private string status; }
Быстрая сортировка Хоара
Продолжая тему рекурсии, познакомимся с реализацией на C# еще одного известного рекурсивного алгоритма, применяемого при сортировке массивов. Описанный ранее рекурсивный алгоритм сортировки слиянием имеет один существенный недостаток - для слияния двух упорядоченных массивов за линейное время необходима дополнительная память. Разработанный Ч. Хоаром метод сортировки, получивший название быстрого метода сортировки - QuickSort, не требует дополнительной памяти. Хотя этот метод и не является самым быстрым во всех случаях, но на практике он обеспечивает хорошие результаты. Нужно отметить, что именно этот метод сортировки встроен в класс System.Array.
Идея алгоритма быстрой сортировки состоит в том, чтобы выбрать в исходном массиве некоторый элемент M, затем в начальной части массива собрать все элементы, меньшие M. Так появляются две подзадачи размерности - k и n-k, к которым рекурсивно применяется алгоритм. Если в качестве элемента M выбирать медиану сортируемой части массива, то обе подзадачи имели бы одинаковый размер и алгоритм быстрой сортировки был бы оптимальным по времени работы. Но расчет медианы требует своих затрат времени и усложняет алгоритм. Поэтому обычно элемент M выбирается случайным образом. В этом случае быстрая сортировка оптимальна лишь в среднем, а для плохих вариантов (когда в качестве M всякий раз выбирается минимальный элемент) имеет порядок n2.
Несмотря на простоту идеи, алгоритм сложен в своей реализации, поскольку весь построен на циклах и операторах выбора. Я проводил построение алгоритма параллельно с обоснованием его корректности, введя инварианты соответствующих циклов. Текст обоснования встроен в текст метода. Приведу его, а затем дам некоторые объяснения. Вначале, как обычно, приведу нерекурсивную процедуру, вызывающую рекурсивный метод:
/// <summary> /// Вызывает рекурсивную процедуру QSort, /// передавая ей границы сортируемого массива. /// Сортируемый массив tower1 задается /// соответствующим полем класса. public void QuickSort() { QSort(0,size-1); }
Вот чистый текст рекурсивной процедуры быстрой сортировки Хоара:
void QSort(int start, int finish) { if(start != finish) { int ind = rnd.Next(start,finish); int item = tower1[ind]; int ind1 = start, ind2 = finish; int temp; while (ind1 <=ind2) { while((ind1 <=ind2)&& (tower1[ind1] < item)) ind1++; while ((ind1 <=ind2)&&(tower1[ind2] >= item)) ind2--; if (ind1 < ind2) { temp = tower1[ind1]; tower1[ind1] = tower1[ind2]; tower1[ind2] = temp; ind1++; ind2--; } } if (ind1 == start) { temp = tower1[start]; tower1[start] = item; tower1[ind] = temp; QSort(start+1,finish); } else { QSort(start,ind1-1); QSort(ind2+1, finish); } } }// QuickSort
Проведите эксперимент - закройте книгу и попробуйте написать эту процедуру самостоятельно. Если вам удастся сделать это без ошибок и она пройдет у вас с первого раза, то вы - блестящий программист и вам нужно читать другие книги. Я полагаю, что в таких процедурах ошибки неизбежны и для их исправления требуется серьезная отладка. Полагаю также, что помимо обычного тестирования полезно применять обоснование корректности, основанное на предусловиях и постусловиях, инвариантах цикла. Проектируя эту процедуру, я параллельно встраивал обоснование ее корректности. Это не строгое доказательство, но, дополняя тестирование, оно достаточно, чтобы автор поверил в корректность процедуры и представил ее на суд зрителей, как это сделал я.
/// <summary> /// Небольшая по размеру процедура содержит три /// вложенных цикла while, два оператора if и рекурсивные /// вызовы. Для таких процедур задание инвариантов и /// обоснование корректности облегчает отладку. /// </summary> /// <param name="start">начальный индекс сортируемой части /// массива tower</param> /// <param name="finish">конечный индекс сортируемой части /// массива tower</param> /// Предусловие: (start <= finish) /// Постусловие: массив tower отсортирован по возрастанию void QSort(int start, int finish) { if(start != finish) //если (start = finish), то процедура ничего не делает, //но постусловие выполняется, поскольку массив из одного //элемента отсортирован по определению. Докажем истинность //постусловия для массива с числом элементов >1. { int ind = rnd.Next(start,finish); int item = tower1[ind]; int ind1 = start, ind2 = finish; int temp; /// Введем три непересекающихся множества: /// S1: {tower1(i), start <= i =< ind1-1} /// S2: {tower1(i), ind1 <= i =< ind2} /// S3: {tower1(i), ind2+1 <= i =< finish} /// Введем следующие логические условия, /// играющие роль инвариантов циклов нашей программы: /// P1: объединение S1, S2, S3 = tower1 /// P2: (S1(i) < item) Для всех элементов S1 /// P3: (S3(i) >= item) Для всех элементов S3 /// P4: item - случайно выбранный элемент tower1 /// Нетрудно видеть, что все условия становятся /// истинными после завершения инициализатора цикла. /// Для пустых множеств S1 и S3 условия P2 и P3 /// считаются истинными по определению. /// Inv = P1 & P2 & P3 & P4 while (ind1 <=ind2) { while((ind1 <=ind2)&& (tower1[ind1] < item)) ind1++; //(Inv == true) & ~B1 (B1 - условие цикла while) while ((ind1 <=ind2)&&(tower1[ind2] >= item)) ind2--; //(Inv == true) & ~B2 (B2 - условие цикла while) if (ind1 < ind2) //Из Inv & ~B1 & ~B2 & B3 следует истинность: //((tower1[ind1] >= item)&&(tower1[ind2]<item))==true. //Это условие гарантирует, что последующий обмен //элементов обеспечит выполнение инварианта Inv { temp = tower1[ind1]; tower1[ind1] = tower1[ind2]; tower1[ind2] = temp; ind1++; ind2--; } //(Inv ==true) } //из условия окончания цикла следует: (S2 - пустое множество) if (ind1 == start) //В этой точке S1 и S2 - это пустые множества, -> //(S3 = tower1) // Нетрудно доказать, что отсюда следует истинность: //(item = min) // Как следствие, можно минимальный элемент сделать первым, // а к оставшемуся множеству применить рекурсивный вызов. { temp = tower1[start]; tower1[start] = item; tower1[ind] = temp; QSort(start+1,finish); } else // Здесь оба множества S1 и S3 не пусты. // К ним применим рекурсивный вызов. { QSort(start,ind1-1); QSort(ind2+1, finish); } //Индукция по размеру массива и истинность инварианта //доказывает истинность постусловия в общем случае. } }// QuickSort
Приведу некоторые пояснения к этому доказательству. Задание предусловия и постусловия процедуры QSort достаточно очевидно - сортируемый массив должен быть не пустым, а после работы метода должен быть отсортированным. Важной частью обоснования является четкое введение трех множеств - S1, S2, S3 - и условий, накладываемых на их элементы. Эти условия и становятся частью инварианта, сохраняющегося при работе различных циклов нашего метода. Вначале множества S1 и S3 пусты, в ходе вычислений пустым становится множество S2. Так происходит формирование подзадач, к которым рекурсивно применяется алгоритм. Особым представляется случай, когда множество S1 тоже пусто. Нетрудно показать, что эта ситуация возможна только в том случае, если случайно выбранный элемент множества, служащий критерием разбиения исходного множества на два подмножества, является минимальным элементом.
Почему обоснование полезно практически? Дело в том, что в данном алгоритме приходится следить за границами множеств (чтобы они не пересекались), за пустотой множеств (служащих условием окончания циклов), за выполнением условий, накладываемых на элементы множеств. Если явно не ввести эти понятия, то вероятность ошибки существенно возрастает. В заключение следует все-таки привести результат сортировки хотя бы одного массива.

Рис. 10.3. Результаты быстрой сортировки массива
Что нужно знать о методах?
Знания формального синтаксиса и семантики недостаточно, чтобы эффективно работать с методами. Рассмотрим сейчас несколько важных вопросов, касающихся различных сторон работы с методами класса.
Цикл foreach
Новым видом цикла, не унаследованным от С++, является цикл foreach, удобный при работе с массивами, коллекциями и другими подобными контейнерами данных. Его синтаксис:
foreach(тип идентификатор in контейнер) оператор
Цикл работает в полном соответствии со своим названием - тело цикла выполняется для каждого элемента в контейнере. Тип идентификатора должен быть согласован с типом элементов, хранящихся в контейнере данных. Предполагается также, что элементы контейнера (массива, коллекции) упорядочены. На каждом шаге цикла идентификатор, задающий текущий элемент контейнера, получает значение очередного элемента в соответствии с порядком, установленным на элементах контейнера. С этим текущим элементом и выполняется тело цикла - выполняется столько раз, сколько элементов находится в контейнере. Цикл заканчивается, когда полностью перебраны все элементы контейнера.
Серьезным недостатком циклов foreach в языке C# является то, что цикл работает только на чтение, но не на запись элементов. Так что наполнять контейнер элементами приходится с помощью других операторов цикла.
В приведенном ниже примере показана работа с трехмерным массивом. Массив создается с использованием циклов типа for, а при нахождении суммы его элементов, минимального и максимального значения используется цикл foreach:
/// <summary> /// Демонстрация цикла foreach. Вычисление суммы, /// максимального и минимального элементов /// трехмерного массива, заполненного случайными числами. /// </summary> public void SumMinMax() { int [,,] arr3d = new int[10,10,10]; Random rnd = new Random(); for (int i =0; i<10; i++) for (int j =0; j<10; j++) for (int k =0; k<10; k++) arr3d[i,j,k]= rnd.Next(100); long sum =0; int min=arr3d[0,0,0], max=arr3d[0,0,0]; foreach(int item in arr3d) { sum +=item; if (item > max) max = item; else if (item < min) min = item; } Console.WriteLine("sum = {0}, min = {1}, max = {2}", sum, min, max); }//SumMinMax
Циклы While
Цикл while (выражение) является универсальным видом цикла, включаемым во все языки программирования. Тело цикла выполняется до тех пор, пока остается истинным выражение while. В языке C# у этого вида цикла две модификации - с проверкой условия в начале и в конце цикла. Первая модификация имеет следующий синтаксис:
while(выражение) оператор
Эта модификация соответствует стратегии: "сначала проверь, а потом делай". В результате проверки может оказаться, что и делать ничего не нужно. Тело такого цикла может ни разу не выполняться. Конечно же, возможно и зацикливание. В нормальной ситуации каждое выполнение тела цикла - это очередной шаг к завершению цикла.
Цикл, проверяющий условие завершения в конце, соответствует стратегии: "сначала делай, а потом проверь". Тело такого цикла выполняется, по меньшей мере, один раз. Вот синтаксис этой модификации:
do оператор while(выражение);
Приведу пример, в котором участвуют обе модификации цикла while. Во внешнем цикле проверка выполняется в конце, во внутреннем - в начале. Внешний цикл представляет собой типичный образец организации учебных программ, когда в диалоге с пользователем многократно решается некоторая задача. На каждом шаге пользователь вводит новые данные, решает задачу и анализирует полученные данные. В его власти, продолжить вычисления или нет, но хотя бы один раз решить задачу ему приходится. Внутренний цикл do while используется для решения уже известной задачи с палиндромами. Вот текст соответствующей процедуры:
/// <summary> /// Два цикла: с проверкой в конце и в начале. /// Внешний цикл - образец многократно решаемой задачи. /// Завершение цикла определяется в диалоге /// с пользователем. /// </summary> public void Loop() { string answer, text; do { Console.WriteLine("Введите слово"); text = Console.ReadLine(); int i =0, j = text.Length-1; while ((i<j) && (text[i] == text[j])) {i++; j--;} if (text[i] == text[j]) Console.WriteLine(text +" - это палиндром!"); else Console.WriteLine(text +" - это не палиндром!"); Console.WriteLine("Продолжим? (yes/no)"); answer = Console.ReadLine(); } while(answer =="yes"); }//Loop
Делегаты и события
Наверное, вы уже заметили, что схема работы с событиями вполне укладывается в механизм, определяемый делегатами. В C# каждое событие определяется делегатом, описывающим сигнатуру сообщения. Объявление события - это двухэтапный процесс:
Вначале объявляется делегат - функциональный класс, задающий сигнатуру. Как отмечалось при рассмотрении делегатов, объявление делегата может быть помещено в некоторый класс, например, класс Sender. Но, чаще всего, это объявление находится вне класса в пространстве имен. Поскольку одна и та же сигнатура может быть у разных событий, то для них достаточно иметь одного делегата. Для некоторых событий можно использовать стандартные делегаты, встроенные в каркас. Тогда достаточно знать только их имена.Если делегат определен, то в классе Sender, создающем события, достаточно объявить событие как экземпляр соответствующего делегата. Это делается точно так же, как и при объявлении функциональных экземпляров делегата. Исключением является добавление служебного слова event. Формальный синтаксис объявления таков:[атрибуты] [модификаторы]event [тип, заданный делегатом] [имя события]
Есть еще одна форма объявления, но о ней чуть позже. Чаще всего, атрибуты не задаются, а модификатором является модификатор доступа - public. Приведу пример объявления делегата и события, представляющего экземпляр этого делегата:
namespace Events { public delegate void FireEventHandler(object Sender, int time, int build); public class TownWithEvents { public event FireEventHandler FireEvent; ... }//TownWithEvents ... }//namespace Events
Здесь делегат FireEventHandler описывает класс событий, сигнатура которых содержит три аргумента. Событие FireEvent в классе TownWithEvents является экземпляром класса, заданного делегатом.
Делегаты как свойства
В наших примерах рассматривалась ситуация, при которой в некотором классе объявлялись функции, удовлетворяющие контракту с делегатом, но создание экземпляров делегата и их инициирование функциями класса выполнялось в другом месте, там, где предполагалось вызывать соответствующие функции. Чаще всего, создание экземпляров удобнее возложить на класс, создающий требуемые функции. Более того, в этом классе делегат можно объявить как свойство класса, что позволяет "убить двух зайцев". Во-первых, с пользователей класса снимается забота создания делегатов, что требует некоторой квалификации, которой у пользователя может и не быть. Во-вторых, делегаты создаются динамически, в тот момент, когда они требуются. Это важно как при работе с функциями высших порядков, когда реализаций, например, подынтегральных функций, достаточно много, так и при работе с событиями класса, в основе которых лежат делегаты.
Рассмотрим пример, демонстрирующий и поясняющий эту возможность при работе с функциями высших порядков. Идея примера такова. Спроектируем два класса:
класс объектов Person с полями: имя, идентификационный номер, зарплата. В этом классе определим различные реализации функции Compare, позволяющие сравнивать два объекта по имени, по номеру, по зарплате, по нескольким полям. Самое интересное, ради чего и строится данный пример: для каждой реализации Compare будет построена процедура-свойство, которая задает реализацию делегата, определенного в классе Persons;класс Persons будет играть роль контейнера объектов Person.
В этом классе будут определены операции над объектами. Среди операций нас, прежде всего, будет интересовать сортировка объектов, реализованная в виде функции высших порядков. Функциональный параметр будет задавать класс функций сравнения объектов, реализации которых находятся в классе Person. Делегат, определяющий класс функций сравнения, будет задан в классе Persons.
Теперь, когда задача ясна, приступим к ее реализации. Класс Person уже появлялся в наших примерах, поэтому он просто дополнен до нужной функциональности. Добавим методы сравнения двух объектов Person:
//методы сравнения private static int CompareName(Person obj1, Person obj2) { return(string.Compare(obj1.name,obj2.name)); } private static int CompareId(Person obj1, Person obj2) { if( obj1.id > obj2.id) return(1); else return(-1); } private static int CompareSalary(Person obj1, Person obj2) { if( obj1.salary > obj2.salary) return(1); else if(obj1.salary < obj2.salary)return(-1); else return(0); } private static int CompareSalaryName(Person obj1, Person obj2) { if( obj1.salary > obj2.salary) return(1); else if(obj1.salary < obj2.salary)return(-1); else return(string.Compare(obj1.name,obj2.name)); }
Заметьте, методы закрыты и, следовательно, недоступны извне. Их четыре, но могло бы быть и больше, при возрастании сложности объекта растет число таких методов. Все методы имеют одну и ту же сигнатуру и удовлетворяют контракту, заданному делегатом, который будет описан чуть позже. Для каждого метода необходимо построить экземпляр делегата, который будет задавать ссылку на метод. Поскольку не все экземпляры нужны одновременно, то хотелось бы строить их динамически, в тот момент, когда они понадобятся. Это можно сделать, причем непосредственно в классе Person. Закрытые методы будем рассматривать как закрытые свойства и для каждого из них введем статическую процедуру-свойство, возвращающую в качестве результата экземпляр делегата со ссылкой на метод. Проще написать, чем объяснить на словах:
//делегаты как свойства public static Persons.CompareItems SortByName { get {return(new Persons.CompareItems(CompareName));} } public static Persons.CompareItems SortById { get {return(new Persons.CompareItems(CompareId));} } public static Persons.CompareItems SortBySalary { get {return(new Persons.CompareItems(CompareSalary));} } public static Persons.CompareItems SortBySalaryName { get {return(new Persons.CompareItems(CompareSalaryName));} }
Всякий раз, когда будет запрошено, например, свойство SortByName класса Person, будет возвращен объект функционального класса Persons.CompareItems, задающий ссылку на метод CompareName класса Person. Объект будет создаваться динамически в момент запроса.
Класс Person полностью определен, и теперь давайте перейдем к определению контейнера, содержащего объекты Person. Начну с определения свойств класса Persons:
class Persons { //контейнер объектов Person //делегат public delegate int CompareItems(Person obj1, Person obj2); private int freeItem = 0; const int n = 100; private Person[]persons = new Person[n]; }
В классе определен функциональный класс - делегат CompareItems, задающий контракт, которому должны удовлетворять функции сравнения элементов.
Контейнер объектов реализован простейшим образом в виде массива объектов. Переменная freeItem - указатель на первый свободный элемент массива. Сам массив является закрытым свойством, и доступ к нему осуществляется благодаря индексатору:
//индексатор public Person this[int num] { get { return(persons[num-1]); } set { persons[num-1] = value; } }
Добавим классический для контейнеров набор методов - добавление нового элемента, загрузка элементов из базы данных и печать элементов:
public void AddPerson(Person pers) { if(freeItem < n) { Person p = new Person(pers); persons[freeItem++]= p; } else Console.WriteLine("Не могу добавить Person"); } public void LoadPersons() { //реально загрузка должна идти из базы данных AddPerson(new Person("Соколов",123, 750.0)); AddPerson(new Person("Синицын",128, 850.0)); AddPerson(new Person("Воробьев",223, 750.0)); AddPerson(new Person("Орлов",129, 800.0)); AddPerson(new Person("Соколов",133, 1750.0)); AddPerson(new Person("Орлов",119, 750.0)); }//LoadPersons public void PrintPersons() { for(int i =0; i<freeItem; i++) { Console.WriteLine("{0,10} {1,5} {2,5}", persons[i].Name, persons[i].Id, persons[i].Salary); } }//PrintPersons
Конечно, метод LoadPerson в реальной жизни устроен по-другому, но в нашем примере он свою задачу выполняет. А теперь определим метод сортировки записей с функциональным параметром, задающим тот или иной способ сравнения элементов:
//сортировка public void SimpleSortPerson(CompareItems compare) { Person temp = new Person(); for(int i = 1; i<freeItem;i++) for(int j = freeItem -1; j>=i; j--) if (compare(persons[j],persons[j-1])==-1) { temp = persons[j-1]; persons[j-1]=persons[j]; persons[j] = temp; } }//SimpleSortObject }//Persons
Единственный аргумент метода SimpleSortPerson принадлежит классу CompareItems, заданному делегатом. Что касается метода сортировки, то реализован простейший алгоритм пузырьковой сортировки, со своей задачей он справляется. На этом проектирование классов закончено, нужная цель достигнута, показано, как можно в классе экземпляры делегатов задавать как свойства. Для завершения обсуждения следует продемонстрировать, как этим нужно пользоваться. Зададим, как обычно, тестирующую процедуру, в которой будут использоваться различные критерии сортировки:
public void TestSortPersons() { Persons persons = new Persons(); persons.LoadPersons(); Console.WriteLine (" Сортировка по имени: "); persons.SimpleSortPerson(Person.SortByName); persons.PrintPersons(); Console.WriteLine (" Сортировка по идентификатору: "); persons.SimpleSortPerson(Person.SortById); persons.PrintPersons(); Console.WriteLine (" Сортировка по зарплате: "); persons.SimpleSortPerson(Person.SortBySalary); persons.PrintPersons(); Console.WriteLine (" Сортировка по зарплате и имени: "); persons.SimpleSortPerson(Person.SortBySalaryName); persons.PrintPersons(); }//SortPersons
Результаты работы сортировки данных изображены на рис. 20.5.

Рис. 20.5. Сортировка данных
Деструкторы класса
Если задача создания объектов полностью возлагается на программиста, то задача удаления объектов, после того, как они стали не нужными, в Visual Studio .Net снята с программиста и возложена на соответствующий инструментарий - сборщик мусора. В классическом варианте языка C++ деструктор так же необходим классу, как и конструктор. В языке C# y класса может быть деструктор, но он не занимается удалением объектов и не вызывается нормальным образом в ходе выполнения программы. Так же, как и статический конструктор, деструктор класса, если он есть, вызывается автоматически в процессе сборки мусора. Его роль - в освобождении ресурсов, например, файлов, открытых объектом. Деструктор C# фактически является финализатором (finalizer), с которыми мы еще встретимся при обсуждении исключительных ситуаций. Приведу формальное описание деструктора класса Person:
~Person() { //Код деструктора }
Имя деструктора строится из имени класса с предшествующим ему символом ~ (тильда). Как и у статического конструктора, у деструктора не указывается модификатор доступа.
Динамические массивы
Во всех вышеприведенных примерах объявлялись статические массивы, поскольку нижняя граница равна нулю по определению, а верхняя всегда задавалась в этих примерах константой. Напомню, что в C# все массивы, независимо от того, каким выражением описывается граница, рассматриваются как динамические, и память для них распределяется в "куче". Полагаю, что это отражение разумной точки зрения: ведь статические массивы, скорее исключение, а правилом является использование динамических массивов. В действительности реальные потребности в размере массива, скорее всего, выясняются в процессе работы в диалоге с пользователем.
Чисто синтаксически нет существенной разницы в объявлении статических и динамических массивов. Выражение, задающее границу изменения индексов, в динамическом случае содержит переменные. Единственное требование - значения переменных должны быть определены в момент объявления. Это ограничение в C# выполняется автоматически, поскольку хорошо известно, сколь требовательно C# контролирует инициализацию переменных.
Приведу пример, в котором описана работа с динамическим массивом:
public void TestDynAr() { //объявление динамического массива A1 Console.WriteLine("Введите число элементов массива A1"); int size = int.Parse(Console.ReadLine()); int[] A1 = new int[size]; Arrs.CreateOneDimAr(A1); Arrs.PrintAr1("A1",A1); }//TestDynAr
В особых комментариях эта процедура не нуждается. Здесь верхняя граница массива определяется пользователем.
Динамические методы класса String
Операции, разрешенные над строками в C#, разнообразны. Методы этого класса позволяют выполнять вставку, удаление, замену, поиск вхождения подстроки в строку. Класс String наследует методы класса Object, частично их переопределяя. Класс String наследует и, следовательно, реализует методы четырех интерфейсов: IComparable, ICloneable, IConvertible, IEnumerable. Три из них уже рассматривались при описании классов-массивов.
Рассмотрим наиболее характерные методы при работе со строками.
Сводка методов, приведенная в таблице 14.2, дает достаточно полную картину широких возможностей, имеющихся при работе со строками в C#. Следует помнить, что класс string является неизменяемым. Поэтому Replace, Insert и другие методы представляют собой функции, возвращающие новую строку в качестве результата и не изменяющие строку, вызвавшую метод.
| Insert | Вставляет подстроку в заданную позицию |
| Remove | Удаляет подстроку в заданной позиции |
| Replace | Заменяет подстроку в заданной позиции на новую подстроку |
| Substring | Выделяет подстроку в заданной позиции |
| IndexOf, IndexOfAny, LastIndexOf, LastIndexOfAny | Определяются индексы первого и последнего вхождения заданной подстроки или любого символа из заданного набора |
| StartsWith, EndsWith | Возвращается true или false, в зависимости от того, начинается или заканчивается строка заданной подстрокой |
| PadLeft, PadRight | Выполняет набивку нужным числом пробелов в начале и в конце строки |
| Trim, TrimStart, TrimEnd | Обратные операции к методам Pad. Удаляются пробелы в начале и в конце строки, или только с одного ее конца |
| ToCharArray | Преобразование строки в массив символов |
Дизассемблер и ассемблер
Если у вас есть готовый PE-файл, то иногда полезно анализировать его IL-код и связанные с ним метаданные. В состав Framework SDK входит дизассемблер - ildasm, выполняющий дизассемблирование PE-файла и показывающий метаданные, а также IL-код с комментариями в наглядной форме. Мы иногда будем пользоваться результатами дизассемблирования. У меня на компьютере кнопка, вызывающая дизассемблер, находится на панели, где собраны наиболее часто используемые мной приложения. Вот путь к папке, в которой обычно находится дизассемблер:
C:\Program Files\Microsoft Visual Studio .Net\ FrameworkSDK\Bin\ildasm.exe
Профессионалы, предпочитающие работать на низком уровне, могут программировать на языке ассемблера IL. В этом случае в их распоряжении будет вся мощь библиотеки FCL и все возможности CLR. У меня на компьютере путь к папке, где находится ассемблер, следующий:
C:\WINDOWS\Microsoft.Net\Framework\v1.1.4322\ilasm.exe
В этом курсе к ассемблеру мы обращаться не будем - я упоминаю о нем для полноты картины.
Добавление методов и изменение методов родителя
Потомок может создать новый собственный метод с именем, отличным от имен наследуемых методов. В этом случае никаких особенностей нет. Вот пример такого метода, создаваемого в классе Derived:
public void DerivedMethod() { Console.WriteLine("Это метод класса Derived"); }
В отличие от неизменяемых полей классов - предков, класс - потомок может изменять наследуемые им методы. Если потомок создает метод с именем, совпадающим с именем метода предков, то возможны три ситуации:
перегрузка метода. Она возникает, когда сигнатура создаваемого метода отличается от сигнатуры наследуемых методов предков. В этом случае в классе потомка будет несколько перегруженных методов с одним именем, и вызов нужного метода определяется обычными правилами перегрузки методов;переопределение метода. Метод родителя в этом случае должен иметь модификатор virtual или abstract. Эта наиболее интересная ситуация подробно будет рассмотрена в следующих разделах нашей лекции. При переопределении сохраняется сигнатура и модификаторы доступа наследуемого метода;скрытие метода. Если родительский метод не является виртуальным или абстрактным, то потомок может создать новый метод с тем же именем и той же сигнатурой, скрыв родительский метод в данном контексте. При вызове метода предпочтение будет отдаваться методу потомка, а имя наследуемого метода будет скрыто. Это не означает, что оно становится недоступным. Скрытый родительский метод всегда может быть вызван, если при вызове уточнить ключевым словом base имя метода.
Метод потомка, скрывающий метод родителя, следует сопровождать модификатором new, указывающим на новый метод. Если этот модификатор опущен, но из контекста ясно, что речь идет о новом методе, то выдается предупреждающее сообщение при компиляции проекта.
Вернемся к нашему примеру. Класс Found имел в своем составе метод Analysis. Его потомок класс Derived создает свой собственный метод анализа, скрывая метод родителя:
new public void Analysis() { base.Analysis(); Console.WriteLine("Сложный анализ"); }
Если модификатор new опустить, он добавится по умолчанию с выдачей предупреждающего сообщения о скрытии метода родителя. Как компилятор узнает, что в этой ситуации речь идет о новом методе? Причины понятны. С одной стороны, родительский метод не имеет модификаторов virtual или abstract, поэтому речь не идет о переопределении метода. С другой стороны, в родительском классе уже есть метод с данным именем и сигнатурой, и поскольку в классе не могут существовать два метода с одинаковой сигнатурой, то речь может идти только о новом методе класса, скрывающем родительский метод. Несмотря на "интеллект" транслятора, хороший стиль программирования требует явного указания модификатора new в подобных ситуациях.
Заметьте, потомок строит свой анализ на основе метода, наследованного от родителя, вызывая первым делом скрытый родительский метод.
Рассмотрим случай, когда потомок добавляет перегруженный метод. Вот пример, когда потомок класса Derived - класс ChildDerived создает свой метод анализа, изменяя сигнатуру метода Analysis:
public void Analysis(int level) { base.Analysis(); Console.WriteLine("Анализ глубины {0}", level); }
Большой ошибки не будет, если указать модификатор new и в этом случае, но будет выдано предупреждающее сообщение, что модификатор может быть опущен, поскольку сокрытия родительского метода не происходит.
Добавление полей потомком
Ничего не делающий самостоятельно потомок не эффективен, от него мало проку. Что же может делать потомок? Прежде всего, он может добавить новые свойства - поля класса. Заметьте, потомок не может ни отменить, ни изменить модификаторы или типы полей, наследованных от родителя - он может только добавить собственные поля.
Модифицируем наш класс Derived. Пусть он добавляет новое поле класса, закрытое для клиентов этого класса, но открытое для его потомков:
protected int debet;
Напомню, хорошей стратегией является стратегия "ничего не скрывать от потомков". Какой родитель знает, что именно из сделанного им может понадобиться потомкам?
Доступ к методам
Каждый метод имеет модификатор доступа, принимающий одно из четырех значений: public, private, protected, internal. Атрибутом доступа по умолчанию является атрибут private. Независимо от значения атрибута доступа, все методы доступны для вызова при выполнении метода класса. Если методы имеют атрибут доступа private, возможно, опущенный, то тогда они доступны только для вызова и только внутри методов самого класса. Такие методы считаются закрытыми. Понятно, что класс, у которого все методы закрыты, абсурден, поскольку никто не смог бы вызвать ни один из его методов. Как правило, у класса есть открытые методы, задающие интерфейс класса, и закрытые методы. Интерфейс - это лицо класса и именно он определяет, чем класс интересен своим клиентам, что он может делать, какие сервисы предоставляет клиентам. Закрытые методы составляют важную часть класса, позволяя клиентам не вникать во многие детали реализации. Эти методы клиентам класса недоступны, они о них могут ничего не знать, и, самое главное, изменения в закрытых методах никак не отражаются на клиентах класса при условии корректной работы открытых методов.
Если некоторые методы класса A должны быть доступны для вызовов в методах класса B, являющегося потомком класса A, то такие методы следует снабдить атрибутом protected. Если некоторые методы должны быть доступны только для методов классов B1, B2 и так далее, дружественных по отношению к классу A, то такие методы следует снабдить атрибутом internal, а все дружественные классы B поместить в один проект. Наконец, если некоторые методы должны быть доступны для методов любого класса B, которому доступен сам класс A, то такие методы снабжаются модификатором public.
Доступ к полям
Каждое поле имеет модификатор доступа, принимающий одно из четырех значений: public, private, protected, internal. Атрибутом доступа по умолчанию является атрибут private. Независимо от значения атрибута доступа, все поля доступны для всех методов класса. Они являются для методов класса глобальной информацией, с которой работают все методы, извлекая из полей нужные им данные и изменяя их значения в ходе работы. Если поля доступны только для методов класса, то они имеют атрибут доступа private, который можно опускать. Такие поля считаются закрытыми, но часто желательно, чтобы некоторые из них были доступны в более широком контексте. Если некоторые поля класса A должны быть доступны для методов класса B, являющегося потомком класса A, то эти поля следует снабдить атрибутом protected. Такие поля называются защищенными. Если некоторые поля должны быть доступны для методов классов B1, B2 и так далее, дружественных по отношению к классу A, то эти поля следует снабдить атрибутом internal, а все дружественные классы B поместить в один проект (assembly). Такие поля называются дружественными. Наконец, если некоторые поля должны быть доступны для методов любого класса B, которому доступен сам класс A, то эти поля следует снабдить атрибутом public. Такие поля называются общедоступными или открытыми.
Два наследника формы TwoLists
Построим по указанной технологии двух наследников формы TwoLists. Дадим им имена: TwoLists_Strings и TwoLists_Books. Они будут отличаться тем, что первый из них будет заполнять левый список строками, а второй - "настоящими объектами" класса Book. Второй список при открытии форм будет оставаться пустым и служить для хранения выбора, сделанного пользователем. Оба наследника будут также задавать обработчики события Click для командных кнопок, завершающих работу с этими формами. На рис. 24.6 показана наследуемая форма, открытая в дизайнере форм.

Рис. 24.6. Наследуемая форма, открытая в дизайнере
Обратите внимание на значки, сопровождающие все наследуемые элементы управления. В классе TwoLists_Strings добавлены поля:
string[] source_items; string[] selected_items; const int max_items = 20;
В конструктор класса добавлен код, инициализирующий массивы:
source_items = new string[max_items]; selected_items = new string[max_items]; InitList1();
Вызываемый в конструкторе закрытый метод класса InitList заполняет массив source_items - источник данных - строками, а затем передает эти данные в левый список формы. По-хорошему, следовало бы организовать заполнение списка формы из базы данных, но я здесь выбрал самый примитивный способ:
void InitList1() { //задание элементов источника и инициализация списка формы source_items[0] ="Бертран Мейер: Методы программирования"; //аналогично заполняются другие элементы массива //перенос массива в список ListBox1 int i = 0; while (source_items[i] != null) { this.listBox1.Items.Add(source_items[i]); i++; } //this.listBox1.DataSource = source_items; }
Закомментирована альтернативная возможность заполнения списка формы, использующая свойство DataSource. Когда форма откроется, ее левый список будет заполнен, пользователь сможет выбрать из списка понравившиеся ему книги и перенести их в правый список. Зададим теперь обработчики события Click для командных кнопок ("Сохранить выбор" и "Не сохранять"):
private void button3_Click(object sender, System.EventArgs e) { int i =0; foreach(string item in listBox2.Items) { selected_items[i] = item; Debug.WriteLine(selected_items[i]); i++; } this.Hide(); } private void button4_Click(object sender, System.EventArgs e) { foreach(string item in listBox2.Items) { Debug.WriteLine(item); } this.Hide(); }
Оба они в Debug-версии проекта выводят данные о книгах, выбранных пользователем, и скрывают затем форму. Но первый из них сохраняет результаты выбора в поле selected_items.
Второй наследник TwoLists_Books устроен аналогично, но хранит в списке не строки, а объекты класса Book. Приведу уже без комментариев соответствующие фрагменты кода:
Book[] source_items; Book[] selected_items; const int max_items = 20;
Код, добавляемый в конструктор:
source_items = new Book[max_items]; selected_items = new Book[max_items]; InitList1();
Метод InitList1 скорректирован для работы с книгами:
void InitList1() { //задание элементов источника и инициализация списка формы Book newbook; newbook = new Book("Бертран Мейер", "Методы программирования",3,1980); source_items[0] =newbook; //остальные элементы массива заполняются аналогичным //образом //перенос массива в список ListBox1 int i = 0; while (source_items[i] != null) { this.listBox1.Items.Add(source_items[i]); i++; } }
Обработчики событий Click командных кнопок, завершающих работу с формой, имеют вид:
private void button3_Click(object sender, System.EventArgs e) { int i =0; foreach(object item in listBox2.Items) { selected_items[i] = (Book)item; selected_items[i].PrintBook(); i++; } this.Hide(); } private void button4_Click(object sender, System.EventArgs e) { Book book; foreach(object item in listBox2.Items) { book = (Book)item; book.PrintBook(); } this.Hide(); }
Класс Book определен следующим образом:
public class Book { //поля string author, title; int price, year; public Book(string a, string t, int p, int y) { author = a; title = t; price = p; year = y; } public override string ToString() { return( title + " : " + author); } public void PrintBook() { Debug.WriteLine("автор:" + author + " название: " + title + " цена: " + price.ToString() +" год издания: " + year.ToString()); } }
Обратите внимание, что в классе, как и положено, переопределен метод ToString, который задает строку, отображаемую в списке.
В завершение проекта нам осталось спроектировать главную форму. Сделаем ее в соответствии с описанным ранее шаблоном кнопочной формой (рис. 24.7).

Рис. 24.7. Главная кнопочная форма проекта
Обработчики событий Click вызывают соответствующую форму для работы либо со списком, хранящим строки, либо со списком, хранящим объекты. На рис. 24.8 показана форма, хранящая строки, в процессе работы с ней.

Рис. 24.8. Форма TwoLists_Strings в процессе работы
Два основных механизма объектной технологии
Наследование и универсальность являются двумя основными механизмами, обеспечивающими мощность объектной технологии разработки. Наследование позволяет специализировать операции класса, уточнить, как должны выполняться операции. Универсализация позволяет специализировать данные, уточнить, над какими данными выполняются операции.
Эти механизмы взаимно дополняют друг друга. Универсальность можно ограничить (об этом подробнее будет сказано ниже), указав, что тип, задаваемый родовым параметром, обязан быть наследником некоторого класса и/или ряда интерфейсов. С другой стороны, когда формальный тип T заменяется фактическим типом TFact, то там, где разрешено появляться объектам типа TFact, разрешены и объекты, принадлежащие классам-потомкам TFact.
Эти механизмы в совокупности обеспечивают бесшовный процесс разработки программных систем, начиная с этапов спецификации и проектирования системы и заканчивая этапами реализации и сопровождения. На этапе задания спецификаций появляются абстрактные, универсальные классы, которые в ходе разработки становятся вполне конкретными классами с конкретными типами данных. Механизмы наследования и универсализации позволяют существенно сократить объем кода, описывающего программную систему, поскольку потомки не повторяют наследуемый код своих родителей, а единый код универсального класса используется при каждой конкретизации типов данных. На рис. 22.2 показан схематически процесс разработки программной системы.

Рис. 22.2.1. 1: Этап проектирования: абстрактный класс с абстрактными типами

Рис. 22.2.2. 2: Наследование: уточняется представление данных; задается или уточняется реализация методов родителя

Рис. 22.2.3. 3: Родовое порождение: уточняются типы данных; порождается класс путем подстановки конкретных типов
На этапе спецификации, как правило, создается абстрактный, универсальный класс, где задана только сигнатура методов, но не их реализация; где определены имена типов, но не их конкретизация. Здесь же, используя возможности тегов класса, формально или неформально задаются спецификации, описывающие семантику методов класса. Далее в ходе разработки, благодаря механизму наследования, появляются потомки абстрактного класса, каждый из которых задает реализацию методов. На следующем этапе, благодаря механизму универсализации, появляются экземпляры универсального класса, каждый из которых выполняет операции класса над данными соответствующих типов.
Для наполнения этой схемы реальным содержанием давайте рассмотрим некоторый пример с прохождением всех трех этапов.
Две проблемы с обработчиками событий
Объекты, создающие события, ничего не знают об объектах, обрабатывающих эти события. Объекты, обрабатывающие события, ничего не знают друг о друге, независимо выполняя свою работу. В такой модели могут возникать определенные проблемы. Рассмотрим некоторые из них.
Две роли классов
У класса две различные роли: модуля и типа данных. Класс - это модуль, архитектурная единица построения программной системы. Модульность построения - основное свойство программных систем. В ООП программная система, строящаяся по модульному принципу, состоит из классов, являющихся основным видом модуля. Модуль может не представлять собой содержательную единицу - его размер и содержание определяется архитектурными соображениями, а не семантическими. Ничто не мешает построить монолитную систему, состоящую из одного модуля - она может решать ту же задачу, что и система, состоящая из многих модулей.
Вторая роль класса не менее важна. Класс - это тип данных, задающий реализацию некоторой абстракции данных, характерной для задачи, в интересах которой создается программная система. С этих позиций классы - не просто кирпичики, из которых строится система. Каждый кирпичик теперь имеет важную содержательную начинку. Представьте себе современный дом, построенный из кирпичей, и дом будущего, где каждый кирпич выполняет определенную функцию: один следит за температурой, другой - за составом воздуха в доме. ОО-программная система напоминает дом будущего.
Состав класса, его размер определяется не архитектурными соображениями, а той абстракцией данных, которую должен реализовать класс. Если вы создаете класс Account, реализующий такую абстракцию как банковский счет, то в этот класс нельзя добавить поля из класса Car, задающего автомобиль.
Объектно-ориентированная разработка программной системы основана на стиле, называемом проектированием от данных. Проектирование системы сводится к поиску абстракций данных, подходящих для конкретной задачи. Каждая из таких абстракций реализуется в виде класса, которые и становятся модулями - архитектурными единицами построения нашей системы. В основе класса лежит абстрактный тип данных.
В хорошо спроектированной ОО-системе каждый класс играет обе роли, так что каждый модуль нашей системы имеет вполне определенную смысловую нагрузку. Типичная ошибка - рассматривать класс только как архитектурную единицу, объединяя под обложкой класса разнородные поля и функции, после чего становится неясным, какой же тип данных задает этот класс.
Две стратегии реализации интерфейса
Давайте опишем некоторый интерфейс, задающий дополнительные свойства объектов класса:
public interface IProps { void Prop1(string s); void Prop2 (string name, int val); }
У этого интерфейса два метода, которые и должны будут реализовать все классы - наследники интерфейса. Заметьте, у методов нет модификаторов доступа.
Класс, наследующий интерфейс и реализующий его методы, может реализовать их явно, объявляя соответствующие методы класса открытыми. Вот пример:
public class Clain:IProps { public Clain() {} public void Prop1(string s) { Console.WriteLine(s); } public void Prop2(string name, int val) { Console.WriteLine("name = {0}, val ={1}", name, val); } }//Clain
Класс реализует методы интерфейса, делая их открытыми для клиентов класса и наследников. Другая стратегия реализации состоит в том, чтобы все или некоторые методы интерфейса сделать закрытыми. Для реализации этой стратегии класс, наследующий интерфейс, объявляет методы без модификатора доступа, что по умолчанию соответствует модификатору private, и уточняет имя метода именем интерфейса. Вот соответствующий пример:
public class ClainP:IProps { public ClainP(){ } void IProps.Prop1(string s) { Console.WriteLine(s); } void IProps.Prop2(string name, int val) { Console.WriteLine("name = {0}, val ={1}", name, val); } }//class ClainP
Класс ClainP реализовал методы интерфейса IProps, но сделал их закрытыми и недоступными для вызова клиентов и наследников класса. Как же получить доступ к закрытым методам? Есть два способа решения этой проблемы:
Обертывание. Создается открытый метод, являющийся оберткой закрытого метода.Кастинг. Создается объект интерфейсного класса IProps, полученный преобразованием (кастингом) объекта исходного класса ClainP. Этому объекту доступны закрытые методы интерфейса.
В чем главное достоинство обертывания? Оно позволяет переименовывать методы интерфейса. Метод интерфейса со своим именем закрывается, а потом открывается под тем именем, которое класс выбрал для него. Вот пример обертывания закрытых методов в классе ClainP:
public void MyProp1(string s) { ((IProps)this).Prop1(s); } public void MyProp2(string s, int x) { ((IProps)this).Prop2(s, x); }
Как видите, методы переименованы и получили другие имена, под которыми они и будут известны клиентам класса. В обертке для вызова закрытого метода пришлось использовать кастинг, приведя объект this к интерфейсному классу IProps.
Двухэтапная компиляция. Управляемый модуль и управляемый код
Компиляторы языков программирования, включенные в Visual Studio .Net, создают модули на промежуточном языке MSIL (Microsoft Intermediate Language), называемом далее просто - IL. Фактически компиляторы создают так называемый управляемый модуль - переносимый исполняемый файл (Portable Executable или PE-файл). Этот файл содержит код на IL и метаданные - всю необходимую информацию как для CLR, так и конечных пользователей, работающих с приложением. О метаданных - важной новинке Framework .Net - мы еще будем говорить неоднократно. В зависимости от выбранного типа проекта, PE-файл может иметь уточнения exe, dll, mod или mdl.
Заметьте, PE-файл, имеющий уточнение exe, хотя и является exe-файлом, но это не совсем обычный, исполняемый Windows, файл. При его запуске он распознается как специальный PE-файл и передается CLR для обработки. Исполнительная среда начинает работать с кодом, в котором специфика исходного языка программирования исчезла. Код на IL начинает выполняться под управлением CLR (по этой причине код называется управляемым). Исполнительную среду можно рассматривать как своеобразную виртуальную IL-машину. Эта машина транслирует "на лету" требуемые для исполнения участки кода в команды реального процессора, который в действительности и выполняет код.
Единство каркаса
Каркас стал единым для всех языков среды. Поэтому, на каком бы языке программирования не велась разработка, она использует классы одной и той же библиотеки. Многие классы библиотеки, составляющие общее ядро, используются всеми языками. Отсюда единство интерфейса приложения, на каком бы языке оно не разрабатывалось, единство работы с коллекциями и другими контейнерами данных, единство связывания с различными хранилищами данных и прочая универсальность.
Емкость буфера
Каждый экземпляр строки класса StringBuilder имеет буфер, в котором хранится строка. Объем буфера - его емкость - может меняться в процессе работы со строкой. Объекты класса имеют две характеристики емкости - текущую и максимальную. В процессе работы текущая емкость изменяется, естественно, в пределах максимальной емкости, которая реально достаточно высока. Если размер строки увеличивается, то соответственно автоматически растет и текущая емкость. Если же размер строки уменьшается, то емкость буфера остается на том же уровне. По этой причине иногда разумно уменьшать емкость. Следует помнить, что попытка уменьшить емкость до величины, меньшей длины строки, приведет к ошибке.
У класса StringBuilder имеется 2 свойства и один метод, позволяющие анализировать и управлять емкостными свойствами буфера. Напомню, что этими характеристиками можно управлять также еще на этапе создания объекта, - для этого имеется соответствующий конструктор. Рассмотрим свойства и метод класса, связанные с емкостью буфера:
свойство Capacity - возвращает или устанавливает текущую емкость буфера;свойство MaxCapacity - возвращает максимальную емкость буфера. Результат один и тот же для всех экземпляров класса;метод int EnsureCapacity (int capacity) - позволяет уменьшить емкость буфера. Метод пытается вначале установить емкость, заданную параметром capacity; если это значение меньше размера хранимой строки, то емкость устанавливается такой, чтобы гарантировать размещение строки. Это число и возвращается в качестве результата работы метода.
Приведу код, в котором проводятся различные эксперименты с емкостью буфера:
//Емкость буфера int curvol1 = txtbuild.Capacity; int curvol2 = strbuild.Capacity; int maxvol1 = txtbuild.MaxCapacity; int maxvol2 = strbuild.MaxCapacity; Console.WriteLine("curvol1= {0}",curvol1); Console.WriteLine("curvol2= {0}",curvol2); Console.WriteLine("maxvol1= {0}",maxvol1); Console.WriteLine("maxvol2= {0}",maxvol2); int sure1 = txtbuild.EnsureCapacity(100); int sure2 = strbuild.EnsureCapacity(100); Console.WriteLine("sure1= {0}",sure1); Console.WriteLine("sure2= {0}",sure2); curvol2 = strbuild.Capacity; Console.WriteLine("curvol2= {0}",curvol2); //ошибка! попытка установить емкость меньше длины строки //strbuild.Capacity = 25; strbuild.Capacity = 256; //так можно! curvol2 = strbuild.Capacity; Console.WriteLine("curvol2= {0}",curvol2); //увеличим строку - емкость увеличится int len = txtbuild.Length; txtbuild.Append(txtbuild.ToString()); curvol1 = txtbuild.Capacity; Console.WriteLine("curvol1= {0}",curvol1); //уменьшим строку txtbuild.Remove(len, len); curvol1 = txtbuild.Capacity; Console.WriteLine("curvol1= {0}",curvol1);
В этом фрагменте кода анализируются и изменятся емкостные свойства буфера двух объектов. Демонстрируется, как меняется емкость при увеличении и уменьшении размера строки. Результаты работы этого фрагмента кода показаны на рис. 14.5.

Рис. 14.5. Анализ емкостных свойств буфера
Еще раз о двух семантиках присваивания
В заключение разговора о ссылочных и развернутых типах построим класс CPoint, являющийся полным аналогом структуры Point. Не буду приводить описание этого класса - надеюсь, оно достаточно понятно. Ограничусь примером, в котором аналогичные действия выполняются над объектами, принадлежащими структуре Point и классу CPoint:
public void TestTwoSemantics() { Console.WriteLine("Структуры: присваивание развернутого типа!"); Point pt1 = new Point(3,5), pt2; pt2 = pt1; Console.WriteLine ("pt1: " + pt1); Console.WriteLine ("pt2=pt1: " + pt2); pt1.X +=10; Console.WriteLine ("pt1.X =pt1.X +10: " + pt1); Console.WriteLine ("pt2: " + pt2); Console.WriteLine("Классы: присваивание ссылочного типа!"); CPoint cpt1 = new CPoint(3,5), cpt2; cpt2 = cpt1; Console.WriteLine ("cpt1: " + cpt1); Console.WriteLine ("cpt2=cpt1: " + cpt2); cpt1.X +=10; Console.WriteLine ("cpt1.X =cpt1.X +10: " + cpt1); Console.WriteLine ("cpt2: " + cpt2); }
Результаты вычислений показаны на рис. 17.2.

Рис. 17.2. Две семантики присваивания
Действия над объектами Point и CPoint выполняются аналогичные а результаты получаются разные: в конце вычислений pt1 и pt2 различны, а cpt1 и cpt2 совпадают.
Еще раз о семантике присваивания
Подводя итоги рассмотрения присваивания x=e, следует отметить, что семантика присваивания далеко не столь проста, как может показаться с первого взгляда. Напомню, что деление типов на значимые и ссылочные приводит к двум семантикам присваивания. Будет ли семантика значимой или ссылочной - определяется типом левой части присваивания. Переменные значимых типов являются единоличными владельцами памяти, в которой хранятся их значения. При значимом присваивании память для хранения значений остается той же - меняются лишь сами значения, хранимые в ней. Переменные ссылочных типов (объекты) являются ссылками на реальные объекты динамической памяти. Ссылки могут разделять одну и ту же область памяти - ссылаться на один и тот же объект. Ссылочное присваивание - это операция над ссылками. В результате ссылочного присваивания ссылка начинает указывать на другой объект.
Форма и элементы управления
Как населить форму элементами управления? Чаще всего, это делается вручную в режиме проектирования. Доступные элементы управления, отображаемые на специальной панели (Toolbox), перетаскиваются на форму. Этот процесс поддерживается особым инструментарием - дизайнером форм (Designer Form). Как только на этапе проектирования вы сажаете на форму элемент управления, немедленно в тексте класса появляются соответствующие строки кода (в лекции 2 об этом подробно рассказано). Конечно, все можно делать и программно - появление соответствующих строк кода приводит к появлению элементов управления на форме. Нужно понимать, что форма - это видимый образ класса Form, а элементы управления, размещенные на форме - это видимые образы клиентских объектов соответствующих классов, наследников класса Control. Так что форма с ее элементами управления есть прямое отражение программного кода.
Каждый вид элементов управления описывается собственным классом. Библиотека FCL содержит большое число классов, задающих различные элементы управления. Одним из типов проектов, доступных на C#, является проект, создающий элемент управления, так что ничто не мешает создавать собственные элементы управления и размещать их на формах наряду со встроенными элементами. Многие фирмы специализируются на создании элементов управления - это один из видов повторно используемых компонентов.
В каких отношениях находятся класс Form, класс Control, классы элементов управления? На рис. 24.1 показана иерархия отношений, связывающих эти классы.
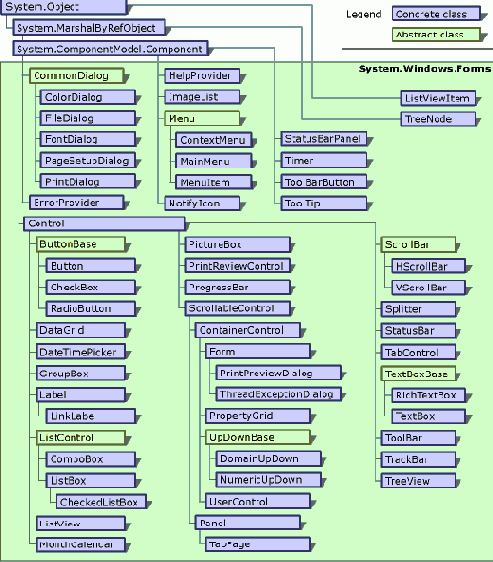
Рис. 24.1. Иерархия классов элементов управления
Естественно, все эти классы являются потомками прародителя - класса Object. Заметьте, класс Control в иерархии классов занимает довольно высокое положение, хотя и у него есть два важных родительских класса - класс Component, определяющий возможность элементам управления быть компонентами, и класс MarshalByRefObject, задающий возможность передачи элементов управления по сети. Класс Control задает важные свойства, методы и события, наследуемые всеми его потомками. Все классы элементов управления являются наследниками класса Control. Чаще всего, это прямые наследники, но иногда они имеют и непосредственного родителя, которым может быть абстрактный класс - это верно для кнопок, списков, текстовых элементов управления. Может показаться удивительным, но класс Form является одним из потомков класса Control, так что форма - это элемент управления со специальными свойствами. Будучи наследником классов ScrollableControl и ContainerControl, форма допускает прокрутку и размещение элементов управления.
Framework .Net - единый каркас среды разработки
В каркасе Framework .Net можно выделить два основных компонента:
статический - FCL (Framework Class Library) - библиотеку классов каркаса;динамический - CLR (Common Language Runtime) - общеязыковую исполнительную среду.
Framework .Net и универсальность
Универсальность принадлежит к основным механизмам языка. Ее введение в язык C# не могло не сказаться на всех его основных свойствах. Как уже говорилось, классы и все частные случаи стали обладать этим свойством. Введение универсальности не должно было ухудшить уже достигнутые свойства языка - статический контроль типов, динамическое связывание и полиморфизм. Не должна была пострадать и эффективность выполнения программ, использующих универсальные классы.
Решение этих задач потребовало введения универсальности не только в язык C#, но и поддержки на уровне каркаса Framework .Net и языка IL, включающем теперь параметризованные типы. Универсальный класс C# не является шаблоном, на основе которого строится конкретизированный класс, компилируемый далее в класс (тип) IL. Компилятору языка C# нет необходимости создавать классы для каждой конкретизации типов универсального класса. Вместо этого происходит компиляция универсального класса C# в параметризованный тип IL. Когда же CLR занимается исполнением управляемого кода, то вся необходимая информация о конкретных типах извлекается из метаданных, сопровождающих объекты.
При этом дублирования кода не происходит и на уровне JIT-компиляторов, которые, однажды сгенерировав код для конкретного типа, сохраняют ссылку на этот участок кода и передают ее, когда такой код понадобится вторично. Это справедливо как для ссылочных, так и значимых типов.
Естественно, что универсальность потребовала введения в библиотеку FCL соответствующих классов, интерфейсов, делегатов и методов классов, обладающих этим свойством.
Так, например, в класс System.Array добавлен ряд универсальных статических методов. Вот один из них:
public static int BinarySearch<T>(T[] array, T value);
В таблице 22.1 показаны некоторые универсальные классы и интерфейсы библиотеки FCL 2.0 из пространства имен System.Collections.Generic и их аналоги из пространства System.Collections.
| Comparer<T> | Comparer | ICollection<T> | ICollection |
| Dictionary<K,T> | HashTable | IComparable<T> | IComparable |
| LinkedList<T> | ---- | IDictionary<K,T> | IDictionary |
| List<T> | ArrayList | IEnumerable<T> | IEnumerable |
| Queue<T> | Queue | IEnumerator<T> | IEnumerator |
| SortedDictionary<K,T> | SortedList | IList<T> | IList |
| Stack<T> | Stack |
Сериализация и универсализация также согласуются друг с другом, так что можно иметь универсальный класс, для которого задан атрибут сериализации.
Функции с побочным эффектом
Функция называется функцией с побочным эффектом, если помимо результата, вычисляемого функцией и возвращаемого ей в операторе return, она имеет выходные аргументы с ключевыми словами ref и out. В языках C/C++ функции с побочным эффектом применяются сплошь и рядом. Хороший стиль ОО-программирования не рекомендует использование таких функций. Выражения, использующие функции с побочным эффектом, могут потерять свои прекрасные свойства, присущие им в математике. Если f(a) - функция с побочным эффектом, то a+f(a) может быть не равно f(a) +a, так что теряется коммутативность операции сложения.
Примером такой функции является функция f, приведенная выше. Вот тест, демонстрирующий потерю коммутативности сложения при работе с этой функцией:
/// <summary> /// тестирование побочного эффекта /// </summary> public void TestSideEffect() { int a = 0, b=0, c=0; a =1; b = a + f(ref a); a =1; c = f(ref a)+ a; Console.WriteLine("a={0}, b={1}, c={2}",a,b,c); }
На рис. 9.2 показаны результаты работы этого метода.

Рис. 9.2. Демонстрация вызова функции с побочным эффектом
Обратите внимание на полезность указания ключевого слова ref в момент вызова. Его появление хоть как-то оправдывает некоммутативность сложения.
Функции высших порядков
Одно из наиболее важных применений делегатов связано с функциями высших порядков. Функцией высшего порядка называется такая функция (метод) класса, у которой один или несколько аргументов принадлежат к функциональному типу. Без этих функций в программировании обойтись довольно трудно. Классическим примером является функция вычисления интеграла, у которой один из аргументов задает подынтегральную функцию. Другим примером может служить функция, сортирующая объекты. Аргументом ее является функция Compare, сравнивающая два объекта. В зависимости от того, какая функция сравнения будет передана на вход функции сортировки, объекты будут сортироваться по-разному, например, по имени, или по ключу, или по нескольким полям. Вариантов может быть много, и они определяются классом, описывающим сортируемые объекты.
Где, как и когда выполняются преобразования типов?
Необходимость в преобразовании типов возникает в выражениях, присваиваниях, замене формальных аргументов метода фактическими.
Если при вычислении выражения операнды операции имеют разные типы, то возникает необходимость приведения их к одному типу. Такая необходимость возникает и тогда, когда операнды имеют один тип, но он несогласован с типом операции. Например, при выполнении сложения операнды типа byte должны быть приведены к типу int, поскольку сложение не определено над байтами. При выполнении присваивания x=e тип источника e и тип цели x должны быть согласованы. Аналогично, при вызове метода также должны быть согласованы типы источника и цели - фактического и формального аргументов.
Главная кнопочная форма
Одним из образцов, применимых к главной форме, является главная кнопочная форма. Такая форма состоит из текстового окна, в котором описывается приложение и его возможности, и ряда командных кнопок; обработчик каждой кнопки открывает форму, позволяющую решать одну из задач, которые поддерживаются данным приложением. В качестве примера рассмотрим Windows-приложение, позволяющее работать с различными динамическими структурами данных. Главная кнопочная форма такого приложения показана на рис. 24.2.

Рис. 24.2. Главная кнопочная форма
Обработчик события Click для каждой командной кнопки открывает форму для работы с соответствующей динамической структурой данных. Вот как выглядит обработчик события кнопки Список:
private void button4_Click(object sender, System.EventArgs e) { //Переход к показу формы для работы со списком FormList fl= new FormList(); fl.Show(); }
Как видите, открывается новая форма для работы со списком, но главная форма не закрывается и остается открытой.
Глобальные переменные уровня модуля. Существуют ли они в C#?
Где еще могут объявляться переменные? Во многих языках программирования переменные могут объявляться на уровне модуля. Такие переменные называются глобальными. Их область действия распространяется, по крайней мере, на весь модуль. Глобальные переменные играют важную роль, поскольку они обеспечивают весьма эффективный способ обмена информацией между различными частями модуля. Обратная сторона эффективности аппарата глобальных переменных, - их опасность. Если какая-либо процедура, в которой доступна глобальная переменная, некорректно изменит ее значение, то ошибка может проявиться в другой процедуре, использующей эту переменную. Найти причину ошибки бывает чрезвычайно трудно. В таких ситуациях приходится проверять работу многих компонентов модуля.
В языке C# роль модуля играют классы, пространства имен, проекты, решения. Поля классов, о которых шла речь выше, могут рассматриваться как глобальные переменные класса. Но здесь у них особая роль. Данные (поля) являются тем центром, вокруг которого вращается мир класса. Заметьте, каждый экземпляр класса - это отдельный мир. Поля экземпляра (открытые и закрытые) - это глобальная информация, которая доступна всем методам класса, играющим второстепенную роль - они обрабатывают данные.
Статические поля класса хранят информацию, общую для всех экземпляров класса. Они представляют определенную опасность, поскольку каждый экземпляр способен менять их значения.
В других видах модуля - пространствах имен, проектах, решениях - нельзя объявлять переменные. В пространствах имен в языке C# разрешено только объявление классов и их частных случаев: структур, интерфейсов, делегатов, перечислений. Поэтому глобальных переменных уровня модуля, в привычном для других языков программирования смысле, в языке C# нет. Классы не могут обмениваться информацией, используя глобальные переменные. Все взаимодействие между ними обеспечивается способами, стандартными для объектного подхода. Между классами могут существовать два типа отношений - клиентские и наследования, а основной способ инициации вычислений - это вызов метода для объекта-цели или вызов обработчика события. Поля класса и аргументы метода позволяют передавать и получать нужную информацию. Устранение глобальных переменных как источника опасных, трудно находимых ошибок существенно повышает надежность создаваемых на языке C# программных продуктов.
Введем в класс Testing нашего примера три закрытых поля и добавим конструктор с параметрами, инициализирующий значения полей при создании экземпляра класса:
//fields int x,y; //координаты точки string name; //имя точки //конструктор с параметрами public Testing(int x, int y, string name) { this.x = x; this.y = y; this.name = name; }
В процедуре Main первым делом создается экземпляр класса Testing, а затем вызываются методы класса, тестирующие различные ситуации:
Testing ts = new Testing(5,10,"Точка1"); ts.SimpleVars();
Глобальные переменные уровня процедуры. Существуют ли?
Поскольку процедурный блок имеет сложную структуру с вложенными внутренними блоками, то и здесь возникает тема глобальных переменных. Переменная, объявленная во внешнем блоке, рассматривается как глобальная по отношению к внутренним блокам. Во всех известных мне языках программирования во внутренних блоках разрешается объявлять переменные с именем, совпадающим с именем глобальной переменной. Конфликт имен снимается за счет того, что локальное внутреннее определение сильнее внешнего. Поэтому область видимости внешней глобальной переменной сужается и не распространяется на те внутренние блоки, где объявлена переменная с подобным именем. Внутри блока действует локальное объявление этого блока, при выходе восстанавливается область действия внешнего имени. В языке C# этот гордиев узел конфликтующих имен разрублен, - во внутренних блоках запрещено использование имен, совпадающих с именем, использованным во внешнем блоке. В нашем примере незаконная попытка объявить во внутреннем блоке уже объявленное имя y закомментирована.
Обратите внимание, что подобные решения, принятые создателями языка C#, не только упрощают жизнь разработчикам транслятора. Они способствуют повышению эффективности программ, а самое главное, повышают надежность программирования на C#.
Отвечая на вопрос, вынесенный в заголовок, следует сказать, что глобальные переменные на уровне процедуры в языке C#, конечно же, есть, но нет конфликта имен между глобальными и локальными переменными на этом уровне. Область видимости глобальных переменных процедурного блока распространяется на весь блок, в котором они объявлены, начиная от точки объявления, и не зависит от существования внутренних блоков. Когда говорят, что в C# нет глобальных переменных, то, прежде всего, имеют в виду их отсутствие на уровне модуля. Уже во вторую очередь речь идет об отсутствии конфликтов имен на процедурном уровне.
Игнорирование коллег
Задумывались ли вы, какую роль играет ключевое слово event, появляющееся при объявлении события? Событие, объявленное в классе, представляет экземпляр делегата. В предыдущей лекции, когда речь шла о делегатах, их экземпляры объявлялись без всяких дополнительных ключевых слов.
Слово "event" играет важную роль, позволяя решить проблему, названную нами "игнорированием коллег". В чем ее суть? В том, что некоторые из классов Receiver могут вести себя некорректно по отношению к своим коллегам, занимающимся обработкой того же события. При присоединении обработчика события в классе Receiver можно попытаться вместо присоединения обработчика выполнить операцию присваивания, игнорируя, тем самым, уже присоединенный список обработчиков. Взгляните еще раз на процедуру OnConnect класса Receiver2; там демонстрируется такая попытка в закомментированном операторе. Аналогично, в процедуре OffConnect вместо отсоединения (операции -) можно попытаться присвоить событию значение null, отсоединяя тем самым всех других обработчиков.
С этим как-то нужно бороться. Ключевое слово "event" дает указание компилятору создать для события закрытое поле, доступ к которому можно получить только через два автоматически создаваемых для события метода: Add, выполняющий операцию присоединения "+=", и Remove, выполняющий обратную операцию отсоединения "-=". Никаких других операций над событиями выполнять нельзя. Тем самым, к счастью, решается проблема игнорирования коллег. Ошибки некорректного поведения класса Receiver ловятся еще на этапе трансляции.
Имя .Net
Имена нынешнего поколения продуктов от Microsoft сопровождаются окончанием .Net (читается Dot Net), отражающим видение Microsoft современного коммуникативного мира. Компьютерные сети объединяют людей и технику. Человек, работающий с компьютером или использующий мобильный телефон, естественным образом становится частью локальной или глобальной сети. В этой сети используются различные специальные устройства, начиная от космических станций и кончая датчиками, расположенными, например, в гостиницах и посылающими информацию об объекте всем мобильным устройствам в их окрестности. В глобальном информационном мире коммуникативная составляющая любых программных продуктов начинает играть определяющую роль.
В программных продуктах .Net за этим именем стоит вполне конкретное содержание, которое предполагает, в частности, наличие открытых стандартов коммуникации, переход от создания монолитных приложений к созданию компонентов, допускающих повторное использование в разных средах и приложениях. Возможность повторного использования уже созданных компонентов и легкость расширения их функциональности - все это непременные атрибуты новых технологий. Важную роль в этих технологиях играет язык XML, ставший стандартом обмена сообщениями в сети.
Не пытаясь охватить все многообразие сетевого взаимодействия, рассмотрим реализацию новых идей на примере Visual Studio .Net - продукта, важного для разработчиков.
Индексаторы
Свойства являются частным случаем метода класса с особым синтаксисом. Еще одним частным случаем является индексатор. Метод-индексатор является обобщением метода-свойства. Он обеспечивает доступ к закрытому полю, представляющему массив. Объекты класса индексируются по этому полю.
Синтаксически объявление индексатора - такое же, как и в случае свойств, но методы get и set приобретают аргументы по числу размерности массива, задающего индексы элемента, значение которого читается или обновляется. Важным ограничением является то, что у класса может быть только один индексатор и у этого индексатора стандартное имя this. Так что если среди полей класса есть несколько массивов, то индексация объектов может быть выполнена только по одному из них.
Добавим в класс Person свойство children, задающее детей персоны, сделаем это свойство закрытым, а доступ к нему обеспечит индексатор:
const int Child_Max = 20; //максимальное число детей Person[] children = new Person[Child_Max]; int count_children=0; //число детей public Person this[int i] //индексатор { get {if (i>=0 && i< count_children)return(children[i]); else return(children[0]);} set { if (i==count_children && i< Child_Max) {children[i] = value; count_children++;} } }
Имя у индексатора - this, в квадратных скобках в заголовке перечисляются индексы. В методах get и set, обеспечивающих доступ к массиву children, по которому ведется индексирование, анализируется корректность задания индекса. Закрытое поле count_children, хранящее текущее число детей, доступно только для чтения благодаря добавлению соответствующего метода-свойства. Надеюсь, текст процедуры-свойства Count_children сумеете написать самостоятельно. Запись в это поле происходит в методе set индексатора, когда к массиву children добавляется новый элемент.
Протестируем процесс добавления детей персоны и работу индексатора:
public void TestPersonChildren() { Person pers1 = new Person(), pers2 = new Person(); pers1.Fam = "Петров"; pers1.Age = 42; pers1.Salary = 10000; pers1[pers1.Count_children] = pers2; pers2.Fam ="Петров"; pers2.Age = 21; pers2.Salary = 1000; Person pers3= new Person("Петрова"); pers1[pers1.Count_children] = pers3; pers3.Fam ="Петрова"; pers3.Age = 5; Console.WriteLine ("Фам={0}, возраст={1}, статус={2}", pers1.Fam, pers1.Age, pers1.Status); Console.WriteLine ("Сын={0}, возраст={1}, статус={2}", pers1[0].Fam, pers1[0].Age, pers1[0].Status); Console.WriteLine ("Дочь={0}, возраст={1}, статус={2}", pers1[1].Fam, pers1[1].Age, pers1[1].Status); }
Заметьте, индексатор создает из объекта как бы массив объектов, индексированный по соответствующему полю, в данном случае по полю children. На рис. 16.2 показаны результаты вывода.

Рис. 16.2. Работа с индексатором класса
Интерфейс ISerializable
При необходимости можно самому управлять процессом сериализации. В этом случае наш класс должен быть наследником интерфейса ISerializable. Класс, наследующий этот интерфейс, должен реализовать единственный метод этого интерфейса GetObjectData и добавить защищенный конструктор. Схема сериализации и десериализации остается и в этом случае той же самой. Можно использовать как бинарный форматер, так и soap-форматер. Но теперь метод Serialize использует не стандартную реализацию, а вызывает метод GetObjectData, управляющий записью данных. Метод Deserialize, в свою очередь, вызывает защищенный конструктор, создающий объект и заполняющий его поля сохраненными значениями.
Конечно, возможность управлять сохранением и восстановлением данных дает большую гибкость и позволяет, в конечном счете, уменьшить размер файла, хранящего данные, что может быть крайне важно, особенно если речь идет об обмене данными с удаленным приложением. Если речь идет о поверхностной сериализации, то атрибут NonSerialized, которым можно помечать поля, не требующие сериализации, как правило, достаточен для управления эффективным сохранением данных. Так что управлять имеет смысл только глубокой сериализацией, когда сохраняется и восстанавливается граф объектов. Но, как уже говорилось, это может быть довольно сложным занятием, что будет видно и для нашего простого примера с рыбаком и рыбкой.
Рассмотрим, как устроен метод GetObjectData, управляющий сохранением данных. У этого метода два аргумента:
GetObjectData(SerializedInfo info, StreamingContext context)
Поскольку самому вызывать этот метод не приходится - он вызывается автоматически методом Serialize, то можно не особенно задумываться о том, как создавать аргументы метода. Более важно понимать, как их следует использовать. Чаще всего используется только аргумент info и его метод AddValue (key, field). Данные сохраняются вместе с ключом, используемым позже при чтении данных. Аргумент key, который может быть произвольной строкой, задает ключ, а аргумент field - поле объекта. Например, для сохранения полей name и age можно задать следующие операторы:
info.AddValue("name",name); info.AddValue("age", age);
Поскольку имена полей уникальны, то их разумно использовать в качестве ключей.
Если поле son класса Father является объектом класса Child и этот класс сериализуем, то для сохранения объекта son следует вызвать метод:
son.GetObjectData(info, context)
Если не возникает циклов, причиной которых являются взаимные ссылки, то особых сложностей с сериализацией и десериализацией не возникает. Взаимные ссылки осложняют картину и требуют индивидуального подхода к решению. На последующем примере мы покажем, как можно справиться с этой проблемой в конкретном случае.
Перейдем теперь к рассмотрению специального конструктора класса. Он может быть объявлен с атрибутом доступа private, но лучше, как и во многих других случаях, применять атрибут protected, что позволит использовать этот конструктор потомками класса, осуществляющими собственную сериализацию. У конструктора те же аргументы, что и у метода GetObjectData. Опять-таки, в основном используется аргумент info и его метод GetValue(key, type), который выполняет операцию, обратную к операции метода AddValue. По ключу key находится хранимое значение, а аргумент type позволяет привести его к нужному типу. У метода GetValue имеется множество типизированных версий, позволяющих не задавать тип. Так что восстановление полей name и age можно выполнить следующими операторами:
name = info.GetString("name"); age = info.GetInt32("age");
Восстановление поля son, являющегося ссылочным типом, выполняется вызовом его специального конструктора:
son = new Child(info, context);
А теперь вернемся к нашему примеру со стариком, старухой и золотой рыбкой. Заменим стандартную сериализацию собственной. Для этого, оставив атрибут сериализации у класса Personage, сделаем класс наследником интерфейса ISerializable:
[Serializable] public class Personage :ISerializable {...}
Добавим в наш класс специальный метод, вызываемый при сериализации - метод сохранения данных:
//Специальный метод сериализации public void GetObjectData(SerializationInfo info, StreamingContext context) { info.AddValue("name",name); info.AddValue("age", age); info.AddValue("status",status); info.AddValue("wealth", wealth); info.AddValue("couplename",couple.name); info.AddValue("coupleage", couple.age); info.AddValue("couplestatus",couple.status); info.AddValue("couplewealth", couple.wealth); }
В трех первых строках сохраняются значимые поля объекта и тут все ясно. Но вот запомнить поле, хранящее объект couple класса Personage, напрямую не удается. Попытка рекурсивного вызова
couple.GetObjectData(info,context);
привела бы к зацикливанию, если бы раньше из-за повторяющегося ключа не возникала исключительная ситуация в момент записи поля name объекта couple. Поэтому приходится явно сохранять поля этого объекта уже с другими ключами. Понятно, что с ростом сложности структуры графа объектов задача существенно осложняется.
Добавим в наш класс специальный конструктор, вызываемый при десериализации - конструктор восстановления состояния:
//Специальный конструктор сериализации protected Personage(SerializationInfo info, StreamingContext context) { name = info.GetString("name"); age = info.GetInt32("age"); status = info.GetString("status"); wealth = info.GetString("wealth"); couple = new Personage(info.GetString("couplename"), info.GetInt32("coupleage")); couple.status = info.GetString("couplestatus"); couple.wealth = info.GetString("couplewealth"); this.couple = couple; couple.couple = this; }
Опять первые строки восстановления значимых полей объекта прозрачно ясны. А с полем couple приходится повозиться. Вначале создается новый объект обычным конструктором, аргументы которого читаются из сохраняемой памяти. Затем восстанавливаются значения других полей этого объекта, а затем уже происходит взаимное связывание двух объектов.
Кроме введения конструктора класса и метода GetObjectData, никаких других изменений в проекте не понадобилось - ни в методах класса, ни на стороне клиента. Внешне проект работал совершенно идентично ситуации, когда не вводилось наследование интерфейса сериализации. Но с внутренних позиций изменения произошли: методы форматеров Serialize и Deserialize в процессе своей работы теперь вызывали созданный нами метод и конструктор класса. Небольшие изменения произошли и в файлах, хранящих данные.
Мораль: должны быть веские основания для отказа от стандартно реализованной сериализации. Повторюсь, такими основаниями могут служить необходимость в уменьшении объема файла, хранящего данные, и в сокращении времени передачи данных.
Когда в нашем примере вводилось собственное управление сериализацией, то не ставилась цель минимизации объема хранимых данных, в обоих случаях сохранялись одни и те же данные. Тем не менее представляет интерес взглянуть на таблицу, хранящую объемы создаваемых файлов.
| Бинарный поток | Стандартная | 355 байтов |
| Бинарный поток | Управляемая | 355 байтов |
| XML-документ | Стандартная | 1, 14 Кб. |
| XML-документ | Управляемая | 974 байта |
Интерфейсы
Слово "интерфейс" многозначное и в разных контекстах оно имеет различный смысл. В данной лекции речь идет о понятии интерфейса, стоящем за ключевым словом interface. В таком понимании интерфейс - это частный случай класса. Интерфейс представляет собой полностью абстрактный класс, все методы которого абстрактны. От абстрактного класса интерфейс отличается некоторыми деталями в синтаксисе и поведении. Синтаксическое отличие состоит в том, что методы интерфейса объявляются без указания модификатора доступа. Отличие в поведении заключается в более жестких требованиях к потомкам. Класс, наследующий интерфейс, обязан полностью реализовать все методы интерфейса. В этом - отличие от класса, наследующего абстрактный класс, где потомок может реализовать лишь некоторые методы родительского абстрактного класса, оставаясь абстрактным классом. Но, конечно, не ради этих отличий были введены интерфейсы в язык C#. У них значительно более важная роль.
|
Введение в язык частных случаев усложняет его и свидетельствует о некоторых изъянах, для преодоления которых и вводятся частные случаи. Например, введение структур в язык C# позволило определять классы как развернутые типы. Конечно, проще было бы ввести в объявление класса соответствующий модификатор, позволяющий любой класс объявлять развернутым. Но этого сделано не было, а, следуя традиции языка С++, были введены структуры как частный случай классов. Подробнее о развернутых и ссылочных типах см. лекцию 17. |
Интерфейсы позволяют частично справиться с таким существенным недостатком языка, как отсутствие множественного наследования классов. Хотя реализация множественного наследования встречается с рядом проблем, его отсутствие существенно снижает выразительную мощь языка. В языке C# полного множественного наследования классов нет. Чтобы частично сгладить этот пробел, допускается множественное наследование интерфейсов. Обеспечить возможность классу иметь несколько родителей - один полноценный класс, а остальные в виде интерфейсов, - в этом и состоит основное назначение интерфейсов.
Отметим одно важное назначение интерфейсов. Интерфейс позволяет описывать некоторые желательные свойства, которыми могут обладать объекты разных классов. В библиотеке FCL имеется большое число подобных интерфейсов, с некоторыми из них мы познакомимся в этой лекции. Все классы, допускающие сравнение своих объектов, обычно наследуют интерфейс IComparable, реализация которого позволяет сравнивать объекты не только на равенство, но и на "больше", "меньше".
Инварианты и варианты цикла
Циклы, как правило, являются наиболее сложной частью метода - большинство ошибок связано именно с ними. При написании корректно работающих циклов крайне важно понимать и использовать понятия инварианта и варианта цикла. Без этих понятий не обходится и формальное доказательство корректности циклов. Ограничимся рассмотрением цикла в следующей форме:
Init(x,z); while(B)S(x,z);
Здесь B - условие цикла while, S - его тело, а Init - группа предшествующих операторов, задающая инициализацию цикла. Реально ни один цикл не обходится без инициализирующей части. Синтаксически было бы правильно, чтобы Init являлся бы формальной частью оператора цикла. В операторе for это частично сделано - инициализация счетчиков является частью цикла.
Определение 3 (инварианта цикла): предикат Inv(x, z) называется инвариантом цикла while, если истинна следующая триада Хоара:
{Inv(x, z)& B}S(x,z){Inv(x,z)}
Содержательно это означает, что из истинности инварианта цикла до начала выполнения тела цикла и из истинности условия цикла, гарантирующего выполнение тела, следует истинность инварианта после выполнения тела цикла. Сколько бы раз ни выполнялось тело цикла, его инвариант остается истинным.
Для любого цикла можно написать сколь угодно много инвариантов. Любое тождественное условие (2*2 =4) является инвариантом любого цикла. Поэтому среди инвариантов выделяются так называемые подходящие инварианты цикла. Они называются подходящими, поскольку позволяют доказать корректность цикла по отношению к его пред- и постусловиям. Как доказать корректность цикла? Рассмотрим соответствующую триаду:
{Pre(x)} Init(x,z); while(B)S(x,z);{Post(x,z)}
Доказательство разбивается на три этапа. Вначале доказываем истинность триады:
(*) {Pre(x)} Init(x,z){RealInv(x,z)}
Содержательно это означает, что предикат RealInv становится истинным после выполнения инициализирующей части. Далее доказывается, что RealInv является инвариантом цикла:
(**) {RealInv(x, z)& B} S(x,z){RealInv(x,z)}
На последнем шаге доказывается, что наш инвариант обеспечивает решение задачи после завершения цикла:
(***) ~B & RealInv(x, z) -> Post(x,z)
Это означает, что из истинности инварианта и условия завершения цикла следует требуемое постусловие.
Определение 4 (подходящего инварианта): предикат RealInv, удовлетворяющий условиям (*), (**), (***) называется подходящим инвариантом цикла.
С циклом связано еще одно важное понятие - варианта цикла, используемое для доказательства завершаемости цикла.
Определение 5 (варианта цикла): целочисленное неотрицательное выражение Var(x, z) называется вариантом цикла, если выполняется следующая триада:
{(Var(x,z)= n) & B} S(x,z){(Var(x,z)= m) & (m < n)}
Содержательно это означает, что каждое выполнение тела цикла приводит к уменьшению значения его варианта. После конечного числа шагов вариант достигает своей нижней границы, и цикл завершается. Простейшим примером варианта цикла является выражение n-i для цикла:
for(i=1; i<=n; i++) S(x, z);
Пользоваться инвариантами и вариантами цикла нужно не только и не столько для того, чтобы проводить формальное доказательство корректности циклов. Они способствуют написанию корректных циклов. Правило корректного программирования гласит: "При написании каждого цикла программист должен определить его подходящий инвариант и вариант". Задание предусловий, постусловий, вариантов и инвариантов циклов является такой же частью процесса разработки корректного метода, как и написание самого кода.
Исключения и охраняемые блоки. Первое знакомство
В этом примере мы впервые встречаемся с охраняемыми try-блоками. Исключениям и способам их обработки посвящена отдельная лекция, но не стоит откладывать надолго знакомство со столь важным механизмом. Как показывает практика программирования, любая вызываемая программа не гарантирует, что в процессе ее работы не возникнут какие-либо неполадки, в результате которых она не сможет выполнить свою часть контракта. Исключения являются нормальным способом уведомления об ошибках в работе программы. Возникновение ошибки в работе программы должно приводить к выбрасыванию исключения соответствующего типа, следствием чего является прерывание нормального хода выполнения программы и передача управления обработчику исключения - стандартному или предусмотренному самой программой.
|
Заметьте, рекомендуемый стиль программирования в C# отличается от стиля, принятого в языках С/C++, где функция, в которой возникла ошибка, завершается нормальным образом, уведомляя об ошибке в возвращаемом значении результата. Вызывающая программа должна анализировать результат, чтобы понять, была ли ошибка в работе вызванной функции и какова ее природа. При программировании в стиле C# ответственность за обнаружение ошибок лежит на вызванной программе. Она должна не только обнаружить ошибку, но и явно сообщить о ней, выбрасывая исключение соответствующего типа. Вызываемая программа должна попытаться исправить последствия ошибки в обработчике исключения. Подробности смотри в лекции про исключения. |
В состав библиотеки FCL входит класс Exception, свойства и методы которого позволяют работать с исключениями как с объектами, получать нужную информацию, дополнять объект собственной информацией. У класса Exception - большое число потомков, каждый из которых описывает определенный тип исключения. При проектировании собственных классов можно параллельно проектировать и классы, задающие собственный тип исключений, который может выбрасываться в случае ошибок при работе методов класса. Создаваемый класс исключений должен быть потомком класса Exception.
Если в некотором модуле предполагается возможность появления исключений, то разумно предусмотреть и их обработку. В этом случае в модуле создается охраняемый try-блок, предваряемый ключевым словом try. Вслед за этим блоком следуют один или несколько блоков, обрабатывающих исключения, - catch-блоков. Каждый catch-блок имеет формальный параметр класса Exception или одного из его потомков. Если в try-блоке возникает исключение типа T, то catch-блоки начинают конкурировать в борьбе за перехват исключения. Первый по порядку catch-блок, тип формального аргумента которого согласован с типом T - совпадает с ним или является его потомком - захватывает исключение и начинает выполняться; поэтому порядок написания catch-блоков небезразличен. Вначале должны идти специализированные обработчики. Универсальным обработчиком является catch-блок с формальным параметром родового класса Exception, согласованным с исключением любого типа T. Универсальный обработчик, если он есть, стоит последним, поскольку захватывает исключение любого типа.
Конечно, плохо, когда в процессе работы той или иной процедуры возникает исключение. Однако его появление еще не означает, что процедура не сможет выполнить свой контракт. Исключение может быть нужным образом обработано, после чего продолжится нормальный ход вычислений приложения. Гораздо хуже, когда возникают ошибки в работе процедуры, не приводящие к исключениям. Тогда работа продолжается с неверными данными без исправления ситуации и даже без уведомления о возникновении ошибки. Наш пример показывает, что вычисления в C# могут быть небезопасными и следует применять специальные средства языка, такие как, например, checked-блоки, чтобы избежать появления подобных ситуаций.
Вернемся к обсуждению нашего примера. Здесь как в проверяемых, так и в непроверяемых блоках находятся охраняемые блоки с соответствующими обработчиками исключительных ситуаций. Во всех случаях применяется универсальный обработчик, захватывающий любое исключение в случае его возникновения в try-блоке. Сами обработчики являются простыми уведомителями, они лишь сообщают об ошибочной ситуации, не пытаясь исправить ее.
Исключительные ситуации
Что происходит, когда при вызове некоторой функции (процедуры) обнаруживается, что она не может нормальным образом выполнить свою работу? Возможны разные варианты обработки такой ситуации. Функция может возвращать код ошибки или специальное значение типа HResult, может выбрасывать исключение, тип которого характеризует возникшую ошибку. В CLR принято во всех таких ситуациях выбрасывать исключение. Косвенно это влияет и на язык программирования. Выбрасывание исключений наилучшим образом согласуется с исполнительной средой. В языке C# выбрасывание исключений, их дальнейший перехват и обработка - основной рекомендуемый способ обработки исключительных ситуаций.
Искусство отладки
Нужно стараться создавать надежный код. Но без отладки пока обойтись невозможно. Роль тестеров в современном процессе разработки ПО велика.
Отладка - это некоторый детективный процесс. Программа, в которую внесены изменения, подозревается в том, что она работает некорректно. Презумпция невиновности здесь не применима. Если удается предъявить тест, на котором программа дает неверный результат, то доказано, что подозрения верны. Втайне мы всегда надеемся, что программа работает правильно. Но цель тестирования другая - попытаться опровергнуть это предположение. Отладка может доказать некорректность программы, но она не может доказать ее правильность. Отладка не гарантирует корректности программы, даже если все тесты пройдены успешно. Искусное тестирование создает высокую степень уверенности в корректности программы.
Часть ошибок программы ловится автоматически еще на этапе компиляции. Сюда относятся все синтаксические ошибки, ошибки несоответствия типов и некоторые другие. Это простые ошибки и их исправление, как правило, не вызывает трудностей. В отладке нуждается синтаксически корректная программа, результаты вычислений которой получены, но не соответствуют требуемым спецификациям. Чаще всего еще не отлаженная программа на одних исходных данных работает правильно, на других - дает ошибочный результат. Искусство отладки состоит в том, чтобы обнаружить все ситуации, в которых работа программы приводит к ошибочным вычислениям.
Как и во всякой детективной деятельности, в ходе отладки необходим сбор улик, для чего применяется две группы средств. Первая позволяет контролировать ход вычислительного процесса: порядок следования операторов в методах, порядок вызова самих методов, условия окончания циклов, правильность переходов. Вторая отслеживает изменение состояния вычислительного процесса (значения свойств объектов) в процессе выполнения.
Есть и другая классификация. Средства, используемые при отладке, можно разделить на инструментарий, предоставляемый средой разработки Visual Studio .Net, и программные средства, предоставляемые языком и специальными классами библиотеки FCL. Начнем рассмотрение с программных средств.
Явные преобразования
Как уже говорилось, явные преобразования могут быть опасными из-за потери точности. Поэтому они выполняются по указанию программиста, - на нем лежит вся ответственность за результаты.
Элемент управления класса ListBox
Во многих задачах пользователю предлагается некоторый список товаров, гостиниц, услуг и прочих прелестей, и он должен выбрать некоторое подмножество элементов из этого списка. Элемент управления ListBox позволяет собрать в виде списка некоторое множество объектов и отобразить для каждого объекта связанную с ним строку. Он дает возможность пользователю выбрать из списка один или несколько элементов.
В списке могут храниться строки, тогда объект совпадает с его отображением. Если же хранятся объекты, то в классе объекта следует переопределить метод ToString, возвращаемый результат которого и будет строкой, отображаемой в списке.
Давайте рассмотрим главный вопрос: как список заполняется элементами? Есть несколько разных способов. Новой и интересной технологией, применимой к самым разным элементам управления, является связывание элемента управления с данными, хранящимися в различных хранилищах, прежде всего, в базах данных. Для этого у списка есть ряд свойств - DataBinding и другие. Эта технология заслуживает отдельного рассмотрения, я о ней только упоминаю, но рассматривать ее не буду. Рассмотрим три других способа.
Заполнить список элементами можно еще на этапе проектирования. Для этого достаточно выбрать свойство Items: появится специальное окно для заполнения списка строками - элементами списка. Добавлять объекты других классов таким способом невозможно.
Но это можно делать при программной работе со свойством Items, возвращающим специальную коллекцию объектов, которая задана классом ObjectCollection. Эта коллекция представляет объекты, хранимые в списке, и является основой для работы со списком. Класс ObjectCollection предоставляет стандартный набор методов для работы с коллекцией - вставки, удаления и поиска элементов. Метод Add позволяет добавить новый объект в конец коллекции, метод Insert позволяет добавить элемент в заданную позицию, указанную индексом. Метод AddRange позволяет добавить сразу множество элементов, заданное обычным массивом, массивом класса ListArray или коллекцией, возвращаемой свойством Items другого списка. Для удаления элементов используются методы Remove, RemoveAt, Clear. Метод Contains позволяет определить, содержится ли заданный объект в коллекции, а метод IndexOf позволяет определить индекс такого элемента. Коллекция может автоматически сортироваться, для этого достаточно задать значение true свойства Sorted, которым обладает список ListBox.
Еще один способ задания элементов списка поддерживается свойством DataSource, значение которого позволяет указать источник данных, ассоциируемый со списком. Понятно, что этот способ является альтернативой коллекции, задаваемой свойством Items. Так что, если источник данных определен свойством DataSource, то нельзя использовать методы класса ObjectCollection - Add и другие для добавления или удаления элементов списка, - необходимо изменять сам источник данных.
Главное назначение элемента ListBox - предоставить пользователю возможность осуществлять выбор из отображаемых списком элементов. Свойство SelectionMode позволяет указать, сколько элементов разрешается выбирать пользователю - один или несколько. Для работы с отобранными элементами имеется ряд свойств. SelectedItem и SelectedIndex возвращают первый отобранный элемент и его индекс. Свойства SelectedItems и SelectedIndices возвращают коллекции, заданные классами SelectedObjectCollection и SelectedIndexCollection, которые дают возможность анализировать все отобранные пользователем объекты. Методы Contains и IndexOf позволяют определить, выбрал ли пользователь некоторый элемент. Добавлять или удалять элементы из этих коллекций нельзя.
Среди других методов и свойств ListBox - упомяну свойство MultiColumn, с помощью которого можно организовать показ элементов списка в нескольких столбцах; свойство HorizonalScrollBar, задающее горизонтальный скроллинг; методы BeginUpdate и EndUpdate, позволяющие повысить эффективность работы со списком. Все методы по добавлению и удалению элементов, стоящие после BeginUpdate, не будут приводить к перерисовке списка, пока не встретится метод EndUpdate.
У элемента управления ListBox большое число событий, с некоторыми из которых мы встретимся при рассмотрении примеров. Перейдем теперь к рассмотрению примеров работы с этим элементом управления и, как обещано, построим некоторый шаблон, демонстрирующий работу с двумя списками, когда пользователь может переносить данные из одного списка в другой и обратно. На рис. 24.4 показано, как выглядит форма, реализующая данный шаблон.

Рис. 24.4. Шаблон формы для обмена данными двух списков
На форме показаны два списка - listBox1 и listBox2, между которыми расположены две командные кнопки. Обработчик события Click первой кнопки переносит выбранную группу элементов одного списка в конец другого списка, (если включено свойство Sorted, то автоматически поддерживается сортировка списка). Переносимые элементы удаляются из первого списка. Вторая кнопка реализует операцию переноса всех элементов списка. Направление переноса - из левого списка в правый и обратно - задается заголовками (">", ">>") или ("<", "<<"), изображенными на кнопках. Заголовки меняются автоматически в обработчиках события Enter, возникающих при входе в левый или правый списки - listBox1 или listBox2. Еще две командные кнопки, как следует из их заголовков, предназначены для закрытия формы с сохранением или без сохранения результатов работы пользователя. Таково общее описание шаблона. А теперь рассмотрим реализацию. Начнем с обработчиков события Enter наших списков:
private void listBox1_Enter(object sender, System.EventArgs e) { /*** Событие Enter у списка возникает при входе в список ***/ button1.Text = ">"; button2.Text = ">>"; } private void listBox2_Enter(object sender, System.EventArgs e) { /*** Событие Enter у списка возникает при входе в список ***/ button1.Text = "<"; button2.Text = "<<"; }
Посмотрим, как устроены обработчики события Click для командных кнопок, осуществляющих перенос данных между списками:
private void button1_Click(object sender, System.EventArgs e) { /* Обработчик события Click кнопки "> <" * Выборочный обмен данными между списками * ListBox1 <-> ListBox2******************/ if(button1.Text == ">") MoveSelectedItems(listBox1, listBox2); else MoveSelectedItems(listBox2, listBox1); } private void button2_Click(object sender, System.EventArgs e) { /* Обработчик события Click кнопки ">> <<" * Перенос всех данных одного списка в конец другого списка * ListBox1 <-> ListBox2******************/ if(button2.Text == ">>") MoveAllItems(listBox1, listBox2); else MoveAllItems(listBox2, listBox1); }
Обработчики событий устроены достаточно просто - они вызывают соответствующий метод, передавая ему нужные аргументы в нужном порядке. Рассмотрим метод, переносящий множество отобранных пользователем элементов из одного списка в другой:
private void MoveSelectedItems(ListBox list1, ListBox list2) { /*** Выделенные элементы списка list1 **** *** помещаются в конец списка List2 ***** *** и удаляются из списка list1 ********/ list2.BeginUpdate(); foreach (object item in list1.SelectedItems) { list2.Items.Add(item); } list2.EndUpdate(); ListBox.SelectedIndexCollection indeces = list1.SelectedIndices; list1.BeginUpdate(); for (int i = indeces.Count -1; i>=0 ; i--) { list1.Items.RemoveAt(indeces[i]); } list1.EndUpdate(); }
Некоторые комментарии к этому тексту. Заметьте, для добавления выделенных пользователем элементов к другому списку используется коллекция SelectedItems и метод Add, поочередно добавляющий элементы коллекции. Метод AddRange для добавления всей коллекции здесь не проходит:
list2.Items.AddRange(list1.SelectedItems);
поскольку нет автоматического преобразования между коллекциями ObjectCollection и SelectedObjectCollection.
Для удаления выделенных элементов из списка list1 используется коллекция индексов. Обратите внимание, при удалении элемента с заданным индексом из любой коллекции индексы оставшихся элементов автоматически пересчитываются. Поэтому удаление элементов происходит в обратном порядке, начиная с последнего, что гарантирует корректность оставшихся индексов.
Намного проще устроен метод, переносящий все элементы списка:
private void MoveAllItems(ListBox list1, ListBox list2) { /*** Все элементы списка list1 **** **** переносятся в конец списка list2 **** **** список list1 очищается *************/ list2.Items.AddRange(list1.Items); list1.Items.Clear(); }
Добавим еще одну функциональную возможность - разрешим переносить элементы из одного списка в другой двойным щелчком кнопки мыши. Для этого зададим обработчики события DoubleClick наших списков:
private void listBox1_DoubleClick(object sender, System.EventArgs e) { /* Обработчик события DoubleClick левого списка * Выбранный элемент переносится в правый список * ListBox1 <-> ListBox2******************/ MoveSelectedItems(listBox1, listBox2); } private void listBox2_DoubleClick(object sender, System.EventArgs e) { /* Обработчик события DoubleClick правого списка * Выбранный элемент переносится в левый список * ListBox1 <-> ListBox2******************/ MoveSelectedItems(listBox2, listBox1); }
Обработчики вызывают уже рассмотренные нами методы.
На этом закончим рассмотрение функциональности проектируемого образца формы. Но, скажете вы, остался не заданным целый ряд вопросов: непонятно, как происходит заполнение списков, как сохраняются элементы после завершения переноса, обработчики события Click для двух оставшихся кнопок не определены. Ничего страшного. Сделаем нашу форму родительской, возложив решение оставшихся вопросов на потомков, пусть каждый из них решает эти вопросы по-своему.
Как определяется функциональный тип и как появляются его экземпляры
Слово делегат (delegate) используется в C# для обозначения хорошо известного понятия. Делегат задает определение функционального типа (класса) данных. Экземплярами класса являются функции. Описание делегата в языке C# представляет собой описание еще одного частного случая класса. Каждый делегат описывает множество функций с заданной сигнатурой. Каждая функция (метод), сигнатура которого совпадает с сигнатурой делегата, может рассматриваться как экземпляр класса, заданного делегатом. Синтаксис объявления делегата имеет следующий вид:
[<спецификатор доступа>] delegate <тип результата > <имя класса> (<список аргументов>);
Этим объявлением класса задается функциональный тип - множество функций с заданной сигнатурой, у которых аргументы определяются списком, заданным в объявлении делегата, и тип возвращаемого значения определяется типом результата делегата.
Спецификатор доступа может быть, как обычно, опущен. Где следует размещать объявление делегата? Как и у всякого класса, есть две возможности:
непосредственно в пространстве имен, наряду с объявлениями других классов, структур, интерфейсов;внутри другого класса, наряду с объявлениями методов и свойств. Такое объявление рассматривается как объявление вложенного класса.
Так же, как и интерфейсы C#, делегаты не задают реализации. Фактически между некоторыми классами и делегатом заключается контракт на реализацию делегата. Классы, согласные с контрактом, должны объявить у себя статические или динамические функции, сигнатура которых совпадает с сигнатурой делегата. Если контракт выполняется, то можно создать экземпляры делегата, присвоив им в качестве значений функции, удовлетворяющие контракту. Заметьте, контракт является жестким: не допускается ситуация, при которой у делегата тип параметра - object, а у экземпляра соответствующий параметр имеет тип, согласованный с object, например, int.
Начнем примеры этой лекции с объявления трех делегатов. Поместив два из них в пространство имен, третий вложим непосредственно в создаваемый нами класс:
namespace Delegates { //объявление классов - делегатов delegate void Proc(ref int x); delegate void MesToPers(string s); class OwnDel { public delegate int Fun1(int x); int Plus1( int x){return(x+100);}//Plus1 int Minus1(int x){return(x-100);}//Minus1 void Plus(ref int x){x+= 100;} void Minus(ref int x){x-=100;} //поля класса public Proc p1; public Fun1 f1; char sign; //конструктор public OwnDel(char sign) { this.sign = sign; if (sign == '+') {p1 = new Proc(Plus);f1 = new Fun1(Plus1);} else {p1 = new Proc(Minus);f1 = new Fun1(Minus1);} } }//class OwnDel
Прокомментирую этот текст.
Первым делом объявлены три функциональных класса - три делегата: Proc, MesToPers, Fun1. Каждый из них описывает множество функций фиксированной сигнатуры.В классе OwnDel описаны четыре метода: Plus, Minus, Plus1, Minus1, сигнатуры которых соответствуют сигнатурам, задаваемых классами Proc и Fun1.Поля p1 и f1 класса OwnDel являются экземплярами классов Proc и Fun1.В конструкторе класса поля p1 и f1 связываются с конкретными методами Plus или Minus, Plus1 или Minus1. Связывание с той или иной функцией в данном случае определяется значением поля sign.
Заметьте, экземпляры делегатов можно рассматривать как ссылки (указатели на функции), а методы тех или иных классов с соответствующей сигнатурой можно рассматривать как объекты, хранимые в динамической памяти. В определенный момент происходит связывание ссылки и объекта (в этой роли выступают не обычные объекты, имеющие поля, а методы, задающие код). Взгляд на делегата как на указатель функции характерен для программистов, привыкших к С++.
Приведу теперь процедуру, тестирующую работу созданного класса:
public void TestOwnDel() { int account = 1000, account1=0; OwnDel oda = new OwnDel('+'); Console.WriteLine("account = {0}, account1 = {1}", account, account1); oda.p1(ref account); account1=oda.f1(account); Console.WriteLine("account = {0}, account1 = {1}", account, account1); }
Клиент класса OwnDel создает экземпляр класса, передавая конструктору знак той операции, которую он хотел бы выполнить над своими счетами - account и account1. Вызов p1 и f1, связанных к моменту вызова с закрытыми методами класса, приводит к выполнению нужных функций.
В нашем примере объявление экземпляров делегатов и связывание их с внутренними методами класса происходило в самом классе. Клиенту оставалось лишь вызывать уже созданные экземпляры, но эту работу можно выполнять и на стороне клиентского класса, чем мы сейчас и займемся. Рассмотрим многократно встречавшийся класс Person, слегка изменив его определение:
class Person { //конструкторы public Person(){name =""; id=0; salary=0.0;} public Person(string name){this.name = name;} public Person (string name, int id, double salary) {this.name = name; this.id=id; this.salary = salary;} public Person (Person pers) {this.name = pers.name; this.id = pers.id; this.salary = pers.salary;} //методы public void ToPerson(string mes) { this.message = mes; Console.WriteLine("{0}, {1}",name, message); } //свойства private string name; private int id; private double salary; private string message; //доступ к свойствам public string Name {get {return(name);} set {name = value;}} public double Salary {get {return(salary);} set {salary = value;}} public int Id {get {return(id);} set {id = value;}} }//class Person
Класс Person устроен обычным способом: у него несколько перегруженных конструкторов, закрытые поля и процедуры-свойства для доступа к ним. Особо обратить внимание прошу на метод класса ToPerson, сигнатура которого совпадает с сигнатурой класса, определенной введенным ранее делегатом MesToPers. Посмотрите, как клиент класса может связать этот метод с экземпляром делегата, определенного самим клиентом:
Person man1 = new Person("Владимир"); MesToPers mestopers = new MesToPers(man1.ToPerson); mestopers("пора работать!");
Обратите внимание, что поскольку метод ToPerson не является статическим методом, то при связывании необходимо передать и объект, вызывающий метод. Более того, переданный объект становится доступным экземпляру делегата. Отсюда сразу же становится ясным, что экземпляры делегата - это не просто указатели на функцию, а более сложно организованные структуры. Они, по крайней мере, содержат пару указателей на метод и на объект, вызвавший метод. Вызываемый метод в своей работе использует как информацию, передаваемую ему через аргументы метода, так и информацию, хранящуюся в полях объекта. В данном примере переданное сообщение "пора работать" присоединится к имени объекта, и результирующая строка будет выдана на печать. В тех случаях, когда метод, связываемый с экземпляром делегата, не использует информацию объекта, этот метод может быть объявлен как статический метод класса. Таким образом, инициализировать экземпляры делегата можно как статическими, так и динамическими методами, связанными с конкретными объектами.
Последние три строки были добавлены в вышеприведенную тестирующую процедуру. Взгляните на результаты ее работы.

Рис. 20.1. Объявление делегатов и создание их экземпляров
Как получить подробную информацию о классе?
Пожалуй, следует рассказать не только о том, как можно получить переменную типа Type, а и о том, что можно с этой переменной делать.
|
Этот и последующий раздел прерывают последовательное рассмотрение темы операций языка C#. Полагаю, понимание того, с какой целью выполняются те или иные операции, не менее важно, чем знание самой операции, И я не стал откладывать изложение этого материала на последующие лекции. |
Можно ли, зная тип (класс), получить подробную информацию обо всех методах и полях класса? Ясно, что такая информация может быть весьма полезной, если класс поставлен сторонней фирмой. Оказывается, это сделать нетрудно. Вся необходимая информация содержится в метаданных, поставляемых вместе с классом. Процесс получения метаданных называется отражением (reflection). Об отражении и метаданных уже говорилось в первой вводной лекции, и эта тема будет обсуждаться и далее. А сейчас я приведу пример, демонстрирующий получение подробной информации о методах и полях класса. Первым делом следует упростить в проекте использование классов пространства имен Reflection, добавив в начало проекта предложение
using System.Reflection.
В класс Testing я добавил существенно расширенный вариант метода WhoIsWho, который уже появлялся в наших примерах. Вот текст новой версии этой процедуры:
/// <summary> /// Подробная информация о классе объекта, его значении, /// методах класса, всех членов класса /// </summary> /// <param name="name">имя объекта</param> /// <param name="any">объект любого типа</param> public void WhoIsWho(string name,object any) { Type t = any.GetType(); Console.WriteLine("Тип {0}: {1} , значение: {2}", name, any.GetType(), any.ToString()); Console.WriteLine("Методы класса:"); MethodInfo[] ClassMethods = t.GetMethods(); foreach (MethodInfo curMethod in ClassMethods) { Console.WriteLine(curMethod); } Console.WriteLine("Все члены класса:"); MemberInfo[] ClassMembers = t.GetMembers(); foreach (MemberInfo curMember in ClassMembers) { Console.WriteLine(curMember.ToString()); } }//WhoIsWho
Коротко прокомментирую эту процедуру. Вначале
Коротко прокомментирую эту процедуру. Вначале создается переменная t типа Type. Значением этой переменной будет тип аргумента, переданного в процедуру в качестве значения параметра any. Напомню, any имеет базовый тип object и потому метод может быть вызван с аргументом, роль которого может играть выражение любого типа. Далее вызываются методы переменной t - GetMethods() и GetMembers(). Эти методы соответственно возвращают в качестве значений массивы элементов классов MethodInfo и MemberInfo. Эти классы содержатся в пространстве имен Reflection, они хранят информацию в первом случае о методах класса, во втором - о полях и методах класса, заданного переменной t. В пространстве имен Reflection имеются и другие классы, чьи методы и свойства полезны для получения дополнительной информации об исследуемом классе. Но я не буду сейчас столь подробно развивать эту тему.
В процедуре Main дважды вызывается процедура WhoIsWho. В первом вызове ее аргументом является выражение типа double, во втором - сам объект ts, вызывающий метод:
ts.WhoIsWho("2+2.5", 2+2.5); ts.WhoIsWho("ts", ts);
И класс double, и созданный в этом проекте класс Testing имеют довольно много методов. Имеют они и свойства. Процедура WhoIsWho выдаст подробную информацию обо всех элементах этих классов. Результаты консольного вывода, полученного при двух вызовах этой процедуры, показаны на рис. 6.2.

Рис. 6.2. Информация о классах int и Testing, полученная в процедуре WhoIsWho
Рассмотрим выводимую информацию о классах. Для созданного в проекте класса Testing отображается информация о полях и методах как собственных, так и наследуемых от общего родителя - класса Object. Заметьте, отображается информация только об открытых полях и методах класса, а поскольку поля нашего класса закрыты, то и информации о них нет.
Класс Int подробно обсуждался в предыдущей и в этой лекции. Все методы, которые могут вызывать переменные (объекты) класса Int, были уже рассмотрены. Тем не менее, из выводимой информации можно узнать и нечто новое, поскольку выдаются сведения и о статических полях и методах класса.
Как справиться с арифметикой
Представьте себе, что мы хотим иметь специализированный вариант нашего списка, элементы которого допускали бы операцию сложения и одно из полей которого сохраняло бы сумму всех элементов, добавленных в список. Как задать соответствующее ограничение на класс?
Как уже говорилось, наличие ограничения операции, где можно было бы указать, что над элементами определена операция +, решало бы проблему. Но такого типа ограничений нет. Хуже того, нет и интерфейса INumeric, аналогичного IComparable, определяющего метод сложения Add. Так что нам не может помочь и ограничение наследования.
Вот один из возможных выходов, предлагаемых в такой ситуации. Стратегия следующая: определим абстрактный универсальный класс Calc с методами, выполняющими вычисления. Затем создадим конкретизированных потомков этого класса. В классе, задающем список с суммированием, введем поле класса Calc. При создании экземпляров класса будем передавать фактические типы ключа и элементов, а также соответствующий калькулятор, но уже не как тип, а как аргумент конструктора класса. Этот калькулятор, согласованный с типом элементов, и будет выполнять нужные вычисления. Давайте приступим к реализации этой стратегии. Начнем с определения класса Calc:
public abstract class Calc<T> { public abstract T Add(T a, T b); public abstract T Sub(T a, T b); public abstract T Mult(T a, T b); public abstract T Div(T a, T b); }
Наш абстрактный универсальный класс определяет четыре арифметические операции. Давайте построим трех его конкретизированных потомков:
public class IntCalc : Calc<int> { public override int Add(int a, int b) { return (a + b);} public override int Sub(int a, int b) { return (a - b);} public override int Mult(int a, int b) { return (a * b);} public override int Div(int a, int b) { return (a / b); } } public class DoubleCalc : Calc<double> { public override double Add(double a, double b) {return (a + b);} public override double Sub(double a, double b) {return (a - b);} public override double Mult(double a, double b) {return (a * b);} public override double Div(double a, double b) {return (a / b);} } public class StringCalc : Calc<string> { public override string Add(string a, string b) {return (a + b);} public override string Sub(string a, string b) {return (a );} public override string Mult(string a, string b) {return (a );} public override string Div(string a, string b) {return (a);} }
Здесь определяются три разных калькулятора: один - над целочисленными данными, другой - над данными с плавающей точкой, третий - над строковыми данными. В последнем случае определена, по сути, только операция сложения строк (конкатенации).
Теперь нам нужно ввести изменения в ранее созданный класс OneLinkList. Обратите внимание на важный технологический принцип работы с объектными системами. Пусть уже есть нормально работающий класс с нормально работающими клиентами класса. Не следует изменять этот класс. Класс закрыт для изменений. Используйте наследование и открывайте класс-потомок, в который и вносите изменения, учитывающие добавляемую специфику класса. Принцип "Закрыт - Открыт" является одним из важнейших принципов построения программных систем в объектном стиле.
В полном соответствии с этим принципом построим класс SumList - потомок класса OneLinkList. То, что родительский класс является универсальным, ничуть не мешает строить потомка класса, сохраняющего универсальный характер родителя.
public class SumList<K, T> : OneLinkList<K, T> where K : IComparable<K>
{ Calc<T> calc; T sum; public SumList(Calc<T> calc) { this.calc = calc; sum = default(T); } public new void add(K key, T item) { Node<K, T> newnode = new Node<K, T>(); if (first == null) { first = newnode; cursor = newnode; newnode.key = key; newnode.item = item; sum = calc.Add(sum, item); } else { newnode.next = cursor.next; cursor.next = newnode; newnode.key = key; newnode.item = item; sum = calc.Add(sum, item); } } public T Sum() {return (sum); } }//SumList
У класса добавилось поле sum, задающее сумму хранимых элементов, и поле calc - калькулятор, выполняющий вычисления. Метод add, объявленный в классе с модификатором new, скрывает родительский метод add, задавая собственную реализацию этого метода. Родительский метод можно было бы определить как виртуальный, переопределив его у потомка, но я не стал трогать код родительского класса. К классу добавился еще один запрос, возвращающий значение поля sum.
Некоторые изменения в уже существующем проекте пришлось-таки сделать, изменив статус доступа у полей. А все потому, что в целях экономии текста кода я не стал закрывать поля и вводить, как положено, открытые процедуры-свойства для закрытых полей.
Проведем теперь эксперименты с новыми вариантами списков, допускающих суммирование элементов:
public void TestSum() { SumList<string, int> list1 = new SumList<string, int>(new IntCalc()); list1.add("Петр", 33); list1.add("Павел", 44); Console.WriteLine("sum= {0}", list1.Sum()); SumList<string, double> list2 = new SumList<string, double> (new DoubleCalc()); list2.add("Петр", 33.33); list2.add("Павел", 44.44); Console.WriteLine("sum= {0}", list2.Sum()); SumList<string, string> list3 = new SumList<string, string> (new StringCalc()); list3.add("Мама", " Мама мыла "); list3.add("Маша", "Машу мылом!"); Console.WriteLine("sum= {0}", list3.Sum()); }
Обратите внимание на создание списков:
SumList<string, int> list1 = new SumList<string, int>(new IntCalc()); SumList<string, double> list2 = new SumList<string, double>(new DoubleCalc()); SumList<string, string> list3 = new SumList<string, string>(new StringCalc());
Как видите, конструктору объекта передается калькулятор, согласованный с типами данных, которые хранятся в списке. Результаты вычислений, полученных при работе с этими списками, приведены на рис. 22.6.
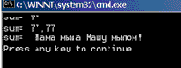
Рис. 22.6. Списки с суммированием
Как зажигаются события
Причины возникновения события могут быть разными. Поэтому вполне вероятно, что одно и то же событие будет зажигаться в разных методах класса в тот момент, когда возникнет одна из причин появления события. Поскольку действия по включению могут повторяться, полезно в состав методов класса добавить защищенную процедуру, включающую событие. Даже если событие зажигается только в одной точке, написание такой процедуры считается признаком хорошего стиля. Этой процедуре обычно дается имя, начинающееся со слова On, после которого следует имя события. Будем называть такую процедуру On-процедурой. Она проста и состоит из вызова объявленного события, включенного в тест, который проверяет перед вызовом, а есть ли хоть один обработчик события, способный принять соответствующее сообщение. Если таковых нет, то нечего включать событие. Приведу пример:
protected virtual void OnFire(int time, int build) { if (FireEvent!=null) FireEvent(this,time, build); }
Хочу обратить внимание: те, кто принимает сообщение о событии, должны заранее присоединить обработчики событий к объекту FireEvent, задающему событие. Присоединение обработчиков должно предшествовать зажиганию события. При таком нормальном ходе вещей, найдется хотя бы один слушатель сообщения о событии - следовательно, FireEvent не будет равно null.
Заметьте также, что процедура On объявляется, как правило, с модификаторами protected virtual. Это позволяет потомкам класса переопределить ее, когда, например, изменяется набор аргументов события.
Последний шаг, который необходимо выполнить в классе Sender - это в нужных методах класса вызвать процедуру On. Естественно, что перед вызовом нужно определить значения входных аргументов события. После вызова может быть выполнен анализ выходных аргументов, определенных обработчиками события. Чуть позже рассмотрим более полные примеры, где появится вызов процедуры On.
Кисти и краски
Создадим в нашем проекте новую форму RandomShapes, в которой будем рисовать и закрашивать геометрические фигуры трех разных типов - эллипсы, сектора, прямоугольники. Для каждого типа фигуры будем использовать свой тип кисти: эллипсы будем закрашивать градиентной кистью, сектора - сплошной, а прямоугольники - узорной. Цвет фигуры, ее размеры и положение будем выбирать случайным образом. Рисование фигур будет инициироваться в обработчике события Click. При каждом щелчке кнопкой мыши на форме будут рисоваться три новых экземпляра фигур каждого типа. В отличие от кривых Безье, старые фигуры стираться не будут.
На рис. 24.15 показана форма после нескольких щелчков кнопки мыши. Конечно, черно-белый рисунок в книге не может передать цвета, особенно смену оттенков для градиентной кисти. На экране дисплея или цветном рисунке все выглядит красивее.
А теперь приведем программный код, реализующий рисование. Начнем, как обычно, с полей класса:
//fields int cx,cy; Graphics graph; Brush brush; Color color; Random rnd;
Инициализация полей производится в методе MyInit, вызываемом конструктором класса:

Рис. 24.15. Рисование кистями разного типа
void MyInit() { cx = ClientSize.Width; cy = ClientSize.Height; graph = CreateGraphics(); rnd = new Random(); }
Рассмотрим теперь основной метод, реализующий рисование фигур различными кистями:
void DrawShapes() { for(int i=0; i<3; i++) { //выбирается цвет - красный, желтый, голубой int numcolor = rnd.Next(3); switch (numcolor) { case 0: color = Color.Blue; break; case 1: color = Color.Yellow; break; case 2: color = Color.Red; break; } //градиентной кистью рисуется эллипс, //местоположение случайно Point top = new Point(rnd.Next(cx), rnd.Next(cy)); Size sz = new Size(rnd.Next(cx-top.X), rnd.Next(cy-top.Y)); Rectangle rct = new Rectangle(top, sz); Point bottom = top + sz; brush = new LinearGradientBrush(top, bottom, Color.White,color); graph.FillEllipse(brush,rct); //сплошной кистью рисуется сектор, //местоположение случайно top = new Point(rnd.Next(cx), rnd.Next(cy)); sz = new Size(rnd.Next(cx-top.X), rnd.Next(cy-top.Y)); rct = new Rectangle(top, sz); brush = new SolidBrush(color); graph.FillPie(brush,rct,30f,60f); //узорной кистью рисуется прямоугольник, //местоположение случайно top = new Point(rnd.Next(cx), rnd.Next(cy)); sz = new Size(rnd.Next(cx-top.X), rnd.Next(cy-top.Y)); rct = new Rectangle(top, sz); HatchStyle hs = (HatchStyle)rnd.Next(52); brush = new HatchBrush(hs,Color.White, Color.Black); graph.FillRectangle(brush,rct); } }
Приведу некоторые комментарии в дополнение к тем, что встроены в текст метода. Здесь многое построено на работе со случайными числами. Случайным образом выбирается один из возможных цветов для рисования фигуры, ее размеры и положение. Наиболее интересно рассмотреть создание кистей разного типа. Когда создается градиентная кисть.
brush = new LinearGradientBrush(top, bottom, Color.White,color);
то нужно в конструкторе кисти задать две точки и два цвета. Точки определяют интервал изменения оттенков цвета от первого до второго. В начальной точке имеет место первый цвет, в конечной - второй, в остальных точках - их комбинация. Разумно, как это сделано у нас, в качестве точек выбирать противоположные углы прямоугольника, ограничивающего рисуемую фигуру.
Наиболее просто задается сплошная кисть:
brush = new SolidBrush(color);
Для нее достаточно указать только цвет. Для узорной кисти нужно задать предопределенный тип узора, всего их возможно 52. В нашем примере тип узора выбирается случайным образом:
HatchStyle hs = (HatchStyle)rnd.Next(52); brush = new HatchBrush(hs,Color.White, Color.Black);
Помимо первого аргумента, задающего тип узора, указываются еще два цвета - первый определяет цвет повторяющегося элемента, второй - цвет границы между элементами узора.
Непосредственное рисование кистью осуществляют методы группы Fill:
graph.FillEllipse(brush,rct); graph.FillPie(brush,rct,30f,60f); graph.FillRectangle(brush,rct);
Первый аргумент всегда задает кисть, а остальные зависят от типа рисуемой фигуры. Как правило, всегда задается прямоугольник, ограничивающий данную фигуру.
Вызов метода DrawShapes, как уже говорилось, встроен в обработчик события Click формы RandomShapes:
private void RandomShapes_Click(object sender, System.EventArgs e) { DrawShapes(); }
На этом поставим точку в рассмотрении данной темы. По сути, этим завершается и наш учебный курс. В последней лекции будет рассмотрен некоторый заключительный проект.
